|
Опрос
|
реклама
Быстрый переход
Учёные натренировали робопса играть в бадминтон — он самообучается, но пока играет на уровне любителя
11.06.2025 [18:26],
Сергей Сурабекянц
Группа учёных из ETH Zürich под руководством робототехника Юньтао Ма (Yuntao Ma) представила робота, способного играть в бадминтон. Робот ANYmal внешне напоминает миниатюрного жирафа с ракеткой «в зубах», и создан на базе четвероногого промышленного робота, предназначенного для работы в нефтегазовой отрасли, от компании ANYbotics. Вес ANYmal составляет около 50 кг, длина корпуса — менее метра, а ширина — менее 50 сантиметров. 
Источник изображений: ETH Zürich На робота установлен манипулятор с несколькими степенями свободы, в который закреплена бадминтонная ракетка. Отслеживание полёта волана и мониторинг окружающей среды осуществляется с помощью стереоскопической камеры. По словам разработчиков, на создание робота ушло около пяти лет. При разработке системы управления ANYmal были использованы современные методы обучения моделей ИИ с подкреплением. «Вместо того чтобы строить продвинутые модели, мы смоделировали робота в виртуальной среде и позволили ему научиться двигаться самостоятельно», — пояснил Ма. Обучение разбивалось на повторяющиеся блоки, в каждом из которых робот должен был предсказать траекторию полёта волана и попытаться его отбить. В ходе этого процесса ANYmal, как настоящий спортсмен, также определял пределы своих физических возможностей.  Обучение было направлено на развитие зрительно-моторной координации, аналогичной той, которой обладают спортсмены-люди. Модель восприятия, основанная на данных с камеры в реальном времени, обучала робота удерживать волан в поле зрения, несмотря на помехи и ошибки отслеживания. «Представьте, что робот занимает позицию для приёма волана, — рассказал Ма. — Если он движется медленно, шансы на успех снижаются. Если быстро — тряска камеры увеличивает погрешность отслеживания. Это компромисс, и мы хотели, чтобы он научился с ним справляться». В результате обучения с подкреплением робот освоил принципы правильного позиционирования на площадке. Он пришёл к выводу, что после удачного удара наилучшая стратегия — возврат в центр площадки к задней линии. ANYmal научился самостоятельно вставать на задние «лапы», чтобы лучше видеть приближающийся волан, понял, как избегать падений и оценивать разумность риска с учётом своей ограниченной скорости. Он также воздерживался от попыток, заведомо обречённых на неудачу, тем самым снижая вероятность повреждений.  Результаты реальных матчей с людьми показали, что ANYmal как бадминтонист пока что не более чем любитель. Его время реакции составляло около 0,35 секунды, в то время как средний человек реагирует за 0,2–0,25 секунды, а элитные игроки с натренированными рефлексами и развитой мышечной памятью сокращают это время до 0,12–0,15 секунды. Ещё одной проблемой является ограниченное поле зрения камеры робота. Учёные планируют продолжать развитие навыков ANYmal. В частности, они намерены сократить время реакции путём предсказания траектории волана на основе позы соперника перед ударом. Также предполагается оснастить робота более продвинутыми камерами со сверхнизкой задержкой. Модернизации потребуют и приводы манипуляторов. Сам по себе робот, играющий в бадминтон, — скорее курьёз, чем практическое устройство. Однако опыт, полученный в процессе разработки, может быть масштабирован для самых разных задач. «Я думаю, что предлагаемая нами архитектура обучения будет полезна в любом приложении, где необходимо балансировать между восприятием и управлением — например, при подъёме предметов, а также их ловле и броске», — заключил Ма. Китайская ИИ-модель Kimi k1.5 освоила мультимодальные рассуждения и превзошла OpenAI o1
30.01.2025 [19:29],
Сергей Сурабекянц
Если 2024 год стал годом клонов ChatGPT, то 2025 год обещает стать эрой рассуждающих моделей ИИ, а лидерство в этой области захватывают китайские лаборатории. На прошлой неделе много шума наделала DeepSeek со своей рассуждающей моделью R1. А на днях Moonshot AI представила мультимодальную Kimi k1.5, которая обгоняет в тестах OpenAI o1, а стоит в разы меньше. Эти модели представляют собой смену представления о «мыслительном процессе» ИИ. 
Источник изображения: kimi.ai Новые модели далеко ушли от банального пересказа Википедии. Им по силам сложные проблемы — от решения головоломок до объяснения квантовой физики. А Kimi k1.5 уже успела заработать звание «первого настоящего конкурента o1». По оценкам экспертов, Kimi k1.5 — это не просто ещё одна модель ИИ — это скачок вперёд в мультимодальном рассуждении и обучении с подкреплением. Kimi k1.5 от Moonshot AI объединяет текст, код и визуальные данные для решения сложных задач, порою в разы превосходя таких лидеров отрасли, как GPT-4o и Claude Sonnet 3.5 в ключевых тестах. Контекстное окно Kimi k1.5 на 128 тыс. токенов позволяет модели «за один подход» обрабатывать объём информации, эквивалентный солидному роману. В математических задачах модель может планировать, отражать и корректировать свои шаги на протяжении сотен токенов, имитируя решение проблемы человеком. Вместо того, чтобы повторно генерировать полные ответы, Kimi использует фрагменты предыдущих траекторий, повышая эффективность и сокращая затраты на обучение. 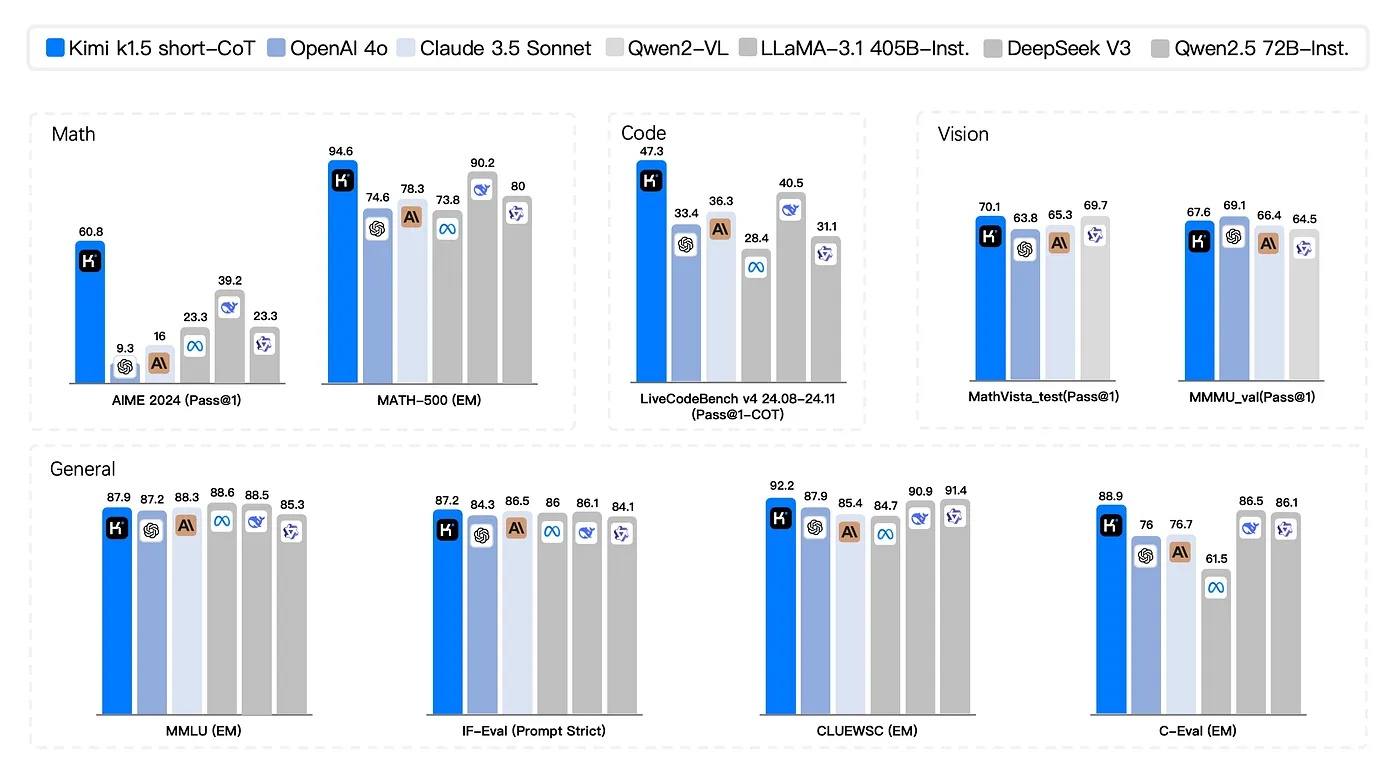
Источник изображений: medium.com Традиционный подход, основанный на принципах обучения с подкреплением, предполагает использование сложных инструментов, таких как поиск по дереву Монте-Карло или сети ценностей. Команда Moonshot AI отказалась от них и создала упрощённый фреймворк на базе обучения с подкреплением, используя штраф за длину и баланс между исследованием и эксплуатацией. В результате разработчикам удалось создать модель, которая обучается быстрее и избегает «чрезмерного обдумывания» — распространённой ошибки, когда ИИ тратит вычислительные ресурсы на ненужные шаги. Kimi k1.5 успела показать себя как мощный инструмент визуализации и одновременной работы с текстом. Модель умеет анализировать диаграммы, решать геометрические задачи и отлаживать код — в тесте MathVista модель показала точность 74,9 %, объединив текстовые подсказки с графическими диаграммами. 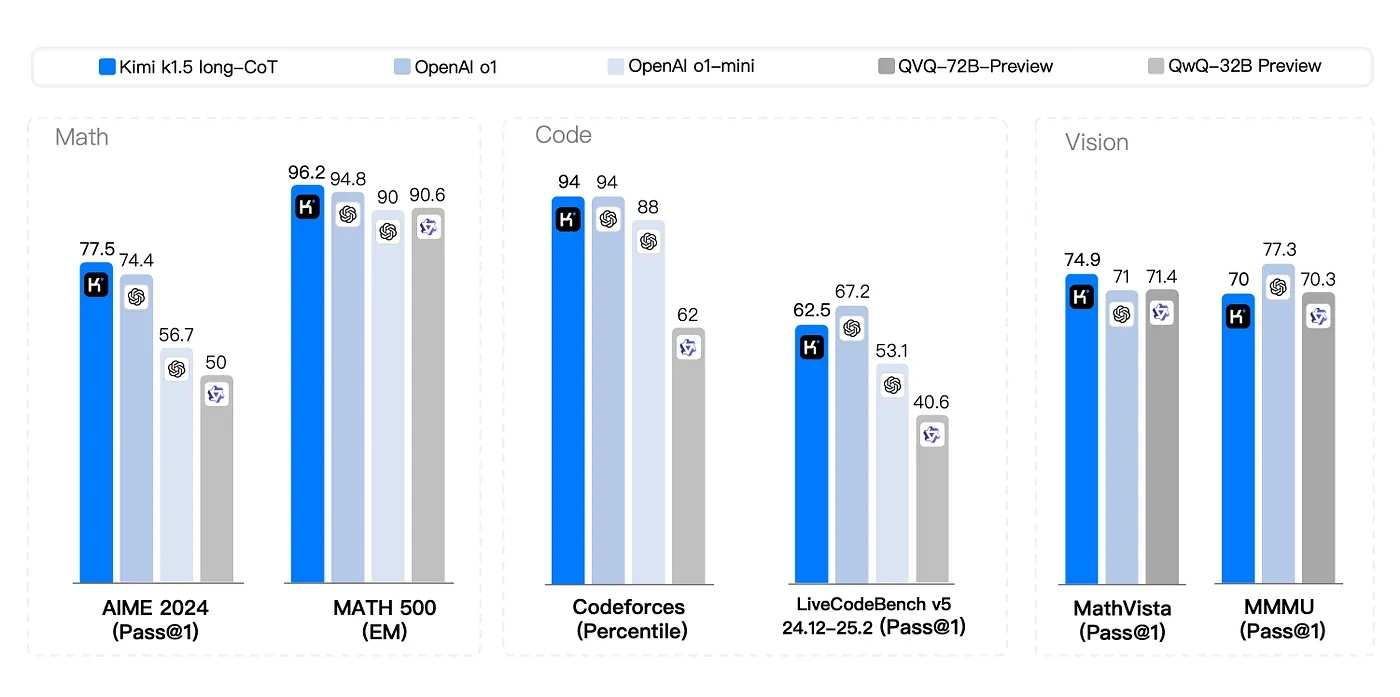 Исследователи Moonshot AI, вместо того чтобы полагаться на мощные, но медленные длинноцепочечные рассуждения (Long-CoT), использовали метод Long2Short («длинные-в-короткие»), добившись более лаконичных и быстрых ответов. Для этого применялись следующие методы:
Даже при прямом сравнении Kimi K1.5 оставляет GPT-4o и Claude Sonnet 3.5 далеко позади. Разработчикам Moonshot AI удалось оптимизировать процесс обучения с подкреплением благодаря:
По мнению экспертов, Kimi K1.5 — это не просто технологический прорыв, а взгляд в будущее ИИ. Объединяя обучение с подкреплением с мультимодальным рассуждением, эта модель решает задачи быстрее, умнее и эффективнее. |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex


