|
Опрос
|
реклама
Быстрый переход
Meta✴ начала тестировать платформу для ИИ-поиска товаров
03.03.2026 [17:49],
Павел Котов
Meta✴✴ приступила к тестированию функции по поиску товаров в интерфейсе чат-бота с искусственным интеллектом — сервис составит конкуренцию аналогичным возможностям, которые уже появились в OpenAI ChatGPT и Google Gemini. 
Источник изображения: Shoper / unsplash.com Новой функцией могут воспользоваться некоторые американские пользователи чат-бота Meta✴✴ AI в веб-интерфейсе. При получении запроса он выдаёт карусель с изображениями товаров и подписями: информацией о бренде, веб-сайте и цене продукта. В формате списка также приводится краткое пояснение механизма рекомендаций. Представитель Meta✴✴ подтвердил агентству Bloomberg, что такая функция тестируется, но дополнительные подробности сообщить отказался. Ранее глава компании Марк Цукерберг (Mark Zuckerberg) поставил перед подчинёнными задачу разработать «персональный сверхинтеллект», который поможет Meta✴✴ AI конкурировать с другими популярными чат-ботами — в ChatGPT и Gemini уже появились первые функции электронной коммерции. В январе Цукерберг пообещал, что в ближайшие месяцы компания представит новые продукты, которые продемонстрируют её способность обеспечивать пользователям платформ Meta✴✴ «уникальный персонализированный опыт», основанный на их истории, интересах, контенте и отношениях. На практике рекомендации Meta✴✴ AI адаптируются к тому, что компания уже знает о местоположении пользователя, и к его полу — он определяется по имени. Когда женщина из Нью-Йорка попросила подобрать пуховик, сервис указал её местоположение и вывел только женские модели. Функций заказа и оплаты в чат-боте Meta✴✴ AI пока нет — можно переходить по ссылкам на страницы интернет-магазинов. В компании не сообщили, получает ли она комиссионные за рекомендации чат-бота, а также отдаёт ли платформа приоритет брендам, которые рекламируются в Facebook✴✴ и Instagram✴✴. Но предприятиям Meta✴✴ уже рекомендует ориентироваться на конкретных людей, которые заинтересованы в их продукции — «новые средства агентского поиска дадут людям возможность находить тот набор товаров, который им нужен», пообещал ранее господин Цукерберг. Alibaba представила малые ИИ-модели Qwen3.5, которые работают на ноутбуке и обходят аналоги OpenAI
03.03.2026 [17:28],
Павел Котов
Специализирующееся на технологиях искусственного интеллекта подразделение Alibaba Qwen представило новую линейку моделей — их отличают небольшие размеры и высокая производительность при качестве ответов, значительно превосходящем ведущие американские аналоги. 
Источник изображений: Alibaba Младшие в новой линейке модели Alibaba Qwen3.5-0.8B и 2B характеризуются как «миниатюрная» и «быстрая»; они предназначаются для разработки прототипов и быстрого развёртывания на мобильных устройствах с минимальной производительностью, когда время автономной работы имеет первостепенное значение. Мультимодальная Qwen3.5-4B предназначена для создания легковесных агентов и изначально поддерживает контекстное окно в 262 144 токена. Рассуждающая Qwen3.5-9B превосходит по возможностям американского конкурента — открытую OpenAI gpt-oss-120B, которая крупнее по размеру в 13,5 раза; модель от Alibaba демонстрирует знание языков и логическое мышление на уровне аспирантуры. Веса моделей доступны для всех желающих под лицензией Apache 2.0, которая допускает корпоративное и коммерческое использование, в том числе дополнительное обучение по мере необходимости. При разработке малых моделей серии Qwen3.5 компания отошла от стандартных архитектур Transformer — здесь использована гибридная архитектура, сочетающая нейросети Gated Delta Networks и разреженную смесь экспертов (Mixture-of-Experts — MoE). Гибридный подход помогает решить проблему «ограничения памяти», характерную для небольших моделей; Gated Delta Networks, в свою очередь, обеспечивает повышенную пропускную способность и уменьшенную задержку при ответе. Модели изначально мультимодальные. В отличие от предыдущих поколений, когда