|
Опрос
|
реклама
Быстрый переход
В Instagram✴ теперь можно настраивать алгоритмы Reels под свои предпочтения
11.12.2025 [13:25],
Владимир Мироненко
Instagram✴✴ добавила в Reels новый инструмент «Ваш алгоритм» на базе ИИ, позволяющий пользователям контролировать темы, которые рекомендует к просмотру алгоритм и настраивать рекомендации в соответствии с их интересами. 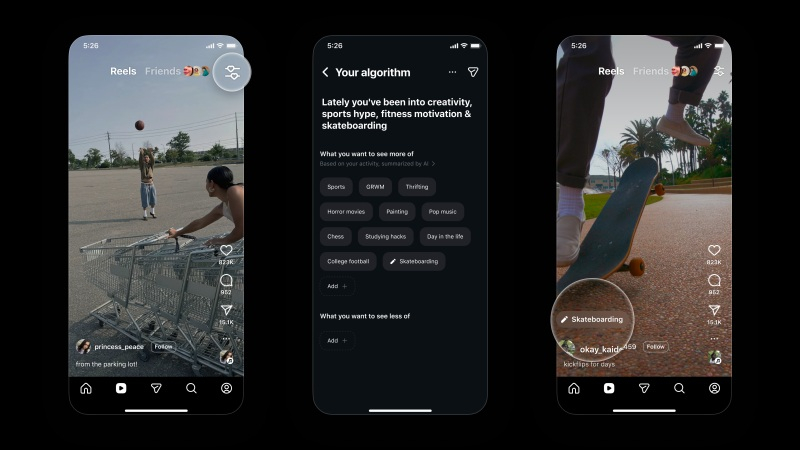
Источник изображения: TechCrunch «По мере того, как ваши интересы меняются со временем, мы хотим предоставить вам более эффективные способы контролировать то, что вы видите, — сообщается в блоге Instagram✴✴. — Используя ИИ, вы теперь можете проще просматривать и персонализировать темы, которые формируют ваши Reels, делая рекомендации ещё более индивидуальными для вас». Соцсеть пообещала вскоре добавить эту возможность в раздел «Исследовать» и другие разделы приложения. Для настройки алгоритма Reels необходимо коснуться значка в правом верхнем углу (две линии с сердечками). После этого откроется раздел «Ваш алгоритм», где отображаются темы, которые, по мнению Instagram✴✴, интересуют пользователя. Здесь можно указать, какие из них хотелось бы видеть чаще или реже, и в дальнейшем алгоритм будет следовать этим рекомендациям. При желании пользователь может поделиться своими интересами в своей «Истории», чтобы друзья и подписчики могли видеть, чем он увлекается. На данный момент новая функция «Ваш алгоритм» в Reels доступна только для пользователей в США, но в дальнейшем к ней получат доступ пользователи из других регионов. Аналогичная функция под названием «Управление темами» есть в TikTok. С её помощью они могут лучше контролировать то, что видят в ленте «Для вас». IBM заставила алгоритм коррекции ошибок квантовых компьютеров работать на обычных чипах AMD
24.10.2025 [19:57],
Сергей Сурабекянц
Сегодня компания IBM сообщила о реальной возможности запуска ключевого алгоритма коррекции ошибок квантовых вычислений на общедоступных чипах производства компании Advanced Micro Devices. Это открытие может существенно приблизить начало коммерческого использования квантовых вычислений. 
Источник изображения: IBM Квантовые компьютеры используют так называемые кубиты для решения специфических задач, например, расчёта взаимодействия триллионов атомов на протяжении больших временных промежутков. На поиск ответа обычным компьютерам потребовались бы тысячи лет. Однако квантовые вычисления подвержены ошибкам и влиянию шума, которые могут быстро свести на нет вычислительную мощность квантового чипа. В июне IBM заявила, что разработала алгоритм для работы с квантовыми чипами, способный устранять подобные ошибки. В исследовательской работе, которая должна быть опубликована 27 октября, компания продемонстрирует его запуск в реальном времени на чипе AMD типа Valve Array («программируемая вентильная матрица»). 
Источник изображения: AMD По словам директора по исследованиям IBM Джей Гамбетта (Jay Gambetta), исследование доказало, что новый алгоритм IBM для коррекции ошибок квантовых вычислений не только работает в реальном мире, но и запускается на существующем чипе AMD, который «смехотворно дёшев». Он также подчеркнул, что «внедрение алгоритма и демонстрация того, что он действительно в 10 раз быстрее, чем требуется, — это большая задача», которая была завершена на год раньше запланированного. IBM стремится завершить работы по созданию полноценного квантового компьютера Starling к 2029 году. 
Источник изображения: IBM Российские учёные усовершенствовали MP3
12.07.2025 [12:58],
Павел Котов
Российские учёные из Московского технического университета связи и информатики (МТУСИ) усовершенствовали алгоритм сжатия звука MP3 — его новый вариант позволяет уменьшить размер файлов на 20 % при сохранении того же качества звука, что и в классическом варианте формата, пишут «Известия». 
Источник изображения: Ciocan Ciprian / unsplash.com «Формат MP3, несмотря на популярность, имеет недостатки. Например, при оцифровке аналогового сигнала (импульсно-кодовой модуляции, ИКМ) в цифровой на скорости 250–270 Кбит/с теряются нюансы, так называемые атаки, которые определяют насыщенность звука и его разборчивость», — цитирует издание заявление пресс-службы МТУСИ. Улучшение качества звука по сравнению с обычным сжатием MP3 у нового формата заметно уже при 56 кбит/с, что подтверждается опросами людей и объективными измерениями. Эксперты также запатентовали алгоритм «не искажающего компандирования» — эффективного сжатия, которое не сопровождается искажениями и шумами. «Метод сжимает динамический диапазон до 10–15 дБ, но звук передаётся без искажений. А качество даже при использовании 16-битного формата сравнимо с 32-битным входным сигналом, то есть негативные стороны 16 бит снижены», — отметили также в пресс-службе вуза. Проблема традиционных форматов сжатия звука состоит в том, что они исключают из аудиокартины некоторые нюансы, и в первую очередь тихие звуки; доходит до потери половины данных, указывают опрошенные «Известиями» эксперты. Искажения проявляются в появлении шумов, «металлического» оттенка и смазанности; в диапазоне от 56 до 128 Кбит/с пропадают детали, и звук становится плоским. Разработка российских учёных окажется полезной при работе в студиях звукозаписи, на потоковых платформах и для устройств с ограниченным объёмом памяти, считают эксперты. Для успешного внедрения технологии потребуется её применение на стриминговых сервисах, хорошем подспорьем станет и общее повышение качества звуковой аппаратуры, хотя и современные смартфоны уже в среднем сегменте способны обеспечить качественное звучание. На практике оптимизированный формат MP3 окажется наиболее полезным при низких битрейтах — это пригодится в онлайн-вещании, подкастинге и киберспорте, где важен чёткий звук при минимальном потреблении трафика. При работе в студии алгоритм будет полезным в сжатии «многодорожных фонограмм без потери субъективного качества». Проект особенно актуален с учётом роста потребления медиаконтента и потребности оптимизировать инфраструктуру хранения данных. Британский стартап объявил о разработке революционного алгоритма сжатия данных
04.07.2025 [17:46],
Павел Котов
Британский стартап утверждает, что добился прорыва в задаче сжатия данных без потерь — алгоритм CompressionX, по словам создателей, помогает уменьшить занимаемое файлом дисковое пространство на величину до 65 %. 
