|
Опрос
|
реклама
Быстрый переход
Google планирует за пару лет расширить выпуск ИИ-чипов TPU до 12–15 млн в год — прямо как Nvidia
31.07.2026 [16:39],
Павел Котов
Google в ближайшие годы намеревается резко нарастить производство собственных чипов для искусственного интеллекта и выйти на уровень производства компании Nvidia. По неофициальной информации, в 2028 году Google рассчитывает развернуть от 12 млн до 15 млн новейших ускорителей TPU v9. 
Источник изображения: cloud.google.com Если эти цифры подтвердятся, Google действительно достигнет показателей Nvidia: по оценкам аналитиков, в течение 2026 года Nvidia поставит 8,2 млн графических процессоров для центров обработки данных, и к 2028 году этот показатель может вырасти до 12,4 млн. Таким образом, один облачный провайдер готов выпускать ИИ-ускорители в объёмах, сопоставимых с ведущим поставщиком коммерческих чипов. В Google TPU девятого поколения, которые дебютируют как раз в 2028 году, будут использоваться четыре вычислительных кристалла, что соответствует общеотраслевому тренду на чиплетную компоновку; запланированный объём производства, как ожидается, более чем вдвое превысит потребности по сравнению с уровнем 2027 года. Размещение нескольких больших кристаллов на одном чипе требует передовых технологий межсоединений и упаковки, а их выпуск в больших масштабах усложняет задачу. Ограничивающим фактором грозят стать производственные мощности: TSMC в одиночку с таким заказом не справится, и, возможно, придётся подключать производственное подразделение Intel. Технологии упаковки у разных производителей отличаются, и используемые Intel EMIB или EMIB-T не имеют прямой совместимости с CoWoS-L. Google разрабатывает собственные чипы уже около десяти лет, и их роль в инфраструктуре увеличивается. Первоначально это был способ поддержать рабочие нагрузки, а сейчас речь идёт о широкой стратегии облачного бизнеса. Если Google в 2028 году достигнет своей цели, она может стать крупнейшим пользователем ИИ-ускорителей. Это не значит, что закупки у Nvidia придётся прекратить, но у Google будет значительно больше контроля над собственный вычислительной инфраструктурой и поставками. Сравнительных тестов Google TPU девятого поколения с Nvidia Rubin и Rubin Ultra пока нет. Масштаб планов поискового гиганта указывает, что конкуренция на рынке оборудования для ИИ всё больше зависит от объёмов развёртывания, а не только от производительности чипов. Huawei впервые бросит вызов Nvidia за пределами Китая — ИИ-ускорители Ascend появятся в Южной Корее
07.07.2026 [18:58],
Павел Котов
В четвёртом квартале 2026 года Huawei планирует выйти на южнокорейский рынок ускорителей искусственного интеллекта — компания предложит клиентам ИИ-процессоры серии Ascend 950 и вычислительную платформу Atlas 950 SuperPod, передаёт ETNews.  Это будет первый значительный шаг Huawei на одном из крупнейших зарубежных рынков ИИ-ускорителей для Nvidia. Китайская компания намеревается предложить более низкие цены — её оборудование позиционируется как альтернатива для клиентов, которые стремятся снизить свою зависимость от американского производителя чипов. В линейку продуктов для корейского рынка Huawei включит новейшие нейропроцессоры Ascend 950PR и Ascend 950DT. Первый запущен в серийное производство в апреле и предназначен для инференса ИИ; второй разработан для задач обучения ИИ и планируется к выпуску в IV квартале. Оба процессора дебютируют в Корее вместе с Atlas 950 SuperPod — интегрированной платформой для вычислений в области ИИ, которая может масштабироваться до 8192 процессоров Ascend в одной системе. Филиал Huawei Korea уже заключил генеральные дистрибьюторские соглашения с двумя местными партнёрами: Hansol PNS и своим давним партнёром SK Shieldus. Уже стартовала подготовка к коммерциализации: техническое обучение, разработка ценовой политики, маркетинговых стратегий и локализованного брендинга для корейского рынка. Корейскую кампанию Huawei выстраивает на агрессивной ценовой политике и высокой вычислительной производительности оборудования. Китайский электронный гигант утверждает, что Ascend 950PR примерно в 2,87 раза производительнее Nvidia H20 в задачах ИИ, но при этом вчетверо дешевле. ИИ-ускоритель H20 разрабатывался для Китая, но попал под санкции Вашингтона как слишком производительный. Huawei признаёт, что её чип уступает флагманскому Nvidia H200, но разрыв можно сократить, объединив несколько тысяч процессоров Ascend в кластер на платформе Atlas 950. В серии Ascend 950 используется собственная высокоскоростная память (HBM) Huawei, а не чипы зарубежных производителей. В случае 950PR это Huawei HiBL 1.0, а в 950DT — HiZQ 2.0. Флагманские ускорители Nvidia оцениваются в десятки тысяч долларов за единицу, и продукция, которая вчетверо дешевле H20, даст корейским клиентам реальный повод задуматься об альтернативе. Huawei также заявила, что повысила совместимость своего программного стека Compute Architecture for Neural Networks (CANN) с Nvidia CUDA, чтобы упростить разработчикам миграцию. В 2013 году Huawei добилась успеха, выведя на корейский рынок своё оборудование для сетей LTE. Отраслевые эксперты, однако, прогнозируют, что на этот раз всё будет несколько сложнее: сдерживающими факторами станут репутация китайских технологий, вопросы безопасности, энергопотребление и тепловыделение, а также привязка к поставщику. В Корее есть и собственная отрасль ИИ-ускорителей, представленная в основном стартапами, и для них Huawei станет серьёзным конкурентом. Baikal обещает к 2030 году выпустить «основу суверенных дата-центров» — отечественные ИИ-чипы, совместимые с Nvidia CUDA
19.05.2026 [09:54],
Павел Котов
Российская Baikal Electronics анонсировала на конференции ЦИПР 2026 в Нижнем Новгороде собственные решения для систем искусственного интеллекта: два ускорителя и серверный комплект с процессорами нового поколения. 
