|
Опрос
|
реклама
Быстрый переход
AMD и Cerebras объединились для противостояния Nvidia Groq
24.07.2026 [13:03],
Павел Котов
Графические процессоры хорошо подходят для обучения искусственного интеллекта, но для инференса, то есть развёртывания уже обученных моделей требуется большой объём быстрой памяти. AMD объединилась с Cerebras Systems для разработки вычислительной платформы, объединяющей системы Instinct с ускорителями на базе памяти SRAM, чтобы обеспечить инференс со сверхнизкой задержкой для работы ИИ-агентов. 
Источник изображения: cerebras.ai Совместный проект восполняет пробел в портфеле AMD, образовавшийся после того, как Nvidia в декабре поглотила за $20 млрд стартап Groq. Гендиректор и соучредитель Cerebras Эндрю Фельдман (Andrew Feldman) не в восторге от деятельности Nvidia, которую он сравнивал с торговцами оружием. В отличие от графических процессоров, чипы Cerebras Wefer Scale Engine (WSE) используют не HBM4, а встроенную в чипы память SRAM, которая на порядки быстрее. Благодаря этому оборудование Cerebras является одним из быстрейших в мире в задачах инференса — скорость генерации часто превышает 2000 токенов в секунду. Комплексные системы обрабатывают сложные запросы на ускорителях AMD Instinct, а генерация токенов, требующая больших объёмов памяти, делегируется Cerebras WSE — в результате достигается высокая производительность без ущерба для пропускной способности или стоимости. Конкретные показатели пока не приводятся, кроме одного: количество генерируемых токенов в секунду на ватт потребляемой энергии возрастает пятикратно. Подобная схема есть у конкурента. Вместе с системами Nvidia Vera Rubin работают LPU (Language Processing Units) Groq 3 — разница в том, что если для обслуживания модели с 1 трлн параметров Kimi K2.5 требуются две тысяч чипов Groq, то в системах AMD и Cerebras хватит и нескольких десятков. Объединённое решение будет доступно в Cerebras Cloud уже в этом году, и это не последняя сделка AMD со стартапом. Nvidia вступит в битву за инференс: готовится чип на технологиях Groq для OpenAI и ИИ-агентов
28.02.2026 [15:52],
Павел Котов
Nvidia намерена представить новый процессор, специально разработанный для того, чтобы помочь OpenAI и другим клиентам создавать более быстрые и эффективные приложения на основе обученных моделей искусственного интеллекта, сообщает The Wall Street Journal. Ранее продукты компании были ориентированы в первую очередь на обучение ИИ. 
Источник изображений: nvidia.com Nvidia ведёт разработку новой системы для инференса — запуска моделей ИИ, когда они отвечают на запросы пользователей. Новая платформа, которую компания представит на конференции для разработчиков Nvidia GTC в марте, будет включать чип, разработанный стартапом Groq. Конкуренция в этой области сейчас ожесточается — Google и Amazon уже создали собственные ускорители, способные сравниться с продукцией Nvidia; ситуацию усугубляет взрывной рост популярности технологий вайб-кодинга — написания программных продуктов системами ИИ по текстовым запросам пользователей. Одним из крупнейших клиентов на новый процессор уже согласилась стать OpenAI, сообщают источники издания, и это крупная победа для Nvidia. Накануне разработчик ChatGPT намекнул на этот проект, объявив о заключении крупной сделки по приобретению «выделенных мощностей для инференса» у Nvidia, а также об инвестициях в размере $30 млрд от «зелёного» производителя. Компания также заключила соглашение на предмет использования ИИ-ускорителей Amazon Trainium. Nvidia доминирует на рынке графических процессоров (GPU) — чипов, способных одновременно выполнять миллиарды простых задач. GPU семейств Hopper, Blackwell и Rubin считаются лучшими для обучения ИИ, и здесь доля компании на мировом рынке, по оценкам аналитиков, составляет не менее 90 %. Глава компании Дженсен Хуанг (Jensen Huang) утверждает, что продукция Nvidia одинаково хорошо подходит и для обучения, и для инференса. Однако разработчики ИИ-агентов и других приложений на основе ИИ начинают понимать, что по сравнению с разработками конкурентов чипы Nvidia слишком дороги, слишком энергозатратны и не так хорошо подходят для запуска уже обученных моделей.  В январе OpenAI заключила со стартапом Cerebras соглашение о партнёрстве — компания предложила ориентированный на инференс чип, который, по её утверждению, работает быстрее ускорителей Nvidia. OpenAI начала переговоры с Cerebras ещё минувшей осенью, когда инженеры компании запросили более быстрое оборудование для приложений агентного написания кода. Nvidia же в минувшем году заключила со стартапом Groq сделку на $20 млрд, лицензировав её технологии и приняв на работу топ-менеджеров компании, включая её основателя. Groq разработала чипы на принципиально иной архитектуре — они включают «блоки языковой обработки», отличающиеся высокой эффективностью в задачах инференса. О своих намерениях использовать эти активы Nvidia пока умалчивает. Одним из наиболее востребованных направлений в сфере ИИ являются задачи, связанные с генерацией программного кода. Лидером здесь считается сервис Anthropic Claude Code, который работает в облачных инфраструктурах Amazon и Google, но активно развивается и служба OpenAI Codex, которая будет работать на новой инфраструктуре Nvidia. Nvidia также заключила соглашение с компанией Meta✴✴ об инференсе ИИ-систем для таргетирования рекламы — и эта задача эффективнее всего решается на центральных процессорах. Nvidia похвалилась, что Blackwell удешевили инференс нейросетей до 10 раз — и это заслуга не только «железа»
13.02.2026 [16:42],
Павел Котов
С развёртыванием ускорителей искусственного интеллекта на архитектуре Nvidia Blackwell стоимость инференса, то есть запуска обученных систем ИИ, удалось сократить в 4–10 раз. Такие данные привела сама Nvidia. Но за счёт одной только аппаратной части добиться подобных результатов не получилось бы. 
Источник изображений: nvidia.com Значительного снижения затрат удалось добиться за счёт запуска ускорителей на архитектуре Nvidia Blackwell и моделей с открытым исходным кодом в инфраструктуре облачных операторов Baseten, DeepInfra, Fireworks AI и Together AI для задач, связанных со здравоохранением, играми, агентским ИИ и обслуживанием клиентов. Ещё один фактор — оптимизированные программные стеки. Перевод оборудования на Nvidia Blackwell помог сократить стоимость инференса вдвое по сравнению с ускорителями предыдущего поколения, а дальнейшему снижению затрат способствовал перевод систем в форматы пониженной точности, такие как NVFP4. Компания Sully.ai добилась сокращения затрат на вывод данных ИИ в области здравоохранения на 90 %, то есть в десять раз; время отклика улучшилось на 65 % за счёт перехода от закрытых к открытым моделям ИИ в инфраструктуре Baseten. Автоматизация задач по написанию кода и ведению медицинских записей помогла сэкономить специалистам 30 млн минут рабочего времени. Latitude на своей платформе AI Dungeon сократила затраты на вывод данных ИИ в четыре раза. Для этого она запустила в инфраструктуре DeepInfra модели с конфигурацией «смеси экспертов» (MoE), снизив стоимость 1 млн токенов с $0,20 до $0,10, а перевод системы на низкоточный формат данных NVFP4 помог сократить цену до $0,05. 