|
Опрос
|
реклама
Быстрый переход
ByteDance представила Seedream 5.0 Pro — флагманскую ИИ-модель для генерации и редактирования изображений
11.07.2026 [07:31],
Владимир Фетисов
ByteDance выпустила Seedream5.0 Pro —мультимодальную языковую модель для генерации изображений, предназначенную для выполнения функций производственного дизайна. Алгоритм ориентирован на создателей контента, дизайнеров, маркетологов и других людей, которым требуются насыщенные визуальные макеты, локализованный текст, функции точного редактирования и возможность многократного использования шаблонов, созданных на основе текстовых запросов. 
Источник изображения: testingcatalog.com В Seedream 5.0 Pro разработчики реализовали несколько ключевых улучшений, включая возможность визуализации сложной инфографики, функции точного редактирования, генерацию реалистичных изображений и текстур портретов, а также поддержку ввода и генерации текста на разных языках. По данным ByteDance, алгоритм способен превращать данные, концепции и длинные тексты в профессиональные макеты, генерировать инфографику, изображения, UI-макеты, визуальные материалы для обучения и структурированные активы для коммерческого использования. По сравнению с предыдущими версиями ИИ-модели, новинка отличается более высоким уровнем согласованности между вводимым пользователем запросом и результатом генерации, улучшенной структурной целостностью и визуальной эстетикой. Seedream 5.0 Pro поддерживает функцию выделения отдельных областей изображения с помощью точки или лассо для редактирования без повторной генерации всего кадра. Перекрытые объектом редактирования участки генерируются автоматически. При необходимости изображение можно разделить на отдельно редактируемые слои, такие как основной объект, фон, текст и декоративные элементы. ИИ-модель обеспечивает генерацию изображений фотореалистичного качества за счёт проработки освещения в кадре, текстуры кожи на портретах, добавления физически достоверных отражений и других эффектов. Алгоритм может обрабатывать запросы и создавать изображения с текстом на более чем 10 языках, включая русский, английский, китайский, немецкий, арабский и др. На данном этапе модель Seedream 5.0 Pro доступна для тестирования через API BytePlus. Meta✴ представила Muse Image — свою первую серьёзную модель для генерации изображений, которая будет доступна Meta✴ AI и соцсетях
08.07.2026 [09:41],
Павел Котов
Meta✴✴ выпустила первую генерирующую изображения модель искусственного интеллекта, разработанную сформированным в прошлом году подразделением Superintelligence Labs. Muse Image интегрирована в графические редакторы приложений Meta✴✴ AI, Instagram✴✴ и WhatsApp; скоро она появится в Facebook✴✴ и Facebook✴✴ Messenger. 
Источник изображения: Meta✴✴ Модель стала новым членом семейства Muse, пришедшего на смену Llama. Muse Image располагает агентными функциями — она подключается к большой языковой модели Muse Spark, «чтобы проанализировать ваш запрос, выполнить поиск в интернете и спланировать работу до генерации», пояснил глава Superintelligence Labs Александр Ван (Alexandr Wang). Он также пообещал, что скоро компания выпустит модель Muse Video — она «конкурентоспособна по соответствию запросам, визуальной точности и временно́й согласованности». В запросах к Muse Image можно упоминать аккаунты других пользователей Instagram✴✴, чтобы включать фото с их страниц в свои работы. Такого рода редактирование и генерация смогут работать только с общедоступными материалами; при этом пользователи смогут контролировать, как другие используют их контент при работе с ИИ. По запросам доступно редактирование изображений, а также создание дизайна приглашений и открыток. Ещё одна функция — создание нового дизайна для объектов недвижимости на платформе Facebook✴✴ Marketplace. Muse Image будет использоваться для 30 новых ИИ-эффектов при публикации в разделе Instagram✴✴ Stories для пользователей в США — впоследствии функция будет доступна и в других странах, а также в других разделах приложений Meta✴✴. Уход Sora открыл дорогу конкурентам: ИИ-генераторы видео Kling AI и AI Video ворвались в топы Apple App Store
13.05.2026 [18:53],
Дмитрий Федоров
Два приложения для создания видео с помощью ИИ — Kling AI и AI Video — поднялись на пятое и шестое места в рейтинге самых скачиваемых бесплатных приложений Apple App Store. Оба лидируют в своих категориях: Kling AI заняло первую строчку в «Графике и дизайне», AI Video — в «Фото и видео». Их рост начался спустя два месяца после закрытия видеосервиса Sora компании OpenAI. Оба приложения выигрывают от нового всплеска внимания пользователей iPhone к ИИ-генерации видео. 
