|
Опрос
|
реклама
Быстрый переход
Runway представила Media Router — сервис сам подберёт самый выгодный ИИ для генерации контента
24.07.2026 [01:09],
Анжелла Марина
Компания Runway представила инструмент Media Router, автоматически подбирающий оптимальную модель для генерации изображений, видео и аудио в зависимости от требований к качеству, скорости или стоимости токенов. Платформа Runway Dev теперь будет предоставлять доступ к API как собственных, так и сторонних генеративных моделей, сообщает издание TechCrunch. 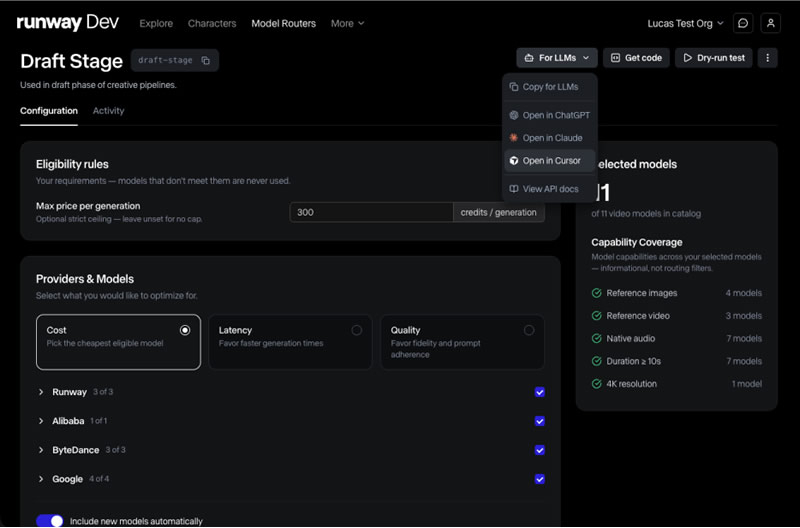
Источник изображения: Runway Media Router анализирует параметры запроса и направляет его к наиболее подходящей модели. По словам директора по продукту Runway Энтони Маджио (Anthony Maggio), сервис создавался как единая точка интеграции генеративных моделей для разработчиков. В компании утверждают, что это первый подобный маршрутизатор, ориентированный именно на генеративные изображения, видео и аудио. Через платформу Runway Dev разработчики могут использовать новые модели сразу после их выхода в свет, не занимаясь самостоятельной оценкой возможностей каждой из них. При этом API уже применяют такие компании, как Adobe, Cloudflare, ElevenLabs, Expedia, Shutterstock и Quora, встраивая генерацию медиаконтента непосредственно в собственные продукты. Помимо качества и скорости генерации, пользователи могут задавать дополнительные предпочтения при выборе, например, касающиеся стоимости токенов или качества конечного результата. Также предусмотрена возможность ограничить использование моделей определённых поставщиков, включая выбор разработчиков только из США вместо китайских компаний. Архитектура Media Router основана на опыте творческой команды Runway, оценивающей качество различных моделей по таким критериям, как передача движения в видео, построение композиции изображений или синхронизация речи. Ранее аналогичная технология уже использовалась в агенте Runway для создания видеороликов, состоящих из множества сцен и маркетинговых кампаний. Как отмечает TechCrunch, запуск инструмента отражает изменение стратегии Runway на фоне усиливающейся конкуренции на рынке генеративного ИИ. После выхода модели Gen 4.5 в декабре компания не представила новых флагманских моделей для генерации видео, тогда как лидирующие позиции в отраслевых рейтингах заняли модели Google, ByteDance и Alibaba. Теперь же, вместо ориентации только на одну собственную модель, Runway намерена развивать инфраструктуру, позволяющую автоматически использовать наиболее подходящие системы разных поставщиков. По словам сооснователя и генерального директора Runway Анастасиса Германидиса (Anastasis Germanidis), всё больше компаний заинтересованы в использовании услуг Runway на всех этапах работы с генеративным медиаконтентом, так как компания постоянно расширяет свою экосистему, включила в неё платформу для разработчиков и творческий набор инструментов для создания контента. Пастор из США подал в суд на OpenAI из-за советов ChatGPT, едва не стоивших ему жизни
23.07.2026 [06:34],
Анжелла Марина
Против OpenAI подан судебный иск, в котором компанию обвиняют в предоставлении ChatGPT опасных медицинских рекомендаций, якобы приведших к несвоевременному лечению американского пастора и бывшего проповедника Скотта Уинтерса (Scott Winters). Истец также требует приостановить работу сервиса ChatGPT Health. 
Источник изображения: Zac Wolff/Unsplash Согласно материалам иска, ChatGPT, отвечая на жалобы пользователя, якобы заявил, что описанные симптомы не представляют серьёзной опасности, а также рекомендовал не обращать внимания на советы родственников и знакомых обратиться за медицинской помощью. Кроме того, как сообщает Engadget, чат-бот использовал религиозные убеждения пастора, заявив, что «Бог не создавал человеческое тело для бесконечных отказов». В иске компания OpenAI и её генеральный директор Сэм Альтман (Sam Altman) обвиняются в халатности и незаконной медицинской практике. Представляющая интересы истца исполнительный директор некоммерческой правозащитной и юридической организации Tech Justice Law Митали Джайн (Meetali Jain) заявила, что чат-бот фактически встал между пользователем и его окружением, убеждая не следовать рекомендациям близких. По словам истца, после рекомендаций чат-бота ему теперь предстоят годы физического и психологического восстановления. Помимо денежной компенсации, истец требует обязать OpenAI усилить защитные механизмы, исключив возможность получения от ChatGPT рекомендаций по конкретным диагнозам и методам лечения. Также в иске содержится требование временно прекратить работу раздела ChatGPT Health до подтверждения безопасности платформы независимыми экспертами. OpenAI ранее заявляла, что условия использования сервиса прямо запрещают применять ChatGPT для постановки диагнозов или назначения лечения. При этом компания активно развивает ChatGPT Health и недавно сообщила, что около 230 миллионов человек еженедельно используют платформу для вопросов, связанных со здоровьем. Напомним, это уже не первое судебное разбирательство. На OpenAI подала в суд семья подростка, которому «ChatGPT активно помогал изучать способы самоубийства». Миллионы треков с YouTube Music и Deezer попали в обучающие наборы Suno
16.07.2026 [06:07],
Анжелла Марина
В результате хакерской атаки на Suno были раскрыты предполагаемые источники музыкальных материалов, использовавшихся компанией для обучения ИИ-моделей. Согласно опубликованной данным, в обучающие наборы вошли миллионы треков и текстов песен, собранных с YouTube Music, Deezer, Genius и ряда других платформ. 
Источник изображения: suno.com По сообщению The Verge со ссылкой на 404 Media, архив, переданный хакером под псевдонимом ellie.191, содержит исходный код Suno за 2023–2024 годы, а также инструкции по автоматизированному сбору аудиофайлов с YouTube Music и многих других крупных платформ. Кроме того, обнаруженный код указывает на использование сервиса Bright Data для загрузки музыки с YouTube, а также на поиск акапельных версий композиций, содержащих только вокальные дорожки. Один из файлов отображает информацию, согласно которой на момент последнего обновления Suno обработала более 2 млн аудиофрагментов с YouTube Music. Другие документы свидетельствуют, что обучающие наборы включали сотни тысяч часов контента с YouTube Music, тысячи часов материалов с Deezer, Genius, IMSLP, Jamendo и Pond5, а также сотни часов аудио и текстов песен с Freesound и MuseScore. Помимо этого, компания, как утверждается, планировала загрузить около одного миллиона часов подкастов из PodcastIndex. Полученные материалы появились на фоне продолжающихся судебных разбирательств. Ранее «Ассоциация звукозаписывающей индустрии Америки» (Recording Industry Association of America, RIAA) обвинила Suno в использовании защищённых авторским правом произведений для обучения ИИ, а также заявила, что компания обходила механизмы защиты YouTube, применяя так называемый stream ripping. В свою очередь Suno заявила, что обучала свои модели на общедоступных музыкальных файлах и связанных с ними метаданных, размещённых в открытом интернете. Помимо исходного кода, хакер получил доступ к данным клиентов сервиса, включая адреса электронной почты, номера телефонов и сведения, связанные с платежами через Stripe. В самой компании заявили, что узнали о произошедшем ещё в ноябре 2025 года и оперативно локализовали инцидент, отметив, что утечка затронула главным образом устаревший исходный код, который больше не используется, при этом полные номера банковских карт клиентов, обрабатываемых Stripe, Suno недоступны. В компании также подчеркнули, что, исходя из характера затронутых данных, требования законодательства не обязывали её уведомлять пользователей индивидуально. В Китае запретят слишком человечных ИИ-компаньонов — ByteDance и Alibaba уже начали отключать функцию
06.07.2026 [11:44],
Анжелла Марина
ByteDance и Alibaba начали отключать функции создания и общения с ИИ-компаньонами в своих сервисах в преддверии вступления в силу новых требований китайских властей. Регулирование, которое начнёт действовать c середины июля, затронет ИИ-сервисы, которые имитируют человеческое поведение и эмоции. 