Источник изображений: t.me/anti_agi Старший ускоритель получил название Baikal BE-AI-D1000 — он предназначен для работы на серверах и в центрах обработки данных, выступая в одном классе с представленным в 2023 году NVIDIA L40S. Производительность компонента составляет 1000 Тфлопс (FP8) и 500 Тфлопс (FP16); прочих подробностей в данном аспекте разработчик пока не приводит. Объем памяти составляет от 48 до 64 Гбайт, причём это GDDR, а не высокоскоростная HBM. 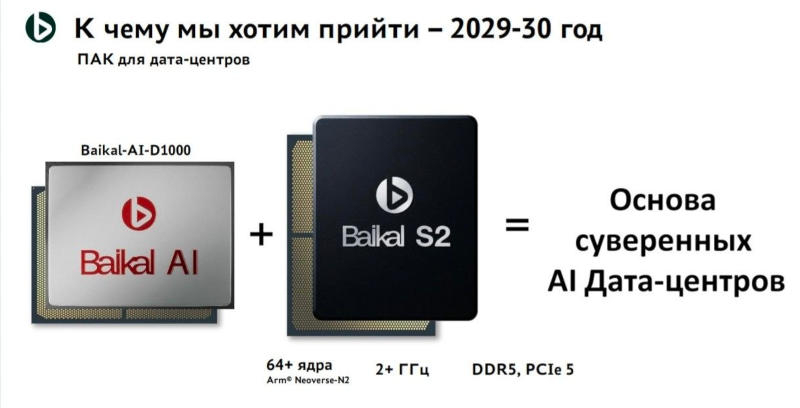 В Baikal не раскрыли, в каком формате исполнен ИИ-ускоритель, неизвестны и механизмы масштабирования — собственный аналог NVLink или открытый UALink. Известно, однако, что стоимость одного ускорителя составит около $10 000. Обещана совместимость с архитектурой CUDA, возможно, через слой трансляции ZLUDA — это позволит штатными средствами запускать PyTorch, TensorFlow и другие популярные фреймворки. Ещё одно нововведение — комплексное серверное решение, сочетающее графический и центральный процессоры. В качестве центрального выступает новый Baikal S2 на архитектуре Arm Neoverse N2, выпущенной в 2020 году. Речь идёт о своего рода отечественном аналоге Nvidia DGX. Разработку ускорителя Baikal ведёт совместно с российскими технологическими гигантами, корректируя проект по обратной связи. Эксперты указывают, что проекты имеют ощутимые перспективы наравне с проектами отечественных базовых станций для операторов мобильной связи. Выпуск продуктов намечен на 2029–2030 гг. Китайские ИТ-гиганты ускорили переход на отечественные ИИ-ускорители, несмотря на возможное возвращение Nvidia
16.05.2026 [11:02],
Владимир Фетисов
Производство китайских ускорителей для ИИ может вырасти в этом году, поскольку крупнейшие технологические компании страны стремятся внедрить больше отечественных технологий. Это происходит на фоне сообщений о возможном возвращении на рынок Китая продукции американской Nvidia. 
Источник изображения: Maxence Pira / unsplash.com На этой неделе интернет-гигант Tencent объявил, что ожидает активизации производства отечественной полупроводниковой продукции, а гигант электронной коммерции Alibaba сообщил об увеличении масштабов использования ускорителей собственной разработки. Эти сообщения подчёркивают, что в отсутствие на рынке Китая передовых чипов Nvidia из-за экспортных ограничений со стороны США страна активно продвигает отечественные разработки для реализации собственных амбиций в сфере искусственного интеллекта. Директор по стратегическому развитию Tencent Джеймс Митчелл (James Mitchell) заявил, что компания планирует «существенное увеличение» капитальных затрат, особенно во второй половине года, поскольку китайские ускорители «доступны нам из месяца в месяц». Он также добавил, что поставки графических ускорителей китайской разработки будут постепенно наращиваться в течение года. В дополнение к этому было сказано, что объём поставок китайских ускорителей растёт как за счёт производственных мощностей внутри КНР, так и за счёт предприятий в соседних странах. В Китае существует множество местных производителей чипов, которые активизировались за счёт выхода на биржу и запуска новых продуктов. В число компаний, которые пытаются заполнить вакуум, образовавшийся после введения экспортных ограничений со стороны США, входят Moore Threads, MetaX и Huawei. Это послужило основой для того, чтобы выручка китайских производителей чипов достигла рекордных показателей. Alibaba разрабатывает собственные ИИ-ускорители, которые использует в своих центрах обработки данных, являющихся основой облачного бизнеса компании. «Собственные ускорители от T-Head достигли стадии массового производства. В условиях нехватки вычислительных ресурсов это структурное преимущество благоприятно сказывается на росте нашей выручки и увеличении валовой маржи»,— заявил представитель Alibaba во время объявления финансовых результатов по итогам квартала. Alibaba также дала понять, что компания может поставлять серверы на базе собственных ускорителей другим игрокам, строящим вычислительные кластеры или центры обработки данных. Также не исключается вариант совместного строительства таких объектов, что подчёркивает растущую роль технологического гиганта в китайской полупроводниковой отрасли. Заявления Alibaba и Tencent прозвучали за день до того, как появились сообщения о том, что США дали зелёный свет нескольким китайским компаниям, включая Alibaba и Tencent, на покупку ускорителей Nvidia H200, входящих в число наиболее производительных ИИ-ускорителей на рынке. Однако официального подтверждения этого до сих пор не было. «Для меня это новость. Я знаю, что было много споров <…> и нам придётся посмотреть на это. Это функция министерства торговли», — прокомментировал данный вопрос министр финансов США Скотт Бессент (Scott Bessent). За последний год СМИ неоднократно писали о том, что Вашингтон дал разрешение Nvidia на поставку в Китай не самых мощных ИИ-ускорителей, таких как H20. Параллельно с этим сообщалось, что власти Китая поощряют местные компании за использование отечественных альтернатив. Аналитики Counterpoint Research считают, что по мере продвижения китайских компаний к агентному ИИ им потребуются более производительные ускорители, за счёт чего ускорители Nvidia H200 будут востребованы. Alibaba похвалилась выпуском 500 000 ИИ-ускорителей и признала, что они медленнее аналогов Nvidia
20.03.2026 [16:44],
Павел Котов
Руководство китайского технологического гиганта Alibaba подтвердило, что полупроводниковое подразделение компании произвело почти 500 000 чипов, в том числе для ускорителей искусственного интеллекта, но все они отстают от продукции Nvidia. 
Источник изображения: alibabagroup.com Входящий в Alibaba производитель полупроводников T-Head недавно провёл конференцию по итогам III квартала 2026 финансового года, в ходе которой его гендиректор Ёнмин Ву (Yongming Wu) сообщил, что компания выпустила почти 470 000 чипов, в том числе трёх моделей, разработанных специально для рабочих нагрузок искусственного интеллекта: XuanTie C908, TH1520 и Pingtouge Zhenwu 810E. Это значит, что Alibaba действительно наладила мощное производство полупроводников — для сравнения, за год выпущены 6 млн чипов Nvidia Blackwell. Но одной только производственной мощностью всех задач решить не получится — китайские ИИ-ускорители от Alibaba T-Head уступают американской продукции, и в компании с этим не спорят. «Учитывая, что наши чипы всё ещё отстают от зарубежных аналогов по производительности в различных аспектах, мы стремимся углубить совместное проектирование с облачной инфраструктурой Alibaba и моделью Qwen для повышения эффективности. <..> Это одно из ключевых отличий и наш подход к проектированию чипов в T-Head, который выделяет нас среди прочих компаний — производителей чипов. Наша основная цель — создать систему ИИ с превосходным соотношением цены и качества», — отметил Ёнмин Ву. Meta✴ провалила создание собственного ИИ-чипа, потому что это «слишком сложно» и кругом «технические проблемы»
28.02.2026 [10:56],
Павел Котов
Meta✴✴ столкнулась со сложностями при разработке собственных ускорителей для систем искусственного интеллекта и была вынуждена отказаться от самого передового проекта в пользу менее сложного варианта. Об этом сообщил ресурс The Information со ссылкой на осведомлённые источники. 
Источник изображений: Igor Omilaev / unsplash.com На минувшей неделе Meta✴✴ отказалась продолжать работу над наиболее передовым ускорителем для обучения моделей ИИ, потому что столкнулась с трудностями при его проектировании и техническими проблемами; руководство компании проинформировало работников отдела инфраструктуры об изменении планов. Компания пересмотрела дорожную карту, имея множество запасных вариантов. Она заключила многомиллиардную сделку по аренде ИИ-ускорителей TPU у Google; инициировала партнёрский проект в области ускорителей AMD Instinct суммарной мощностью до 6 ГВт; а также объявила о намерении закупать ИИ-ускорители Nvidia текущего и перспективных поколений. Собственные чипы компания разрабатывает в рамках программы Meta✴✴ Training and Inference Accelerator (MTIA) — она призвана снизить затраты и усилить контроль над инфраструктурой центров обработки данных. «Мы по-прежнему привержены инвестициям в диверсифицированный портфель чипов для удовлетворения наших потребностей, что включает в себя развитие нашего портфеля MTIA, и в этом году мы поделимся свежей информацией», — прокомментировал происходящее представитель Meta✴✴. Компания отказалась от одной из версий своего чипа второго поколения для обучения ИИ, проходящего внутри Meta✴✴ под кодовым наименованием Iris, затем она начала работать над более совершенным чипом, которому присвоили название Olympus, но теперь отказалась и от него.  В Meta✴✴ назрело скептическое отношение к возможности создать собственные ИИ-ускорители, сопоставимые по возможностям с чипам Nvidia, признался один из разработчиков Meta✴✴ — всё дело в рисках задержек или вынужденных доработок проектов. Работа требует большой команды инженеров для проектирования, отладки чипов и обеспечения их невысокого энергопотребления, в результате чего продукты Nvidia оказываются более целесообразными. В основу предназначенного для обучения ИИ-ускорителя Iris легла технология пакетной обработки параллельных данных SIMD (Single Instruction, multiple data) — они легче в проектировании, но для них труднее писать ПО. В ускорителе Olympus использовался принятый Nvidia подход SIMT (Single Instruction, Multiple Threads), при котором множество потоков выполняет одну инструкцию, сохраняя логическую независимость. Такие чипы сложнее в проектировании, но под них проще писать ПО для обучения ИИ-моделей. Некоторые технологические компании предпочитают второй подход по образцу Nvidia, потому что он обеспечивает более высокую гибкость и лучше адаптирован для обучения современных моделей ИИ. Meta✴✴ планировала завершить разработку Olympus не раньше IV квартала 2026 года, но в действительности потребовались бы не менее девяти месяцев до передачи проекта в массовое производство. Основу архитектуры Olympus должны были составить наработки стартапа Rivos, поглощённого Meta✴✴ в минувшем году, — они совместимы с ПО Nvidia CUDA, наиболее популярным в обучении и запуске моделей ИИ. Meta✴✴ планировала разработать большие кластеры серверов на чипах Olympus, но руководство компании увидело в этом угрозу для обучения новых моделей в условиях конкуренции с OpenAI и Google. ПО для собственных ускорителей было бы менее стабильным, чем у Nvidia, а сложная архитектура Olympus могла бы затруднить его массовое производство. Поэтому пока Meta✴✴ намерена использовать в обучении ИИ ускорители партнёров, к которым прилагается более развитое и стабильное ПО. Microsoft представила Maia 200 — фирменный 3-нм ИИ-ускоритель с 216 Гбайт HBM3e
26.01.2026 [23:33],
Николай Хижняк
Компания Microsoft представила новейший ускоритель ИИ собственной разработки — Azure Maia 200. Новый чип является следующим поколением линейки серверных графических процессоров Microsoft Maia, предназначенных для выполнения задач вывода моделей ИИ с высокой скоростью и производительностью, превосходящей предложения от таких крупных конкурентов, как Amazon и Google. 
Источник изображения: Microsoft Maia 200 позиционируется как самая эффективная система вывода от Microsoft из когда-либо развёрнутых. Во всех пресс-релизах компании акцент делается как на высоких показателях производительности, так и на заявлениях о приверженности Microsoft принципам защиты окружающей среды. Компания утверждает, что Maia 200 обеспечивает на 30 % большую производительность на доллар, чем Maia 100 первого поколения, что весьма впечатляет, учитывая, что новый чип также имеет на 50 % более высокое значение TDP, чем его предшественник. Maia 200 построен на 3-нм техпроцессе TSMC и содержит 140 млрд транзисторов. Он, как утверждается, способен обеспечивать до 10 петафлопс производительности в вычисления FP4, что в три раза выше, чем у конкурента от Amazon — Trainium3. Maia 200 оснащён 216 Гбайт памяти HBM3e с пропускной способностью 7 Тбайт/с, а также имеет 272 Мбайт встроенной памяти SRAM. 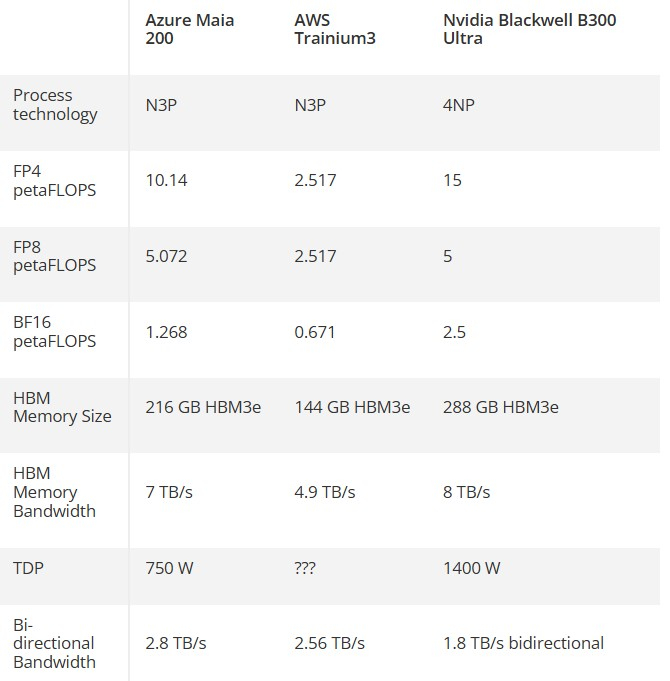
