







 MWC 2018
MWC 2018 2018
2018 Computex
Computex
⇣ Содержание
|
Опрос
|
реклама
Самое интересное в новостях
Микроархитектура Intel Sandy Bridge, часть II
Мы продолжаем цикл публикаций, посвящённых новому поколению микроархитектуры Intel Core II с рабочим названием Sandy Bridge. В предыдущей публикации, Микроархитектура Intel Sandy Bridge, часть I, мы рассмотрели структурные новшества новой процессорной микроархитектуры, а также изучили в деталях принцип работы кольцевой шины, кеш-памяти L3 и системного агента с входящими в его состав контроллером памяти DDR3, модулем управления питанием и прочими модулями. 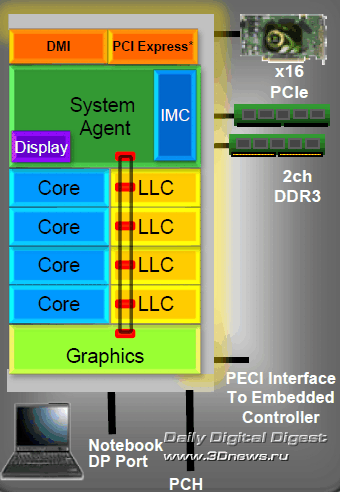
В сегодняшней статье мы познакомимся с особенностями реализации и функционирования процессорных ядер Sandy Bridge, которых в будущих процессорах Core II, согласно предварительной информации, будет насчитываться от двух до двадцати. Материал этот, скорее всего, будет наиболее сложным для восприятия, однако именно ключевые изменения в структуре процессорных ядер и принципе их работы являются наиболее веским основанием для объявления нового поколения микроархитектуры; всё остальное, хоть и не менее важно, всё же вторично. ⇡#Структура процессорного ядра Sandy BridgeЕсли сравнивать строение процессорного ядра Sandy Bridge с самыми первыми представителями микроархитектуры Core, изменения заметны во всём - разница впечатляющая. Если же сравнить ядро Sandy Bridge с его «ближайшим родственником», ядром Nehalem, число действительно серьезных различий будет значительно меньшим. Тем не менее отличия Sandy Bridge настолько существенны, что они обеспечили увеличение ключевого показателя «производительность/энергопотребление» в размерах, опережающих традиционный для очередного обновления микроархитектуры линейный прирост.
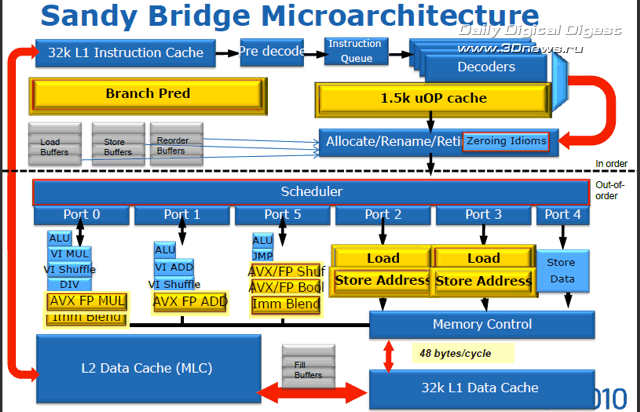
Кроме того, процессорная микроархитектура Sandy Bridge гораздо лучше предшественников соответствует требованиям, предъявляемым приложениями к действительно современным системам. Кроме увеличенной производительности и улучшенных вычислений с плавающей запятой, новая архитектура поддерживает расширенный набор векторных команд Intel AVX (Advanced Vector Extensions), что важно для современных ресурсоёмких приложений; обладает аппаратным модулем ускоренной обработки инструкций шифрования AES (Advanced Encryption Standard) и алгоритмов шифрования RSA и SHA; а также содержит ряд оптимизаций для более эффективной виртуализации и исполнения серверных приложений. ⇡#Элементы входных цепей конвейераБлок упреждающей выборки команд ядра Sandy Bridge предназначен для обеспечения бесперебойной выборки и предварительного декодирования инструкций x86, для последующего их декодирования в операции микрокода. Таким образом, напомним, из инструкций x86 разной длины получается упорядоченный поток равномерных операций, именуемых в Intel «микрооперациями» (μops), для последующей обработки с изменением последовательности (out-of-order). Процесс предварительного декодирования подразумевает формирование очереди из инструкций x86 (до шести инструкций за такт), загружаемых из кеша L1 в промежуточный буфер для последующей передачи на декодирование. От оперативности работы декодеров, от их согласованности с модулем предсказания ветвлений и «умения» заполнять конвейер напрямую зависит бесперебойность потока микроопераций, загрузка конвейера, и в конечном итоге производительность процессора. 