|
Опрос
|
реклама
Быстрый переход
AMD Ryzen 9700X на частоте 6,3 ГГц обогнал разогнанный до 7,1 ГГц Intel Core i9-14900KF в тесте AVX
17.09.2024 [02:19],
Николай Хижняк
Энтузиаст с псевдонимом Skatterbencher разогнал процессор AMD Ryzen 9700X до 6,3 ГГц с помощью жидкого азота, и тот оказался быстрее разогнанного в тех же условиях до 7,1 ГГц флагманского процессора Intel Core i9-14900KF в тесте производительности OCCT. Оверклокер с помощью восьмиядерного процессора AMD на архитектуре Zen 5 установил новый рекорд производительности в бенчмарке OCCT AVX, набрав в нём 269,35 очков. 
Источник изображений: YouTube / Skatterbencher Рекорд был поставлен при работе процессора Ryzen 7 9700X на частоте всего 6318 МГц. Для разгона SkatterBencher не просто поменял множитель частоты процессора и настройки напряжения. Он использовал комбинацию методов, включавших тонкую настройку шины BCLK, функции Precision Boost Overdrive, AMD Curve Optimizer и Curve Shaper, чтобы позволить алгоритму Ryzen Precision Boost работать на частоте выше 6 ГГц под жидким азотом.  С финальным результатом 269,35 очков разогнанный Ryzen 7 9700X превзошёл результат разогнанного до 7,1 ГГц Core i9-14900KF (также с использованием жидкого азота) в том же тесте. Флагман Intel набрал на 14 очков меньше, даже несмотря на то, что его частота была почти 800 МГц выше. Однако в SSE-версии теста OCCT процессор Ryzen 7 9700X оказался не так силён. Он не смог обогнать Core i9-14900KF и набрал всего 127,79 баллов, что на 8,76 меньше, чем у чипа Intel Raptor Lake. 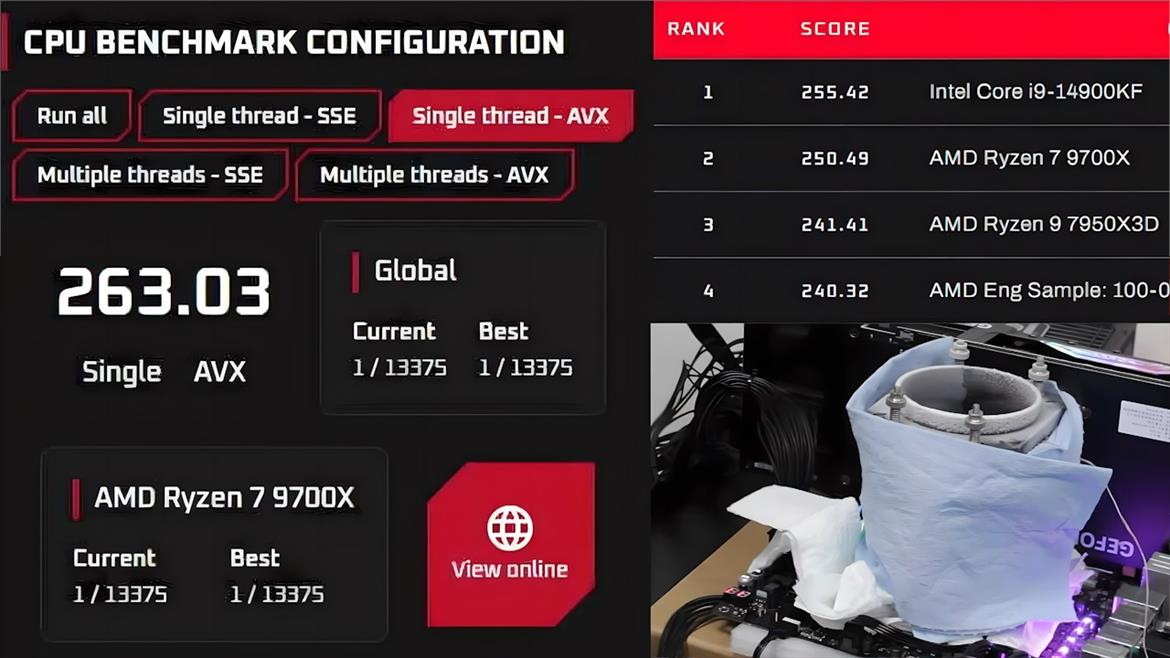 В CPU-Z разогнанный Ryzen 7 9700X набрал 1003 балла в однопоточном испытании производительности и 10 805 баллов в многопоточном. Skatterbencher также смог разогнать Ryzen 7 9700X до 6,8 ГГц, но отключив при этом SMT (многопоточность). В однопоточном тесте Geekbench 6 разогнанный до 6,3 ГГц процессор AMD набрал 3902 балла, а в многопоточном — 21 135 очков. Наша тестовая лаборатория признала Ryzen 7 9700X провальным, но признала заслуги самой архитектуры Zen 5. Результат разгона SkattterBencher продемонстрировал силу архитектуры AMD Zen 5, хоть для этого и понадобилось использовать жидкий азот. Zen 5 — первая архитектура AMD, наделённая поддержкой AVX с полным 512-битным каналом передачи данных. Процессоры Intel Raptor Lake (Core 13-го поколения) и Raptor Lake Refresh (Core 14-го поколения), в свою очередь, не имеют никакой поддержки AVX-512, что вынуждает тот же Core i9-14900KF использовать инструкции AVX и/или AVX2 для теста OCCT. Это, безусловно, основная причина, по которой Ryzen 7 9700X смог обогнать его даже при таком серьёзном недостатке тактовой частоты. |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex


