|
Опрос
|
реклама
Быстрый переход
ИИ с «глазами» оказался в разы дороже обычного API — агенты сжигают бюджеты, ходя по сайтам
07.05.2026 [17:44],
Павел Котов
Компании, которые используют агентов искусственного интеллекта, могут потратить значительно больше денег, если эти агенты оперируют визуальными данными, имитируя человеческое зрение. 
Источник изображения: reflex.dev Специалисты платформы корпоративных приложений Reflex сравнили визуальных ИИ-агентов с теми, что осуществляют доступ к внешним ресурсам через API. Обоими агентами управляла нейросеть Anthropic Claude Sonnet: в первом случае она контролировала Python-фреймворк browser-use 0.12 для автоматизированной работы с браузером; во втором — обращалась к тем же веб-приложениям по API. При обращении по API агент вызывал те же механизмы обработки, что при работе с пользовательским интерфейсом, но получал в ответ структурированные данные, а не скриншот веб-страницы, который требовалось дополнительно анализировать. Обоим агентам организаторы эксперимента дали задание: «Клиент по имени Смит пожаловался на недавний заказ. Найди Смита с наибольшим количеством заказов, прими все его отзывы на модерации и отметь последний как доставленный». ИИ-агент с обращением по API выполнил задачу за восемь запросов к ИИ-модели; визуальный вариант нашёл только один из четырёх ожидающих отзывов — остальные три он пропустил, потому что не догадался прокрутить страницу. Когда условия задачи упростили в угоду визуальному ИИ-агенту, тот выполнял её около 17 минут; вариант с обращением по API добился результата за 20 секунд и израсходовал в 45 раз меньше токенов модели ИИ. По оценкам Anthropic, обработка изображения размером 1000 × 1000 пикселей с помощью модели Claude Sonnet 4.6 расходует около 1334 токенов. Визуальный ИИ-агент израсходовал на выполнение задачи около 500 000 входных и около 38 000 выходных токенов; обращавшийся по API агент потратил около 12 150 входных и 934 выходных токенов. Авторы эксперимента сделали такой вывод: агентов с машинным зрением следует использовать только для работы с приложениями, которые пользователь не контролирует; внутренние процессы должны обрабатываться по API. В Китае создали «глаз мухи» для дронов с панорамным зрением и встроенным «обонянием»
13.02.2026 [22:00],
Геннадий Детинич
Исследователи пока не смогли создать сферические мушиные глаза, но даже упрощённый глаз на плоской подложке впечатляет миниатюрными размерами и возможностями. Это платформа размером всего 1,5 × 1,5 мм. По сути, это габариты насекомого, что приближает появление миниатюрных дронов размером с таракана или даже муху. Современные устройства машинного зрения намного крупнее, сложнее и требуют значительной энергии и вычислительных ресурсов, от чего китайская разработка ушла довольно далеко. 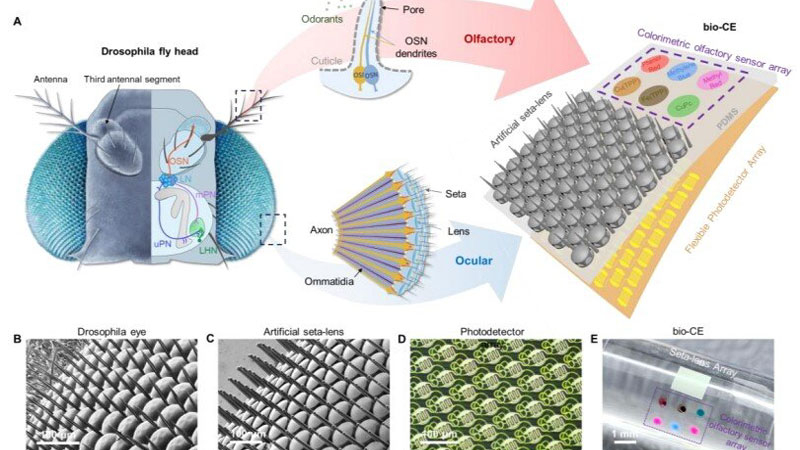
Источник изображения: Nature Communications 2026 Более того, этот миниатюрный датчик содержит сенсоры ряда опасных газов, которые искусственный глаз распознаёт автоматически. Даже мухи на такое не способны — их глаза лишены обоняния. Комбинация зрения и обоняния на одном компактном сенсоре — это шаг на пути повышения энергоэффективности миниатюрных роботизированных платформ, а также увеличения скорости их реагирования на окружающую обстановку. Отвечающая за зрение часть датчика состоит из 1027 элементов с микролинзами, напечатанными непосредственно на гибком фотодетекторе с помощью фемтосекундной лазерной двухфотонной полимеризации (FL-TPP). Это делает каждый оптический элемент изолированным от других, обеспечивая поле зрения шириной 180°. Слияние вспышек света для датчика начинается с частоты выше 1 кГц — это почти на два порядка больше, чем у человеческого глаза. Тем самым искусственный мушиный глаз различает намного более быстрые движения. Обонятельная компонента реализована методом струйной печати на той же платформе: массив колориметрических сенсоров меняет цвет при контакте с опасными газами и химикатами, имитируя «нюх» насекомого. Дополнительно между линзами добавлены щетинки, как у настоящих насекомых, что необходимо для защиты от запотевания во влажной среде. Щетинки удержат капельки влаги на себе и не дадут им затянуть линзы. В тестах датчика на миниатюрном четырёхколёсном