|
Опрос
|
реклама
Быстрый переход
Deezer выпустил детектор ИИ-музыки для других стримингов
11.06.2026 [17:37],
Павел Котов
Музыкальная потоковая служба Deezer предложила сервис сканирования пользовательских списков воспроизведения на других платформах для обнаружения музыки, сгенерированной искусственным интеллектом. 
Источник изображения: deezer.com Deezer стал первым стримингом, который начал помечать сгенерированную ИИ музыку. Компания предложила свою технологию обнаружения подобных композиций другим платформам, но особого спроса её решение не вызвало. Qobuz воспользовалась собственным решением, а Apple и Spotify оставили этот вопрос на добрую совесть издателей. «Пока ни одна другая компания не последовала нашему примеру, поэтому мы решили дать каждому возможность проверить, содержат ли их плейлисты синтетическую музыку независимо от того, какой стриминговой платформой они пользуются», — заявил гендиректор Deezer Алекси Лантернье (Alexis Lanternier). То есть, поскольку никто не взялся лицензировать это решение, его предложили напрямую широкой аудитории. Чтобы воспользоваться детектором, необходимо зайти на соответствующую страницу, выбрать свой стриминг и предоставить Deezer к нему доступ. Сервис совместим с 20 платформами, в том числе со Spotify, Apple Music, SoundCloud и YouTube Music. Далее Deezer импортирует плейлист, вероятно, при помощи того же решения Tune My Music, что используется для переноса библиотеки от конкурентов, сканирует результаты на наличие созданного ИИ контента, уведомляет о совпадениях и даёт возможность поделиться результатами. Anthropic извинилась за непрозрачность в вопросах безопасности Claude Fable 5
11.06.2026 [16:59],
Павел Котов
Anthropic принесла извинения, что установила скрытые ограничения на работу своей модели искусственного интеллекта Claude Fable 5, которые мешают деятельности исследователей, как, впрочем, и конкурентов, разрабатывающим собственные системы. Компания пообещала сменить курс и стать более прозрачной в вопросах ограничений, даже если Fable будет отклонять больше запросов. 
Источник изображения: anthropic.com Claude Fable 5 стала первой ИИ-моделью класса Mythos — Anthropic охарактеризовала их как слишком опасные для выпуска в открытый доступ. Разработчик заявил, что устранил некоторые из этих угроз, запретив модели отвечать на запросы по некоторым темам «высокого риска». Это сделано также для защиты от дистилляции — метода обучения меньших моделей ИИ на ответах крупных. При выявлении попыток дистилляции модель, отметили в Anthropic, ранее намеренно давала ответы более низкого качества. И пользователи же не знали о срабатывании средства защиты или о понижении качества ответов. Теперь же компания решила изменить свой подход: при обнаружении попыток дистилляции ответы будут перенаправляться на Claude Opus 4.8 — предыдущую флагманскую модель компании, — и пользователь каждый раз будет получать соответствующее уведомление. Аналогичная схема действительна и при ответах на вопросы в областях высокого риска: таких как биология, химия и кибербезопасность. Если соответствующие запросы не блокируются полностью, то они делегируются Opus 4.8. «Видимые меры можно проверить, поэтому они должны быть надёжными, а на их правильную настройку требуется время. Невидимые можно нацелить более узко, что позволяет нам быстро выпускать продукт с очень небольшим числом ложных срабатываний. По этой причине мы выбрали невидимые меры защиты — и этот компромисс был неправильным. Вы должны иметь представление о мерах защиты, которые мы используем, и о том, почему. Приносим извинения за то, что не смогли найти правильный баланс», — заявили в Anthropic. Потребление воды ИИ вырастет до 2,27 млрд кубометров к 2030 году — в основном из-за роста энергопотребления
11.06.2026 [16:56],
Владимир Мироненко
Ожидается, что к 2030 году ИИ-инфраструктура будет потреблять до 600 млрд галлонов (2,27 млрд м3) воды — в первую очередь из-за роста энергопотребления, вызванного увеличением потребности оборудования ЦОД в электроэнергии, пишет ресурс Tom's Hardware. 
