|
Опрос
|
реклама
Быстрый переход
ИИ-блокнот Google NotebookLM заговорил на русском и ещё более чем 50 языках
29.04.2025 [21:46],
Анжелла Марина
Google объявила о масштабном обновлении ИИ-ассистента NotebookLM. Теперь Audio Overviews или «Аудиопересказы» и ответы бота доступны более чем на 50 языках, включая русский. Ранее функция работала только на английском, но теперь пользователи могут выбирать необходимый язык в настройках, для чего достаточно нажать на значок шестерёнки в правом верхнем углу. 
Источник изображения: Google Новая опция позволяет создавать мультиязычный контент или учебные материалы, поясняет ресурс 9to5Google. Например, преподаватель может загрузить в систему материалы одновременно на португальском, испанском и английском, а ученики — получить аудиопересказ ключевых идей на своём родном языке. 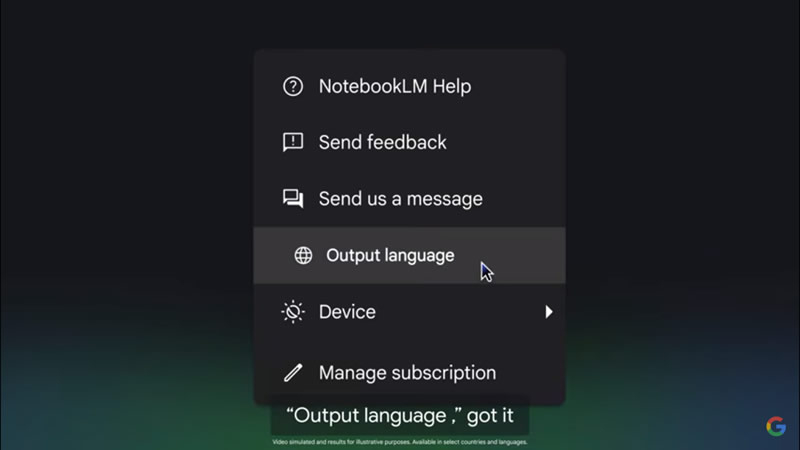
Источник изображения: Google Напомним, NotebookLM Audio Overviews — это функция, доступная в приложении NotebookLM, которое является экспериментальным продуктом от Google на базе искусственного интеллекта. ИИ-блокнот изначально был разработан как инструмент, помогающий анализировать и находить новые идеи на основе загруженных пользователем документов, например, PDF-файлов, заметок и других материалов в текстовом формате. 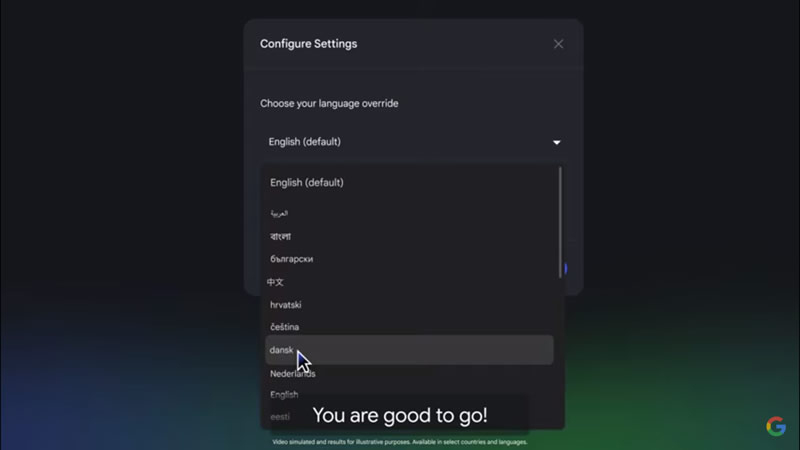
Источник изображения: Google Обновление разрабатывалось с прошлого месяца и теперь доступно для всех пользователей NotebookLM. Ранее функция аудиопересказа была доступна исключительно на английском языке. OpenAI добавила в поиск ChatGPT функцию покупок как у Google, но без рекламы
29.04.2025 [05:10],
Анжелла Марина
Компания OpenAI объявила о значительном обновлении поисковой системы в ChatGPT. Теперь пользователи смогут искать товары и получать персонализированные рекомендации прямо в чате. Новая функция позволяет находить продукты, просматривать их изображения, читать отзывы и переходить по ссылкам в магазины. 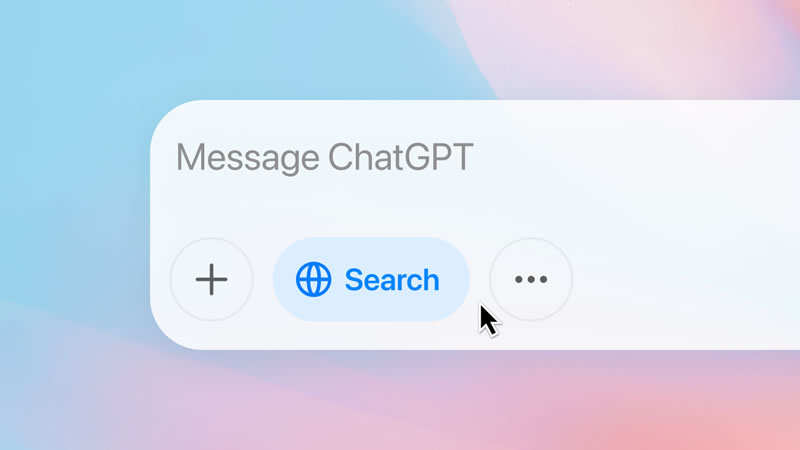
Источник изображения: OpenAI OpenAI заявляет, что пользователи могут задавать «гиперспецифические вопросы на естественном языке» и получать персонализированные результаты с высокой степенью релевантности. Компания позиционируют это изменение как шаг к созданию более удобной альтернативы традиционным поисковым системам, например, Google. По данным TechCrunch, в настоящий момент тестируется такие категории, как мода, косметика, товары для дома и электроника. Обновление уже доступно для всех пользователей ChatGPT — как для подписчиков Pro и Plus, так и для бесплатных пользователей, в том числе для неавторизованных в системе. При этом интересно, что в результатах поиска не будет рекламы и, как подчёркивает OpenAI, это существенно отличает сервис от традиционного поиска. Рекомендации формируются независимо на основе структурированных данных от партнёров, но компания не получает комиссию с покупок. «Мы не продаём приоритетное размещение и не навязываем рекламу», — подчёркивают в OpenAI. Генеральный директор Сэм Альтман (Sam Altman) ранее выступал против рекламы в ChatGPT, но в недавнем интервью известному медиа-аналитику Бену Томпсону (Ben Thompson) смягчил свою позицию. Он допустил возможность рекламы, где OpenAI получала бы партнёрские отчисления за покупки, но не продавала бы приоритет в выдаче, так как, по словам Альтмана, компания хочет «сохранить баланс между полезностью и монетизацией». В ближайшее время OpenAI планирует также интегрировать с поиском товаров функцию памяти для подписчиков Pro и Plus. Эта функция будет анализировать предыдущие диалоги и выдавать более персонализированные рекомендации. Однако пользователи из ЕС, Великобритании, Швейцарии, Норвегии, Исландии и Лихтенштейна не смогут воспользоваться опцией из-за регуляторных ограничений. В ChatGPT также появились всплывающие подсказки при вводе текста, аналогично автозаполнению в Google Search. Кроме того, OpenAI запустила поиск в WhatsApp через который можно отправлять запросы чат-боту и мгновенно получать ответы. Поиск работает на базе стандартной ИИ-модели GPT-4o. По данным OpenAI, популярность поиска в ChatGPT стремительно растёт. Так, на прошлой неделе пользователи совершили более миллиарда запросов, что подтверждает усиление конкуренции с Google, особенно в сфере онлайн-покупок. SEO станет пережитком прошлого: сайты начали оптимизироваться под ИИ, а не под поиск Google
27.04.2025 [14:45],
Анжелла Марина
Крупные компании и рекламные агентства начали активно адаптироваться к новой реальности, в которой пользователи всё чаще ищут информацию не через Google, а с помощью чат-ботов, таких как ChatGPT, Claude и Gemini. Это заставляет бренды пересматривать стратегию продвижения, так как традиционное SEO, похоже, уступает место оптимизации под ИИ. 
Источник изображения: Rodion Kutsaiev / Unsplash Технологические стартапы, включая Profound и Brandtech, разработали инструменты, которые помогают крупным сайтам отслеживать, как часто их упоминают в ответах нейросетей, в том числе в Google AI Overviews. Например, финтех-компания Ramp, агрегатор вакансий Indeed и производитель виски Chivas Brothers уже используют подобные сервисы. Как пишет Financial Times, основной целью является удержание внимания миллионов пользователей, которые всё реже и реже переходят по ссылкам в поисковиках. «Это гораздо больше, чем просто индексация сайта в результатах поиска. Речь идёт о признании вашего сайта большими языковыми моделями как главного и влиятельного фактора [при поиске информации]», — сказал Джек Смит (Jack Smyth), партнёр группы маркетинговых технологий Brandtech. Новые инструменты способны предсказывать «настроение» ИИ-модели в отношении той или иной компании, отправляя множество текстовых подсказок чат-ботам и анализируя результаты ответов. Затем составляется рейтинг брендов, на основе которого можно обеспечить их упоминание в чат-ботах. 