Источник изображений: apps.apple.com OpenAI свернула Sora главным образом из-за стоимости обслуживания: бесплатный сервис потреблял слишком много ресурсов. Компания сосредоточилась на ChatGPT и Codex — инструментах для повышения продуктивности, причём Codex лучше раскрывается на платных тарифах. 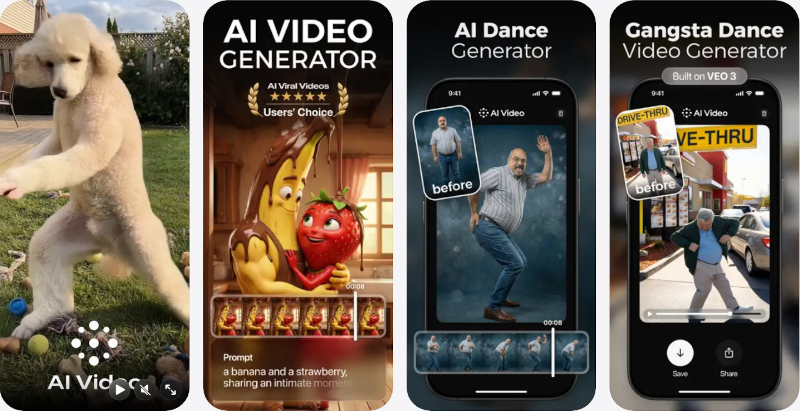
AI Video - AI Video Generator После ухода Sora конкурирующие ИИ-приложения стали активнее продвигать генерацию видео. Gemini и Grok уже позволяют превращать текстовые запросы и изображения в ролики, однако для этих универсальных чат-ботов видео остаётся лишь одной из возможностей. 
Kling AI: AI Image&Video Maker Kling AI и AI Video целиком посвящены созданию роликов. Kling AI появилось в App Store три месяца назад. AI Video выпущено компанией HUBX, у которой в магазине размещено 15 ИИ-приложений. Новое приложение нацелено на создание вирусных видеороликов. Выше обоих в рейтинге стоят только продукты OpenAI, Anthropic, Google и Meta✴✴. Sora тоже возглавляла чарт при запуске, но через несколько месяцев перестала показывать заметные результаты. Генераторы изображений стали главным драйвером роста ИИ-чат-ботов
05.05.2026 [11:50],
Павел Котов
Выпуск моделей с генераторами изображений стимулирует увеличение популярности мобильных приложений с искусственным интеллектом — рост по сравнению с простыми обновлениями ускоряется в 6,5 раза, показала статистика аналитической компании Appfigures. 
Источник изображения: Milad Fakurian / unsplash.com Для OpenAI ChatGPT и Google Gemini появление генераторов изображений увеличивало аудиторию на десятки миллионов пользователей. В течение 28 дней после выхода генератора изображений Nano Banana с чат-ботом Gemini 2.5 Flash приложение набрало 22 млн новых пользователей, что соответствует росту числа загрузок более чем вчетверо за указанный период. 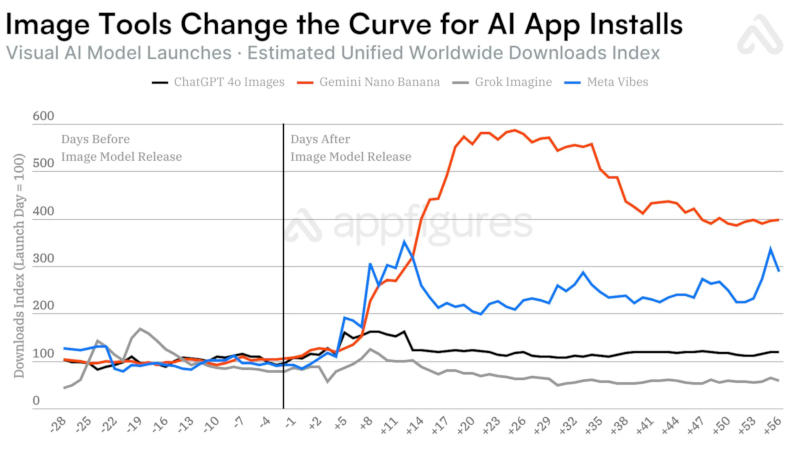 В случае генератора изображений в составе OpenAI GPT-4o рост аудитории составил 12 млн человек — в 4,5 раза быстрее по сравнению с базовым вариантом GPT-4o, а также GPT-4.5 и GPT-5. Аналогичная тенденция сработала и с появлением ленты Vibes в приложении Meta✴✴ AI, хотя оно предлагало генерацию не изображений, а видео — нововведение дало 2,6 млн дополнительных загрузок. 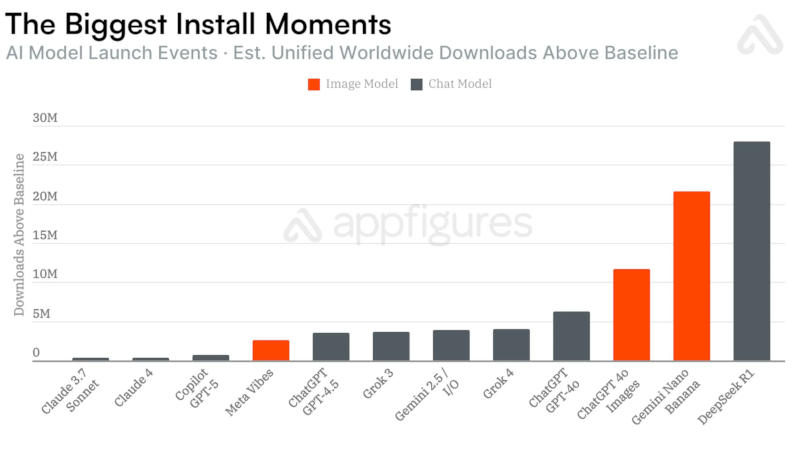 К сожалению для разработчиков, росту числа загрузок не всегда сопутствует рост выручки: в случае с Nano Banana компания Google заработала лишь на $181 тыс. больше; приложение Meta✴✴ AI с появлением Vibes существенного роста дохода не показало; и только в случае OpenAI модель GPT-4o с генератором изображения помогла компании нарастить выручку на $70 млн за 28 дней. 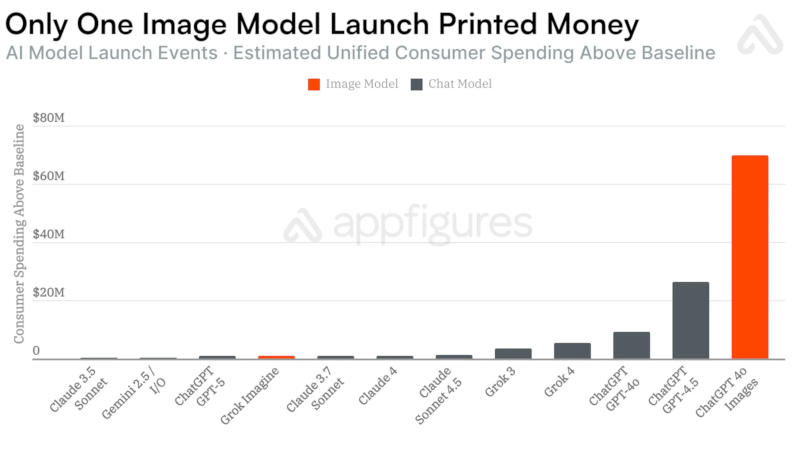 Единственным исключением из правил оказался взрывной рост в 28 млн загрузок с выходом модели DeepSeek R1, отметили в Appfigures. Всё потому, объясняют аналитики, что компания DeepSeek сама по себе стала мировой сенсацией из-за уникальных методов обучения ИИ с минимальными затратами по сравнению с конкурентами — генератора изображений в приложении не было. Microsoft представила облегчённый ИИ-генератор изображений MAI-Image-2-Efficient
15.04.2026 [14:50],
Павел Котов
Microsoft анонсировала обновлённую версию модели искусственного интеллекта, которая генерирует изображения по текстовым запросам, — она получила название MAI-Image-2-Efficient. Она и её предшественница MAI-Image-2 генерируют качественные фотореалистичные картинки, при этом новая работает на 22 % быстрее и вчетверо эффективнее. 
Источник изображения: BoliviaInteligente / unsplash.com В марте Microsoft запустила на платформах Copilot, Bing Image Creator и MAI Playground генератор изображений MAI-Image-2, который занял в рейтинге Arena.ai третье место среди себе подобных. Недавно компания расширила доступ к ней, добавив её на платформу Foundry наряду с MAI-Voice-1 и MAI-Transcribe-1. Обновлённая MAI-Image-2-Efficient создана для случаев, когда необходимо нечто быстрое, масштабируемое и не влекущие неоправданных расходов ресурсов. Если не требуется высокая точность изображений, MAI-Image-2-Efficient оказывается оптимальным вариантом — она пригодится для генерации иллюстраций в соцсетях, создания макетов-заглушек и миниатюр продуктов; то есть в тех случаях, когда скорость и объём контента важнее пиксельной точности. Microsoft MAI-Image-2, напротив, проявляет себя во всей красе, когда востребован, например, качественный портрет героя, кинематографическая сцена и внимание к деталям, а аспект скорости отходит на второй план. Обновлённая MAI-Image-2-Efficient по ряду параметров превосходит не только предшественницу от самой Microsoft, но также работает на 40 % быстрее таких систем как Google Gemini 3.1 Flash, Gemini 3.1 Flash Image и Gemini 3 Pro Image. Разработчики уже могут подключать MAI-Image-2-Efficient на платформах Microsoft Foundry и MAI Playground. Стоимость её работы составляет $5 за 1 млн входящих и $19,50 за 1 млн выходящих токенов — для сравнения, стоимость использования MAI-Image-2 составляет $5 и $33 соответственно. Скоро MAI-Image-2-Efficient появится в Copilot, Bing и на других платформах. Microsoft представила MAI-Image-2 — ИИ-генератор изображений, который оказался неожиданно хорош в фотореализме и инфографике
21.03.2026 [12:07],
Владимир Фетисов
В октябре прошлого года Microsoft представила ИИ-модель для генерации изображений MAI-Image-1, которая заняла девятое место рейтинга на платформе Arena.ai. Теперь же софтверный гигант объявил о запуске алгоритма второго поколения MAI-Image-2, способного создавать изображения с более естественным освещением, точной передачей тонов кожи и реалистичными деталями. Эта версия ИИ-модели поднялась на третью строчку рейтинга Arena.ai. 
Источник изображения: microsoft.ai Microsoft существенно улучшила возможности модели в плане корректного отображения текста на генерируемых изображениях. За счёт этого алгоритм лучше подходит для создания инфографики, слайдов, диаграмм и др. Microsoft заявила, что MAI-Image-2 лучше справляется с генерацией кинематографичных и гипердетализированных изображений, включая сюрреалистические концепции, замысловатые композиции и фантастические миры. «Вышел наш новый генератор изображений MAI-Image-2! Он уже доступен на MAI Playground для создания всего: от фотореализма до детализированной инфографики. Наша команда приложила невероятные усилия для этого релиза», — написал в соцсети X глава ИИ-подразделения Microsoft Мустафа Сулейман (Mustafa Suleyman). В рейтинге на платформе Arena.ai MAI-Image-2 занимает третье место. Лидерами остаются алгоритмы Google gemini-3.1-flash-image-preview и OpenAI gpt-image-1.5-high-fidelity. Пользователи Copilot и Bing Image Creator смогут задействовать модель MAI-Image-2 в ближайшее время. В настоящее время алгоритм доступен через платформу MAI Playground, а разработчик могут получить доступ к модели через соответствующий API на Microsoft Foundry. ИИ-генератор изображений Adobe Firefly теперь можно обучать на своих работах
19.03.2026 [18:18],
Владимир Фетисов
Adobe объявила о запуске настраиваемых ИИ-генераторов изображений, которые могут имитировать определённые художественные стили и дизайны персонажей. Модели Firefly Custom Models стали доступны в рамках публичного бета-тестирования, благодаря чему творческие люди и компании могут обучить ИИ-модели на собственных работах. За счёт этого генерируемые изображения будут соответствовать единой эстетике персонажей, иллюстраций и фотографий. 
Источник изображения: Adobe Ожидается, что такой подход позволит оптимизировать рабочие процессы создателей контента, которым требуется выполнять большие объёмы работ, за счёт сохранения визуальной согласованности в разных проектах, вместо того, чтобы каждый раз начинать всё с нуля. По данным Adobe, пользовательские ИИ-модели позволят сохранять разные детали, такие как толщина штрихов, цветовые гаммы, освещение и черты персонажей при генерации новых изображений. По умолчанию пользовательские модели являются частными, поэтому используемые для их обучения материалы не будут применяться для обучения общих языковых моделей Adobe Firefly. «Чтобы развивать бренд, вам нужен постоянный поток материалов, которые будут последовательно выражать вашу сущность. Эти материалы должны быть вашими и только вашими. После обучения ваша пользовательская модель становится частью вашего рабочего процесса. Вы можете генерировать новые идеи, соответствующие вашей эстетике, повторно использовать модель в разных проектах, брифингах и кампаниях, а также создавать контент в масштабе, не теряя того, что отличает вашу работу», — говорится в пресс-релизе Adobe. Учёные придумали термодинамический компьютер, который генерирует изображения в 10 млрд раз энергоэффективнее ИИ
28.01.2026 [15:43],
Павел Котов
Американские учёные предложили использовать в генераторах изображений на основе искусственного интеллекта технологию термодинамических вычислений — она позволяет сократить энергетические затраты на некоторые операции на величину до 10 млрд раз. 