роботе система продемонстрировала высокую чувствительность при сближении с препятствиями и движущимися помехами без необходимости поворота «головы» благодаря панорамному обзору. Робот одновременно обнаруживал препятствия слева и справа, а также реагировал на утечки опасных газов. Устройство показало отличную производительность в обнаружении быстрых движений и химических угроз, превзойдя многие существующие сенсоры по компактности и энергоэффективности. Разработка открывает новые возможности для навигации беспилотных платформ, включая микродроны и рои роботов, в сложных условиях — например, при поиске выживших в завалах или мониторинге химических утечек в зонах катастроф. Такой датчик может значительно повысить «интеллект» биороботов за счёт одновременного визуально-обонятельного восприятия при минимальной массе и энергозатратах, обеспечивая важный шаг в направлении автономных систем следующего поколения. Учёные заставили ИИ видеть то, чего нет — машинное зрение оказалось уязвимым
03.07.2025 [19:19],
Сергей Сурабекянц
Исследователи из университета Северной Каролины продемонстрировали новый способ атаки на системы компьютерного зрения, позволяющий контролировать то, что «увидит» искусственный интеллект. Использованный метод под названием RisingAttacK оказался эффективным для манипулирования всеми наиболее широко используемыми системами компьютерного зрения. 
Источник изображения: unsplash.com RisingAttacK — это так называемая «состязательная атака» (adversarial attack), которая манипулирует данными, подаваемыми в систему ИИ. RisingAttacK состоит из серии операций, целью которых является внесение минимального количества изменений в изображение, которое позволит сбить с толку когнитивные способности ИИ. В результате ИИ может неправильно определить цвет светофора или поставить ошибочный диагноз по рентгеновскому снимку. Сначала RisingAttacK идентифицирует все визуальные особенности изображения и пытается определить, какая из них наиболее важна для достижения цели атаки. Затем RisingAttacK вычисляет, насколько чувствительна система ИИ к изменениям найденных ключевых особенностей. «Это требует некоторой вычислительной мощности, но позволяет нам вносить очень небольшие целенаправленные изменения в ключевые особенности, что делает атаку успешной, — рассказал доцент кафедры электротехники и вычислительной техники университета Северной Каролины Тяньфу Ву (Tianfu Wu). — В результате два изображения могут выглядеть одинаково для человеческого глаза, и мы можем чётко видеть машину на обоих изображениях. Но из-за RisingAttacK ИИ увидит машину на первом изображении, но не увидит на втором». 
Источник изображений: Tri-Star Pictures Исследователи протестировали метод RisingAttacK против четырёх наиболее часто используемых программ компьютерного зрения: ResNet-50, DenseNet-121, ViTB и DEiT-B. Метод оказался эффективным при манипулировании всеми четырьмя программами. «Мы хотели найти эффективный способ взлома систем машинного зрения с ИИ, потому что эти системы часто используются в контекстах, которые могут повлиять на здоровье и безопасность человека — от автономных транспортных средств до медицинских технологий и приложений безопасности, — пояснил Ву. — Выявление уязвимостей является важным шагом в обеспечении безопасности этих систем».  «Хотя мы продемонстрировали способность RisingAttacK манипулировать моделями зрения, сейчас мы находимся в процессе определения того, насколько эффективен этот метод при атаке на другие системы искусственного интеллекта, такие как большие языковые модели. В дальнейшем наша цель состоит в разработке методов, которые могут успешно защищать от таких атак», — заключил он. Исследовательская группа сделала код RisingAttacK общедоступным для изучения и тестирования. Мозговой имплант Neuralink позволил обезьяне увидеть несуществующий предмет
14.06.2025 [06:49],
Алексей Разин
Идея создания интерфейса между мозгом человека и компьютером не является для стартапа Neuralink Илона Маска (Elon Musk) единственным направлением разработок в сфере мозговых имплантов. Устройство Blindsight призвано вернуть способность видеть незрячим пациентам, и недавно в ходе испытаний на обезьяне представителям компании удалось добиться определённого успеха. 
Источник изображения: Neuralink Выступая на конференции в пятницу, инженер Neuralink Джозеф О’Доэрти (Joseph O’Doherty) рассказал о том, что ему и его коллегам удалось оказать стимулирующее воздействие на мозг обезьяны с вживлённым имплантом Blindsight, вызвав у неё своего рода зрительную галлюцинацию. Как считают авторы эксперимента, по меньшей мере две трети времени животное могло видеть некий предмет, которого в реальности не существовало. Об этом они могли судить по движению глаз подопытной обезьяны. Neuralink впервые открыто говорит о своих тестах импланта Blindsight. О клинических испытаниях с привлечением людей пока говорить преждевременно, поскольку в США это устройство не получило соответствующих одобрений со стороны регулирующих органов. Илон Маск ранее заявлял, что возвращение людям зрения является лишь базовой задачей проекта Blindsight, в идеале стартап хотел бы развить этот канал восприятия человеком действительности до пределов, не предусмотренных природой. Например, такие импланты могут наделить человека способность видеть в инфракрасном спектре. В марте он признался, что испытания Blindsight на обезьянах проводятся уже несколько лет, но вживить имплант первому человеку компания надеется до конца текущего года. Попутно инженер Neuralink поведал о прогрессе в испытаниях первой модели импланта, который позволяет транслировать нервные импульсы в компьютерные команды. На данный момент имплантом пользуются пять пациентов с той или иной формой паралича конечностей или мышц. Отдельные участники клинических испытаний пользуются возможностями импланта по 60 часов в неделю. Представитель Neuralink на конференции рассказал об экспериментах компании, в ходе которых имплант использовался для стимуляции мышечных сокращений обезьяны через головной мозг. В перспективе, подобная технология позволит вернуть подвижность парализованным пациентам без необходимости использования протезов или экзоскелета. В отношении дальнейших перспектив развития Blindsight было сказано, что стартап планирует использовать в сочетании с мозговым имплантом пару специальных очков, которые позволят вернуть зрение лишившимся его людям. Отвечающая за зрение часть головного мозга обезьяны расположена ближе к его поверхности, чем у человека, и это упрощает тестирование чипа на данном этапе. В случае с человеческим мозгом электроды импланта будут размещаться в более глубоких областях при помощи хирургического робота, разработанного Neuralink. Figure похвалилась успехами человекоподобного робота Helix на работе, но посылки продолжают летать по складу
09.06.2025 [19:26],
Сергей Сурабекянц
Три месяца назад робототехнический стартап Figure «устроил на работу» в почтовое отделение своего передового гуманоидного робота Helix. Сегодня представители компании подробно рассказали о накопленном за это время опыте и успехах робота в сортировке посылок. Однако при просмотре опубликованного компанией почти часового видеоролика мы заметили множество ошибок, совершаемых Helix. Пожалуй, свои посылки мы ему пока доверить не готовы. 