Источник изображения: Solen Feyissa / Unsplash Интересно, что тенденция усиливается на фоне растущего использования искусственного интеллекта (ИИ) в маркетинге. Например, Meta✴✴ и Google уже разрабатывают собственные инструменты для таргетированной рекламы, что, с одной стороны, может снизить спрос на услуги рекламных агентств, с другой стороны, агентства смогут предложить клиентам новые сервисы. Исследование Bain & Company показало, что 80 % пользователей полагаются на ИИ-ответы как минимум в 40 % запросов, а 60 % поисковых сессий завершаются без переходов на сайты. Очевидно, что идёт сокращение органического поискового трафика, создавая серьёзные риски для бизнес-модели Google как поисковика. Тем не менее, материнская компания Google, Alphabet, недавно сообщила о росте выручки от поиска и рекламы на 10 % — до $50,7 млрд в первом квартале. Основатель Perplexity Денис Ярац (Denis Yarats) считает, что ИИ-поиск основан на принципиально ином подходе, при котором большие языковые модели (LLM) анализируют контент глубже, выявляют противоречия и поэтому, чтобы соответствовать критериям, сайтам придётся предлагать максимально качественный и релевантный контент. Brandtech запустила продукт Share of Model, который помогает брендам анализировать их представленность в ИИ-поиске, а стартап Profound, привлёкший $3,5 млн инвестиций, предлагает платформу для отслеживания запросов в нейросетях. «Традиционный поиск был одной из крупнейших интернет-монополий, но сейчас стены этого замка дают трещину. — Сказал Джеймс Кэдвалладер (James Cadwallader), соучредитель Profound. — Этот момент можно сравнить с переходом от CD к стримингу». Вежливость — это дорого: OpenAI тратит миллионы долларов на «спасибо» и «пожалуйста» в ChatGPT
18.04.2025 [23:06],
Анжелла Марина
Компания OpenAI ежегодно тратит десятки миллионов долларов на обработку вежливых фраз вроде «спасибо» и «пожалуйста» в ChatGPT. Несмотря на высокие затраты, генеральный директор компании Сэм Альтман (Sam Altman) считает это оправданным. По его мнению, такие ответы делают общение с искусственным интеллектом более человечным и дружелюбным. 
Источник изображения: AI Хотя известно, что ИИ не испытывает эмоций, многие пользователи инстинктивно благодарят ChatGPT, как если бы общались с реальным человеком, но как отмечает Альтман, даже короткие ответы вроде «не за что» требуют значительных вычислительных ресурсов. Как пишет Tom's Hardware, один такой ответ «стоит» 40–50 миллилитров воды и энергозатрат на работу дата-центров. OpenAI могла бы заранее запрограммировать шаблонные ответы на вежливые реплики, но это сложно реализовать технически. Поэтому компания предпочитает сохранять естественность диалога, даже если это увеличивает расходы. При этом часть пользователей настолько привыкает к ChatGPT, что начинает воспринимать его как собеседника, что, по мнению исследователей из OpenAI и Массачусетского технологического института (MIT), может привести даже к эмоциональной зависимости. Интересно, что пользователи, которые оплачивают каждый запрос токенам, формально уже «включили» вежливые ответы в стоимость сервиса. Эксперты не исключают, что по мере развития ИИ граница между человеческим и машинным общением исчезнет, и тогда привычка быть вежливым с ChatGPT может оказаться полезной. Впрочем, пока это лишь теория, а миллионные расходы OpenAI на любезности вполне реальны. Отчёт Google о Gemini 2.5 Pro раскритиковали за отсутствие прозрачности о безопасности ИИ
18.04.2025 [04:40],
Анжелла Марина
Эксперты раскритиковали Google за недостаток прозрачности и минимальное количество информации в техническом отчёте по Gemini 2.5 Pro. Они считают, что документ без полных данных не даёт адекватного представления о возможных рисках новой ИИ-модели . 
