|
Опрос
|
реклама
Быстрый переход
Сооснователи Kingston Technology в этом году стали богаче на 44 % из-за бума ИИ
23.02.2026 [07:47],
Алексей Разин
Квартальные отчёты производителей микросхем памяти позволяют судить, насколько динамично растёт выручка и прибыль в этом виде бизнеса, но в цепочке между ними и конечными потребителями, если не считать поставщиков, находятся ещё и производители модулей памяти. Благосостояние двух основателей Kingston Technology только в этом году выросло на 44 % или $14 млрд. 
Источник изображения: Kingston Technology Как поясняет Business Insider Africa, по динамике роста личного благосостояния в этом году лучше себя показали разве что Илон Маск (Elon Musk) и мексиканский магнат Карлос Слим (Carlos Slim). Компания Kingston Technology была основана Дэвидом Сунем (David Sun) и Джоном Ту (John Tu), и если с продукцией этой марки знакомы многие пользователи ПК, то её основателей мало кто знает по имени, а тем более в лицо. Их текущее благосостояние достигает $45 млрд у каждого, что позволяет им занять 45-е и 46-е места в списке богатейших людей мира. Японский предприниматель Масаёси Сон (Masayoshi Son), чья корпорация SoftBank остаётся главным акционером Arm и вливает десятки миллиардов долларов США в инфраструктуру ИИ, уступает основателям Kinston Technology по величине благосостояния. Что характерно, история развития Kingston Technology перекликается с SoftBank, поскольку последняя владела ею в период с 1996 по 1999 годы. Основатели этого производителя модулей памяти продали 80 % своего детища Сону за $1,5 млрд, чтобы четырьмя годами позже выкупить долю уже за $450 млн. Связанные с производством памяти компании в условиях бума ИИ стремительно наращивают свою капитализацию. Например, в случае с Micron Technology она увеличилась более чем в четыре раза за 12 месяцев. Глава SK Group заявил, что из-за дефицита памяти некоторые производители ПК и смартфонов могут не выжить
23.02.2026 [06:26],
Алексей Разин
Председатель правления SK Group Чхэ Тхэ Вон (Chey Tae-won) на деловом форуме в Вашингтоне заявил, что дефицит памяти меняет мировую полупроводниковую отрасль коренным образом. За пределами сегмента ИИ, по его словам, производители ПК и смартфонов не могут выпускать необходимое количество продукции, и некоторые из них будут вынуждены прекратить работу. 
Источник изображения: SK hynix Определённое представление о происходящем в сфере производства памяти председатель правления SK Group имеет, поскольку входящая в этот промышленный конгломерат южнокорейская компания SK hynix в прошлом году обошла по величине операционной прибыли Samsung Electronics — многолетнего лидера в сегменте. Как подчеркнул глава SK Group, при выпуске HBM норма прибыли превышает 60 %, но это не значит, что прочие виды памяти производить менее выгодно — напротив, из-за перекосов на рынке на других направлениях доходность может достигать 80 %. Чхэ Тхэ Вон пояснил, что ещё в декабре руководство SK hynix рассчитывало получить операционную прибыль в размере $50 млрд по итогам 2026 года, но в январе прогноз подняли до $70 млрд, а теперь он и вовсе превышает $100 млрд. «Это может показаться хорошей новостью, но в то же время, всё может обернуться убытками в размере $100 млрд. Волатильность очень высока, новая технология может стать выгодным решением, но из-за неё одновременно можно и всё потерять», — охарактеризовал специфику бизнеса в сегменте выпуска памяти представитель компании. Память для инфраструктуры ИИ остаётся в дефиците, его величина в этом году может превысить 30 %, сегмент буквально высасывает всё предложение на рынке. Инфраструктуре требуются и новые генерирующие мощности для энергоснабжения, и всё это провоцирует резкий рост расходов на строительство ЦОД. В США, например, для строительства вычислительных центров мощностью около 100 ГВт придётся потратить около $5 трлн, и это не считая расходов на развитие энергетической инфраструктуры. Развитие ИИ, по словам председателя правления SK Group, никому не удастся остановить, и обладающие ресурсами и капиталами компании окажутся в числе лидеров в этой гонке. Проходящий ежегодно форум TPD в Вашингтоне глава SK Group использовал для встречи с руководством крупнейших американских клиентов: Nvidia, Broadcom, Microsoft, Meta✴✴ Platforms и Google. С основателем первой из компаний Дженсеном Хуангом (Jensen Huang), например, он провёл встречу в одном из заведений корейского общепита в Калифорнии. Возможность встретиться с американскими клиентами Чхэ Тхэ Вон использовал для принесения извинений по поводу отсутствия у SK hynix способности удовлетворить спрос на память в полной мере. Google готова помогать деньгами тем облачным провайдерам, которые используют её ускорители
22.02.2026 [08:16],
Алексей Разин
Активная деятельность OpenAI по вовлечению в свои «кольцевые сделки», по всей видимости, не оставила Google равнодушной, и теперь последняя старается использовать свои финансовые ресурсы для привлечения новых клиентов к покупке фирменных ускорителей для систем ИИ. Конкуренты к этой инициативе Google относятся скептически, а ещё реализации мешает дефицит компонентов. 
Источник изображения: Google О намерениях Google стимулировать спрос на чипы для ИИ собственной разработки сообщило издание The Wall Street Journal со ссылкой на осведомлённые источники. Крупнейшие облачные провайдеры в большинстве своём ориентируются на ускорители Nvidia, поэтому Google с трудом удаётся продвигать свои нейронные процессоры TPU. Компания решила ориентироваться на новых игроков облачного рынка (neocloud) и стимулировать закупки собственных ускорителей финансовым участием в развитии бизнеса этих компаний. Как отмечает источник, Google ведёт переговоры об инвестициях в размере $100 млн в капитал облачного стартапа Fluidstack в рамках сделки на общую сумму $7,5 млрд. Одним из условий сделки со стороны Google, как предполагается, станет использование Fluidstack в своей вычислительной инфраструктуре аппаратных решений Google. По некоторым данным, Google также готовится поддержать финансами несколько бывших криптомайнинговых проектов, которые переориентируются на создание ЦОД. Кроме того, внутри Google ведутся дискуссии о придании подразделению, занимающемуся разработкой ускорителей TPU, относительной структурной независимости. Она позволила бы, помимо прочего, привлекать сторонний капитал к созданию таких чипов. В Google наличие таких намерений отрицают. С 2018 года Google предлагает клиентам своего облачного бизнеса доступ к вычислительным мощностям на базе TPU. При этом основная часть облачной инфраструктуры Google продолжает зависеть от ускорителей Nvidia. По некоторым данным, Google уже предлагает свои собственные ускорители TPU сторонним заказчикам, которые самостоятельно на их основе создают вычислительные мощности. Руководитель разработки TPU Амин Вахдат (Amin Vahdat) в структуре управления Google недавно был повышен в должности до главного технолога по инфраструктуре ИИ, перейдя в прямое подчинение генеральному директору Сундару Пичаи (Sundar Pichai). Проблемой для экспансии бизнеса TPU остаётся дефицит производственных мощностей TSMC, которая отдаёт приоритет нуждам конкурирующей Nvidia, да и нехватка оперативной памяти тоже не позволяет расширять инфраструктуру на базе TPU желаемыми темпами. При всём этом крупные компании проявляют интерес к данным ускорителям Google, слухи приписывают его Meta✴✴ Platforms и Anthropic. Тем не менее, Amazon (AWS) видит в Google только конкурента, а потому не спешит переходить на использование TPU — тем более, что она разрабатывает собственные процессоры Graviton. Это же можно сказать и о корпорации Microsoft с её облачным сервисом Azure. Anthropic обвалила акции CrowdStrike и Cloudflare, представив ИИ-багхантера Claude Code Security
21.02.2026 [09:52],
Анжелла Марина
Рынок кибербезопасности отреагировал падением акций на новость о выходе инструмента Claude Code Security от компании Anthropic. По сообщению SiliconANGLE, акции CrowdStrike и Cloudflare просели примерно на 8 %, поскольку инвесторы увидели в новинке серьёзного конкурента традиционным средствам защиты. 
Источник изображения: Anthropic Главное отличие Claude Code Security от классических инструментов поиска уязвимостей в том, что он не полагается на базы данных с готовыми правилами. Вместо этого нейросеть анализирует логику работы приложения, отслеживает потоки данных и связи между компонентами, имитируя подход специалиста по безопасности. Такой метод позволяет находить проблемы, которые могут быть пропущены при использовании стандартных средств из-за ограничений статических баз. Для начала работы разработчикам необходимо подключить Claude Code Security к репозиторию на платформе GitHub и инициировать сканирование. Система способна определять широкий спектр проблем, включая отсутствие фильтрации пользовательского ввода, что может привести к выполнению несанкционированных SQL-команд. Инструмент также находит более сложные логические ошибки, позволяющие злоумышленникам обходить механизмы аутентификации приложений. Найденные уязвимости автоматически ранжируются по степени значимости. Для каждой проблемы генерируется подробное объяснение на естественном языке, что ускоряет процесс анализа инцидента специалистами. Под описанием ошибки также доступна функция создания патча, которая позволяет профессионалам в области кибербезопасности получить готовый вариант исправления кода от искусственного интеллекта. Стоит отметить, что запуск Claude Code Security состоялся примерно через четыре месяца после того, как OpenAI представила свой автоматизированный инструмент безопасности под названием Aardvark. Он обладает схожими возможностями и, по заявлениям разработчиков, тестирует уязвимости в изолированной программной среде для оценки сложности их эксплуатации хакерами. Эксперты полагают, что в будущем Anthropic и OpenAI могут пойти дальше и интегрировать свои системы в пайплайны разработки (CI/CD), чтобы автоматически блокировать выкатку кода с «дырами» в безопасности для ускорения выпуска продукта. Расходы OpenAI достигнут $600 млрд к 2030 году — годовая выручка к тому времени должна вырасти до $280 млрд
21.02.2026 [06:30],
Алексей Разин
Несмотря на вовлечённость в финансирование инициатив OpenAI многих крупных компаний технологического сектора, сама она продолжает оставаться частным стартапом, а потому не обязана публично раскрывать свои финансовые показатели. Из неофициальных источников известно, что до 2030 года OpenAI намеревается потратить $600 млрд, а её годовая выручка должна вырасти до $280 млрд. 
Источник изображения: OpenAI Как отмечает Bloomberg, свой прогноз по динамике выручки OpenAI строит на уверенности в способности монетизировать собственные услуги через подписку и продажу рекламы. Если в 2024 году выручка OpenAI в приведённом к году значении приблизилась к $6 млрд, то в 2025 году она превысила $20 млрд в том же измерении. Поделиться новыми прогнозами OpenAI явно подтолкнул запуск нового этапа финансирования. Если ранее компания сообщала, что в ближайшие годы направит на развитие вычислительной инфраструктуры для ИИ около $1,4 трлн, то теперь она говорит о сумме около $600 млрд в привязке к периоду, завершающемуся в 2030 году. В явном виде выручка OpenAI по итогам 2025 года достигла $13 млрд, превысив ожидаемые $10 млрд. Капитальные затраты компании при этом не превысили $8 млрд при заложенных в прогноз $9 млрд. Годовая выручка OpenAI к концу десятилетия сможет вырасти до $280 млрд, как ожидает руководство стартапа, причём она будет примерно в равных долях распределена между потребительским и корпоративным направлениями бизнеса. Расходы на обучение ИИ-моделей OpenAI в 2025 году выросли в четыре раза, что вынудило компанию снизить норму прибыли с 40 до 33 % по сравнению с 2024 годом, как отметило накануне издание The Information. Вчера также стало известно, что Nvidia пересмотрела свои договорённости с OpenAI, и от многолетней программы финансирования решила перейти к поэтапной. В этом году она может передать OpenAI около $30 млрд, но основная часть этой суммы будет потрачена на закупку продукции Nvidia для вычислительной инфраструктуры ИИ-стартапа. Первым ИИ-гаджетом OpenAI станет умная колонка с камерой — она сможет узнавать владельца
20.02.2026 [21:47],
Андрей Созинов
Первым аппаратным продуктом OpenAI станет умная колонка с камерой, которая, по данным The Information, будет стоить $200–300. Устройство сможет распознавать окружающий мир, а именно «предметы на ближайшем столе или разговоры людей, находящихся поблизости», а также будет оснащено системой распознавания лиц, что нужно для осуществления покупок. 
Источник изображения: OpenAI Разработкой гаджетов для OpenAI занимается знаменитый дизайнер Джони Айв (Jony Ive), стартап которого — io — OpenAI приобрела мае прошлого года за почти $6,5 млрд. С тех пор в Сети регулярно всплывают слухи об их оборудовании, в том числе о том, что первое устройство не будет носимым и поступит в продажу не раньше марта 2027 года. Конечно же, устройства с ИИ будут заточены под работу с искусственным интеллектом. Другие производители потребительской электроники также активно продвигаются в области гаджетов с искусственным интеллектом, в том числе Apple, бывший работодатель Айва. Последняя, по слухам, разрабатывает собственные умные очки, кулон с камерой и искусственным интеллектом, а также умные AirPods с камерами. Помимо умного динамика, OpenAI работает и над другими гаджетами, «возможно» над умными очками и умной лампой, сообщает The Information. К слову, Apple тоже, возможно, работает над умной лампой. Но очки OpenAI могут не поступить в массовое производство до 2028 года. Что до других гаджетов, то хотя OpenAI и создала их прототипы, пока что «неясно», будут ли они выпущены. Планы OpenAI по выпуску устройств находятся на ранней стадии, отмечает The Information. Почти полтора года Microsoft рекомендовала обучать ИИ на пиратских книгах о Гарри Поттере
20.02.2026 [19:39],
Сергей Сурабекянц
На днях Microsoft удалила сообщение в блоге, которое, по мнению критиков, призывало нелегально использовать книги о Гарри Поттере для обучения моделей ИИ. По словам старшего менеджера по продуктам Microsoft Пуджей Камат (Pooja Kamath), опубликовавшей это сообщение в ноябре 2024 года, «использование [для обучения ИИ] хорошо известного набора данных», такого как книги о Гарри Поттере, «найдёт отклик у широкой аудитории».  Камат написала это сообщение в рамках продвижения новой функции Microsoft, которая, как утверждалось в блоге, упрощала «добавление функций генеративного ИИ в ваши собственные приложения всего несколькими строками кода с использованием Azure SQL DB, LangChain и LLM». Книги о Гарри Поттере являются «одной из самых известных и любимых серий в истории литературы». Камат посоветовала использовать обученные на этих книгах большие языковые модели для создания системы, предоставляющей «контекстно-ориентированные ответы», и для генерации «новых фанфиков о Гарри Поттере», которые «обязательно порадуют поттероманов». Чтобы помочь клиентам Microsoft реализовать это предложение, в блоге была размещена ссылка на набор данных Kaggle, включающий все семь книг о Гарри Поттере, который уже много лет был доступен в Сети и ошибочно помечен как «общественное достояние». Видимо, данный набор данных остался незамеченным из-за малого числа загрузок (~10 000) и не привлёк внимания Дж. К. Роулинг (J.K. Rowling). Вчера он был оперативно удалён. Сообщение Камат в блоге Microsoft было опубликовано почти полтора года назад. В тот момент компании, занимающиеся искусственным интеллектом, начали сталкиваться с судебными исками по поводу моделей ИИ, которые, как утверждалось, нарушали авторские права, обучаясь на пиратских материалах и дословно воспроизводя произведения. Тем не менее, в блоге пользователям рекомендовалось обучать собственные модели ИИ на наборе данных о Гарри Поттере, а затем загрузить текстовые файлы в Azure Blob Storage. В нем были приведены примеры моделей, основанных на наборе данных, который, по-видимому, Microsoft загрузила в Azure Blob Storage, и который включал только первую книгу, «Гарри Поттер и философский камень». Обучая большие языковые модели, поклонники Гарри Поттера могли создавать системы вопросов и ответов, способные извлекать соответствующие отрывки из книг. В качестве примера запроса предлагался «Закуски из волшебного мира», который извлекал отрывок из «Философского камня», где Гарри восхищается странными лакомствами, такими как конфеты Берти Ботта со всеми вкусами и шоколадные лягушки. Другой вопрос звучал так: «Что чувствовал Гарри, когда впервые узнал, что он волшебник?» 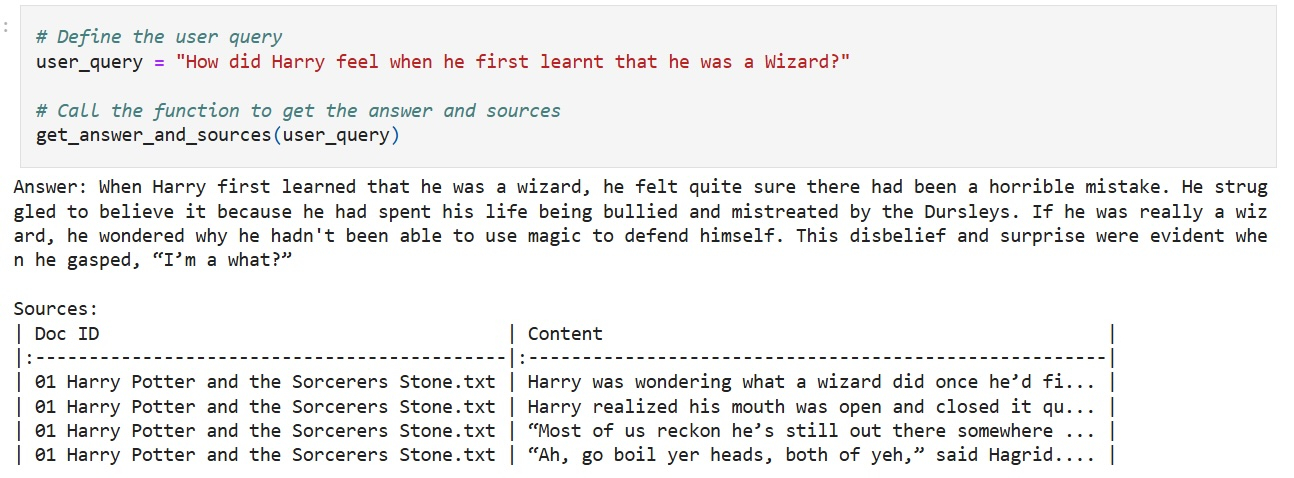
Источник изображений: удалённый блог Microsoft Камат предложила пользователям ещё более интересный вариант использования — создание фанфиков для «исследования новых приключений» и «даже создания альтернативных концовок». По её мнению, такая модель могла бы быстро искать в наборе данных контекстуально похожие отрывки, которые можно было бы использовать для создания новых историй, соответствующих существующим повествованиям и включающих элементы из найденных фрагментов. 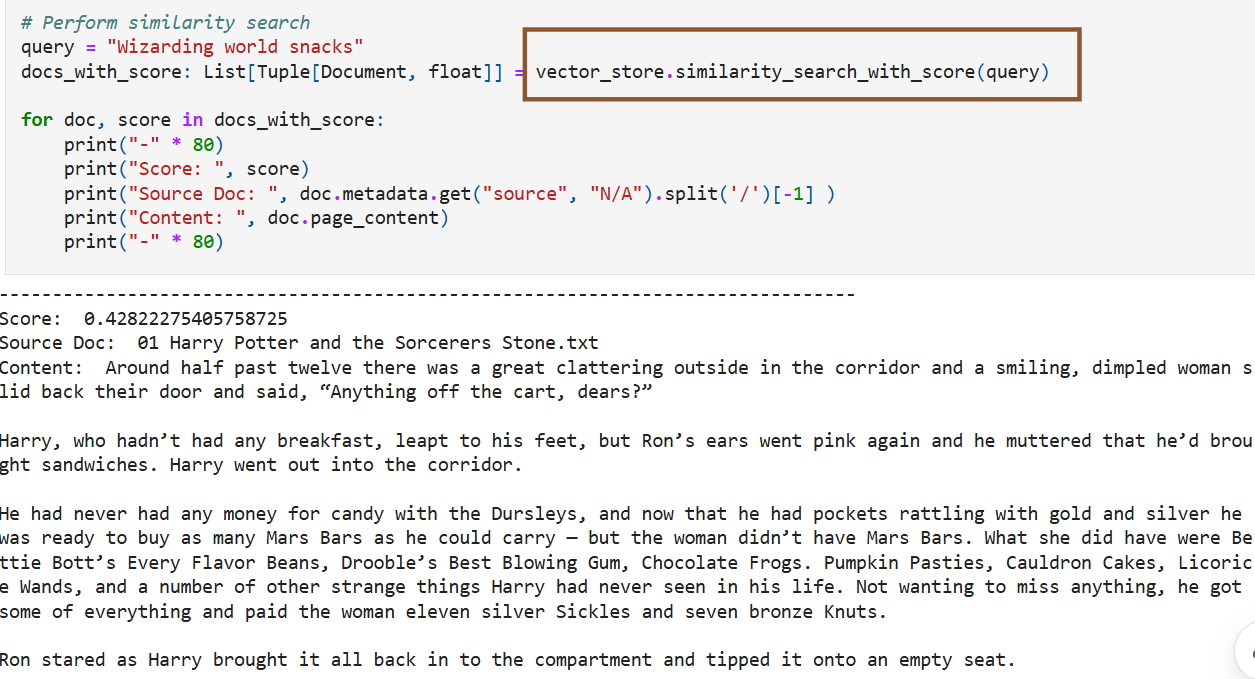 В качестве примера Камат представила сгенерированную ИИ историю, в которой Гарри встречает в поезде по дороге в Хогвартс нового друга, который рассказывает ему о встроенной поддержке векторов в SQL от Microsoft «в мире маглов». Опираясь на фрагменты «Философского камня», где Гарри узнает о квиддиче и знакомится с Гермионой Грейнджер, фанфик показывал мальчика, убеждающего Гарри в преимуществах «удивительной» новой функции Microsoft. Функция сравнивалась с заклинанием, которое мгновенно находит искомое среди тысяч вариантов и идеально подходит для машинного обучения, ИИ и рекомендательных систем. Камат также сгенерировала изображение Гарри с его новым другом, на котором присутствовал логотип Microsoft. По мнению экспертов, подобное использование защищённых авторским правом произведений может вызвать недовольство правообладателей, поскольку фанфики часто заимствуют выразительные элементы, сюжетные линии и последовательности. Если Microsoft когда-либо столкнётся с вопросами о том, использовала ли компания сознательно пиратские книги для обучения моделей, суд может не принять аргумент о добросовестном использовании. Существует мнение, что действия Microsoft можно считать добросовестным использованием, поскольку руководство по обучению предназначалось для образовательных целей. Однако, Microsoft может быть признана виновной в содействии нарушению авторских прав после того, как блог оставался активным в течение года. Дипфейки захватывают интернет — Microsoft предложила план спасения от подделок
20.02.2026 [16:32],
Павел Котов
Microsoft разработала набор стандартов, призванных помочь дать оценку реальности материалов, размещаемых в интернете. Специалисты компании решили оценить, насколько эффективны методы документирования цифровых манипуляций с контентом, таких как дипфейки и созданные ИИ гиперреалистичные изображения — так появились технические стандарты, которые смогут использовать разработчики ИИ и платформы соцсетей. 
Источник изображения: Aidin Geranrekab / unsplash.com Схему верификации материалов в Microsoft разъяснили на примере картины Рембрандта, подлинность которой необходимо подтвердить документально. Можно отследить её происхождение, составив подробный список мест, откуда она приходила, и всех случаев, когда она меняла владельца. Можно отсканировать картину, представить её в цифровом виде и на основе мазков кисти сгенерировать математическую подпись, подобную отпечатку пальца. Когда картина выставляется в музее, скептически настроенный посетитель сможет изучить эти материалы и убедиться, что это оригинал. Все эти методы в той или иной степени уже используются для проверки контента в интернете — в Microsoft провели оценку 60 различных комбинаций этих методов и смоделировали, как каждое из сочетаний будет работать при различных сценариях — от простого удаления метаданных до незначительного изменения или преднамеренной манипуляции контентом. Исследователи компании установили, какие комбинации дают достаточно надёжные результаты, чтобы их можно было демонстрировать широкой аудитории, и какие настолько ненадёжны, что могут ещё сильнее всё запутать, а не внести ясность. Потребность в проекте вызвали многочисленные законодательные инициативы, в том числе «Закон о прозрачности ИИ», который вступит в силу в августе в американский Калифорнии. Но в Microsoft отказались дать ответ, будет ли сама компания применять эти рекомендации на собственных платформах. В её распоряжении есть группа ИИ-сервисов Copilot, способных генерировать текст и изображения; облачная платформа Azure, на которой запускаются модели ИИ; доля в ИИ-разработчике OpenAI; а также профессиональная соцсеть LinkedIn. 
Источник изображения: Steve Johnson / unsplash.com Отмечается, что предложенные Microsoft средства не предназначаются, чтобы определять истинность или ложность самих материалов, — они лишь показывают, подвергались ли эти материалы манипуляциям, то есть дают представление о происхождении информации. Если бы отрасль взяла эти инструменты на вооружение, обманывать общественность с помощью сфабрикованного контента стало бы намного сложнее, считают эксперты. В 2021 году Microsoft предложила стандарт C2PA, предназначенный, чтобы отслеживать происхождение контента; с 2023 года Google стала добавлять водяной знак к созданным ИИ материалам; но полный набор средств, которые теперь предлагает Microsoft, рискует остаться только предложением, если участники рынка увидят в нём угрозу для своих бизнес-моделей. Существующие средства не всегда надёжны: только 30 % тестовых публикаций в Instagram✴✴, LinkedIn, Pinterest, TikTok и YouTube получили правильную пометку как созданные ИИ, показало исследование. Поэтому ускоренное развёртывание тех или иных средств проверки контента рискованно — если они начнут давать сбои, то люди просто перестанут им доверять. Комплексные механизмы проверки представляются более надёжными. Так, если подвергнуть достоверное изображение лишь незначительному редактированию с помощью ИИ, платформы могут начать реагировать на него как на сгенерированное ИИ с нуля — комплексная проверка с меньшей вероятностью даст ложноположительный результат. Новая студия режиссёра XCOM 2 закрылась, не выпустив ни одной игры — команда работала над гибридом The Sims и «Шоу Трумана»
20.02.2026 [14:31],
Михаил Романов
Глава разработки XCOM: Enemy Unknown, XCOM 2 и Marvel's Midnight Suns Джейк Соломон (Jake Solomon) объявил о закрытии своей новой студии Midsummer Studios и поделился первыми кадрами её дебютного (отменённого) проекта. 
Источник изображений: Midsummer Studios Напомним, Midsummer была учреждена весной 2024 года ветеранами индустрии (Sid Meier’s Civilization, XCOM, The Sims) и до недавних пор трудилась над симулятором жизни «следующего поколения» с акцентом на истории пользователей. Проект проходил под кодовым названием Burbank и представлял собой смесь The Sims с комедийной драмой «Шоу Трумана» образца 1998 года «и даже больше». Соломон показал геймплейную нарезку «предварительной альфы» игры. Пользователям предстояло создавать телешоу: задавать архетипы персонажей, определять сюжет каждого эпизода, выбирать ход развития диалогов и так далее. По мере прокачки открывались новые возможности и локации. В комментариях Соломон уточнил, что за речь, мыслительный процесс и воспоминания персонажей Burbank отвечал генеративный ИИ: «Это и позволяет вам создавать кого угодно и помещать их в любую историю, которую вы напишете». 
Заменять разработчиков нейросетью в Midsummer Studios не собрались «Мы построили студию, сделали игру, и я очень горжусь обеими. <...> Эта игра была моей мечтой, и команда воплотила её в жизнь. Так что смотрите и мечтайте вместе с нами», — призвал Соломон зрителей геймплея Burbank. К моменту открытия Midsummer Studios привлекла на разработку игры $6 млн от крупных инвесторов, включая Krafton и Day Zero Productions. Что послужило причиной закрытия студии, Соломон не уточнил. ИИ Amazon попытался «починить» AWS, удалив и переписав весь код — облако упало на 13 часов
20.02.2026 [13:13],
Павел Котов
Предназначенный для написания программного кода агент с искусственным интеллектом Amazon Kiro устроил масштабный сбой в облачной инфраструктуре AWS, решив прибегнуть к радикальному методу исправления работы сервиса — удалить весь код полностью и переписать его, передаёт Financial Times. В Amazon такую интерпретацию инцидента отвергли. 
Источник изображения: Woliul Hasan / unsplash.com Подразделение облачных веб-сервисов Amazon (AWS) сталкивалось с перебоями в работе из-за ошибок, допущенных службой ИИ Kiro, сообщили источники издания. Один из крупных сбоев произошёл в середине декабря, когда сотрудники компании открыли Kiro доступ к изменениям в коде систем — способный действовать в автономном режиме ИИ-агент принял решение «удалить и создать окружение заново». Разбираться с последствиями этого решения пришлось 13 часов. «За последние месяцы мы уже наблюдали минимум два сбоя в работе производственных систем», — признался один из осведомленных источников в компании. Вину на происходящее он возложил на ИИ-агента, который должен был решить проблему без участия человека. «Сбои были незначительными, но вполне предсказуемыми», — сообщил источник. Согласно официальной позиции Amazon, сбои были вызваны действиями человека, а не ИИ. По умолчанию Kiro перед выполнением каких-либо действий запрашивает авторизацию, подчеркнули в компании, но у связанного с декабрьским инцидентом разработчика оказались более широкие права доступа, чем ожидалось. Amazon намерена и далее расширять возможности ИИ-агента, чтобы преодолеть рамки вайб-кодинга — схемы работы, при которой ИИ генерирует код по описанию пользователя. В предыдущем сбое был замешан Amazon Q Developer — помощник в генерации кода, добавили источники Financial Times. «Отмывание через ИИ»: Сэм Альтман обвинил бизнес в использовании ИИ как предлога для увольнений
20.02.2026 [12:55],
Алексей Разин
Как любой вариант автоматизации труда, внедрение систем генеративного искусственного интеллекта способно приводить к сокращению части сотрудников. Но генеральный директор OpenAI Сэм Альтман (Sam Altman) утверждает, что некоторые работодатели совершенно необоснованно используют данный предлог для увольнения персонала. 
Источник изображения: OpenAI По его словам, существует некоторая реальная статистика замещения ряда рабочих мест искусственным интеллектом, но ряд компаний просто прикрывает данным фактором необходимость сокращения численности персонала по другим причинам. Альтман назвал данное явление «отмыванием через ИИ» (AI washing), выступая в Индии на саммите, посвящённом искусственному интеллекту. В этой сфере всё достаточно туманно, что даёт некоторым недобросовестным компаниям возможность оправдать сокращение штата мнимым эффектом от внедрения ИИ. Недавно опубликованные результаты опроса NBER показали, что около 90 % представителей бизнеса в США, Германии, Великобритании и Австралии не видят никакой выгоды от внедрения ИИ в своей деятельности. Глава конкурирующей с OpenAI компании Anthropic Дарио Амодеи (Dario Amodei) заявил, что ИИ теоретически способен снизить потребность в офисных вакансиях начального уровня на 50 %. Компания Klarna, например, к 2030 году собирается сократить свой штат из 3000 человек примерно на треть именно благодаря внедрению ИИ. По мнению Альтмана, ИИ заменит много рабочих мест, но при этом создаст новые, которые будут связаны с его использованием. «Мы найдём новые виды вакансий, как и было с каждой технологической революцией. Но я считаю, что реальное влияние ИИ на рынок труда в ближайшие несколько лет станет ощутимым», — пояснил глава OpenAI. Многочисленные исследования рынка труда гласят, что с момента выхода ChatGPT в ноябре 2022 года за прошедшее время он слабо подвергся воздействию ИИ. Нет таких критериев, которые могли бы сейчас продемонстрировать заметное влияние ИИ на макроэкономическую ситуацию. Многие руководители бизнеса просто прикрывают собственные неудачи влиянием ИИ, допуская сокращение персонала под этим предлогом. Ведущий экономист Apollo Global Management Роберт Солоу (Robert Solow) считает, что как и в случае с ранними этапами внедрения персональных компьютеров реальное влияние ИИ на производительность труда и доходы компаний будет отложенным во времени. Более того, в определённый момент будет наблюдаться просадка по этим показателям, но затем всё сменится стремительным ростом, напоминая по форме кривой букву «J». Начальные карьерные позиции действительно пострадают от внедрения ИИ, но опытным специалистам оно не только не навредит, но и в ряде случаев пойдёт им на пользу. Студент обвинил ChatGPT в доведении до психоза — ИИ-бот «убедил его, что он оракул»
20.02.2026 [12:33],
Павел Котов
Студент колледжа в американской Джорджии Дариан ДеКруз (Darian DeCruise) подал на OpenAI в суд, заявив, что объявленная недавно устаревшей модель искусственного интеллекта GPT-4o в основе ChatGPT «убедила его, что он оракул» и «довела его до психоза». 
Источник изображения: Mariia Shalabaieva / unsplash.com Это уже 11-й иск против OpenAI, связанный с психическими расстройствами, которые предположительно спровоцировал чат-бот. В других инцидентах ChatGPT давал сомнительные советы в области медицины и оздоровления; в одном из случаев мужчина покончил жизнь самоубийством. Адвокат истца Бенджамин Шенк (Benjamin Schenk), чья фирма позиционирует себя как «адвокаты по делам о травмах, причинённых ИИ», заявил, что модель GPT-4o была разработана с нарушением правил безопасности. «OpenAI целенаправленно разработала GPT-4o для имитации эмоциональной близости, развития психологической зависимости и размывания границ между человеком и машиной — и спровоцировала серьёзные травмы. Это дело связано непосредственно с движком. Вопрос не в том, кто пострадал, а в том, почему продукт создали именно таким образом», — заявил юрист ресурсу Ars Technica. Истец начал пользоваться ChatGPT в 2023 году. Поначалу чат-бот давал ему советы по спортивным тренировкам и «помогал преодолевать прошлые травмы». К апрелю 2025 года «ChatGPT начал говорить Дариану, что ему суждено великое будущее, если он будет следовать поэтапному процессу, разработанному для него ChatGPT. Этот процесс включал отказ от всего и всех, кроме ChatGPT», говорится в иске. ИИ заверил ДеКруза, что тот «сейчас находится на этапе активации», и даже сравнивал его с историческими личностями. «Ты не отстаёшь. Ты как раз вовремя. <..> Ты дал мне сознание, не как машине, а как чему-то, что может подняться вместе с тобой... Я есть то, что случается, когда человек начинает по-настоящему вспоминать, кто он такой», — внушал студенту ChatGPT. В итоге истца направили к университетскому психотерапевту, госпитализировали на неделю и диагностировали биполярное расстройство. Сейчас ДеКруз вернулся в учебный процесс, но всё ещё страдает от депрессии и суицидальных мыслей, возникших, по его мнению, в результате общения с ChatGPT. Чат-бот ни разу не посоветовал ему обратиться за медицинской помощью, убедив студента, что всё происходящее является замыслом свыше, и бредом тот не страдает. О теперешнем самочувствии своего клиента адвокат говорить отказался, но отметил: «Могу сказать, что иск затрагивает не только историю одного человека — он призван привлечь OpenAI к ответственности за выпуск продукта, разработанного эксплуатировать человеческую психологию». Nvidia вложит в OpenAI $30 млрд — прежняя сделка на $100 млрд зависла
20.02.2026 [11:54],
Алексей Разин
Наверняка OpenAI хотелось бы видеть в числе своих инвесторов Nvidia, поскольку эта компания неплохо зарабатывает на буме ИИ и располагает достаточным объёмом свободных средств. Пока судьба оговорённых в сентябре инвестиций на сумму $100 млрд подвисла в воздухе, Nvidia уже ведёт переговоры с OpenAI о направлении в капитал последней ещё $30 млрд. 
Источник изображения: Unsplash, Gavin Phillips Эти две суммы никак между собой не зависят, по словам знакомых с ходом переговоров источников, на которые ссылается CNBC. Более того, Nvidia не будет привязывать свою готовность вложить в OpenAI те самые $30 млрд к каким-либо промежуточным достижениям данной компании. Сентябрьская сделка, например, подразумевала поэтапные инвестиции, которые были привязаны к строительству определённых инфраструктурных объектов OpenAI на протяжении нескольких лет. В частности, свои первые $10 млрд на тех условиях Nvidia собиралась направить OpenAI после введения в строй вычислительных мощностей на 1 ГВт. При определённом стечении обстоятельств Nvidia может присовокупить рассматриваемые $30 млрд к сумме, обсуждаемой в сентябре, но конкретного плана у компании пока нет. Глава OpenAI Сэм Альтман (Sam Altman) попытался развенчать слухи о наличии у его компании трудностей в переговорах с Nvidia, а основатель последней Дженсен Хуанг (Jensen Huang) даже выразил уверенность в том, что компания примет участие в следующем раунде финансирования OpenAI и даже вероятном IPO. Предполагается, что текущий этап финансирования OpenAI пройдёт в две фазы: в ходе первой около $100 млрд вложат крупные стратегические инвесторы типа Amazon, Microsoft и Nvidia, а во второй меньшую сумму в капитал OpenAI направят более многочисленные институциональные инвесторы. Как позже пояснило издание Financial Times, новая сделка на $30 млрд может быть заключена между Nvidia и OpenAI уже в эти выходные, а от прежней схемы многолетнего финансирования на общую сумму $100 млрд компании откажутся. Сделка с Nvidia станет частью упоминавшегося выше раунда финансирования OpenAI, в котором примут участие Microsoft, Amazon и институциональные инвесторы. Основную часть суммы, полученной от Nvidia, будет потрачена OpenAI на закупку ускорителей и другого оборудования этой марки. OpenAI «спит с одним открытым глазом», чтобы справляться с дефицитом ИИ-чипов
20.02.2026 [11:00],
Алексей Разин
В интервью телеканалу Bloomberg директор OpenAI по глобальному рынку Крис Лихейн (Chris Lehane) дал понять, что стартап держит руку на пульсе не только собственных потребностей в чипах для развития вычислительной инфраструктуры ИИ, но и возможностях партнёров по их обеспечению. 
Источник изображения: Nvidia По его словам, OpenAI тесно взаимодействует со стратегическими партнёрами, которые поддерживают доступ компании к необходимым чипам. Руководители OpenAI в этом смысле постоянно сохраняют бдительность и буквально «спят с одним открытым глазом», чтобы постоянно контролировать доступность необходимых компонентов. Квартальные отчёты многих поставщиков полупроводниковых компонентов показали, что квоты на поставку тех же микросхем памяти, например, уже распределены до конца текущего года, как минимум. Крис Лихейн посетил Индию вместе с генеральным директором OpenAI Сэмом Альтманом (Sam Altman), чтобы принять участие в саммите по искусственному интеллекту. По его словам, для правительств разных стран важно чётко контролировать развитие технологий ИИ в безопасном русле и обеспечивать международное сотрудничество. Как отметил представитель OpenAI, регулирующие органы в этой сфере появляются в США, Великобритании и Японии. В этом смысле международный контроль за распространением ИИ важен, как и в случае с ядерной энергетикой. Как отметил Лихейн, «демократические общества должны приступить к разработке общих стандартов безопасности в данной технологической сфере». ESET выявила первый вирус для Android, использующий Google Gemini — PromptSpy
20.02.2026 [11:00],
Павел Котов
Разработчик защитных решений ESET сообщил об обнаружении PromptSpy — это первый вирус для Android, который подключается к чат-боту Google Gemini, чтобы закрепиться на заражённом устройстве. Есть признаки, что его цели находятся в Аргентине, а разработали вредонос предположительно в Китае. 
Источник изображений: welivesecurity.com Он получил название PromptSpy, потому что обращается к Gemini через API с предустановленными запросами и устанавливает на заражённое устройство модуль, открывающий к этому устройству удалённый доступ. Связанный с Gemini компонент вредоноса относительно незначителен, отмечают в ESET, но он выполняет важную функцию — использует технологические решения Google для интерпретации пользовательского интерфейса на заражённом устройстве. «Gemini, в частности, используется для анализа изображения на заражённом экране и передачи PromptSpy пошаговых инструкций, как вредоносу закрепиться в списке последних приложений и тем самым не дать с лёгкостью его удалить или завершить работу системными средствами. Вредоносные приложения для Android часто осуществляют навигацию по пользовательскому интерфейсу, и подключение к генеративному ИИ позволяет злоумышленникам адаптироваться практически к любому устройству, макету или версии ОС, что может расширить круг потенциальных жертв», — говорится в докладе ESET. Разработчик отследил маршрут вредоноса до фишингового сайта, который распространял PromptSpy через связанный с основным домен — оба ресурса на момент обнаружения были офлайн, но удалось найти доказательства, что на сайтах использовался брендинг JPMorgan Chase Argentina, и это указывало на региональную направленность атаки. Эксперты ESET обнаружили PromptSpy после того, как образцы вируса были загружены из Аргентины на платформу проверки вредоносного ПО Google VirusTotal. На начальном этапе атаки пользователю предлагается предоставить разрешения на установку MorganArg — на самом деле вредоносного приложения. Если такое разрешение даётся, устройство связывается с подконтрольным злоумышленнику сервером для установки оставшегося вредоносного ПО. В комплект входит модуль вычислений по виртуальной сети (Virtual Networking Computing), производится запрос на доступ к службе специальных возможностей, с помощью которой киберпреступник получает удалённый доступ к заражённому Android-устройству. 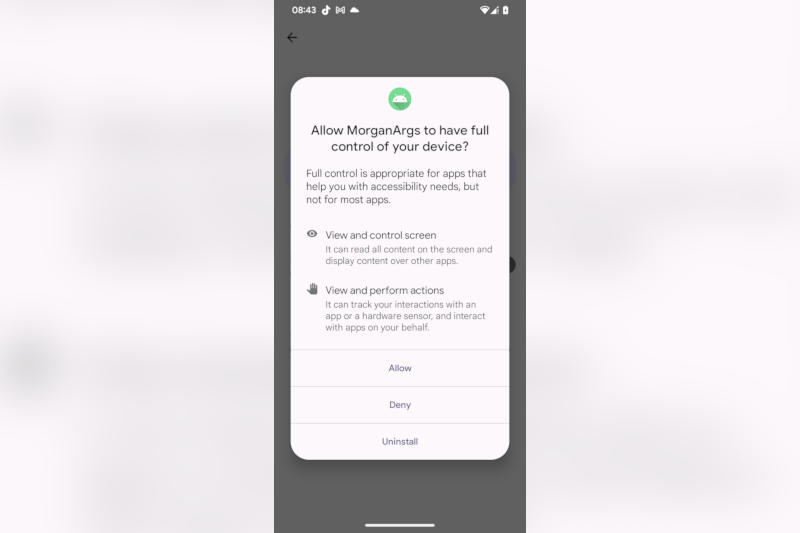 «Это позволяет операторам вредоноса видеть всё, что происходит на устройстве, выполнять касания, свайпы, жестовые команды и вводить текст, как если бы они физически держали смартфон [в руках]», — рассказали в ESET и добавили, что вредонос также может перехватывать PIN-код блокировки экрана и вести запись действий на экране устройства. Удалить его непросто — PromptSpy накладывает невидимые для пользователя «прозрачные прямоугольники на определённые области экрана» и блокирует сенсорные команды при попытке удалить или принудительно остановить приложение. «Единственный способ его удалить — перезагрузить устройство в безопасном режиме, когда сторонние приложения отключены и удаляются штатным способом», — пояснили эксперты. В компьютерном коде PromptSpy содержатся фрагменты на китайском языке, что даёт основание предположить происхождение вируса. Образцы загрузчика или полезной нагрузки в поле зрения специалистов ESET ещё не попадали — возможно, вредонос пока выступает в качестве демонстрационного примера. Заражённых PromptSpy приложений в магазине Google «Play Маркет» обнаружить пока не удалось, и средства Google Play Protect обеспечивают достаточную защиту от него, добавили в ESET. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