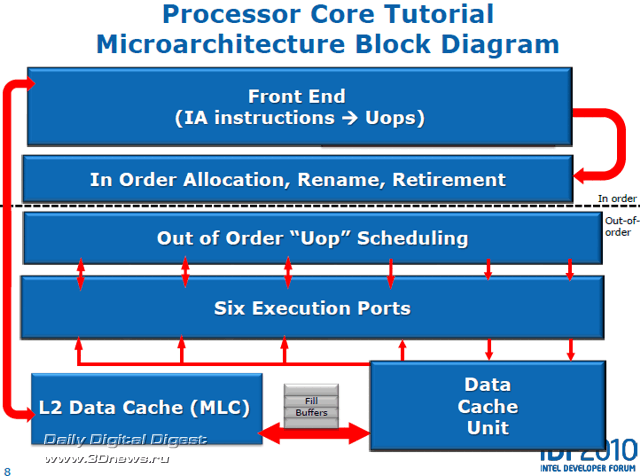 Кеш инструкций L1 ядра Sandy Bridge размером 32 Кбайт обладает восьмиканальной (8-way) ассоциативностью. После упреждающей выборки и предварительного декодирования команды x86 подаются на декодеры, которые, в свою очередь, выдают на выходе микрооперации фиксированной длины для дальнейшей обработки с изменением последовательности (out-of-order). В полной аналогии с ядром Nehalem, три из четырёх декодеров ядра Sandy Bridge обрабатывают простые команды, в результате чего каждый выдаёт по одной микрооперации на выходе, в то время как четвёртый декодер обрабатывает сложные инструкции и выдаёт до четырёх микроопераций. Кроме того, микропрограммные инструкции размером более четырех микроопераций разбиваются на блоки по четыре микрооперации. 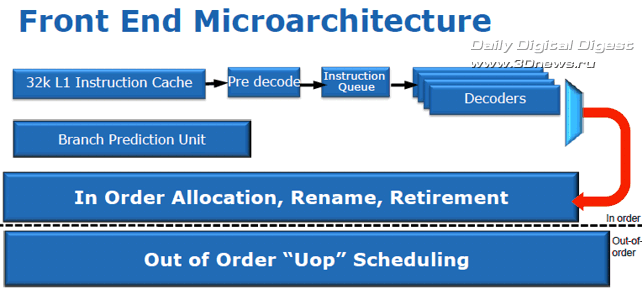 В полной аналогии с предыдущими поколениями процессоров, блоки декодирования Sandy Bridge поддерживают как микро-слияния (Micro Fusion), объединяющие несколько инструкций в ряд одиночных микроопераций, так и макро-слияния (Macro Fusion), объединяющие пары инструкций в одну микроинструкцию. В любом случае, декодеры Sandy Bridge, как и декодеры Nehalem, вне зависимости от характера поступающих инструкций выдают на выходе не более четырех микроопераций за такт. Одним из наиболее важных нововведений микроархитектуры Sandy Bridge является кеш декодированных микроопераций, или кеш инструкций L0. По сути своей кеш декодированных микроопераций напоминает трассировочный кеш микроархитектуры NetBurst (Pentium 4), однако принцип работы у них совершенно разный, сходство заканчивается на том, что оба они работают с микрооперациями. 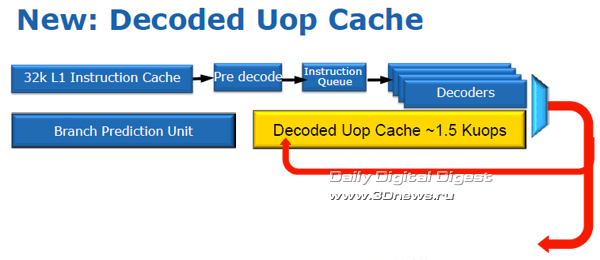 Благодаря структурной организации формата 32х8 с возможностью хранения шести микроопераций в линии, кеш декодированных микроопераций вмещает чуть более полутора тысяч микроопераций. Без особых затей он кеширует на выходе декодеров все предварительно декодированные микрооперации. Как только поступает на обработку новая инструкция, блок упреждающей выборки первым делом производит сверку с кешем L0, и в случае обнаружения совпадений, загрузка конвейера по четыре микрооперации за такт в обход декодеров осуществляется уже из кеша L0. Незадействованные и простаивающие цепи декодеров, кстати, весьма сложные, и потому достаточно «прожорливые», в этот момент попросту… отключаются от питания. В противном случае, когда кеш декодированных операций оказывается невостребованным, продолжается обычная работа по выборке и декодированию команд, а кеш декодированных операций переводится в режим экономии энергии. Кеш L0 в какой-то мере можно считать частью кеша L1, в который он, кстати, интегрирован, но отдельной и очень быстрой его частью. По словам представителей Intel, при работе с большинством приложений, вероятность удачного «попадания» в кеш декодированных микроопераций очень велика и может достигать 80%. 