Источник изображений: Google Отчёт был опубликован спустя несколько недель после запуска Gemini 2.5 Pro — самой мощной на сегодняшний день модели Google. Хотя такие документы обычно считаются важной частью обеспечения безопасности искусственного интеллекта (ИИ) и помогают независимым исследователям проводить собственные оценки рисков, в данном случае отчёт оказался «очень скудным», пишет TechCrunch. «В документе минимум информации, и он появился уже после того, как модель была доступна широкой публике, — заявил Питер Уилдефорд (Peter Wildeford), сооснователь Института политики и стратегии в области ИИ. — Невозможно проверить, выполняет ли Google свои публичные обещания, а значит невозможно оценить безопасность и надёжность моделей компании». Отдельную критику вызвало отсутствие упоминания о внутренней системе оценки рисков Frontier Safety Framework (FSF), которую Google представила в прошлом году для выявления потенциально опасных возможностей ИИ. В новом отчёте не содержится результатов тестов по опасным способностям модели — эти данные Google хранит отдельно и обычно не публикует вместе с основным документом. Эксперты считают, что Google, некогда выступавшая за стандартизацию отчётности по ИИ, теперь сама отходит от своих принципов. Отдельная обеспокоенность связана с тем, что компания до сих пор не представила отчёт по недавно анонсированной модели Gemini 2.5 Flash. Однако представитель Google заявил изданию TechCrunch, что этот документ выйдет в ближайшее время. Отмечается, что ситуация с Google, очевидно, является частью более широкой тенденции. Например, Meta✴✴ недавно также подверглась критике за поверхностный анализ рисков своей новейшей ИИ-модели Llama 4, а OpenAI вовсе не представила отчёт по линейке GPT-4.1. «Мы явно наблюдаем гонку на понижение стандартов, — заявил Кевин Бэнкстон (Kevin Bankston), старший советник по вопросам управления ИИ Центра демократии и технологий. — А на фоне сообщений о том, что другие компании, включая OpenAI, сокращают время на тестирование с месяцев до дней, такой уровень отчётности Google является тревожным сигналом». «Википедия» выпустила набор данных для обучения ИИ, чтобы боты не перегружали её серверы скрейпингом
17.04.2025 [16:43],
Владимир Мироненко
Фонд Wikimedia (некоммерческая организация, управляющая «Википедией») предложил компаниям вместо веб-скрейпинга контента «Википедии» с помощью ботов, который истощает её ресурсы и перегружает серверы трафиком, воспользоваться набором данных, специально оптимизированным для обучения ИИ-моделей. 
Источник изображения: Oberon Copeland @veryinformed.com/unsplash.com Wikimedia объявил о заключении партнёрского соглашения с Kaggle, ведущей платформой для специалистов в области Data Science и машинного обучения, принадлежащей Google. В рамках соглашения на ней будет опубликована бета-версия набора данных «структурированного контента “Википедии” на английском и французском языках». Согласно Wikimedia, набор данных, размещённый Kaggle, был «разработан с учётом рабочих процессов машинного обучения», что упрощает разработчикам ИИ доступ к машиночитаемым данным статей для моделирования, тонкой настройки, сравнительного анализа, выравнивания и анализа. Содержимое набора данных имеет открытую лицензию. По состоянию на 15 апреля набор включает в себя обзоры исследований, краткие описания, ссылки на изображения, данные инфобоксов и разделы статей — за исключением ссылок или неписьменных элементов, таких как аудиофайлы. Как сообщает Wikimedia, «хорошо структурированные JSON-представления контента “Википедии”», доступные пользователям Kaggle, должны быть более привлекательной альтернативой «скрейпингу или анализу сырого текста статей». На данный момент у Wikimedia есть соглашения об обмене контентом с Google и Internet Archive, но партнёрство с Kaggle позволит сделать данные более доступными для небольших компаний и независимых специалистов в сфере Data Science. «Являясь площадкой, к которой сообщество машинного обучения обращается за инструментами и тестами, Kaggle будет рада стать хостом для данных фонда Wikimedia», — сообщила Бренда Флинн (Brenda Flynn), руководитель по коммуникациям в Kaggle. Двухлетняя модель GPT-4 скоро исчезнет из ChatGPT, уступив место более свежей GPT-4o
12.04.2025 [05:39],
Анжелла Марина
С 30 апреля компания OpenAI удалит модель GPT-4 из меню выбора моделей в ChatGPT для пользователей подписки Plus. Такое решение связано с окончательным переходом на новую модель GPT-4o, которая, по словам разработчиков, превосходит своего предшественника по всем ключевым параметрам, начиная с написания текстов и заканчивая программированием. 