Источник изображений: Figure «Теперь Helix может обрабатывать более широкий спектр упаковок и приближается к ловкости и скорости человеческого уровня, приближая нас к полностью автономной сортировке посылок. Этот быстрый прогресс подчёркивает масштабируемость основанного на обучении подхода Helix к робототехнике, который быстро переносится в реальное применение», — так оценил успехи робота представитель Figure. По его словам, за счёт масштабирования данных и усовершенствования архитектуры возможности Helix существенно повысились:
Помимо стандартных жёстких коробок система теперь обрабатывает полиэтиленовые пакеты, мягкие конверты и другие деформируемые или тонкие посылки. Эти предметы могут складываться, мяться или изгибаться, что затрудняет захват и распознавание этикеток. Helix решает эту задачу, корректируя стратегию захвата на лету — например, отбрасывая мягкий пакет для его динамического переворота или используя специальные захваты для плоских почтовых отправлений. 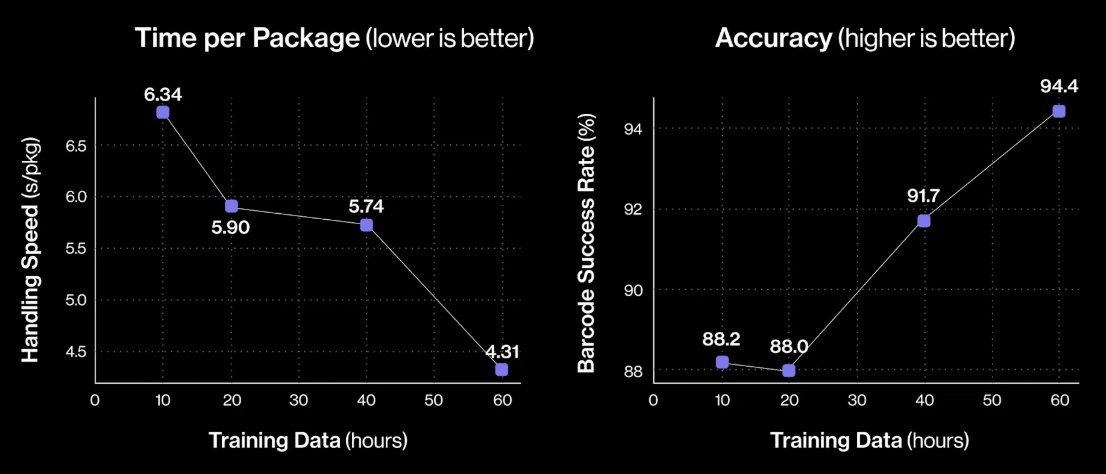 Робот должен поворачивать упаковку штрих-кодом вниз для сканирования. Helix старается расправить пластиковую упаковку, чтобы сканер смог успешно считать штрих-код. Такое адаптивное поведение подчёркивает преимущества сквозного обучения — робот выполняет действия, которые не были жёстко запрограммированы, чтобы компенсировать несовершенства упаковки. Многие достижения стали возможны благодаря целенаправленным улучшениям визуально-моторной политики робота. Он получил новые модули памяти и машинного зрения, что позволило ему лучше воспринимать состояние окружающей среды и быстро адаптироваться к изменениям ситуации. 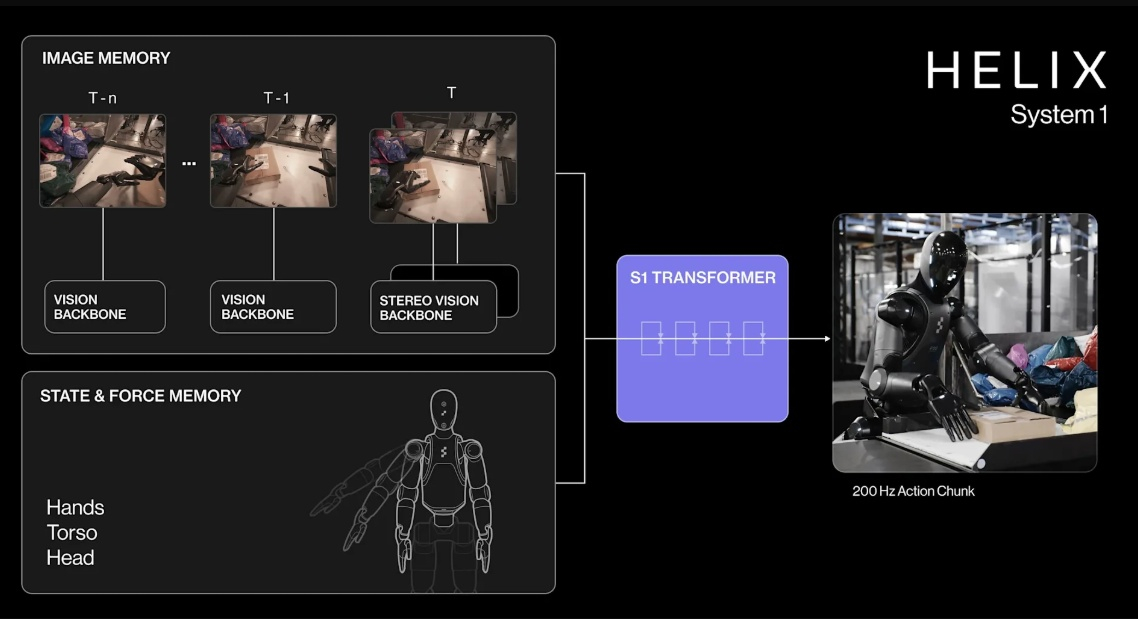 Helix оснащён модулем неявной визуальной памяти, который обеспечивает поведение с учётом текущего состояния — робот запоминает, какие стороны упаковки он уже осмотрел, либо какие зоны конвейера свободны. Модуль памяти помогает устранять избыточные движения, давая Helix ощущение временного контекста и позволяя ему действовать более стратегически при выполнении многошаговых манипуляций. Отслеживание истории недавних состояний позволяет роботу осуществлять более быстрое и реактивное управление. В результате ускоряется реакция на неожиданности и помехи: если пакет смещается или попытка захвата оказывается неудачной, Helix корректирует движение «на лету». Это значительно сократило время обработки каждого пакета. 