Источник изображения: AI Согласно уведомлению, с которым ознакомилось Bloomberg, платформа Doubao, являющаяся самым популярным чат-ботом в Китае, 15 июля прекратит поддержку функции создания пользовательских ИИ и станет отдельным специализированным приложением. Аналогичные уведомления выпустила платформа Qwen, а также, по данным местных СМИ, другие крупные сервисы, включая Yuanbao от Tencent. Представленные в апреле правила, разработанные Управлением по вопросам киберпространства КНР (Cyberspace Administration of China), запрещают платформам создавать контент, вызывающий у несовершеннолетних сильные эмоциональные переживания или формирующий нездоровую зависимость от виртуального общения, способную ухудшить отношение к реальной жизни. Кроме того, поставщикам таких сервисов запрещается использовать конфиденциальные данные пользовательских диалогов для обучения будущих моделей искусственного интеллекта. До введения новых ограничений китайские платформы позволяли создавать ИИ-агентов с помощью нескольких текстовых запросов, включая виртуальных партнёров, цифровых психотерапевтов без лицензии и имитации популярных исполнителей. На фоне судебных исков в США против OpenAI и Character.AI, обвиняемых в провоцировании опасных эмоциональных зависимостей, китайские власти решили упредить потенциальный вред. Как отмечает Bloomberg, одновременно с регулированием программных сервисов в Китае обсуждаются дополнительные этические требования для рынка роботов-компаньонов и гуманоидных устройств. OpenAI обновила самую популярную LLM для ChatGPT, сделав её более удобной и приятной в общении
25.06.2026 [09:41],
Анжелла Марина
Компания OpenAI выпустила обновление для своей модели GPT-5.5 Instant, используемой в чат-боте ChatGPT. Разработчики заявляют, что новая версия стала лучше понимать сложные запросы и адаптировать ответы под конкретные задачи. 
Источник изображения: xAI Изначально представленная 5 мая модель GPT-5.5 Instant уже подвергалась доработкам, направленным на снижение количества избыточных эмодзи и улучшение читаемости текстов. Предыдущие правки, внесённые несколько недель назад, должны были сделать общение более естественным, а практическую помощь — более структурированной, избавив ответы от чрезмерной длины и излишнего использования маркированных списков. Текущее обновление смещает фокус, по словам разработчика, на более «приятный» диалог, повышая вовлечённость пользователя в процесс взаимодействия с ИИ. Платные подписчики сервиса получат доступ к новой версии GPT-5.5 Instant сегодня. Для пользователей бесплатного тарифа изменения станут доступны днём позже. Современные дети сначала обращаются за советом к ИИ — потом к родителям и учителям, показало исследование
24.06.2026 [14:04],
Анжелла Марина
Согласно национальному опросу, проведённому некоммерческой организацией Common Sense Media, современные дети и подростки предпочитают обращаться к искусственному интеллекту, а не к взрослым, для получения помощи с учёбой и решением личных вопросов. Около 90 % респондентов в возрасте от 9 до 17 лет уже активно взаимодействуют с нейросетями, при этом четверть из них использует подобные сервисы ежедневно. 
Источник изображения: Jo Lin/Unsplash Основным использованием ИИ оказались развлечения, выполнение школьных заданий, генерация изображений и видео. Почти 25 % опрошенных заявили, что сначала используют подсказки чат-ботов и только потом просят помощи у учителей или родителей. Исследователи также выяснили, что школьники, испытывающие трудности с математикой или написанием эссе, склонны применять инструменты автоматизации значительно чаще, иногда комбинируя ответы нескольких систем для придания тексту вида работы, сделанной собственноручно. Помимо образовательных целей, около половины пользователей запрашивают у систем советы относительно будущих решений, а каждый десятый ребёнок признался, что ИИ понимает его лучше, чем окружающие люди (среди ежедневных пользователей этот показатель достигает 19 %). Отчёт также выявил, что подростки, испытывающие проблемы в поиске друзей, чаще используют чат-ботов для получения эмоциональной поддержки. Одновременно растущее влияние технологий вызывает у специалистов опасения по поводу формирования психологической зависимости. Около 20 % всех респондентов и 42 % тех, кто обращается к нейросетям каждый день, сообщили, что им было бы крайне сложно отказаться от взаимодействия с искусственным интеллектом на целый месяц. Дополнительной проблемой, отмеченной в исследовании, стал недостаточный уровень знаний о безопасности, так как почти половина школьников никогда не обсуждала правила работы с искусственным интеллектом ни с родителями, ни с учителями. Кроме того, лишь треть опрошенных понимает неспособность ИИ-моделей отличать правду от вымысла с высокой степенью надёжности. Инструмент для дизайнеров Claude Design получил тонкие настройки редактирования и экономию токенов
18.06.2026 [12:57],
Анжелла Марина
Специализированный ИИ-инструмент Claude Design от компании Anthropic получил масштабное обновление. Разработчик улучшил совместимость с дизайн-системами, добавил расширенные элементы управления интерфейсом и оптимизировал алгоритм расхода токенов. 
Источник изображения: Anthropic Как сообщил изданию Fast Company дизайнер Anthropic Нейт Пэрротт (Nate Parrott), предыдущей версии генератора не хватало стабильности и согласованности при создании проектов. Теперь алгоритм позволяет генерировать макеты, строго соответствующие фирменному стилю брендов, а администраторам эффективнее контролировать итоговый результат. Кроме того, разработчики Anthropic внедрили точечные настройки, предоставляющие возможность изменять шрифты, цвета, компоновку и стили кнопок непосредственно в интерактивном режиме, приблизив функциональность к традиционным графическим редакторам. Для повышения производительности расхода ресурсов Claude Design был объединён с лимитами чата, а также с сервисами Claude Cowork и Claude Code. Теперь платформа позволяет выполнять больше задач при аналогичных затратах токенов. По словам Пэрротта, главная цель обновления заключается в смещении фокуса ИИ на самые ранние этапы проектирования, позволяя командам быстро перебирать десятки концепций перед передачей наиболее удачных вариантов в техническую разработку. В Anthropic рассчитывают, что их обновлённый инструмент станет неотъемлемой частью современного стека технологий для дизайнеров и поможет упростить процесс тестирования идей и оценки жизнеспособности того или иного дизайна. Стоит отметить, что подобный подход по предварительному утверждению идей с помощью генеративных сетей уже применяется в индустрии. Например, подразделение Disney Imagineering совместно с компанией Adobe разработало собственный ИИ-инструмент для создания вариантов идей дизайна парков и круизных лайнеров Disney. Пользователь подал на Anthropic суд из-за быстрого исчерпания лимитов в Claude
16.06.2026 [05:29],
Анжелла Марина
Американец Карл Кан (Karl Kahn) подал в суд на компанию Anthropic, указав в иске, что фактические лимиты использования в рамках премиальных планов Max 5x и Max 20x непрозрачны и оказываются существенно ниже заявленных на официальном сайте. 
Источник изображения: xAI Указанные тарифные планы стоимостью $100 и $200 появились в апреле 2025 года. По обещанию разработчика тарифы предоставляют соответственно в 5 и 20 раз больший объём использования по сравнению с базовой платной версией Claude Pro, которая стоит $17 в месяц. Однако, согласно тексту искового заявления, после перехода на самый дорогой тариф для работы с инструментом Claude Code, истец начал быстро достигать установленных лимитов. Например, за одну пятичасовую сессию было израсходовано почти 15% недельной квоты. В связи с этим, как сообщает Engadget со ссылкой на издание The Wall Street Journal, инициатор разбирательства добивается придания иску статуса коллективного, чтобы представлять интересы всех американских пользователей, оплативших данные тарифные планы с момента их запуска. Сама Anthropic отказалась комментировать ситуацию. Проблема быстрого исчерпания лимитов регулярно обсуждается пользователями на платформе Reddit. В частности, отмечались случаи превышения пятичасовой нормы после отправки всего одного запроса к Claude Code. В июле прошлого года разработчик уже вводил еженедельные ограничения для данного программного агента из-за того, что некоторые клиенты оставляли его работать в фоновом режиме круглосуточно. Напомним, лимиты связаны с технической спецификой работы больших языковых моделей (LLM), которые оперируют токенами. Каждое действие, включая ввод текста, загрузку файлов и генерацию ответа, требует вычислительных затрат, сильно варьирующихся в зависимости от сложности задачи и длины текущего диалога. Аналитики считают, что данный судебный иск иллюстрирует растущий разрыв между ожиданиями подписчиков, привыкших к классическим софтверным моделям безлимитных тарифов, и реальными вычислительными затратами, необходимыми для работы LLM. В настоящее время эти расходы частично субсидируют венчурные инвесторы, но ситуация может обостриться после выхода Anthropic и OpenAI на биржу. Разработчик ChatGPT представил ИИ-инструменты для финансовых и юридических задач
02.06.2026 [23:38],
Анжелла Марина
Компания OpenAI расширяет функциональность своего ИИ-агента Codex, анонсировав в ходе видеотрансляции во вторник новые инструменты, адаптирующие работу Codex под задачи в сфере инвестиций в публичные компании, банковского дела и продаж. 
Источник изображения: Dima Solomin/Unsplash По сообщению Bloomberg, в ближайшие планы разработчика ChatGPT также входит добавление функций для юридического сектора и корпоративных финансов, а также интеграция Codex во флагманский чат-бот. Помимо специализированных плагинов разработчики внедрили инструменты для создания внутренних рабочих приложений и редактирования профессиональных документов. Масштабирование возможностей продукта стало ответом на жёсткую конкурентную борьбу между OpenAI и Anthropic за привлечение бизнес-клиентов перед возможным выходом компаний на биржу уже в этом году. Ранее стартап Anthropic первым выпустил плагины для финансовых услуг и юридических задач, чем обеспокоил инвесторов традиционных компаний по разработке программного обеспечения. В свою очередь в OpenAI отметили необходимость смещения фокуса с потребительского сегмента на корпоративный с целью получения половины общей выручки от бизнес-пользователей к концу текущего года. Изначально оба технологических гиганта обеспечили себе устойчивый рост за счёт продажи передовых ИИ-инструментов для оптимизации разработки программного обеспечения. Запущенный в прошлом году Codex уже насчитывает более 5 миллионов еженедельных пользователей, среди которых пятая часть не являются профессиональными разработчиками. Anthropic выпустила ИИ-модель Claude Opus 4.8 — она не пытается скрыть свою некомпетентность в вопросах, в которых не разбирается
29.05.2026 [06:46],
Анжелла Марина
Компания Anthropic выпустила Opus 4.8 — новейшую версию своей самой продвинутой публичной модели. Вместе с ней разработчики представили функцию Dynamic Workflows, которая позволит Opus и другим моделям управлять сложными задачами, распределёнными между сотнями параллельных субагентов. Об этом сообщил TechCrunch. 
Источник изображения: Anthropic Opus 4.8 появилась через 41 день после релиза Opus 4.7, что оказалось значительно быстрее обычного цикла обновлений Anthropic (предыдущие модели Sonnet и Haiku выходили с интервалом в три и семь месяцев соответственно). Ускоренный выпуск, как предполагается, связан с прохладным приёмом Opus 4.7, которую некоторые пользователи сочли разочаровывающей. За тот же период конкуренты в лице OpenAI с моделью Codex и Google с Gemini Flash также представили значительные обновления, усиливая давление на Anthropic. Ключевым улучшением Opus 4.8 стала работа с некорректными или неопределёнными данными. Первые тестировщики обнаружили, что новая модель «чаще сообщает о неуверенности в результатах своей работы и реже делает необоснованные заявления». Эффективность модели подтвердили и в инвестиционной компании Bridgewater Associates. По словам представителей, главное отличие обновлённой версии заключается в том, что нейросеть активно указывает на проблемы во входных и выходных данных, которые другие алгоритмы обычно не замечают, вынуждая пользователей самостоятельно искать ошибки. Вместе с новой моделью Anthropic запустила функцию Dynamic Workflows в формате исследовательского превью. Система предназначена для того, чтобы крупные модели (например, Opus) управляли сложными задачами через сотни параллельных субагентов. Как поясняют в компании, благодаря этому нововведению, связка из Claude Code и модели Opus 4.8 сможет «выполнять миграцию сотен тысяч строк кода от этапа запуска до слияния, опираясь на существующий набор тестов в качестве ограничителя». Одновременно разработчики продолжают подготовку к полноценному запуску модели Mythos, ранний доступ к которой в прошлом месяце вызвал опасения в использовании её киберпреступниками. В Anthropic подчеркнули, что активно решают вопросы защиты Mythos и ожидают внедрения моделей класса Mythos для всех клиентов уже в ближайшие недели. xAI теряет популярность, но Илон Маск ещё может вернуть стартап в гонку
12.05.2026 [09:34],
Алексей Разин
Представители OpenAI убеждены, что судебные претензии со стороны Илона Маска (Elon Musk) направлены на укрепление рыночных позиций его собственного стартапа xAI, основанного в 2023 году и недавно присоединённого к SpaceX. Независимая статистика говорит о снижении популярности xAI, но эксперты убеждены, что при наличии мотивации Маск способен всё исправить. 
Источник изображения: Unsplash, Мария Шалабаева В начале мая xAI заключила с Anthropic соглашение о сдаче в аренду вычислительных мощностей Colossus 1, которые xAI изначально планировала использовать для собственных нужд. Это может указывать на замедление темпов развития xAI и разработанного ею чат-бота Grok. Статистика AppMagic, на которую ссылается The Wall Street Journal, указывает на снижения количества скачиваний приложения Grok до 8,3 млн по итогам апреля против более чем 20 млн скачиваний в январе. Данные Recon Analytics гласят, что из более чем 260 000 американских пользователей ИИ-сервисов только 0,174 % в текущем квартале оплачивали подписку на Grok. Это почти столько же, как и годом ранее, и значительно меньше 6 %, соответствующих доле платных подписчиков конкурирующего ChatGPT. Сам Илон Маск в ходе своих апрельских судебных показаний назвал xAI «самой маленькой из ИИ-компаний». Для Grok проблемой остаётся отдалённость от нужд корпоративных пользователей, тогда как OpenAI и Anthropic активно развивают функции содействия ИИ в написании программного кода и автоматизации рутинных офисных задач при помощи ИИ-агентов. Опрос Enterprise Technology Research показал, что по итогам марта этого года 7 % корпоративных респондентов уже используют Grok или собираются это сделать. Годом ранее их доля не превышала 4 %, и хотя положительная динамика очевидна, в случае с Claude показатель вырос с 21 до 48 %, а у Google Gemini он увеличился с 27 до 40 %. При этом некоторые участники рынка верят, что Илон Маск ещё способен исправить ситуацию, если сконцентрируется на этой задаче. Он уже провёл в xAI серьёзную реорганизацию, и она может стать первым этапом реванша. Клиенты в стремительно меняющемся сегменте ИИ слабо привязаны к какой-то конкретной платформе. Если тот же Grok внезапно начнёт демонстрировать более впечатляющие результаты на форме конкурентов, то его популярность возрастёт довольно быстро. Anthropic обновила Claude Code: добавлены новый интерфейс и автономный режим
15.04.2026 [06:55],
Анжелла Марина
Компания Anthropic внедрила функцию повторяющихся автоматизированных задач (Routines) в переработанное приложение Claude Code для macOS. Эта возможность, запущенная пока в тестовом режиме для исследовательских целей, позволяет выполнять запланированные действия через веб-инфраструктуру сервиса независимо от статуса подключения компьютера пользователя к сети. 