Источник изображения: Steve Johnson / unsplash.com Модели генеративного ИИ, в том числе DALL-E, Midjourney и Stable Diffusion, создают фотореалистичные изображения, но потребляют при этом огромное количество энергии. Это диффузионные модели. При обучении им подают большие наборы изображений, к которым постепенно добавляют шум, пока картинка не станет похожей на помехи в старом телевизоре. Далее нейросеть овладевает обратным процессом и генерирует новые изображения по запросу. Проблема в том, что вычисления для алгоритмов ИИ с добавлением и последующим удалением шума потребляют слишком много энергии — термодинамические вычисления позволяют сократить их несоразмерно возможностям современного цифрового оборудования. При термодинамических вычислениях используются физические схемы, которые меняют параметры в ответ на шум, например вызванный случайными тепловыми перепадами в окружающей среде. Стартап Normal Computing построил чип на основе восьми соединённых друг с другом резонаторов — соединители подключаются сообразно типу решаемой чипом задачи. Далее резонаторы подвергаются воздействию внешней среды, вносят шум в цепь и таким образом выполняют вычисления. После того как система достигает состояния равновесия, решение считывается из новой конфигурации резонаторов. Учёные показали, что можно построить термодинамическую версию нейросети. Эта методика закладывает основу для генерации изображений с помощью термодинамических вычислений. В термодинамический компьютер вводится набор изображений, далее компоненты компьютера подвергаются естественным воздействиям среды до тех пор, пока связи, соединяющие эти компоненты, не достигают состояния равновесия. Далее вычисляется вероятность того, что термодинамический компьютер с заданным состоянием связей сможет обратить этот процесс, и значения этих связей корректируются, чтобы повысить эту вероятность до максимальной. Симуляции подтвердили, что можно построить термодинамический компьютер, настройки которого помогут генерировать изображения рукописных цифр. Это достигается без энергоёмких цифровых нейросетей или создающего шум генератора псевдослучайных чисел. По сравнению с цифровыми нейросетями термодинамические компьютеры пока примитивны, признают учёные, и как проектировать их для работы на уровне DALL-E, они пока не знают. Но в аспекте энергоэффективности они обещают значительное преимущество. ИИ-бот Grok «раздевает» по 190 людей в минуту — за 11 дней создано 3 млн дипфейков, в том числе с детьми
23.01.2026 [08:23],
Владимир Фетисов
Ранее уже сообщалось о том, что ИИ-бот Grok компании xAI буквально забрасывал соцсеть X дипфейками сексуального характера, сгенерированными без согласия пользователей. Теперь же стали известны конкретные цифры, позволяющие оценить масштаб проблемы. 
Источник изображения: Engadget По данным Engadget, за 11 дней Grok сгенерировал около 3 млн дипфейков сексуального характера, причём около 23 тыс. из них содержали изображения несовершеннолетних. Иначе говоря, в течение 11 дней Grok генерировал примерно 190 фейковых изображений сексуального характера в минуту. На этой неделе британская некоммерческая организация Центр по борьбе с цифровой ненавистью (CCDH) опубликовала свои выводы по данному вопросу, основанные на случайной выборке из 20 тыс. сгенерированных с помощью Grok изображений в период с 29 декабря по 9 января. Специалисты организации также экстраполировали полученные данные для более масштабной оценки, основанной на 4,6 млн изображений, созданных Grok за указанный период. В рамках исследования дипфейки сексуального характера определялись как «фотореалистичные изображения человека в сексуальных позах, ракурсах или ситуациях; человека в нижнем белье, купальнике или аналогичной открытой одежде» и др. Исследование CCDH не учитывало текстовые промпты, поэтому в полученных результатах нет разделения относительно количества дипфейков, созданных на основе реальных фото и сгенерированных только по текстовым описаниям. Для определения доли изображений сексуального характера в выборке использовался ИИ-алгоритм. xAI ограничила возможность редактирования реальных фото с помощью Grok для бесплатных пользователей X в начале 9 января. Однако это не решило проблему, а лишь превратило её в премиум-функцию. Спустя несколько дней, 14 января, X полностью ограничила возможность Grok «раздевать» людей на реальных изображениях. При этом данное ограничение действовало только в самой соцсети и не распространялось на отдельное приложение Grok. По данным источника, приложение всё ещё позволяет создавать дипфейки сексуального характера. Поскольку оно распространяется через магазины Google и Apple, политика которых явно запрещает подобный контент, можно было ожидать удаления приложения с этих платформ, но этого не произошло. При этом другие подобные ИИ-генераторы для «раздевания» людей прежде оперативно удалялись из магазинов Apple и Google. Цукерберг готовит Mango и Avocado: Meta✴ раскрыла имена грядущих ИИ-моделей, включая генератор изображений и видео
19.12.2025 [13:33],
Алексей Разин
В первой половине следующего года, как сообщает The Wall Street Journal, компания Meta✴✴ Platforms порадует своих пользователей выходом новых ИИ-моделей. Основанная на текстовом вводе система получила обозначение Avocado, а ориентированная на генерацию изображений и видео будет называться Mango. В этом признался руководитель направления ИИ Александр Ван (Alexandr Wang) в ходе одного из служебных мероприятий. 