Источник изображения: Tom's Hardware Из сравнительной таблицы выше, подготовленной порталом Tom’s Hardware, видно, что Maia 200 демонстрирует явное превосходство в вычислительной мощности по сравнению с решением компании Amazon и по некоторым показателям соответствует ИИ-ускорителю B300 Ultra от Nvidia. Очевидно, что сравнивать их как прямых конкурентов бессмысленно. Покупатели не могут приобрести Maia 200 напрямую, а Blackwell B300 Ultra оптимизирован для гораздо более ресурсоёмких задач, чем чип Microsoft. Кроме того, программный стек Nvidia предоставляет B300 значительное преимущество перед любыми другими конкурентами. Однако Maia 200 превосходит B300 по эффективности, что является большим достижением в эпоху, когда обеспокоенность общественности негативным воздействием ИИ на окружающую среду неуклонно растёт. Maia 200 работает при почти вдвое меньшем TDP, чем B300 (750 против 1400 Вт). И если новый ИИ-ускоритель Microsoft похож по энергоэффективности на предшественника Maia 100, то он, как и предшественник, будет работать ниже своего теоретического максимального TDP. Для Maia 100 был заявлен TDP на уровне 700 Вт, но Microsoft утверждает, что в рабочем режиме его энергопотребление составляет всего 500 Вт. Maia 200 оптимизирован для работы с вычислениями 4-битной (FP4) и 8-битной (FP8) точности с плавающей запятой. Он ориентирован на клиентов, которые работают с ИИ-моделями, требующими производительности FP4, а не для более сложных операций. Как предполагает Tom’s Hardware, значительная часть бюджета Microsoft на исследования и разработки этого чипа была направлена на иерархию памяти, использующуюся внутри его 272 Мбайт высокоэффективной SRAM-памяти. Последняя разделена на «многоуровневую кластерную SRAM (CSRAM) и плиточную SRAM (TSRAM)», что обеспечивает повышенную эффективность работы и философию интеллектуального и равномерного распределения рабочей нагрузки по всем кристаллам HBM и SRAM. Сообщается, что ИИ-процессоры Maia 200 уже развёрнуты в центральном дата-центре Microsoft в США (Azure), а в будущем их развёртывание планируется в западном дата-центре (Финикс, Аризона). Чипы станут частью гетерогенной инфраструктуры Microsoft, работая в тандеме с другими различными ускорителями ИИ. Китайский ответ Nvidia: Moore Threads представила игровые GPU Lushan и ИИ-ускорители Huashan — и они кратно быстрее прежних
20.12.2025 [15:31],
Павел Котов
Китайский производитель чипов Moore Threads представил два новых графических процессора: предназначенный для игр Lushan и ориентированный на задачи искусственного интеллекта Huashan — в обоих случаях обещан значительный прирост скорости в сравнении с графикой предыдущего поколения у того же производителя, сообщает Wccftech. 
Источник изображений: wccftech.com В основе Lushan и Huashan лежит архитектура Flower Harbor (Huagang) с улучшенными вычислительными блоками, в которых вычислительная плотность чипов увеличилась на 50 %, а энергоэффективность выросла на 10 %. Новая архитектура поддерживает следующие форматы вычислений: FP64, FP32, TF32, FP16, BF16, FP8, FP6, FP4, INT8, MTFP8, MTFP6, MTFP4. Сделан упор на параллельную работу и масштабирование: ускорители обмениваются данными с высокой скоростью и работают асинхронно — при помощи технологии MTLink можно сформировать кластер из более чем 100 тыс. графических процессоров Huashan. Видеокарты Lushan адресованы любителям игр и создателям контента и выступают преемниками потребительских Moore Threads MTT S80 и MTT S90. Подробности о продукте пока не приводятся, но разработчик уже рассказал, каких результатов можно ждать от видеокарт нового поколения:
 Moore Threads обеспечила графике на новой архитектуре полную совместимость с наиболее популярными API, в том числе DirectX 12 Ultimate — продукты из предыдущей потребительской линейки в этом плане сильно отставали. Другие важные нововведения — рендеринг с использованием генеративного ИИ теперь встроен в единый конвейер UniTE; полностью переработана аппаратная часть подсистемы трассировки лучей. В итоге стало удобнее работать с нейронным рендерингом и задачами трассировки пути. Графический процессор Huashan состоит из двух чиплетов и включает восемь ячеек памяти HBM. Moore Threads сравнивает возможности ускорителя с чипами Nvidia Hopper и Blackwell: по скорости вычислений с плавающей запятой он приблизился к Blackwell B200, сравнялся с B200 по общей пропускной способности и даже превзошёл Blackwell по способности работать с большим объёмом памяти одновременно и обслуживать большое число обращений. Новые графические процессоры, как ожидается, получат вчетверо больший объём памяти: модели MTT S80/S90 комплектовались 16 Гбайт GDDR6, так что в новых моделях можно ожидать до 64 Гбайт. Первые видеокарты Lushan и ускорители Huashan выйдут в 2026 году. Компания также поделилась сведениями о производительности ускорителя MTT S5000 — он позиционируется как конкурент Nvidia Hopper: для модели DeepSeek V3 скорость обработки запросов составляет 4000, а генерации ответов — 1000 токенов в секунду. MTT S5000 будет работать в составе суперсервера MTT C256, который также ожидается в следующем году. Вышел первый обзор ПК на двухчиповых ИИ-ускорителях Intel Arc Pro B60 — восемь GPU и 192 Гбайт GDDR6
03.12.2025 [23:03],
Николай Хижняк
Первое практическое тестирование платформы Intel Arc Pro B60 Battlematrix, опубликованное порталом Storage Review, демонстрирует плотную локальную систему ИИ, построенную на базе четырёх двухчиповых профессиональных видеокарт Arc Pro B60. 
Источник изображения: VideoCardz Каждая карта в составе системы оснащена 48 Гбайт видеопамяти GDDR6 (по 24 Гбайт на каждый GPU). Таким образом, общий объём VRAM составляет 192 Гбайт, что идеально подходит для сценариев локальной работы с большими языковыми моделями, которые позволяют избежать издержек, связанных с облачными вычислениями, а также проблем с обменом данными. 
Источник изображения здесь и ниже: Storage Review Intel установила цену на одночиповую Arc Pro B60 около $600, поэтому двухчиповая версия с 48 Гбайт памяти стоит около $1200. При таком объёме видеопамяти профессиональный ускоритель от Intel значительно дешевле (как минимум вдвое) большинства профессиональных GPU с аналогичным объёмом памяти от других производителей. Видеокарты Arc Pro B60 не предназначены для игр. А двухчиповая Arc Pro B60 — не совсем двухчиповая в том привычном смысле, какой была, например, игровая GeForce GTX 690 от Nvidia в своё время. Компания Maxsun, партнёр Intel, предоставивший карты для тестирования, уже объяснила, что Arc Pro B60 с двумя GPU — это две видеокарты в составе одной печатной платы, использующие один слот PCIe благодаря бифуркации (разделению линий). По сути, два графических процессора делят одну плату и один слот, но для операционной системы это две отдельные видеокарты. Таким образом, система вместо четырёх карт видит восемь Arc Pro B60, где у каждой имеется 24 Гбайт видеопамяти.  Для многих языковых моделей эффективность связана с количеством используемых графических ускорителей. И чем их меньше, тем лучше. Небольшие языковые модели можно разместить в составе стека памяти VRAM одного ускорителя. Однако физические ограничения доступного объёма памяти приводят к необходимости использования большего числа ускорителей, особенно в случае очень больших языковых моделей. Это, в свою очередь, накладывает определённые ограничения, связанные с технологиями межсоединений — повышается задержка в распределении данных. Конфигурация из восьми графических процессоров становится целесообразной, когда вы повышаете уровень параллелизма и объёмы пакетов данных, где пропускная способность имеет большее значение. Однако программное обеспечение, необходимое для такой обработки, пока находится на ранней стадии разработки. Только модели GPT-OSS на основе MXFP4 работали должным образом с низкоточными путями, в то время как такие форматы, как стандартные INT4, FP8 и AWQ, отказывались запускаться, поэтому многим плотным моделям пришлось работать в формате BF16. 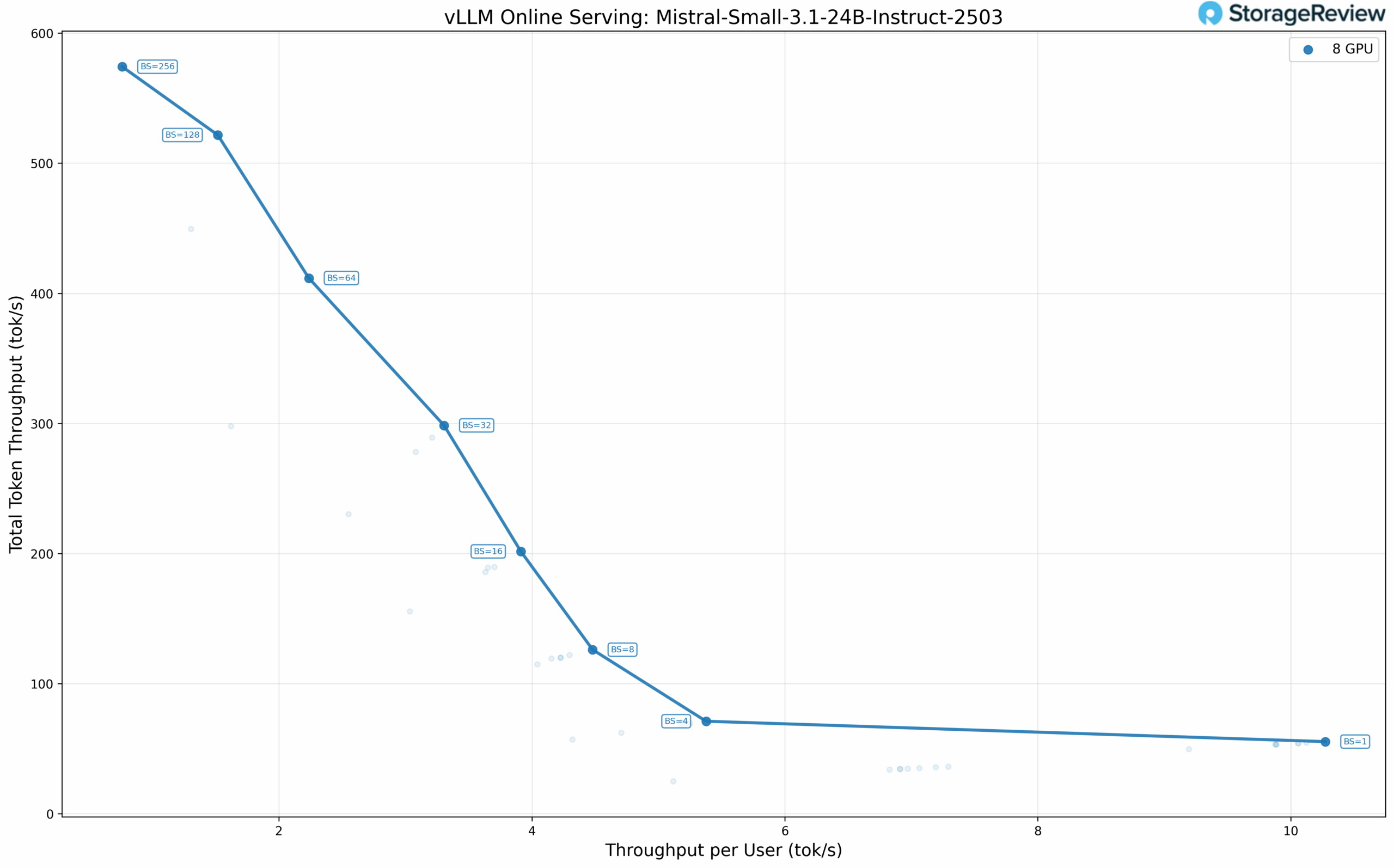
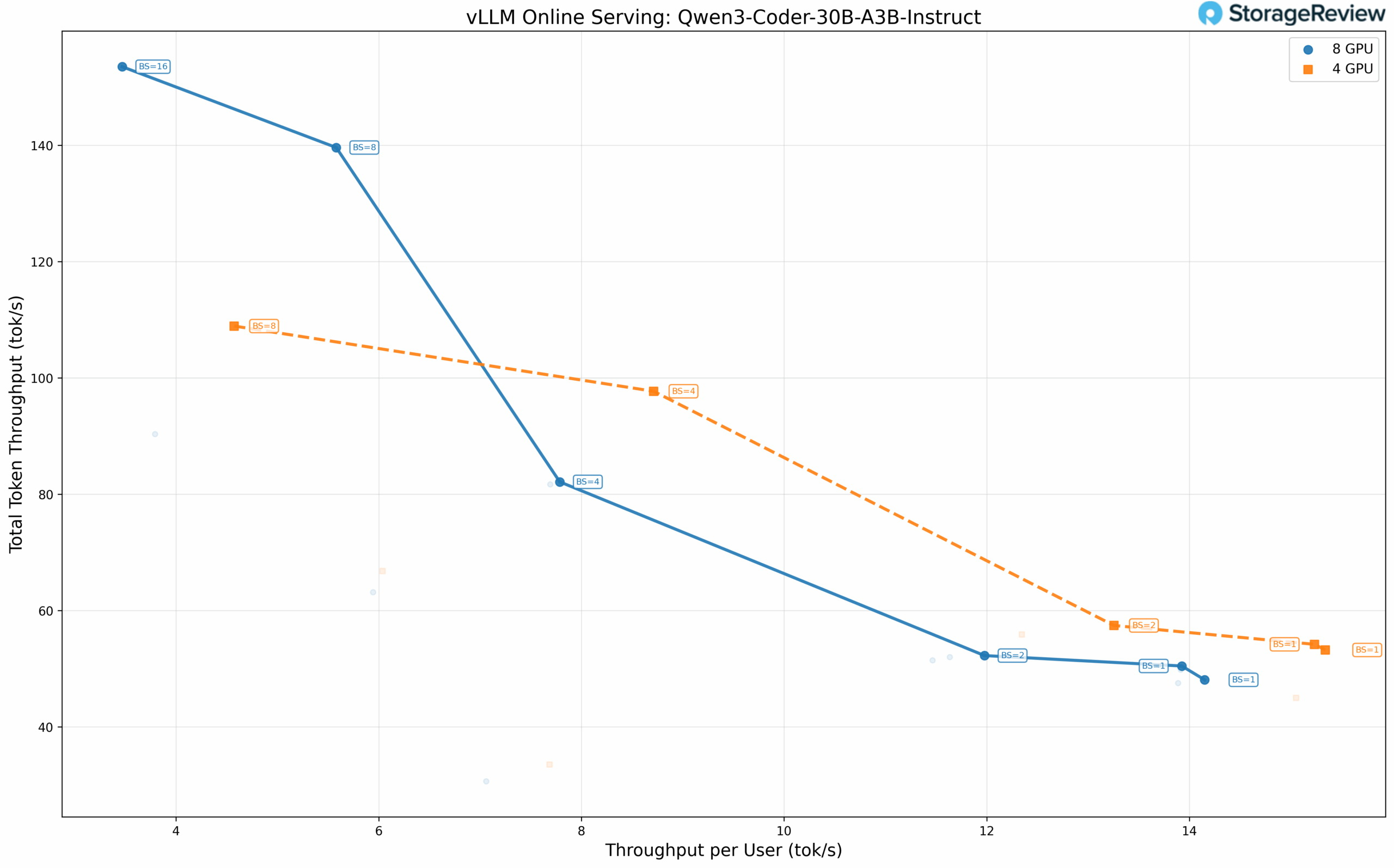 «Для всех протестированных моделей прослеживается общая закономерность: при небольших размерах пакета с нашей конфигурацией с 256 токенами ввода/вывода использование минимального количества графических процессоров, необходимого для размещения модели, обеспечивает лучшую производительность на пользователя, чем распределение по всем восьми графическим процессорам. Издержки взаимодействия между графическими процессорами через PCIe, даже на скоростях PCIe 5.0, приводят к задержке, превышающей преимущества распараллеливания в однопользовательских или низкоконкурентных сценариях», — пишет Storage Review. Физически двухчиповые Arc Pro B60 крупнее одночиповых. Они длиннее, оснащены двухслотовым кулером и потребляют до 400 Вт через один разъём 12V-2×6. Из-за большей длины видеокарты могут возникнуть сложности при её установке в некоторые стандартные Tower-корпуса. В моделях корпусов серверного уровня эти карты помещаются без проблем. В тестах, проведённых Storage Review, использовались ранние версии драйверов, предварительная сборка LLM Scaler и система AMD EPYC вместо процессоров Intel Xeon 6, с которыми должны поставляться решения Battlematrix, поэтому все предоставленные данные указаны как предварительные. Intel анонсировала ИИ-системы Battlematrix ещё в мае, но обозреватель ожидает, что аппаратно-программное обеспечение станет полностью готовым только к 2026 году. В Китае похвастались разработкой ИИ-ускорителя в полтора раза быстрее чипа Nvidia пятилетней давности
28.11.2025 [13:36],
Павел Котов
Китайский стартап Zhonghao Xinying доложил о разработке тензорного процессора общего назначения (GPTPU), который может использоваться для обучения и запуска моделей искусственного интеллекта. Производительность этого ускорителя, утверждает разработчик, в 1,5 раза превосходит показатели модели Nvidia A100, выпущенной в 2020 году. 
Источник изображения: Igor Omilaev / unsplash.com Разработчиком чипа Ghana значится Янгун Ифань (Yanggong Yifan), получивший образование в Стэнфорде и Мичиганском университете. Ранее он работал в Oracle и Google — в последней участвовал в создании тензорных процессоров, которые использует поисковый гигант. Соучредитель стартапа Чжэн Ханьсюнь (Zheng Hanxun) тоже работал в Oracle, а также в техасском центре исследований и разработки Samsung. Созданный в компании ускоритель основан только на китайских технологических решениях — в его разработке, проектировании и производстве не участвуют ни сами западные компании, ни их ПО или компоненты; чипы не требуют иностранных технологических лицензий, подчеркнули в Zhonghao Xinying. Чип Ghana, утверждают в компании, способен обеспечить производительность в 1,5 раза выше, чем у Nvidia A100 при сниженном на 25 % потреблении энергии. Следует, однако, подчеркнуть, что это чип относится к классу ASIC, то есть он имеет узкое предназначение в отличие от более универсального решения Nvidia, которое к тому же более чем на одно поколение старше актуальных Blackwell Ultra. Это приемлемое решение для клиентов, которые стремятся избавиться от доминирующей в области ИИ-ускорителей Nvidia — ярким примером является Google с собственными TPU. Но в отрасли в обозримом будущем наиболее востребованными останется продукция Nvidia и её традиционного конкурента — AMD. Nvidia распродала все ИИ-ускорители, но на подходе ещё больше Blackwell
20.11.2025 [11:18],
Павел Котов
Nvidia побила собственные прогнозы по прибыли за III квартал 2026 финансового года, реализовав больше ускорителей искусственного интеллекта, чем когда-либо прежде. Компания распродала все серверные чипы, заявил её гендиректор Дженсен Хуанг (Jensen Huang), но вскоре их запасы увеличатся. 
Источник изображения: nvidia.com По итогам отчётного периода выручка Nvidia составила рекордные $57 млрд, а чистая прибыль в пересчёте составила $4000 в секунду. Всего за один квартал бизнес компании в сфере центров обработки данных вырос на $10 млрд до $51,2 млрд — это на 66 % больше, чем за аналогичный период прошлого года. Для аналитиков показатели дохода Nvidia по направлению ЦОД служат индикатором «пузыря ИИ», о котором в последнее время говорят всё больше. Но никаких признаков негативной динамики у компании не наблюдается: прогноз на IV квартал составляет $65 млрд, то есть всего за три месяца квартальная выручка увеличится ещё на $8 млрд. «Продажи [ИИ-ускорителей на архитектуре] Blackwell зашкаливают, а облачные GPU распроданы», — заявил Дженсен Хуанг. Впрочем, распроданы, видимо, они не окончательно. «У нас ещё достаточно Blackwell на продажу и много Blackwell на подходе», — добавил он позже. Основной движущей силой роста в сегменте ЦОД и не только стали ускорители на обновлённой архитектуре Blackwell Ultra, признался гендиректор Nvidia: «Наша ведущая архитектура для всех категорий клиентов теперь Blackwell Ultra; продолжительным высоким спросом пользовалась наша предыдущая архитектура Blackwell». Выручка по игровому направлению показала рост на 30 % по сравнению с прошлым годом, и это хороший сигнал для видеокарт семейства Nvidia Blackwell, отзывы о которых в начале года были неоднозначными. Инвесторов же Дженсен Хуанг призвал не паниковать: «О пузыре ИИ говорят много. С нашей точки зрения наблюдается нечто совершенно иное». Nvidia много лет предупреждала, что ИИ изменит всё, и сейчас эта технология достигла переломного момента, считает глава компании: «Революционным станет переход к агентному и физическому ИИ». Под последним понимается робототехника с ИИ. Frore представила водоблоки LiquidJet с 3D-охлаждением — они справятся с чипами до 4400 Вт
15.10.2025 [15:21],
Николай Хижняк
Компания Frore Systems представила LiquidJet — водоблок системы жидкостного охлаждения (СЖО), поддерживающий существующие графические процессоры для ИИ, такие как Nvidia Blackwell, с тепловой мощностью 1400 Вт. Производительность LiquidJet может быть масштабирована для ускорителей ИИ следующего поколения, включая Nvidia Feynman, общая мощность которых составит до 4400 Вт. 
Источник изображений: Frore Systems Современные графические процессоры для ИИ, такие как системы на кристалле Nvidia Blackwell, потребляют огромное количество энергии и поэтому требуют жидкостного охлаждения. Традиционные медные водоблоки СЖО имеют относительно длинные «двумерные» микроканалы с малым поперечным сечением, изготовленные на станках с ЧПУ или выточенные из медных блоков высокой чистоты. Из-за большой длины этих микроканалов жидкость должна проходить большее расстояние и соприкасаться с большой площадью поверхности, что увеличивает гидравлическое сопротивление и снижает давление внутри контура, влияя на эффективность охлаждения.  Компания Frore утверждает, что её водоблоки LiquidJet с трёхмерной микроструктурой каналов струйной обработки и короткими контурами снижают гидравлическое сопротивление и, следовательно, поддерживают более высокое давление внутри системы, повышая производительность охлаждения. Frore отмечает, что адаптировала «технологии производства полупроводников для изготовления металлических пластин» и может создавать трёхмерные микроструктуры каналов струйной обработки, соответствующие картам горячих точек конкретных процессоров. Это значительно повышает производительность и эффективность, хотя и обходится дороже по сравнению с традиционными методами производства. По словам Frore, результаты оказались впечатляющими. LiquidJet поддерживает плотность горячих точек до 600 Вт/см² при температуре на входе 40 °C, что вдвое превосходит показатели стандартных водоблоков. Отношение удаления тепла к скорости потока у LiquidJet увеличено на 50 %, а потери давления снижены в четыре раза — с 0,94 до 0,24 фунта на квадратный дюйм. В результате, по утверждению компании, LiquidJet обеспечивает более низкие температуры и более предсказуемую производительность процессоров Nvidia Blackwell Ultra при полной нагрузке. 