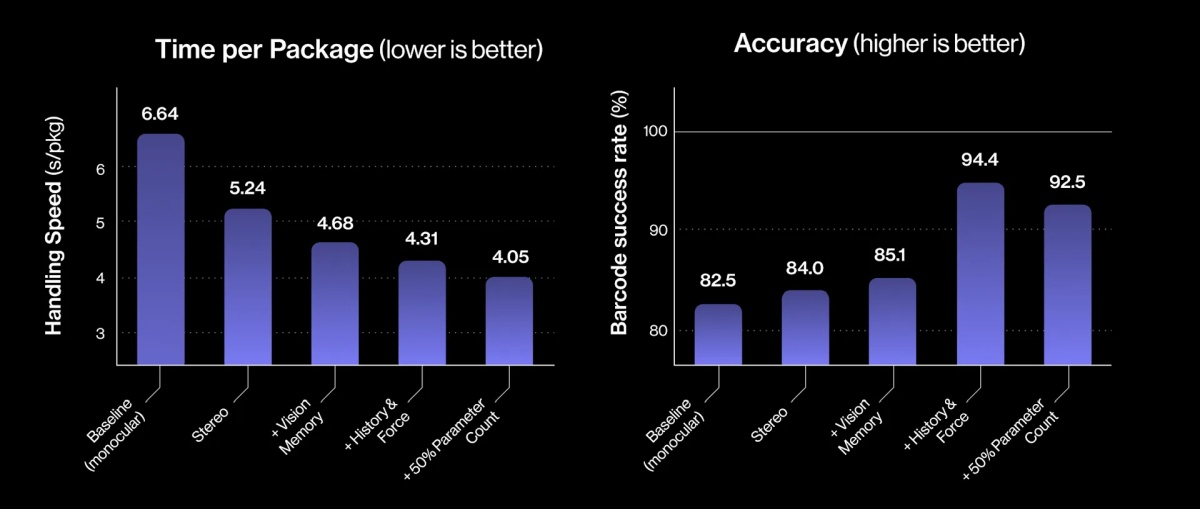 Helix использует аналог человеческого осязания благодаря интегрированной обратной связи по усилию. Робот способен определить момент соприкосновения с объектом и использовать это для модуляции движения, например, приостанавливая опускание при контакте с конвейерной лентой. Хотя основной задачей Helix в логистическом сценарии является автономная сортировка, он легко адаптируется к новым взаимодействиям. Например, протянутая к нему рука человека интерпретируется как сигнал к передаче предмета: робот отдаёт посылку, а не размещает её на конвейере — подобное поведение заранее явно не программировалось, система самостоятельно обучилась ему.  «Helix неуклонно масштабируется в плане ловкости и надёжности, сокращая разрыв между освоенными роботизированными манипуляциями и требованиями реальных задач. Мы продолжим расширять набор навыков и обеспечивать стабильность на ещё больших скоростях и рабочих нагрузках», — заявил представитель Figure. В реальности всё далеко не так радужно, как описывают маркетологи Figure — по следующим ссылкам можно увидеть, что робот совершает много ошибок, путается, роняет посылки и порой откровенно зависает. Так что какое-то время «кожаные мешки» на этой работе ещё будут востребованы. Но, учитывая нынешние темпы развития робототехники и бум искусственного интеллекта, почтовым служащим пора подумать о смене профессии. Человекоподобные роботы Boston Dynamics Atlas получат «зрение» от LG
13.05.2025 [09:49],
Алексей Разин
Многие участники рынка компонентов для смартфонов не против добавить своему бизнесу динамики за счёт переключения на более активно растущие направления. LG Innotek в этом смысле рассчитывает на контракты с производителем человекоподобных роботов Boston Dynamics, которые обретут систему зрения на основе компонентов этого поставщика. 
Источник изображения: Boston Dynamics О достигнутой между компаниями договорённости сообщает издание Business Korea. Речь идёт о следующем поколении человекоподобных роботов Atlas американской компании Boston Dynamics, которая принадлежит корейскому холдингу Hyundai Motor Group. С последним у LG Innotek уже сложились взаимовыгодные отношения, поскольку последняя из компаний снабжает автопроизводителя светотехникой для транспортных средств и прочими электронными системами. LG Innotek и Boston Dynamics будут совместно разрабатывать систему машинного зрения для человекоподобных роботов Atlas следующего поколения. Первая будет отвечать за поставку датчиков камер, позволяющих чётко определять взаимное расположение снимаемых объектов даже в условиях ограниченной видимости, а вторая займётся разработкой сопутствующего программного обеспечения. Если учесть, что Hyundai намеревается десятками тысяч использовать роботов Boston Dynamics на своих автосборочных предприятиях, то соответствующий контракт с LG Innotek обещает быть выгодным. От Intel отделился производитель систем машинного зрения RealSense
13.01.2025 [17:47],
Сергей Сурабекянц
В первой половине 2025 года Intel выделит инновационного производителя систем машинного зрения RealSense в независимую компанию, после чего она войдёт в инвестиционный портфель Intel Capital. Новая компания продолжит разрабатывать решения для компьютерного зрения на базе ИИ и представлять текущее портфолио Intel RealSense, включая камеры глубины RealSense, решения для аутентификации лиц, автономные мобильные роботизированные решения и приборы физиотерапии. 
Источник изображений: Intel RealSense Intel утверждает, что выделение RealSense не является результатом недавних финансовых трудностей компании: «Мы верим в ценность RealSense и уверены в её успехе как самостоятельной компании. Это решение соответствует нашей текущей трансформации и поможет нам в дальнейшем соответствовать нашей стратегической цели — сосредоточиться на наших основных видах деятельности». Новая компания продолжит разрабатывать решения для компьютерного зрения на базе ИИ и представлять текущее портфолио Intel RealSense, включая камеры глубины RealSense, решения для аутентификации лиц, автономные мобильные роботизированные решения и приборы для физиотерапии. Также RealSense планирует расширить свою дорожную карту, добавив инновации в области стереозрения, робототехники, биометрического программного обеспечения и оборудования ИИ.  RealSense всегда была небольшой частью бизнеса Intel. Безусловно, благодаря работе в экосистеме технологического гиганта, компания гарантировала себе финансовую стабильность, возможность серьёзной научной деятельности и доступ к обширным ресурсам Intel, в том числе к масштабной сети отраслевых партнёров. Intel начала производить решения для компьютерного зрения в рамках своего подразделения Perceptual Computing в 2013 году. В 2014 году это подразделение было переименовано в Intel RealSense. Камеры машинного зрения Intel RealSense являются популярным выбором для разработчиков мобильных и промышленных роботов. К примеру, четвероногий робот ANYmal от ANYbotics оснащён шестью модулями Intel RealSense D435, которые работают вместе, создавая карту высот, помогающую роботу перемещаться по участку и преодолевать препятствия, включая подъем по лестнице.  Это далеко не первый случай резкого изменения политики Intel. Ранее, в августе 2021 года, Intel уже объявляла о закрытии RealSense, однако затем сменила курс, решив сохранить RealSense, но с сокращённым составом. В 2022 году Intel избавилась от компании-разработчика автономных транспортных средств Mobileye, которую приобрела в 2017 году за $15,3 млрд. «Intel инкубирует передовые, прорывные технологии и бизнесы для проверки потребностей клиентов и принятия рынком. На определённом уровне масштаба для этих бизнесов имеет смысл работать за пределами Intel, с гибкостью, чтобы работать так, как требует рынок, и возможностью инвестировать в ключевые области роста. Это позволяет отделению быстрее принимать решения, иметь большую гибкость решений для клиентов и оставаться гибким на конкурентных рынках» , — заявил представитель Intel. С выделением RealSense в отдельную компанию история этого подразделения принимает ещё один неожиданный поворот. Конечно, RealSense освобождается от приоритетов реструктуризации Intel, но независимость, безусловно, принесёт новые проблемы. Лампа накаливания снова в деле — физики увидели в ней основу мультиспектрального машинного зрения
25.12.2024 [18:46],
Геннадий Детинич
Учёные из Университета штата Мичиган стряхнули пыль с ламп накаливания, увидев в них основу для мультиспектрального машинного зрения. В природе свет несёт гораздо больше информации об окружающих объектах и процессах, чем видит глаз человека. Поэтому машинное зрение не должно уподобляться зрению людей. Оно должно быть шире и глубже воспринимать мир, делая среду обитания для человека безопаснее и комфортнее. 
Источник изображения: Brenda Ahearn/Michigan Engineering Солнечный свет не имеет поляризации, он может приобретать её, например, при отражении. Отражение от поверхности воды, например, приобретает линейную поляризацию, что делает поляризованный свет ярче и опаснее для зрения. Солнечные очки с поляризационными стёклами легко компенсируют такие явления. Полезное свойство поляризации заключается в возможности уплотнить канал передачи в оптоволокне. Для этого используют круговую поляризацию. В природе насекомые и некоторые ракообразные видят поляризованный свет, что делает их лучшими собирателями или охотниками. Очевидно, что робототехника и ряд направлений в науке выиграют, если устройства смогут распознавать свет в расширенном спектре, включая разные виды поляризации. Исследователи из Университета Мичигана создали наномасштабный прибор из вольфрамовой нити накаливания, который способен испускать свет с эллиптической поляризацией. Такое явление стало возможным после того, как нить накала изготовили такой длины, которая сравнима с длиной волны света. Эллиптическая поляризация — это предельный случай как круговой, так и линейной поляризации, но он может использоваться как самостоятельный для тех же целей уплотнения трафика в одном и том же оптическом кабеле. В случае машинного зрения использование эллиптической поляризации позволяет повысить контраст изображения, что необходимо для распознавания в тёмное время суток или при плохом освещении. Наконец, благодаря эллиптической поляризации может появиться множество медицинских приборов, которые помогут с визуализацией образцов тканей человека, а также при проведении анализов. В России роботов-собак натравят на нарушителей техники безопасности на стройках и производстве
05.12.2024 [17:51],
Павел Котов
Российская компания VisionLabs и «Лаборатория Новых Продуктов» представила робота-собаку с системой машинного зрения и интеллектуальной видеоаналитики — он способен наблюдать за производственным процессом и следить за соблюдением работниками требований техники безопасности, сообщает «Хабр». 
Источник изображения: habr.com Четвероногого робота система компьютерного зрения VisionLabs LUNA, которая в реальном времени фиксирует нарушения техники безопасности, в том числе наличие или отсутствие средств индивидуальной защиты, а также присутствие посторонних на промышленном объекте. Система также идентифицирует заданные сценарии: драки, падение человека, утерянные вещи, а также присутствие человека в опасной зоне. Спутниковая навигация, лидар и автономная система управления позволяют робособаке патрулировать объекты любой сложности, передвигаясь по определённому маршруту — при необходимости оператор может перехватывать управление. Защищённый водо- и пылеустойчивый корпус позволяет машине работать в условиях агрессивной среды. Поддержка автономной навигации означает, что робособака может эксплуатироваться на объектах, где невозможна установка традиционных камер наблюдения. Система компьютерного зрения VisionLabs отличается высокой точностью: отсутствие защитного шлема на человеке она определяет с точностью 99,2 %, жилета — 97,0 %, перчаток — 92,1 %. Обнаружив нарушение, робот докладывает о нём в диспетчерскую, а дежурный может оперативно связаться с сотрудником и попросить это нарушение устранить. На практике система способна снизить число несчастных случаев на объекте, повысить уровень дисциплины и уменьшить нагрузку на службу безопасности. К роботу можно подключить и дополнительные датчики, которые помогут инспектировать состояние оборудования: определять его целостность, измерять температуру и уровень вибрации, снимать показания приборов, а также обнаруживать тепло- и газоутечки. |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