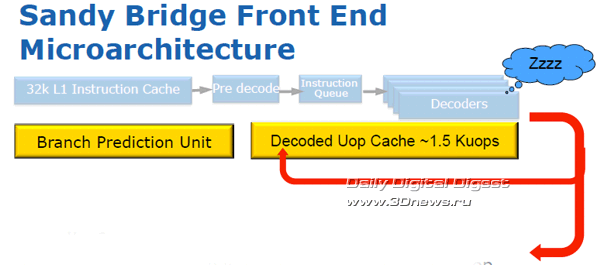 Ничуть не меньше изменился блок предсказания ветвлений (branch prediction). В частности, буфер предсказания результата ветвления (branch target buffer, BTB) чипа Sandy Bridge вмещает в два раза больше адресов результатов ветвления и вдвое большую историю комбинаций команд, нежели аналогичный буфер Nehalem. Кроме того, увеличены размеры области хранения истории ветвлений, в том числе предсказанных и выполненных. Так, удалось снизить количество неудачных предсказаний ветвлений, что положительно отозвалось как на увеличении производительности за счёт уменьшения времени вынужденного простоя для сброса конвейера с десятками обработанных впустую инструкций, так и на потреблении энергии, затрачиваемой зря на обработку неудачных ветвлений. Формирование потока команд с изменением последовательности Процессы распределения, переименования, планировки и вывода данных в процессе конвейерного выполнения макроопераций в микроархитектуре Sandy Bridge подверглись самой значительной переработке.
Реализация алгоритма исполнения инструкций с изменением последовательности в предыдущих поколениях процессоров Intel Core, вплоть до Westmere, базировалась на использовании буфера переупорядочивания - ROB (reorder buffer), который в конечном итоге также служит для восстановления последовательности инструкций. По структуре этот буфер представляет собой матрицу с записями всех исполняемых в данный момент инструкций, а также гигантский массив виртуальных данных со значениями регистров и информацией о перемещениях между регистрами.

Теперь, в микроархитектуре Sandy Bridge, результаты отслеживания и переименования микроопераций фиксируются с помощью физического регистрового файла, PRF (physical register file), присущего архитектуре NetBurst (Pentium 4) и также характерного для многих Out-of-Order архитектур вроде AMD Bulldozer/Bobcat, IBM POWER, но отсутствующего в ядрах Nehalem. Фактически, на буфер переупорядочивания в ядре Sandy Bridge возложена только функция «трассировки» инструкций, обрабатываемых в данный момент времени, в то время как функции хранения данных возложены на независимый физический регистровый файл. Иными словами, факт исполнения операции в Out-of-Order структуре Sandy Bridge приводит только к тому, что регистр указывает на иное значение в PRF, а не к переносу 32-, 64-, 128- или 256-битных данных, как в случае, когда используется только буфер переупорядочивания.
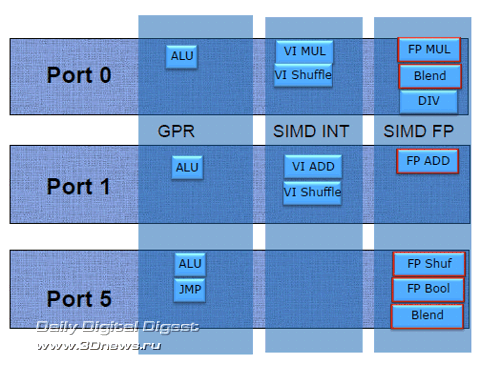
Распределение процессов между двумя структурами вместо одной может показаться архитектурным ретроградством, ведущим к усложнению конструкции и дополнительному увеличению количества транзисторов, то есть, к росту энергопотребления чипа. Тем не менее в конечном итоге такое разделение функций значительно разгружает буфер переупорядочивания, постоянно перегруженный в чипах Nehalem и от того постоянно «горячий». Кроме появления Исполнительные блоки Как и раньше, в чипах Nehalem, загрузка микроопераций всех типов: SIMD, целочисленных и с плавающей запятой, происходит по одинаковому сценарию, единым унифицированным планировщиком, динамически распределённым между всеми потоками. Разница в том, что в архитектуре Sandy Bridge планировщик более ёмкий и загружается сразу 54 переименованными и готовыми к исполнению микрокомандами.