генераторы изображений «прикреплялись» к текстовым моделям, Qwen3.5 обучались на мультимодальных токенах. В результате версии 4B и 9B умеют распознавать элементы пользовательского интерфейса и подсчитывают объекты на видео. В визуальном тесте MMMU-Pro модель Qwen3.5-9B набрала 70,1 балла, обогнав Google Gemini 2.5 Flash-Lite (59,7) и даже специализированную Qwen3-VL-30B-A3B (63,0). В тесте на логическое мышление она получила 81,7 балла, превзойдя результат OpenAI gpt-oss-120b (80,1), у которой более чем вдесятеро больше параметров. В математическом бенчмарке HMMT Feb 2025 модель Qwen3.5-9B показала 83,2 балла, а вариант 4B — 74,0, доказав, что для решения сложных задач в области точных наук больше не нужны значительные облачные ресурсы. Старшая модель стала лидером в тесте OmniDocBench v1.5 с результатом 87,7 балла; в многоязычном MMMLU она набрала 81,2 балла, обойдя gpt-oss-120b, у которой 78,2 балла. 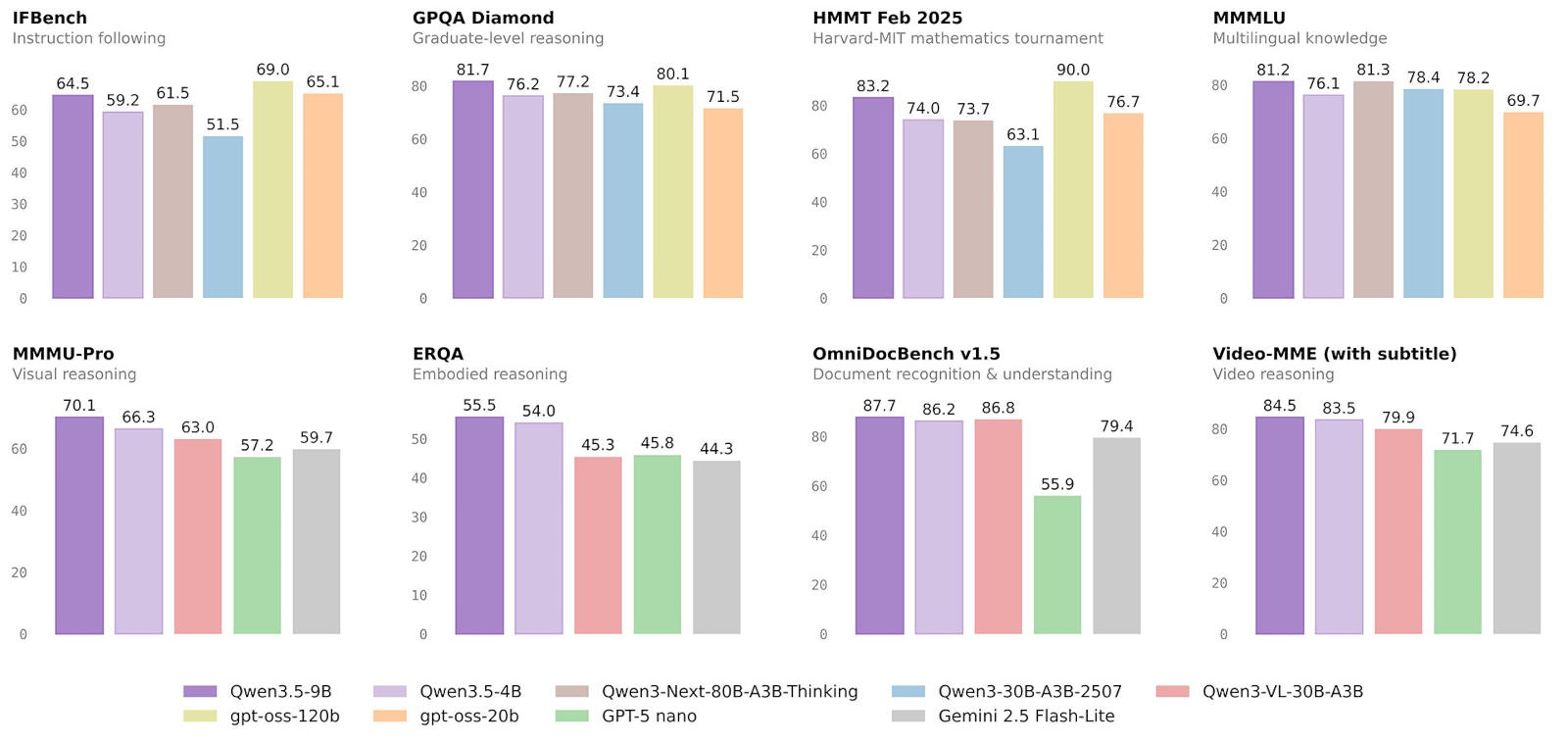 Выпуск моделей Qwen3.5 малой серии совпал с этапом расцвета ИИ-агентов. Простых чат-ботов современному пользователю уже недостаточно — растёт спрос на функции автономности. Автономный ИИ-агент должен «думать» (рассуждать), «видеть» (быть мультимодальным) и «действовать» (уметь пользоваться инструментами). Выполнять эти функции с моделями размером в триллионы параметров, очень дорого, а эксплуатация Qwen3.5-9B обходится значительно дешевле. Масштабировав технологию обучения с подкреплением в средах с миллионами агентов, Alibaba наделила эти модели функциями «человеческого суждения» — они могут организовать рабочий стол или провести обратное проектирование игры в код по видеозаписи. Запущенная на смартфоне версия на 0,8 млрд параметров или на рабочей станции модель на 9 млрд параметров делают «эпоху агентов» демократичной. Организации могут запускать ИИ-агентов на собственных локальных ресурсах, не расходуя средства на подключение к облачным ресурсам и не используя средства API. Используя механизм «привязки на уровне пикселей», эти модели способны перемещаться по пользовательским интерфейсам ПК и мобильных устройств, заполнять формы и сортировать файлы, выполняя инструкции на простом языке. С продемонстрированной в тестах точностью 90 % они производят оптическое распознавание текста, анализируют макеты и извлекают структурированные данные из форм и диаграмм в документах. Можно загружать целые репозитории кода (до 400 000 строк) в контекстное окно размером до 1 млн токенов для рефакторинга или автоматизированной отладки. Предназначенные для мобильных устройств модели Qwen3.5-0.8B и 2B могут в локальном режиме составлять сводки по видео при длине до 60 секунд и частоте до 8 кадров в секунду; а также демонстрировать пространственное мышление. Указываются и аспекты, на которые следует обращать внимание при развёртывании малых моделей Qwen3.5. В многоэтапных агентных сценариях одна ошибка на раннем этапе выполнения задачи может привести к каскаду сбоев, при котором агент будет следовать неверному или бессмысленному плану. Модели хорошо справляются с написанием кода с нуля, но могут испытывать затруднения с отладкой или доработкой сложных устаревших проектов. Для производительной работы модели Qwen3.5-9B требуется значительный объём видеопамяти. При развёртывании моделей на предприятиях следует отдавать приоритет «проверяемым» задачам: написанию кода, математическим вычислениям или следованию инструкциям — всему тому, где результаты можно проверить на соответствие определённым нормам, чтобы избежать скрытых сбоев. Сэм Альтман пообещал, что OpenAI внесёт поправки в «скользкий» контракт с Минобороны, чтобы защитить людей от слежки
03.03.2026 [13:52],
Алексей Разин
Вскоре после того, как Пентагон отказался от использования ИИ-моделей Anthropic из-за сопротивления руководства компании предоставить ведомству полную свободу их применения, соответствующая сделка была заключена с конкурирующей OpenAI. Глава последней Сэм Альтман (Sam Altman) признал, что этот шаг выглядел не очень красиво в сложившихся обстоятельствах. 