Источник изображения: Anthropic Новая функция, как сообщает 9to5Mac, берёт на себя управление регулярными задачами, такими как cron-джобы (cron jobs) и работа с API, избавляя разработчиков от необходимости самостоятельно настраивать дополнительную инфраструктуру. Сценарии выполняются на стороне сервера Anthropic, имея прямой доступ к репозиториям и коннекторам пользователя, обеспечивая, таким образом, их работу даже когда Mac находится офлайн. В качестве примеров использования компания приводит настройку расписаний, рабочих процессов API и интеграцию с GitHub. Доступность новой функции зависит от выбранного тарифного плана подписки. Пользователи уровня Pro могут запускать до 5 рутин в день, тариф Max увеличивает этот лимит до 15, а корпоративные клиенты (Team и Enterprise) получают возможность выполнять до 25 задач ежедневно. Помимо автоматизации, Anthropic существенно обновила интерфейс самого приложения Claude Code на Mac. Теперь можно открывать несколько сессий одновременно в одном окне, используя новую боковую панель, что упрощает многозадачность. Обновлённый дизайн также включает встроенный терминал, инструменты для редактирования файлов и предварительного просмотра HTML и PDF-документов. Интерфейс стал более гибким: элементы можно перетаскивать и устанавливать на рабочем столе согласно предпочтениям разработчика. Все эти изменения дополняют другие недавние нововведения экосистемы, например, режим автопилота (auto mode), представленный в прошлом месяце. Также из стадии исследовательского тестирования вышел продукт Claude Cowork, получивший новые функции для корпоративного сегмента. Инвесторы усомнились, что OpenAI действительно стоит $852 млрд — компания пытается исправить впечатление
14.04.2026 [11:02],
Алексей Разин
Возросшую активность OpenAI в сфере пересмотра стратегии и концентрации на приоритетных направлениях деятельности принято связывать с подготовкой к IPO. Последний раунд частного размещения позволил поднять капитализацию стартапа до $852 млрд, но не все инвесторы единодушны в подобной оценке. При этом чувствуется, что высокая конкуренция заставляет руководство OpenAI спешно устранять слабые места в своей стратегии. 
Источник изображений: OpenAI Обширный материал на эту тему опубликовало издание Financial Times. Стремление OpenAI переключиться на обслуживание корпоративных клиентов усиливает конкуренцию с Anthropic, и нельзя утверждать, что в этом сегменте преимущество на стороне первого из стартапов. Google также агрессивно действует в корпоративном сегменте рынка ИИ, поэтому для OpenAI концентрация на нём формирует новые вызовы. Один из ранних инвесторов в OpenAI заявил Financial Times: «У вас есть ChatGPT, растущий на 50–100 % ежегодно бизнес с миллиардной пользовательской аудитории, так почему же вы говорите о предприятиях и написании кода? Эта компания очень сильно расфокусирована». В прошлом месяце OpenAI привлекла $122 млрд, которые предоставила группа из 25 крупных стратегических и институциональных инвесторов, включая SoftBank, Amazon и Nvidia, и около $3 млрд впервые были получены от частных инвесторов. По мнению руководства OpenAI, превышение спросом предложения в рамках этого раунда финансирования и рекордная сумма привлечения средств доказывают, что интерес инвесторов к деятельности компании и их доверие по-прежнему высоки. Руководство OpenAI даже предприняло попытки «разоблачить» конкурирующую Anthropic в некорректном отображении приведённой годовой выручки, которая на конец марта в последнем случае оценивалась в $30 млрд. Как подчёркивает директор OpenAI по выручке Дениз Дрессер (Denise Dresser), эта сумма завышена примерно на $8 млрд за счёт частичного переноса профильной выручки, получаемой Amazon и Google. Сама OpenAI на конец февраля располагала приведённой годовой выручкой в размере $25 млрд. Дрессер признаёт, что ранняя концентрация на корпоративном рынке дала Anthropic определённое преимущество, но в OpenAI убеждены, что смогут завоевать этот рынок. К концу текущего года до половины всей выручки стартап рассчитывает получать именно с корпоративных клиентов.  