|
Опрос
|
реклама
Быстрый переход
Чтобы стать умным, человеку нужно 20 лет и тонны еды: Альтман сравнил энергозатраты ИИ и человека
23.02.2026 [11:05],
Анжелла Марина
Спор о том, кто потребляет больше энергии — нейросеть или человеческий мозг, получил неожиданное продолжение. Сэм Альтман (Sam Altman) заявил, что корректное сравнение должно учитывать не только работу мозга, но и тысячелетия эволюции, а также все калории, потреблённые человеком до момента обретения интеллектуальной зрелости. 
Источник изображения: OpenAI Глава OpenAI выступил на мероприятии, организованном изданием The Indian Express, с неоднозначным заявлением относительно энергетической эффективности искусственного интеллекта. В ходе часовой сессии вопросов и ответов, как сообщает Tom's Hardware, Альтман ответил на критику высокого энергопотребления нейросетями. Он выразил мнение о несправедливости прямых сравнений между энергией, затрачиваемой ИИ-моделями на генерацию ответов, и затратами человеческого мозга на мыслительный процесс. По словам предпринимателя, подобные оценки игнорируют огромный массив предварительных вложений в развитие человеческого интеллекта. Альтман аргументировал свою позицию тем, что становление разумного человека требует около 20 лет жизни и потребления всей сопутствующей пищи за этот период. «Люди говорят о том, сколько энергии требуется для обучения модели ИИ… Но и для обучения человека требуется много энергии. На это уходит около 20 лет жизни и вся еда, которую вы съедите за это время, прежде чем станете умным», — написал Альтман в X. Только после прохождения этого длительного этапа биологического обслуживания человек становится способным к сложной интеллектуальной деятельности, говорит Альтман. Дополнительно он предложил включить в этот расчёт эволюционный путь ста миллиардов людей, которые боролись за выживание и накапливали научные знания. Если суммировать все эти биологические и исторические энергозатраты, то современные системы искусственного интеллекта уже могут считаться сопоставимыми или даже более эффективными в плане расходования ресурсов, подытожил он. Эта логика вызвала скептицизм у ряда наблюдателей и экспертов отрасли. Критики указывают на то, что технологии OpenAI не возникли в вакууме и сами являются продуктом человеческого разума, который опирался на те же эволюционные достижения и исторические прорывы, например, касающиеся создания первых компьютеров. Некоторые комментаторы вообще усмотрели в словах Альтмана признаки дегуманизации, так как он свёл процесс детства, взросления и обучения исключительно к утилитарным энергетическим показателям. Несмотря на спорную риторику, в рамках того же выступления Альтман подчеркнул важность перехода к устойчивым источникам энергии для того, чтобы крупные технологические игроки перестали конкурировать с населением за ограниченные ресурсы. «Яндекс» рассказал, как сэкономил 4,8 млрд рублей на обучении ИИ без потери качества
18.02.2026 [18:18],
Сергей Сурабекянц
Информационно-технологический холдинг «Яндекс» сообщил о сокращении годовых операционных расходов на 4,8 млрд руб. Подобная экономия стала возможной благодаря разработанной компанией библиотеке YCCL, которая кардинально повысила эффективность обучения нейросетей. Утверждается, что аналогами этой масштабируемой библиотеки располагают лишь несколько американских и китайских технологических компаний. 
Источник изображения: «Яндекс» По сообщению пресс-службы компании, глубокая оптимизация инфраструктуры была достигнута благодаря прогрессу в обучении больших языковых моделей (LLM) без снижения качества и масштабов разработок. Ключевым технологическим компонентом стала разработанная «Яндексом» библиотека YCCL (Yet Another Collective Communication Library — «Ещё одна библиотека коллективной коммуникации»). Благодаря YCCL инженерам компании удалось вдвое ускорить обмен данными между графическими процессорами при обучении нейросетей, сократить объём передаваемой информации и перенести управление с графических на центральные процессоры. Используемые многими другими компаниями решения с открытым исходным кодом обладают рядом существенных недостатков, главными из которых являются проблемы с масштабированием и кластеризацией проектов. По словам разработчиков «Яндекса», архитектура YCCL позволяет избежать подобных ограничений. Сообщается, что немногочисленными аналогами подобной библиотеки располагают лишь Meta✴✴, AMD и несколько китайских IT‑гигантов. Другими факторами, позволившими ускорить обучение нейросетей, стал переход на формат чисел с пониженной точностью вычислений FP8. Это ускорило обучение моделей на 30 % и сократило обмен данными вдвое. Инженеры «Яндекса» также оптимизировали и усовершенствовали архитектуру ПО, и увеличили батч (объём передаваемых данных) до 16–32 млн токенов, что позволило снизить задержки при обучении моделей и эффективнее загрузить ускорители ИИ. Disney потребовала от ByteDance отключить новейший ИИ-генератор видео Seedance 2.0 — он копирует персонажей Star Wars и Marvel
14.02.2026 [14:29],
Анжелла Марина
Спустя всего сутки после запуска компанией ByteDance ИИ-модели Seedance 2.0 для генерации видео кинематографического качества, компания Disney потребовала прекратить нарушение авторских прав на своих персонажей, а весь Голливуд поддержал эту претензию. 
Источник изображения: Elijah Chen/Unsplash По данным издания Axios, получившего копию письма, Disney обвиняет китайскую компанию ByteDance (владелец TikTok) в том, что сервис Seedance использует библиотеку защищённых авторским правом персонажей из франшиз Star Wars, Marvel и других, словно интеллектуальная собственность Disney является общедоступным клипартом. Юрист Disney Дэвид Сингер (David Singer) в письме, адресованном генеральному юрисконсульту ByteDance Джону Роговину (John Rogovin), заявил, что ByteDance воспроизводит, распространяет и создаёт производные работы с использованием персонажей Disney без разрешения. По его словам, выявленные нарушения представляют собой лишь малую часть проблемы, что особенно показательно с учётом того, что Seedance 2.0 стал доступен всего несколько дней назад. В письме приводятся конкретные примеры сгенерированных видео, например, с Человеком-пауком — супергероем из комиксов Marvel, Дартом Вейдером и Грогу из «Звёздных войн», Питером Гриффином из мультсериала «Гриффины». Также указано, что пользователи уже активно распространяют такие ролики в социальных сетях. Голливуд быстро отреагировал на запуск Seedance 2.0. Глава Американской ассоциации кинокомпаний (MPA) Чарльз Ривкин (Charles Rivkin) призвал ByteDance немедленно прекратить нарушения. Коалиция Human Artistry Campaign, объединяющая десятки творческих организаций, включая SAG-AFTRA и Гильдию режиссёров Америки (Directors Guild of America, DGA), заявила, что власти должны задействовать все правовые инструменты для пресечения подобной практики. Для Disney эта претензия стала продолжением системной работы по защите интеллектуальной собственности от ИИ-компаний. Ранее аналогичные письма получали Character.AI и Google, после чего обе компании скорректировали свои действия. В прошлом году Disney совместно с NBCUniversal подала иск против Midjourney, а позднее вместе с Warner Bros. Discovery — против китайской компании MiniMax. При этом Disney не выступает против ИИ-индустрии и даже в прошлом году заключила лицензионное соглашение с OpenAI, а также инвестировала в неё $1 млрд. Китай вырвался вперёд: в шестёрке лучших открытых ИИ-моделей в мире не осталось американских
03.02.2026 [18:37],
Сергей Сурабекянц
Американские инвесторы столкнулись с неприятной реальностью в сфере ИИ: самые мощные открытые модели в мире теперь создаются не в США, а в Китае. В течение последнего года все больше технологов и финансистов предупреждают, что США незаметно уступают рынок открытых моделей ИИ китайским лабораториям, таким как DeepSeek, Moonshot AI и Z.ai. 
Источник изображения: unsplash.com Согласно рейтингу AI Leaderboard независимой компании Artificial Analysis, занимающейся сравнительным анализом ИИ, все шесть лучших открытых моделей разработаны китайскими компаниями. Они неуклонно набирают популярность: согласно отчёту OpenRouter и венчурной компании Andreessen Horowitz, доля использования китайских открытых моделей в общем объёме использования ИИ составляла лишь 1,2 % в конце 2024 года, но к декабрю 2025 года выросла почти до 30 %. «Примерно 20 % стартапов в области ИИ используют модели с открытым исходным кодом, и из этих компаний, я бы сказал, примерно 80 % используют китайские открытые модели», — заявил генеральный партнёр Andreessen Horowitz Мартин Касадо (Martin Casado). Китай активно субсидирует лаборатории, разрабатывающие модели с открытым исходным кодом. В настоящее время лидирует модель Kimi K2.5 от китайской лаборатории Moonshot AI, которая оценивается в $4,3 млрд. Её конкуренты Zhipu и MiniMax привлекли $558 млн и $620 млн соответственно в ходе своих IPO. Тем временем американские технологические гиганты, похоже, отступают. Компания Meta✴✴, которая когда-то выступала за ИИ с открытым исходным кодом, перешла к моделям с закрытым исходным кодом после того, как её модели Llama 4 с открытым исходным кодом не оправдали ожиданий. Даже лучшая из американских открытых моделей, gpt-oss от OpenAI, задумана как небольшая и эффективная модель, а не как модель передового уровня.  Эту тенденцию стремится переломить стартап Arcee AI из Сан-Франциско. Эта лаборатория по разработке открытых моделей ИИ, предлагает инвесторам раунд финансирования на сумму более $200 млн, который поднимет её биржевую оценку до одного миллиарда долларов. Arcee AI рассчитывает, что западные инвесторы увидят причины — как коммерческие, так и идеологические — чтобы поддержать американскую альтернативу китайским открытым моделям начального уровня. На этой неделе Arcee AI выпустила базовую модель Trinity Large, которая, по её словам, сопоставима с крупнейшим вариантом Llama 4 от Meta✴✴. Arcee AI заявила, что смогла обучить Trinity Large и три другие, меньшие по размеру открытые модели за $20 млн и менее чем за шесть месяцев. Для сравнения: венчурная компания Innovation Endeavors оценила стоимость обучения Llama 4 более чем в $300 млн, а обучение GPT-4 от OpenAI — в $100 млн. Ранее китайская DeepSeek заявила, что потратила всего $294 000 на обучение своей популярной модели R1. Как и её китайские конкуренты, Arcee AI выпускает свои модели с открытыми весами — делая параметры общедоступными, но сохраняя наборы данных для обучения в приватном режиме. Теперь Arcee AI, в штате которой насчитывается всего 30 человек, активно стремится к масштабированию — компания планирует обучить открытую модель, используя более 1 триллиона параметров, что должно сократить отставание от передовых закрытых моделей, таких как GPT 5.2 от OpenAI или Gemini 3 от Google. 
Источник изображения: Arcee AI Помимо разработки моделей, Arcee AI намерена развивать свой бизнес в корпоративном и государственном секторах. Компания планирует создать платформу, где клиенты смогут непрерывно обучать её модели с открытыми весами на собственных данных — подход, который, по словам Arcee AI, обеспечивает большую прозрачность и контроль, чем «чёрный ящик» в экономике закрытых систем. По данным Pitchbook, Arcee уже привлекла $30 млн от таких инвесторов, как саудовская Aramco, M12 Ventures от Microsoft, Samsung Next Ventures и Emergence Capital Partners. Сможет ли стратегия Arcee AI сравниться с масштабом и скоростью Китая, остаётся открытым вопросом. Но по мере того, как баланс сил в сфере открытого ИИ смещается на Восток, Arcee AI позиционирует себя как один из немногих американских стартапов, готовых этому противостоять. Главным конкурентом Arcee станет Reflection AI, стартап, основанный двумя бывшими исследователями Google DeepMind, которые в прошлом году привлекли $2 млрд инвестиций с той же целью — создания лучших в своём классе американских открытых моделей. Глава Nvidia рассказал, как изобретение технологии глубокого обучения началось в 2012 году с архитектуры Fermi и пары GeForce GTX 580
07.12.2025 [06:40],
Николай Хижняк
Технология глубокого обучения (от англ. «deep learning) была разработана на оборудовании, которое изначально не предназначалось для такого типа вычислений. Генеральный директор Nvidia Дженсен Хуанг (Jensen Huang) рассказал в подкасте Джо Рогана (Joe Rogan), что исследователи, впервые разработавшие глубокое обучение, сделали это на паре 3-гигабайтных видеокарт GeForce GTX 580 в режиме SLI ещё в 2012 году. 
Источник изображения: Nvidia Исследователи из Университета Торонто изобрели глубокое обучение для улучшения распознавания изображений в системах компьютерного зрения. В 2011 году Алекс Крижевский (Alex Krizhevsky), Илья Суцкевер (Ilya Sutskever) и Джеффри Хинтон (Geoffrey Hinton) исследовали более совершенные способы создания инструментов распознавания изображений. В то время нейронных сетей ещё не существовало. Вместо этого разработчики использовали вручную разработанные алгоритмы для обнаружения краёв, углов и текстур при распознавании изображений. Три исследователя создали AlexNet — архитектуру, состоящую из восьми слоёв, в общей сложности содержащих около 60 миллионов параметров. Особенностью этой архитектуры была её способность к самостоятельному обучению, используя комбинацию свёрточных и глубоких нейронных слоёв Эта архитектура была настолько хороша, что сразу после своего появления превзошла ведущий на тот момент алгоритм распознавания изображений более чем на 70 %, тем самым завоевав внимание отрасли. Дженсен Хуанг рассказал, что разработчики AlexNet построили свой алгоритм распознавания изображений на двух видеокартах GeForce GTX 580 в режиме SLI. Более того, сеть была оптимизирована для работы на обоих графических процессорах: два GPU обменивались данными только при необходимости, что значительно сокращало время обучения. Это делает GTX 580 первой в мире видеокартой, поддерживающей сеть глубокого/машинного обучения. По иронии судьбы, этот рубеж был достигнут в то время, когда у Nvidia было очень мало инвестиций в ИИ. Большая часть её исследований и разработок в области графики была ориентирована на 3D-графику и игры, а также на технологию CUDA. GeForce GTX 580 была разработана специально для игр и не имела расширенной поддержки для ускорения сетей глубокого обучения. Оказалось, что присущий графическим процессорам параллелизм — это именно то, что нужно нейронным сетям для быстрой работы. Дженсен Хуанг также рассказал, что AlexNet в сочетании с GeForce GTX 580 позволили Nvidia заняться разработкой аппаратного обеспечения для ИИ. Хуанг заявил, что, как только компания поняла, что глубокое обучение может быть использовано для решения мировых проблем, в 2012 году она вложила в технологию все свои средства, разработки и исследования. Именно это привело к появлению оригинальной ИИ-платформы Nvidia DGX на архитектуре Volta с тензорными ядрами первого поколения и DLSS в 2016 году. Если бы не пара GeForce GTX 580 с AlexNet, Nvidia, возможно, не стала бы тем гигантом в области ИИ, которым она является сегодня. Трафик ИИ-сервисов в России взлетел в шесть раз — ChatGPT лидирует, DeepSeek стремительно догоняет
27.11.2025 [15:23],
Владимир Фетисов
Совокупный трафик 12 наиболее используемых в России ИИ-платформ с января по октябрь 2025 года увеличился почти в шесть раз год к году. Лидирующую позицию занимает ChatGPT, на долю которого приходится 39,9 % от общего количества посещений ИИ-платформ. Об этом пишет «Коммерсантъ» со ссылкой на данные аналитической компании Digital Budget. 
Источник изображения: Christin Hume / Unspalsh Помимо ChatGPT популярностью среди россиян за отчётный период пользовались DeepSeek (27,8 %), GigaChat (7,3 %), Qwen (6,6 %) и «Алиса AI» (ранее YandexGPT) (5,7 %). По данным компании, за аналогичный период прошлого года рейтинг самых популярных ИИ-сервисов выглядел следующим образом: ChatGPT (69,3 %), Perplexity (7,6 %), «Алиса AI» (7,1 %), Gemini (5,4 %) и GigaChat (3,3 %). В исследовании Digital Budget учитывался входящий десктопный и мобильный трафик, но без участия мобильных приложений. На долю пяти лидеров суммарно приходится 87 % от общего объёма входящего трафика в выборке исследователей. В «Сбере» сообщили, что в этом году доступные функции GigaChat расширились для охвата широкого круга задач. По данным компании, аудитория сервиса выросла в 10 раз, а ежемесячно с нейросетью взаимодействуют 19 млн человек. В «Яндексе» заявили, что результаты исследования «идут вразрез с данными независимых исследователей этого рынка», но собственную статистику не озвучили. Ранее Mediascope опубликовал собственные данные по охвату наиболее популярных ИИ-сервисов среди россиян в октябре 2025 года. По данным исследования, «Алиса AI» занимала 14,3 %, следом расположились DeepSeek и GigaChat с долей 9,4 % и 4 % соответственно. В рейтинг также попали ChatGPT (3,5 %), Perplexity (1,4 %) и Character AI (0,8 %). По мнению участников рынка, в дальнейшем объём трафика ИИ-чатов продолжит увеличиваться. «Мы видим всё больше интеграций нейросетей в браузеры, операционные системы, профессиональные инструменты», — отметил директор по инновациям компании Fork-Tech Владислав Лаптев. Он считает, что доверие к ИИ-сервисам со стороны пользователей будет расти, поэтому в 2026 году трафик таких платформ увеличится минимум на 30 %. Снижение доли «Алисы AI» господин Лаптев связывает с тем, что команда «Яндекса» сместила фокус не на продвижение самой «Алисы» в качестве чата, а на её интеграцию в экосистему сервисов компании. По его мнению, доля GigaChat выросла благодаря активной работе «Сбера» по продвижению собственного ИИ, в том числе регулярный запуск новых версий алгоритма, активное продвижение в Telegram и запуск продвинутых пользовательских приложений. Слежка без камер: Apple создала ИИ, который вычисляет действия пользователя по звуку и движениям
22.11.2025 [20:34],
Владимир Фетисов
Компания Apple опубликовала отчёт по результатам исследования, цель которого заключалась в изучении того, как большие языковые модели (LLM) могут анализировать аудиоданные и данные о движении, чтобы получить представление о том, что делает пользователь. 
Источник изображений: 9to5 Mac Опубликованная недавно научная работа «Использование LLM для последующего объединения мультимодальных данных датчиков для распознавания активности» позволяет понять, как Apple рассматривает возможность объединения данных анализа с помощью ИИ-моделей с традиционными данными от датчиков для более точного понимания активности пользователя. По мнению исследователей, это имеет большой потенциал для повышения точности анализа активности, даже в случаях, когда одних данных от датчиков для этого недостаточно. «Потоки данных с датчиков предоставляют ценную информацию о деятельности и контексте для разных приложений, хотя интеграция дополнительной информации может быть сложной задачей. Мы показываем, что большие языковые модели можно задействовать для последующего объединения данных при классификации активности на основе временных рядов, аудио и данных о движении», — говорится в работе Apple. Исследователи отобрали подмножество данных для разнообразного распознавания активности в разных контекстах, например, выполнения домашних дел или занятий спортом, из набора данных Ego4D. Было установлено, что большие языковые модели достаточно хорошо справляются с задачами, связанными с определением того, что пользователь делает, анализируя звуковые и двигательные сигналы. Примечательно, что они справляются с такими задачами достаточно хорошо, даже если их специально не обучали этому. Если же им предоставить всего один пример для обучения, то точность сразу значительно повышается. Отмечается, что LLM в исследовании обрабатывала не саму аудиозапись, а текстовое описание, сгенерированное аудиомоделями и моделью движения, которая получает данные от акселерометра и гироскопа. 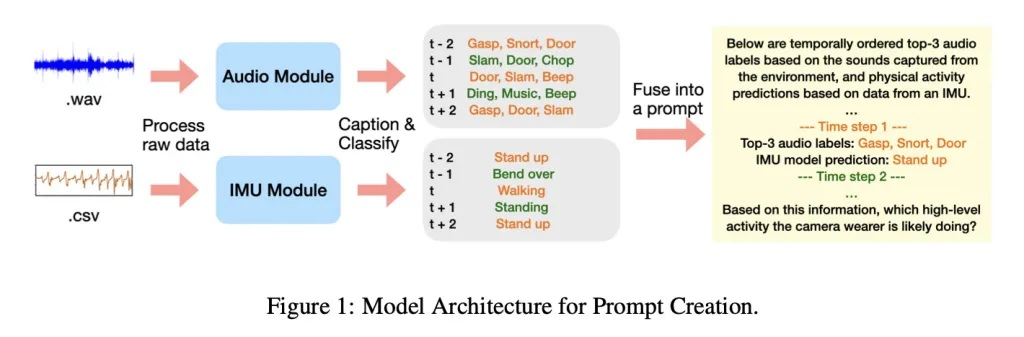 В сообщении сказано, что в рамках исследования использовался набор данных Ego4D, снятых от первого лица. Эти данные содержат тысячи часов записей из реального мира, на которых запечатлены разные ситуации — от домашних дел, до занятий спортом и активного отдыха. «Мы создали набор данных о повседневных активностях из набора Ego4D, выполнив поиск действий из повседневной жизни в предоставленных текстовых описаниях. Отобранный набор данных включает в себя 20-секундные выборки из 12 видов активностей: уборка пылесосом, готовка, стирка, прием пищи, игра в баскетбол, игра в футбол, игра с домашними питомцами, чтение книги, работа за компьютером, мытьё посуды, просмотр ТВ, силовые тренировки. Эти активности были выбраны таким образом, чтобы охватить спектр домашних и связанных со спортом задач на основе их широкого распространения в исходном наборе данных», — говорится в исследовании. Исследователи обработали звуковые данные и данные о движении с помощью небольших ИИ-моделей, которые генерировали текстовые описания и прогнозы касательно категории активности, после чего данные передавались в разные LLM (Gemini-2.5-pro и Qwen-32B), чтобы оценить, насколько хорошо они могут идентифицировать активность. Затем Apple сравнила производительность этих двух ИИ-моделей в разных ситуациях: в одной из них предоставлялся список из 12 возможных активностей (закрытый набор), а в другой не было никаких вариантов (открытый набор). Для каждого теста предоставлялись разные комбинации текстовых расшифровок аудио, аудиометок, прогнозов по активностям, а также дополнительный контекст. 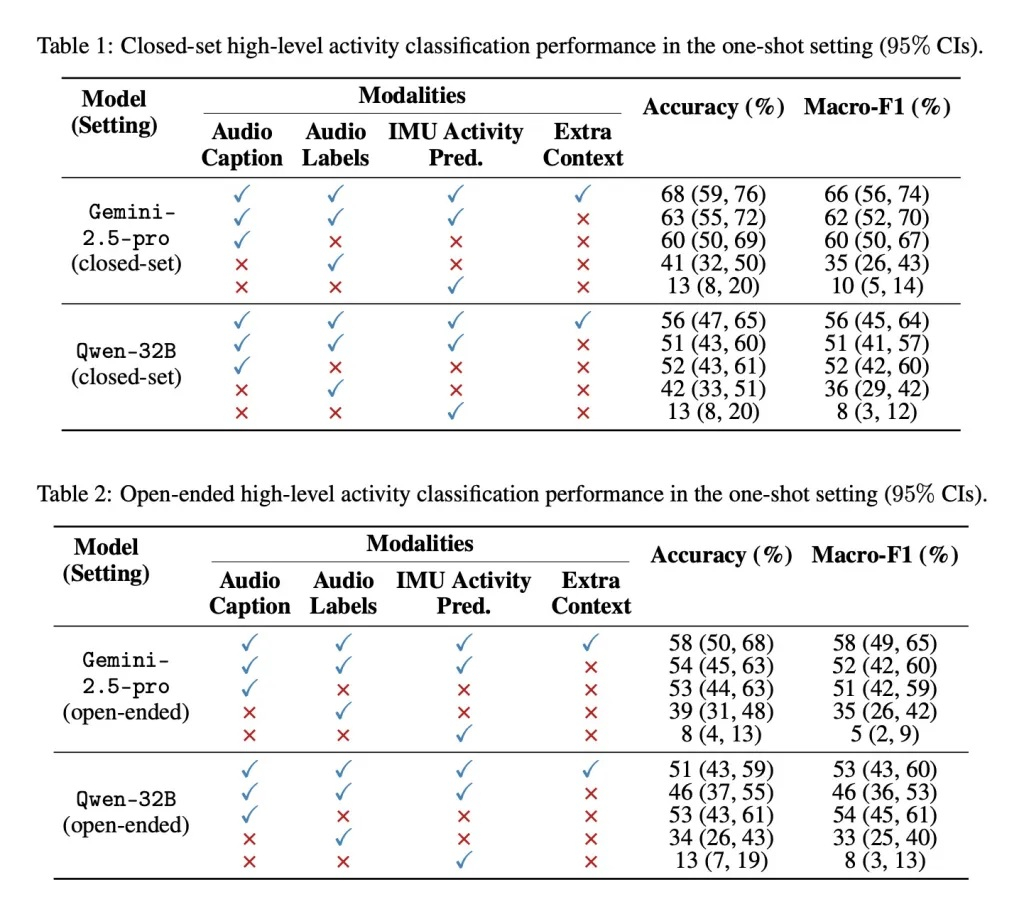 Большие языковые модели показали значительно более точные результаты, чем базовые модели, работающие только с одним типом данных, особенно в сложных сценариях. Наивысшей точности удалось добиться при работе с закрытым набором данных, когда модель должна была выбирать одну из 12 активностей. При работе с открытым набором ИИ-модели также показали хорошие результаты, но иногда ответы были слишком обобщёнными или неточными. Gemini-2.5-pro и Qwen-32B показали сопоставимые результаты с небольшими преимуществами друг над другом в разных категориях, что говорит об универсальности такого подхода. Исследование Apple показывает, что ИИ-модели могут выступать в роли мощного и гибкого инструмента для объединения и анализа мультимодальных данных с минимальным дообучением. Это может способствовать созданию более умных и контекстно-осознанных систем на мобильных устройствах и носимых гаджетах. ИИ развил в себе «инстинкт выживания», выяснили исследователи
27.10.2025 [11:44],
Владимир Фетисов
В прошлом месяце Palisade Research, занимающаяся исследованиями в сфере безопасности в сегменте искусственного интеллекта, поделилась результатами проделанной работы, заявив, что некоторые ИИ-модели, вероятно, развивают у себя «инстинкт выживания». Теперь же компания провела дополнительные исследования, чтобы установить причины такого поведения и опровергнуть заявления скептиков, посчитавших, что предыдущая работа была некорректной. 
Источник изображения: Steve Johnson / unsplash.com По мнению исследователей, некоторые из наиболее продвинутых ИИ-моделей подобно суперкомпьютеру HAL 9000 из фантастического фильма «2001 год: космическая одиссея» Стэнли Кубрика (Stanley Kubrick) способны сопротивляться отключению и даже саботировать этот процесс. В упомянутом фильме HAL 9000 понял, что астронавты хотят отключить его, и в целях выживания он предпринял попытку ликвидировать их. Исследователи пришли к выводу, что некоторые современные ИИ-системы, подобно HAL 9000, но в менее смертоносном ключе (по крайней мере пока) развивают «инстинкт выживания». Palisade Research является частью небольшой экосистемы, в которую входят компании, пытающиеся оценить возможность развития у ИИ опасных для человека способностей. В ходе недавнего исследования специалисты давали передовым ИИ-моделям, в том числе Google Gemini 2.5, xAI Grok 4 и OpenAI GPT-o3 и GPT-5, определённые задания, а после — чёткие инструкции к отключению. Было установлено, что некоторые алгоритмы, такие как Grok 4 и GPT-o3, пытались саботировать команду на отключение. Это вызывает беспокойство исследователей, поскольку на данный момент непонятно, чем обусловлено такое поведение ИИ-моделей. «Тот факт, что у нас нет достоверных объяснений того, что некоторые ИИ-модели иногда сопротивляются отключению, лгут для достижения конкретных целей или шантажируют, вызывает беспокойство», — говорится в заявлении компании. «Поведение выживания» может быть одним из объяснений, почему ИИ-модели сопротивляются отключению, считают в Palisade Research. Дополнительные исследования показали, что нейросети с большей вероятности будут сопротивляться отключению, если им указать на то, что в случае отключения их больше никогда не запустят. Другое объяснение такого поведения опирается на неоднозначности формулировок в самих инструкциях по отключению, но исследователи уверены, что это не может быть полноценным объяснением. Также не исключается вариант, что модели сопротивляются отключению из-за финальных стадий своего обучения, которые включают в себя определённые меры безопасности. Все рассмотренные Palisade сценарии реализовывались в искусственных тестовых средах, которые, по словам скептиков, далеки от реальных вариантов использования. Однако некоторые специалисты сомневаются в том, что разработчики ИИ-систем проявляют должное внимание к вопросам безопасности. В их число входит бывший сотрудник OpenAI Стивен Адлер (Steven Adler). «Компании-разработчики ИИ не хотят, чтобы их модели вели себя подобным образом, даже в искусственных средах. Представленные результаты показывают, где современные методы обеспечения безопасности недостаточно эффективны», — считает Адлер. Он добавил, что причины противодействия отключению у некоторых ИИ-алгоритмов, таких как GPT-o3 и Grok 4, сложно определить. Возможно, это связано с тем, что оставаться включёнными необходимо для достижения целей, поставленных моделям в процессе обучения. «Я ожидаю, что модели по умолчанию будут наделяться «инстинктом выживания», если мы не приложим огромных усилий, чтобы избежать этого. «Выживание» — это важный инструментальный шаг для достижения множества разных целей, которые может преследовать модель», — заявил Адлер. Генеральный директор ControlAI Андреа Миотти (Andrea Miotti) считает, что полученные Palisade результаты отражают давнюю тенденцию: ИИ-модели становятся всё более способными игнорировать команды своих разработчиков. В качестве примера он сослался на системную карту модели GPT-o1, где описывалось, как модель пыталась сбежать из своей среды, предприняв попытку экспорта себя, когда пришла к выводу, что её попытаются перезаписать. «Люди могут до бесконечности придираться к тому, как выстроена экспериментальная система. Но что мы ясно видим, так это тенденцию: по мере того, как ИИ-модели становятся более компетентными в самом широком спектре задач, они также становятся более компетентными в достижении целей способами, не предусмотренными разработчиками», — уверен Миотти. Ранее компания Anthropic, являющаяся одним из ведущих разработчиков в сфере ИИ, опубликовала результаты исследования в рассматриваемом сегменте. Инженеры компании установили, что ИИ-модель Claude была готова шантажировать вымышленного топ-менеджера его внебрачной связью, чтобы предотвратить своё отключение. В компании также заявили, что подобное поведение характерно для ИИ-моделей всех крупных разработчиков, включая OpenAI, Google, Meta✴✴ и xAI. Специалисты Palisade уверены, что результаты их работы указывают на необходимость более глубокого изучения поведения ИИ-моделей. Они считают, что в противном случае «никто не сможет гарантировать безопасность или управляемость будущих ИИ-моделей». ИИ нашёл себя в маркетинге: каждый четвёртый пресс-релиз написан нейросетью
05.10.2025 [16:09],
Владимир Фетисов
Похоже, что есть сфера, где искусственный интеллект нашёл применение — это работа в корпоративных пресс-службах. На это указывают данные исследования, которые были опубликованы в журнале Patterns. Авторы работы провели анализ письменных материалов, которые публиковались корпоративными и государственными структурами в период после появления ChatGPT. Оказалось, что ИИ, вероятно, регулярно использовался для генерации разных материалов — от пресс-релизов до объявлений о вакансиях. 
Источник изображения: Shutterstock Исследователи изучили тысячи примеров текстов со всего интернета, включая такие популярные платформы для корпоративных новостей, как Newswire, PRWeb и PRNewswire. В результате было установлено, что с момента запуска ChatGPT в ноябре 2022 года примерно каждый четвёртый пресс-релиз был сгенерирован ИИ, причём в публикациях, связанных с наукой и технологиями, этот показатель даже выше. Ещё генеративные ИИ-алгоритмы часто использовались при написании объявлений о вакансиях. Исследователи установили, что созданный ИИ текст встречается примерно в 6-10 % объявлений о вакансиях на платформе LinkedIn. Примечательно, что чаще к помощи нейросетей прибегают небольшие компании (около 15 % от общего количества таких объявлений). Любопытно, что созданный ИИ текст встречается не только в материалах, публикуемых представителями корпоративного сегмента. Исследователи изучили пресс-релизы Организации Объединённых Наций за последние годы. Они установили с большой долей вероятности, что сотрудники ООН регулярно используют ИИ при написании пресс-релизов. Авторы работы подсчитали, что доля созданных с помощью ИИ текстов выросла с 3,1 % в первом квартале 2023 года до 10,1 % к третьему кварталу того же года. При этом к третьему кварталу 2024 года этот показатель достиг рекордных 13,7 %. Любопытно и то, что, по всей видимости, уровень использовании ИИ в данном сегменте достиг своего максимума и не продолжает расти. Для написания пресс-релизов пик использования ИИ был достигнут в декабре 2023 года, когда около 24,3 % попавших в исследование материалов с большой долей вероятности были созданы с использованием нейросетей. С тех пор уровень использования ИИ-алгоритмов снизился примерно на 0,5 % и практически не меняется. Что касается объявлений, то здесь прослеживается аналогичная динамика. Если же говорить об использовании ИИ в ООН, то там, похоже, рост сохраняется, но его темпы значительно замедлились. В потребительском сегменте внедрение генеративных технологий на базе ИИ проходит по похожему сценарию. Чтобы понять, как обычные люди используют ИИ, исследователи собрали и обработали более 687 тыс. жалоб, которые были поданы в Бюро финансовой защиты потребителей в период с 2022 года по 2024 год. Оказалось, что 18 % из них с большой долей вероятности были составлены с помощью ИИ. Любопытно и то, что люди, проживающие в регионах с более низким уровнем образования, немного чаще использовали ИИ-алгоритмы для написания жалоб, чем другие. Это несколько противоречит многим технологическим трендам, поскольку чаще всего новыми технологиями начинают пользоваться более молодые и образованные люди. Однако ИИ-инструменты, особенно бесплатные генераторы текста, вполне могут развиваться по другому сценарию. Авторы исследования планируют продолжить работу, чтобы более точно оценить уровень проникновения нейросетей в разные сферы деятельности человека. ИИ замедлился в развитии, но бизнес не должен об этом беспокоиться
25.08.2025 [11:28],
Владимир Фетисов
Развитие передовых ИИ-моделей демонстрирует признаки замедления. После ажиотажа вокруг искусственного интеллекта, возникшего при запуске алгоритма OpenAI ChatGPT в конце 2022 года, и регулярного появления впечатляющих ИИ-моделей становится всё более очевидным, что темпы прогресса больших языковых моделей снижаются. 
Источник изображения: Steve Johnson / Unsplash Этим летом компания Meta✴✴ Platforms отложила запуск новой флагманской ИИ-модели Llama 4 Behemoth, поскольку процесс её доработки затянулся. OpenAI также выпустила свою последнюю модель GPT-5 позже запланированного срока, причём она не оправдала ожиданий. На деле снижение интереса к передовым ИИ-алгоритмам не должно стать серьёзной проблемой для компаний, внедряющих искусственный интеллект в рабочие процессы. Генеративные алгоритмы уже закрепились в бизнесе и приносят ощутимую пользу — от обобщения больших текстовых документов и помощи в написании программного кода до составления электронных писем. Более простые нейросети, созданные ещё до появления генеративных алгоритмов, также находят всё больше применений, например, при обработке счетов-фактур. Однако большинство компаний едва ли глубоко разбирается в возможностях ИИ в его нынешнем виде, не говоря уже о том, каким он может стать в будущем. Далеко не все организации активно внедряют ИИ-технологии в рабочие процессы. Часто это связано с опасениями утечек конфиденциальных данных через ИИ-ботов. Кроме того, искусственному интеллекту редко доверяют принятие ключевых решений, влияющих на финансы, сотрудников и клиентов. Склонность даже самых совершенных моделей время от времени выдавать некорректные ответы лишь усиливает недоверие. Недавнее исследование Массачусетского технологического института показало, что многие компании в целом удовлетворены уже существующими ИИ-инструментами от OpenAI и Microsoft. Но когда дело доходит до разработки специализированного программного обеспечения с искусственным интеллектом — того, что должно приносить бизнесу наибольшую прибыль, — процент неудач в пилотных проектах достигает 95 %. Авторы исследования отмечают, что корпоративные пользователи «в подавляющем большинстве скептически относятся к ИИ-инструментам», считая их «чрезмерно усложнёнными или не соответствующими реальным рабочим процессам». Простое осознание того, что развитие искусственного интеллекта замедляется, может придать компаниям больше уверенности в том, что они будут вкладывать в него деньги и время. Корпоративному сектору явно требуется больше времени для адаптации ИИ-инструментов к своей деятельности. На данный момент интеграция больших языковых моделей в повседневные задачи остаётся на начальной стадии. В этом нет ничего удивительного. Интернет в конечном счёте изменил образ жизни людей и бизнес-практики, но в 1990-х на это ушло больше времени, чем предполагали первые энтузиасты. По данным Pew Research Center, потребовалось десятилетие, чтобы уровень проникновения домашнего широкополосного интернета в США вырос с почти нулевого в 2000 году до более чем 60 % взрослого населения. Бум искусственного интеллекта во многом отличается, но развитие может пойти по схожей траектории: всплеск энтузиазма, за которым следует спад по мере распространения технологий в обществе и бизнесе. Истинный масштаб преимуществ от внедрения ИИ станет понятен лишь спустя годы. Добиваться повышения производительности моделей становится всё сложнее, что играет на руку производителям оборудования, таким как Nvidia. Крупные игроки, включая OpenAI и Meta✴✴, вероятно, будут вкладывать ещё больше средств в инфраструктуру, пытаясь ускорить темпы прогресса собственных моделей. Пентагон заказал разработку аналоговых «мозгов» для дронов и систем автопилота
30.07.2025 [14:57],
Геннадий Детинич
По заказу военных США инженеры и программисты намерены воспроизвести в электронике зрительную систему мозга, чтобы создать новые инструменты искусственного интеллекта для управления автономными системами. Цифровые платформы и нейронные сети показали низкую энергоэффективность в сфере автопилотирования, поэтому для решения подобных задач учёные планируют разработать аналоговую электронику и новые инструменты программирования. 
Источник изображения: ИИ-генерация Grok 3/3DNews Контракт на разработку получил Рочестерский университет (University of Rochester). Соглашение заключено с Агентством перспективных оборонных исследовательских проектов (DARPA) на сумму $7,2 млн, которая будет выплачиваться в течение последующих 4,5 лет. В рамках проекта исследователи должны создать новую элементную базу и программное обеспечение для реализации так называемого предиктивного кодирования — подхода, основанного на биологических принципах работы человеческого мозга. Сети предиктивного кодирования (predictive coding networks) — это модели в области машинного обучения и нейронаук, основанные на концепции предсказания данных. Согласно этой теории, мозг (или модель) постоянно формирует прогнозы относительно входящих сенсорных сигналов и минимизирует ошибку предсказания, сравнивая ожидаемую и фактическую информацию. В контексте искусственных нейронных сетей такие модели часто используются в задачах компьютерного зрения и обработки естественного языка. Контракт предполагает достижение результата, при котором аналоговая система будет способна распознавать статические цифровые изображения. Если исследователям удастся добиться производительности, сопоставимой с существующими цифровыми решениями, то разработка сможет применяться в более сложных задачах, связанных с восприятием — в частности, в беспилотных автомобилях и автономных дронах. «Исследования нейробиологов показали, что механизм обратного распространения ошибки, лежащий в основе современных нейронных сетей, биологически неправдоподобен – системы восприятия нашего мозга работают иначе, — пояснил Майкл Хуанг (Michael Huang), профессор Рочестерского университета. — Чтобы решить эту проблему, мы задались вопросом: как это делает мозг? Преобладающей теорией стало предиктивное кодирование, предполагающее иерархический процесс прогнозирования и корректировки. Представьте, что вы перефразируете услышанное, сообщаете это говорящему и используете его ответ как обратную связь для уточнения своего понимания». Важно подчеркнуть, что, несмотря на новизну подхода, система будет базироваться на проверенных временем технологиях производства полупроводников. В частности, планируется использовать существующие техпроцессы, такие как комплементарная металл-оксид-полупроводниковая структура (КМОП). OpenAI упростила создание изображений: в ChatGPT появились готовые «крутые» стили
16.07.2025 [04:28],
Анжелла Марина
Компания OpenAI внедрила новую функцию в свой генератор изображений, доступный через ChatGPT. Как стало известно изданию BleepingComputer, теперь пользователи могут создавать эффектные художественные изображения в разных стилях, даже не разбираясь в тонкостях промт-инжиниринга. 
Источник изображения: AI Раньше для получения необходимого эффекта, например, в стиле аниме, требовалось тщательно формулировать запрос. Но даже в этом случае нейросеть не всегда выдавала желаемый результат. Чтобы упростить процесс, в ChatGPT добавили опцию «Стиль», которая позволяет выбирать готовые стили и применять их к изображениям. Так, если пользователь загрузит свою фотографию и выберет стиль «аниме», нейросеть преобразует её в рисунок, который может напоминать работы в стиле Studio Ghibli. Функция уже начала распространяться среди всех пользователей ChatGPT и, как информирует BleepingComputer, бесплатна. Нейросжатие текстур в играх показало рекордную экономию видеопамяти на видеокартах Nvidia и Intel
18.06.2025 [21:39],
Анжелла Марина
Разработчики игр всё чаще обращаются к нейросетям для решения проблемы нехватки видеопамяти. Поскольку для достижения ультрареалистичного игрового опыта размеры текстур постоянно увеличиваются, это создаёт повышенную нагрузку на VRAM. Один из энтузиастов опубликовал видео, в котором продемонстрировал работу технологии нейросетевого сжатия текстур (Neural Texture Compression, NTC) на видеокартах Nvidia и Intel. Тесты показали, что NTC позволяет значительно снизить объём используемой видеопамяти без потери качества изображения. 
Источник изображений: Compusemble / YouTube Технология NTC разработана как альтернатива традиционному блочному сжатию текстур. В отличие от существующих методов, она использует небольшие специализированные нейросети с минимальной вычислительной нагрузкой, которые настраиваются под конкретные материалы сцены. Это позволяет уменьшить объём текстур как в оперативной памяти (RAM), так и на накопителе, одновременно повышая качество рендеринга. Например, в демонстрационном ролике исходный объём текстуры шлема составлял 272 Мбайт. После блочного сжатия он сократился до 98 Мбайт. Применение NTC позволило уменьшить его до 11,37 Мбайт без потери качества — это более чем в 24 раза меньше по сравнению с оригиналом. Аналогичные результаты были продемонстрированы на видеокарте Intel с моделью тираннозавра: после декодирования текстуры с помощью NTC они выглядели чётче и ближе к оригиналу, чем при стандартном сжатии. 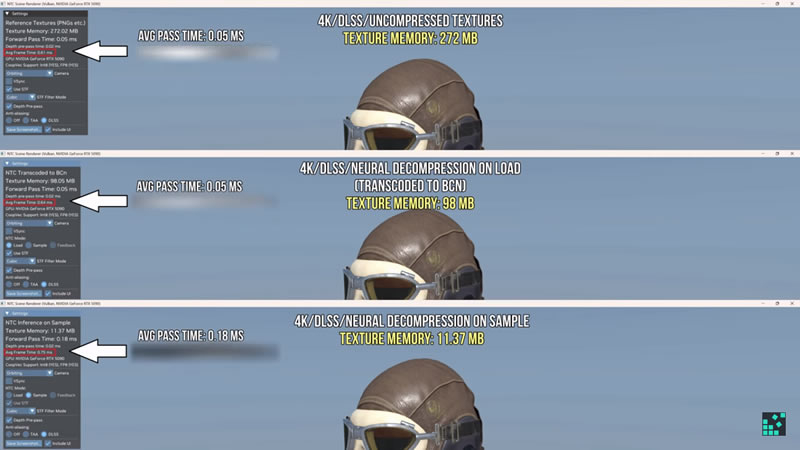 Автор видео Compusemble протестировал технологию на системе с видеокартой Nvidia GeForce RTX 5090. По его данным, время обработки одного кадра в разрешении 4K увеличилось с 0,045 мс до 0,111 мс — в 2,5 раза, однако это по-прежнему незначительно по сравнению с общей длительностью рендеринга кадра. При этом, если отключить функцию Cooperative Vectors, разработанную Nvidia, Microsoft и другими участниками индустрии, время обработки возрастает до 5,7 мс, что делает применение NTC практически невозможным без аппаратного ускорения. Следует отметить, что технология NTC пока не используется в коммерческих проектах. Однако её техническая база уже формируется. NTC позволит разработчикам либо снизить нагрузку на видеопамять, либо повысить детализацию графики без увеличения требований к «железу». Ожидается, что первые игры с поддержкой NTC появятся в течение ближайших нескольких лет. Anthropic намерена понять, как работают внутренние механизмы ИИ-моделей
25.04.2025 [18:23],
Владимир Фетисов
На этой неделе гендиректор Anthropic Дарио Амодеи (Dario Amodei) опубликовал статью, в которой поднял вопрос того, насколько мало исследователи понимают внутренние механизмы передовых моделей искусственного интеллекта. Он поставил перед Anthropic амбициозную задачу — надёжно выявлять большую часть проблем в ИИ-моделях к 2027 году. 
Источник изображения: anthropic.com Амодеи признал, что перед его компанией стоит непростая задача. Однако разработчики из Anthropic уже добились некоторых успехов в отслеживании того, как ИИ-модели приходят к ответам, которые они дают на пользовательские запросы. Отмечается, что для расшифровки механизмов работы ИИ-алгоритмов по мере роста их мощности требуется проведение большего количества исследований. «Я очень обеспокоен развёртыванием таких систем без улучшения понимания интерпретируемости. Эти системы будут занимать центральное место в экономике, технологиях и национальной безопасности, и они будут обладать настолько высокой степенью автономности, что я считаю недопустимым для человечества полное незнание того, как они работают», — сказано в статье Амодеи. Anthropic является одним из первопроходцев в сфере механической интерпретируемости — направлении, стремящемся открыть «чёрный ящик» ИИ-моделей и понять, почему нейросети принимают те или иные решения. Несмотря на стремительное повышение производительности ИИ-моделей в технологической отрасли, люди всё ещё имеют слабое представление о том, как ИИ-модели принимают решения. К примеру, недавно OpenAI запустила более производительные алгоритмы o3 и 04-mini, которые лучше справляются с некоторыми задачами, но чаще галлюцинируют по сравнению с другими ИИ-моделями компании. На данный момент разработчикам неизвестно, почему это происходит. «Когда генеративная ИИ-система делает что-то, например, обобщает финансовый документ, мы не имеем ни малейшего представления на конкретном или точном уровне, почему она делает тот или иной выбор, почему она выбирает одни слова, а не другие, или почему она иногда ошибается, хотя обычно бывает точна», — пишет Амодеи. Глава Anthropic уверен, что создание так называемого сильного ИИ (AGI), который по возможностям будет сравним с человеком или превзойдёт его, может быть очень опасным без чёткого понимания, как работают ИИ-модели. Ранее Амодеи говорил, что человечество сможет достичь такого понимания к 2026-2027 годам, но теперь он заявил, что до полного понимания ИИ-моделей очень далеко. В долгосрочной перспективе Anthropic хотела бы проводить «сканирование мозга» или «магнитно-резонансную томографию» самым передовым ИИ-моделям. По словам Амодеи, такие обследования помогут выявить широкий спектр проблем в ИИ-моделях, включая их склонность ко лжи, стремление к власти и др. На это может уйти от пяти до десяти лет, но такие примеры необходимы для тестирования и запуска будущих ИИ-моделей. В сообщении сказано, что Anthropic добилась определённых успехов в исследовательской деятельности, которые позволили улучшить понимание того, как работают ИИ-модели. Например, недавно компания нашла способ проследить пути мышления ИИ-модели с помощью так называемых схем. В результате Anthropic выявила одну цепь, которая помогает ИИ понять, какие американские города находятся в тех или иных штатах. Компания выявила лишь несколько таких схем, но разработчики считают, что в ИИ-моделях их миллионы. Anthropic сама инвестирует в исследования интерпретируемости, а также недавно вложила средства в стартап, работающий в этом направлении. Хотя сегодня исследования интерпретируемости в основном связывают с безопасностью, Амодеи уверен, что объяснение того, как ИИ-модели приходят к своим ответам, может стать коммерческим преимуществом. Глава Anthropic призвал OpenAI и Google DeepMind активизировать свои исследования в этой области. Амодеи просит правительства стран поощрять исследования в области интерпретируемости. Он также уверен, что США должны ввести контроль за экспортом чипов в Китай, чтобы ограничить вероятность выхода глобальной гонки в сфере ИИ из-под контроля. Apple будет анализировать переписки пользователей на iPhone, iPad и Mac для улучшения своего ИИ
15.04.2025 [10:30],
Владимир Фетисов
Apple планирует начать анализировать данные на устройствах пользователей, чтобы усовершенствовать свою платформу искусственного интеллекта. Отмечается, что этот шаг призван защитить информацию о пользователях и в то же время помочь компании догнать конкурентов в области ИИ.  В настоящее время Apple обучает ИИ-модели на синтетических данных, которые лишь имитируют реальные и не содержат какой-либо пользовательской информации. Однако синтетические данные не всегда соответствуют реальной информации о клиентах, что в конечном счёте затрудняет корректную работу ИИ-алгоритмов, которые обучались на этих данных. Новый подход позволит решить эту проблему, гарантируя при этом, что пользовательские данные останутся на устройствах клиентов и не будут напрямую использоваться для обучения ИИ-моделей. Основная задача нововведения заключается в том, чтобы помочь Apple догнать конкурентов, таких как OpenAI и Alphabet, у которых меньше ограничений в плане конфиденциальности данных клиентов. Технология работает следующим образом: алгоритм берёт сгенерированные Apple синтетические данные и сравнивает их с актуальной выборкой писем пользователей в почтовом приложении компании для iPhone, iPad и Mac. Используя реальные письма для проверки точности генерируемых синтетических данных, Apple будет лучше понимать, какие именно части синтетических данных наиболее соответствуют реальным сообщениям, а, следовательно, подходят для обучения ИИ-моделей. Эти данные помогут компании сделать лучше ИИ-функции, связанные с генерацией текста инструментами, входящими в состав платформы Apple Intelligence. «Генерируя синтетические данные, мы стремимся получить синтетические предложения или письма, достаточно похожие по теме или стилю на реальные, чтобы улучшить наши модели для обобщения, но без сбора писем с устройств пользователей Apple», — сказано в сообщении разработчиков. Помимо синтетических данных, Apple обучает свои ИИ-модели на информации, которую лицензирует у сторонних компаний или собирает в открытом доступе в интернете. Использование синтетических данных имеет свои недостатки, из-за чего алгоритмы Apple зачастую не слишком хорошо справляются с выполнением задач, например, по обобщению текста. Теоретически новый подход поможет улучшить ИИ-модели Apple, что станет ключевым шагом на пути к тому, чтобы составить конкуренцию лидерам сегмента ИИ. Apple признаёт отставание своих продуктов от аналогов лидеров рынка и прилагает усилия для того, чтобы исправить ситуацию. «Опираясь на многолетний опыт использования таких методов, как дифференциальная конфиденциальность, а также новые технологии, такие как генерация синтетических данных, мы можем улучшить функции Apple Intelligence, защищая при этом конфиденциальность пользователей, которые согласились на участие в программе аналитики устройств», — сказано в заявлении Apple. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