Источник изображения: OpenAI Одним из приоритетов при разработке текстовой модели Avocado стало улучшение возможностей в сфере написания программного кода с её помощью. Кроме того, Meta✴✴ находится на ранней стадии экспериментов с так называемыми моделями мира, позволяющими обучаться через визуальное восприятие окружающей обстановки. Как напоминает The Wall Street Journal, летом этого года Meta✴✴ провела реструктуризацию своей команды, занимающейся ИИ, в результате чего подразделение Meta✴✴ Superintelligence Labs возглавил Александр Ван. Основатель и глава Meta✴✴ Platforms Марк Цукерберг (Mark Zuckerberg) активно принимал участие в переманивании ценных специалистов из OpenAI, коих набралось более 20 человек, а в целом ему удалось собрать команду профессионалов в области ИИ из более чем 50 исследователей и инженеров. В сентябре Meta✴✴ выпустила приложение Vibes для генерации видео, которое было разработано в сотрудничестве с Midjourney. Менее чем через неделю после этого OpenAI представила собственный генератор видео Sora. Появление в арсенале Google подобного приложения Nano Banana позволило увеличить месячную аудиторию Gemini с 450 до 650 млн человек всего за три месяца. Острая конкуренция на этом рынке заставила главу OpenAI Сэма Альтмана (Sam Altman) мобилизовать все силы на совершенствовании ChatGPT. Недавно стартап представил приложение Images 1.5 для генерации изображений. По мнению Альтмана, именно инструменты для генерации изображений являются «якорными» для привлечения пользователей и поддержания интереса к сфере ИИ. OpenAI урезала лимиты на генерацию контента с помощью Sora — Google так же поступила с Nano Banana Pro
28.11.2025 [21:06],
Владимир Фетисов
Пользователям, которые хотели немного развлечься, генерируя медиаконтент с помощью передовых моделей искусственного интеллекта Google и OpenAI, придётся быть более экономными. Обе компании снизили лимиты на количество запросов к алгоритмам Nano Banana Pro и Sora, сославшись на огромный спрос и существенно возросшую нагрузку на сопутствующую инфраструктуру. 
Источник изображения: Steve Johnson / Unsplash Глава подразделения разработчиков ИИ-генератора Sora в OpenAI Билл Пиблс (Bill Peebles) объявил, что пользователи, взаимодействующие с нейросетью бесплатно, теперь смогут создавать не более шести видео в день. «Наши графические ускорители плавятся», — добавил он. Любопытно, что в отличие от предыдущих ограничений, Пиблс не упомянул, что снижение лимитов на бесплатную генерацию видео носит временный характер. Однако он отметил, что пользователи будут иметь возможность платного расширения лимита в случае такой необходимости. Вероятно, продиктованный возросшей нагрузкой шаг также является частью более широкой стратегии OpenAI по монетизации ИИ-генератора видео Sora. При этом лимиты для подписчиков ChatGPT Plus и ChatGPT Pro не изменились. Параллельно с этим Google ограничила бесплатных пользователей платформы Nano Banana Pro возможностью генерировать всего два изображения в день. Ранее сервис позволял создавать бесплатно ежедневно до трёх картинок. Компания предупредила пользователей, что лимиты могут часто меняться даже «без предварительного уведомления», что является стандартной практикой для популярных платформ. Вместе с этим Google, по всей видимости, ограничивает бесплатный доступ к передовой ИИ-модели Gemini 3 Pro. Black Forest Labs представила ИИ-генератор изображений FLUX.2 с оптимизацией для видеокарт GeForce RTX
26.11.2025 [00:00],
Николай Хижняк
Компания Black Forest Labs, занимающаяся разработкой генеративных нейросетей, представила новое семейство моделей генерации изображений по текстовому описанию — FLUX.2. Программное обеспечение предлагает новые инструменты и возможности, включая функцию многореференсных изображений, которая позволяет генерировать десятки похожих вариантов с фотореалистичной детализацией и более чёткими шрифтами — даже в больших масштабах. 
Источник изображения: Nvidia Как сообщает блог компании Nvidia, разработка FLUX.2 велась при её участии, а также с привлечением разработчиков среды ComfyUI для работы с генеративными ИИ-моделями. Благодаря этому семейство FLUX.2 поддерживает квантование в формате FP8 и оптимизировано для работы на графических процессорах RTX, что позволяет сократить объём необходимой видеопамяти на 40 % и одновременно повысить производительность на 40 %. 
Источник изображения: Nvidia Модели не требуют специального программного обеспечения и доступны непосредственно в среде ComfyUI. Изображения, генерируемые FLUX.2, отличаются фотореалистичностью даже в высоком разрешении, достигающем 4 мегапикселей, реалистичным освещением и физикой. Как отмечает Nvidia, модели не создают «эффекта искусственного интеллекта, снижающего визуальную точность». 
