







 MWC 2018
MWC 2018 2018
2018 Computex
ComputexВ первых битвах за господство видеоускорителей мы наблюдали намного большее число соперников, нежели двойка ATi и nVidia. Но в результате жесткой конкуренции и естественного отбора сейчас на рынке присутствует два крупнейших игрока, что, в общем-то, не так и плохо. Производительность видеоускорителей многократно выросла со времен Savage3D и G200, в то время как качество изображения и функциональность достигли новых высот. Однако рынок ускорителей весьма переменчив, любая компания может очень легко сойти на нем с арены. Сейчас явно прослеживается тенденция использования в видеоускорителях более гибких, программируемых ядер (то есть видеоускориитель все больше начинает напоминать процессор).
Хотя nVidia поставляет первый массовый программируемый видеоускоритель уже почти два года, технология все еще остается довольно примитивной. Хорошим подспорьем для современных ускорителей служит Microsoft DirectX 8, который обещает задействовать всю мощь программируемых шейдеров. И хотя мы пока не видим игр, полностью использующих привлекательные DX8 возможности, они уже на горизонте. Демо-версии уже используют пиксельные и вершинные шейдеры, демонстрируя потрясающие эффекты. Но, как считает 3DLabs, иметь очень гибкие шейдеры – это еще далеко не все.
Зачем нужна программируемость?
Программируемость видеоускорителей – одна из модных тем. Раньше, до появления 3D ускорителей, разработчики задействовали центральный процессор для просчета всего, начиная с физики и AI, и заканчивая рендерингом кадров. Проблема заключалось в том, что даже самые мощные процессоры слишком плохо справлялись с работой, необходимой для нормального запуска 3D игры. Конечно, процессор очень гибок – вы можете запрограммировать его практически под любую функцию, однако процессор ограничен пропускной способностью памяти и вычислительной мощностью, которых недостаточно для нормальной 3D игры с высокой частотой кадров.
Появление аппаратных 3D ускорителей переместило часть нагрузки с центрального процессора на видеопроцессор, который к тому же обладает достаточным объемом выделенной видеопамяти с пропускной способностью, специально подогнанной для 3D рендеринга. Проблема же здесь заключается в том, что производители видеопроцессоров четко определили, что программисты могут делать с "железом". И хотя инженеры видеочипов прекрасно справляются с составлением вычислительных цепочек и оптимизацией логики, они все же не являются Тимом Свини или Джоном Кармаком в области определения нужд 3D игр следующего поколения.
Далее последовало сегодняшнее поколение "программируемых" (мы далее объясним, почему мы вынесли это слово в кавычки) 3D ускорителей. Архитектуры типа GeForce4 или Radeon 8500 дали разработчикам некоторый простор для творчества. Однако этот простор все же ограничен. Та свобода, которую получает разработчик при написании кода для AMD Athlon XP или Intel Pentium 4 не существует для игрового разработчика, создающего 3D движок. Гибкость сегодняшних видеопроцессоров хорошо помогает разработчикам, чей талант был ограничен фиксированными графическими конвейерами прошлого, однако, как считает 3DLabs, этого не достаточно.
Как мы уже говорили, центральный процессор плохо подходит на роль видеоускорителя. Однако что будет, если сделать 3D ускоритель полностью программируемым, как центральный процессор? Представьте себе видеопроцессор с огромным числом параллельных исполнительных устройств, специально предназначенных для SIMD природы 3D вычислений, который имеет программируемость центрального процессора. Мощь процессора может быть подкреплена высокоуровневым языком программирования (типа C/C++, Fortran, Java, C# и т.д.) и такой процессор даст игровым разработчиком невиданную до сего времени гибкость в своем творчестве.
Только что мы изложили точку зрения 3DLabs (ее реалистичность мы обсудим чуть позже). Честно говоря, современный рынок 3D графики идет именно в этом направлении. Ситуация на рынке многократно ухудшится, если разработчика будут принуждать между поддержкой пиксельных шейдеров ATi или nVidia. Ведь когда разработчики ПО пишут программы для x86 процессоров, они не выбирает между AMD версией x86 или версией Intel. Существует один стандартизированный набор инструкций, в то время как аппаратная реализация инструкций может различаться у разных производителей процессоров. Но она прозрачна для разработчика.
Для подтверждения существования проблемы с современными "программируемыми" 3D ускорителями 3DLabs приводит цитату из плана Джона Кармака по поводу пиксельных шейдеров GeForce3: "другие компании обладают потенциально лучшими подходами, но они вынуждены понижать их до уровня GF3 для соблюдения совместимости. Хорошо, что мы еще увидим некоторую дополнительную гибкость в OpenGL расширениях".
Итак, вместо понижения своего подхода к программируемому пиксельному конвейеру до уровня GeForce3, 3DLabs решила создать более гибкую программируемую архитектуру, которая позиционируется как наиболее совершенный поход из всех существующих.
Более того, 3DLabs удивила многих, объявив, что их последняя графическая архитектура будет использоваться повсеместно – от профессиональных карт до игровых, причем уже в этом году. Что еще более удивляет – 3DLabs уже обладает качественным кремниевым образцом, и по самым пессимистичным прогнозам поставки чипа должны начаться не позднее, чем через 2 месяца.
Новый термин – визуальный процессор (VPU)
3DLabs решила не использовать сокращение GPU для отражения революционности своего видеопроцессора. Существующие графические процессоры обеспечивают недостаточную гибкость, именно по этой причине был выбран термин "визуальный процессор" - Visual Processing Unit, VPU.
Новый чип 3DLabs называется P10, он является первой итерацией архитектуры визуального процессора, и наверняка не последней. Однако отличия P10 VPU от GeForce4 NV25 или Radeon 8500 R200 кроются отнюдь не в конвейере – в нем используются те же ступени. Только операции на каждой ступени были изменены.
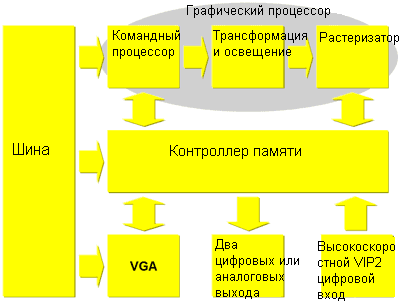
На высоком уровне вы можете видеть, что P10 очень похож на другие 3D ускорители. Самое большое улучшение по сравнению с конкурентами заключается в использовании 256-битной DDR шины памяти. GeForce4 и Radeon 8500 используют лишь 128-битную DDR шину, так что теоретическая пропускная способность памяти у P10 как минимум в два раза выше. Использование BGA памяти облегчает задачу прокладки дорожек, перенося 256-битную DDR шину памяти в реальность. Не считайте такую ширину шины заслугой 3DLabs – они просто стали первыми, кто стал ее использовать. Хотя 3DLabs еще официально не объявили спецификации карт, они уже говорят о более чем 20 Гбайт/с пропускной способности памяти в P10, для чего им понадобится, по крайней мере, 312,5 МГц DDR SDRAM. Учитывая, что GeForce4 Ti4600 использует 325 МГц DDR SDRAM, такая пропускная способность выглядит реалистично.

Кроме наличия 256-битной шины памяти и добавления командного процессора (о нем чуть позже), P10 выглядит знакомо. Краткие спецификации:
- 0,15 мкм техпроцесс производства;
- 76 млн. транзисторов;
- изготовлен на TSMC (там же производятся и чипы nVidia);
- 860 шариковая HSBGA упаковка (самая современная технология упаковки TSMC);
- 4 пиксельных конвейера рендеринга, могут обрабатывать по две текстуры на конвейер;
- 256-битный DDR интерфейс памяти (до 20 Гбайт/с пропускной способности с 312,5 МГц DDR памятью);
- до 256 Мбайт памяти на карте;
- поддержка AGP 4X;
- полная поддержка DX8 пиксельных и вершинных шейдеров.
