







 MWC 2018
MWC 2018 2018
2018 Computex
ComputexКогда AMD впервые рассказывала о своих планах и архитектуре K7 на Microprocessor Forum 1998 года, никто даже представить себе не мог, насколько популярным окажется Athlon. Этой архитектуре всего два года, и она уже смогла сместить Intel Pentium III. Многие пользователи даже начинают задумываться, стоит ли вообще переходить на платформу Pentium 4. Сегодня Athlon XP показывает максимальную производительность среди x86 процессоров, при этом процессор создан по архитектуре K7, представленной на том самом форуме.
Но обратимся к настоящему. На сегодня AMD получила неплохую долю рынка, и на нынешнем форуме представила архитектуру нового поколения под кодовым названием "Hammer" ("молоток").
Зная о производительности Athlon, и зная о том скромном начале на MPF 98, невольно задаешься вопросом: а что ещё предпримет AMD, чтобы превзойти свои достижения?
Hammer под микроскопом
По первому впечатлению, архитектура Hammer должна была использоваться в первых 64-битных процессорах x86. Мы уже знаем, что в своем 64-битном детище Itanium Intel изменила системы команд x86 и взяла за основу новую систему команд, называемую EPIC. Цель нашей статьи - не только выявить все плюсы и минусы расширения стандартной 32-битной x86 архитектуры AMD, но и рассмотреть все детали, включая саму архитектуру Hammer - ведь разница заключается не только в увеличении количества регистров и увеличении адресного пространства.
Чтобы понять противоречия между 64-битными решениями от AMD и Intel, важно осознавать, что архитектура команд x86 далека от совершенства. Cовременные x86 процессоры топчутся на месте в основном благодаря ограничениям x86 архитектуры. Причиной тому - сам рынок. Под эту архитектуру чего только не разработано. Кстати, несмотря на то, что процессоры Intel Itanium используют новую систему команд, пройдет много лет, прежде чем она распространится.
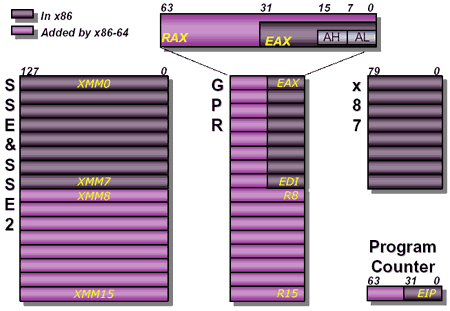
Hammer можно назвать особенным не только из-за его набора команд. Но в первую очередь, мы остановимся именно на этом. Положение AMD не настолько сильно, чтобы перейти на свой набор команд и полностью отказаться от x86, поэтому кажется правильным переход на систему команд x86-64, расширение имеющейся 32-битной архитектуры x86. А то, что AMD не собирается отказываться от этой архитектуры - вовсе не означает, что Hammer обречен.
Для начала, выделим преимущества архитектуры x86-64:
- Обратная совместимость с инструкциями x86;
- 8 новых 64-битных регистров общего назначения (general purpose registers, GPRs), плюс 64-битные версии прежних 8 регистров общего назначения;
- Поддержка SSE и SSE2, плюс 8 новых регистров SSE2;
- Увеличен объем адресуемой памяти для приложений, работающих с большими объемами данных;
- Высокая производительность 32-битных приложений, плюс поддержка появляющихся 64-битных приложений, хороший вариант переходного процессора.
Ниже перечислены основные недостатки:
- Процессор продолжает поддерживать архитектуру x86, которой уже давно пора кануть в лету.
- Новые регистры общего назначения можно использовать лишь в 64-битном режиме, что не позволяет повысить производительность 32-битных приложений посредством улучшения архитектуры системы команд.
Новая архитектура x86-64 - излюбленная тема для разговоров. В нашей же статье мы поговорим не о стратегическом выборе архитектуры системы команд AMD, а о том, что стоит за Hammer. Итак, рассмотрим, как заставить и без того быстрый процессор работать ещё быстрее.
Способы достижения цели
Нетрудно предположить, что AMD с процессором нового поколения, скорее всего, последует тем же основным принципам, что и Intel в архитектуре NetBurst:
- использование длинных конвейеров (более 20 ступеней) позволяет достичь высокой тактовой частоты (более 10 ГГц к 2006 году);
- небольшие кэши с маленькими задержками и подсистема памяти с большой пропускной способностью (к примеру, RDRAM).