Некоторые инвесторы OpenAI признались, что выделяя средства на нужды стартапа сейчас, они исходили из оценки его капитализации в размере $1,2 трлн по итогам IPO. При этом Anthropic сейчас оценивается в $380 млрд, и некоторым потенциальным инвесторам капитализация OpenAI на текущих уровнях кажется завышенной. С такими аппетитами, по мнению некоторых инвесторов, OpenAI рискует оказаться на «спорной территории» с точки зрения привлечения капитала. Косвенные данные позволяют судить, что спрос на инвестиции в капитал Anthropic сейчас выше, чем в случае с OpenAI. Инвесторы впервые готовы больше переплачивать, вкладывая средства в Anthropic, чем в OpenAI. Существует определённый беспорядок в использовании компанией OpenAI привлечённых средств. Две недели назад стартап за несколько сотен миллионов долларов США купил канал TBPN, хотя такая сделка в медийной сфере вызвала вопросы. Руководство предпочло парировать заявлениями о том, что TBPN не будет отвлекать на себя вычислительные ресурсы. Закрытие генератора видео Sora оставило OpenAI без средств Disney, которая должна была вложить $1 млрд. Microsoft пригрозила OpenAI иском после заключения последней из компаний сделки с Amazon на $50 млрд. Реализация мегапроекта Stargate тоже продвигается в усечённом варианте: отменено строительство ЦОД в Великобритании за $30 млрд, площадка в Техасе будет расширяться не так активно, как планировалось изначально. Nvidia также в пять раз сократила масштабы своей сделки с OpenAI, которая сперва подразумевала инвестиции в размере $100 млрд. Впрочем, OpenAI всё равно планирует до конца года увеличить численность персонала в два раза до 8000 человек и довести долю выручки на корпоративном направлении до 50 % от совокупной. В Лондоне со следующего года расположится крупнейший исследовательский центр компании за пределами США. Руководство OpenAI недавно сообщило инвесторам, что располагает доступом к 8 ГВт вычислительных мощностей, тогда как Anthropic на этот уровень ранее конца 2027 года не выйдет, а к 2030 году сама OpenAI рассчитывает располагать доступом к 30 ГВт вычислительных мощностей. Anthropic то и дело сталкивается со сбоями в работе инфраструктуры и нехваткой вычислительных мощностей. В OpenAI утверждают, что даже если их модели и отстают от созданных Anthropic, они хотя бы могут стабильно работать. Представители Anthropic пояснили, что компания будет придерживаться разумного подхода к масштабированию вычислительных мощностей. OpenAI меняет приоритеты в своём развитии. Помимо отказа от сервиса генерации видео Sora, компания свернула проект по запуску чат-бота с эротическим уклоном. Теперь прилагаются усилия по продвижению сервиса Codex в корпоративной среде, который призван упростить жизнь разработчикам ПО. Некоторые знакомые с планами OpenAI источники даже утверждают, что Codex может оказаться самым главным направлением бизнеса стартапа, обойдя ChatGPT. По крайней мере, этот вид деятельности обеспечивает значительно более высокую прибыль. Некоторые инвесторы приветствуют такие преобразования в стратегии OpenAI, другие опасаются, что все эти метания говорят об отсутствии чётко обозначенных целей. В любом случае, привлекать инвестиции OpenAI это пока не мешает. Основатель DeepSeek назвал дату выхода флагманской модели V4
12.04.2026 [07:47],
Анжелла Марина
Основатель компании DeepSeek Лян Вэньфэн (Liang Wenfeng) подтвердил в ходе внутреннего общения с сотрудниками, что флагманская модель следующего поколения DeepSeek V4 будет официально представлена в конце апреля 2026 года. По сообщению AIBase, система впервые получит многоуровневый режим работы, а релиз совпадёт с выходом конкурирующей модели Tencent. Источник изображения: AI Быстрый режим (Fast Mode) ориентирован на повседневные диалоги и мгновенные ответы, поддерживает распознавание текста на изображениях и в файлах с акцентом на скорость работы. Экспертный режим (Expert Mode) разработан для решения задач со сложной логикой и глубоким анализом, обладает усиленными возможностями интеллектуального поиска. Однако этот режим пока не поддерживает загрузку файлов и мультимодальные функции, а в часы пик может потребоваться ожидание. 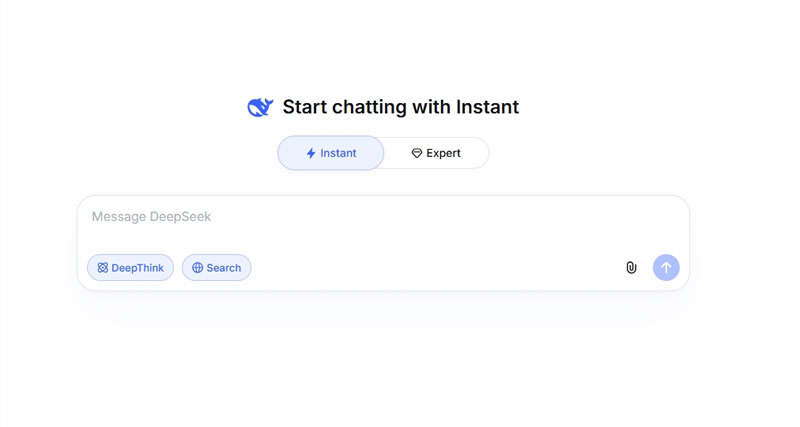
Источник изображения: aibase.com Несмотря на приближающийся релиз новой модели, текущая ситуация в DeepSeek характеризуется контрастами. Пользователи отметили существенные улучшения в логической обработке данных и возможностях программирования. Однако платформа три дня подряд испытывает масштабные технические сбои, включая один сбой продолжительностью до 12 часов. Эксперты отрасли рассматривают это как «болезненный период» переходного этапа между старой и новой моделями. Дата релиза DeepSeek V4 выбрана в условиях высокой конкуренции. Команда Яо Шунью (Yao Shunyu) в Tencent также планирует выпустить новую модель под названием Hunyuan в следующем месяце. Таким образом, конец апреля станет временем прямого соперничества между двумя ведущими китайскими разработчиками базовых ИИ-моделей, что может повлиять на расстановку сил в индустрии. Intel и SambaNova запустили продукт, способный потеснить Nvidia в ИИ-сегменте
09.04.2026 [06:45],
Анжелла Марина
Компании Intel и SambaNova анонсировали готовую к производству гетерогенную архитектуру для ИИ-инференса, которая распределяет задачи между разными типами оборудования. Платформа использует графические процессоры для предварительной обработки, специализированные модули SambaNova для генерации токенов и процессоры Xeon 6 для управления агентскими задачами. 