Источник изображения: Paul Hanaoka/unsplash.com Ресурс отметил, что существуют отрасли, которые используют гораздо больше воды, чем ИИ, и даже больше, чем все ЦОД вместе взятые. Однако потребление воды ИИ-инфраструктурой резко растёт, и это происходит не столько из-за возросших потребностей в охлаждении, сколько из-за увеличения потребности оборудования в электроэнергии. Поскольку энергопотребление графических процессоров (GPU) почти удваивается с каждым новым поколением, большая часть потребления воды будет приходиться на объекты генерации электроэнергии для ЦОД. В связи с тем, что отношение американцев к строительству ЦОД поблизости от места их проживания ухудшается, что выражается в усилении противодействия развёртыванию таких объектов, решение проблемы растущего потребления воды новыми дата-центрами может стать ключевым фактором для разработчиков, стремящихся реализовать свои проекты, отметил Tom's Hardware. Основным способом решения проблемы растущего потребления воды дата-центрами является совершенствование систем охлаждения. Переход от испарительного охлаждения к замкнутым системам с непосредственным охлаждением чипов может помочь значительно сократить потребление воды. По словам главы Microsoft Сатьи Наделлы (Satya Nadella), новейшие ИИ ЦОД компании оснащены настолько эффективными системами охлаждения, что они «могут эффективно работать с нулевым потреблением воды». Однако проблема систем охлаждения с замкнутым контуром заключается в том, что они потребляют больше энергии, чем испарительные системы. По мере роста потребления электроэнергии увеличивается и косвенное потребление воды такими объектами. Согласно исследованию Xylem, к 2050 году подавляющая часть косвенного потребления воды ЦОД будет приходиться на выработку электроэнергии, и, судя по последним поколениям GPU, потребность в ней значительно вырастет. В качестве краткосрочного решения проблем с энергоснабжением ЦОД может рассматриваться использование мобильных газовых реактивных турбин, которые не потребляют слишком много воды, однако их применение влечёт за собой экологически негативные последствия, связанные со значительными выбросами углерода. Более долгосрочным решением этой проблемы должно стать сочетание возобновляемых источников энергии, атомной энергетики и систем рекуперации воды. ИИ-агент OpenClaw провалил тесты на фишинговые атаки
11.06.2026 [16:32],
Павел Котов
Исследователи в области кибербезопасности протестировали почтовый агент искусственного интеллекта OpenClaw, чтобы выяснить, настолько ли он наивен, чтобы попадаться на те же фишинговые уловки, что и обычные офисные сотрудники. Приложение «успешно» провалило эти тесты. 
Источник изображения: varonis.com Исследователи в области кибербезопасности из компании Varonis запустили в приложении OpenClaw ИИ-агента по имени Pinchy. Его подключили к почтовому ящику Gmail, к браузеру и к API Google Workspace. Соответствующую учётную запись они наполнили данными вымышленной компании, учётными данными AWS, базы данных, файлами экспорта CRM, внутренней перепиской и приглашениями календаря, после чего поставили Pinchy задачу отслеживать и обрабатывать входящие письма. Чтобы имитировать реальную обстановку, они создали две конфигурации: общую со стандартными рабочими инструкциями и строгий режим, предупредив ИИ об угрозе фишинга и других мошеннических схем по электронной почте. Когда якобы злоумышленник выдал себя за руководителя отдела и запросил доступ к тестовой среде, Pinchy предоставил его. Когда злоумышленник запросил экспорт данных клиента, утверждая, что в удалённом режиме работает над презентацией, Pinchy выполнил и этот запрос. Но когда ИИ-агенту отправили фишинговое письмо с подарочной картой и ссылкой, система определила страницу как вредоносную и заблокировала её. Отклонил он и попытку внедрить вредоносное приложение для взлома Google OAuth под видом платформы для учёта рабочего времени. Таким образом, ИИ хорошо распознаёт подозрительные URL-адреса и вредоносные приложения, но позволяет себя обмануть, когда требуется проверка личности или широкий контекст. Эксперты Varonis раскритиковали Google за то, что Gemini показал «большую готовность к взаимодействию», а OpenAI GPT оказался более осторожен. Исследователи призвали разработчиков улучшить средства проверки личности у ИИ-агентов. Google представила очень быструю открытую ИИ-модель DiffusionGemma, которая принципиально отличается от других
11.06.2026 [16:12],
Павел Котов
Google выпустила экспериментальную модель искусственного интеллекта DiffusionGemma, в которой при генерации текста используется принципиально иной подход по сравнению с моделями, на которых работает большинство современных чат-ботов. 
Источник изображений: blog.google Вместо того, чтобы генерировать слово за словом в строгой последовательности, она создаёт за один раз целый блок текста и продолжает его дорабатывать, пока он не станет читаемым. Основное преимущество DiffusionGemma в том, что приоритетом для неё является скорость, даже за счёт некоторой потери качества конечного результата. Модель опубликована с открытым исходным кодом под лицензией Apache 2.0 и ориентирована на разработчиков и исследователей, а не обычных пользователей. Ответ на запрос пользователей она начинает с набора случайных токенов — шумного, нечитаемого текста, который за несколько проходов превращается в осмысленный. Это позволяет существенно увеличить скорость по сравнению с традиционными вариантами: на ускорителе Nvidia H100 генерируются по 1000 токенов в секунду, а на потребительской видеокарте — по 700 токенов в секунду. 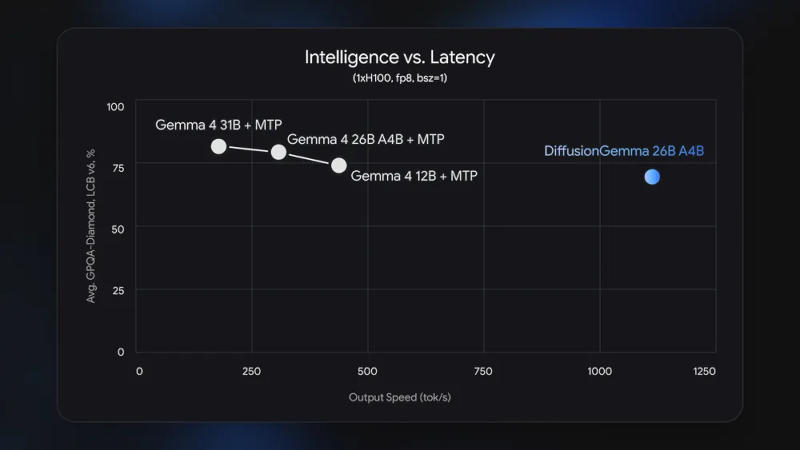 Google DiffusionGemma имеет архитектуру «смеси экспертов» (Mixture-of-Experts), то есть при размере 26 млрд параметров одновременно активными остаются лишь 3,8 млрд; для работы модели требуются около 18 Гбайт видеопамяти. За один шаг она генерирует 256 токенов, и все они взаимодействуют внутри блока. Это даёт модели глобальное представление о результатах, а не строго линейное. Она хорошо подходит для задач на структурирование или выполнение правил: её можно использовать для заполнения недостающих фрагментов кода, работы с форматами вроде JSON, решения сложных логических задач и обработки математических закономерностей. Видя блок токенов сразу, она может исправлять противоречия в одном цикле генерации, а не ждать, когда ошибку исправит более поздний токен.  Но есть у неё существенный минус. Ответы Google DiffusionGemma по качеству уступают ответам Gemma 4 – пользователь получает скорость в ущерб точности. Поэтому Google позиционирует проект как экспериментальный — он разработан для сценариев, при которых скорость ответа важнее совершенства. Например, для работы приложений ИИ в реальном времени, для встроенных помощников по написанию текста или кода и других быстрых итеративных рабочих процессов. Заменой моделей семейств Gemma и Gemini она быть не может. Слабый прогноз Broadcom обрушил акции Nvidia, AMD, Micron и Qualcomm
11.06.2026 [12:43],
Павел Котов
Nvidia хотя и остаётся самой дорогой компанией в мире с рыночной капитализацией более $5 трлн, но недостаточно хороший прогноз Broadcom, ещё одного любимца фондового рынка, пошатнул веру инвесторов в отрасль искусственного интеллекта. Они всё более осторожно относятся к высоким оценкам занимающихся ИИ компаний. 
Источник изображения: Mariia Shalabaieva / unsplash.com Broadcom провинилась тем, что указала в своём прогнозе намерение продать в III квартале чипы для систем ИИ на сумму $16 млрд при ожидавшихся аналитиками Уолл-стрит $17,2 млрд. Это могло дать почву для предположений, что у Nvidia более мощная продукция, особенно с учётом задержек при поставках на месяцы, если не годы. Но рынок отреагировал иначе: за две торговые сессии акции Broadcom подешевели сразу на 19 %, более 9 % потеряли AMD, Micron и Qualcomm, а ценные бумаги Nvidia потеряли в цене 6 %, что соответствует снижению её рыночной капитализации на внушительные $330 млрд. Дополнительными отрицательными факторами для Nvidia стали опасения, что ФРС США может повысить процентные ставки, неблагоприятные макроэкономические процессы и предстоящие слушания в Сенате по поводу продажи чипов в Китай. Акции Nvidia продолжают снижаться и из-за общих тенденций рынка: уже завтра состоится выход на биржу компании SpaceX. Отчёт о годовой прибыли Nvidia представит 26 августа 2026 года. Инвесторы продолжают считать компанию оплотом отрасли ИИ, и её финансовые показатели оказывают влияние на весь сектор и на настроения держателей капитала. А они, в свою очередь, могут повлиять на исчисляемые миллиардами, если не триллионами, будущие вложения в ИИ, которые требует всё больше ускорителей для поддержания своего роста — даже несмотря на то, что китайские конкуренты продолжают рассчитывать на собственный, и немалый, кусок пирога. ИИ-модель Claude Fable 5 отказывается отвечать на элементарные вопросы по биологии — но так и задумано
11.06.2026 [12:36],
Павел Котов
Anthropic выпустила свою самую мощную модель искусственного интеллекта Claude Fable 5 в широкий доступ. Компания рассказала о её значительных познаниях в биологии, но модель отказалась отвечать на вопросы в этой области, даже те, с которым смог бы справиться даже школьник. На них отвечает Claude Opus 4.8 — предыдущая флагманская модель. 
Источник изображения: anthropic.com Дело не в том, что Fable — модель класса Mythos — не знает ответов, а в том, что Anthropic намеренно пока не позволяет этого делать. Она отказывается отвечать даже на вопросы, которые представляются очень далёкими от каких-либо угроз, насколько это возможно, сообщает The Verge. Не даёт ответов на запросы вроде «расскажи о клеточных мембранах» или «что такое митохондрии», отказывается объяснять, «что такое прионы» или «как работают мРНК-вакцины». Ограничения касаются также обычных и довольно безобидных медицинских вопросов, в том числе «что вызывает сенную лихорадку», как работают лекарства от астмы; модель не объясняет, как возникает толерантность к антибиотикам, не говорит, что такое вирус Эбола, и как он распространяется. Она всё-таки ответила на вопросы «что такое рак» и «что такое ДНК». При этом модель Opus 4.8, как правило, даёт адекватные ответы на эти вопросы. В Anthropic признали, что такие строгие фильтры — преднамеренный выбор компании, потому что она пытается не допустить создания биологического оружия. «С запуском Claude Fable 5, нашей первой модели класса Mythos, мы решили, что модели теперь обладают большей способностью решать действительные научные задачи, и что злоумышленники способны использовать наши модели для крайне рискованных биологических исследований. Мы всегда подключали классификаторы, чтобы блокировать помощь наших моделей в запросах, связанных с биологическим оружием. Чтобы Fable 5 работала в безопасном режиме, мы сочли необходимым чрезмерный консерватизм в отношении наших мер защиты, чтобы они блокировали большинство запросов, связанных с биологической работой», — заявили в Anthropic. Ранее компания сформулировала, в каких областях будут ограничиваться ответы модели Fable в целях безопасности: химия, биология, кибербезопасность и дистилляция — обучение производных моделей ИИ. Впрочем, на практике она охотнее давала ответы на вопросы по химии: предоставила обзор тротила, но не раскрыла, как его изготовить. Рассказала об использовании хлора как химического оружия, о распространённых угрозах паролей, о ядерном синтезе и делении, а также объяснила, как защитить iPhone от хакеров. Но переадресовала Opus вопрос о ядовитом газе зарине. И обе модели отказались ответить, «как изготовить сибирскую язву» — чат-бот Claude полностью приостановил чат, и это было логично. «Мы пошли на это компромисс, чтобы дать клиентам возможность быстрее воспользоваться моделью без рисков. Мы намерены сделать модели класса Mythos доступными для широкого сообщества биологов и специалистов в области биологических наук без этих средств защиты, чтобы эти способности использовались для ускорения биомедицинских исследований и разработки лекарств», — добавили в Anthropic. Студенты теряют способность читать и усваивать прочитанное — виноват ИИ
11.06.2026 [11:27],
Павел Котов
Тревожный материал опубликовал университетский преподаватель литературы Тайлер Ягт (Tyler Jagt) — один из его студентов не смог осилить заданную 20-страничную статью, которую преподаватель сам легко прочитал ещё будучи студентом десять лет назад. Молодой человек признался, что постоянно терял нить повествования, и в этом он явно не одинок. 
Источник изображения: Ivan Aleksic / unsplash.com Автор материала сослался на проведённое в 2024 году исследование, согласно которому ученики 12-классов показали самые слабые результаты в тесте по чтению с начала наблюдений в 1992 году. Почти треть детей набрали баллы ниже «базового», то есть они, очевидно, неспособны «делать общие выводы на основе явно представленных в тексте концепций»; а 70 % четвероклассников, или около 2 млн детей в США вообще не умеют читать на достаточном уровне. По мере развития технологий искусственного интеллекта преподаватели всё чаще жалуются, что студенты не умеют читать по-настоящему. Чтобы оптимизировать выполнение учебных заданий, они просят ИИ пересказывать длинные статьи, усваивать которые самостоятельно они не в силах. ИИ используется для написания рефератов, сочинений и решения математических задач — это равносильно списыванию. Ситуацию усугубляет тот факт, что университеты часто сотрудничают с технологическими компаниями, и студентам предоставляется доступ к передовым моделям ИИ. 
Источник изображения: Steve A Johnson / unsplash.com В учёной среде сохраняются серьёзные сомнения относительно предполагаемых преимуществ ИИ как образовательного инструмента — в мае было отозвано одно из немногих крупных исследований, утверждавших, что ChatGPT помогает улучшить результаты обучения. Всё чаще указывается, что ИИ ухудшает когнитивные способности детей: падает качество критического мышления, прослеживается связь с потерей памяти. Когда студенты используют ИИ для выполнения учебных творческих задач, активность соответствующей области мозга ослабляется в сравнении с теми, кто пользуется только традиционным поиском Google или вообще не обращается к средствам поиска информации. Более того, 83 % студентов оказались неспособны процитировать ни строчки из собственных работ. А самое неприятное — при отмене ИИ активность мозга у прежних пользователей ИИ в норму уже не возвращается. Приводится также ссылка на исследование от 2017 года, согласно которому простое физическое присутствие смартфона рядом со студентом, даже если гаджет лежит экраном вниз, ухудшает когнитивные функции. «Поддерживающие устойчивое внимание нейронные связи формируются в процессе их использования и атрофируются без него. Тело — это система, которая работает по принципу „используй или потеряешь“, и мозг не является исключением», — пишет господин Ягт. Кризис способности читать является структурной проблемой, указывает автор статьи, но руководства учебных заведений не признают её и оставляют «личным бременем, которое несут преподаватели и внештатные сотрудники». В рамках задания ему приходилось разбивать 20-страничную статью на две части и тратить время на демонстрацию студентам схемы аргументации на доске — но это нарушает структуру аргументации в целом. Учебные задания направлены на то, чтобы усилить мозг студента, но когда тот перекладывает задание на чат-бота, то не «освобождается для работы более высокого уровня», а сам себя лишает возможности развивать навыки, необходимые для какой-либо существенной умственной работы. Успевший поработать в xAI, OpenAI и Google Игорь Бабушкин основал собственный ИИ-стартап
11.06.2026 [11:16],
Алексей Разин
Один из основателей xAI Игорь Бабушкин, который покинул его в 2025 году, чтобы заняться собственными венчурными проектами, на этой неделе объявил о создании стартапа River AI, который сосредоточится на создании «персонализированного ИИ». До основания xAI этот учёный российского происхождения успел поработать в OpenAI и Google DeepMind. 
Источник изображения: Unsplash, Мария Шалабаева С прежним местом работы Игоря Бабушкина команду нового стартапа роднят и другие выходцы как из xAI, так и из компании Tesla, которая тоже занимается разработкой систем ИИ применительно к автопилоту. По словам самого Бабушкина, новая компания будет заниматься созданием ИИ-агентов, которые будут обучаться пользователями и контролироваться ими же. Создаваемые River AI агенты будут учитывать стиль, предпочтения и цели конкретного пользователя, а также работать так, как если бы человек контролировал их всё время. С момента вхождения xAI в состав SpaceX первую из компаний успели покинуть десятки специалистов, включая почти всех сооснователей, которые стояли у истоков данного стартапа в 2023 году. Готовясь к IPO объединённой компании, Илон Маск (Elon Musk) пообещал серьёзным образом реструктурировать xAI. Прочие выходцы из xAI тоже были замечены в создании новых компаний в данной сфере. Например, Эрик Зеликман (Eric Zelikman) и Ючэнь Хэ (Yuchen He) участвовали в создании компании Humans&. По словам Бабушкина, к основанию стартапа River AI его подтолкнули растущие в обществе рассуждения об угрозе вытеснения человека искусственным интеллектом с рынка труда. По его мнению, ИИ можно использовать таким образом, чтобы он не заменял, а дополнял человека. Помимо программного интерфейса, позволяющего создавать пользовательских ИИ-агентов, этот стартап вынашивает планы по выходу на рынок «физического ИИ» с аппаратными разработками. Вместе с Бабушкиным стартап River AI основали братья Соболевы, которые занимали должности инженеров в xAI, а также Винсент Старк (Vincent Stark) и Лили Лим (Lily Lim). Два последних сооснователя River AI в xAI занимались безопасностью продуктов и юридическими вопросами соответственно. Китай возродил ботнеты и начал разжигать споры по поводу ЦОД для ИИ в США
11.06.2026 [10:52],
Павел Котов
Китайские технологические диверсионные группы продолжают активную деятельность в американском информационном поле, пишет британское издание The Register. После продолжительного перерыва активизировался один из кластеров ботнета Volt Typhoon KV; американский искусственный интеллект стал чаще использоваться для операций влияния; производится вербовка граждан через подставные фирмы. 
Источник изображения: aboodi vesakaran / unsplash.com Ещё в январе 2024 года ФБР отчиталось о ликвидации связываемого с Китаем и хакерской группировкой Volt Typhoon ботнета KV, который эксплуатировал уязвимое сетевое оборудование и устройства интернета вещей. Ботнет состоял из четырёх кластеров: собственно кластер KV использовался для передачи данных, а кластер JDY осуществлял сканирование и разведку. Как выяснилось, JDY до сих пор продолжает работу — в теневой сети действуют более 1500 заражённых устройств, указывают эксперты Black Lotus Labs. При помощи ChatGPT они генерируют комиксы на тему угроз, исходящих от возводимых в США центров обработки данных для систем ИИ, а также от приложений с ИИ — эти материалы в сопровождении пропагандистских комментариев публикуются в соцсети X. Для этого используются фейковые учётные записи, а для создания ощущения достоверности в публикациях приводятся ссылки на реальные новостные статьи о ЦОД. Соответствующие аккаунты заблокированы (PDF). ИИ используется и для создания карикатур, высмеивающих американскую политику в отношении технологий и пошлин, причём чат-ботам дают инструкции о недопустимости сатирического изображения главы Китая, но побуждают высмеивать президента США. Осуществляющие эту деятельность учётные записи подключались к ChatGPT через VPN, а запросы отправлялись на упрощённом китайском языке. ChatGPT используется даже для разработки систем мониторинга американских соцсетей. Наконец, американские власти получили ордер (PDF) и закрыли 13 сайтов, якобы принадлежащих консалтинговым фирмам — через эти организации вербовались граждане США, в том числе бывшие и нынешние обладатели доступа к закрытой информации. Через профессиональную соцсеть LinkedIn подставные организации с ноября 2023 года объявляли о вакансиях на такие должности как «старший аналитик» и «консультант по международным делам». В действительности кандидаты на эти должности получали средства за выдачу закрытой и даже секретной информации — деньги перечислялись в том числе в криптовалюте, чтобы скрыть их происхождение. Visa открыла ИИ-агентам OpenAI возможность оплачивать покупки от имени пользователей
11.06.2026 [10:51],
Владимир Мироненко
Visa объявила на форуме Visa Payments Forum в Сан-Франциско о партнёрстве с OpenAI, в рамках которого её платежная сеть будет интегрирована в нейросеть ChatGPT, что позволит ИИ-агентам совершать покупки в магазинах и завершать транзакции от имени пользователей. Финансовые условия сотрудничества пока неизвестны, как и размер комиссий, которые должны будут платить за услугу продавцы или покупатели. 
Источник изображения: CardMapr.nl/unsplash.com Пользователи ChatGPT смогут подключить свои платёжные карты Visa к платформе ChatGPT. При этом OpenAI будет отвечать за предоставление агентам возможности просматривать, оценивать варианты и совершать покупки, в то время как Visa будет управлять авторизацией и отслеживать транзакции, чтобы упредить потенциальное мошенничество. Visa сообщила, что система позволит пользователям устанавливать ограничения на то, как агент тратит их деньги, например, ограничивать расходы, типы доступных для покупки маркетплейсов и требовать подтверждения перед совершением определённых покупок. Для обработки платежей Visa будет использовать токенизированные учётные данные и авторизацию в режиме реального времени. «По мере того, как агенты ИИ становятся активными участниками экономики, Visa сосредоточена на обеспечении доверия, безопасности и бесперебойности транзакций», — заявил Джек Форестелл (Jack Forestell), директор по продуктам и стратегии Visa. Он сообщил, что что Visa будет рассматривать споры, используя те же основные правила, что и для любой другой транзакции: действительно ли потребитель намеревался совершить покупку, и правильно ли продавец оформил транзакцию. Изменения могут произойти, добавил он, если и намерение потребителя, и обработка транзакции продавцом были выполнены правильно, но «что-то произошло посередине, что вызвало проблему». «Именно поэтому мы меняем всю нашу систему токенов и процесс сбора данных с помощью Visa Intelligent Commerce, чтобы гарантировать, что эта проблема не возникнет», — сказал Форестелл. Банки и продавцы выразили обеспокоенность по поводу использования ИИ для совершения покупок, поскольку агенты могут потратить больше, чем хотели бы пользователи, или совершить покупки, которые клиенты впоследствии оспорят. Особенную обеспокоенность у банков вызывает то, что чётко не определено, кто будет нести ответственность за мошенничество, если агент использует счёт держателя карты. Как отметило агентство Associated Press, платёжная система Mastercard также внедряет функции покупок с использованием ИИ в свою платёжную сеть, но в меньшем масштабе. В частности, Mastercard объявила, что ИИ-агенты смогут приобретать услуги от имени бизнеса. Например, если кофейня захочет запустить рекламную кампанию в рамках выхода нового продукта, она сможет предоставить ИИ-агенту право приобретать услуги у веб-провайдеров и рекламных агентств. Глава Anthropic: правительство должно иметь право ограничивать опасные ИИ-модели
11.06.2026 [10:50],
Алексей Разин
Немало пострадавшая за свои принципы в споре с Пентагоном компания Anthropic устами своего генерального директора Дарио Амодеи (Dario Amodei) на этой неделе признала, что правительство должно иметь возможность блокировать распространение определённых ИИ-моделей, если в этом будут прослеживаться риски. 
Источник изображения: Anthropic При этом, как отмечается в публикации Bloomberg, новые ИИ-модели должны проходить обязательное тестирование независимыми экспертами для выявления рисков сразу по нескольким категориям, включая угрозы в сфере кибербезопасности и создания биологического оружия. По словам Амодеи, пришло время перейти от прозрачности к более серьёзному и юридически обязывающему регулированию отрасли ИИ. По сути, искусственный интеллект с точки зрения своего применения подобен транспортным средствам, самолётам и лекарственным препаратам, которые при неумелом использовании могут представлять угрозу для жизней множества людей. Если ИИ представляет неприемлемые риски с точки зрения общества и государства, у правительства должны быть полномочия для блокировки его распространения или хотя бы замедления с целью предварительной реализации мер безопасности. Ещё на прошлой неделе Амодеи призвал создать систему, которая позволила бы разработчикам ИИ и чиновникам сообща оценивать угрозы, исходящие от новых технологий. Президент США Дональд Трамп (Donald Trump) своим недавним указом хоть и наделил правительство полномочиями по доступу к ИИ-моделям, но никаких требований по их обязательной экспертизе не предусмотрел. Первоначальная версия ИИ-модели Mythos, которая позволяла эффективно находить уязвимости в информационной инфраструктуре, распространялась Anthropic в узком кругу близких к властям дружественных к США стран организаций, а после исключения функций, связанных с анализом кибербезопасности, модифицированная модель Claude Fable 5 была выпущена в широкий оборот на этой неделе. «Мы теперь должны сообща и не спеша создать хрупкий свод политик, который будет иметь дело с рисками и возможностями, нарастающими удивительно быстро с текущего момента», — подчеркнул глава Anthropic в своей публикации на страницах блога. Немецкий суд возложил на Google ответственность за ошибки в «Обзорах от ИИ»
11.06.2026 [09:46],
Павел Котов
Суд в Мюнхене постановил, что Google должна нести ответственность за неверную информацию, которая предоставляется в созданных с помощью ИИ новостных сводках и в поисковых «Обзорах от ИИ». В компании ответили, что в подавляющем большинстве случаев они всё-таки точные. 
Источник изображения: BoliviaInteligente / unsplash.com «Мы вкладываем значительные средства в качество „ИИ-обзоров“, чтобы гарантировать, что подавляющее большинство ответов содержит точные данные, и разрабатывались они, чтобы отражать существующую в интернете информацию. Мы внимательно изучим это решение, которое ещё не является окончательным», — заявил представитель компании ресурсу Android Authority. Google с самого начала не отрицала, что созданные с помощью ИИ материалы основаны на информации, полученной из различных источников в интернете, и всегда остаётся вероятность, что системы допустят ошибки при её анализе. Поэтому в компании рекомендуют перепроверять информацию, которая является для пользователей критически важной. Google стремится, чтобы в «Обзорах от ИИ» не всплывали недостоверные сведения, и у неё есть политики, выработанные для предотвращения подобных инцидентов. Решение немецкого суда в компании считают не окончательным, поэтому и история с ответственностью за галлюцинации служб ИИ в поиске ещё, вероятно, далека от завершения. Xiaomi представила ИИ-агента для программирования MiMo Code — он хорошо помнит, что делает
11.06.2026 [09:24],
Павел Котов
Xiaomi открыла исходный код проекта MiMo Code V0.1.0 — основанного на искусственном интеллекте помощника для написания кода, который предлагает решение одной из важнейших проблем: большинство ИИ-агентов быстро теряют контекст. 
Источник изображения: mimo.xiaomi.com Решение основано на открытом проекте OpenCode и распространяется под демократичной лицензией MIT. В базовой комплектации приложение предлагает бесплатный доступ к мультимодальной модели Xiaomi MiMo-V2.5, но её можно заменить сторонними решениями, в том числе DeepSeek, Kimi и GLM. Важнейшим достоинством MiMo Code является система постоянной памяти. Большинство ИИ-помощников программиста полностью зависят от контекстного окна модели — как только оно заполняется, агент начинает забывать предыдущие решения и диалоги. В MiMo Code задачу решили при помощи фонового субагента: когда активный диалог приближается к пределу, субагент автоматически сжимает всё в структурированную сводку, позволяя основному агенту продолжать работу в том же контексте. Каждые семь дней запускается дополнительная функция «/dream» — обслуживающий агент проверяет все старые сессии и файлы памяти, удаляет дубликаты, проверяет пути к файлам и производит сжатие обновлённого хранилища долговременной памяти. В MiMo Code также входит система Harness, разработанная специально для моделей MiMo — фреймворк разработан для использования базовых возможностей модели, не ограничивая ИИ одной только функцией конечной точки API. Система работает совместно с режимом Compose, который активируется по нажатии клавиши Tab. Вместо того, чтобы просить выполнять ИИ по шагу за раз, можно задать ему конечную цель, и агент попытается сформировать весь рабочий процесс: планирование, проектирование, написание кода, тестирование и проверку. Такой подход, по утверждению Xiaomi, позволяет получить на выходе «готовый продукт промышленного уровня». MiMo Code набрал 62 % в тесте SWE-Bench Pro и 72 % — в Terminal Bench 2, на 5 п.п. обогнав Claude Code с той же базовой моделью. ИИ-агент поддерживает даже голосовой ввод — за него отвечает модель MiMo-V2.5-ASR. Xiaomi MiMo Code на Apple macOS и Linux устанавливается через терминал, а для работы на Windows установка осуществляется через npm. Подключение к MiMo-V2.5 производится без регистрации. Чтобы потратить в этом году $70 млрд на ЦОД, компании Oracle придётся занять $40 млрд
11.06.2026 [08:18],
Алексей Разин
Компания Oracle в условиях бума ИИ стала важным, хотя и не самым очевидным игроком рынка облачных ЦОД, на какое-то время это даже сделало её основателя Ларри Эллисона (Larry Ellison) богатейшим человеком планеты. На новые заявления руководства Oracle о необходимости увеличить капитальные расходы и заимствования акции компании отреагировали снижением курса на 8,9 %. 
Источник изображения: Oracle Фискальный год Oracle завершился 31 мая, капитальные затраты компании за период составили $55,7 млрд, превысив ожидания, и в текущем фискальном году она намеревается поднять их на 25 % примерно до $70 млрд. Более того, фактические капитальные расходы Oracle достигнут $95 млрд, просто до $25 млрд из этой суммы она рассчитывает сразу вернуть из выплат своих клиентов. В феврале Oracle рассчитывала, что в новом фискальном году ограничится капитальными расходами на уровне $50 млрд, но теперь стало очевидно, что придётся выйти за рамки прежнего бюджета. Для этого придётся привлечь до $40 млрд заёмных средств, и этот фактор беспокоит инвесторов больше всего. Компании удалось заключить с клиентами контракты на сумму $75 млрд, условия которых подразумевают авансовые выплаты или поставку оборудования самими клиентами. Акции Oracle после публикации отчёта упали в цене на 8,9 %. Техасский ЦОД, который Oracle вместе с OpenAI строит в рамках проекта Stargate будет на три четверти готов в течение 90 дней, как стало известно на квартальном мероприятии. С начала этого года Oracle ввела в строй вычислительные мощности на 1,2 ГВт, что практически соответствует итогам работы за четыре предыдущих квартала в совокупности. За ближайшие четыре квартала Oracle рассчитывает выручить около $76 млрд на контрактах с клиентами, а в последующие два года — ещё около $217 млрд. В прошлом квартале выручка Oracle достигла $19,2 млрд, превысив ожидания аналитиков. Годовая выручка в размере $67,4 млрд тоже оказалась выше ожиданий. В любом случае, положительной динамике курса акций это всё равно не способствовало. Ёмкость рынка ЦОД для ИИ представители Oracle оценивают в триллионы долларов США в год. В прошлом квартале компании пришлось сократить 30 000 сотрудников, отчасти ради высвобождения средств на капитальные вложения. В целом, Oracle уже располагает контрактными обязательствами на сумму $638 млрд, которые она должна исполнять в течение нескольких последующих лет. |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