Источник изображения: OpenAI Напомним, что до заключения сделки с Министерством войны США, как оно теперь называется, Альтман выражал солидарность с позицией своего бывшего соратника Дарио Амодеи (Dario Amodei), который ныне возглавляет Anthropic. Однако, как только военное ведомство США отказалось от услуг этой компании и начало искать альтернативу для внедрения в свою секретную инфраструктуру, сделка с OpenAI была заключена поспешно и на не самых прозрачных условиях. Альтман назидательно повторял после заключения контракта с Пентагоном, что интересы правительства выше принципов любой частной компании. В конце прошлой недели Альтман настаивал, что изначальный вариант соглашения OpenAI с Пентагоном подразумевал больше ограничений, чем все предыдущие случаи применения ИИ в секретных системах, включая сделку с Anthropic. К понедельнику генеральный директор OpenAI Сэм Альтман заявил, что заключать соглашение с Пентагоном не следовало бы в такой спешке, а его условия будут пересматриваться уже после сделки, и изменения вносятся в настоящий момент. Он отметил, что в тексте соглашения следовало бы явно прописать, что «ИИ-система не должна намеренно использоваться для наблюдения за гражданами и жителями США на территории страны». Как подчеркнул Альтман, Министерство войны понимает, что существуют подобного рода ограничения на применение ИИ, даже если данные о гражданах были получены третьей стороной. Соответствующие правки будут внесены в текст соглашения OpenAI с военным ведомством США. OpenAI также удалось получить от Министерства войны США гарантии того, что ИИ-инструменты компании не будут использоваться разведывательными структурами типа АНБ. Альтман пояснил: «Есть много вещей, к которым технология пока не готова, и много сфер, в которых мы не понимаем, какими должны быть уступки для обеспечения безопасности». Компания, по его словам, готова сотрудничать с Пентагоном для создания технических ограничений, обеспечивающих безопасное применение ИИ. Поспешность заключения сделки в пятницу он объяснил желанием снизить градус эскалации и избежать гораздо худшего исхода, но он понимает, что со стороны всё выглядело «оппортунистическим и скользким». Ещё в пятницу глава OpenAI сообщил, что Пентагон согласился на ограничения использования технологий, выдвинутые компанией. Публичное недовольство действиями OpenAI уже привело к тому, что люди начали отказываться от ChatGPT в пользу решений Anthropic. Последняя с момента своего основания в 2021 году делает особый упор на безопасное применение ИИ. Условия соглашения OpenAI с Пентагоном были пересмотрены не в последнюю очередь под давлением общественности. Даже сотрудники компании начали выражать недовольство первоначальным вариантом сделки. В минувшие выходные перед штаб-квартирой OpenAI в Сан-Франциско появилась выполненная мелом надпись "Нет массовой слежке!". Альтман добавил, что в тексте соглашения с Anthropic фигурировали простые формулировки ограничений, но не было ссылок на соответствующие законодательные акты, тогда как сама OpenAI в предоставлении таких ссылок проблем не видела. OpenAI подтверждает, что может ограничивать применение своих технологий для массовой слежки за гражданами США и управления вооружениями, предназначенными для автоматического выбора и уничтожения целей. Компания разрешила Пентагону применять свои ИИ-модели только в облачной части инфраструктуры с сохранением доступа к ним со стороны своих сотрудников, но не на конечном оборудовании военной техники, которое используется для управления оружием. В действительности OpenAI уступила Пентагону в вопросах применения ИИ для слежки и в военных целях
03.03.2026 [12:04],
Павел Котов
OpenAI заключила с Пентагоном соглашение об использовании разработанных компанией систем искусственного интеллекта, сменив Anthropic, у которой возникли серьёзные сомнения в моральной стороне такого сотрудничества. В ответ на обеспокоенность общественности глава OpenAI Сэм Альтман (Sam Altman) объявил, что компания успешно договорилась с Министерством обороны США о новых условиях соглашения, но на деле это не вполне так, пишет The Verge. 
Источник изображения: Mariia Shalabaieva / unsplash.com «Два важнейших для нас принципа безопасности — это запрет на внутреннюю массовую слежку и ответственность человека за применение силы, в том числе с автономными системами вооружения. Министерство обороны согласилось с этими принципами, отражая их в законах и политике, и мы включили их в наше соглашение», — подчеркнул Альтман. В соцсетях, однако, стали выражать сомнения по поводу того, что OpenAI удалось договориться с Пентагоном о соблюдении этих ограничений. Эксперты считают, что в действительности Министерство обороны США не уступило, и сделка с OpenAI предполагает более мягкие условия для ведомства — всё упирается в формулировку «любое законное применение». В ходе переговоров, сообщил осведомлённый источник издания, Пентагон не отступал от желания собирать и анализировать большие объёмы данных, связанных с гражданами США; OpenAI же открыла военным возможность выполнять любые действия, которые с технической точки зрения являются законными. За последние десятилетия американские власти в значительной мере расширили представления о том, что «технически законно», и в это определение сейчас включаются программы массовой слежки. В OpenAI, впрочем, такую интерпретацию отвергли. «Систему нельзя использовать для сбора или анализа данных американцев в больших объёмах, в неограниченном объёме или в обобщённом виде», — заявила представитель компании. Важнейшим достоинством систем ИИ является их умение находить закономерности, а поведение человека — это как раз набор закономерностей. ИИ способен объединять источники данных для каждого человека: информацию о местоположении, о просмотре веб-страниц, личную финансовую информацию, записи с камер видеонаблюдения, данные о регистрации избирателей и многое другое — часть из этого массива находится в открытом доступе, а часть приобретается у брокеров данных. Anthropic добивалась того, чтобы эти действия не допускались вне зависимости от их правового статуса, а OpenAI ограничилась существующими законодательными ограничениями. Упоминаются, в частности, Четвёртая поправка к Конституции США, «Закон о национальной безопасности» от 1947 года, «Закон о внешней разведке и наблюдении» от 1978 года, Исполнительный указ номер 12333, а также директивы ведомства, в которых указываются конкретные цели в области внешней разведки. 