Ниже приведена таблица, где приведено сравнение характеристик P10 с основными конкурентами.
| Чип | P10 | GeForce4 (NV25) | Radeon R200 |
| Число транзисторов | 76M | 63M | 60M |
| Техпроцесс | 0,15 мкм | 0,15 мкм | 0,15 мкм |
| Ширина шины памяти | 256-битная DDR | 128-битная DDR | 128-битная DDR |
| Пиковая пропускная способность памяти | 20 Гбайт/с | 10 Гбайт/с | 10 Гбайт/с |
| Программируемость | Универсальная, включая циклы и процедуры | Ограничена DX8 вершинными и пиксельными шейдерами | Ограничена DX8.1 вершинными и пиксельными шейдерами |
| Число одновременно обрабатываемых текстур | 8 | 4 | 6 |
| Мультисемплирование | 8-way | 4-way | нет |
| Текстуры высоких порядков | N-patches, Bezier, B-Splines, NURBS | Полиномиальные поверхности (Bezier, B-splines) | n-patches |
| Вершинные процессоры | 16 SIMD скалярные | 2 x 4 векторные | 4 (векторные) |
| Текстурные процессоры | 128 SIMD скалярных, программируемых процессора (8 текстур за такт) |
Регистровые (4 текстуры за такт) | Регистровые (6 текстур за такт) |
| Сглаживание | 64 SIMD скалярных процессора; 8 мультисемпловый AA; программируемый | Фиксированное, 4 мультисемпла | Фиксированное, 6 семлов, вероятностный паттерн, суперсемплирование |
| Обработка изображений с помощью аппаратного ускорения | 64 SIMD скалярных процессора (те же самые, что используются в AA) | Нет | Нет |
| Виртуальная память | Да (16 Гбайт) | Нет | Нет |
| Точность цвета ЦАП | 10 bpp | 8 bpp | 8 bpp |
| Поддержка двух мониторов | Да | Да | Да |
3D конвейер
Мы уже упоминали, что конвейер P10 очень похож на традиционный 3D конвейер, но что определяет "традиционность" 3D конвейера? Давайте вкратце вспомним, как работает 3D конвейер.
- Первая ступень наиболее очевидна – отсылка команд и данных на графический чип. Инициатором является программа, отсылка производится по шине AGP и, в конце концов, команды и данные через графический драйвер достигают графического процессора.
- Сейчас, когда GPU знает, какие данные ему нужны для обработки, и что конкретно нужно сделать с этими данными, он начинает работать. Данные посылаются на GPU в виде вершин полигонов, которые когда-нибудь отобразятся на вашем экране. Первая истинная исполнительная ступень графического конвейера часто называется "трансформация и освещение" - T&L. Здесь происходит трансформация вершинных данных, которые были посланы на GPU, в 3D сцену. Этап трансформации требует использования повторяющихся матричных вычислений с плавающей точкой. Далее происходят вычисления освещения для каждой из этих вершин. В программируемом GPU начальные этапы обработки вершин очень гибки в том, что касается коротких вершинных программ-шейдеров, которые могут управлять большим числом характеристик вершин типа формы, вида или поведения.
- После того, как мы трансформировали и осветили вершины, настало время сгенерировать несколько пикселей, дабы отобразить их на экране. Но перед этим требуется провести предварительную работу. Производится отбрасывание ненужных вершин, которые находятся за пределами сцены. Далее в большинстве современных GPU происходят вычисления по отбрасыванию вершин, которые закрыты другими полигонами и не будут видны пользователю. Здесь используются такие технологии, как HyperZ и визуальная подсистема nVidia.
- После предварительной очистки настало время генерации пикселей. Оставшиеся вершины преобразуются в видимое пространство – 2D пространство вашего монитора. Вы ведь не забыли, что в 3D мир вы смотрите через плоское окно монитора? Здесь вычисляется z-буфер, содержащий информацию о том, насколько удалены пиксели от наблюдателя.
- Вычисляются координаты текстур, которые будут использоваться для наложения текстур на полигоны, созданные при помощи вершин. На этом этапе подгружаются текстуры и работают пиксельные шейдеры, которые в современных программируемых GPU могут использоваться для создания визуальных эффектов на пикселях (отображение теней, корректное по z отображение неровностей и т.д.).
- Наконец, мы подходим к концу конвейера, где выполняется фильтрация, сглаживание и другие подобные техники. Затем пиксели попадают в кадровый буфер и отсылаются на RAMDAC или TMDS передатчик.
Сейчас настало время осознать, что этот конвейер одинаков как для P10, так и для GeForce4. Однако различия кроются в операциях, производимых на этих ступенях.
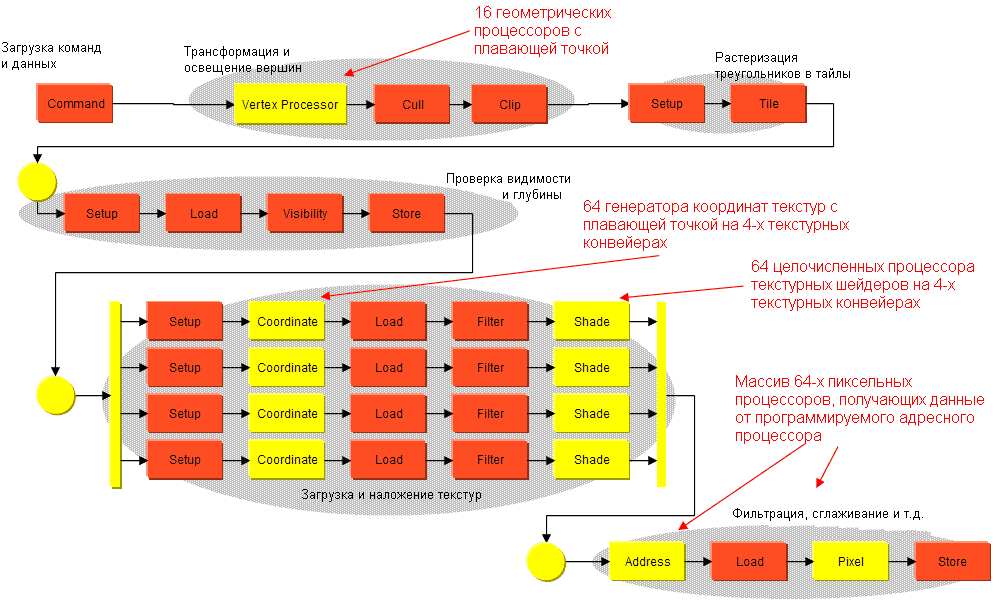
Конвейер P10 VPU. Желтые блоки программируемые, красные – с фиксированной функциональностью.
Выше мы вкратце рассмотрели P10 3D конвейер. Далее мы более подробно остановимся на самых интересных ступенях, для этого будет полезно открыть картинку конвейера в отдельном окне.
Многопоточная графика?
При обработке множества 3D потоков, посылаемых на графическую карту, необходимо учитывать несколько вещей, которые обычно упускают. В качестве примеров можно привести управление исполнительными ресурсами, время переключения контекста и способность выделять ресурсы конкретному заданию.
Стоит сразу сказать, что почти во всех современных играх вы этого не встретите. Если вы желаете посмотреть на подобный уровень параллелизма, вам нужно обратиться к профессиональному миру и даже к будущим версиям Microsoft OS. Если вы не знаете, что такое Longhorn, то пришло время открыть глаза. Longhorn – кодовое имя для пользовательского интерфейса Microsoft Windows следующего поколения, который будет усиленно использовать аппаратное DirectX ускорение рабочего стола. Даже при элементарной работе с Longhorn на вашу графическую карту будут параллельно посылаться потоки, поэтому достаточно важной задачей становится управление этими потоками.
3DLabs не зря гордится своим командным процессором, который предназначен для управления подобными многопоточными ситуациями. Когда несколько потоков выполняются параллельно, необходимо максимально эффективно использовать исполнительные ресурсы. В этом и заключается одна из основных ролей командного процессора. Командный процессор предоставляет пред-потоковые командные буферы, причем подобные буферы уже некоторое время применяются в high-end видеокартах. В случае если один из потоков посылает ошибочные данные на видеокарту, то этот поток будет завершен, однако ОС продолжит свое функционирование, что очень важно для ситуаций типа Longhorn. В настоящее же время, если игра посылает ошибочные данные на вашу видеокарту, то вы получите любимый синий экран, поскольку у вас нет пред-потоковых буферов для обеспечения хоть какой-то изоляции между потоками. Командный процессор также позволяет очень быстро изменять текущее состояние, что бывает полезно при переключении между несколькими 3D окнами.

Но если подобный подход очень важен для Longhorn, то для обычных пользователей все эти функции некоторое время будут практически бесполезны. Командный процессор играет важную роль в любом многопоточном 3D приложении, где к VPU обращается несколько потоков. Что касается современных игр, то командный процессор в них не столь важен, как другие упомянутые ниже функции.
16 вершинных процессоров с плавающей точкой
На второй ступени мы рассматривали трансформацию и освещение вершин, а также роль, которую вершинные шейдеры играют в современных программируемых GPU. Но до сих пор самым мощным ускорителем для пользовательских компьютеров являлся nVidia GeForce4, который имеет два блока вершинных шейдеров. 3DLabs P10 оснащен 16-ю 32-битными геометрическими процессорами с плавающей точкой, которые выполняют обработку вершин. Значит ли это, что P10 в 8 раз эффективнее работает с шейдерами, чем GeForce4? Конечно же, нет.
Каждый из блоков вершинных шейдеров у nVidia работает с 4-элементными векторными данными (vect4), которые прекрасно подходят для той работы, которую производят блоки шейдеров. К сожалению, если вы пошлете что-нибудь отличное от vect4 операнда на вершинный процессор, то эффективность снизится. К примеру, данные блоки могут обрабатывать только одну скалярную величину в единицу времени. Как вы помните, процесс трансформации задействует тяжелые матричные вычисления, где достаточно часто происходит генерация скалярных величин. Даже с двумя блоками вершинных шейдеров, падение производительности от работы с отличными от vect4 данными ощутимо. К примеру, vect4 операция может быть обработана за один такт в блоке вершинных шейдеров nVidia, но такое же время требуется и на выполнение одной скалярной операции. Вершинные шейдеры ATi работают точно таким же образом, и если вы пожелаете оценить вершинные шейдеры nVidia/ATi тем, что 3DLabs называет "вершинный процессор", вы можете говорить, что каждый из блоков nVidia/ATi имеет 4 вершинных процессора.
P10 использует другой подход. Вместо включения очень мощных блоков, 3DLabs решила разделить их, в результате мы получаем 16 32-битных скалярных вершинных процессоров (VP). Каждый из этих процессоров может обработать одну скалярную операцию за один такт, но они задействуют четыре такта на вычисление vect4 операции. Причина же значительного потенциала P10 во всех типах вершинных операций заключается в большом числе (16) параллельно работающих вершинных процессоров.
Если вы сравните теоретическую пропускную способность вершин между P10 и GeForce4, то вы получите примерно двойное преимущество P10. Но на самом деле выигрыш P10 даже выше, поскольку чип эффективнее работает со скалярными операциями, которые могут быть выполнены за один такт на любом из 16-ти процессоров.
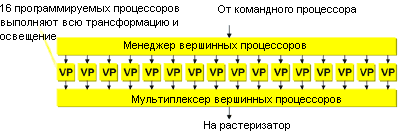
Программы видят лишь один виртуальный вершинный процессор и взаимодействуют с менеджером вершинных процессоров, который затем управляет работой всех 16-ти процессоров
Программное обеспечение не видит массив вершинных процессоров. Разработчики могут использовать массив как один вершинный процессор, а уже затем менеджер вершинных процессоров корректно распределяет операции между 16-ю параллельными процессорами. После вычислений мультиплексор собирает данные от процессоров и посылает их на следующую ступень конвейера.
Массив 16-ти вершинных процессоров – это вариация вершинных шейдеров nVidia, поэтому они обеспечивают полную поддержку всех существующих DX8 вершинных шейдеров. Как считает 3DLabs, они смогут объявить и о полной поддержке вершинных шейдеров 2.0 в DirectX9, но поскольку DX9 пока еще не вышел, об этом несколько рано говорить.
Не мозаичная (тайловая) архитектура
Хотя архитектура P10 и лишена броских маркетинговых имен, одно имя здесь все же используется, причем не совсем корректно. На ступени растеризации P10 использует мозаичный (тайловый) процессор, как его называет 3DLabs. Мозаичный процессор разбивает рендеринг сцены на участки, но это отнюдь не означает, что P10 осуществляет отложенный рендеринг.
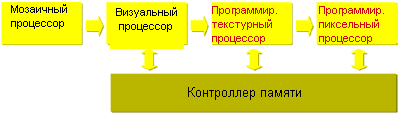
P10 разделяет сцену на участки 8x8 пикселей и далее обрабатывает сцену. Такой метод был выбран просто по причине того, что он наиболее эффективно использует кэши P10. К тому же P10 – это мгновенный рендерер (immediate-mode renderer), точно так же, как и GeForce4 и Radeon 8500.
3DLabs снабдила P10 тем, что они называют визуальным процессором (visibility processor), который выполняет z-отсечение (z-occlusion) в конвейере. Мы не обладаем достаточной информацией об этом процессоре, но, по всей видимости, его функциональность аналогична тому, что мы видим у ATi и nVidia.
Пиксельные шейдеры P10
Один из самых больших камней в огород ATi и nVidia 3DLabs метнула, когда назвала их пиксельные шейдеры полу-программируемыми. 3DLabs называет пиксельные шейдеры ATi и nVidia регистровыми блоками, которые обеспечивают гибкость, но на самом деле не являются программируемыми. Вспомните фразу Джона Кармака, которую мы привели выше, где он недоволен подходом nVidia к пиксельным шейдерам.
3DLabs отнюдь не дискредитирует мощь этих регистровых блоков, однако они упоминают их недостаточность, поэтому P10 предлагает иное решение. Программируемый текстурный процессор P10 поддерживает все существующие DX8 спецификации пиксельных шейдеров, однако, как и в вершинном движке, он разбит на несколько 32-битных процессоров, работающих параллельно.
Четыре пиксельных конвейера P10. Желтые блоки программируемые, красные – с фиксированной функциональностью
P10 обладает в общей сложности 64-мя процессорами по генерации координат с плавающей точкой, которые помогают определить наложение текстуры, в то время как другие 64-е целочисленных процессора используются для вычисления финальных цветов пикселя. Как вы, наверняка, догадались, все эти процессоры полностью программируемы и как мы уже упоминали, они полностью поддерживают функциональность пиксельных шейдеров DX8.
Важно заметить, что хотя P10 поддерживает пиксельные шейдеры DX8, к DX9 это не относится. Одно из требования DX9 заключается в том, что все пиксельные конвейеры, от начала до конца, работают с плавающей точкой. В случае же с P10 такого не происходит. Переход к процессорам с плавающей точкой по всему конвейеру не является экономически выгодным решением для 3DLabs, поскольку в этом случае увеличится объем передаваемых данных по сравнению со смешанным конвейером (где часть процессоров целочисленные, а часть работает с плавающей точкой). Как предполагает 3DLabs, для полной поддержки DX9 им будет необходим, по крайней мере, 0,13 мкм техпроцесс, или даже 0,1 мкм техпроцесс. 0,13 мкм техпроцесс TSMC пока еще недостаточно отработан с экономической точки зрения, так что касательно DX9 нам следует подождать следующего года. Вы также должны учитывать, что чип nVidia следующего поколения (NV30) будет изготавливаться по 0,13 мкм техпроцессу, и, скорее всего, он будет полностью поддерживать DX9 в момент своего выхода осенью.
Что касается других спецификаций программируемого текстурного процессора P10, то он может накладывать 8 текстур за один проход (не за один такт) по сравнению с 6-ю текстурами Radeon 8500 и 4-мя GeForce4. Процессор также поддерживает произвольные размеры текстур, что будет важно для Longhorn, но опять же, эта функция предназначена для будущих, а не для существующих приложений.
Хотя общие алгоритмы фильтрации текстур жестко встроены в пиксельные конвейеры, P10 позволяет использовать программируемые фильтры.
Еще одна программируемая ступень
Последняя ступень конвейера в P10 также программируемая, что несколько отличается от существующих GPU. После того, как текстура будет наложена и отфильтрована, в дело вступают технологии типа сглаживания. Во всех других GPU эти финальные операции не программируются и жестко встроены в конвейер, но в P10 все несколько по-другому.