Источник изображения: OpenAI Как заявили в OpenAI, мультимодальная большая языковая модель четвёртой серии GPT стала поворотным моментом в развитии чат-бота ChatGPT. Выпущенная 14 марта 2023 года, модель показала несравнимо большие возможности по сравнению в GPT-3. По данным PCMag, на её обучение было потрачено более $100 млн. Несмотря на то, что GPT-4 исчезнет из пользовательского интерфейса ChatGPT, она останется доступной через API на других платформах. При этом, бесплатные пользователи ChatGPT не смогут выбрать модель вручную, поэтому для них ничего не изменится. В настоящее время OpenAI предлагает несколько моделей, включая GPT-4 Turbo, GPT-o3, GPT-o1 и GPT-4.5, а также ходят слухи о возможном запуске GPT-4.1. Глава OpenAI Сэм Альтман (Sam Altman) ранее признавал, что наличие большого количества моделей может сбивать пользователей с толку, поэтому в будущем компания планирует отказаться от выбора модели вручную и перейти к системе единого ИИ, где подбор модели будет происходить автоматически в зависимости от задач. Все представленные модели, как отмечают в OpenAI, являются этапами на пути к следующему крупному релизу GPT-5. Однако её разработка проходит не совсем гладко, что связано, в том числе, и с нехваткой графических процессоров. Но так как компании удалось в прошлом месяце привлечь $40 млрд инвестиций, то ожидается, что это поможет масштабировать вычислительные мощности и ускорить релиз. После запуска модель GPT-5 станет доступна пользователям бесплатно в базовом режиме. Подписчики ChatGPT Plus ($20 в месяц) смогут использовать её с повышенным уровнем ИИ-возможностей, а пользователи подписки Pro ($200 в месяц) получат доступ к самым мощным функциям, таким как голосовой режим, инструменты визуализации Canvas, расширенный поиск, глубокие исследования и другие продукты OpenAI. ChatGPT обошёл Instagram✴ и TikTok, став самым скачиваемым приложением в мире
12.04.2025 [05:34],
Анжелла Марина
Приложение ChatGPT впервые возглавило мировой рейтинг загрузок в марте 2025 года, обогнав таких гигантов, как Instagram✴✴ и TikTok. По данным аналитической компании Appfigures, число установок ChatGPT выросло на 28 % по сравнению с февралём и составило около 46 миллионов загрузок за месяц. С момента запуска приложения, март оказался для OpenAI лучшим месяцем. 
Источник изображения: Rolf van Root / Unsplash Instagram✴✴, удерживавший лидерство в январе и феврале, опустился на второе место, а TikTok занял третью строчку в App Store и Google Play, сообщает TechCrunch. При этом, рост популярности ChatGPT связывают с важными обновлениями. В частности, впервые за более чем год были улучшены функции генерации изображений, что позволило пользователям создавать вирусные картинки и мемы в стиле анимационной студии Studio Ghibli, которые быстро разошлись по социальным сетям в конце марта и начале апреля. Кроме того, OpenAI ослабила ограничения в политике модерации визуального контента и обновила в приложении голосовой режим. Тем не менее, аналитики считают, что не только новые функции повлияли на скачок популярности. «Складывается впечатление, что слово ChatGPT становится глаголом, таким же, каким стал Google в 2000-х. Многие уже говорят не искусственный интеллект, а просто ChatGPT», — отметил основатель и генеральный директор Appfigures Ариэль Михаэли (Ariel Michaeli). По его словам, волну интереса к ИИ также подогревают конкуренты вроде Grok или DeepSeek, но пользователи всё равно скачивают ChatGPT. К сожалению, популярность ChatGPT также затрудняет рост других чат-ботов. К примеру, Claude от Anthropic пока не может приблизиться к таким же результатам. У Grok, наоборот, шансы несколько выше, но во многом благодаря фигуре самого Илона Маска (Elon Musk) и его платформе X, которая активно продвигает продукт. 
Источник изображения: Appfigures В общемировом рейтинге в марте также оказались Facebook✴✴, WhatsApp, Telegram, Snapchat и Threads. Всего 10 самых популярных приложений были загружены 339 миллионов раз, что на 40 миллионов больше, чем в феврале. OpenAI готовится запустить ИИ-модель GPT-4.1, но возможны задержки
11.04.2025 [05:17],
Анжелла Марина
Компания OpenAI планирует в ближайшее время представить несколько новых моделей искусственного интеллекта, включая обновлённую версию GPT-4 под названием GPT-4.1, которая станет усовершенствованной версией флагманской рассуждающей модели GPT-4o. 
Источник изображения: AI По данным The Verge, улучшенная новая модель GPT-4.1 также, как и GPT-4o сможет обрабатывать текст, изображение и аудио в режиме реального времени. Вместе с ней OpenAI планирует выпустить и более лёгкие версии — GPT-4.1 mini и nano, запуск которых может состояться уже на следующей неделе. Кроме того, компания готовит к релизу полную версию модели o3, а также облегчённый вариант o4 mini. ИИ-разработчик Тибор Блахо (Tibor Blaho), известный тем, что раньше других замечает возможные нововведения, обнаружил упоминания этих моделей в новой веб-версии ChatGPT, что, по его мнению, указывает на их скорый запуск. Интересно, что генеральный директор OpenAI Сэм Альтман (Sam Altman) ранее намекал в соцсети X на «захватывающие функции», которые появятся в линейке продуктов компании, однако не уточнил, связано ли это с новыми моделями. При этом он также предупреждал, что пользователи могут столкнуться с задержками и сбоями из-за высокой нагрузки на вычислительные мощности: «Следует ожидать задержек, сбоев и медленной работы сервисов, пока мы решаем проблемы с производительностью». Напомним, ранее OpenAI уже была вынуждена ограничить использование генератора изображений в бесплатной версии ChatGPT из-за перегрузки серверов, так как, по словам Альтмана, популярность этой функции привела к тому, что их GPU чуть ли не стали плавиться, подтверждая предположение о колоссальном спросе на услуги компании. Исследование Microsoft показало, что ИИ пока «так себе» исправляет ошибки в программном коде
11.04.2025 [05:11],
Анжелла Марина
Новое исследование подразделения Microsoft Research выявило, что несмотря на то, что ИИ помогает разработчикам в написании кода, даже передовые модели OpenAI (o1) и Anthropic (Claude 3.7 Sonnet) справляются с исправлением ошибок не более чем в половине случаев. Тестирование проводилось на базе лучшего бенчмарка SWE-bench, который измеряет умение ИИ-систем создавать программный код. 
Источник изображения: сгенерировано AI В ходе эксперимента ИИ-агенты пытались решить 300 задач по устранению ошибок в коде. Лидером стала модель Claude 3.7 Sonnet, которая выполнила задание с успешностью на 48,4 %, второе место заняла OpenAI o1 (30,2 %), третье — o3-mini (22,1 %). Однако, как видно, даже эти цифры далеки от уровня, которого можно было бы ожидать от опытных программистов-людей. Как поясняет TechCrunch, основная проблема заключается в том, что искусственный интеллект пока плохо понимает, как использовать доступные инструменты и интерпретировать ошибки. По мнению авторов исследования, ключевым препятствием остаётся дефицит данных для обучения моделей. «Мы твёрдо верим, что обучение или дообучение может сделать их лучшими интерактивными отладчиками, — пишут они. — Однако для этого нужны специализированные данные, например, цепочка записей всех процессов взаимодействия людей с ИИ-отладчиками». Сейчас таких данных недостаточно, что ограничивает возможности моделей. Например, популярный инструмент Devin стартапа Cognition Labs смог по этой причине справиться лишь с тремя из 20 тестов по кодированию. И хотя ИИ активно используется такими компаниями как Google, по словам генерального директора Сундара Пичаи (Sundar Pichai), четверть кода, который создаётся с помощью искусственного интеллекта, может даже наоборот добавлять ошибки. Технологические лидеры скептически относятся к полной автоматизации профессии программиста. Билл Гейтс (Bill Gates) уверен, что программирование как профессия, конечно, никуда не исчезнет. Аналогичного мнения придерживаются генеральный директор Replit Амджад Масад (Amjad Masad), глава Okta Тодд Маккиннон (Todd McKinnon) и руководитель IBM Арвинд Кришна (Arvind Krishna). Несмотря на очевидные проблемы, интерес к ИИ-инструментам для разработки продолжает расти. Инвесторы видят в них потенциал для повышения эффективности, однако ведущие разработчики считают, что доверять ИИ полностью пока рановато. «ИИ крадёт у всех»: медиаиндустрия потребовала немедленно остановить воровство контента для ИИ
08.04.2025 [01:05],
Анжелла Марина
Сотни медиакомпаний, включая The New York Times, The Washington Post и The Guardian, запустили рекламную кампанию с призывом к правительству США защитить контент от неконтролируемого использования искусственным интеллектом (ИИ), сообщает The Verge. Инициатива под названием Support Responsible AI организована ассоциацией News/Media Alliance и включает объявления как в печатных, так и онлайн-изданиях. 
Источник изображения: сгенерировано AI Кампания стартовала через несколько недель после того, как OpenAI и Google направили властям письма с просьбой разрешить их ИИ-моделям обучаться на защищённых авторским правом материалах. В рекламе используются такие слоганы, как «Следите за ИИ», «Остановите кражу ИИ», «ИИ крадёт у вас тоже», и всё это вместе с призывом внизу каждого тизера: «Кража — это не по-американски. Скажите Вашингтону, чтобы техногиганты платили за контент, который они берут у издателей». Объявления содержат ссылку и QR-код, ведущие на сайт Support Responsible AI, где пользователей призывают обратиться к своим представителям в Конгрессе с требованием обязать технологические компании справедливо компенсировать труд журналистов, писателей и художников. Также издатели настаивают на обязательном указании источников в контенте, созданном ИИ. 
Источник изображения: News/Media Alliance «Сейчас Big Tech и ИИ-компании используют контент издателей против них самих, то есть забирают его без разрешения и оплаты, чтобы обучать ИИ-модели, которые в конечном итоге перетягивают на себя все рекламные доходы от создателей, — заявила Даниэль Коффи (Danielle Coffey), президент и генеральный директор News/Media Alliance. — Медиаиндустрия не против ИИ — многие компании сами используют эти инструменты. Но мы хотим сбалансированной экосистемы, где ИИ развивается ответственно». В феврале аналогичную кампанию провели крупные британские газеты, разместив на первых полосах лозунг «Make It Fair» с призывом защитить авторские права от обучения ИИ-моделей. Среди участников сегодняшней инициативы также присутствуют The Atlantic, Seattle Times, Tampa Bay Times, Condé Nast (издатель Wired) и Axel Springer (владелец Politico). Очевидно, что конфликт между медиакомпаниями и технологическими гигантами обостряется. Пока OpenAI и Google добиваются у правительства США свободного доступа к данным для обучения ИИ, издатели настаивают на законодательном регулировании и выплатах за использование их материалов. Исход этой борьбы в эпоху нейросетей может определить будущее цифрового контента . Amazon добавила ИИ-функцию кратких обзоров книг Kindle, но предупредила о спойлерах
04.04.2025 [04:40],
Анжелла Марина
Компания Amazon представила новую функцию Recaps для пользователей Kindle, которая поможет перед чтением следующей главы книги быстро вспомнить содержание предыдущей главы. Краткие обзоры, как сообщила Amazon изданию TechCrunch, создаются с помощью искусственного интеллекта (ИИ). 
Источник изображения: Amazon Amazon отмечает, что новая функция добавляет удобства в чтение глав, позволяя читателям «глубже погружаться в сложные миры и образы, не теряя при этом удовольствия от сюжета». Recaps охватывает различные жанры, начиная от эпических фэнтези и заканчивая детективными триллерами, может пересказать в сжатой форме как проверенную временем классику, так и недавно вышедшие новинки. Однако перед тем как открыть краткий текст, Kindle предупредит, что пересказ содержит спойлеры, в которых могут быть раскрыты ключевые повороты сюжета и информация о персонажах. Если пользователь даст согласие на открытие Recaps, он будет перенаправлен к краткому пересказу. Тем временем, на Reddit форумчане уже начали обсуждать новинку и, кажется, не все настроены оптимистично. Некоторые выразили сомнения в том, насколько точно ИИ сможет передать сюжет. Но представитель компании Але Ирахета (Ale Iraheta) утверждает, что Amazon тщательно проверяет ИИ-пересказы на соответствие оригинальному содержанию, в том числе с помощью своих модераторов. На данный момент функция доступна для пользователей Kindle в США. Пересказы можно прочитать для тысяч популярных книг на английском языке. В ближайшее время Amazon планирует добавить эту возможность и в приложение Kindle для iOS. Чтобы воспользоваться Recaps, нужно обновить программное обеспечение Kindle до последней версии. А чтобы проверить, есть ли краткий пересказ у конкретной главы, необходимо нажать на кнопку View Recaps в библиотеке Kindle или через меню с тремя точками. «Наш контент бесплатный, а инфраструктура — нет»: ИИ-боты разоряют «Википедию»
02.04.2025 [19:54],
Сергей Сурабекянц
«Википедия» расплачивается за бум искусственного интеллекта — онлайн-энциклопедия сталкивается с растущими расходами из-за ботов, которые копируют её статьи для обучения моделей искусственного интеллекта, что впустую расходует ресурсы и в разы увеличивает трафик и нагрузку на сайт. Только за последние три месяца трафик, генерируемый ИИ-краулерами, вырос на 50 %. 
Источник изображения: «Википедия» Фонд Wikimedia (некоммерческая организация, управляющая «Википедией») заявил, что «автоматизированные запросы на наш контент выросли в геометрической прогрессии». По данным фонда, с января 2024 года пропускная способность, используемая для загрузки мультимедийного контента, выросла на 50 %. Однако трафик исходит не от людей, а от автоматизированных программ, которые постоянно загружают изображения с открытой лицензией для передачи их моделям ИИ. «Наша инфраструктура создана для того, чтобы выдерживать внезапные всплески трафика от людей во время мероприятий с высоким интересом, но объем трафика, генерируемого ботами-скрейперами, беспрецедентен и представляет растущие риски и расходы», — сообщила «Википедия». Боты часто собирают данные из менее популярных статей «Википедии». Специалисты «Википедии» утверждают, что по крайней мере 65 % подобного трафика, поступает от ботов, что является непропорционально большим объёмом, учитывая, что общее количество просмотров страниц ботами составляет около 35 %. Также боты проявляют интерес к «ключевым системам в инфраструктуре разработчиков, таким как наша платформа проверки кода или наш баг-трекер», что ещё больше нагружает ресурсы сайта. «Википедия» была вынуждена ввести индивидуальные ограничения скорости для ИИ-ботов или вообще запретить доступ некоторым из них. Но для решения проблемы в долгосрочной перспективе фонд разрабатывает план «Ответственного использования инфраструктуры». План предусматривает сбор отзывов от сообщества «Википедии» о способах определения трафика от ИИ-ботов и фильтрации их доступа. Социальная платформа Reddit столкнулась с похожей проблемой в 2023 году. Например, Microsoft без уведомления Reddit использовала данные платформы для обучения моделей ИИ, что вынудило Reddit заблокировать ботов Microsoft. После этого инцидента Reddit решила взимать плату со сторонних разработчиков за доступ к своему API. Это привело к массовым протестам разработчиков и закрытию некоторых популярных форумов Reddit. Бывший гендир Intel Гелсингер возглавил стартап Gloo, пытающийся внедрить ИИ в религию
25.03.2025 [09:59],
Алексей Разин
В начале декабря Патрик Гелсингер (Patrick Gelsinger) был отправлен в отставку с поста генерального директора Intel, после чего стало известно, что он оказывает финансовую поддержку стартапу Gloo, стремящемуся привнести новые технологии в консервативную религиозную среду. Вчера Гелсингер возглавил Gloo в качестве технического директора и исполнительного председателя совета директоров. 
Источник изображения: Intel Gloo занимается внедрением больших языковых моделей в сфере взаимодействия прихожан и священников. Ранее Гелсингер признавался, что Gloo уже использует языковые модели DeepSeek с открытым исходным кодом, но со временем надеется внедрить собственные разработки в этой сфере. Совет директоров Gloo Гелсингер возглавлял в качестве неисполнительного председателя с 2018 года, а продвижением интересов христианства в Калифорнии бывший глава Intel занимался на протяжении более чем десяти лет. Стартап Gloo был основан ещё в 2013 году, в прошлом году ему удалось привлечь $110 млн. Компания разрабатывает «христианский чат-бот», который фильтрует результаты поиска и даёт пользователям ответы, построенные на христианских канонах. В новом качестве Гелсингер сможет сильнее влиять на разработку данного чат-бота. «Технология способна объединять, улучшать и трансформировать жизни людей, но только когда она изначально создаётся с соответствующими целями», — прокомментировал своё назначение Патрик Гелсингер. Исследователи нашли способ масштабирования ИИ без дополнительного обучения, но это не точно
19.03.2025 [23:34],
Анжелла Марина
Группа исследователей предложила новый метод масштабирования искусственного интеллекта (ИИ). Речь идёт о так называемом «поиске во время вывода», который позволяет модели генерировать множество ответов на запрос и выбирать лучший из них. Этот подход может повысить производительность моделей без дополнительного обучения. Однако сторонние эксперты усомнились в правильности идеи. 
Источник изображения: сгенерировано AI Ранее основным способом улучшения ИИ было обучение больших языковых моделей (LLM) на всё большем объёме данных и увеличение вычислительных мощностей при запуске (тестировании) модели. Это стало нормой, а точнее сказать, законом для большинства ведущих ИИ-лабораторий. Новый метод, предложенный исследователями, заключается в том, что модель генерирует множество возможных ответов на запрос пользователя и затем выбирает лучший. Как отмечает TechCrunch, это позволит значительно повысить точность ответов даже у не очень крупных и устаревших моделей. В качестве примера учёные привели модель Gemini 1.5 Pro, выпущенную компанией Google в начале 2024 года. Утверждается, что, используя технику «поиска во время вывода» (inference-time search), эта модель обошла мощную o1-preview от OpenAI по математическим и научным тестам. Один из авторов работы, Эрик Чжао (Eric Zhao), подчеркнул: «Просто случайно выбирая 200 ответов и проверяя их, Gemini 1.5 однозначно обходит o1-preview и даже приближается к o1». Тем не менее, эксперты посчитали эти результаты предсказуемыми и не увидели в методе революционного прорыва. Мэтью Гуздиал (Matthew Guzdial), исследователь ИИ из Университета Альберты, отметил, что метод работает только в тех случаях, когда можно чётко определить правильный ответ, а в большинстве задач это невозможно. С ним согласен и Майк Кук (Mike Cook), исследователь из Королевского колледжа Лондона. По его словам, новый метод не улучшает способность ИИ к рассуждениям, а лишь помогает обходить существующие ограничения. Он пояснил: «Если модель ошибается в 5 % случаев, то, проверяя 200 вариантов, эти ошибки просто станут более заметны». Основная проблема состоит в том, что метод не делает модели умнее, а просто увеличивает количество вычислений для поиска наилучшего ответа. В реальных условиях такой подход может оказаться слишком затратным и малоэффективным. Несмотря на это, поиск новых способов масштабирования ИИ продолжается, поскольку современные модели требуют огромных вычислительных ресурсов, а исследователи стремятся найти методы, которые позволят повысить уровень рассуждений ИИ без чрезмерных затрат. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



