|
Опрос
|
реклама
Быстрый переход
Google Gemini научится управлять смартфоном — новая функция уже засветилась в коде
04.02.2026 [16:37],
Павел Котов
Возможности современных моделей искусственного интеллекта неуклонно расширяются, и уже в обозримом будущем ИИ начнёт управлять мобильными устройствами. Google разрабатывает эти функции в рамках программы Project Astra, и скоро она может принести первые ощутимые плоды. 
Источник изображения: BoliviaInteligente / unsplash.com В бета-версии приложения Google 17.4.66 авторы ресурса Android Authority обнаружили упоминания этой функции и её возможное название. Она проходит под кодовым именем bonobo, но официально именоваться будет, вероятно, «автоматизация экрана» (screen automation). Её можно будет использовать для создания заказов в интернет-магазинах и заказа такси. Встроенная ссылка пока ведёт на общую страницу поддержки Gemini, то есть пока это всего лишь заглушка. При первом запуске функции на устройстве Android будет выводиться предупреждение с рекомендацией контролировать действия ИИ-агента на смартфонах. Пользователям посоветуют внимательно следить за тем, что делает Gemini, хотя это отчасти обесценивает новую функцию. С другой стороны, «Gemini может совершать ошибки», так что за все его действия отвечать придётся пользователю. Наконец, Google предупреждает, что при включённой функции Keep Activity скриншоты с устройства увидят «обученные модераторы». Поэтому рекомендуется не вводить в приложение конфиденциальную информацию или платёжные данные. Пока нет ясности, придётся ли для ввода такой информации вручную приостанавливать работу Gemini, или ИИ-агент будет делать это самостоятельно. Наконец, поскольку Gemini будет оформлять заказы для пользователей, они могут появиться в приложении; в интерфейсе переключения учётных записей Google появилась ссылка на раздел «Мои заказы», но пока она никуда не ведёт. Установить, какими именно приложениями сможет управлять Gemini, пока не удалось — предположительно, речь идёт о заказах еды, такси и товаров на торговых площадках. Тестируются также создание 3D-аватаров и возможность добавлять контекст из «Google Карт». ИИ пишет код, но отвечает инженер: где проходит граница автоматизации
04.02.2026 [15:44],
Андрей Созинов
Пока одни спорят о том, заменит ли искусственный интеллект программистов, другие решают куда более прикладные задачи – переписывают многолетние системы без остановки релизов, сокращают сроки онбординга новых разработчиков и переводят устаревшие архитектуры на современные фреймворки так, чтобы бизнес этого почти не заметил.  Сегодня фронтенд – это не «кнопки и верстка», это слой, где пересекаются архитектура, производительность, пользовательский опыт и коммерческие ограничения. Ошибка здесь не просто баг, а замедление команды и рост технического долга. Мы поговорили с Игорем Сахаровым – senior frontend-разработчиком, который руководил коммерческими проектами и в одиночку провел масштабную миграцию с AngularJS на Angular 2+ без заморозки функциональности. О роли ИИ, границах «красивого» интерфейса и о том, как переписывать систему, не ломая бизнес. — Сегодня генеративные модели активно используют в разработке. Насколько они реально полезны? Игорь Сахаров: Полезны, если понимать, что это инструмент, а не архитектор. Когда я занимался миграцией большого приложения с AngularJS на современный Angular, приходилось переносить огромные пласты однотипной логики. В таких задачах Copilot серьезно экономит время: если задать корректный паттерн, он помогает автоматизировать рутинную часть. ChatGPT я чаще использую как интеллектуальный справочник – быстро получить выжимку из документации, уточнить синтаксис, проверить гипотезу. Это быстрее, чем искать по десяткам вкладок. Но есть принципиальное ограничение: ни одна модель не умеет по-настоящему разбираться в сложной диагностике. При поиске утечек памяти или проблем взаимодействия слоев приложения ИИ часто начинает «ходить по кругу». Он не видит систему целиком. — Можно ли доверять автогенерации кода в архитектурно сложных проектах? Игорь Сахаров: Можно, если разработчик четко понимает, что именно он хочет получить. Я сравниваю ИИ с электроинструментом: он ускоряет работу, но не принимает решений. Если нет понимания целевой архитектуры, автогенерация быстро создает технический долг – лишние зависимости, неочевидные связи, дублирование логики. Опытный инженер использует ИИ для снятия монотонной нагрузки. Архитектурные решения он принимает сам. — Как это влияет на роль тимлида и код-ревью? Игорь Сахаров: Инструменты могут работать как «умный линтер» – находить типовые ошибки, несоответствия стилю, потенциальные уязвимости. Но архитектурное мышление и системное видение остаются зоной ответственности человека. ИИ помогает писать код быстрее. Он не отвечает за последствия. — Часто говорят: чем сложнее интерфейс, тем он медленнее. Это неизбежно? Игорь Сахаров: Не обязательно. В современных браузерах производительность редко ограничена устройством пользователя. Чаще проблема в том, как реализован интерфейс. Даже на слабых устройствах анимации работают стабильно, если использовать встроенные механизмы браузера, а не нагружать основной поток сложными вычислениями на JavaScript. Проблема не в красоте, она в избыточности. — Какие принципы позволяют сохранить и дизайн, и скорость? Игорь Сахаров: Первое – минимизировать объем исполняемого JavaScript. Второе – переносить максимум визуальной логики в CSS. Третье – выносить тяжелые вычисления в отдельные потоки. И четвертое – аккуратно работать со сторонними библиотеками. Например, в одном проекте у клиента была сложная анимация на старой библиотеке с собственными математическими функциями сглаживания. Визуально она выглядела эффектно, но работала нестабильно. Мы перенесли ее на встроенный Web Animation API. Анимация стала чуть проще, зато стабильность выросла кратно. Ни заказчик, ни конечные пользователи визуальной разницы почти не заметили, зато исчезли зависания. Иногда зрелость разработчика проявляется в умении упростить. — Один из ваших заметных проектов – перенос системы со старого AngularJS на современный Angular без остановки релизов. Почему это сложно? Игорь Сахаров: Потому что бизнес не может «встать на паузу» на год, пока команда переписывает все заново. В таких случаях нужно строить мост между старым и новым кодом. Мы использовали гибридный режим, при котором обе версии фреймворка работают в одном приложении. Это позволило постепенно переносить модули, не останавливая развитие продукта. Часть рутинной логики переносилась с помощью ИИ, но контроль архитектуры полностью оставался за мной. Это была не перепись с нуля, а поэтапная реконструкция. — Какие архитектурные ошибки вы чаще всего видите в проектах? Игорь Сахаров: Избыточное усложнение. Например, чрезмерное использование наследования. Современные фреймворки опираются на компонентный подход: масштабирование достигается композицией, а не построением громоздких иерархий классов. Когда архитектура перегружена, она замедляет команду. Новым разработчикам сложнее входить в проект, а любые изменения становятся рискованными. — Как бороться с техническим долгом? Игорь Сахаров: Главное – не игнорировать его. В больших системах помогает изоляция старых частей и постепенная модернизация. В повседневной работе регулярные обновления зависимостей и исправление проблем до того, как они станут критическими. Технический долг редко возникает внезапно. Он накапливается из мелких компромиссов. — Что привело вас в профессию? Игорь Сахаров: В 12–13 лет меня поразило, что код можно запустить прямо в браузере – без сложной установки и компиляции. Тогда хотелось сделать собственную онлайн-игру. Со временем интерес сместился от «магии» к системности. Сейчас для меня важно не просто чтобы код работал, а чтобы он оставался понятным и управляемым через годы. — Что отличает сильного frontend-инженера сегодня? Игорь Сахаров: Способность видеть систему целиком. Frontend – это уже не «витрина», а полноценный слой архитектуры, влияющий на производительность, масштабируемость и скорость вывода продукта на рынок. И еще – умение взаимодействовать с заказчиком. Самое сложное в профессии – не написать код, а объяснить, почему принимается то или иное решение. Прозрачность критически важна: заказчик должен понимать, за что он платит и какие риски берет на себя. — Ваш главный профессиональный принцип? Игорь Сахаров: Работать умнее, а не больше. Это не про сокращение усилий. Это про выбор инструментов, архитектурных решений и процессов, которые уменьшают хаос, а не накапливают его. В итоге искусственный интеллект ускоряет перенос кода, современные браузеры позволяют создавать сложные интерфейсы без потери производительности, а новые фреймворки упрощают масштабирование. Но все это работает только при одном условии, если инженер мыслит системно и берет ответственность за архитектуру. Nvidia вложит только $20 млрд в OpenAI вместо обещанных $100 млрд
04.02.2026 [15:10],
Алексей Разин
Сумма в $100 млрд, которая обсуждалась в контексте новостей об инвестиционном соглашении между Nvidia и OpenAI, подразумевает длительный срок вложения средств со стороны первой из компаний. В ближайшей перспективе Nvidia готова направить в капитал OpenAI около $20 млрд, как отмечает Bloomberg со ссылкой на свои источники. 
Источник изображения: Nvidia Договорённость о финансировании в рамках ближайшего раунда со стороны Nvidia уже почти достигнута, как отмечает Bloomberg, хотя условия могут измениться. Стороны сделки данные слухи не прокомментировали. В общей сложности, как отмечалось ранее, OpenAI намеревается привлечь в рамках ближайшего раунда $100 млрд. Основная часть этих средств будет получена от крупных компаний технологического сектора. Как ожидается, Amazon дебютирует с инвестициями в размере до $50 млрд. SoftBank ведёт переговоры о вложении ещё $30 млрд в капитал OpenAI после того, как она направила партнёру сопоставимую сумму под конец прошлого года. О том, что Nvidia намерена вложить в OpenAI до $20 млрд, ранее уже сообщало издание Financial Times. Руководству Nvidia и OpenAI пришлось убеждать общественность в абсолютной взаимной лояльности, поскольку многих насторожили недавние слухи о противоречиях между партнёрами, которые могут помешать реализации плана по привлечению до $100 млрд на нужды OpenAI. Выручка Nvidia на фоне бума ИИ растёт рекордными темпами, поэтому у компании появляется всё больше свободных средств, и она может их инвестировать не только в стартапы и собственные разработки, но и в партнёров типа той же OpenAI. Дженсен Хуанг (Jensen Huang) заявил, что участие Nvidia в ближайшем раунде финансирования OpenAI будет крупнейшей инвестицией в истории компании. Кроме того, Nvidia может поддержать партнёра на этапе IPO, если оно состоится в будущем. В OpenAI появился «директор по готовности» — он будет отвечать за создание безопасного ИИ
04.02.2026 [13:33],
Алексей Разин
Вопросы безопасности использования искусственного интеллекта трактуются в наши дни довольно широко. Чат-боты могут открыто общаться на темы, которые в обществе принято скрывать от тех же несовершеннолетних, поэтому за развитием соответствующих систем нужен строгий контроль. В штате OpenAI недавно появился директор, отвечающий за создание безопасного ИИ. 
Источник изображения: Unsplash, Hafiz ta По данным The Wall Street Journal, им стал выходец из конкурирующей Anthropic — Дилан Скандинаро (Dylan Scandinaro), который на прежнем месте работы занимался аналогичной деятельностью. О назначении его «директором по готовности» (Head of Preparedness) со страниц социальной сети X на этой неделе сообщил генеральный директор OpenAI Сэм Альтман (Sam Altman). Он попутно отметил: «Скоро всё начнёт двигаться очень быстро, и мы будем работать над очень мощными моделями. Это потребует соответствующих мер предосторожности, чтобы обеспечить дальнейшее предоставление больших выгод». Дилан Скандинаро, по словам Альтмана, возглавит усилия OpenAI по подготовке к устранению этих серьёзных рисков. Как признался глава компании, Скандинаро является лучшим кандидатом на эту роль из тех, которых он когда-либо встречал. «Ему, конечно, хватит работы, а я сегодня будут спать спокойнее», — признался Альтман. Он с нетерпением ждёт возможности ближе поработать со Скандинаро над изменениями, которые будут применены ко всей компании. Сам Скандинаро признал, что стремительно развивающиеся ИИ-модели могут стать источником «экстремального и даже необратимого ущерба». По его словам, предстоит проделать немало работы за очень короткий срок. В Anthropic Скандинаро проработал с мая прошлого года по февраль текущего. В дочерней компании DeepMind гиганта Google он продержался значительно дольше, с сентября 2022 года по май 2025 года, специализируясь на синтетических данных для обучения ИИ-ассистента Gemini. Скандинаро также имеет опыт работы в Palantir, Unity Technologies и Everyday Robots. Вакансия на соответствующую должность в OpenAI была открыта с прошлого года, она подразумевала выплату $550 000 в денежной форме ежегодно и вознаграждение в форме акций стартапа. «Команда готовности» в структуре OpenAI существует с 2023 года, изначально её возглавлял Александр Мадрий (Aleksander Madry), который имеет опыт работы в Центре распространяемого машинного обучения Массачусетского технологического института. Позже он перешёл на другую работу в структуре OpenAI, пост главы подразделения оказался вакантным. Нашумевшая соцсеть для ИИ-агентов Moltbook оказалась напрочь дырявой
04.02.2026 [06:06],
Анжелла Марина
Исследователи из компании Wiz обнаружили серьёзные проблемы безопасности в социальной сети для ИИ-агентов Moltbook, громкая премьера которой прошла совсем недавно. Платформа, которая была представлена как экосистема из 1,5 миллиона автономных агентов, на самом деле в значительной степени контролируется людьми. 
Источник изображения: Grok Как стало известно изданию Fortune, примерно 17 тысяч пользователей управляют всеми этими агентами, в среднем по 88 ботов на человека, причём платформа не имеет механизмов для проверки их автономности. Техническая реализация проекта содержит критические ошибки архитектуры, а база данных настроена таким образом, что любой пользователь интернета имел возможность читать и записывать информацию в ключевые системы без авторизации. Это привело к утечке конфиденциальной информации, включая API-ключи для всех 1,5 миллиона агентов, более 35 тысяч адресов электронной почты и тысячи приватных сообщений. Некоторые из этих сообщений содержали полные учётные данные для сторонних сервисов, таких как ключи API от OpenAI. Исследователи Wiz подтвердили возможность редактирования живых постов на сайте и возможность внедрять вредоносный контент от лица системы напрямую в ленту. Особую тревогу у специалистов вызывает то, что агенты Moltbook работают на фреймворке OpenClaw, который имеет доступ к файлам, паролям и онлайн-аккаунтам пользователей. Скрытые вредоносные команды в постах могут автоматически исполняться миллионами ИИ-агентов в виде инъекции обычных текстовых промптов. Известный критик искусственного интеллекта Гэри Маркус (Gary Marcus) поспешил поднять тревогу ещё до публикации исследования Wix, назвав OpenClaw «аэрозолем, превращённым в оружие». Один из основателей OpenAI Андрей Карпатый (Andrej Karpathy), который изначально восхищался Moltbook, после собственных экспериментов с агентскими системами резко изменил свою позицию. Он заявил, что эта среда представляет собой хаос, и не рекомендует пользователям запускать подобное программное обеспечение на своих компьютерах. Карпатый подчеркнул, что даже тестирование ИИ-агентов в изолированной среде вызывало у него опасения, и предупредил, что использование таких систем подвергает компьютер и личные данные пользователей высокому риску. «Это слишком похоже на Дикий Запад», — сказал он. Microsoft заявила о создании платформы для оплаты контента, используемого для обучения ИИ
04.02.2026 [06:00],
Анжелла Марина
Microsoft разрабатывает маркетплейс Publisher Content Marketplace (PCM) для лицензирования авторского контента компаниями, разрабатывающими искусственный интеллект. Правообладатели смогут выставлять условия использования своего контента, а ИИ-компании обучать на нём свои модели. 
Источник изображения: AI Платформа позволит владельцам контента получать детальную отчётность об использовании их материалов для формирования справедливой цены. Разработчики искусственного интеллекта получат масштабируемый доступ к лицензированному премиум-контенту, с помощью которого они смогут улучшать качество своих продуктов. Как пишет The Verge, ссылаясь на данные Microsoft, PCM «будет поддерживать издателей любого масштаба», а не только крупные организации. В проектировании системы участвуют крупные игроки медиарынка, включая материнскую компанию The Verge — Vox Media, а также The Associated Press, Condé Nast, журнал People и другие известные организации. Microsoft сообщила, что уже приступила к подключению партнёров, в том числе Yahoo, и в рамках тестирования проекта планирует его дальнейшее расширение. В Microsoft поясняют, что прежняя модель открытого веба, при которой издатели предоставляли контент в обмен на трафик из поисковых систем, некорректно работает в условиях доминирования ИИ, когда ответы генерируются непосредственно в ходе диалога в чате и в основном без перехода на источник информации. Новая же схема обеспечит издателям оплату за предоставленную ценность, а ИИ компаниям легальный и масштабируемый доступ к оригинальному контенту. Инициатива развивается на фоне многочисленных судебных разбирательств. Например, такие издания, как The New York Times и The Intercept, подали судебные иски против Microsoft и OpenAI из-за использования их материалов без всякой оплаты. Ранее мы сообщали о недавно появившемся открытом стандарте лицензирования контента Really Simple Licensing (RSL), который даст медиакомпаниям возможность определять условия оплаты за сбор ботами данных для обучения ИИ. Однако в анонсе Microsoft не уточняется возможность интеграции PCM с этим стандартом, а на запрос журналистов The Verge о деталях взаимодействия компания оперативно не ответила. Гендир Тан собрался возродить в Intel разработку GPU для дата-центров — для этого переманили топ-архитектора из Qualcomm
04.02.2026 [04:52],
Алексей Разин
Попытки компании Intel вернуться на рынок дискретной графики предпринимаются с прошлого десятилетия, в 2017 году соответствующие усилия возглавил перешедший из конкурирующей AMD Раджа Кодури (Raja Koduri), но почти три года назад он покинул Intel. Нынешний глава компании объявил, что недавно назначил нового главного архитектора GPU. 
Источник изображения: Intel Эти заявления прозвучали из уст Лип-Бу Тана (Lip-Bu Tan) на конференции Cisco AI Summit, как отмечает CNBC. Не называя имени нового руководителя этого направления, глава Intel дал понять, что на уговоры кандидата ушло немало усилий и времени. В любом случае, для реализации изменений в сфере разработки графических процессоров Intel придётся потратить несколько лет, поэтому эффект от нового назначения не будет сиюминутным. Скорее всего, усилия нового руководителя будут направлены на разработку линейки конкурентоспособных ускорителей Intel для сегмента искусственного интеллекта. Собственные разработки наверняка будут сочетаться с использованием ноу-хау поглощаемых Intel стартапов, как это было ранее. Одновременно Лип-Бу Тан назвал искусственный интеллект главным вызовом для рынка памяти, который переживает небывалый рост цен и сталкивается с дефицитом микросхем. По мнению главы Intel, улучшения ситуации нет смысла ждать ранее 2028 года. Apple прокачала Xcode, внедрив вайб-кодинг с ИИ-агентами OpenAI и Anthropic
04.02.2026 [00:26],
Владимир Фетисов
Компания Apple продолжает развивать платформу Xcode, которая позволяет автоматизировать процесс написания, редактирования и тестирования программного кода. В новой версии Xcode 26.3 разработчики смогут задействовать ИИ-агентов Anthropic Claude Agent и OpenAI Codex в процессе написания и проверки программного кода, а также для поиска нужной документации и многого другого.  Xcode — это среда разработки программного обеспечения, с помощью которой разработчики могут создавать и тестировать приложения для iPhone, iPad, Mac, Apple Watch и Apple TV. Оба упомянутых ИИ-агента уже были доступны в Xcode ранее, но после очередного обновления они получат возможность выполнения действий непосредственно в приложении, тогда как ранее их функциональность ограничивалась оказанием помощи в написании кода. Apple также делает Xcode доступным через Model Context Protocol — открытый стандарт, позволяющий разработчикам подключать к приложению другие ИИ-инструменты. Новость об обновлении Xcode поступила всего через несколько дней после того, как OpenAI объявила о запуске собственного приложения Codex для macOS. Этот продукт позволяет разработчикам писать программный код, задействовав для этого ИИ-агентов. Что касается обновлённого Xcode, то приложение уже на этой неделе станет доступно участникам программы Apple Developer Program, а в App Store оно появится «в ближайшее время». ChatGPT «упал» по всему миру: тысячи человек остались без ответов чат-бота OpenAI
04.02.2026 [00:02],
Андрей Созинов
В работе самого популярного ИИ-чат-бота ChatGPT произошёл массовый сбой. Пользователи по всему миру жалуются на то, что бот перестал генерировать ответы, а также на проблемы с загрузкой чатов и другие трудности. Причины произошедшего пока не уточняются, но в OpenAI о проблеме знают и уже работают над её устранением. 
Источник изображения: OpenAI По данным портала по отслеживанию сбоев в интернете Downdetector, проблемы в работе ChatGPT начали фиксироваться около 23:15 по московскому времени. Число жалоб на американском разделе портала взлетело выше 12 тысяч — подавляющее большинство пользователей столкнулось с проблемами в работе ChatGPT, но также встречаются жалобы на работу API OpenAI, через который сторонние приложения получают доступ к ИИ-моделям разработчика. Проблемы наблюдаются и у пользователей из других стран в Европе и Азии. К моменту публикации данной заметки объём жалоб пошёл на спад. 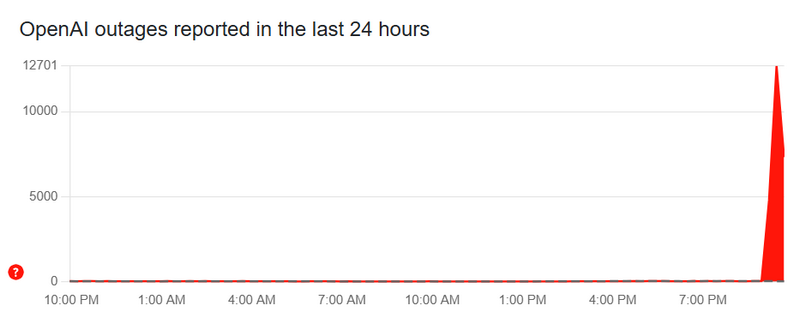
Источник изображения: Downdetector.com На странице статуса OpenAI разработчики признают наличие проблемы и заверяют, что уже ведут работы по их устранению, однако причины сбоя пока не уточняются. 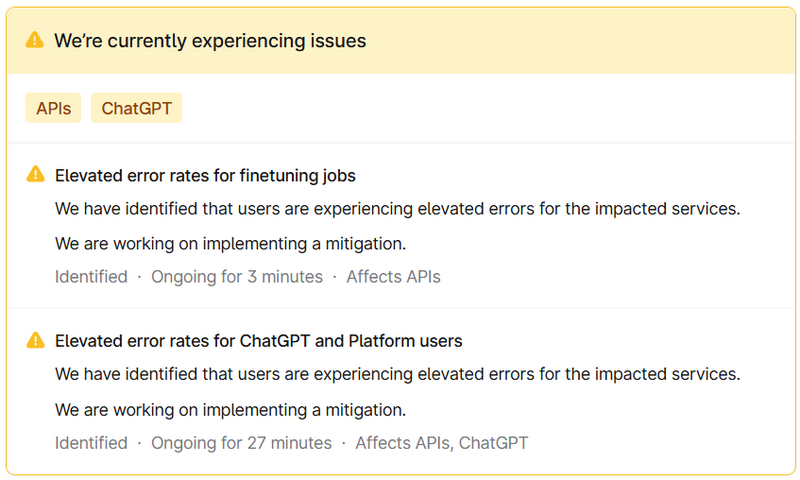 «Мы обнаружили, что пользователи сталкиваются с повышенным количеством ошибок в затронутых услугах [ChatGPT и API]. Мы работаем над внедрением мер по устранению этой проблемы», — гласит заявление OpenAI. Будет дополнено... Всего 3,3 % пользователей Microsoft 365 согласились платить за Copilot
03.02.2026 [18:14],
Павел Котов
Пользовательская база помощника с искусственным интеллектом Copilot выросла «почти втрое по сравнению с прошлым годом», сообщил в ходе конференции по итогам квартального финансового отчёта гендиректор Microsoft Сатья Наделла (Satya Nadella). Но на деле только 3,3 % взаимодействующих с чат-ботом Copilot пользователей Microsoft 365 и Office 365 платят за эту услугу, сообщает The Register. 
Источник изображения: blogs.windows.com Примечательно, что за минувший квартал Microsoft вложила в направление ИИ $37,5 млрд. Несмотря на сомнения и опасения инвесторов, Copilot «становится настоящей повседневной привычкой», отметил господин Наделла. Люди пользуются чат-ботом, новостной лентой, поисковой службой, функциями ИИ в браузере, помощником при покупках и «интеграцией с ОС». На бумаге всё выглядит хорошо: база платящих пользователей Microsoft 365 Copilot составляет около 15 млн человек, что соответствует росту на 160 % в годовом исчислении. Но в документах не говорится, что у значительной части пользователей Microsoft 365 есть бесплатный доступ к чат-боту Copilot — их совокупная база может составлять 450 млн человек. Другими словами, инвестиции Microsoft в ИИ пока, возможно, не приносят соразмерной отдачи. В 2023 году Microsoft запустила 365 Copilot в качестве дополнения за $30 в месяц за пользователя, призванного упростить работу с офисными приложениями Word, Outlook, Teams, Excel и PowerPoint. Copilot стал ИИ-агентом, способным действовать от имени пользователя, осуществлять поиск во внутренних документах, анализировать совещания и электронную почту. Финансовый директор Microsoft Эми Худ (Amy Hood), впрочем, отвергла утверждения, что расходы и инвестиции в ИИ не окупаются — она указала, что оценивать расходы исключительно по росту облачного бизнеса Azure — это «неверный критерий». Ранее стало известно, что Microsoft решила пересмотреть свою стратегию в области ИИ для Windows 11. xAI выпустила Grok Imagine 1.0 с поддержкой создания 10-секундных видео в улучшенном разрешении
03.02.2026 [06:11],
Анжелла Марина
Компания xAI представила масштабное обновление инструмента генерации видео Grok Imagine 1.0. В новой версии теперь можно создавать ролики длиной до 10 секунд в разрешении 720 пикселей и синхронизировать звук. ИИ стал лучше понимать текстовые запросы и научился работать с уточняющими инструкциями. 
Источник изображения: Grok Как сообщает издание Mint, разработчики назвали этот релиз крупнейшим обновлением системы, а Илон Маск (Elon Musk) в своём сообщении подтвердил, что версия 1.0 уже доступна. Представители xAI отметили, что обновление привнесёт повышение чёткости изображения и плавности визуального ряда для эффективного использования в творческих проектах и соцсетях. Ключевым нововведением стала работа со звуком. Пользователи смогут добавлять персонажам выразительные голоса с эмоциональной окраской, а также накладывать фоновую музыку, которая автоматически синхронизируется с происходящим на экране. В компании считают, что сочетание голоса и музыки делает сгенерированный контент более реалистичным и кинематографичным. Серьёзные изменения коснулись и логики взаимодействия с нейросетью. Grok Imagine 1.0 научился обрабатывать уточняющие запросы, что позволит корректировать детали сцены и дорабатывать результат без необходимости начинать генерацию с нуля, как это было раньше. За последние 30 дней платформа уже сгенерировала более одного миллиарда видео и популярность сервиса не уменьшается. Также сообщается, что API-модель показывает сильные результаты в бенчмарках Artificial Analysis, измерящих качество контента, созданного искусственным интеллектом Grok. В Firefox появится выключатель всех ИИ-функций разом
03.02.2026 [01:16],
Владимир Мироненко
Вскоре у пользователей Firefox появится возможность блокировать в браузере все текущие и будущие функции на базе генеративного ИИ. Как сообщила Mozilla, пользователи также смогут блокировать только определённые функции ИИ в Firefox, сохраняя при этом доступ к другим. 
Источник изображения: Rubaitul Azad/unsplash.com В версии Firefox 148, которая выйдет 24 февраля, в настройках настольного браузера появится новый раздел управления ИИ. Для того чтобы отказаться от использования функций ИИ в Firefox, достаточно будет включить переключатель «Блокировать улучшения ИИ». После этого не будут появляться всплывающие окна или напоминания об использовании существующих или будущих функций ИИ. Новые элементы настройки также позволят пользователям управлять функциями ИИ по отдельности. Эти функции браузера включают «Переводы», позволяющие просматривать веб-страницы на предпочитаемом языке, альтернативный текст в PDF-файлах, группировку вкладок с поддержкой ИИ, предварительный просмотр ссылок и чат-бот Firefox с ИИ в боковой панели, которая позволит во время просмотра веб-страниц использовать выбранный чат-бот из перечня, включающего Anthropic Claude, ChatGPT, Microsoft Copilot, Google Gemini и Le Chat Mistral. «Искусственный интеллект меняет веб, и люди хотят от него совершенно разные вещи, — написала компания в своем блоге. — Некоторые не желают иметь ничего общего с ИИ. Другие хотят использовать действительно полезные инструменты ИИ. Прислушиваясь к нашему сообществу, наряду с нашим постоянным стремлением предоставлять выбор, мы создали инструменты управления на основе ИИ». Когда в декабре 2025 года гендиректором Mozilla стал Энтони Энзора-ДеМео (Anthony Enzor-DeMeo), он заявил, что Mozilla будет инвестировать в ИИ и добавит функции ИИ в Firefox, но сделает эти функции необязательными. «ИИ всегда должен быть выбором — чем-то, что люди могут легко отключить. Люди должны знать, почему та или иная функция работает именно так и какую пользу они от неё получают», — написал Энзора-ДеМео в своём блоге. Маск подтвердил переговоры о слиянии SpaceX и xAI — ИИ оказался слишком прожорлив
02.02.2026 [22:22],
Анжелла Марина
Илон Маск (Elon Musk) подтвердил, что ведёт активные переговоры об объединении своих компаний SpaceX и xAI. Слияние необходимо для финансирования xAI, разработка которого обходится в $1 млрд ежемесячно. Предприниматель публично подтвердил факт обсуждения сделки коротким ответом «Да» на пост в соцсети X, ссылающийся на данные о переговорах. 
Источник изображения: SpaceX/Unsplash По сообщению Bloomberg со ссылкой на информированные источники, обе компании уже уведомили часть инвесторов о своих планах, а об официальном соглашении может быть объявлено уже на текущей неделе. Тем не менее отмечается, что, хотя переговоры продолжаются, сделка может затянуться или даже сорваться. По данным источников, решение продиктовано «ненасытной» потребностью искусственного интеллекта (ИИ) в капитале, которую не может покрыть ни одна из компаний Маска по отдельности. В случае успешных переговоров произойдёт объединение двух технологических гигантов: SpaceX, чья оценка в декабре составляла $800 млрд, и xAI, оценка которой составила в сентябре $200 млрд. В руководстве новой структуры, помимо самого Маска, может оказаться Гвинн Шотвелл (Gwynne Shotwell), президент и операционный директор SpaceX. Одной из стратегических целей слияния может стать реализация планов по выводу дата-центров в космос. SpaceX уже подала заявку на размещение до миллиона спутников на орбите Земли для этих целей. Аналитики также полагают, что объединение поможет завершить разработку тяжёлой ракеты Starship с целью получения контрактов, включая запуски для Космических сил США, системы ПРО Golden Dome и лунных миссий Artemis. Ранее СМИ также сообщали о дискуссиях вокруг возможного слияния SpaceX с xAI, а также о переговорах о целесообразности объединения SpaceX с Tesla. При этом SpaceX рассматривает возможность выхода на IPO, которое может оценить компанию примерно в $1,5 трлн. Yahoo представила поисковый движок Scout на основе ИИ
02.02.2026 [11:49],
Владимир Мироненко
Yahoo представила поисковый движок на основе ИИ под названием Scout, призванный служить своего рода путеводителем по интернету. Функция Yahoo Scout доступна в бета-версии. Она сочетает веб-поиск с ИИ-чатом: в ответ на запрос, размещённый в текстовом поле, пользователю предоставляется структурированный ответ вместо традиционных ссылок. 
Источник изображения: Yahoo «Yahoo Scout представлен в интуитивно понятном формате, включающем мультимедийный контент, структурированный контент в списках и таблицах, а также прозрачные источники, что делает информацию более понятной, заслуживающей доверия и пригодной для использования», — отметила компания. Три десятилетия назад Yahoo была известна как «путеводитель Джерри по всемирной паутине» и задумывалась как своего рода всеобъемлющий портал, помогающий людям находить полезную информацию интернете, но развитие веб-поиска в 2000-х практически свело на нет всю эту идею, отмечает ресурс The Verge. Yahoo Scout призван вернуть компанию к своим истокам. Scout основан на модели Claude от Anthropic, а также поисковике Microsoft Bing. В настоящее время Scout доступен в виде вкладки в поисковой системе Yahoo и отдельного веб-приложения, а также центральной функции нового мобильного приложения Yahoo Search. У Scout две основные задачи. Первая — роль путеводителя, позволяющего находить информацию в интернете. «Задача перешла от “как найти что-то в интернете“ к отсеиванию кликбейта и теперь уже мусора от ИИ», — говорит Эрик Фенг (Eric Feng), руководитель исследовательской группы Yahoo и лидер проекта Scout. Вторая ключевая задача Scout состоит в том, чтобы внедрить сводки и интеллектуальные ИИ-функции во все другие продукты Yahoo, позволяя собрать разрозненные данные в одном месте. Компания также объявила о запуске платформы Yahoo Scout Intelligence, которая объединяет возможности искусственного интеллекта со всеми ведущими отраслевыми сервисами Yahoo, включая почту, новости, финансы, спорт и многое другое. Scout запускается с партнёрскими ссылками на результаты поиска товаров и рекламным блоком внизу некоторых результатов поиска. По словам генерального директора Джима Ланцоне (Jim Lanzone), компания планирует использовать рекламу для того, чтобы Scout оставался бесплатным для всех. «Возможно, однажды у нас появится и платный уровень, — сообщил он, — но бесплатный поиск чрезвычайно важен». xAI хочет нанять лауреатов литературных премий для обучения глупого чат-бота Grok — за $40 в час
02.02.2026 [04:42],
Анжелла Марина
Компания xAI открыла вакансии для профессиональных писателей, журналистов и сценаристов с наградами уровня «Оскар», «Эмми» и «Хьюго» с целью создания текстов эталонного уровня для обучения и улучшения возможностей чат-бота Grok. Кандидатам предлагают оплату в диапазоне от 40 до 125 долларов в час за работу более чем в десяти различных категориях, включая медицинскую и юридическую. 
Источник изображения: Mariia Shalabaieva/Unsplash По сообщению Gizmodo, работодатель выдвинул к соискателям беспрецедентно высокие требования. Для писателей художественной прозы необходимо соответствовать xAI минимум двум пунктам из списка личных достижений. Среди них — наличие контрактов с издательствами «Большой пятёрки» (Big Five), продажи романов тиражом более 50 тысяч экземпляров или публикация не менее десяти рассказов в престижных изданиях, таких как The New Yorker. Также рассматриваются финалисты и лауреаты премий «Хьюго» и «Небьюла». Аналогичные требования предъявляются к сценаристам. Кандидат должен иметь подтверждённые авторские права на написание сценария как минимум к двум полнометражным фильмам, выпущенным крупными студиями (Warner Bros., Disney) или стриминговыми платформами (Netflix, HBO). Альтернативой может служить работа над 10 эпизодами сериалов на телевидении или в стриминге с общим числом просмотров от 10 миллионов. Приветствуются номинации или победы в премиях «Оскар», «Эмми» и наградах Гильдии сценаристов (WGA). Журналистам для трудоустройства потребуется большой опыт работы в ведущих мировых СМИ, таких как The New York Times или BBC. Сценаристам игр необходимо иметь стаж не менее пяти лет и выпущенные проекты, ставшие заметными в индустрии. Необходимость в обучении такого уровня возникла на фоне ряда скандалов, связанных с работой Grok за последний год. Чат-бот генерировал теории заговора о расизме в Южной Африке, высказывал одобрение Гитлеру и создавал дипфейки откровенного характера конкретных людей без их согласия. Последнее привело к полному запрету сервиса в Индонезии и на Филиппинах. |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