Благодаря существенной доработке, нацеленной на удвоение производительности при работе с 256-битными векторными инструкциями AVX и возможности исполнения большинства из них как единой микрооперации, исполнительные блоки микроархитектуры Sandy Bridge стали вдвое мощнее, чем у чипов Nehalem. Теперь они способны обрабатывать восемь операций

Несмотря на увеличение разрядности исполнительных блоков ядра до 256 бит, увеличения ширины шины данных до 256 бит не произошло. Для исполнения 256-битных микроопераций в ядре Sandy Bridge объединяются возможности имеющихся в наличии 128-битных трактов для работы с данными SIMD INT и SIMD FP.
 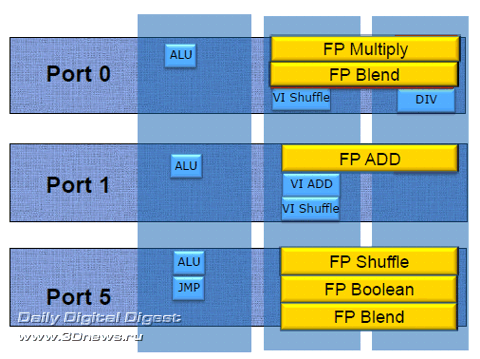
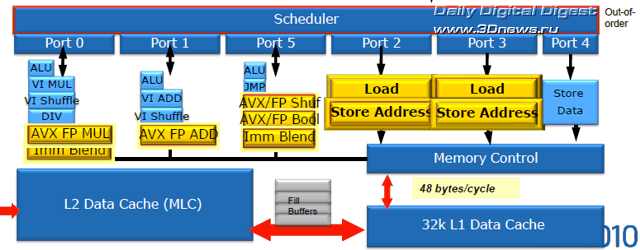
Также стоит упомянуть, что в ядре Sandy Bridge повышена производительность при обработке инструкций стандарта шифрования AES и RSA, а также производительность при вычислении хешей SHA-1. Подсистема памяти Необходимость работы с вдвое увеличенными (до 256 бит) операндами SSE FP не могла не сказаться на нагрузке подсистемы памяти ядра Sandy Bridge, которая должна обслуживать не менее двух запросов за такт, гарантированно обеспечивая возможность 16-байт записи и 16-байт чтения.
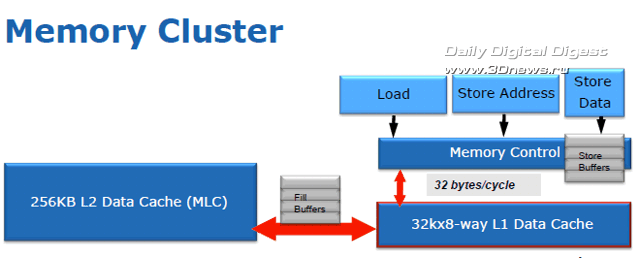
Вот почему в структуре 8-банкового кеша данных L1 ядра Sandy Bridge был добавлен второй 16-битный порт чтения, благодаря которому суммарная пропускная способность кеша выросла до 48 байт за такт: два 16-байт запроса чтения и 16-байт запись. Размеры буферов записи и чтения, разделённых между исполнительными блоками ядра Sandy Bridge, были также увеличены: буфер записи - до 64 ячеек, буфер чтения - до 36 ячеек.
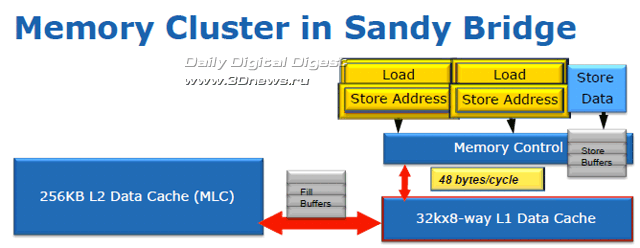
8-банковый ассоциативный кеш L2 микроархитектуры Sandy Bridge, распределённый по 256 Кбайт на каждое ядро, достаточно схож с тем, что применялось в предыдущих поколениях процессоров Intel. Здесь изменения минимальны. Итак, мы закончили знакомство с большинством компонентов новой процессорной микроархитектуры Intel. В третьей, завершающей статье цикла, мы познакомимся со строением и принципом работы интегрированной графической подсистемы Sandy Bridge, подведём итог и вкратце обсудим перспективы платформы на базе новых процессоров Intel Core II и новых чипсетов Intel Series 6.
 Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.
Материалы по теме
|
|||||||||||||||||||||||||||||||||||||
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.