Однако, согласитесь, для AMD не имело смысла полностью отказываться от их неплохой архитектуры K7 только для того, чтобы их следующий процессор был похож на P4. В то же время, AMD вовсе даже не хотела, чтобы в ее процессорах наблюдались недостатки работы на высоких частотах. Как мы уже рассказывали в нашей статье о технологии BBUL от Intel, при увеличении тактовой частоты возрастает значение упаковки (того, во что заключен кристалл, и того, что обеспечивает связь этого кристалла со внешним миром). В свете недавнего перехода AMD на некерамическую упаковку (для сравнения, Intel отказалась от керамики ещё во времена Pentium), маловероятно, что AMD имеет все необходимое для производства в ближайшее время процессоров с частотой 10-20 ГГц. И даже новая технология безударно наращиваемых слоев (Bumpless Buildup Layer, BBUL) от Intel ещё не созрела, а научно-исследовательское подразделение Intel препятствует разработкам AMD. Итак, с точки зрения технологии, AMD не сможет создавать процессоры с высокой тактовой частотой, так как кроме самого ядра процессора, на частоту оказывает влияние множество различных факторов. Для этого AMD недостает целой инфраструктуры, имеющейся у Intel. Поэтому AMD не сможет последовать примеру Intel с её Pentium 4.
Но это ещё ничего не означает: достаточно обратится к современному рынку наиболее мощных процессоров. Например, в тесте SPEC CFP2000 процессор Alpha 21264A с частотой 667 МГц смог бы превзойти наш любимый AMD Athlon, работающий на вдвое большей частоте, не говоря уже об Intel Itanium 800МГц, показавший ещё более высокие результаты. К сожалению, существует популярное, но, в общем-то, неправильное мнение, что когда создавался Pentium 4, группа маркетологов, ничего не смыслящих в архитектуре процессоров, решила, что новый процессор должен работать на максимально высоких частотах. На самом деле, Intel смыслит в этом деле ничуть не меньше AMD и остальных производителей процессоров, она прекрасно понимает, что тактовая частота - далеко не единственный важный фактор, влияющий на производительность процессора. AMD стала пропагандировать количество инструкций, выполняемых за один такт (Instructions Per Clock, IPC) - именно в этом она превосходит конкурентов, а Intel, по очевидным причинам, решила играть на максимальной тактовой частоте. Оба этих показателя (и IPC, и тактовая частота) являются частями одного уравнения - уравнения производительности. То есть теоретически возможно либо создать процессор с высоким количеством выполняемых за цикл инструкций, либо процессор с высокой тактовой частотой.
Как и в случае с архитектурой K7, не предполагалось, что Hammer будет работать на очень высоких частотах. Вместо этого должно было быть существенно увеличено количество инструкций, выполняемых за такт, и немного добавлена тактовая частота. Это совсем не похоже на подход Intel (NetBurst и Pentium 4). Нельзя сказать, правильнее это, или нет. Это просто разные подходы.
Конвейер
С появлением Pentium 4 стало модно вести разговоры о количестве ступеней в конвейере, при этом распространилось мнение, что чем длиннее конвейер, тем это хуже сказывается на реальной производительности. Так как Hammer отличается от архитектуры NetBurst, мы решили начать рассказ с самого яркого отличия архитектур - с конвейера.
| Сравнение целочисленных конвейеров AMD | ||
| Такт | Архитектура K7 | Архитектура Hammer |
| 1 | Выборка (Fetch) | Выборка (первая ступень) |
| 2 | Сканировение (Scan) | Выборка (вторая ступень) |
| 3 | Выравнивание 1 (Align 1) | Выбор (Pick) |
| 4 | Выравнивание (Align 2) | Декодирование 1 (Decode 1) |
| 5 | EDEC | Декодирование 2 (Decode 2) |
| 6 | IDEQ/Переименование | Упаковка (Pack) |
| 7 | Планирование (Schedule) | Упаковка/декодирование (Pack/Decode) |
| 8 | AGU/ALU | Отправка (Dispatch) |
| 9 | Генерация адреса L1 (Address Generation) | Планирование (Schedule) |
| 10 | Кэш данных (Data Cache) | AGU/ALU |
| 11 | Кэш данных 1 (Data Cache 1) | |
| 12 | Кэш данных 2 (Data Cache 2) | |
На таблице вы видите главный целочисленный конвейер архитектур K7 и Hammer. Путь инструкции с плавающей точкой будет дольше, для наших же целей вполне хватит и целочисленного конвейера. Вы конечно же заметили, что конвейер Hammer на целых две ступени длиннее. Новые ступени служат для увеличения тактовой частоты. Для того, чтобы убедиться в этом, рассмотрим предназначение ступеней вообще.
В начале этой статьи мы рассказывали о современных высокопроизводительных процессорах на базе архитектуры x86. Как же они преодолевают ограничения архитектуры x86? В настоящее время часто практикуется следующее: берутся стандартные x86 инструкции, декодируются в микрокод, скорость выполнения которого значительно выше. В Pentium 4 такое декодирование - довольно сложная операция, сильно влияющая на производительность процессора.
Те из вас, кто близко знаком с архитектурой K7, знают, что ступени декодирования, в зависимости от декодируемого кода, могут изменяться. Но чтобы не усложнять объяснения, мы намеренно опустили эти изменения - особой роли в анализе они не играют.
Итак, первое место, где архитектуры K7 и Hammer расходятся - это вторая ступень. Здесь у Hammer находится так называемая вторая ступень приема инструкций (second Fetch stage). Эту ступень можно рассматривать как переходную, ее цель - перемещение кода, предназначенного для выполнения, из кэша инструкций в декодеры. В архитектуре NetBurst тоже имеется подобная ступень, позволяющая перемещать данные по чипу. Единственное предназначение таких ступеней - увеличение тактовой частоты.
На фазе приема инструкции готовятся к отправке на первые ступени декодирования. Схема очень напоминает ступень разбиения (align stage) K7. Здесь процессор пытается передать устройствам выполнения как можно больше независимых инструкций. Первая и вторая ступени декодирования на самом деле не разбивают инструкции на меньшие коды (AMD называет их термином "Macro-Ops"). Вместо этого, на этих ступенях собирается информация об инструкциях, но до разбиения (или декодирования) дело не доходит. Схема очень напоминает ступень раннего декодирования K7 (Early Decode, EDEC), где непосредственно перед декодированием выбирается путь инструкций (прямой или векторный). Единственное отличие заключается здесь в том, что у Hammer на эту фазу отведено два цикла, опять же, для увеличения тактовой частоты.
На следующей, упаковочной ступени (pack stage) инструкция принимается с предыдущих ступеней декодирования и готовится к преобразованию в макрокод (macro-ops). Затем эти макрокоманды распределяются по устройствам выполнения, в итоге они попадают в кэш L1, который в обеих архитектурах одинаков.
Итак, мы видим, что единственное различие в основном целочисленном конвейере Hammer и K7 - в двух ступенях. В итоге, количество инструкций, выполняемых за такт, в результате удлинения конвейера снизилось лишь незначительно. Напомним, что длина конвейера Pentium 4 вдвое больше конвейера P6, а здесь длина увеличилась лишь на пятую часть. В то же время, вероятно AMD не сможет достичь той же частоты, на которой будут работать процессоры NetBurst.
От "небольшого отличия" к "великим переменам"
Удлинение конвейера на 2 ступени дает AMD возможность несколько увеличить тактовую частоту, но выше мы уже упомянули о том, что в Hammer сделана ставка не на увеличение тактовой частоты, а на увеличение количества инструкций за такт. Почему же увеличивается количество инструкций за такт?
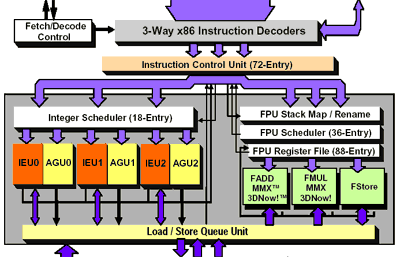
Так выполняются команды в K7
Один из способов увеличения количества выполняемых за один такт инструкций заключается в увеличении количества исполнительных устройств. В архитектуре K7 имеется три арифметико-логических устройства (АЛУ - для операций с целыми числами), три устройства адресации (Address Generation Units, AGUs - для операций выгрузки из кэша и для записи в кэш), и три устройства для операций с плавающей точкой. Ничего не стоило бы оснастить Hammer вдвое большим количеством устройств, но, к сожалению, на производительности это существенно не отразилось бы. Даже обеспечить работой все исполнительные устройства Athlon довольно сложно, как сложно вообще обеспечить работой исполнительные устройства любого современного процессора, включая Pentium 4. Именно поэтому увеличение частоты FSB приводит к существенному улучшению производительности, ведь именно от нее зависит насколько вы сможете загрузить работой исполнительные устройства.
Intel решает эту проблему с помощью технологии Hyper-Threading. Благодаря ей многопроцессорная операционная система использует один процессор как два, и выдает одновременно два потока команд. Смысл технологии заключается в том, что в большинстве случаев исполнительные устройства процессора далеки от полной загруженности. От передачи на выполнение вдвое большего потока команд повышается загрузка исполнительных устройств. В результате новой технологии Intel ожидает прирост производительности на 10-20 процентов, и это не лишено смысла.
Как и Intel, AMD понимает, что с простым увеличением количества исполнительных устройств производительность не повысится. То есть теоретически, возможно, и получится, но на практике - не получится.
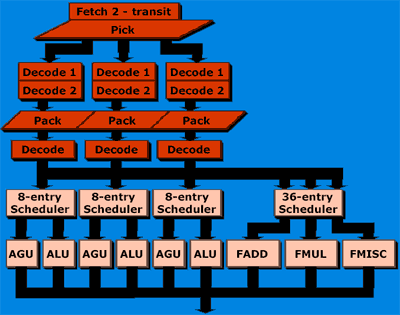
Исполнительные устройства Hammer аналогичны Athlon
AMD решила эту проблему со свойственной ей оригинальностью. Было решено оставить такое же количество исполнительных устройств, что мы видели в K7. Быть может, это покажется вам не совсем технологично. Грубо говоря, AMD решила "не будить Лихо, пока тихо". Мы уверены, что AMD знает о проблемах использования исполнительных устройств намного больше нашего. И мы вправе предположить, с Athlon в этом отношении, все в порядке.
Тогда возникает логичный вопрос: каким же образом AMD планирует увеличить количество выполняемых за такт инструкций в Hammer?
Рассмотрим три основных улучшения новой архитектуры по сравнению с K7:
- встроенный контроллер памяти и северный мост
- доработано устройство предсказания ветвлений
- то, что AMD любит называть "большой загрузкой буфера быстрого преобразования адреса (translation lookaside buffer, TLB)"
AMD не дала этим новинкам никакого специального названия, и нам ничего не остается, как рассмотреть их подробнее.
Интегрированный контроллер памяти и северный мост
Годами AMD лишь догоняла Intel. Мы уже знакомы с судьбами других таких последователей, как-то Cyrix и IDT. И если и есть хоть что-то, что отличает AMD от всех этих производителей, так это Hammer. Сейчас вы увидите, почему.
Большая пропускная способность системной памяти, и маленькое значение задержки памяти всегда были актуальны. С момента возникновения AnandTech - с 1997 года - мы наблюдаем за развитием памяти: переход с EDO на SDRAM, с PC66 на PC133, с SDR на DDR, и даже с VC на DRDRAM. Мы видели, что одно лишь использование DDR SDRAM увеличивает производительность Athlon на 20-30 процентов. Кроме того, мы видели, насколько важно значение задержек при большой пропускной способности памяти. Большая задержка доступа к памяти стала причиной неудачи чипсета Ali MAGiK1, выпущенного за несколько месяцев до DDR решения VIA для Athlon. Вы спросите: если производители процессоров могут выпускать настолько мощные процессоры, почему никто не может для них придумать эффективный способ получения данных из памяти?
Рассмотрим путь, который проходят данные, перед тем как попасть из памяти в процессор. Когда процессор выполняет считывание из системной памяти, в первую очередь команда посылается по системной шине в северный мост чипсета, который затем передает её встроенному контроллеру памяти. Именно в этих первых шагах скрываются подводные камни. Иногда (хотя и редко - ведь системная шина и шины памяти обычно синхронизируются) не хватает пропускной способности системной шины. В результате снижается скорость чтения из памяти. Намного чаще случаются большие задержки из-за неэффективной работы северного моста и контроллера памяти.
Далее, когда контроллер памяти получил команду на считывание (мы не рассматриваем многочисленные буферы, которые должна пройти команда, и т.д.), по шине памяти запрос пересылается в память, и через несколько операций найденные данные пересылаются назад, в контроллер памяти. Затем контроллер памяти принимает эти данные и передает на интерфейс системной шины в северном мосту, и далее эти данные попадают назад в процессор.
Что касается второй половины этого процесса, все зависит целиком от типа используемой памяти и частоты шины памяти. Однако с помощью чипсета и системной шины можно повлиять на скорость выполнения первой и нескольких последних операций.
Можно было бы применить промежуточный кэш L3 как способ сокращения задержек и как способ увеличения загрузки канала между северным мостом и процессором, но AMD выбрала интеграцию контроллера памяти прямо в процессор.

Hammer
Оцените преимущества интеграции контроллера памяти в процессор. От этого не только сокращаются задержки в работе с памятью (теперь запросы на запись/считывание минуют внешний северный мост), но существенно сокращаются шансы того, что чипсет будет тормозить общую производительность платформы. Мы видели множество примеров того, как Athlon не достигал максимальной производительности лишь благодаря платформам, работающим не так, как положено. В то же время, AMD ясно дала знать, что она не имеет ни желания, ни возможности последовать Intel и производить чипсеты в таком же объеме. Поэтому ничего лучше, как избавиться от источника проблем и интегрировать контроллер памяти в процессор, придумано не было.
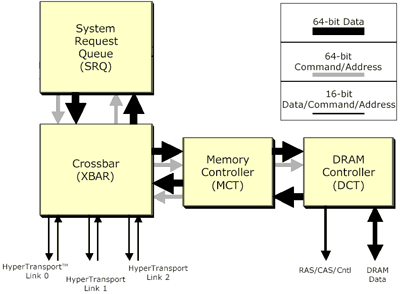
Ядро Hammer взаимодействует с очередью системных запросов (SRQ) для посылки запросов на контроллеры памяти (MCT/DCT) через перекрестный контроллер (crossbar controller).
Таким образом, архитектура Hammer обращается к встроенному контроллеру памяти (MCT) и встроенному контроллеру DRAM (DCT). Контроллер памяти представляет собой обобщенный интерфейс между ядром Hammer и контроллером DCT. Этот контроллер понимает, что такое память вообще, но он никоим образом не привязан к конкретному типу используемой памяти. Контроллер памяти подключен к DCT, который представляет собой более специфическое устройство, работающее лишь с определенными типами памяти. Теоретически AMD могла создать Hammer с поддержкой DDR SDRAM, и Hammer с поддержкой RDRAM просто изменив контроллер DTC, но заметим, что пользы от использования RDRAM для Hammer крайне мало. Напомним, что один из недостатков RDRAM - слишком большие задержки, проявляющиеся довольно часто. Один из способов решения этой проблемы - использование RDRAM совместно с процессорами с длинными конвейерами, как в Pentium 4. Теперь уже ясно, что конвейер Hammer не такой длинный, и тактовая частота у него не сможет компенсировать задержки RDRAM, как сделано в Pentium 4. Поэтому решение AMD остаться с DDR SDRAM вполне разумно.
Первые процессоры на архитектуре Hammer будут обладать либо 64-битным, либо 128-битным контроллером DDR SDRAM. Контроллер DCT может поддерживать тактовые частоты 100, 133, или 166МГц под DDR200, DDR266 или DDR333 SDRAM. AMD ясно дала понять, что в более поздних версиях Hammer DCT контроллер DDR поменяют на контроллер DDR-II.
| Сравнение пропускной способности памяти | ||
| Тип памяти | 64-бит DCT | 128-бит DCT |
| DDR200 | 1,6 Гбайт/с | 3,2 Гбайт/с |
| DDR266 | 2,1 Гбайт/с | 4,2 Гбайт/с |
| DDR333 | 2,7 Гбайт/с | 5,4 Гбайт/с |
 Расположение контроллера памяти непосредственно на кристалле означает ещё и то, что скорость доступа к памяти напрямую зависит от тактовой частоты, так как данные уже попадают в процессор, минуя системную шину. В качестве примера на Microprocessor Forum AMD привела теоретический 2ГГц Hammer с задержкой памяти всего 12 нс (справа вы видите конвейер Hammer). Очевидно, сюда не входит время считывания данных из памяти, но в любом случае, это оказывается намного быстрее работы через внешний северный мост. Итак, AMD собирается увеличить количество инструкций, выполняемых за такт за счет увеличения скорости считывания данных из памяти. В результате этого, исполнительные устройства Hammer будут лучше обеспечены данными, нежели исполнительные устройства Athlon.
Расположение контроллера памяти непосредственно на кристалле означает ещё и то, что скорость доступа к памяти напрямую зависит от тактовой частоты, так как данные уже попадают в процессор, минуя системную шину. В качестве примера на Microprocessor Forum AMD привела теоретический 2ГГц Hammer с задержкой памяти всего 12 нс (справа вы видите конвейер Hammer). Очевидно, сюда не входит время считывания данных из памяти, но в любом случае, это оказывается намного быстрее работы через внешний северный мост. Итак, AMD собирается увеличить количество инструкций, выполняемых за такт за счет увеличения скорости считывания данных из памяти. В результате этого, исполнительные устройства Hammer будут лучше обеспечены данными, нежели исполнительные устройства Athlon.
Итак, встроенный контроллер памяти перенимает на себя одну из основных функций внешнего северного моста. AMD пошла дальше и практически встроила северный мост в кристалл процессора. Единственное, что осталось на долю традиционного внешнего северного моста - это контроллер AGP. Это практически устранит все проблемы с производительностью, которые бы возникли при использовании Hammer с современными чипсетами, к тому же, это осчастливит производителей материнских плат - ведь значительно упростится компоновка дорожек между памятью и процессором.
Ниже представлен пример однопроцессорной системы Hammer.

Как видите, единственный чип, имеющийся на материнской плате (кроме южного моста) - это контроллер AGP 8X. Он взаимодействует с процессором по шине HyperTransport. Вероятно, в поисках дешевого решения, производители чипсетов просто создадут один единственный чип, который будет выполнять все традиционные функции южного моста плюс функции контроллера AGP 8X.
Кроме того, на изображении видно только два банка памяти. AMD заявила, что однопроцессорные системы на базе Hammer будут поддерживать максимум 2 небуферизованных DIMM.
Усовершенствованное устройство предсказания ветвлений
Не думайте, что если конвейер Hammer состоит всего из 12 ступеней, то AMD не станет улучшать устройство предсказания ветвлений. Усовершенствование все равно необходимо - чтобы не снизилось количество выполняемых за цикл инструкций в ситуациях, когда предсказания затруднительны, ведь конвейер все же стал длиннее - на целых 20 процентов. Напомним, что в результате неправильного предсказания, Hammer проделывает на 20 процентов больше работы, чем Athlon. Это так же одна из причин, почему в Hammer должно быть улучшено устройство предсказания ветвлений.
Вы, вероятно, помните, каким образом Intel решила эту проблему - был создан кэш с отслеживаниями (trace cache). В нем хранятся декодированные инструкции, причем в том порядке, в каком они должны быть выполнены. Поэтому, в случае неправильного предсказания, не будет тратиться время на повторное декодирование инструкций. Этот кэш прекрасно справляется со своими обязанностями при небольших, непостоянных нагрузках, но AMD быстро выявила ситуацию, когда такой кэш с отслеживаниями становится неэффективным - при больших нагрузках. Большими нагрузками AMD считает те, когда обрабатываются большие объемы информации - например, к ним относятся научные расчеты. Большую нагрузку могут обеспечить и несколько небольших, но работающих одновременно программ. Например, это может быть что-то вроде сервера баз данных, параллельно выполняющего множество небольших транзакций.
Перед тем, как пройти далее, рассмотрим, действительно ли снижается эффективность кэша с отслеживаниями при больших нагрузках. В нашем обзоре 760MP мы проводили три итерации теста CSA Research's Office Bench 2001. В каждом следующей итерации нагрузку значительно увеличивалась - с помощью увеличения количества выполняемых процессов. Так в первой (baseline) итерации не было ни одной фоновой задачи, а в третьей (level 2) итерации, кроме всего прочего, было запущено несколько окон Windows Media Player, и выполнялись запросы к базе данных. По всем теоретическим показателям Intel Xeon 1,7 ГГц должен был справляться с дополнительной нагрузкой намного лучше, чем Athlon MP 1,2 ГГц (использовались однопроцессорные системы). Полоса пропускания системной шины и памяти у Xeon (как и Pentium 4) шире, она как раз и может хорошо задействоваться этим тестом.
Во второй итерации (level 1), уровень загрузки был средним. Для сравнения с первой (baseline) итерацией, и Athlon MP 1,2ГГц, и Xeon 1,7 ГГц во второй работали на 39% медленнее. При максимальной нагрузке (level 2), оказалось, что Xeon работал в 3,1 раза медленнее, чем на первой (baseline) итерации, для сравнения, Athlon MP работал всего лишь в 2,7 раза медленнее. Было бы наивно предполагать, что такая разница возникла благодаря тому, что кэш с отслеживаниями плохо справляется с большой нагрузкой, но некоторое влияние он оказывает.
В отличие от Pentium 4, архитектура Hammer будет применяться повсеместно, во всей линейке AMD. То есть AMD предлагают свое решение и для 4-х и 8-ми процессорных серверов, конкурируя с Itanium, и такое же решение для мобильного и базового рынков. Кроме того, AMD предлагает Hammer и на рынок high-end рабочих станций и серверов, где работают законы больших нагрузок, и где можно утверждать, что кэш с отслеживаниями особой пользы не приносит.
В Hammer AMD существенно доработала устройство предсказания ветвлений Athlon. Массив конечных ветвей (branch taget array) все так же ограничен 2K вхождениями, стек возврата (return stack) тоже остался на 12 записей, на само устройство предсказания было существенно изменено. Переключатели ветвлений (branch selectors) представляют собой биты, хранящиеся в кэше L1 (они содержат информацию о том, где в коде находятся ветвления и к какому типу они относятся). У этих переключателей имеется ещё один бит, указывающий на то, является ли ветвь статичной, и таким образом, позволяющий процессору предсказывать её статически. Статическая ветвь - это та ветвь, результат которой почти всегда известен, например, это ветвление на коды ошибок в программе, которое почти всегда можно предсказать с высокой вероятностью. Это позволяет общему накопителю инструкций (здесь хранится история предсказаний, улучшающая последующие предсказания) не замусориваться лишней информацией. Согласитесь, ведь знание результата ветвления на какую-либо конкретную ошибку не поможет предсказать нестатическую ветвь позже.
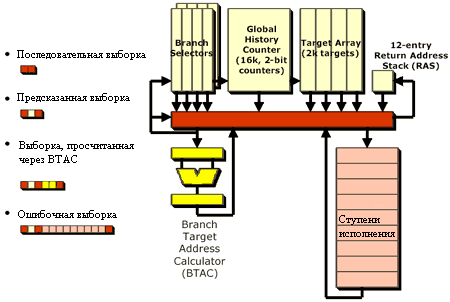
И, наконец, рассмотрим кусочек логики, на которой работает устройство предсказания ветвлений Hammer - это вычислитель адреса ветвей (Branch Target Address Calculator, BTAC). Но сначала, рассмотрим, как поступает Itanium, когда ему встречается несколько условных переходов. Itanium -мощный процессор, поэтому вместо предсказания ветвления он одновременно вычисляет куски кода, соответствующие обоим результатам ветвления. В конце концов, оно выбирает правильные данные, и отбрасывает ненужные. Например, предположим, оптимизированный компилятор Itanium получает следующие инструкции:
...
3*4
Загрузить данные из адреса памяти A в регистр 5
Если значение регистра пять отрицательное, тогда выполняются инструкции Case 1, в противном случае выполняются инструкции Case 2
Case 1:
12*6
Case 2:
1+1
...
Конечно, наш пример отнюдь не такой сложный, но на нем можно хорошо проиллюстрировать работу Itanium. Итак, Itanium выполняет оба кода Case 1 и Case 2, определяет значение в регистре R5, и затем просто-напросто отбрасывает ненужное значение. Конечно, нельзя сказать, что архитектура Hammer в корне отличается от конкурента. Но Hammer даже не пытается достичь уровня Itanium в распараллеливании инструкций. Вместо этого, Hammer старается лучше предсказывать результат ветвления. В нашем случае, Hammer попробует вычислить направление ветвления, используя BTAC. На такую операцию тратится около пяти тактов, но при этом значительно улучшается эффективность предсказания благодаря опоре на вычисление ветвления, а не на отгадывание. Как вы можете догадаться, от этого также увеличивается количество выполняемых за цикл инструкций.
Буфер быстрого преобразования адреса для больших нагрузок
Когда AMD представляла свое новое ядро Palomino, в нем было увеличено количество записей в буфере TLB. От такого увеличения сокращается время, затрачиваемое на преобразование адресов из виртуальных в физические. Несмотря на то, что задержки памяти в Hammer значительно сокращены (благодаря встроенному в кристалл контроллеру памяти), при определенных операциях увеличение записей TLB приводит к сокращению требуемого количества тактов для ряда операций. Пока не ясно, насколько сильно улучшается производительность при увеличении количества записей в TLB, но такое увеличение, скорее всего, предназначено для серьезных задач с большими нагрузками (при использовании процессора в рабочих станциях и серверах).
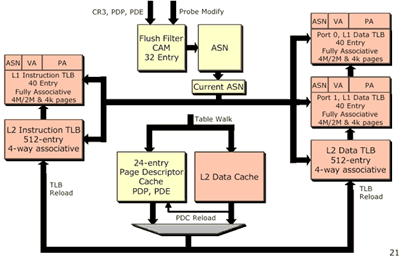
Еще более интересный аспект, касающийся TLB - ими очень легко управлять во время переключения задач. Как правило, при каждом переключении задачи (например, при обработке нового потока), процессор должен сначала освободить содержимое TLB. В многозадачной среде, когда переключение задач не прекращается, поддерживать TLB не так-то просто. В современных RISC процессорах используется система присвоения идентификаторов процессов (process id), чтобы было легче отслеживать содержимое TLB - быстро очищать при переключении на другую задачу и быстро восстанавливать обратно. Предположительно, Hammer использует подобную технологию.
Кэши Hammer
До сих пор мы обсуждали архитектуру Hammer, но при этом мы мало внимания уделяли традиционным критериям сравнения процессоров. Подсистема кэша в Hammer практически не изменилась по сравнению с Athlon. Кэш данных L1 на 64 кб и кэш инструкций L1 на 64 кб остались такими же, как и у Athlon/Athlon XP, и представляют собой 2-х канальный ассоциативный кэш (с небольшой задержкой, а следовательно и с небольшим коэффициентом успеха).
Кэш L2 снова оказался переменного размера, но на этот раз, AMD ограничилась максимумом в 1Мб. Это представляет особенный интерес, ведь после выхода Athlon, AMD намекала, что возможно, в следующем продукте кэш вырастет до 8Мб. Пока что мы знаем только о существовании Athlon на ядре Mustang с 1 Мб кэшем, но ни одного процессора с большим кэшем L2 выпущено не было.
Скорее всего, часть процессоров будет поставляться с кэшем на 512 кб (на рынок производительных компьютеров и рабочих станций начального уровня), а часть - на 1 Мб (для high-end серверов). С технологическим процессом 0,13 мкм будет не слишком трудно встроить в кристалл кэш 512Кб, тем более было бы крайне неразумно размещать кэш меньшего размера, особенно учитывая хорошую производительность процессоров AMD при больших загрузках. Если бы AMD создавала версию Hammer аналогичную Duron, то можно было бы вполне обойтись кэшем L2 на 256 кб.
Ещё раз напомним, что кэш L2 представляет собой 16-канальный ассоциативный кэш, подобно кэшу ядер Thunderbird/Palomino. AMD же уверяет, что L2 кэш для Hammer разрабатывался отдельно от кэша Athlon, и схожие характеристики просто являются совпадением. AMD уже подтвердила, что кэш L2 будет работать эффективнее, нам же остается выяснить, станет ли шире интерфейс этого кэша, и будет ли он эффективнее существующего 64-битного канала данных.
