|
Опрос
|
реклама
Быстрый переход
«Голосовое протезирование с ИИ» превратит мозговые волны немых людей в беглую речь
21.04.2025 [18:27],
Сергей Сурабекянц
Немало людей страдают от потери речи в результате заболеваний, хотя их когнитивные функции остаются незатронутыми. Поэтому на волне прогресса в области ИИ многие исследователи сосредоточились на синтезе естественной речи (вокализации) с помощью комбинации мозговых имплантатов и нейросети. В случае успеха эта технология может быть расширена для помощи людям, испытывающим трудности с вокализацией из-за таких состояний, как церебральный паралич или аутизм. 
Источник изображения: unsplash.com Долгое время основные инвестиции и внимание учёных были сосредоточены на имплантах, которые позволяют людям с тяжёлыми формами инвалидности использовать клавиатуру, управлять роботизированными руками или частично восстанавливать использование парализованных конечностей. Одновременно многие исследователи сконцентрировались на разработке технологий вокализации, которые преобразует мыслительные модели в речь. «Мы добиваемся большого прогресса. Сделать передачу голоса от мозга к синтетическому голосу такой же плавной, как диалог между двумя говорящими людьми — наша главная цель, — рассказал нейрохирург из Калифорнийского университета Эдвард Чанг (Edward Chang). — Используемые нами алгоритмы ИИ становятся быстрее, и мы учимся с каждым новым участником наших исследований». В марте 2025 года Чанг с коллегами опубликовали статью в журнале Nature Neuroscience, в которой описали работу с парализованной женщиной, которая не могла говорить в течение 18 лет после перенесённого инсульта. При помощи учёных она обучала нейронную сеть, безмолвно пытаясь произнести предложения, составленные из 1024 разных слов. Затем звук её голоса был синтезирован путём потоковой передачи её нейронных данных в совместную модель синтеза речи и декодирования текста. 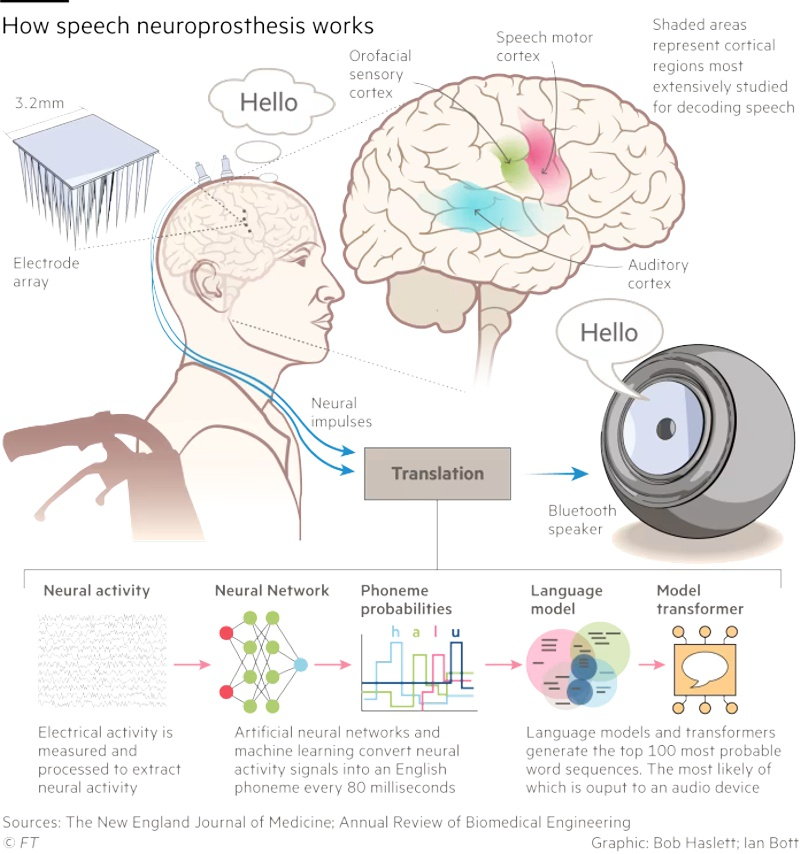
Источник изображения: New England Journal of Medicine Технология позволила сократить задержку между мозговыми сигналами пациента и полученным звуком с первоначальных восьми до одной секунды. Этот результат уже сопоставим с естественным для обычной речи временным интервалом в 100–200 миллисекунд. Медианная скорость декодирования системы достигла 47,5 слов в минуту, что составляет примерно треть от скорости обычного разговора. Аналогичные исследования были произведены компанией Precision Neuroscience, причём её генеральный директор Майкл Магер (Michael Mager) утверждает, что их подход позволяет захватывать мозговые сигналы с более высоким разрешением за счёт «более плотной упаковки электродов». На данный момент Precision Neuroscience провела успешные эксперименты с 31 пациентом и даже получила разрешение регулирующих органов оставлять свои датчики имплантированными на срок до 30 дней. Магер утверждает, что это позволит в течение года обучить нейросеть на «крупнейшим хранилище нейронных данных высокого разрешения, которое существует на планете Земля». Следующим шагом, по словам Магера, будет «миниатюризация компонентов и их помещение в герметичные биосовместимые пакеты, чтобы их можно было навсегда внедрить в тело». 
Источник изображения: UC Davis Health Самым серьёзным препятствием для разработки и использования технологии «мозг-голос» является время, которое требуется пациентам, чтобы научиться пользоваться системой. Ключевой нерешённый вопрос заключается в степени различия шаблонов реагирования в двигательной коре — части мозга, которая контролирует произвольные действия, включая речь, — у разных людей. Если они окажутся схожими, предварительно обученные модели можно будет использовать для новых пациентов. Это ускорит процесс индивидуального обучения, который занимает десятки или даже сотни часов. Все исследователи вокализации солидарны в вопросе о недопустимости «расшифровки внутренних мыслей», то есть того, что человек не хочет высказывать. По словам одного из учёных, «есть много вещей, которые я не говорю вслух, потому что они не пойдут мне на пользу или могут навредить другим». На сегодняшний учёные ещё далеки от вокализации, сопоставимой с обычным разговором среднестатистических людей. Хотя точность декодирования удалось довести до 98 %, голосовой вывод происходит не мгновенно и не в состоянии передать такие важные особенности речи, как тон и настроение. Учёные надеются, что в конечном итоге им удастся создать голосовой нейропротез, который обеспечит полный экспрессивный диапазон человеческого голоса, чтобы пациенты могли контролировать тон и ритм своей речи и даже петь. |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