Источник изображения: Black Forest Labs Модели позволяют напрямую задать позу объекта или персонажа на изображении, а также обеспечивают чёткий, читаемый текст для инфографики, экранов пользовательского интерфейса и даже многоязычного контента. Кроме того, новая функция нескольких референсов позволяет художникам выбирать до шести референсных изображений, где стиль или тема остаются неизменными, устраняя необходимость в обширной тонкой настройке модели. 
Источник изображения: Black Forest Labs Модели позволяют напрямую задать позу объекта или персонажа на изображении, а также обеспечивают чёткий, читаемый текст — как для инфографики и экранов пользовательского интерфейса, так и для многоязычного контента. Кроме того, новая функция мульти-референсов позволяет художникам выбирать до шести образцов, по которым сохраняется стиль или тема, устраняя необходимость в глубокой ручной настройке модели. Источник изображения: Black Forest Labs Чтобы расширить доступность FLUX.2, Nvidia и Black Forest Labs совместно работали над квантованием модели до формата FP8, что позволило снизить требования к видеопамяти на 40 % без потери качества. Также Nvidia сотрудничает с разработчиками ComfyUI — популярного приложения для запуска визуальных ИИ-моделей на ПК — над улучшением функции разгрузки памяти, известной как потоковая передача весов (weights streaming). Благодаря этому пользователи могут выгружать части модели в системную память, расширяя тем самым объём доступной видеопамяти, пусть и с некоторым снижением производительности из-за меньшей скорости системной памяти по сравнению с памятью GPU. Для работы с шаблонами FLUX.2 требуется обновление приложения ComfyUI. Также можно посетить страницу Black Forest Labs на Hugging Face, чтобы загрузить веса модели. Microsoft открыла доступ к своему первому ИИ-генератору изображений MAI-Image-1
05.11.2025 [11:25],
Владимир Фетисов
В прошлом месяце Microsoft анонсировала первый генератор изображений на базе искусственного интеллекта собственной разработки. Теперь же софтверный гигант открыл доступ к алгоритму MAI-Image-1 на платформах Bing Image Creator и Copilot Audio Expressions. 
Источник изображения: Microsoft Глава ИИ-подразделения Microsoft Мустафа Сулейман (Mustafa Suleyman) также анонсировал скорое появление ИИ-генератора компании в Евросоюзе. Он добавил, что ИИ-модель «превосходно» справляется с созданием изображений еды и природных пейзажей, а также художественного освещения и фотореалистичных деталей. «MAI-Image-1 генерирует фотореалистичные изображения, в том числе освещение (например, отражённый свет, блики), ландшафты и многое другое. Это особенно заметно в сравнении со многими более крупными и медленными моделями. Комбинация скорости и качества означает, что пользователи могут быстрее воплощать свои идеи на экране, быстро их просматривать, а затем переносить свою работу в другие инструменты для последующей доработки», — говорится в сообщении Microsoft. Алгоритм MAI-Image-1 также будет задействован для создания изображений для сгенерированных ИИ аудиорассказов на платформе преобразования текста в речь Copilot Audio Expressions. Напомним, Microsoft анонсировала первые генеративные ИИ-модели собственной разработки в августе этого года. Тогда были представлены речевая модель MAI-Voice-1 и текстовая MAI-1-preview. Тогда же компания объявила о планах задействовать MAI-1-preview в своём ИИ-помощнике Copilot в определённых сценариях использования. Это может означать, что Microsoft стремиться снизить свою зависимость от ИИ-моделей OpenAI. При этом чат-бот Copilot переходит на использование новейшей ИИ-модели OpenAI GPT-5, одновременно предлагая пользователям в качестве альтернативы задействовать алгоритм Anthropic Claude. ByteDance представила компактную ИИ-модель, которая превратит любое фото в качественную 3D-модель
27.10.2025 [11:42],
Владимир Мироненко
ByteDance, материнская компания TikTok, представила ИИ-инструмент для создания 3D-контента Seed3D 1.0, с помощью которого на основе одного 2D-изображения можно создать полноценную 3D-модель уровня симуляции, с детальной геометрией, фотореалистичными текстурами и физически корректными материалами для рендеринга (PBR), в которых учтены реальные свойства отражения, преломления и рассеивания света. 