Многопроцессорность
Хотя Hammer и разрабатывался для повсеместного применения, включая high-end серверы и небольшие ноутбуки, очевидно сферы его использования все же будут связаны с серверной природой процессора. Поэтому рассмотрим работу Hammer в многопроцессорной системе.
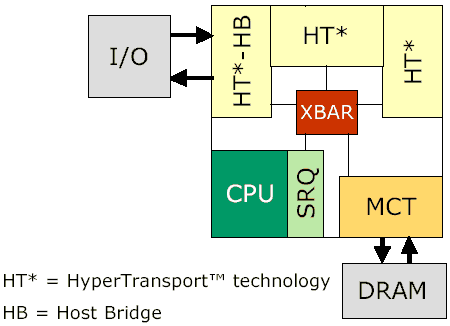
Hammer с тремя каналами Hyper Transport
Одна из проблем, с которыми сталкиваются при разработке многопроцессорных систем, заключается в том, что бывает затруднительно разработать и разместить на материнской плате чипсеты, взаимодействующие по шинному протоколу точка-точка (как EV6 у Athlon). Очевидно, что Hammer не использует этот протокол (вместо него используется Hyper Transport), а проблема многопроцессорности решается подключением к каждому процессору до двух дополнительных каналов Hyper Transport (HT). Один канал используется для обращения ко внешнему контроллеру AGP 8X, остальные два канала могут использоваться для обращения к двум другим процессорам.
Хотя каждый процессор обладает своим собственным контроллером памяти, для операционной системы и приложений вся память будет выглядеть единым блоком. Если процессор попытается обратиться к памяти, подконтрольной другому процессору, инструкция на считывание будет передаваться от процессора к процессору, пока не попадет на тот процессор, который контролирует эту память. Затем результат переправляется запросившему процессору.
Каждый из HT каналов и контроллер памяти подключены к перекрестному арбитру (crossbar arbiter logic), который обрабатывает все запросы, поступающие с других процессоров и других внешних устройств вне процессора. Все прелесть в том, что производительность перекрестного контроллера (crossbar controller) изменяется с изменением тактовой частоты, то есть, чем быстрее работает процессор, тем лучше перекрестный контроллер управляет данными между различными HT каналами и контроллером памяти. Это означает долгожданный отказ от использования системной шины с фиксированной частотой, которая не меняется при росте частоты процессора в обычных системах.
| Многопроцессорность Hammer | ||
 2 |
 4 |
 8 |
Заметьте, насколько просто создаются многопроцессорные системы, отныне нет необходимости в использовании специфических чипсетов, что поможет выйти двухпроцессорным системам на рынок обычных компьютеров. И хотя это всего лишь предположение, с учетом архитектуры Hammer это очень похоже на правду.
Выводы
Hammer - очень интересная тема для обсуждения. Никогда не лишне узнать об альтернативных подходах к улучшению производительности. Из противопоставления Hammer и NetBurst (Pentium 4) нельзя сказать, какая архитектура лучше. AMD выбрала свой путь, и на этом пути AMD столкнется с иными проблемами.
В нашей статье мы не сравнивали напрямую ни процессоры, ни архитектуры - ещё слишком рано делать прогнозы о реальной производительности Hammer или конкурирующих процессоров. Нам известно, что пробные образцы процессоров SledgeHammer и ClawHammer (серверный вариант и вариант для производительных компьютеров соответственно) появятся лишь во второй половине 2002 года. Вы можете сравнить ситуацию с появлением ограниченного количества образцов Athlon в конце 1999, но нам бы хотелось, чтобы в случае с линейкой Hammer не появились неприятности с наличием материнских плат. Настоящий же триумф Hammer начнется через пару лет, к 2003 году, когда эра Athlon будет на закате.
Очевидно, что AMD уже совсем не та компания, какой она была несколько лет назад. Компания постоянно стремится стать лидером индустрии, а не быть на вторых ролях, за что её жестоко критиковали раньше. Архитектура Hammer - наиболее яркий пример того, на что способна AMD в погоне за лидерством.
В то же время, мы не должны сбрасывать со счетов Intel - ведь именно ей принадлежит огромная доля рынка, и именно она может найти достойное применение всем своим технологиям. Тем не менее, последние достижения AMD ясно показали, что в ближайшее время возврата к безоговорочному лидерству Intel не произойдет, и обе компании будут участвовать в гонке. И AMD, и Intel в прошлом совершали ошибки. И хотя ошибки Intel мы видели совсем недавно, AMD от подобных вещей тоже не застрахована.
Уже наработаны технологии Hammer, имеется все для достижения успеха. Но AMD ещё предстоит проделать большую работу до выхода Hammer через год. Многие забывают, что Athlon - первое значительное достижение AMD. Остается лишь пожелать ребятам из команды Hammer всяческих успехов.