P10 виртуально поддерживает любой тип сглаживания, какой можно только придумать: под OpenGL поддерживается краевое сглаживание (edge anti-aliasing), очень эффективный способ, поскольку удар по производительности наносится намного меньший, чем при использовании стандартных методов, а качество обеспечивается прекрасное. Точно также поддерживается суперсемплинг и мультисемплинг, последний предлагает виртуально неограниченные семплы, хотя вы все же ограничены 8x при мультисемплинге.
Из-за программируемости последней ступени конвейера, P10 может обеспечить более точную глубину цвета типа 64-битного цвета. В частности, в P10 вы увидите встроенную поддержку гамма-скорректированных 10-битных RGB выходов. VPU также оснащено 1-битными ЦАПами для поддержки 10:10:10:2 (RBGA) режима.
Виртуальная память – кэш L2 приходит в VPU
Еще одна интересная особенность P10 – то, что 3DLabs называет P10 Virtual Memory System (VMS). VMS сохраняет все текстуры в основной памяти и очищает память на самой графической карте, то есть, фактически, функционирует как кэш. При запросе текстуры, вся текстура не загружается, вместо этого локально загружается блок 32-битных пикселей размером 256x256. Это прекрасный пример, иллюстрирующий эффективность архитектуры в ситуации, когда вы находитесь в 3D окружении и когда вы видите лишь небольшой участок текстуры. В традиционных архитектурах в память должна быть загружена вся текстура, однако благодаря P10 VMS вся текстура хранится в системной памяти, и только лишь часть текстуры перекачивается в видеопамять. Такой подход очень напоминает AGP текстурирование, по сути, он таковым и является, с тем лишь отличием, что при AGP текстурировании не происходит кэширования. К тому же, системная память компьютера, используемая P10 VMS, может быть фрагментирована.
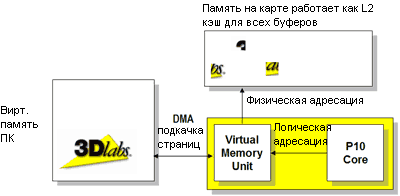
С точки зрения разработчиков, VMS является довольно привлекательным решением, поскольку она позволяет использовать большее количество текстур, чем возможно сегодня. В настоящее время при создании игр разработчики должны быть очень аккуратны, чтобы не использовать большее количество текстур, чем позволяет видеопамять, поскольку подкачка из основной памяти значительно снизит производительность. Но благодаря VMS вы получаете преимущества кэширования с высокой пропускной способностью и можете использовать текстуры большего размера, чем раньше.
Для того чтобы лучше представить преимущества VMS, посмотрите на мир процессоров. Представьте, что L2 кэш вашего процессора, это не кэш, а небольшое количество высокоскоростной локальной памяти, которая не кэширует основную память. Пока запрашиваемые процессором данные находятся в локальной памяти, производительность очень высока. Однако как только приложение превышает размер локальной памяти, производительность ощутимо падает. Как поступить разработчикам программ в такой ситуации? Скажем, писать все программы так, чтобы они полностью попадали в 512 кб локальной памяти? Или, может, использовать этот маленький объем памяти как кэш и разрешить разработчикам задействовать большее количество памяти? Конечно же, второй подход прогрессивнее. А первый не только очень дорог, но и накладывает на разработчиков программ существенные ограничения.
Давайте обратимся к мнению специалиста. Мы спросили Тима Свини из Epic Games о том, что он думает по поводу P10 VMS:
"Это именно то, чего я и Кармак столь долго добивались от производителей 3D карт. Такая архитектура позволяет нам использовать большее количество текстур, чем мы можем сегодня. Однако вы не увидите мгновенных улучшений в современных играх, поскольку игры обычно избегают использовать большее количество текстур, чем помещается в видеопамять, иначе текстуры будут подкачиваться и производительность будет крайне низкой. Виртуальное текстурирование позволяет повысить производительность подкачки текстур, поскольку передаются блоки текстелей, которые действительно будут отрисованы, по требованию.