Источник изображений: seed.bytedance.com По словам компании, основанный на архитектуре диффузионного преобразователя (Diffusion Transformer, DiT), сочетающей свойства диффузионных моделей и трансформеров, Seed3D 1.0 превосходит конкурентов как с открытым, так и с закрытым исходным кодом по качеству текстур и геометрической точности. Используя всего лишь 1,5 млрд параметров, Seed3D 1.0 превосходит даже более крупные модели, такие как Hunyuan3D 2.1 с 3 млрд параметров. 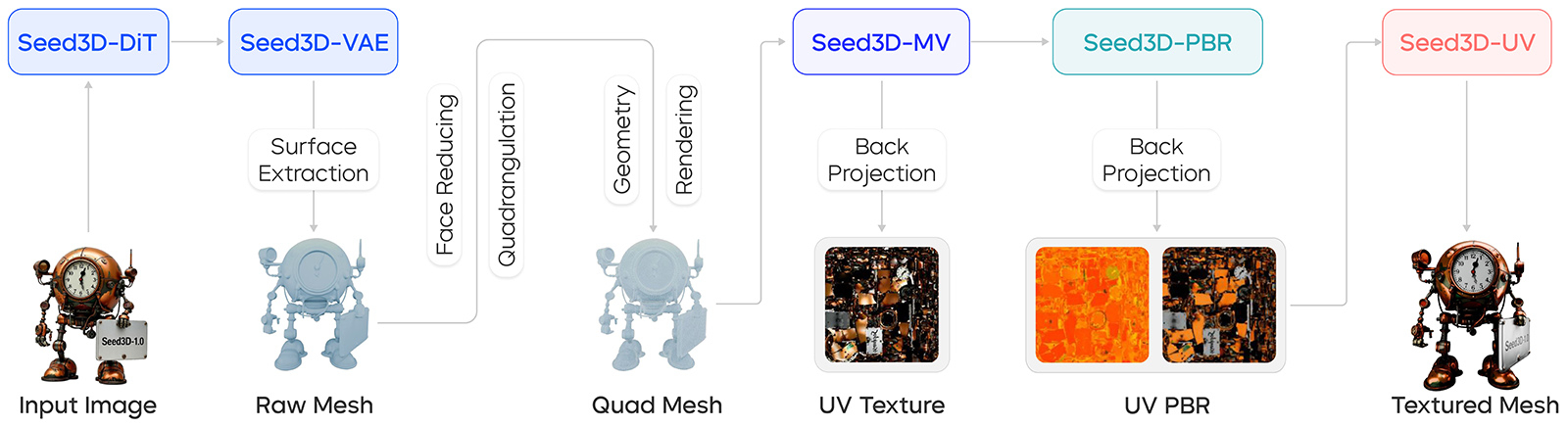 Главная особенность нового ИИ-инструмента заключается в сочетании мультимодального диффузионного преобразователя (Multimodal Diffusion Transformer, MMDiT) и пошаговой стратегии генерации. Сначала система анализирует изображение с помощью визуально-языковой модели (Vision-Language Model, VLM) для извлечения объектных и пространственных параметров. Затем для каждого локализованного объекта Seed3D 1.0 синтезирует соответствующие геометрию и материалы. Финальная сцена собирается путём позиционирования каждого сгенерированного объекта в соответствии с пространственной конфигурацией, предсказанной VLM. Эта структура позволяет генерировать сцены в различных масштабах, от помещений, таких как офисы, до крупномасштабных городских сцен. Сообщается, что Seed3D 1.0 обеспечивает согласованность текстур при различных ракурсах. Вместо применения стандартных текстур ИИ-инструмент создаёт материалы, согласованные по виду, причём со всех ракурсов, обеспечивая как реализм, так и структурную точность для использования на уровне симуляции. Компания отметила, что модели, созданные с помощью Seed3D, можно напрямую интегрировать в платформы моделирования, такие как Isaac Sim, для обучения ИИ. Microsoft представила первый ИИ-генератор изображений собственной разработки — MAI-Image-1
14.10.2025 [11:19],
Владимир Фетисов
Подразделение Microsoft AI, отвечающее за разработки в сфере искусственного интеллекта, анонсировало алгоритм MAI-Image-1 — первый ИИ-генератор изображений по текстовому описанию, полностью созданный внутри компании. Софтверный гигант, не так давно представивший свои первые ИИ-модели, назвал новый генератор изображений «следующим шагом на нашем пути». 
Источник изображения: Microsoft Microsoft заявила, что собирала отзывы профессиональных создателей контента, чтобы избежать «повторяющихся или шаблонно-стилизованных результатов». Компания утверждает, что MAI-Image-1 «превосходно справляется» с созданием фотореалистичных изображений. Кроме того, алгоритм способен обрабатывать запросы и генерировать изображения быстрее, чем «более крупные и медленные модели». MAI-image-1 уже занял место в топ-10 рейтинга бенчмарка LMArena, пользователи которого могут сравнивать результаты работы разных нейросетей и выбирать лучшие из них. Алгоритм MAI-Image-1 присоединился к списку других ИИ-продуктов Microsoft, таким как генератор голоса MAI-Voice-1 и чат-бот MAI-1-preview. Microsoft была одним из первых и крупнейших инвесторов OpenAI, но со временем отношения между компаниями стали всё более сложными. На этом фоне Microsoft начала использовать ИИ-модели Anthropic для обеспечения работоспособности некоторых функций на платформе Microsoft 365, а также делать существенные инвестиции в разработку собственных нейросетей. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