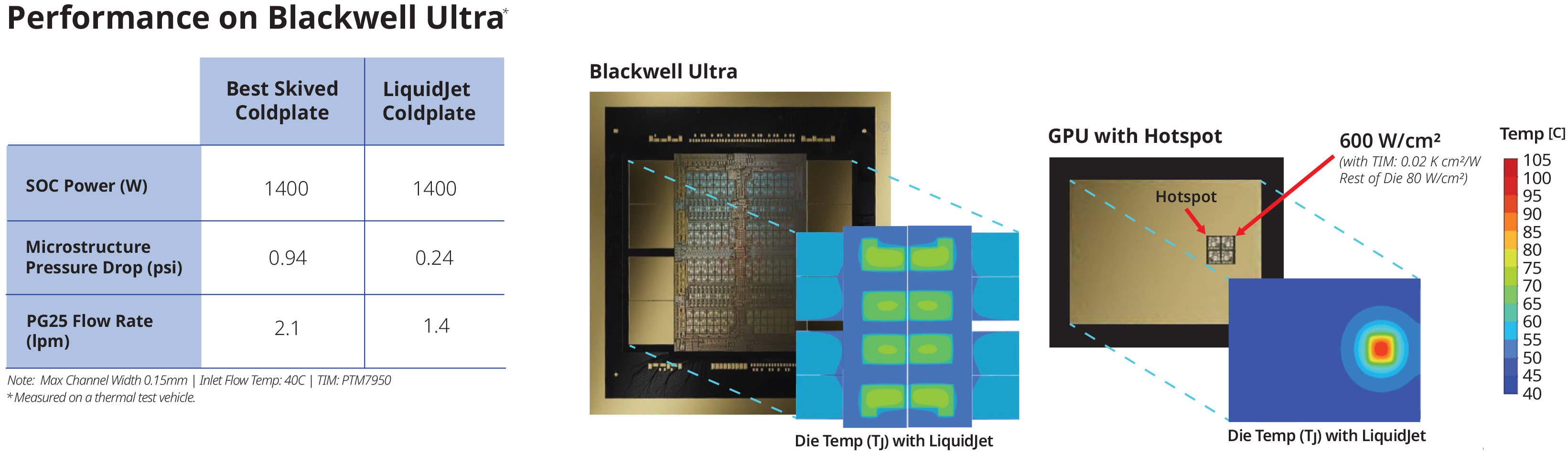 Конструкцию LiquidJet можно масштабировать и адаптировать для будущих специализированных GPU от Nvidia, таких как Rubin (мощность 1800 Вт), Rubin Ultra (3600 Вт) и Feynman (4400 Вт). Водоблок также можно адаптировать для любых других процессоров, поскольку метод производства Frore отличается особой гибкостью с точки зрения настройки под конкретную карту горячих точек того или иного чипа. LiquidJet обеспечивает и другие преимущества. Более эффективное охлаждение позволяет добиться более стабильных частот у специализированных GPU, что означает обработку большего числа токенов в секунду при тех же энергозатратах. Кроме того, высокая эффективность циркуляции жидкости внутри контура снижает энергопотребление насоса, улучшая показатели PUE и снижая TCO (стоимость владения). 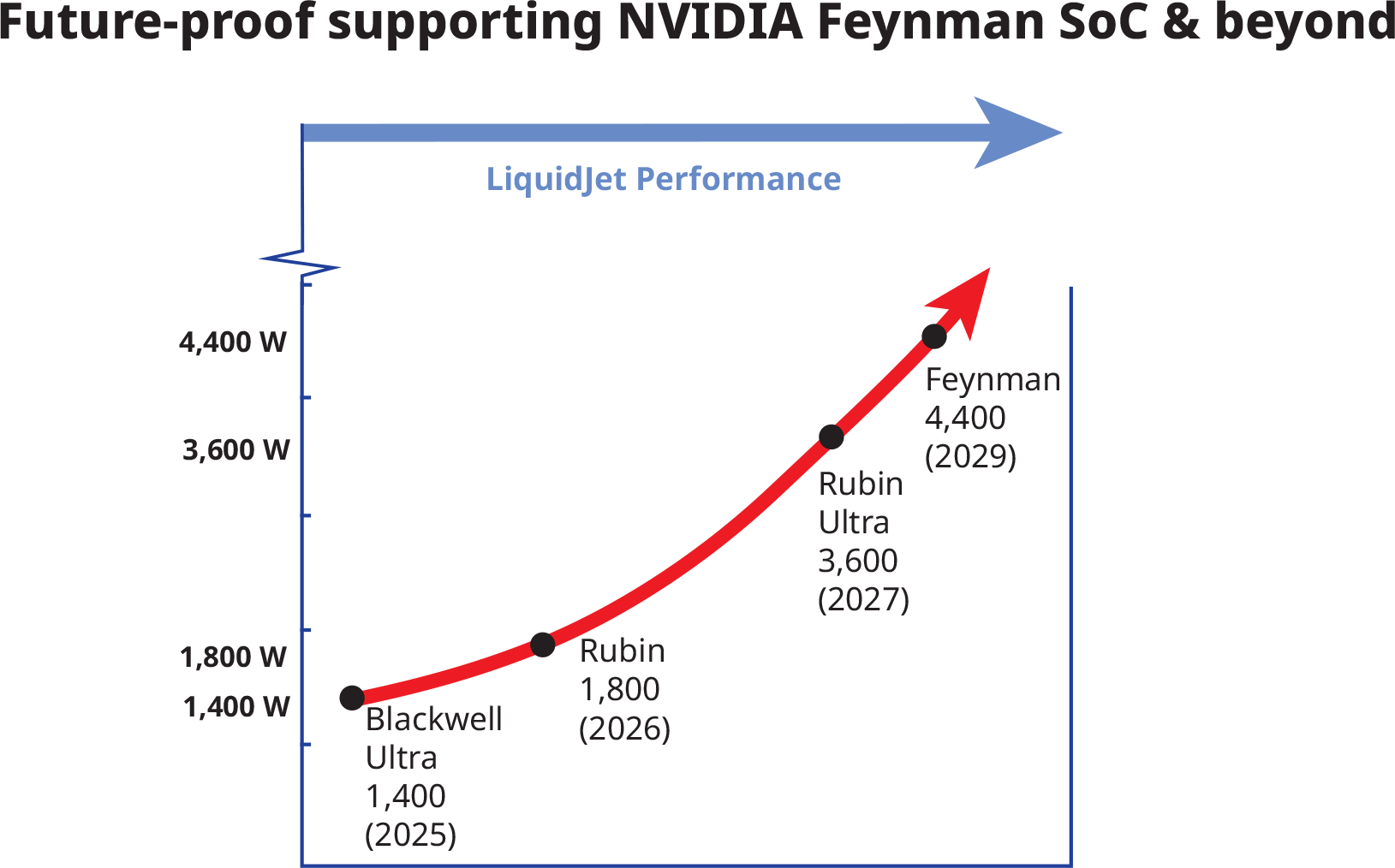 По оценкам KAIST — ведущего корейского исследовательского института передовых технологий, — энергопотребление и тепловыделение ускорителей искусственного интеллекта в течение следующего десятилетия могут вырасти в 10 раз. Будущие ИИ-ускорители, состоящие из специализированных графических процессоров на базе нескольких вычислительных чиплетов и оснащённые десятками стеков памяти HBM, потребуют совершенно новых методов охлаждения, включая встроенные охлаждающие структуры как для вычислительных чиплетов, так и для чипов памяти. Китайская Innosilicon представила видеокарту Fenghua 3 — CUDA, DX12, трассировка лучей и более 112 Гбайт HBM
24.09.2025 [15:31],
Николай Хижняк
Компания Innosilicon представила свой графический процессор третьего поколения — Fenghua 3. Компания обещает, что третья версия графического процессора будет значительно превосходить своих предшественников. Компания называет его первым полнофункциональным GPU собственной разработки, которые построен на открытой архитектуре RISC-V и совместим с CUDA. 
Источник изображений: Innosilicon В отличие от предыдущих поколений ускорителей Fenghua, основанных на архитектуре PowerVR от Imagination Technologies, Fenghua 3 использует в качестве основы проект OpenCore RISC-V Nanhu V3. Innosilicon утверждает, что новый GPU способен справиться с широким спектром рабочих нагрузок: от обучения ИИ и масштабных научных вычислений до САПР, медицинской визуализации и облачного гейминга. Для Fenghua 3 заявляется поддержка DirectX 12, Vulkan 1.2 и OpenGL 4.6 с аппаратной трассировкой лучей. Компания продемонстрировала работу GPU в таких играх, как Tomb Raider, Delta Force и Valorant, хотя данные о частоте кадров и настройках не были предоставлены. Fenghua 3 также поддерживает подключение до шести 8K-мониторов с частотой обновления 30 Гц.  Для задач искусственного интеллекта ускоритель на базе Fenghua 3 предлагает более 112 Гбайт высокоскоростной памяти HBM — это самый большой объём памяти среди китайских видеокарт. Один ускоритель может обрабатывать модели с 32 и 72 млрд параметров, а кластер из восьми — поддерживать огромные модели DeepSeek 671B и 685B. Innosilicon также подтвердила совместимость своей новинки с Qwen 2.5, Qwen 3 и семейством ИИ-моделей DeepSeek V3, V3.1 и R1. Innosilicon также похвасталась тем, что Fenghua 3 — первая в Китае видеокарта, поддерживающая формат YUV444, который обеспечивает наилучшую детализацию и точность цветопередачи. Это будет особенно полезно для тех, кто работает с САПР или занимается видеомонтажом. Кроме того, Fenghua 3 — первая в мире видеокарта, которая предлагает встроенную поддержку технологии DICOM (Digital Imaging and Communication in Medicine). Она позволяет точно визуализировать рентгеновские снимки, МРТ, КТ и УЗИ на стандартных мониторах, устраняя необходимость в дорогостоящих специализированных медицинских дисплеях с градациями серого. Ускоритель работает с системами Windows, Android, Tongxin и Kylin Linux. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex


