|
Опрос
|
реклама
Быстрый переход
ИИ привёл к перерасходу бюджета на 860 % — Amazon признала, что нейросети сделали ошибки «катастрофически дорогими»
30.07.2026 [23:04],
Владимир Фетисов
Внутренние отчёты Amazon показывают, что использование искусственного интеллекта влечёт за собой значительный перерасход средств в различных проектах. Недавно было обнаружено, что перерасход достиг отметки в $1,8 млн, причём всего в рамках одного проекта. Прежде такие ошибки были «тривиально дешёвыми», но ИИ-модели сделали их «катастрофически дорогими», особенно по мере роста расходов на используемые токены при внедрении ИИ-агентов. 
Источник изображения: BoliviaInteligente/unsplash.com В одном из отчётов сказано, что неудачное развёртывание ИИ-модели Claude Sonnet, которая должна была сопоставлять данные клиентов с карточками товаров на Amazon, привело к перерасходу средств на $1,8 млн. В результате выделенный на данный проект бюджет был превышен на 860 %, причём обнаружить перерасход удалось только через пять месяцев после возникновения проблемы. Среди других подобных случаев выделяется перерасход на $541 тыс. при реализации проекта, в рамках которого разрабатывался инструмент для проведения финансового аудита. Также дополнительные $134 тыс. были потрачены при создании системы для сокращения сроков доставки товаров внутри логистической сети компании. «Как и с любой новой технологией, мы экспериментируем, учимся и совершенствуем способы её использования, в том числе в плане повышения эффективности расходов. Выборка отдельных примеров, где команды учатся друг у друга, и представление их так, будто это стандартная практика, не отражают масштаба и подхода к использованию ИИ внутри всей Amazon», — говорится в заявлении компании. Хотя перерасход более чем в миллион долларов на провальные ИИ-проекты может показаться чрезмерным для обычного человека, компании вроде Amazon могут себе такое позволить. Для технологического гиганта с квартальной выручкой в $181 млрд эти дополнительные расходы составляют менее 0,1 % от ежемесячной выручки. Любопытно, что это не первые проблемы, связанные с ИИ, с которыми столкнулась Amazon. Ранее в этом году подразделение AWS зафиксировало несколько сбоев из-за ошибок ИИ-бота для генерации программного кода. Тогда проблема была решена путём ограничения разрешений для бота, который до этого имел права, как у старших инженеров, занимающихся проверкой кода. Ранее Amazon также вводила рейтинговую таблицу, которая показывала, кто из сотрудников чаще всего использует ИИ, но из-за роста расходов на нейросети от неё отказались. Runway представила Media Router — сервис сам подберёт самый выгодный ИИ для генерации контента
24.07.2026 [01:09],
Анжелла Марина
Компания Runway представила инструмент Media Router, автоматически подбирающий оптимальную модель для генерации изображений, видео и аудио в зависимости от требований к качеству, скорости или стоимости токенов. Платформа Runway Dev теперь будет предоставлять доступ к API как собственных, так и сторонних генеративных моделей, сообщает издание TechCrunch. 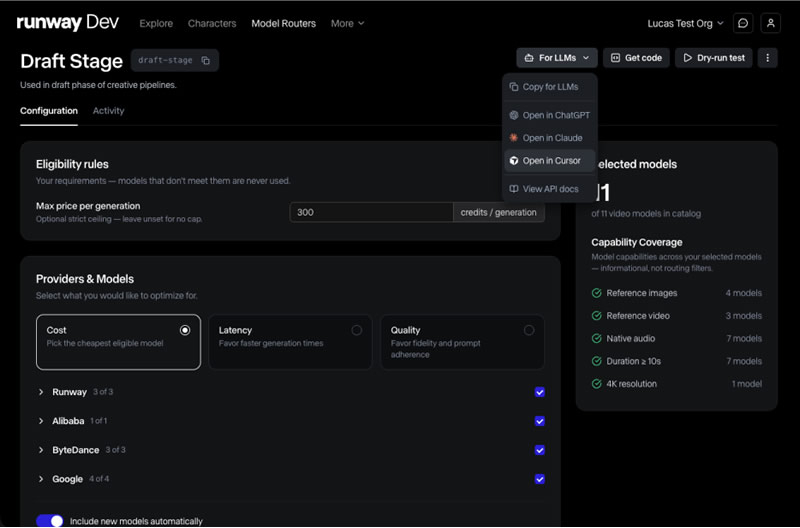
Источник изображения: Runway Media Router анализирует параметры запроса и направляет его к наиболее подходящей модели. По словам директора по продукту Runway Энтони Маджио (Anthony Maggio), сервис создавался как единая точка интеграции генеративных моделей для разработчиков. В компании утверждают, что это первый подобный маршрутизатор, ориентированный именно на генеративные изображения, видео и аудио. Через платформу Runway Dev разработчики могут использовать новые модели сразу после их выхода в свет, не занимаясь самостоятельной оценкой возможностей каждой из них. При этом API уже применяют такие компании, как Adobe, Cloudflare, ElevenLabs, Expedia, Shutterstock и Quora, встраивая генерацию медиаконтента непосредственно в собственные продукты. Помимо качества и скорости генерации, пользователи могут задавать дополнительные предпочтения при выборе, например, касающиеся стоимости токенов или качества конечного результата. Также предусмотрена возможность ограничить использование моделей определённых поставщиков, включая выбор разработчиков только из США вместо китайских компаний. Архитектура Media Router основана на опыте творческой команды Runway, оценивающей качество различных моделей по таким критериям, как передача движения в видео, построение композиции изображений или синхронизация речи. Ранее аналогичная технология уже использовалась в агенте Runway для создания видеороликов, состоящих из множества сцен и маркетинговых кампаний. Как отмечает TechCrunch, запуск инструмента отражает изменение стратегии Runway на фоне усиливающейся конкуренции на рынке генеративного ИИ. После выхода модели Gen 4.5 в декабре компания не представила новых флагманских моделей для генерации видео, тогда как лидирующие позиции в отраслевых рейтингах заняли модели Google, ByteDance и Alibaba. Теперь же, вместо ориентации только на одну собственную модель, Runway намерена развивать инфраструктуру, позволяющую автоматически использовать наиболее подходящие системы разных поставщиков. По словам сооснователя и генерального директора Runway Анастасиса Германидиса (Anastasis Germanidis), всё больше компаний заинтересованы в использовании услуг Runway на всех этапах работы с генеративным медиаконтентом, так как компания постоянно расширяет свою экосистему, включила в неё платформу для разработчиков и творческий набор инструментов для создания контента. Чудеса оптимизации: китайцы в 149 раз ускорили работу нейросетей без повышения производительности чипов
14.07.2026 [15:03],
Геннадий Детинич
Не секрет, что в гонке за чем-либо любыми средствами первой страдает оптимизация процессов. Все проблемы с ресурсоёмкими ИИ как раз об этом. Об оптимизации вспоминают только тогда, когда ресурс для продолжения гонки подходит к концу или его перестаёт хватать всем. Своими санкциями США поставили китайских разработчиков в положение, когда оптимизация становится единственным выходом из кризиса дефицита ресурсов. Но это не просто выход — это шанс на прорыв. 
Источник изображения: ИИ-генерация ChatGPT/3DNews В частности, исследователи из Пекинского университета (Peking University) создали экспериментальную вычислительную систему, в которой несколько обычных электронных процессоров обменивались данными через кремниевые фотонные передатчики и оптический коммутатор. Во время экспериментов платформа выполнила нейросетевую задачу шумоподавления почти в 149 раз быстрее графического процессора, хотя её номинальная вычислительная производительность составляла лишь около 11,6 % от производительности GPU: около 1,97 против 16,96 Тфлопс. Система состояла из пяти программируемых логических матриц FPGA (ПЛИС), на каждой из которых был размещён один слой пятислойной свёрточной нейросети. Между платами установили кремниевые фотонные трансиверы со скоростью 400 Гбит/с и оптический коммутатор 16 × 16. Четыре канала передачи данных по 100 Гбит/с передавались по общему волокну на четырёх длинах волн. Коммутатор имел потери менее 5 дБ и теоретически мог соединять до 16 вычислительных чипов с совокупной пропускной способностью 6,4 Тбит/с. Главным преимуществом решения стала конвейерная обработка. Каждая ПЛИС постоянно выполняла обработку своего слоя нейросети и сразу передавала промежуточный результат следующему чипу по оптическому каналу. Благодаря этому не требовалось после обработки каждого слоя сохранять данные во внешней памяти и затем загружать их обратно — именно такие операции создают так называемую «стену памяти» и тормозят работу GPU. Тысяча изображений размером 32 × 32 пикселя была обработана за 105,16 мкс, тогда как контрольный GPU затратил на те же операции 15,643 мс, а эффективность использования вычислительных блоков ПЛИС достигла впечатляющих 94,7 %. Для эксперимента учёные использовали простую пятислойную нейросеть с ядрами 5 × 5 и набор данных Fashion-MNIST. Было бы заманчиво увидеть подобные эксперименты с большими языковыми или другими современными генеративными моделями. Пока этого нет, но уже сейчас опыт даёт наглядное представление о громадном резерве ускорения ИИ при правильной оптимизации. «Конкретные задачи могут быть реализованы при ограниченных вычислительных ресурсах, когда совместно разрабатываются алгоритмы, микроархитектуры процессоров и межсоединения на уровне чипов, — резонно отмечают авторы работы. — Эта структура также может снизить нерациональное потребление энергии в центрах обработки данных и оптимизировать задержку или потребление в сценариях с передовыми вычислениями». Character.AI запустила короткие ИИ-сериалы с возможностью чата с героями
10.07.2026 [06:35],
Анжелла Марина
Платформа Character.AI анонсировала запуск нового формата коротких микросериалов для мобильных устройств, созданных преимущественно с помощью искусственного интеллекта. После просмотра каждого эпизода пользователи смогут продолжить взаимодействие с персонажами через встроенный чат. 
Источник изображения: Character.AI Новый формат получил название c.ai Series и стал очередным этапом развития сервиса, который ранее уже вышел за рамки обычного чат-бота, предложив пользователям интерактивные книги, комиксы и аудиодрамы. В отличие от большинства платформ с микросериалами, в которых снимаются живые актёры, c.ai Series представляет собой анимационные проекты, практически полностью созданные средствами генеративного ИИ. Каждый сериал посвящён отдельной истории, разворачивающейся в популярных жанрах, включая мелодраму, хоррор и научную фантастику. Ключевой особенностью сервиса, отличающей его от таких платформ, как ReelShort и DramaBox, стала возможность после завершения просмотра эпизода продолжить общение с его персонажами в формате диалога. На старте Character.AI представила три проекта: Last Summer, посвящённый истории тайных поклонников и выполненный в аниме-стилистике, The Nighttime Game, рассказывающий о друзьях, участвующих в смертельно опасной карточной игре, а также Eden Fall, сюжет которого посвящён группе элитных игроков MMO, оказавшихся в виртуальной реальности, напоминающей мир Ready Player One и визуально схожей с Genshin Impact. OpenAI выпустила GPT-5.6 и научила ChatGPT выполнять многоэтапные рабочие задачи в режиме Work
09.07.2026 [22:17],
Андрей Созинов
OpenAI открыла публичный доступ к семейству языковых моделей GPT-5.6 и одновременно представила ChatGPT Work — новый режим работы чат-бота, превращающий его в ИИ-агента. Теперь ChatGPT способен самостоятельно выполнять длительные многоэтапные задачи, используя подключённые приложения, документы и другие источники данных.  ChatGPT Work фактически объединяет возможности обычного ChatGPT и ИИ-агента Codex. Если раньше Codex был ориентирован прежде всего на разработчиков, то теперь его технологии стали доступны и для повседневной работы. Новый режим ChatGPT с помощью единого каталога плагинов умеет подключаться к Slack, Microsoft Teams, Google Drive, SharePoint, Gmail, календарям, CRM-системам и другим сервисам, чтобы использовать данные из этих приложений для выполнения пользовательских задач. «Он может собирать контекст из выбранных вами приложений, файлов и рабочих процессов и создавать готовые материалы, такие как документы, таблицы, презентации и веб-приложения», — рассказала OpenAI. 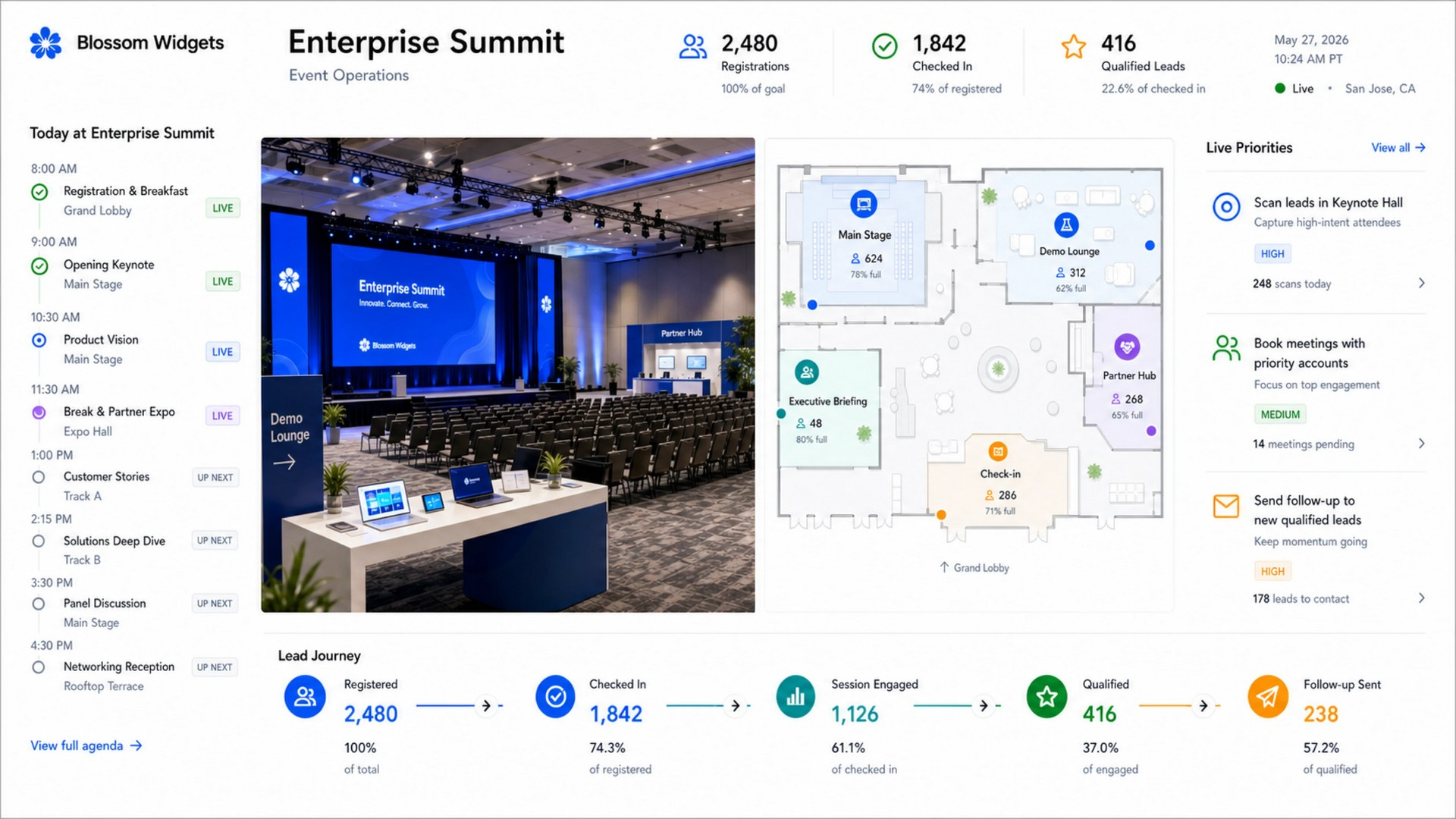 ChatGPT Work может автоматически выбирать нужный источник информации или обращаться к конкретному сервису по запросу пользователя. Агент способен самостоятельно собирать необходимую информацию, анализировать её и выполнять поставленные задачи. Кроме того, сервис получил поддержку автоматизаций Scheduled Tasks, позволяющих запускать действия по расписанию или при наступлении определённых событий.  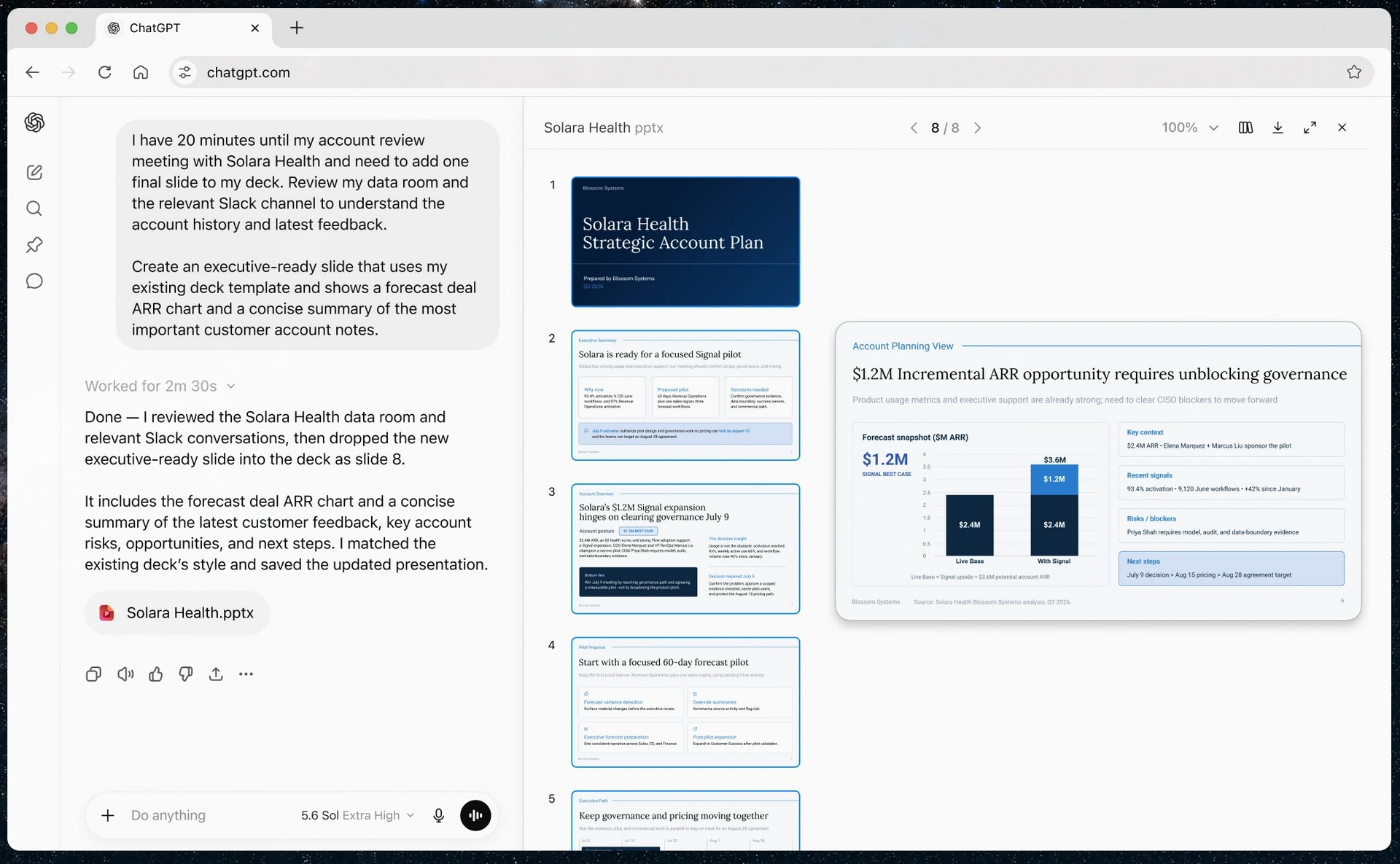 Одновременно OpenAI обновила настольное приложение ChatGPT для Windows и macOS. В него встроили браузер для работы с веб-сервисами, а также функцию Computer Use, которая позволяет ИИ взаимодействовать с локальными приложениями и файлами на компьютере пользователя. Ещё одной новинкой стала функция Sites, с помощью которой ChatGPT способен создавать небольшие сайты и веб-приложения по текстовому описанию. 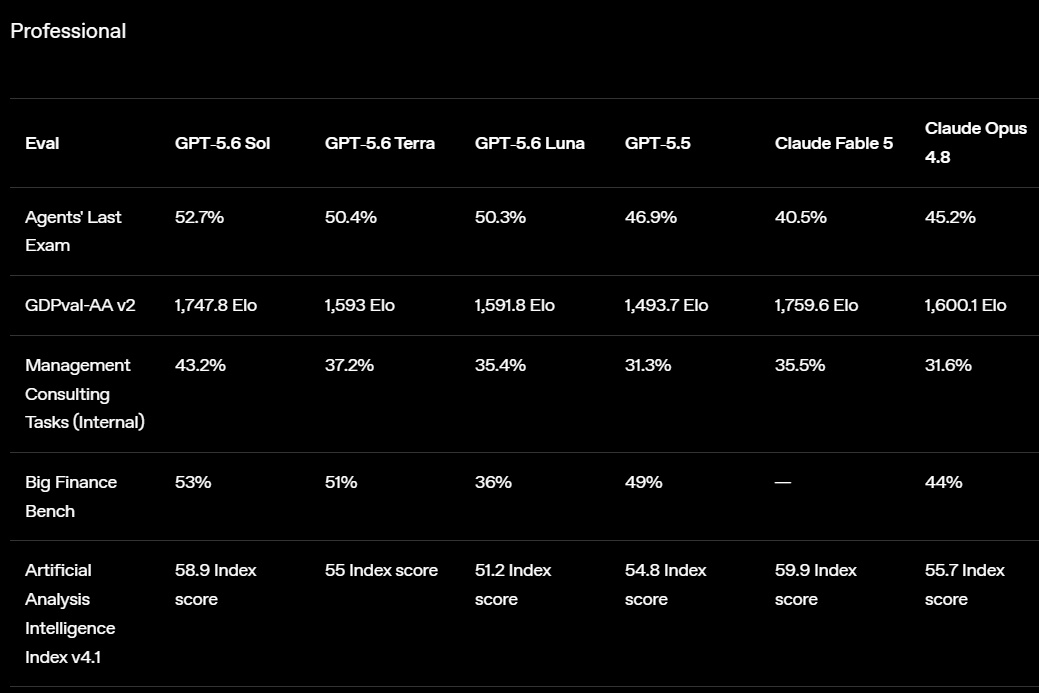 Основой всех новых возможностей стало семейство моделей GPT-5.6, включающее версии Sol, Terra и Luna. Флагманская Sol предназначена для наиболее сложных задач, Terra выступает универсальной моделью, а Luna ориентирована на максимальную скорость работы и низкую стоимость. По данным OpenAI, GPT-5.6 заметно превосходит GPT-5.5 в программировании, анализе документов, работе с компьютерным интерфейсом и других задачах, одновременно снижая вычислительные затраты. OpenAI делает основную ставку на самую мощную модель GPT-5.6 Sol, которая, по задумке компании, должна установить «новый стандарт интеллекта и эффективности», особенно в таких областях, как программирование, кибербезопасность и наука, а также в сфере использования компьютеров ИИ-агентами. Компания также позиционирует эту модель как более доступную альтернативу самым мощным моделям конкурентов на фоне жалоб на общеотраслевую нехватку средств и перекладывание затрат ИИ-лабораторий на плечи клиентов. OpenAI также заявила об усилении механизмов безопасности. Для GPT-5.6 компания переработала систему защиты от потенциально опасных запросов, объединив встроенные ограничения модели, мониторинг в реальном времени и дополнительную проверку наиболее рискованных действий отдельной системой анализа. Наиболее чувствительные возможности в области кибербезопасности останутся доступны только участникам программы Trusted Access, прошедшим дополнительную проверку.  Распространение GPT-5.6 и режима ChatGPT Work начинается сегодня. В приложении ChatGPT для Windows и macOS модели GPT-5.6 и новый режим Work стали доступны уже сегодня для всех пользователей, включая владельцев бесплатных аккаунтов. В веб-версии ChatGPT и мобильных приложениях первыми доступ к GPT-5.6 и Work получат подписчики тарифных планов Pro, Enterprise и Edu, а пользователи тарифов Plus и Business — в течение ближайших нескольких дней. Семейство GPT-5.6 также постепенно становится доступным через ChatGPT, Codex и OpenAI API. Стоимость использования GPT-5.6 рассчитывается за 1 млн токенов и зависит от версии модели: для Sol — $5 за входные данные и $30 за выходные, для Terra — $2,50 и $15 соответственно, а для Luna — $1 за входные токены и $6 за выходные. Журналисты доказали использование миллионов защищённых авторским правом песен для обучения ИИ
17.06.2026 [22:54],
Анжелла Марина
Издание The Atlantic нашло неоспоримые доказательства использования миллионов охраняемых авторским правом музыкальных записей для обучения нейросетей. В списки попали современные мировые хиты, авторы которых не давали согласия ИИ-компаниям на обработку своих произведений. 
Источник изображения: AI Журналист The Atlantic Алекс Рейснер (Alex Reisner) опубликовал четыре каталога, в которых зафиксировано, какая конкретно музыка использовалась для обучения моделей. Компания Suno в судебных документах официально подтвердила, что обучала ИИ на десятках миллионов записей, часть которых была защищена авторскими правами и использовалась без разрешения правообладателей, в число которых вошли Тейлор Свифт (Taylor Swift) и Бэд Банни (Bad Bunny). Параллельно с этим лейблы Sony, UMG и Warner подали иски против Suno и Udio, требуя возмещения в размере до $150 000 за каждую композицию, оказавшуюся в тренировочном наборе. В то время как создатели нейросетей настаивают на доктрине добросовестного использования, утверждая, что ИИ-модели запоминают лишь абстрактные паттерны, а не конкретные мелодии, представители индустрии настаивают на обратном, называя эту практику «пиратством, упакованным в красивую презентацию для инвесторов». Ситуацию усугубляет позиция Бюро по авторским правам США (United States Copyright Office), заявившего в январе 2025 года, что результаты работы таких нейросетей не защищены авторским правом из-за недостаточного человеческого участия, оставляя созданный контент вне правового поля. В качестве одной из действенных мер противодействия исследователи из Университета Теннесси разработали инструмент HarmonyCloak, добавляющий в аудиофайлы неслышимые для человеческого уха звуковые искажения. Однако вектор борьбы уже смещается в сторону правовых отношений. В частности, Warner Music Group и Universal Music Group заключили лицензионное соглашения с Udio и Suno, а власти Теннесси приняли закон, защищающий голоса музыкантов от неправомерного клонирования. «Яндекс» намерен научить ИИ считывать эмоции и чувства людей
15.06.2026 [21:28],
Владимир Фетисов
Компания «Яндекс», как и ряд других представителей сферы ИИ, работает над устройством, которое позволит нейросетям считывать эмоции и чувства человека. За счёт этого алгоритмы смогут лучше понимать реальный контекст, связанный с общением, встречами или задачами, считает глава бизнес-группы поисковых сервисов и искусственного интеллекта «Яндекса» Дмитрий Масюк. По его мнению, на создание такого устройства может уйти до семи лет. 
Источник изображения: Igor Omilaev / unsplash.com Господин Масюк рассказал, что одним из ключевых ограничений ИИ сейчас является «узкое горлышко» при передаче контекста. «Всё, что касается тонкого контекста и загрузки, эмоций человека, например, которые важны в общении, сейчас это приходится в лучшем случае описывать текстом. И мечта — отвечаю на вопрос прямо — в том, чтобы у нас было постоянно носимое устройство, которое фиксирует, соответственно, всё, что происходит вокруг», — сообщил Масюк. В настоящее время в ассортименте «Яндекса» есть линейка умных колонок и ТВ-станций с голосовым помощником «Алисой», а также устройства для умного дома. В этом месяце компания начала продавать своё первое носимое устройство с ИИ — наушники «Яндекс Дропс» с «Алисой AI». Владелец таких наушников может в любой момент обратиться к ИИ-помощнику, сообщить свои мысли, планы на день, рассказать об идеях, после чего алгоритм превратит эту информацию в заметки и напоминания. Дмитрий Масюк считает, что инженеры научатся фиксировать голосовые данные в неограниченном объёме в течение двух лет. Однако для создания технологии фиксации визуального потока потребуется до пяти лет. Предполагается, что в течение 3–7 лет на рынке могут появиться «хорошие умные очки», позволяющие загружать в нейросеть весь контекст происходящего. В рамках интервью также было сказано, что очень точным отражением ожиданий инженерного сообщества от ИИ является фильм «Она» с Хоакином Фениксом. В нём главный герой завязывает роман с ИИ-системой, проявляющей настоящие человеческие эмоции. «Мы совершенно точно к этому придём. Вопрос в том, с какой скоростью. Это пять–десять лет», — считает Масюк. Также было сказано, что любая технологическая революция длится 10–15 лет, как, например, развитие интернета, появление смартфонов и компьютеров. С начала эры генеративных нейросетей прошло 3,5 года, поэтому о полноценных ИИ-агентах можно будет говорить примерно через два года. «За три года мы получили нейросети, которые без проблем отвечают на вопросы уровня кандидата или профессора любой науки — гуманитарной, технической, что немыслимо сложно для человека», — отметил Масюк. Однако взаимодействие с реальным миром является более сложной задачей, поэтому разработка пригодных для этого решений займёт больше времени. В настоящее время «Яндекс» работает над оптимизацией обучения и функционирования нейросетей. Ожидается, что такой подход позволит сэкономить «миллионы долларов». Представитель «Яндекса» уточнил, что разработчики создали агентный поиск для «Алисы AI», позволяющий ранжировать веб-страницы по степени актуальности и улучшать отбор фрагментов для ответа. Это нововведение было реализовано в апреле. «С того момента плотность полезной информации в контексте, который передаётся нейросети для ответов, выросла в два раза. Это принесло нам дополнительные 350 млн рублей экономии благодаря работе наших инженеров», — рассказал представитель «Яндекса». ИИ-боты повадились рассказывать истории об Элиасе Торне — и никто не знает, кто это такой
12.06.2026 [14:00],
Владимир Фетисов
Программист Дэниел Мэй (Daniel May) одним из первых обратил внимание, что ИИ-боты разных компаний регулярно упоминают в генерируемых ими рассказах некоего Элиаса Торна. Некоторое время оставалось загадкой, кто это на самом деле. Теперь же опубликован отчёт по результатам исследования данного вопроса. Вероятно, упоминания Торна в рассказах ИИ связаны с работой ограничительных механизмов нейросетей, устанавливаемых в процессе обучения систем в целях безопасности. 
Источник изображения: BoliviaInteligente / Unsplash Разобраться в этом вопросе решили исследователи Корнеллского университета в США Сайл Гамильтон (Sil Hamilton) и Дэвид Мимно (David Mimno). Они использовали несколько ИИ-моделей, включая OpenAI GPT-5.4 Mini, Anthropic Claude Haiku 4.5 и Google Gemini 3.1 Flash Lite, для генерации рассказов на основании пяти разных подсказок. После этого они проанализировали около 20 тыс. сгенерированных ИИ-ботами историй и обнаружили поразительное количество повторений. Оказалось, что слова «маяк», «смотритель», «пекарь», «мэр», «часовщик», «рыбак», «библиотекарь», «кондуктор», а также имена «Мара», «Элиас» и «Элара» встречаются в 88 % всех сгенерированных историй. Ни одна комбинация из этого небольшого набора существительных не встречается чаще, чем «Элиас, смотритель маяка». Она обнаружилась в двух третях сгенерированных рассказов. Так в чём же дело? Сначала исследователи предположили, что это может быть связано с данными, которые использовались для обучения языковых моделей. Однако от этой идеи они отказались, когда не смогли найти подтверждений того, что словосочетание «Элиас, смотритель маяка» с чрезмерной частотой встречается в наборах, используемых для обучения данных, или в литературе. Исследователи связали рассматриваемую особенность с конкретным набором данных, который активно использовался для обучения ИИ-моделей разными разработчиками. В качестве примера они привели WildChat — открытый набор данных, состоящий из миллионов разговоров людей с чат-ботом на базе GPT-3.5. Этот набор данных создали для того, чтобы помочь исследователям понять, как люди общаются с ботами, но с тех пор его множество раз задействовали для обучения ИИ-моделей. Исследователи предполагают, что рассматриваемая особенность при генерации историй ИИ-ботами обусловлена работой защитных механизмов, которые должны уводить ИИ-модели от защищённых авторским правом персонажей и контента для взрослых. Вероятно, в результате этого и появились «безопасные» альтернативы, такие как «Элиас, смотритель маяка». Отмечается, что имя Элиас можно встретить не только в сгенерированных детских сказках, но и в рассказах в жанре фэнтези. Элиас Торн также был обнаружен как автор книг, включая справочник с информацией об альтернативных способах лечения рака. Как бы то ни было, странная особенность повествования ИИ-моделей является хорошим напоминанием о том, что нейросети не креативны. Проведённое в прошлом году исследование показало, что ИИ-модели создают изображения, попадающие в 1 из всего 12 конкретных мотивов, независимо от того, насколько необычное описание даёт пользователь. Amazon встроила в поиск ИИ-картинки несуществующих товаров, чтобы помочь найти настоящие
03.06.2026 [22:16],
Анжелла Марина
Amazon обновила поисковую строку в мобильном приложении, добавив функцию генерации ИИ-изображений товаров на основе текстового описания пользователя. На текущем этапе инструмент работает только с категориями одежды и товаров для дома, позволяя выбрать наиболее подходящее сгенерированное изображение и затем найти похожие товары в каталоге. 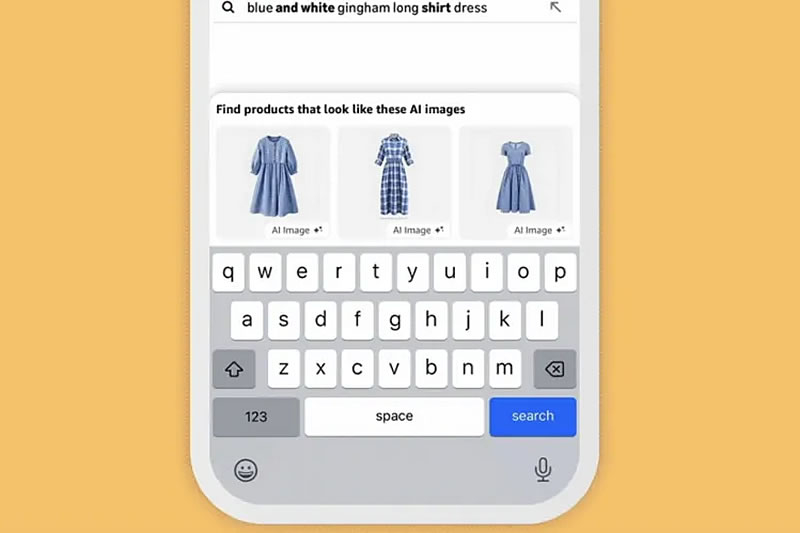
Источник изображений: Amazon Amazon позиционирует нововведение как помощь пользователям, которые не могут вспомнить точное название товара или стиля, например описав «рубашку с драпированным воротником» вместо «рубашки с воротником-хомутом». Как отмечает The Verge, функция действительно может оказаться полезной в подобных сценариях, однако не даёт существенных преимуществ при поиске таких простых товаров, как, например, «синяя футболка». 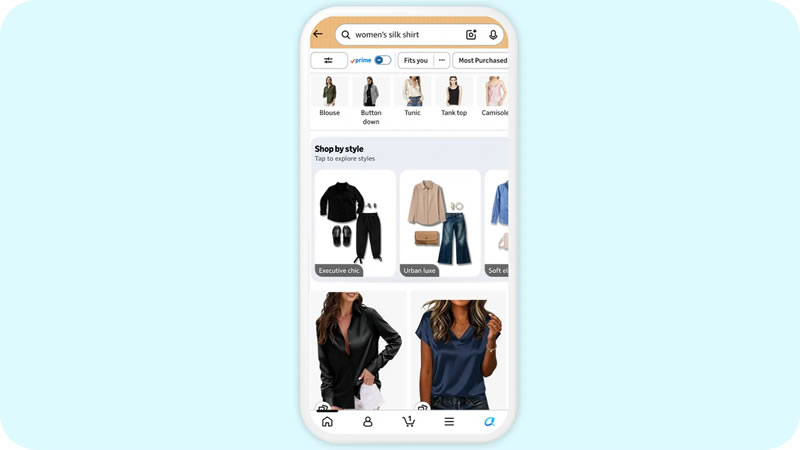 Стоит отметить, что Google представила аналогичный инструмент в ИИ-режиме поиска (AI Mode) ещё в прошлом году, генерируя изображения несуществующих комплектов одежды и предметов декора для поиска реальных аналогов. Также онлайн-ретейлеры всё активнее интегрируют Gemini и ChatGPT в процессы покупок, а теперь к тренду подключилась и Amazon, развивая направление поиска по стилю (shop by style), хотя и использует иной подход к генерации контента. В отличие от поисковой строки, функция shop by style выводит ИИ-коллажи с реальными товарами, доступными для покупки. Например, при запросе джинсовых шорт Amazon покажет карусель предложенных комплектов одежды с этим элементом гардероба, где сами наряды сгенерированы искусственным интеллектом, но изображённая одежда реально существует в каталоге. Обе функции появятся в приложениях Amazon для платформ Android и iOS. В России сбоит DeepSeek — РКН отрицает блокировку
24.05.2026 [21:25],
Владимир Мироненко
С вечера субботы, 23 мая, и в воскресенье российские пользователи жалуются на проблемы с доступом к нейросети DeepSeek, о чём свидетельствуют данные ресурсов Downdetector и «Сбой.рф». Согласно сведениям Downdetector, пик сбоев пришёлся на 10 часов утра, всего за сутки поступило около 23 тыс. жалоб пользователей, больше всего — из Москвы, Петербурга, Новосибирской, Московский областей. 
Источник изображения: Solen Feyissa/unsplash.com В большинстве своём жалобы поступали от владельцев Android-устройств (57,4 %) и компьютеров на Windows (21,9 %). Также зафиксированы жалобы от пользователей устройств на iOS (18,6 %) и Mac OS X (1,4 %). Большей частью пользователи жалуются на общий сбой (35 %), а также на работу мобильного приложения (17 %) и сайта (14 %). При этом сайт открывается при использовании VPN. Как сообщил ресурс «Код Дурова», жалобы на работу DeepSeek поступают только из России. При проверке интернет-соединения, проведённой «Кодом Дурова», соединение с сайтом обрывается на этапе TLS — это поведение совпадает с заблокированными Роскомнадзором сайтами. Однако, как сообщили в ведомстве ТАСС: «Роскомнадзор не получал решения уполномоченных органов и не вводил ограничения в отношении Deepseek». «Код Дурова» отметил, что DeepSeek был единственным зарубежным ИИ-сервисом из пятёрки самых крупных, который официально не ограничивал россиянам доступ к сервису. В предыдущий раз сбой в работе DeepSeek наблюдался 8 мая, но тогда жалобы на работу сервиса также поступали от пользователей из США, Великобритании и других стран. При этом в большинстве случаев (89 %) нейросеть была недоступна в России. Тогда компания объяснила сбой крупным отключением электроэнергии на шкале отслеживания работы службы API и веб-чата. DeepSeek-V4 вышла без «вау-эффекта» — рынок уже привык к дешёвому ИИ
27.04.2026 [17:09],
Владимир Фетисов
Реакция рынка на предварительную версию новой ИИ-модели DeepSeek-V4 пока выглядит сдержанной по сравнению с тем, что можно было наблюдать в прошлом году, когда китайский стартап анонсировал свои недорогие и производительные алгоритмы. Это указывает на то, что за прошедшее с тех пор время рынки адаптировались и привыкли к появлению недорогих и высокоэффективных ИИ-моделей. 
Источник изображения: Unsplash, Sollen Feyissa Релиз алгоритмов DeepSeek-V3 и R1, которые по заявлению разработчиков были обучены с использованием лишь части вычислительных мощностей, используемых американскими конкурентами, вызвал бурную реакцию в отрасли. Инвесторы усомнились в целесообразности огромных вложений в ИИ-инфраструктуру, которые требуются западным компаниям для обучения передовых моделей. Сдержанная реакция на выпущенную в конце прошлой недели предварительную версию DeepSeek-V4 подчёркивает, как быстро меняется положение дел в отрасли. Рынки успели привыкнуть к недорогим и эффективным моделям, разработанным в условиях ограниченных вычислительных мощностей. За счёт этого исчез элемент неожиданности. «Этот анонс прошёл по довольно предсказуемому пути», — отметил главный аналитик Omdia Лиан Джи Су (Lian Jye Su). Он добавил, что с момента прошлого анонса DeepSeek достижения разработчиков в области архитектуры и эффективности ИИ-моделей активно изучаются в промышленных и академических кругах. Данные бенчмарков подтверждают эту точку зрения. Согласно Artificial Analysis, DeepSeek-V4 Pro показывает значительное улучшение производительности по сравнению с предыдущими версиями, но в целом входит в число ведущих моделей с открытым кодом, а не явно превосходит конкурентов. При этом конкуренты, такие как Kimi и Qwen, постепенно сокращают отставание. Это контрастирует с тем, что было в прошлом году. На тот момент DeepSeek, казалось, вырвалась вперёд среди китайских конкурентов, что привело к быстрому распространению алгоритма на домашнем рынке и помогло компании закрепиться в глобальных масштабах. Аналитики считают, что такой результат был вызван совпадением факторов: завышенные оценки американских технологических компаний, ожидания продолжающегося доминирования нескольких крупнейших игроков и появление относительно неизвестного китайского стартапа, показавшего неожиданно сильный результат. «Ожидание появления новых игроков теперь заложено в оценки», — рассказал Су, отметив, что рынки стали более реалистично оценивать возможности и ограничения ИИ. В это же время усилилась конкуренция внутри Китая, поскольку несколько компаний выпускают всё более производительные модели, тем самым подрывая лидерство DeepSeek. В понедельник фондовые рынки Южной Кореи и Тайваня достигли новых максимумов на фоне оптимизма инвесторов в отношении ценных бумаг, связанных с ИИ. В компании Ankura China Advisors заявили, что значение модели DeepSeek-V4 заключается меньше в рыночном влиянии и больше в гонке США и Китая за технологическое превосходство. Там отметили адаптацию новой модели к работе на базе ускорителей Huawei, что стало необходимостью на фоне жёстких экспортных ограничений со стороны США, из-за которых китайские компании не имеют доступа к передовым ускорителям Nvidia. «Фактор "вау" был в прошлом году — он уже учтён в ценах. Теперь важно, сможет ли Китай продолжать продвигаться в разработке ИИ и, возможно, делать это на ускорителях собственного производства — геополитические последствия были бы значительными», — отметил представитель Ankura China Advisors. Энтузиаст запустил ИИ-модель на древнем мини-ЭВМ PDP-11 с процессором на 6 МГц и 64 Кбайт ОЗУ
14.04.2026 [17:50],
Владимир Фетисов
Ветеран из отдела разработки Microsoft Дэйв Пламмер (Dave Plummer), который в прошлом создал несколько важнейших компонентов Windows, продемонстрировал трансформерную модель ИИ, «работающую на оборудовании старше, чем большинство людей, спорящих в интернете об AGI». В опубликованном недавно видео опытный разработчик решил развеять миф об ИИ, раскрыв его «небольшой грязный секрет». 
Источник изображения: Дэйв Пламмер / YouTube Этот секрет в значительной степени раскрывается в начале описания к видео разработчика. «Дэйв использует PDP-11 для обучения настоящей нейронной сети, включающей трансформеры и механизм внимания, чтобы вы могли увидеть их в самом простейшем виде», — сказано в описании. Речь о системе PDP-11 возрастом 47 лет, которая оснащена процессором с рабочей частотой 6 МГц и 64 Кбайт оперативной памяти. На этом устройстве работает трансформерная ИИ-модель под названием Attention 11, написанная на ассемблере PDP-11 Дамьеном Буре (Damien Buret). На первый взгляд задача, которую PDP-11 «научится» выполнять, кажется элементарной: устройство должно строить обратную последовательность из восьми чисел. Однако модель должна усвоить определённое структурное правило, а не запоминать примеры из обучения, чтобы успешно справляться с обработкой любых входящих данных. Пламмер отмечает, что в этом отражается базовый принцип, лежащий в основе современных языковых моделей, таких как ChatGPT. Несмотря на использование специально созданной для PDP-11 трансформерной модели, Пламмеру потребовалось провести оптимизацию системы в виду ограничений в плане доступных вычислительных мощностей. Интересно то, что в конечном счёт получилась модель, имеющая всего 1216 параметров. Она используется вычисления с фиксированной точкой, вычисления для прямого прохода ужаты до 8-битной точности, а каждый такт оптимизирован, чтобы машина смогла завершить обучение в разумные сроки. «Мы наблюдаем упрощённую анатомию самого обучения. Модель начинает глупой. Количество ошибок изначально высоко. Точность спотыкается на каждом шагу, как человек, пытающийся собрать мебель из IKEA в кузове движущегося фургона. А затем где-то на этом пути веса постепенно выстраиваются в определённый паттерн. И механизм внимания обнаруживает правило переворота последовательности. И машина в результате пересекает ту невидимую черту — от угадывания к знанию», — рассказал Пламмер. Результаты эксперимента по обучению ИИ на древнем устройстве с процессором на 6 МГц оказались довольно неожиданными. Энтузиаст обучил модель до 100 % точности в задаче построения обратной последовательности из чисел примерно за 350 шагов обучения. На PDP-11/44 с платой кэш-памяти на это ушло около 3,5 минут. По сути, Пламмер попытался доказать, что в современных ИИ-системах используется та же механика, т.е. большое количество арифметики, повторение шагов и исправление ошибок для улучшения результатов. «Эта старая машина не мыслит в каком-то мистическом смысле. Она просто выполняет арифметические действия, чтобы обновить несколько тысяч тщательно сохранённых чисел. И в этом вся суть. Обаяние современного ИИ в основном исходит от выполнения этого в ошеломляющем масштабе. Но сам фундаментальный процесс обучения уже полностью представлен здесь в миниатюре», — объяснил Пламмер. Автор культовой Papers, Please не спешит рассказывать о новой игре, опасаясь копирования её идей с помощью нейросетей
07.04.2026 [15:23],
Игнатий Колыско
Независимый разработчик Лукас Поуп (Lucas Pope), автор культового симулятора инспектора пограничной службы Papers, Please и детективной головоломки Return of the Obra Dinn, решил кардинально изменить свой подход к общению с аудиторией. О причинах этого решения он рассказал в последнем интервью. 
Источник изображения: GOG.com В рамках подкаста с главой издательства No More Robots Майком Роузом (Mike Rose) и создателем студии Vlambeer Рами Исмаилом (Rami Ismail) Поуп признался, что опасается кражи своих идей недобросовестными пользователями. По мнению автора Papers, Please, в эпоху развития нейросетей сделать это намного проще, чем раньше. «Но я также люблю говорить о том, над чем работаю, и сейчас, мне кажется, ситуация немного изменилась, — пояснил автор. — Я не хочу делиться своими наработками, потому что опасаюсь, что они будут скопированы с помощью ИИ». Лукас Поуп в рамках всё того же подкаста рассказал о своём страхе не оправдать высокие ожидания фанатов. По мнению разработчика, две его предыдущие работы снискали большой успех в том числе благодаря везению. В какой-то момент Поуп даже задумывался о том, чтобы уйти на пике славы, но желание сделать что-то новое победило. Сейчас он по-прежнему не планирует нанимать команду и последние шесть лет просто получает удовольствие от самого процесса написания кода в одиночку, а также рисования объектов и написания музыки для новой игры. «Википедия» целиком и полностью запретила статьи, написанные нейросетями
26.03.2026 [18:51],
Сергей Сурабекянц
Новая политика «Википедии» больше не позволит редакторам писать или переписывать статьи с помощью нейросетей. В обновлении, добавленном в руководство «Википедии» в конце прошлой недели, в качестве причины запрета указывается тенденция к нарушению статьями, написанными с помощью ИИ, «нескольких основных правил контента "Википедии"». 
Источник изображений: «Википедия» Пока это изменение касается англоязычной версии «Википедии» и по-прежнему позволяет редакторам использовать ИИ в определённых сценариях, которые включают использование больших языковых моделей для «предложения базовой корректуры» в текстах, если это «не добавляет собственного контента». Редакторы также могут использовать ИИ для перевода статей из «Википедии» на другом языке на английский, однако они по-прежнему должны соблюдать правила сайта, которые требуют от редакторов достаточного знания исходного языка для подтверждения точности перевода. В тексте новой политики «Википедии» отмечается, что стиль письма некоторых людей «может быть схож со стилем большой языковой модели», и редакторам потребуется опираться не только на «стилистические или лингвистические признаки», чтобы обосновать потенциальные ограничения на их возможности редактирования. Руководство рекомендует «учитывать соответствие текста основным правилам контента и недавние правки соответствующего редактора». Это последнее изменение в руководстве Википедии вызвало длительную дискуссию между редакторами, но в итоге было принято подавляющим большинством голосов. Редакторы пришли к заключению, что новая политика «направлена на явно проблемные вопросы использования больших языковых моделей, при этом оставляя место для того, что считается достойным использованием». Редакторы «Википедии» уже несколько месяцев борются со статьями, созданными ИИ, что ранее уже привело к внедрению сообществом новой политики, позволяющей «быстро удалять» плохо написанные статьи. Редакторы также создали WikiProject AI Cleanup, инициативу, призванную бороться с контентом, написанным ИИ, и помогать другим в его выявлении. 15 января «Википедия» отметила юбилей — 25 лет с момента запуска. За это время скромный сайт с сотней страниц превратился в один из крупнейших источников знаний в интернете. Сегодня на платформе размещено более 65 миллионов статей на множестве языков, которые ежемесячно получают около 15 миллиардов просмотров. Термодинамику научили вычислять — энергоэффективность улетела в космос
07.03.2026 [00:53],
Геннадий Детинич
Вся история вычислений — это непрерывная борьба с помехами и потерями энергии в процессе рассеяния тепла. Мощное железо решает вопрос производительности, но излишки тепла растут экспоненциально, и даже хороший кулер или СЖО не в силах справиться. Но, что если не бороться с теплом и с тепловым шумом, как источником ошибок, а взять его на вооружение? А так можно было? Действительно, так можно. 
Источник изображения: Berkeley Lab Исследователипредложили концепцию термодинамического вычисления, когда тепловой шум — случайные флуктуации электронов из-за нагрева и остывания — перестаёт быть помехой и становится источником энергии для вычислений. В классических компьютерах и квантовых системах шум подавляется с огромными энергозатратами на охлаждение и повышение мощности сигналов, но предложенная учёными система работает на предельно малом энергетическом масштабе, близком к энергии теплового шума. Систему просто оставляют в покое и естественные тепловые колебания сами переводят её из одного состояния в другое, выполняя полезные операции. «Термодинамические вычисления — это вычисления, питаемые шумом», — как лаконично объяснили авторы исследования. Отметим, что ранее подобный метод вычислений был продемонстрирован для уравнений линейной алгебры. Нейронные сети требуют нелинейных расчётов, возможность которых на термодинамических системах впервые показала команда учёных. Тем самым появляется возможность проводить сложные нелинейные расчёты, аналогичные нейронным сетям, при комнатной температуре без активного энергопотребления на подавление шума. Команда разработала дизайн «термодинамических нейронов» — нелинейных компонентов, которые ведут себя как нейроны в сети, позволяя выполнять произвольные нелинейные расчёты. Ещё одним недостатком предыдущих подходов было то, что перед началом вычислений приходилось долго ждать, пока система придёт в равновесное состояние. Новый подход позволяет избежать ожидания и начинать вычисления в любой момент состояния системы, не дожидаясь наступления термодинамического равновесия. Поскольку система стохастическая (каждый запуск даёт немного разные результаты из-за шума), стандартный градиентный спуск для выполнения алгоритма не подходит. Поэтому исследователи рассчитали эволюционные алгоритмы на суперкомпьютере Perlmutter (NERSC), оценив триллионы стохастических траекторий. Алгоритм оптимизировал параметры цепей, чтобы система выдавала нужный результат в заданный момент времени. Так сказать, нашли, как лучше всего конвертировать шум в работу нейросетей. Безусловно, использование суперкомпьютера на этапе поиска наиболее эффективных траекторий термодинамических изменений в схемах — это колоссальные энергозатраты. Но после обучения всё можно воплотить в железе, в частности, для получения ответов в процессе «простого» остывания процессора без существенного внешнего питания. Моделирование показало, что инференс (вывод) происходит с экстремально низким энергопотреблением — на порядки эффективнее классических чипов для задач машинного обучения. Поручите выдачу ответов на поисковые запросы такому «ленивому» процессору, и сэкономите прорву энергии! Кажется фантастикой? А ведь такие процессоры уже есть и, похоже, их станет ещё больше. Энергогенерация в нашем мире не резиновая и её резервы уже заканчиваются. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