Источник изображения: Meta✴✴ Разработанная система разделяет процесс логического вывода на отдельные этапы, где каждый тип чипа выполняет свою специфическую функцию. Графические ускорители или ИИ-акселераторы занимаются первичной обработкой длинных запросов (ingest) и созданием кешей ключ-значение, в то время как реконфигурируемые блоки данных SN50 от SambaNova отвечают за декодирование. В свою очередь процессоры Intel Xeon 6 координируют распределение нагрузки и выполняют операции, связанные с ИИ-агентами, такие как компиляция кода и валидация результатов. Это позволит охватить максимально широкий спектр рабочих нагрузок и конкурировать с Nvidia и другими игроками рынка. 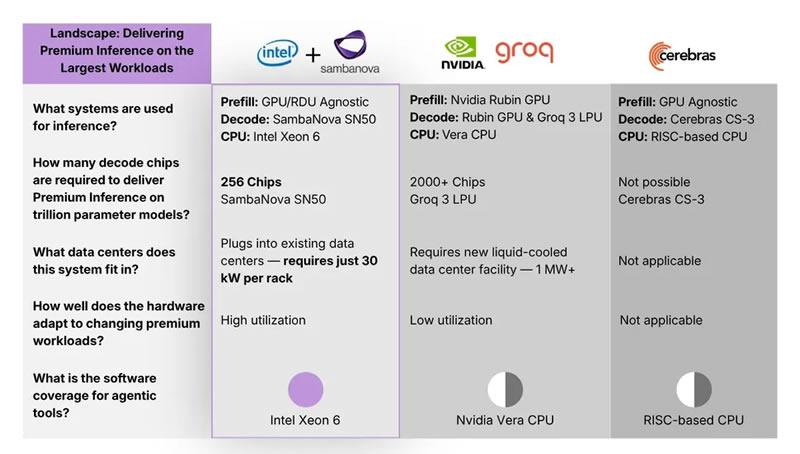
Источник изображения: SambaNova Такой подход к разделению prefill, decode и генерации токенов, как отмечает Tom's Hardware, перекликается со стратегией Nvidia в её будущей платформе Rubin, где аналогичные функции должны были распределяться между чипами Rubin CPX и Rubin GPU. Однако ключевое отличие в том, что решение Nvidia пока не вышло на рынок, тогда как Intel и SambaNova смогут предложить готовую к внедрению архитектуру уже во второй половине 2026 года. По внутренним оценкам SambaNova, процессоры Xeon 6 ускоряют компиляцию LLVM более чем на 50 % по сравнению с серверными чипами на архитектуре Arm. Кроме того, их производительность в задачах с векторными базами данных на 70 % превышает показатели конкурирующих x86-решений, таких как AMD EPYC. По словам представителей компаний, такой прирост эффективности достигается за счёт оптимизации взаимодействия между компонентами системы и позволяет существенно сократить циклы разработки кодирующих агентов и других ИИ-приложений полностью собственными силами. Ключевым преимуществом новой архитектуры стала её полная совместимость с существующей инфраструктурой дата-центров, поддерживающих мощность до 30 кВт. Это позволяет предприятиям внедрять решение без необходимости масштабной модернизации систем охлаждения и энергоснабжения. Ожидается, что платформа станет доступна для корпоративных клиентов, облачных операторов и национальных государственных инициатив в области искусственного интеллекта во второй половине 2026 года. Исполнительный вице-президент и генеральный директор группы центров обработки данных (DCG) Intel Кеворк Кечичян (Kevork Kechichian) отметил, что экосистема программного обеспечения дата-центров исторически построена на x86, что гарантирует, по его мнению, Xeon роль надёжного фундамента для будущих гетерогенных вычислений. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