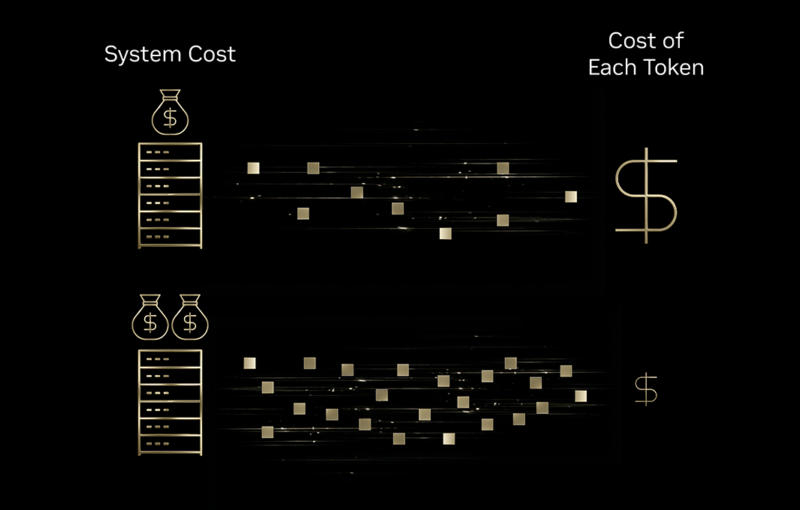 Sentient Foundation повысила экономическую эффективность платформы агентного чата на 25–50 % за счёт оптимизированного для Blackwell стека обработки данных Fireworks AI — платформа управления сложными рабочими процессами в неделю вирусного запуска обработала 5,6 млн запросов без ущерба для величины задержки. Decagon шестикратно снизила затраты на запрос для голосовой поддержки клиентов с ИИ, запустив многомодельный стек в инфраструктуре Together AI на ускорителях Blackwell. Время ответа сохранялось менее 400 мс даже при обработке нескольких тысяч токенов на запрос, что критически важно при голосовом взаимодействии, когда клиенты в любой момент могут прервать разговор. Значение имеют характеристики рабочей нагрузки. ИИ-ускорители Blackwell успешно работают с «рассуждающими» ИИ-моделями, потому что для получения более качественных ответов те генерируют большее число токенов. Платформы эффективно обрабатывают эти расширенные последовательности за счёт дезагрегированного обслуживания — отдельной обработки предварительного заполнения контекста и собственно генерации токенов. При оценке затрат эти аспекты следует учитывать: при высоких объёмах генерации токенов можно добиться десятикратного повышения эффективности; уменьшенная генерация токенов в моделях высокой плотности ведёт лишь к четырёхкратному росту показателей. В приведённых выше примерах речь идёт об ускорителях Nvidia Blackwell, но есть и альтернативные способы снижения затрат на вывод данных. Например, перевод систем на ускорители AMD Instinct MI300, Google TPU, а также специализированное оборудование Groq и Cerebras. Собственные средства оптимизации развёртывают и облачные провайдеры. Поэтому вопрос не в том, является ли архитектура Blackwell единственным вариантом, а в том, соответствует ли конкретное сочетание оборудования, ПО и моделей ИИ требованиям конкретной рабочей нагрузки. OpenAI усомнилась в эффективности ускорителей Nvidia для инференса и всё активнее ищет им альтернативу
03.02.2026 [08:40],
Алексей Разин
Принято считать, что OpenAI и Nvidia являются главными выгодоприобретателями бума искусственного интеллекта, и они поддерживают прочные партнёрские отношения, которые должны быть подкреплены сделкой на сумму $100 млрд. Источники при этом отмечают, что эффективность ускорителей Nvidia в инференсе может не устраивать OpenAI, поэтому она стремится найти им подходящую альтернативу. 
Источник изображения: Nvidia Об этом по своим каналам удалось выяснить Reuters, хотя публично OpenAI и Nvidia продолжают выражать крайнюю степень взаимной лояльности. Если верить данным источника, OpenAI хотела бы до 10 % ускорителей в своей вычислительной инфраструктуре заменить на решения сторонних поставщиков, которые лучше проявляли бы себя в задачах инференса — то есть, эффективнее бы работали с уже обученными большими языковыми моделями. OpenAI даже хотела договориться с Cerebras и Groq о поставках разрабатываемых этими стартапами чипов, но Nvidia решила сработать на опережение, купив в прошлом году последний за $20 млрд. До этого Groq вела переговоры с другими инвесторами о вложении в свой капитал до $14 млрд, но Nvidia предложила больше, обеспечив при этом весьма специфическую структуру сделки. По её условиям, Groq сохранила возможность лицензирования своих разработок другим компаниям, но фактически Nvidia перевела в свой штат основных разработчиков ускорителей из Groq. Фактически, остальным компаниям Groq теперь может предложить только программное обеспечение для облачных систем. Одновременно возникают вопросы по целесообразности сделки, в рамках которой Nvidia предложила направить в капитал OpenAI до $100 млрд. Пока стороны отрицают наличие проблем в этой сфере, хотя Nvidia и подчёркивает, что её обязательства не носят строгого характера. Сделку с Cerebras компании OpenAI заключить удалось, теперь вторая будет покупать у первой так называемые «царь-ускорители», которые неплохо проявляют себя в задачах инференса. Проблема OpenAI до сих пор заключалась в том, что она сильно зависит от ускорителей Nvidia и AMD, которые используют внешнюю, пусть и очень быструю память HBM, а в инференсе себя лучше проявляют чипы с большим объёмом интегрированной памяти. Таковые как раз предлагают Groq и Cerebras, а также конкурирующая Google. С последней, кстати, смогла договориться Anthropic, поэтому OpenAI пришлось искать альтернативы. По некоторым данным, OpenAI столкнулась с неэффективностью ускорителей Nvidia при создании ИИ-агента Codex, который помогает разработчикам создавать программный код. Обычные пользователи того же ChatGPT подобных проблем не испытывают, но для программистов OpenAI постарается предложить другие аппаратные решения типа изделий Cerebras, чтобы повысить производительность соответствующих программных инструментов. Intel подыскала себе нишу на рынке ИИ-чипов, захваченном Nvidia
26.10.2025 [07:52],
Алексей Разин
Тема искусственного интеллекта важна как для участников рынка, так и для инвесторов, а потому на минувшем квартальном отчётном мероприятии руководство Intel не могло обойти её вниманием. Генеральный директор Лип-Бу Тан (Lip-Bu Tan) дал понять, что Intel в ближайшие годы сосредоточится на решениях для инференса в разных сегментах рынка, и при этом будет стараться сотрудничать как с крупными игроками рынка, так и с начинающими. 
Источник изображения: Intel «Я продолжаю верить, что мы сможем играть значительную роль в разработке вычислительных платформ для зарождающихся нагрузок в сфере инференса, появляющихся благодаря агентскому и физическому ИИ. Этот рынок будет заметно более крупным по сравнению с сегментом обучения. Мы будем работать над тем, чтобы платформу Intel выбирали для инференса ИИ, и собираемся сотрудничать с многими устоявшимися игроками, равно как и с зарождающимися компаниями, которые будут определять эту новую парадигму вычислений. Это многолетняя инициатива, и мы будем заключать партнёрские соглашения в тех случаях, когда сможем вывести на рынок лидирующие продукты и предложить что-то отличное», — заявил глава Intel. «В ближайшее время, мы продолжим внедрять ИИ-возможности в Xeon, ИИ-ПК, Arc, GPU и наш открытый программный стек. В дальнейшем мы собираемся представлять последующие поколения наших оптимизированных под инференс GPU на ежегодной основе, они будут оснащаться улучшенной памятью и пропускной способностью для соответствия требованиям в корпоративном секторе», — добавил Лип-Бу Тан. Лучшая роль второго плана: чипы AMD недостаточно хороши, чтобы стать ядром инфраструктуры OpenAI
07.10.2025 [14:59],
Алексей Разин
Даже по мнению главы AMD Лизы Су (Lisa Su), структура анонсированной вчера сделки с OpenAI получилась инновационной и замысловатой, поэтому анализ выгод и преимуществ, которые получат её участники, может занять много времени. По сути, ускорители AMD Instinct потребуются OpenAI для развития инфраструктуры для инференса, но в сфере обучения больших языковых моделей продукция Nvidia всё равно будет на первых ролях. 
Источник изображения: AMD Новые стороны сделки пытается раскрыть издание The Wall Street Journal, которое поясняет, что последний транш акций AMD может достаться OpenAI в рамках сделки в том случае, если их рыночная стоимость достигнет $600. По сути, при текущем курсе около $207 за акцию капитализация AMD уже приблизилась к $330 млрд после вчерашнего скачка котировок, поэтому участники сделки явно рассчитывают, что в определённый момент капитализация AMD вырастет почти до $1 трлн. Казалось бы, это приличная сумма, но в этом случае AMD всё равно остаётся в тени Nvidia, чья капитализация на нынешних уровнях выше почти в 14 раз и достигает $4,5 трлн, а в сегменте ускорителей вычислений и видеокарт её рыночная доля измеряется как минимум 75 %, по мнению многих аналитиков. Глава AMD Лиза Су на этой неделе заявила, что сделка с OpenAI станет «огромным расширением той работы, которую мы делаем», но хорошо известно, что ускорители AMD Instinct в большей мере заточены под инференс, а не обучение языковых моделей. По сути, OpenAI будет использовать сотрудничество с AMD, чтобы перераспределить вычислительные ресурсы оптимальным образом: под инференс будут использоваться ускорители этого партнёра, а для обучения языковых моделей удастся высвободить больше ускорителей Nvidia, с которой у OpenAI оформлена ещё более крупная сделка. Исторически ставка делалась на более производительные чипы, способные работать с обучением больших языковых моделей, использующих миллиарды или даже триллионы параметров. Сейчас же спрос в сфере ИИ постепенно смещается в сторону инференса, который не требует столь значительных вычислительных ресурсов, а потому сделка OpenAI и AMD может быть выгодна обеим компаниям. Клиентам ИИ-сервисов функции, связанные с инференсом, кажутся более полезными и практичными для применения, поэтому и коммерческий потенциал этого сектора рынка будет расти после того, как прогресс в сфере обучения больших языковых моделей достигнет фазы какого-то насыщения. Лиза Су неоднократно отмечала ориентацию решений AMD на инференс и подчёркивала, что пока спрос на решения для ИИ растёт, места на рынке хватит для всех компаний. Кроме того, ускорители AMD традиционно дешевле решений Nvidia и могут быть экономичнее в эксплуатации, а ещё их банально проще купить в условиях всеобъемлющего дефицита, сосредоточенного в сегменте продукции Nvidia. Президент и один из основателей OpenAI Грег Брокман (Greg Brockman) заявил: «Мы действительно верим, что в мире существует недооценка потребностей в инференсе, и что мы движемся к миру, в котором всего не хватает. Это рынок с выгодными условиями для всех участников (very positive-sum market — прим. автора), где люди просто не строят в достаточном количестве. Чипов не будет хватать». Новая ИИ-модель DeepSeek cделает работу с длинным контекстом вдвое дешевле и быстрее
30.09.2025 [10:46],
Владимир Мироненко
Инженеры DeepSeek представили новую экспериментальную модель V3.2-exp, которая обеспечивает вдвое меньшую стоимость инференса и значительное ускорение для сценариев с длинным контекстом. 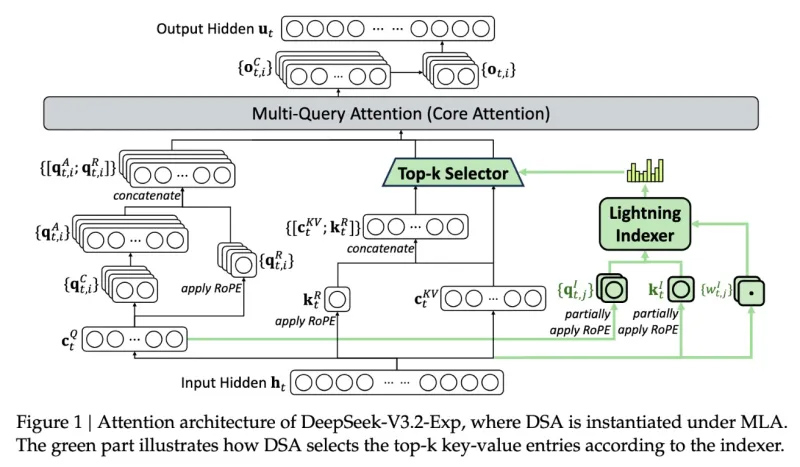
Источник изображения: DeepSeek/TechCrunch «В качестве промежуточного шага к архитектуре следующего поколения, V3.2-Exp дополняет V3.1-Terminus, внедряя DeepSeek Sparse Attention — механизм разреженного внимания, предназначенный для исследования и валидации оптимизаций эффективности обучения и вывода в сценариях с длинным контекстом», — сообщила компания в публикации на платформе Hugging Face, отметив в сообщении в соцсети X, что цены на API снижены более чем на 50 %. С помощью механизма DeepSeek Sparse Attention (DSA), который работает как интеллектуальный фильтр, модель выбирает наиболее важные фрагменты контекста, из которых с использованием системы точного выбора токенов выбирает определённые токены для загрузки в ограниченное окно внимания модуля. Метод сочетает крупнозернистое сжатие токенов с мелкозернистым отбором, гарантируя, что модель не теряет более широкий контекст. DeepSeek утверждает, что новый механизм отличается от представленной раннее в этом году технологии Native Sparse Attention и может быть модифицирован для предобученных моделей. В бенчмарках V3.2-Exp не уступает предыдущей версии ИИ-модели. В тестах на рассуждение, кодирование и использование инструментов различия были незначительными — часто в пределах одного-двух пунктов, — в то время как рост эффективности был значительным, пишет techstartups.com. Модель работала в 2–3 раза быстрее при инференсе с длинным контекстом, сократила потребление памяти на 30–40 % и вдвое повысила эффективность обучения. Для разработчиков это означает более быструю реакцию, снижение затрат на инфраструктуру и более плавный путь к развёртыванию. Для операций с длинным контекстом преимущества системы весьма существенны, отметил ресурс TechCrunch. Для более надёжной оценки модели потребуется дальнейшее тестирование, но, поскольку она имеет открытый вес и свободно доступна на площадке Hugging Face, пользователи сами могут оценить с помощью тестов, насколько эффективна новая разработка DeepSeek. Thinking Machines Lab намерена добиться, чтобы ИИ не отвечал по-разному на одинаковые вопросы
12.09.2025 [12:01],
Павел Котов
Бывшая технический директор OpenAI Мира Мурати (Mira Murati) учредила Thinking Machines Lab — собственный стартап в области искусственного интеллекта, который уже привлёк от инвесторов $2 млрд, не анонсировав ни одного продукта. В минувшую среду компания всё-таки рассказала об одном из своих проектов — она намеревается разработать модель ИИ, способную воспроизводить собственные ответы. Это оказалось не так просто. 
Источник изображения: Steve Johnson / unsplash.com В корпоративном блоге Thinking Machines Lab появилась публикация под заголовком «Преодоление нестабильности в ответах больших языковых моделей». Работающий в компании исследователь Хорас Хэ (Horace He) пытается раскрыть первопричину фактора случайности в ответах моделей ИИ: если задать, например, ChatGPT один и тот же вопрос несколько раз, чат-бот будет всегда отвечать по-разному. Сообщество ИИ приняло эту особенность как данность, современные модели считаются недетерминированными системами, но в Thinking Machines Lab считают проблему решаемой. Хорас Хэ указывает, что первопричина случайного фактора в работе моделей ИИ кроется в механизме взаимодействия между графическими ядрами — запущенными на чипах Nvidia алгоритмами — в процессе инференса, то есть вывода системы ИИ. Если обеспечить тщательный контроль над этим механизмом, можно повысить уровень определённости в работе моделей. В результате увеличится и надёжность ответов ИИ для потребителей, предприятий и учёных. Добившись воспроизводимости, можно повысить также качество обучения с подкреплением — процесса, при котором ИИ получает вознаграждение за правильные ответы: если все они имеют небольшие отличия, то в данных на выходе возникает информационный шум. Когда же ответы моделей ИИ оказываются более согласованными, то и процесс обучения с подкреплением становится более «гладким», рассуждает учёный. 
Источник изображения: thinkingmachines.ai Ранее Thinking Machines Lab сообщила инвесторам, что намеревается предлагать бизнесу модели ИИ, прошедшие настройку с помощью обучения с подкреплением. Первый продукт Мира Мурати пообещала представить в ближайшие месяцы, отметив, что он будет «полезен для исследователей и стартапов, разрабатывающих собственные модели». Что это за продукт, и будут ли применяться при его разработке указанные в новом материале методы повышения воспроизводимости результатов, ясности пока нет. Компания также заявила о планах часто публиковать в блоге записи с программным кодом и другой информацией о своих исследованиях, чтобы «приносить пользу обществу, а также повышать нашу собственную культуру научных разработок». На момент создания Thinking Machines Lab брала на себя обязательство проводить открытую политику в отношении собственных исследований, но по мере роста компания становилась всё более закрытой. Публикация даёт редкую возможность заглянуть за кулисы одного из самых засекреченных стартапов отрасли — точного направления развития технологии пока не даётся, но есть повод утверждать, что Thinking Machines Lab занялась решением одной из важнейших задач в области ИИ. Настоящей проверкой для неё будет ответ на вопрос, способна ли она решать такие задачи и создавать на основе этих исследований продукты, оправдывающие оценку компании в $12 млрд. «Торрент для запуска ИИ»: вышла утилита для распределённого запуска ИИ-моделей на любом оборудовании
27.02.2025 [18:30],
Павел Котов
Большие языковые модели искусственного интеллекта требуют значительных ресурсов не только при обучении, но и при запуске — необходимы существенные объёмы оперативной памяти и мощные графические процессоры. Альтернативу предложили создатели Exo — бесплатной программы для распределённого запуска ИИ на нескольких устройствах. Почти как торренты, только для запуска ИИ. 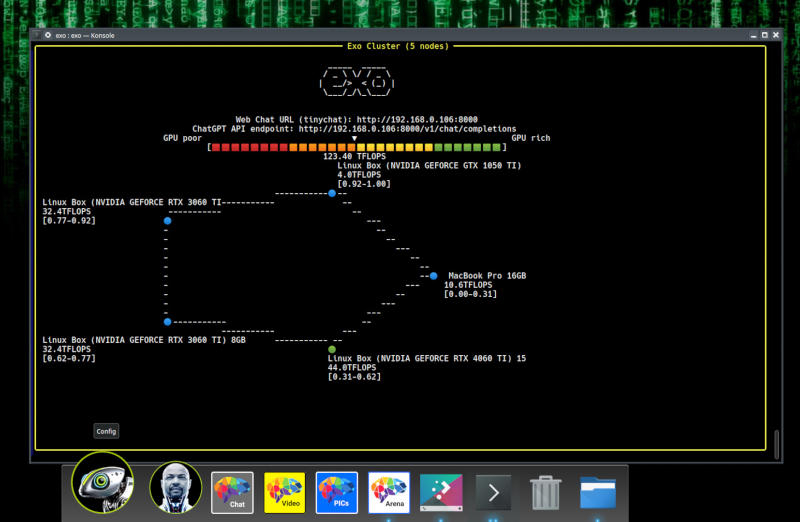
Источник изображения: github.com/exo-explore/exo Приложение позволяет объединять вычислительные ресурсы нескольких компьютеров, смартфонов и даже одноплатных компьютеров, в том числе Raspberry Pi, для запуска моделей, с которыми ни одна из имеющихся в распоряжении пользователя систем не справилась бы самостоятельно. Ресурсы устройств объединяются по одноранговой сети. Exo динамически распределяет нагрузку, создаваемую большой языковой моделью, по доступным в сети устройствам, размещая её слои, исходя из доступного объёма оперативной памяти и имеющейся вычислительной мощности. Поддерживаются LLaMA, Mistral, LlaVA, Qwen и DeepSeek. Программа устанавливается на устройства под управлением Linux, macOS, Android или iOS — версии под Windows пока нет. Для работы Exo требуется минимальная версия Python 3.12.0 и, в случае машин под Linux с графикой Nvidia, ряд других компонентов. Модель ИИ, требующую 16 Гбайт оперативной памяти, можно запустить на двух ноутбуках с 8 Гбайт на каждом; а мощную DeepSeek R1, которой нужны 1,3 Тбайт памяти, в теории можно запустить на кластере из 170 Raspberry Pi 5 с 8 Гбайт. Скорость сети и задержка могут снизить качество работы модели, и разработчики Exo предупреждают, что устройства небольшой производительности способны замедлить ИИ, но с каждым добавленным в сети устройством общая производительность увеличивается. Нельзя также забывать об угрозах безопасности, которые неизбежно возникают при совместном выполнении рабочих нагрузок на нескольких машинах. И даже с учётом этих оговорок Exo представляется перспективной альтернативой облачным ресурсам. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



