







 MWC 2018
MWC 2018 2018
2018 Computex
Computex
⇣ Содержание

Опрос
|
реклама
Самое интересное в новостях
Аналоговый ИИ: теперь и на конденсаторах
Ещё в середине 2025 г. основанный Навином Верма (Naveen Verma), профессором Принстонского университета, стартап EnCharge AI заявил о доведении до готовности к серийному производству аналогового ИИ-ускорителя EN100. Чип этот демонстрирует, по заявлению разработчика, двадцатикратное превосходство над классическими микросхемами, которые применяют (в составе графических ускорителей Nvidia или AMD) на ПК для локального исполнения моделей искусственного интеллекта. Однопроцессорная плата расширения типоразмера M.2, содержащая EN100 со всей необходимой обвязкой, обеспечивает, как утверждает разработчик, производительность в 200 трлн операций в секунду (Топс), рассеивая не более 8,25 Вт мощности, и предназначена для установки в персональные компьютеры, включая мобильные. Предусмотрена и четырёхпроцессорная плата с интерфейсом PCIe для рабочих станций и периферийных систем (edge cpmpiting) — она достигает порога в 1000 Топс. 
Локальный ИИ даже без пассивных радиаторов? Говорят, сработает (источник: EnCharge AI) Вообще говоря, прототипов перспективных электрических (именно электрических; фотоника — особая статья) вычислителей, реализующих аналоговый принцип вычислений прямо в памяти (in-memory computing, IMC) для решения ИИ-задач, появляется в последние годы немало. И по большей части базируются они на резистивных электротехнических элементах — переменных сопротивлениях различного рода. Всё дело в том, что матричное умножение — основа функционирования больших языковых моделей (БЯМ) — великолепно реализуется именно на аналоговых электросхемах с переменными резисторами благодаря чрезвычайно удачному сочетанию двух базовых законов, что описывают функционирование таких схем. Речь идёт о законе Ома, представляющем силу тока как произведение напряжения на проводимость (величину, обратную сопротивлению), и первом правиле Кирхгофа: алгебраическая сумма токов, входящих в данный узел, равна сумме токов, выходящих из него. Получается, что проводимости (или сопротивления, смотря как удобнее считать) выступают в роли весов на входах перцептронов, а распространяющиеся по отдельным шинам токи — в роли сигналов, модифицируемых этими весами. Всё просто и здорово, — вот только эти перспективные прототипы, новости о которых мелькают на профильных веб-сайтах далеко уже не первый год, при всех их бесспорных потенциальных достоинствах в широкую серию не идут, да и в целом особенного прогресса на резистивном направлении IMC пока что-то не намечается. Подход же EnCharge AI — несколько иной: эта компания делает ставку не на переменные сопротивления той или иной физической природы, а на формируемые фотолитографическим методом на кремниевой подложке миниатюрные конденсаторы — и вот здесь, похоже, шансов добиться достойного результата чуть больше. По крайней мере, сравнительно недавно начатые разработки продолжают вестись полным ходом: стартап уже завершил первый этап своей программы раннего доступа, собрал отзывы от партнёров, учёл их замечания и готовит к запуску второй этап. EnCharge AI активно сотрудничает с OEM-производителями и разработчиками программного обеспечения с целью интегрировать свои решения в клиентские устройства и программные экосистемы — в ПК с локально исполняемым Microsoft Copilot, к примеру. В чём же принципиальное преимущество конденсаторных аналоговых ИИ-вычислителей перед резистивными? 
Персонального умного советчика — в каждый ноутбук! (Источник: EnCharge AI) ⇡#Слишком много стохастикиКак мы уже отмечали, функционирование современных БЯМ сводится, по большому счёту, к авторегрессионному предугадыванию следующего токена в цепочке, начало формирования которой положено подсказкой пользователя (в текстовой или любой иной исходной форме, значения не имеет, — всё равно она преобразуется в конечном итоге в токены). В формулу же для определения следующего члена авторегрессионной последовательности входит стохастическое — случайное — слагаемое, то бишь та самая неалгоритмическая «сумасшедшинка», что и выдачу ответов на пользовательские запросы делает более человекоподобной, но и за присущие современным моделям ИИ галлюцинации в немалой степени отвечает. Без стохастического компонента при цифровом моделировании работы нейросетей в памяти фоннеймановских машин не обойтись; другое дело, что влияние его разработчики стараются дозировать и контролировать. А как обстоят дела со случайностью в аналоговых резистивных — мемристорных, в частности, — вычислителях? Оказывается, её там избыточно много, и, хуже того, тонкому контролю она практически не поддаётся. Формально говоря, даже одиночные импульсы (стробы), распространяющиеся по контурам вычислительной системы, всё равно представляют собой аналоговые токи. Однако регистрация их существенно дискретна: грубо говоря, если рабочее напряжение контура — 5 В, то за «логическую 1» регистрирующая система может принять всплеск и в 2,7 В, и в 3,3 В, и тем более в 5,2 В, тогда как «логический 0» — это и, например, 0,2 В, и 0,8 В. Иными словами, на уровне логической схемы сигналы всё равно будут дискретными, даже если фактические их значения заметно отклонятся от штатных величин — вследствие каких-нибудь паразитных наводок, скажем. Аналоговый же сигнал — непрерывный; для него принципиально важно, чтобы при передаче от одного логического контура к другому значение в, условно, 1,8 В не превратилось бы ни в 1,6 В, ни тем более в 2,1 В. В противном случае информация на очередной этап обработки поступит попросту некорректная, и толку от функционирования такой системы выйдет исчезающе мало. 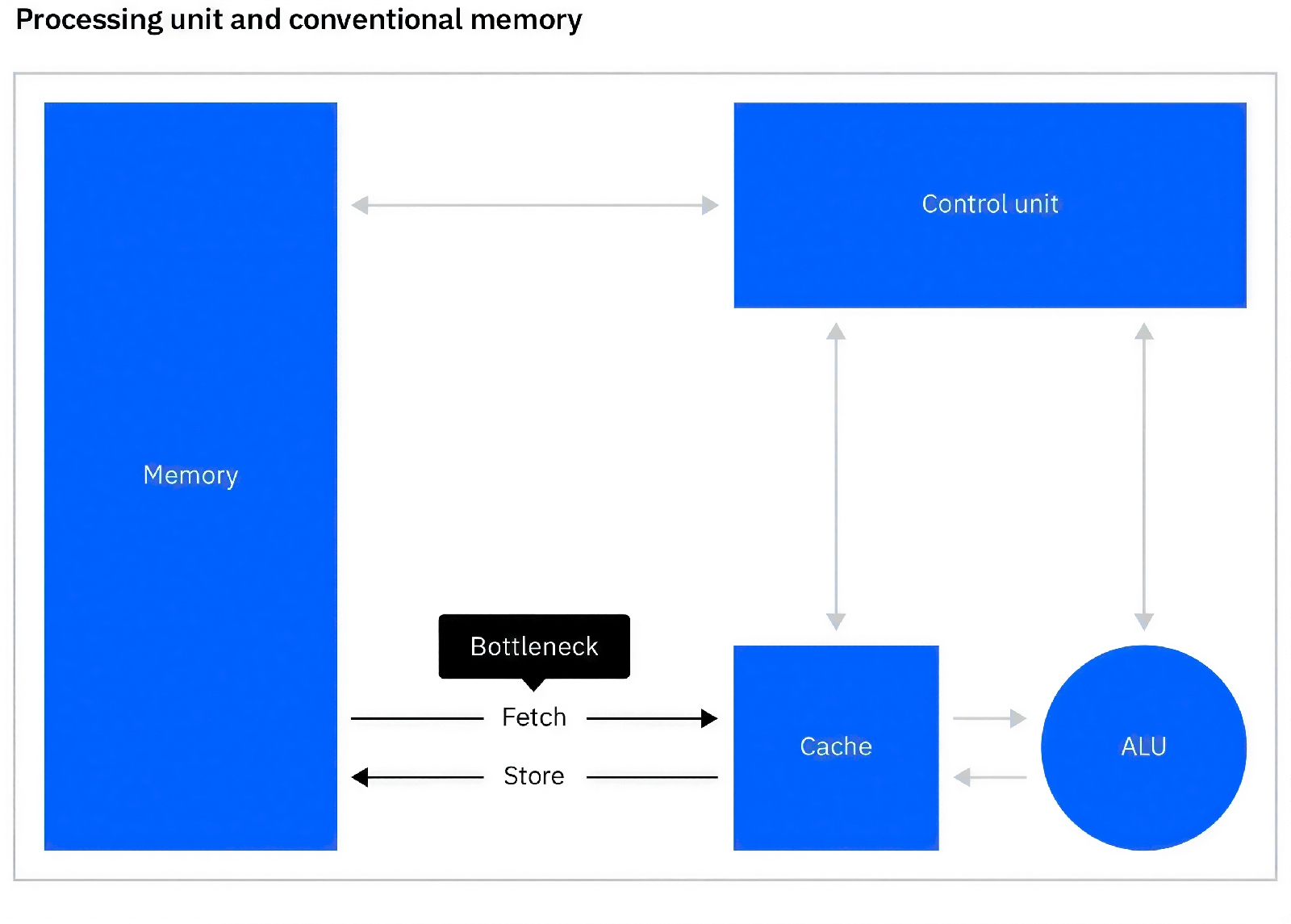
Бутылочное горлышко фон Неймана между основной памятью, хранящей триллионы весов БЯМ, и арифметически-логическим устройством (ALU), на котором производятся операции над этими весами, не на шутку сдерживает развитие ИИ (источник: IBM) И даже если отвлечься от искажений аналогового сигнала на стадии передачи между отдельными узлами вычислительной схемы, сами эти узлы тоже, увы, не без греха. Взять хотя бы такое популярное направление развития аналоговых ИИ-машин, как системы на ячейках резистивной памяти RRAM (resistive random-access memory), вроде бы прекрасно подходящих для реализации малоэнергоёмких масштабных вычислений непосредственно in-memory, минуя пресловутое бутылочное горлышко фон Неймана. Проводимость каждой ячейки RRAM напрямую кодирует синаптический вес на данном входе одного из перцептронов, так что при наличии достаточного числа таких ячеек без особых технических ухищрений можно построить натуральную — физическую, а не эмулированную в памяти прожорливого по части энергии классического сервера — глубокую плотную нейросеть. Но вот какая загвоздка: в ходе обучения этой нейросети придётся менять значения весов, а процедура эта для RRAM реализуется через приложение достаточно высокого напряжения к выбранной ячейке в течение строго определённого времени. А поскольку изготовить даже две полностью идентичные (вплоть до числа формирующих их атомов и взаимного расположения тех) ячейки не представляется возможным, при воздействии на них одного и того же импульса (оставим даже в стороне вопрос о принципиальной возможности сформировать независимо два совершенно одинаковых строба в аналоговой логической схеме) итоговая их проводимость будет чуточку различаться. Пусть на сотые или даже десятитысячные доли процента, — но с учётом масштабности современных БЯМ по части количества параметров (тех самых синаптических весов), что исчисляются уже триллионами, очевидно: ошибки при обучении ИИ, реализованного на RRAM, неизбежно будут копиться, и чем крупнее модель, тем раньше стохастически обусловленное несовершенство аппаратной платформы себя проявит. ⇡#Всё дело в волшебных ёмкостяхСторонники резистивного аналогового ИИ не опускают, конечно же, руки: компенсировать неизбежно возникающий при каждой транзакции внутри физической нейросети шум (избыточную стохастику) предполагается различными способами. Можно закладывать «предзнание» о некотором базовом уровне естественной и неустранимой зашумлённости поступающих на перцептроны сигналов в архитектуру самой модели — снижая, например, соответствующим образом по модулю величину стохастического слагаемого в формуле для вычисления последующего члена авторегрессионного ряда. Можно постараться подыскать такие физические системы, сопротивление которых меняется более предсказуемо, чем в случае ячеек RRAM. Так, IBM, активно разрабатывающая аналоговые ИИ-вычислители, сделала ставку на устройства памяти с фазовым переходом (с изменением фазового состояния вещества), phase-change memory (PCM). Ячейки PCM хранят синаптические веса в виде аналоговых значений проводимости, переключаясь между аморфным (высокое сопротивление) и кристаллическим (низкое сопротивление) состояниями под воздействием электрических импульсов. Микросхемы такого рода уже вышли из лабораторий: их изготавливают по «14-нм» технологии на фабрике IBM Albany NanoTech Complex, добиваясь высокой плотности формируемых таким образом физических нейросетей — более 35 млн переключаемых элементов на одной микросхеме — и энергонезависимости, поскольку текущее фазовое состояние ячейки сохраняется без приложения внешнего питания. Более того, и программные инструменты для их применения предоставляются самой же IBM с открытым исходным кодом: речь идёт об AIHWKit, фреймворке на основе PyTorch для моделирования обучения и инференса моделей на такого рода аналоговом «железе». Точность базирующихся на PCM-чипах моделей достаточно высока: на бенчмарке CIFAR-10, содержащем эталонный для задач машинного обучения и компьютерного зрения набор данных, они получают свыше 92,8 балла из ста, демонстрируя притом на два десятичных порядка более высокую энергоэффективность в сравнении с традиционными графическими процессорами, на которых эмулируются схожие по предназначению и возможностям нейросети. 
Серийный чип с PCM-ячейками для аналоговых ИИ-вычислений смотрится красиво, но на практике находит довольно ограниченный круг приложений (источник: IBM) Правда, пока что нет новостей о массовой замене в гиперскейлерских ЦОДах сверхэнергоёмких серверных стоек, забитых новейшими ускорителями Nvidia, экономичными аналоговыми вычислителями на основе PCM. Причин тому немало: это и несовершенство нынешних технологий изготовления крохотных ячеек из вещества, способного менять фазовое состояние под воздействием электрического тока (здесь опять же проявляет себя неизбежная микроскопическая неодинаковость даже двух соседних таких ячеек на одной и той же подложке), и присущий такому веществу естественный, пусть и крайне неторопливый, структурный дрейф (drift) от текущего его состояния — кристаллического или аморфного — к некоторому промежуточному (грубо говоря, по логарифмическому закону: сопротивление PCM-ячейки меняется со временем как log (t) с коэффициентом от 0,10 до 0,15), и ограниченная по спектру решаемых задач производительность. Последнее особенно важно с практической точки зрения: если в случае распознавания статичных образов энергоэффективность (производительность в пересчёте на затраченный ватт мощности) PCM-вычислителей действительно на полтора-два десятичных порядка превосходит таковую для классических ГП, то, например, при ведении живой беседы с оператором на естественном языке по этому показателю, напротив, изделия IBM привычным сегодня чат-ботам проигрывают — причём примерно с тем же счётом. В целом же для высокопроизводительных ИИ-приложений, где скорость обработки входных данных моделью имеет решающее значение, классическое «железо» продолжает оставаться вне конкуренции — по крайней мере, если сравнивать его с резистивными аналоговыми вычислителями. Оно хоть и прожорливо, зато априори универсально: в памяти машины, организованной по принципам фон Неймана, можно сэмулировать (был бы под рукой соответствующий алгоритм!) хоть чёрта лысого, — которого в аналоговом виде даже и не факт, что в принципе удастся когда-либо заполучить. Разработчики из упомянутого нами в самом начале стартапа EnCharge, видимо, искренне уверившись в бесперспективности резистивных аналоговых ИИ-вычислений, двинулись другим путём: вместо сопротивлений они сделали ставку на ёмкости. Сохраняемый плоским конденсатором заряд, как известно, равен произведению ёмкости этого электротехнического компонента на напряжение на его обкладках. При этом важно, что ёмкость данного конкретного конденсатора определяется только его физическими характеристиками: формой, размером и расстоянием между обкладками, а также свойствами размещённого между последними диэлектрика. Изготовление конденсатора на кремниевой подложке методами фотолитографии — задача, можно сказать, тривиальная: нужны всего лишь два плоских проводника и участок диэлектрика между ними. Чем больше площади проводников-обкладок и чем меньше расстояние между ними, тем выше ёмкость. Современные же методы производства полупроводников как раз и славятся высочайшей точностью, с которой могут выдерживаться геометрические параметры создаваемых на кремниевой подложке микро- и даже наноформаций. Собственно, ёмкостные чипы EnCharge на деле представляют собой гибридные, цифроаналоговые структуры: в нижнем слое таких микросхем формируются, как и положено, логические контуры, а в расположенные над ними слои межсоединений интегрируются медные обкладки — пары которых и формируют микроскопические конденсаторы. 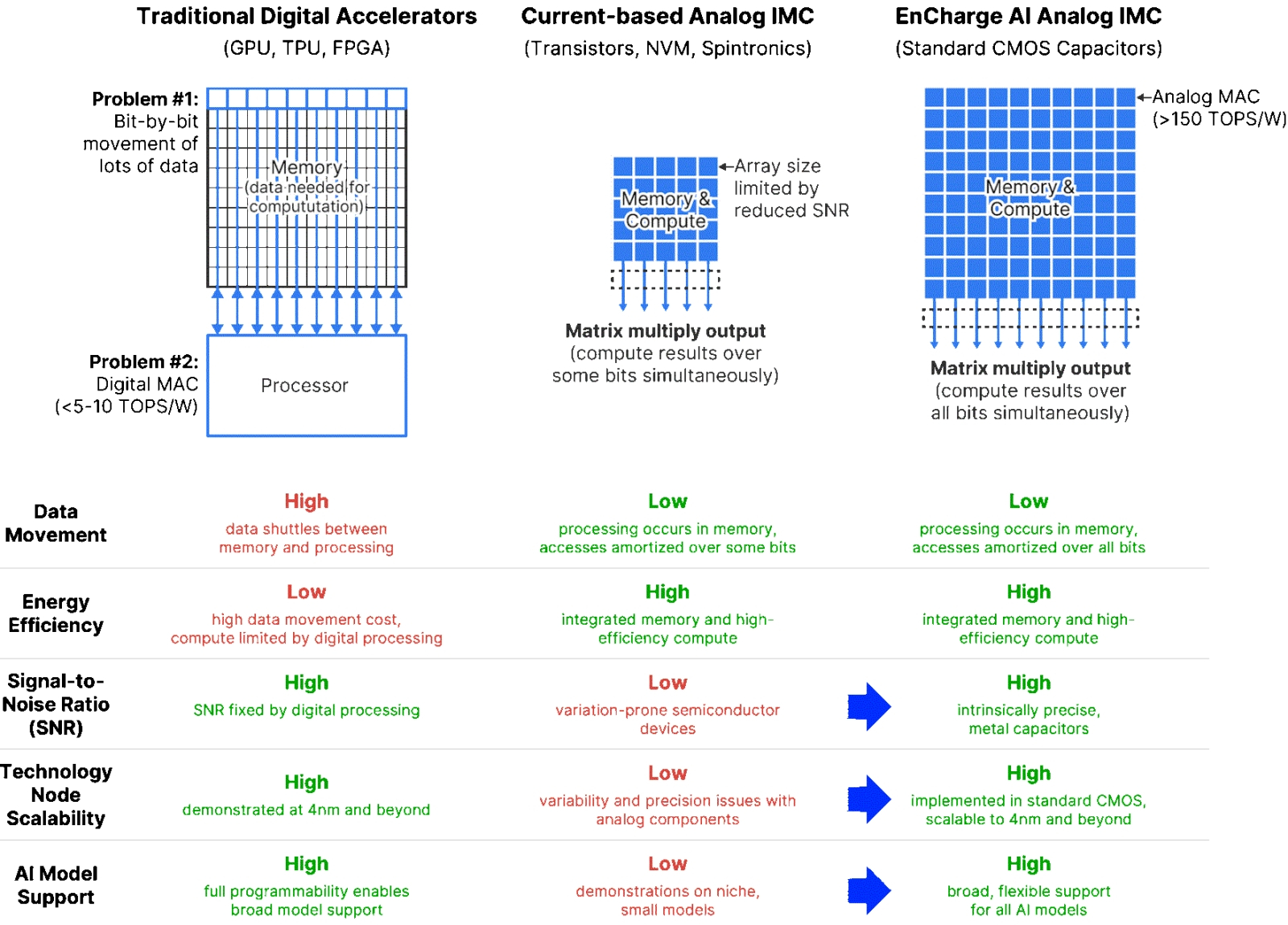
Заявленные преимущества аналоговых ёмкостных вычислений в памяти в сравнении с классическими цифровыми и с теми аналоговыми, что опираются на резистивные (сводящиеся к манипулированию токами — current-base, — а не зарядами) технологии (источник: EnCharge) ⇡#Цифра, аналог… Главное — результат!Навин Верма пришёл к идее использовать конденсаторы для вычислений, производимых непосредственно в памяти (IMC), ещё в 2017 году, и в значительной мере посвятил её проработке — при поддержке DARPA и TSMC, кстати, — деятельность возглавлявшейся им лаборатории Принстонского университета. Само по себе применение зарядов вместо токов в вычислительных системах практикуется не так уж редко; взять хотя бы основанные на компараторах переключаемые конденсаторы (comparator-based switched-capacitor — CBSC), прекрасно заменяющие собой операционные усилители с высоким коэффициентом усиления для широкого класса высокоточных схем с дискретизацией данных — включая аналого-цифровые и цифроаналоговые преобразователи, схемы выборки и хранения, интеграторы и фильтры. Нововведение Верма и его группы заключалось в том, чтобы разобраться, как именно применить столь многообещающие компоненты для реализации вычислений непосредственно в памяти. Подчеркнём снова, что ёмкость конденсатора со строго заданными параметрами жёстко фиксирована, так что для изготовленных на одной и той же подложке конденсаторов с идентичной в пределах погрешности геометрией ёмкости будут с огромной точностью совпадать. Тем самым в уравнении с двумя сомножителями — «заряд = ёмкость × напряжение» — первый можно считать константой для всех элементов физической нейросети в пределах даже не одного чипа, а всей их крупной партии или сразу целого поколения. В то время как полагающиеся на закон Ома — «сила тока = проводимость × напряжение» — резистивные ИИ-вычислители вынуждены иметь дело с куда более подверженной случайным колебаниям (от ячейки к ячейке) величиной, а именно с той самой проводимостью (обратным сопротивлением) отдельных элементов электрической схемы. Правда, в отличие от мемристорных и им подобных систем с опорой на переменные сопротивления, реализованную EnCharge схему трудно назвать полностью аналоговой: это обратная сторона того бесспорного их достоинства, что ёмкости раз и навсегда литографированных на кремниевой подложке наноконденсаторов фиксированы. Чтобы корректировать значения синаптических весов в реализуемой такой системой нейросети, приходится хранить данные о них в массиве ячеек памяти SRAM, каждая из которых подключена к соответствующему конденсатору. Необходимы также контуры (впрочем, конструктивно довольно простые) для преобразования поступающего на данный синапс тока — с учётом приписанного именно этой ячейке веса — в заряд определённой величины, который и будет сохраняться в наноконденсаторе. Однако сложение зарядов из ячеек, что соответствуют предыдущему слою глубокой нейросети, происходит уже естественным образом и фактически без потери качества (без накопления дополнительных паразитных шумов), что делает ёмкостный аналоговый (точнее, конечно, аналого-цифровой) ИИ-вычислитель привлекательнее множества предложенных к настоящему времени резистивных. 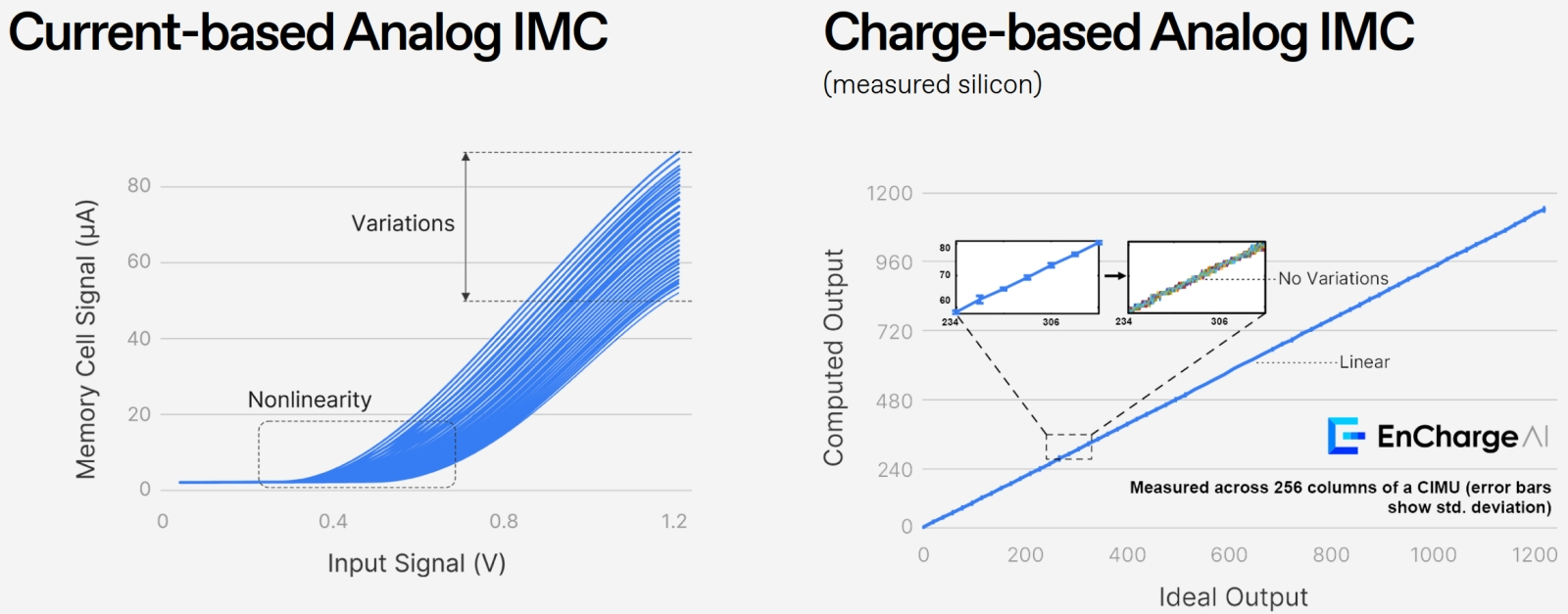
Отношение «сигнал —шум »для аналоговых ИИ-вычислителей в памяти, использующих силу тока (current-based), резко возрастает с увеличением этой силы, тогда как для систем, построенных с применением наноконденсаторов, неизбежно возникающие в ходе работы погрешности можно считать пренебрежимо малыми (источник: EnCharge) Важно ещё раз вернуться к тому, насколько хорош конденсатор в качестве итогового хранилища синаптических весов: ёмкость его не зависит от температуры полупроводникового прибора (по крайней мере, до тех пор, пока из-за её увеличения не начинает существенно меняться его геометрия) и иных посторонних факторов, так что зависимость между зарядом и напряжением оказывается в очень и очень хорошем приближении рабочих условий строго линейной. Суммирование зарядов из предыдущего слоя производится аналоговым способом, и далее для преобразования итогового значения в цифровой формат (в силу тока, который передаст информацию о произведённом сложении сигналов на следующий уровень нейросети) требуется лишь простой аналого-цифровой преобразователь, также не вносящий значимых искажений в получаемый результат. Бесспорно, EnCharge есть ещё над чем поработать: в частности, современные ИИ-модели несуразно огромны (имеется в виду количество параметров, которыми они оперируют), и потому целиком даже в четырёхчиповую конфигурацию наиболее актуальные из них загрузить не удаётся, — приходится фрагментировать нейросети и отрабатывать прохождение сигналов по ним последовательно. Для сокращения накладных аппаратных расходов группа Верма применяет «виртуализированную архитектуру, аналогичную виртуальной памяти», таким образом ещё более отдаляясь от исключительно аналоговой схемы исполнения БЯМ. Правда, судя по всему, именно это промежуточное направление — известное уже как «цифровые вычисления в памяти», digital in-memory compute (DIMC), — наиболее перспективно, если разработчики желают сохранить опору на великолепно отлаженную полупроводниковую элементную базу и не стремятся воспарять в чрезвычайно инвестоёмкие (как раз по причине отсутствия сопоставимой отлаженной за десятилетия производственной основы) эмпиреи принципиально иных подходов; всё той же фотоники, скажем. Упомянем о компании d-Matrix, развивающей матричное умножение непосредственно в ячейках памяти, без необходимости перемещать веса на логические контуры и обратно. Вычислительную платформу под названием Corsair здесь формируют чиплеты, каждый из которых содержит нейронные ядра со встроенными блоками DIMC и ядро управления потоками данных RISC-V. Ускорители Corsair уже планируется интегрировать в облако Gimlet Cloud — где в рамках гибридной архитектуры классические вычислители Nvidia обеспечат ресурсоёмкие этапы инференса, а особо чувствительные к задержкам операции перенаправят как раз на DIMC-узлы. Несколько иной подход избрала голландская компания Axelera AI, сумевшая недавно привлечь 250 млн долл. США для разработки европейских ИИ-ускорителей. Здесь цифровые вычисления в памяти реализуются с применением SRAM: массивы перекрёстных соединений таких ячеек используют и для хранения весов, и для выполнения операций матричного умножения без передачи данных на логические контуры. Поскольку операции эти производятся всё-таки не аналоговым способом (не через сложение токов или иных непрерывных величин), а с применением несложных интегрированных логических контуров, такая реализация DIMC, как утверждают её разработчики, «невосприимчива к аналоговым шумам и неидеальности памяти, обеспечивая высокую точность с весами INT8 и накоплением INT32, — сохраняя точность FP32 без переобучения». У Axelera AI также имеются уже готовые к эксплуатации заинтересованными партнёрами продукты — чип Metis AIPU и Voyager SDK, а в перспективе ожидаются поставки карты расширения с интерфейсом PCI-e и одноплатного компьютера для ИИ-инференса. Чиплет же Titania, финансируемый EuroHPC JU и ориентированный на применение в серверах, и вовсе рассматривается как основа для построения суверенной экосистемы искусственного интеллекта в Европе. Словом, ёмкостные (частично) аналоговые ИИ-вычислители имеют немалый шанс встать в один ряд с другими DIMC-разработками, увеличив тем самым разнообразие платформ, реально доступных для повышения энергоэффективности ИИ-вычислений. Главное тут, чтобы финансирования на всех хватило: на ИТ-рынке за последние несколько кварталов столько всего произошло — от радикального взлёта цен на полупроводники до угрозы сокращения мировых поставок гелия и иных ключевых компонентов, — что свободных средств, не говоря уже о доступных кредитах, на все перспективные проекты банально недостаточно. Стремящиеся минимизировать риск инвесторы наверняка будут в таких условиях продолжать поддерживать на плаву экстенсивно развивающиеся — то есть уже доказавшие свою жизнеспособность — направления. И если в чисто программной области кардинальных перемен ещё стоит ожидать (грубо говоря, Давид развиваемых Advanced Machine Intelligence Labs «мировых моделей» посрамит-таки Голиафа классических БЯМ), то на аппаратном уровне вряд ли стоит ожидать резкого перетока средств в направлении нефоннеймановских вычислительных архитектур. Хотя бы даже и не самых радикально отличных от классики, — как та же самая DIMC. 
Один из предсерийных прототипов ёмкостного ИИ-вычислителя (источник: EnCharge AI)
⇣ Содержание
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.
Материалы по теме
|
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.