Источник изображения: compressionx.co.uk Технология CompressionX рекламируется как альтернатива лучшим средствам сжатия данных на рынке, как экологически дружественный и удобный для бизнеса инструмент. Он работает иначе по сравнению с традиционными средствами, потому что в его основе лежит «умный, адаптивный алгоритм», а не общая процедура сжатия — он более разумно анализирует структуру файлов. К 2030 году центры обработки данных, если верить прогнозам, могут стать источниками 8 % мировых углеродных выбросов, и задуматься об оптимизации следует уже сегодня. Создатели технологии перечисляют несколько функций, призванных выделить CompressionX, в том числе архивирование в соответствии с требованиями европейского «Общего регламента по защите данных» (GDPR), поддержка шифрования XChaCha20, а также совместимость с форматами ZIP и 7Z. Разработчики указывают, что алгоритм может оказаться полезным для тех, кто пользуется популярными облачными хранилищами — он помогает экономить место и облегчает перемещение больших файлов. Есть, впрочем, у CompressionX и недостаток. В бесплатном режиме доступны только основные функции алгоритма и сжатие до 25 Гбайт данных в месяц. Неограниченные возможности и доступ для бизнес-клиентов обойдутся в £3,99 ($5,43) в месяц на одного пользователя, причём плата вносится за год вперёд. ЕС потребовал от соцсети X раскрыть алгоритм рекомендаций и политику модерирования
17.01.2025 [18:52],
Сергей Сурабекянц
В рамках начатого сегодня расследования, Еврокомиссия потребовала от соцсети X предоставить внутренние документы, касающиеся алгоритма рекомендаций платформы. Комиссия также издала «приказ о хранении» всех относящихся к делу документов, для контроля за возможным изменением алгоритма в будущем. Действия Еврокомиссии стали ответом на многочисленные жалобы на платформу со стороны немецких политиков в преддверии выборов в следующем месяце  В поступивших в Еврокомиссию жалобах утверждается, что алгоритм рекомендаций социальной сети X активно продвигает контент немецких ультраправых партий в преддверии выборов, которые запланированы в Германии на 23 февраля. Оправданность этих обвинений косвенно подтверждается заявлением Илона Маска (Elon Musk) в поддержку националистической партии «Альтернатива для Германии», в котором он утверждает, что эта партия «спасёт Германию». На вопрос о том, не инициировано ли расширенное расследование Еврокомиссии спорным интервью Маска, представитель регулятора сообщил, что новый запрос помог «контролировать системы вокруг всех этих происходящих событий». Однако он подчеркнул, что расследование «полностью независимо от каких-либо политических соображений или каких-либо конкретных событий». «Мы стремимся к тому, чтобы каждая платформа, работающая в ЕС, уважала наше законодательство, которое направлено на то, чтобы сделать онлайн-среду справедливой, безопасной и демократичной для всех граждан Европы», — заявила руководитель цифрового направления Еврокомиссии Хенна Вирккунен (Henna Virkkunen). По сообщениям из осведомлённых источников, регулятор ЕС также запросил у соцсети X доступ к внутренним правилам модерации и алгоритмам продвижения контента. Instagram✴ тестирует полное обнуление ленты рекомендаций — для тех, кто хочет начать с чистого листа
19.11.2024 [17:15],
Анжелла Марина
Instagram✴✴ анонсировал тестирование функции сброса системы рекомендаций. Нововведение предназначено для тех, кто устал от старых рекомендаций и хочет начать всё с чистого листа, позволив алгоритму заново изучить предпочтения и сформировать для показа другой контент. 
Источник изображения: Julio Lopez/Unsplash Как пишет TechCrunch, новая функция предназначена для пользователей, которые считают, что рекомендации контента больше не соответствуют их интересам. Например, возможно, раньше кому-то нравились видеоролики с кулинарными рецептами, но затем интересы изменились, однако алгоритм продолжает рекомендовать этот контент в Reels и ленте «Интересное». После сброса в Instagram✴✴ рекомендаций персонализация контента начнёт формироваться заново на основе взаимодействия с публикациями и аккаунтами. Также при сбросе будет предложена опция просмотра списка аккаунтов, на которые пользователь подписан, чтобы отписаться от блогеров, контент которых больше не интересен. Примечательно, что нововведение похоже на функцию, которую TikTok запустил в прошлом году, позволяющую пользователям сбрасывать ленту рекомендаций «Для вас». Глава Instagram✴✴ Адам Моссери (Adam Mosseri) в своём видеообращении отметил, что новую функцию не следует использовать слишком часто, поскольку она предназначена только для случаев, когда требуется действительно полное обновление. «Хочу прояснить этот серьёзный шаг, — сказал Моссери. — Сначала ваш Instagram✴✴ станет достаточно не интересным, потому что мы будем относиться к вам так, как будто ничего не знаем о ваших интересах, и нам потребуется некоторое время, чтобы снова их изучить. Поэтому я не рекомендую делать это постоянно, но если вы окажетесь в ситуации, когда вам действительно захочется начать всё с чистого листа, это даст вам реальный выход из положения». Стоит отметить, что новая функция дополняет уже существующие инструменты Instagram✴✴, позволяющие отслеживать и редактировать личные рекомендации, выбирать в публикациях «Интересно» или «Не интересно», чтобы «проинформировать» алгоритм о своих предпочтениях, а также скрывать контент с определёнными словами или фразами, используя функцию «Скрытые слова». По заявлению компании, функция будет развёрнута по всему миру в ближайшее время. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