Таким образом, видеопамять очень напоминает кэш, и вы можете даже использовать меньшее ее количество – практически вам потребуется память только для кадрового буфера, обратного буфера и для блоков текселей, которые отрисовываются на текущей сцене. Вам больше не потребуется хранить все текстуры в памяти. Производители смогут комплектовать карты меньшим объемом памяти без ущерба производительности, что приведет как к улучшению скорости памяти, так и к уменьшению цены.
Архитектура VMS сделала для рендеринга то, что виртуальная память привнесла в операционные системы: она отбросила аппаратные ограничения памяти (с точки зрения приложений)".
Поддержка API
Обладать прекрасным ускорителем – это прекрасно, но вам нужны программы и API для того, чтобы "железо" работало. P10 естественно будет поддерживать DirectX 9, включая вершинные шейдеры 2.0. Мы смогли посмотреть на несколько DirectX 8 программ, работающих на альфа-версии чипа. Говоря конкретно, ими были 3DMark 2001 и демо Chameleon от nVidia. Хотя чип работал на 1/3 номинальной частоты, демо выглядели прекрасно, даже "природа" в 3DMark 2001.
Нам также продемонстрировали вариант ГИС со спутниковым изображением военной базы. Демо использовало картинку в качестве текстуры с очень высоким разрешением, которая превышала размер кадрового буфера. Однако перемещение по карте осуществлялось мгновенно.
Еще одно ключевое API в P10 – это OpenGL 2.0. 3DLabs занимает лидирующую роль в разработке OpenGL 2.0. Первый выпуск OpenGL 2.0 позволит поддерживать не только новые приложения, но и сохранит функциональность старых версий. Подробнее про OpenGL 2.0 вы можете почитать в нашем обзоре (/reviews/software/opengl2/).
3DLabs продемонстрировала классическую демо чайника, запущенную на P10 с использованием программируемых OpenGL 2.0 шейдеров. Учтите, что язык программируемых шейдеров пока еще не закончен, это будет язык высокого уровня, сочетающий как C, так и Renderman. Хотя он не будет выполнять все функции Renderman в полной мере. Благодаря такому уровню программируемости становится возможным работа анимированных и запрограммированных (procedural) текстур на полной скорости (запрограммированная текстура создается программой, а не картинкой).
Заключение
Первый вопрос, который у вас, наверное, возникнет – а на какой рынок позиционируется P10? Несмотря на покупку 3DLabs Creative Labs, компания продолжит свое существования с независимой торговой маркой, и все так же будет работать на профессиональном рынке. Первые экземпляры карт на базе P10 будут выпущены уже очень скоро, причем они будут нацелены на профессиональный рынок. Но, как мы видим, чип имеет неплохие перспективы и на потребительском/игровом рынке, так что 3DLabs обязательно их реализует.
Вот здесь как раз и потребуется помощь Creative Labs. Creative приспособит технологию P10 под специальные нужды и требования игрового рынка. P10 будет устанавливаться на видеокарты Creative, причем цены на них будут вполне конкурентоспособны с GeForce4 (или как там nVidia назовет свою high-end карту следующего поколения). И хотя 3DLabs не делится своими соображениями по поводу того, какие игровые/потребительские карты нам следует ожидать от Creative, информация появится до конца этого года, где-то в районе августа или, возможно, ближе к осени. Но в интересах компании выпустить карты как можно раньше.
С точки зрения жизненной силы архитектуры P10, это, безусловно, очень мощный чип. Цель создать высокоуровневый язык программирования для P10 возможно слишком оптимистична для 3DLabs, по крайней мере, в их первой итерации технологии VPU. Однако вершинные процессоры уже готовы принять на себя подобную роль, а остальная часть конвейера должна стать столь же гибкой, чего пока еще не наблюдается. Будет интересно увидеть, как следующее поколение VPU на 0,13/0,10 мкм техпроцессе начнет поддерживать DX9 совместимый конвейер.
Что касается конечного пользователя, то отсутствие полной поддержки DX9 может отпугнуть многих, однако следует помнить, что поддержка DX8 в первых версиях GeForce3 была практически бесполезна.