Источник изображения: Growtika / unsplash.com После трагедии 11 сентября 2001 года американские спецслужбы усилили систему слежки, сохранив её, по их мнению, в пределах действующего законодательства. В 2013 году подрядчик Агентства национальной безопасности Эдвард Сноуден (Edward Snowden) раскрыл истинные масштабы происходящего: запись телефонных разговоров абонентов оператора Verizon и сбор данных о физических лицах у технологических компаний, в том числе Microsoft, Google и Apple. А исполнительный указ 12333 позволяет спецслужбам перехватывать данные вне США, даже если эти данные содержат сведения о гражданах страны, отмечают эксперты. Глава Anthropic Дарио Амодеи (Dario Amodei) отмечал, что закон ещё не описывает всех возможностей ИИ по проведению массовой слежки. Альтман, в свою очередь подчеркнул, что контракт OpenAI с Пентагоном ограничен действующим законодательством, то есть если в США начнут действовать новые нормы, формулировки соглашения останутся прежними. Эксперты, однако, обращают внимание, что использованные представителем компании формулировки не дают возможности определить, что именно запрещается в соглашении. «Использование слов „неограниченный“, „обобщённый“, „открытый“ способ — это не полный запрет. Это формулировка, призванная дать руководству свободу выбора. <..> Она также позволяет руководству не лгать сотрудникам, если Пентагон на законных основаниях будет использовать большие языковые модели без ведома руководства OpenAI», — говорят эксперты. Соглашение с OpenAI и действующие правовые ограничения позволяют Пентагону, например, искать информацию об американцах по базам иностранных разведок, скупать базы у брокеров данных и создания профилей граждан по их типичному поведению на основе материалов видеонаблюдения, публикаций в соцсетях, новостей онлайн, данных о регистрации избирателей и других источников. Сомнения вызывает и позиция OpenAI по поводу автономного летального оружия. В контракте компании с Пентагоном говорится о том, что её ИИ «не будет использоваться для самостоятельного управления автономным оружием в тех случаях, когда закон, нормативные акты или политика Министерства требуют контроля со стороны человека», что соответствует директиве Пентагона от 2023 года, но не предполагает иных запретов и ограничений. Для сравнения, Anthropic добивалась полного запрета на неконтролируемое летальное автономное оружие как минимум до тех пор, пока разработчик сам не сочтёт эту технологию готовой к работе. 
Источник изображения: Gavin Phillips / unsplash.com Альтман указывает и на другие решения, способные гарантировать, что Пентагон не станет злоупотреблять возможностями ИИ-моделей OpenAI. Некоторые сотрудники компании получат доступ к секретной информации для проверки систем; будут развёрнуты «классификаторы» — небольшие модели ИИ, способные следить за работой больших и по необходимости блокировать для них некоторые операции. На практике эти меры могут не помочь. Классификатор не сможет подтвердить, проверял ли человек решение системы о нанесении удара, а также является ли запрос на составление профиля американского гражданина единичным или входящим в систему массового наблюдения. И если власти объявят какую-либо операцию законной, классификатор не сможет предотвратить её выполнение. OpenAI говорит об «ответственности человека за применение силы, в том числе в случае с автономными системами вооружения»; Anthropic же требовала вообще не развёртывать эти системы «без надлежащего контроля [со стороны человека]». Это может значить, что в сценарии OpenAI можно будет привлечь к ответственности некое лицо уже после факта нанесения удара, а сценарий Anthropic предусматривает участие людей до и/или во время принятия ИИ решения об уничтожении других людей. OpenAI говорит о технической защите своих систем от возможности строить «роботов-убийц»: для этого применяются средства дополнительного обучения ИИ, а также запуск моделей только в облачной инфраструктуре, а не локально на устройствах. В случае массового наблюдения, однако, подойдёт только способная работать в облаке модель; а в сценарии с автономным оружием непосредственное решение об атаке может принимать сторонняя локальная модель, тогда как система OpenAI возьмёт на себя все предшествующие этапы. «Полностью автономное оружие (то, что полностью исключает участие человека в автоматическом выборе и поражении целей) может оказаться критически важным для нашей национальной обороны. Но сегодня передовые системы ИИ просто недостаточно надёжны для обеспечения [его] работы», — предупредил глава Anthropic Дарио Амодеи. Верховный суд США подтвердил, что ИИ-искусство не может защищаться авторским правом
03.03.2026 [10:00],
Алексей Разин
В сфере авторского права в эпоху искусственного интеллекта американский учёный Стивен Талер (Stephen Thaler) обретает определённую известность, поскольку он уже несколько лет пытается добиться право регистрации за собой изобретений, созданных силами искусственного интеллекта. Он попытался зарегистрировать и авторские права на картину, которая была сгенерирована его системой DABUS, но эти попытки были отклонены недавно Верховным судом США. 
Источник изображения: Unsplash, Sasun Bughdaryan Как поясняет Reuters, Верховный суд США на этой неделе отклонил апелляцию Стивена Талера на решения судов более низких инстанций по поводу регистрации авторских прав на художественное произведение «Недавний вход в рай», которое было создано его ИИ-системой DABUS несколько лет назад. Энтузиаст с 2018 года пытался в США зарегистрировать авторские права на изображение железнодорожных рельсов, уходящих в некий портал, раскрашенный в яркие контрастные цвета. Профильное ведомство США, которое занимается регистрацией авторских прав, отклонило его заявку в 2022 года, мотивируя необходимость закрепления подобных прав за человеком, а не бездушной системой. Более того, ведомство отклоняло и заявки на регистрацию авторских прав художниками, которые создавали свои произведения с использованием большой языковой модели Midjourney. Они настаивали, что являются соавторами данных произведений, тогда как Талер не скрывал, что разработанная им система DABUS создала свою картину без человеческого влияния. В 2023 году суд в Вашингтоне поддержал решение суда нижней инстанции по делу Талера, столичный апелляционный суд подтвердил правомерность такого вердикта в 2025 году. Талер рассчитывал на Верховный суд США, но тот отклонил его апелляционную жалобу. По мнению истца, подобное решение Бюро авторского права США изначально нанесло непоправимый ущерб всей ИИ-отрасли и деятелям творческих профессий в столь важный для их развития период. Ведомство настаивает, что понятие «автор» может применяться только к живому человеку, а не машине. Талер также проиграл в серии отдельных дел, которые должны были закрепить за ним авторские права на изобретения, сделанные искусственным интеллектом его разработки. Тем не менее, в той же Австралии суд встал на его сторону. Скандал между Anthropic с Пентагоном может обойтись стартапу потерей инвестиций на $60 млрд
03.03.2026 [08:49],
Алексей Разин
Как и OpenAI, конкурирующий стартап Anthropic остаётся частной компанией, хотя привлекает для своего развития весьма серьёзные суммы денег. Более 200 венчурных инвесторов вложили в Anthropic в общей сложности более $60 млрд, и теперь их доверие будет испытано на прочность скандалом, в который компания оказалась втянута из-за противоречий с Пентагоном. 
Источник изображения: Anthropic Напомним, что в конце прошлой недели американское военное ведомство отказалось от использования ИИ-разработок Anthropic в секретной части своей инфраструктуры, поскольку стартап настаивал на блокировке использования своих систем для массового слежения за гражданами США и управления теми видами вооружений, которые способны принимать решение о выборе и уничтожении целей без участия человека. Проблем в переговорах добавили и некоторые другие факторы, но они не были первостепенными. Генеральный директор Anthropic Дарио Амодеи (Dario Amodei) настаивает, что для применения в указанных видах вооружений ИИ пока не достиг адекватного развития, а в случае с массовым сбором информации о гражданах США не готова законодательная база. Контракт с Пентагоном был сорван, решения Anthropic были запрещены к использованию всеми американскими правительственными структурами, за шесть месяцев им предстоит найти альтернативу. Публикация Амодеи на страницах корпоративного блога, в которой обсуждались коренные причины спора с Министерством войны США, как отмечает Axios, вызвала в Белом доме дополнительное раздражение. Чиновники опасаются, что своими публичными выступлениями руководство Anthropic «заразит» специалистов других ИИ-компаний, с которыми Пентагон хотел бы наладить сотрудничество. Если запрет на сотрудничество с Anthropic распространится на прочих подрядчиков Пентагона, компания может пострадать серьёзным образом. По крайней мере, та же Nvidia может лишиться возможности снабжать Anthropic своими ускорителями вычислений, а без них развитие бизнеса стартапа станет проблематичным. Как известно, Anthropic своё отнесение к числу сомнительных поставщиков хочет оспорить в суде. По данным Axios, венчурные инвесторы исторически старались избегать вложения средств в капиталы компаний, связанных с правительственными заказами, поскольку эта сфера казалась довольно рискованной и непредсказуемой. Исключением была сфера только биотехнологий, но в последние годы венчурные капиталисты стали посматривать и на другие области, в которых стартапы вели активное сотрудничество с властями. Ситуация с Anthropic снова заставляет инвесторов задуматься, а нужно ли слепо доверять компаниям, пытающимся наладить сотрудничество с правительством. На репутации Anthropic, которая в основном зарабатывает на корпоративных заказах, данный скандал тоже скажется не лучшим образом. На охоту за недорогими модулями DDR5 вышли боты, управляемые спекулянтами
03.03.2026 [08:20],
Алексей Разин
Апокалиптические сценарии по порабощению человека искусственным интеллектом, возможно, останутся в фантазиях голливудских сценаристов, но в реальной жизни человеку уже приходится бороться за ресурсы с ИИ. По крайней мере, он уже используется для скупки модулей памяти, необходимых для развития собственной вычислительной инфраструктуры. 
Источник изображения: Micron Technology Исследователи Galileo, на которых ссылается TechRadar, установили, что программные боты в шесть раз чаще людей обращаются к страницам интернет-магазинов, на которых можно заказать модули памяти типа DDR5. Подобная активность редко приветствуется продавцами, в ходе одной из кампаний было заблокировано более 10 млн запросов, исходящих от ботов. Контрольная выборка показала, что за один час боты сделали 50 000 обращений к 91 страницам интернет-магазинов с предложениями купить DDR5. Каждая страница опрашивалась ими в течение часа в среднем 551 раз, что соответствует одному запросу каждые 6,5 секунд. Ассортимент предложений, охватываемых ботами, простирается от оснащаемых красочными радиаторами и RGB-подсветкой модулей DDR5 до планок памяти промышленного назначения. Фактически, боты используются даже для мониторинга отдельных компонентов, предназначенных для производителей материнских плат — например, самих разъёмов DIMM. Опросы осуществляются круглосуточно с небольшими перерывами, вызываемыми техническими сбоями. В таких условиях у живых покупателей остаётся меньше шансов приобрести желаемые модули памяти по адекватной цене. Серверы Apple «не тянут» умную Siri — компания просит Google помочь с оборудованием
03.03.2026 [06:12],
Анжелла Марина
Apple столкнулась с неэффективностью собственной облачной инфраструктуры Private Cloud Compute, предназначенной для обработки ИИ-запросов. Мощность серверов, специально предназначенных для этих целей, в среднем используются лишь на 10 %, а часть оборудования пылится на складах. 
Источник изображения: Apple По данным 9to5Mac, которые ссылаются на издание The Information, Apple обратилась к Google с просьбой о размещении своих новых моделей Siri на её серверах, так как фрагментация внутренних систем, при которой разные команды Apple работают с изолированными технологическими стеками, не позволяет гибко перераспределять ресурсы. Одновременно финансовый отдел выражает недовольство растущими затратами на дублирующую инфраструктуру и пока не желает вкладывать миллиарды в её перестройку. Технически платформа также отстаёт: модифицированные процессоры M2 Ultra не обеспечивают той производительности, которая необходима для запуска больших языковых моделей (LLM), а обновления программного обеспечения требуют значительных усилий и времени. На этом фоне низкий пользовательский интерес к функциям Apple Intelligence усилил сомнения в целесообразности дальнейшего развёртывания собственных дата-центров. Apple обратилась к Google с просьбой о размещении своих новых моделей Siri на её дата-центрах, поскольку собственная инфраструктура Private Cloud Compute не справляется с тяжёлыми задачами, а Google, напротив, уже имеет большой опыт массового развёртывания серверов для LLM благодаря проекту Gemini. ChatGPT подвергли «отмене» за сотрудничество OpenAI с Пентагоном
02.03.2026 [13:27],
Павел Котов
Обеспокоенные сомнительным сценарием сотрудничества компании OpenAI и Министерства обороны США представители американской общественности сформировали движение по «отмене ChatGPT». Цель движения — поддержать попавшую в «чёрный список» Пентагона компанию Anthropic, которая запретила использовать свои модели искусственного интеллекта для некоторых целей. 
Источник изображения: Levart_Photographer / unsplash.com Конфликт Anthropic и Пентагона разгорелся на почве двух «красных линий», которые разработчик ИИ переходить отказался. Компания не захотела, чтобы её модели самостоятельно принимали решения о применении оружия по человеку, а также чтобы они использовались для наблюдения за американскими гражданами. В результате соглашение с Anthropic расторгли, а саму компанию поместили в «чёрный список», запретив всем оборонным подрядчикам с ней сотрудничать. Место Anthropic в системах Пентагона заняла OpenAI. Глава компании Сэм Альтман (Sam Altman) пообещал, что её модели не станут использоваться для массового наблюдения, но представитель американского правительства опроверг это утверждение и заявил, что они будут работать во «всех законных сценариях», а принятый после трагедии 11 сентября 2001 года «Патриотический акт» позволяет, в частности, собирать метаданные в сетях связи, даже с учётом того, что некоторые его аспекты в последние годы ограничили. 
Источник изображения: Dima Solomin / unsplash.com Этот шаг вызвал резко отрицательную реакцию в сетевых сообществах — люди, которые заявляли, что прекращают пользоваться ChatGPT, стали получать положительные оценки. Следует отметить, что пересекать указанные Anthropic «красные линии» отказываются далеко не все крупные разработчики ИИ. Во внутренних правилах Google такой запрет значился ранее, но теперь компания его отменила. Microsoft не возражает против использования оружия с ИИ, если собственно выстрел производит человек. Amazon ограничивается расплывчатой формулировкой об «ответственном использовании» ИИ. Впоследствии Сэм Альтман повторил тезис, что Министерство обороны США будет соблюдать заявленные компанией «красные линии» в отношении автономного оружия и массового наблюдения за гражданами США, но не внёс ясности, как эти гарантии будут реализованы. Глава OpenAI сослался на действующее в США законодательство, а оно, в частности, допускает наблюдение за лицами без американского гражданства, и в этих целях позволяет косвенным или случайным образом собирать данные о гражданах страны. В глазах общественности, однако, OpenAI предоставила Пентагону возможность интерпретировать, что считается законным, а Anthropic решила сохранить полный контроль над использованием своих технологий. В результате приложение Anthropic Claude AI выбилось в лидеры официальных магазинов как для Android, так и для iOS; оно также выпущено для Windows 11. Новейшая ИИ-модель DeepSeek V4 должна быть оптимизирована под китайские ускорители вычислений
02.03.2026 [09:00],
Алексей Разин
На этой неделе, как сообщает Financial Times, китайская DeepSeek должна представить долгожданную мультимодальную ИИ-модель V4, которая была оптимизирована под использование ускорителей Huawei и Cambricon. В совокупности это позволит китайским компаниям добиться определённых успехов во внедрении технологий ИИ без чрезмерной зависимости от импортных решений. 
Источник изображения: DeepSeek По данным источника, сроки анонса модели DeepSeek V4 будут привязаны к парламентскому заседанию в КНР, которое начнётся 4 марта. Данный релиз для DeepSeek станет крупнейшим с января прошлого года, когда была представлена рассуждающая модель R1. Тогда утверждалось, что китайской компании удалось создать сопоставимую по эффективности с западными решениями ИИ-модель при значительно меньших затратах. Позже выяснилось, что DeepSeek не только могла использовать данные американских моделей для обучения своих, но и опираться на ускорители вычислений Nvidia, которые в необходимом компании ассортименте моделей находятся в КНР под санкциями. Как ожидается, оптимизация DeepSeek V4 под ускорители Huawei и Cambricon будет способствовать росту спроса на эти аппаратные решения в Китае, а также снижению импортозависимости. DeepSeek якобы даже намеренно не оптимизировала свою новейшую модель под ускорители Nvidia. Ранее сообщалось, что первые попытки DeepSeek обучать модель V4 на ускорителях Huawei не увенчались особым успехом. Аннотация к DeepSeek V4 выйдет на этой неделе в сокращённом виде, но примерно через месяц будет опубликована в полном размере. Американская Anthropic недавно обвинила DeepSeek в «дистилляции» собственных ИИ-моделей. Пентагон и Anthropic пытались спасти сделку до последнего момента
02.03.2026 [08:30],
Алексей Разин
На прошлой неделе вокруг сотрудничества Anthropic с Министерством обороны США разразился скандал, который привёл к включению компании в список неблагонадёжных поставщиков и потере ею всех правительственных контрактов. Как поясняет The Atlantic, даже на поздних этапах переговоров противоречия пытались сглаживаться обеими сторонами, но им так и не удалось найти общий язык. 
Источник изображения: Unsplash, Sergey Koznov Напомним, компанию Anthropic смущала перспектива использования её ИИ-систем для массового слежения за гражданами США и автономно управляемых систем вооружения, которые могли бы самостоятельно определять цели и уничтожать их. Ещё в пятницу утром, как сообщает источник, представители американского военного ведомства были готовы пойти на уступки, прописав в тексте контракта соответствующие ограничения, но с важной оговоркой. В исключительных случаях Министерство войны США, как оно теперь называется, хотело оставить за собой право и следить за гражданами страны, и применять ИИ для управления системами вооружений. Представители Anthropic до последнего момента надеялись, что вторая сторона переговоров подобные исключения прописывать не будет, но чуда не произошло, а потому всё завершилось срывом контракта. Главная причина, которая этому способствовала, заключалась в намерениях властей США использовать ИИ компании Anthropic для анализа данных, собираемых об активности американских граждан. Переписка с чат-ботами, социальные сети, история поиска в Google, перемещения с указаниями координат GPS, транзакции по банковским картам и счетам — все эти данные о конкретном гражданине могли быть проанализированы и взаимосвязаны для нужд правительственных структур США. Anthropic это явно не устраивало, поэтому данное противоречие и стало ключевым в развале сделки с Пентагоном. В части управления системами вооружений Anthropic не противилась данной идее в целом, но пыталась сделать его более безопасным. Руководство компании считает, что на современном этапе развития ИИ не настолько совершенен, чтобы управлять вооружениями в полной мере. На одном из этапов переговоров Anthropic настаивала, чтобы её ИИ применялся военными только в пределах облачной инфраструктуры, не переходя на периферийный уровень — грубо говоря, внутри самого дрона или иного автономного средства уничтожения целей. Если бы дроны при таком разделении допускали фатальные ошибки, номинально ИИ компании Anthropic нельзя было бы обвинить в них. Пентагон подобного разделения обеспечить не мог, поскольку современная архитектура управления военной техникой и живой силой не подразумевает чёткой границы между облачными и периферийными вычислениями. Anthropic сама пришла к выводу, что изолировать свой ИИ в облаке она не сможет, а потому связываться с управлением вооружениями лучше вообще не следует. Отдельного внимания заслуживает поведение конкурирующей OpenAI, чей руководитель Сэм Альтман (Sam Altman) выражал солидарность с Anthropic за несколько часов до того, как объявил о достижении договорённости с Пентагоном об использовании ИИ этой компании в секретных системах американского военного ведомства. Он поделился своими взглядами на ситуацию с Anthropic, и ключевой его тезис заключается в том, что в вопросах такого уровня последнее слово должно оставаться не за частной компанией, а за государством. Глава OpenAI заявил, что частные компании не могут иметь больше власти, чем правительство США
02.03.2026 [07:33],
Алексей Разин
Вечером в пятницу Сэм Альтман (Sam Altman) заявил, что возглавляемая им OpenAI заключила с Пентагоном контракт на внедрение технологий ИИ в секретные системы этого ведомства. Чтобы развеять страхи и сомнения общественности по поводу её условий, Альтман провёл сессию вопросов и ответов, заявив о верховенстве демократически избранного правительства над принципами любых частных компаний. 
Источник изображения: OpenAI Напомним, попытки Пентагона внедрить ИИ разработки Anthropic в свои секретные системы без ограничений на его использование наткнулись на протест со стороны разработчиков, в результате контракт на $200 млн был расторгнут, а сама Anthropic попала в список неблагонадёжных поставщиков. Использовать её разработки всем американским правительственным структурам было запрещено, в течение шести месяцев они должны найти замену сервисам Anthropic. Альтман на страницах социальной сети X сообщил, что сделка между OpenAI и Пентагоном была заключена очень быстро для снижения накала ситуации, в обычных условиях переговоры заняли бы больше времени. Он признал, что если сделка OpenAI позволит снизить напряжённость в отношениях Министерства обороны США (с недавних пор — Министерства войны) с представителями отрасли, то на имидже компании это скажется положительным образом. Если же устранить эти противоречия не удастся, то OpenAI обвинят в небрежности и поспешности заключения сделки, как заявил Альтман. Впрочем, пока он видит больше положительных для OpenAI сигналов в этой сфере. Рассуждая, почему именно OpenAI была выбрана в роли подрядчика американскими военными, а не Anthropic, Альтман предположил, что на уровне «языка контракта» обе стороны пришли к согласию быстрее, чем в случае с конкурентом. Глава OpenAI выдвинул гипотезу, что Anthropic пыталась сохранить больше операционного контроля за использованием своих разработок Пентагоном, чем это пытается сделать его компания. Говоря о так называемых «красных линиях», Альтман назвал три ключевых принципа, которых OpenAI готова придерживаться в сфере этики применения ИИ своими клиентами. С другой стороны, как отмечает глава компании, она готова пересматривать данные принципы по мере развития технологий, но при некотором стечении обстоятельств «красных линий» может стать больше. «Для нас нормально, если ChatGPT будет искать ответ на тот или иной противоречивый вопрос. Но я действительно не хотел бы, чтобы мы решали, что делать, если ядерная бомба будет направлена против США», — пояснил позицию OpenAI Альтман. Он добавил, что страной руководят демократически избранные лидеры, и было бы странно, если бы частная компания сама решала, что этично, а что нет, в самых важных областях. По словам Альтмана, переговоры между OpenAI и Пентагоном по поводу использования ИИ-сервисов компании в несекретной части бизнес-процессов ведомства велись на протяжении долгих месяцев, но сферы секретных операций они коснулись лишь недавно. В своих переговорах с Министерством обороны США, как подчеркнул Альтман, OpenAI старалась добиться равных условий взаимодействия ведомства со всеми участниками рынка. Глава компании пояснил, что Anthropic в этой ситуации выглядит не очень красиво, поскольку она сперва поясняет правительству, что в сфере ИИ на международной арене имеются некоторые риски, а потом отказывается помогать ему, обвиняя в разного рода грехах. Реакцию властей США в этой ситуации можно понять, как считает Альтман. По его словам, руководители частных компаний не должны иметь столько же власти, как избранные правители, но помогать последним они могут. Глава OpenAI привёл два примера использования ИИ в сфере национальной безопасности, которые способны продемонстрировать его реальную пользу. Во-первых, ИИ может применяться для защиты от массовых хакерских атак. Во-вторых, сфера биологической безопасности может стать тем полигоном применения ИИ, который позволит предотвратить новую пандемию, например. Anthropic обжалует в суде своё внесение в «чёрный список»
01.03.2026 [13:49],
Владимир Мироненко
Anthropic пообещала обжаловать в суде решение Министерства обороны США о её внесении в чёрный список поставщиков, представляющих риск для национальной безопасности, из-за отказа предоставить ведомству право использования своей модели Claude без каких-либо ограничений, добавив, что она «глубоко опечалена» эскалацией спора. 
Источник изображения: Anthropic В пятницу президент Дональд Трамп (Donald Trump и министр обороны Пит Хегсет (Pete Hegseth) пригрозили лишить Anthropic не только контракта на $200 млн с Пентагоном, но и многочисленных клиентов, присвоив ей статус «риска для цепочки поставок» (Supply Chain Risk), который исторически применяется к угрозам национальной безопасности, в частности, к китайским компаниям. В ответ компания заявила, что «никакое запугивание или угроза наказания» со стороны Министерства обороны США не изменит её позицию в отношении запрета использования Claude для массового слежения за американскими гражданами и полностью автоматизированных систем вооружений. «Мы будем оспаривать любое определение риска в цепочке поставок в суде», — сообщила Anthropic, также сославшись на статью 10 USC 3252, которая гласит, что определение риска для цепочки поставок может распространяться только на контракты с Пентагоном, то есть это определение не может относиться к военным подрядчикам, которые используют Claude для обслуживания других клиентов. Anthropic заявила, что этот спор не касается клиентов или компаний, имеющих с ней коммерческие контракты: «Если вы являетесь индивидуальным клиентом или имеете коммерческий контракт с Anthropic, ваш доступ к Claude — через наш API, claude.ai или любой из наших продуктов — совершенно не затронут». Компания добавила, что для подрядчиков Пентагона определение риска для цепочки поставок — если оно будет официально принято — повлияет только на использование Claude в рамках контрактов Министерства обороны США. При использовании ИИ-технологии в любых других целях всё остается без изменений. Акции Nvidia за неделю подешевели на 7 %, несмотря на неплохой квартальный отчёт
01.03.2026 [07:46],
Алексей Разин
На этой неделе Nvidia не только продемонстрировала рекордную квартальную выручку, которая превзошла ожидания рынка, но и дала более оптимистичный прогноз на текущий квартал, но это не помешало снижению курса её акций на протяжении двух торговых сессий, последовавших за публикацией отчётности. За неделю акции эмитента упали примерно на 7 %. 
Источник изображения: Nvidia Это максимальная величина снижения для этих ценных бумаг с ноября прошлого года, как отмечает CNBC. С начала текущего года акции Nvidia потеряли в цене около 4,2 %, они также повлекли за собой ценные бумаги многих других компаний технологического сектора. Инвесторов беспокоит вероятность достижения суммами капитальных затрат на строительство инфраструктуры ИИ пикового значения, после чего выручка Nvidia начнёт расти гораздо медленнее. Кроме того, строители инфраструктуры находят все больше альтернатив для решений Nvidia. OpenAI собирается арендовать крупные вычислительные мощности Amazon (AWS) на базе чипов Trainium. По всей видимости, это условие было частью сделки по финансированию OpenAI, в рамках которой Amazon направила в капитал стартапа свои $50 млрд, а Nvidia ограничилась $30 млрд. OpenAI получит доступ к 2 ГВт вычислительных мощностей, базирующихся на чипах Amazon Trainium. Это крупнейший пример использования данных решений сторонним клиентом Amazon. Впрочем, в инфраструктуре OpenAI по-прежнему продолжают доминировать решения Nvidia, поскольку первая компания договорилась об использовании до 5 ГВт мощностей на основе новейших GPU семейства Vera Rubin. Стартап также активно использует облачные мощности Microsoft, CoreWeave и Oracle. В части альтернативных разработчиков чипов у OpenAI имеется договорённость с Cerebras о привлечении 750 МВт мощностей на основе одноимённых решений. В текущем фискальном году, как ожидают аналитики, выручка Nvidia успеет вырасти на 65 %, но в последующие три года темпы роста снизятся сперва до 30 %, а потом до 13 % и 14 % соответственно. Meta✴✴ на правах крупного клиента Nvidia также активно изучает альтернативные вычислительные решения типа компонентов AMD и Google. Впрочем, текущее снижение курса акций Nvidia некоторые аналитики предлагают использовать для покупки этих ценных бумаг по более выгодной стоимости. YouTube запустил тест ИИ-ремиксов в Shorts: новые видео создаются из старых
28.02.2026 [18:32],
Павел Котов
Формат коротких вертикальных видео остаётся одним из наиболее востребованных развлечений на различных платформах — вот и в разделе YouTube Shorts стартовало тестирование новой функции. Искусственный интеллект предложит генерировать новые ролики на основе существующих. 
Источник изображения: BoliviaInteligente / unsplash.com В тестировании пока участвует «небольшая группа создателей контента» на YouTube. Им будут предложены два варианта: создание нового ролика на основе единственного кадра из существующего; а также возможность добавлять новые объекты в кадр видео, загруженного другим пользователем. Генерация видео осуществляется по простым текстовым запросам. Участвующие в тестировании пользователи смогут поработать с новыми функциями через меню «Ремикс коротких роликов» (Shorts Remix), которое появится только на подходящих для этого видео. В меню будут два варианта: «Добавить объект» и «Переосмыслить». В первом случае можно будет добавить новые объекты в кадр эпизода продолжительностью всего восемь секунд по текстовому запросу, который введёт сам пользователь, или предложит платформа. Во втором — необходимо будет выбрать кадр оригинального ролика и составить запрос на генерацию виде на его основе. На страницах созданных с помощью этих ИИ-инструментов производных видео будут публиковаться ссылки на исходные ролики. Авторы оригинальных видео смогут запретить другим пользователям генерировать какие-либо ремиксы своих произведений при помощи ИИ. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



