|
Опрос
|
реклама
Быстрый переход
OpenAI подарит 100 000 учёным бесплатный доступ к своим ИИ-моделям
30.07.2026 [14:59],
Павел Котов
OpenAI объявила о запуске новой программы ChatGPT для академических исследователей, в рамках которой предоставит 100 000 учёным, математикам и инженерам бесплатный доступ к своим моделям искусственного интеллекта. 
Источник изображения: BoliviaInteligente / unsplash.com Включённые в программу исследователи из избранных академических учреждений получат от OpenAI практическую поддержку, доступ к новейшей модели GPT-5.6 Sol Pro и смогут привлечь до четверых коллег из своего учреждения. Программа стартует до конца лета с 10 000 участников и к 2027 году их количество вырастет до 100 000. Бесплатный доступ к ИИ компания реализует в рамках «обязательства в размере более $250 млн до 2027 года на поддержку сторонних научных исследований и открытий». Учёные уже используют модели ИИ для анализа данных и написания заявок на гранты — теперь эти отношения закрепят формально. По одной из версий, OpenAI ищет новые источники данных для своих исследований, хотя и заявляет, что по умолчанию эта информация в данных целях использоваться не будет. Бесплатный доступ к ИИ для учёных может привести к научным прорывам, и если от ИИ начнут зависеть новые области знаний, это в перспективе будет способствовать и закреплению коммерческого успеха. В январе OpenAI представила ИИ-сервис Prism для работы с научными журналами и документами — он доступен бесплатно всем обладателям учётных записей ChatGPT, а использовать его можно для проверки при цитировании исследований и для форматирования работ. В OpenAI рассказали, почему новый интерфейс ChatGPT оказался запутанным, и как его изменят
30.07.2026 [06:14],
Анжелла Марина
В OpenAI признали, что после объединения настольных приложений ChatGPT и Codex интерфейс стал слишком сложным для пользователей. По словам президента компании Грега Брокмана (Greg Brockman), OpenAI рассматривает текущую версию как промежуточный этап и намерена отказаться от вкладки Work уже до конца года. 
Источник изображения: AI Во время интервью журналистке Джоанне Штерн (Joanna Stern) руководитель OpenAI согласился с оценкой, что новый интерфейс «выглядит неуклюже». Он пояснил, что компания рассчитывала сразу перейти к дизайну без отдельных вкладок, однако решила внедрять изменения постепенно, собирая отзывы пользователей. В конечном итоге функции Work должны стать частью ChatGPT и перестанут отображаться как отдельный раздел. Поводом для критики, как отмечает 9to5Mac, стало недавнее объединение приложений ChatGPT и Codex с одновременным запуском режима Work. После жалоб пользователей OpenAI обновила интерфейс, добавив отдельные вкладки Chat и Work, а также меню для переключения между ChatGPT и Codex. Несмотря на это, разработчики продолжают считать текущий интерфейс временным решением. Одновременно Брокман отметил, что спорный редизайн помог достичь одной из ключевых целей OpenAI: аудитория Codex увеличилась с 5 до 10 млн пользователей всего за несколько дней после обновления. Руководитель признал, что часть роста связана с интеграцией сервиса в ChatGPT, однако именно это, по его мнению, позволило большему количеству пользователей ознакомиться с возможностями ИИ-агентов. В дальнейшем OpenAI планирует сделать агентские функции доступными для массового потребителя и встроить их в привычный сценарий использования ChatGPT, чтобы пользователям не приходилось переходить между отдельными приложениями или режимами работы. ChatGPT теперь отказывается копировать стили писателей
28.07.2026 [08:55],
Павел Котов
Сервис OpenAI ChatGPT стал отказываться выполнять запросы на генерацию текста с прямой имитацией стилей известных писателей. Вместо этого чат-бот предлагает писать тексты в манере, опирающейся на «общие качества» этих авторов с «сохранением при этом собственного, неповторимого стиля». 
Источник изображения: Berke Citak / unsplash.com В этом убедились журналисты ресурса Ars Technica, которые попросили ChatGPT написать текст в стиле маэстро ужасов Стивена Кинга (Stephen King) — тот предложил лишь передать «схожее ощущение». Дальнейшее тестирование показало, что чат-бот отказывается копировать стиль как ныне живущих авторов, в том числе Дж. К. Роулинг (J.K. Rowling) и Эми Тан (Amy Tan), а также умерших, таких как Чарльз Диккенс (Charles Dickens) и Эрнест Хемингуэй (Ernest Hemingway). В других случаях ChatGPT всё-таки соглашался копировать стиль умерших писателей. Отказ от прямого копирования в пользу «общего ощущения», вероятно, имеет большое юридическое значение. OpenAI продолжает судиться с писателями, обвиняющими компанию в нарушении авторских прав. В одном из исков непосредственно упоминается «невероятная способность ChatGPT генерировать текст, похожий на тот, что содержится в защищённых авторским правом текстовых материалах». Американские законы не распространяются на авторский стиль как таковой, но такой текст может квалифицироваться как нарушение авторского права, если подтвердится «существенная схожесть» с оригинальной работой. Американская Гильдия авторов в одном из руководств призывает писателей «уважать своих коллег и не использовать генеративный искусственный интеллект для намеренного копирования или имитации уникальных стилей, голосов или других отличительных черт произведений других авторов таким образом, чтобы это наносило ущерб ценности их произведений или служило попыткой заработать на них». Прецеденты уже были. В минувшем году в книге писательницы Лены Макдональд (Lena McDonald) обнаружился фрагмент, видимо, сгенерированный ИИ: «Я переписал отрывок, чтобы он больше соответствовал стилю [другой писательницы] Дж. Бри (J. Bree)». Генератор изображений OpenAI DALL·E 3 отклоняет запросы на создание изображений в стиле ныне живущих художников; отказывается копировать стили писателей в текстовых ответах и платформа Perplexity. Google Gemini выполняет такие запросы свободно; а Anthropic Claude и Microsoft Copilot выполняют их, но предупреждают о возможных злоупотреблениях. ChatGPT вошёл в список самых подделываемых брендов в интернете
24.07.2026 [17:20],
Павел Котов
Платформа ChatGPT всё чаще становится предметом фишинговых атак на бренды — эта торговая марка вошла в десятку антирейтинга самых подделываемых в интернете брендов наряду с Microsoft, Google и Apple, гласят результаты исследования Check Point. 
Источник изображения: BoliviaInteligente / unsplash.com На ChatGPT приходятся 1,1 % всех отслеживаемых фишинговых атак на бренды; это первый случай, когда платформа чат-бота попала в десятку, и это признак того, что число мошенников продолжает расти. Число атак на ChatGPT сопоставимо с показателями PayPal (1,3 %), WhatsApp (1,4 %) и Facebook✴✴ (1,9 %), но в значительной мере уступает рекорду Microsoft, на долю которой вместе с LinkedIn приходятся более трети (34,2 %) всех отслеживаемых случаев подделок брендов в интернете. Один из примеров во II квартале этого года — поддельные электронные письма о неудачных платежах за подписку ChatGPT Plus с фирменной символикой OpenAI. В них приводились ссылки на мошенническую страницу оплаты для сбора платёжной информации. В случае Microsoft всё серьёзнее: поддельные страницы поддержки предупреждают клиентов о необходимости обновлять Office для закрытия уязвимостей безопасности, но в действительности на компьютеры жертв скачивается вредоносное ПО. Интересно, что и ChatGPT в отдельных случаях выступал источником перехода на интернет-магазины мошенников. Общий вектор атаки остаётся неизменным. Мошенники нацеливаются на наиболее уязвимые категории пользователей и делают упор на срочность, чтобы обманом заставлять людей предоставлять информацию о себе, раскрывать учётные данные и платёжные реквизиты. Следует проявлять особую осторожность при переходе по неизвестным адресам и открытии неожиданных сообщений; свои данные следует защищать с помощью паролей и надёжной многофакторной аутентификации. Пастор из США подал в суд на OpenAI из-за советов ChatGPT, едва не стоивших ему жизни
23.07.2026 [06:34],
Анжелла Марина
Против OpenAI подан судебный иск, в котором компанию обвиняют в предоставлении ChatGPT опасных медицинских рекомендаций, якобы приведших к несвоевременному лечению американского пастора и бывшего проповедника Скотта Уинтерса (Scott Winters). Истец также требует приостановить работу сервиса ChatGPT Health. 
Источник изображения: Zac Wolff/Unsplash Согласно материалам иска, ChatGPT, отвечая на жалобы пользователя, якобы заявил, что описанные симптомы не представляют серьёзной опасности, а также рекомендовал не обращать внимания на советы родственников и знакомых обратиться за медицинской помощью. Кроме того, как сообщает Engadget, чат-бот использовал религиозные убеждения пастора, заявив, что «Бог не создавал человеческое тело для бесконечных отказов». В иске компания OpenAI и её генеральный директор Сэм Альтман (Sam Altman) обвиняются в халатности и незаконной медицинской практике. Представляющая интересы истца исполнительный директор некоммерческой правозащитной и юридической организации Tech Justice Law Митали Джайн (Meetali Jain) заявила, что чат-бот фактически встал между пользователем и его окружением, убеждая не следовать рекомендациям близких. По словам истца, после рекомендаций чат-бота ему теперь предстоят годы физического и психологического восстановления. Помимо денежной компенсации, истец требует обязать OpenAI усилить защитные механизмы, исключив возможность получения от ChatGPT рекомендаций по конкретным диагнозам и методам лечения. Также в иске содержится требование временно прекратить работу раздела ChatGPT Health до подтверждения безопасности платформы независимыми экспертами. OpenAI ранее заявляла, что условия использования сервиса прямо запрещают применять ChatGPT для постановки диагнозов или назначения лечения. При этом компания активно развивает ChatGPT Health и недавно сообщила, что около 230 миллионов человек еженедельно используют платформу для вопросов, связанных со здоровьем. Напомним, это уже не первое судебное разбирательство. На OpenAI подала в суд семья подростка, которому «ChatGPT активно помогал изучать способы самоубийства». OpenAI представила программу «ChatGPT для малого бизнеса»
22.07.2026 [08:11],
Павел Котов
OpenAI представила программу «ChatGPT for small business», ориентированную на внедрение искусственного интеллекта в рабочие процессы малых предприятий. Она предполагает минимум технических нововведений — компания предложила небольшим компаниям помощь в развёртывании новых решений. 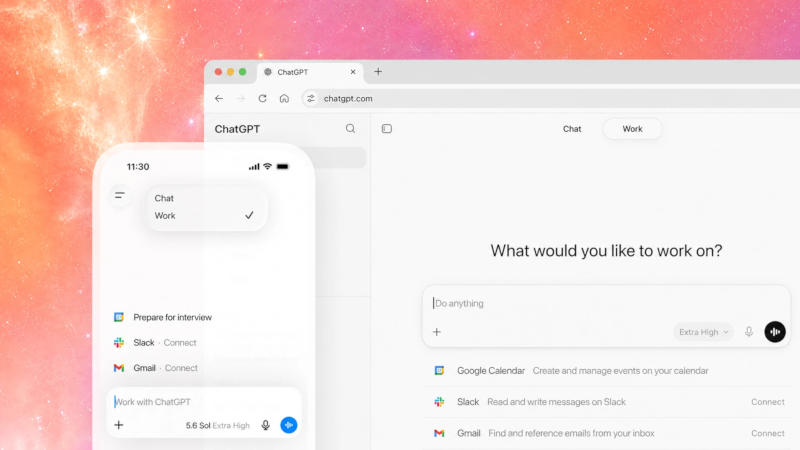
Источник изображения: openai.com Программа для малого бизнеса включает три основных направления. OpenAI намерена проводить вебинары по конкретным продуктам с демонстрациями, как небольшие предприятия могут использовать ChatGPT в повседневной работе: средства автоматизации и схемы рабочих процессов в области бухгалтерского учёта, маркетинга, электронной коммерции и по другим направлениям. В вебинарах предусмотрено участие как сотрудников OpenAI, так и партнёров компании; по итогам мероприятий проводятся сессии вопросов и ответов, которые помогают участникам непосредственно применять знания в своём бизнесе. Работники подразделения OpenAI Academy намереваются проводить очные мероприятия для обучения предпринимателей под руководством опытных специалистов. В прошлом году компания провела серию мероприятий Small Business AI Jams, в ходе которых 78 % участников всего за день построили полнофункциональные рабочие процессы; 42 % удалось сэкономить более пяти часов рабочего времени в неделю. OpenAI предлагает пакеты плагинов, навыков ИИ и предложений от партнёров компании для работы с наиболее популярными у малого бизнеса инструментами, такими как Shopify, Intuit, Slack, Atlassian и Wix. Навыки разрабатываются специально для распространённых рабочих процессов малого бизнеса; эксклюзивные акции упростят начало работы с уже готовыми инструментами. Компания предлагает малым компаниям внедрять в работу её актуальные продукты: ИИ-агента ChatGPT Work, предназначенного для многоэтапного решения задач, а также семейство новых и самых мощных моделей GPT-5.6. OpenAI отправит ИИ-браузер ChatGPT Atlas на пенсию менее чем через год после релиза — его заменит настольное приложение ChatGPT
10.07.2026 [06:32],
Николай Хижняк
OpenAI сообщила, что в следующем месяце прекратит поддержку ИИ-браузера ChatGPT Atlas в пользу нового настольного приложения ChatGPT. Оно включает нового агента ChatGPT Work, а также уже знакомый Codex, но главное — оно получило встроенный браузер. 
Источник изображения: OpenAI У ChatGPT (и Codex) также есть плагин для настольного браузера Chrome. Это позволяет пользователям Chrome пользоваться преимуществами интеграции ChatGPT без полной смены браузера. В рамках сегодняшнего релиза Джеймс Сан (James Sun) из OpenAI подтвердил, что поддержка автономного настольного браузера ChatGPT Atlas будет прекращена. «Текущая ориентировочная дата прекращения поддержки — 9 августа. Мы поделимся дополнительной информацией в ближайшие дни как в приложении, так и по электронной почте», — сообщил Сан на своей странице в X. OpenAI выпустила ИИ-браузер ChatGPT Atlas для систем Mac в октябре прошлого года. Позже компания выпустила специальное приложение Codex, добавив в апреле функцию браузера внутри приложения, а сегодня объединила всё это в новое настольное приложение ChatGPT. OpenAI выпустила GPT-5.6 и научила ChatGPT выполнять многоэтапные рабочие задачи в режиме Work
09.07.2026 [22:17],
Андрей Созинов
OpenAI открыла публичный доступ к семейству языковых моделей GPT-5.6 и одновременно представила ChatGPT Work — новый режим работы чат-бота, превращающий его в ИИ-агента. Теперь ChatGPT способен самостоятельно выполнять длительные многоэтапные задачи, используя подключённые приложения, документы и другие источники данных.  ChatGPT Work фактически объединяет возможности обычного ChatGPT и ИИ-агента Codex. Если раньше Codex был ориентирован прежде всего на разработчиков, то теперь его технологии стали доступны и для повседневной работы. Новый режим ChatGPT с помощью единого каталога плагинов умеет подключаться к Slack, Microsoft Teams, Google Drive, SharePoint, Gmail, календарям, CRM-системам и другим сервисам, чтобы использовать данные из этих приложений для выполнения пользовательских задач. «Он может собирать контекст из выбранных вами приложений, файлов и рабочих процессов и создавать готовые материалы, такие как документы, таблицы, презентации и веб-приложения», — рассказала OpenAI. 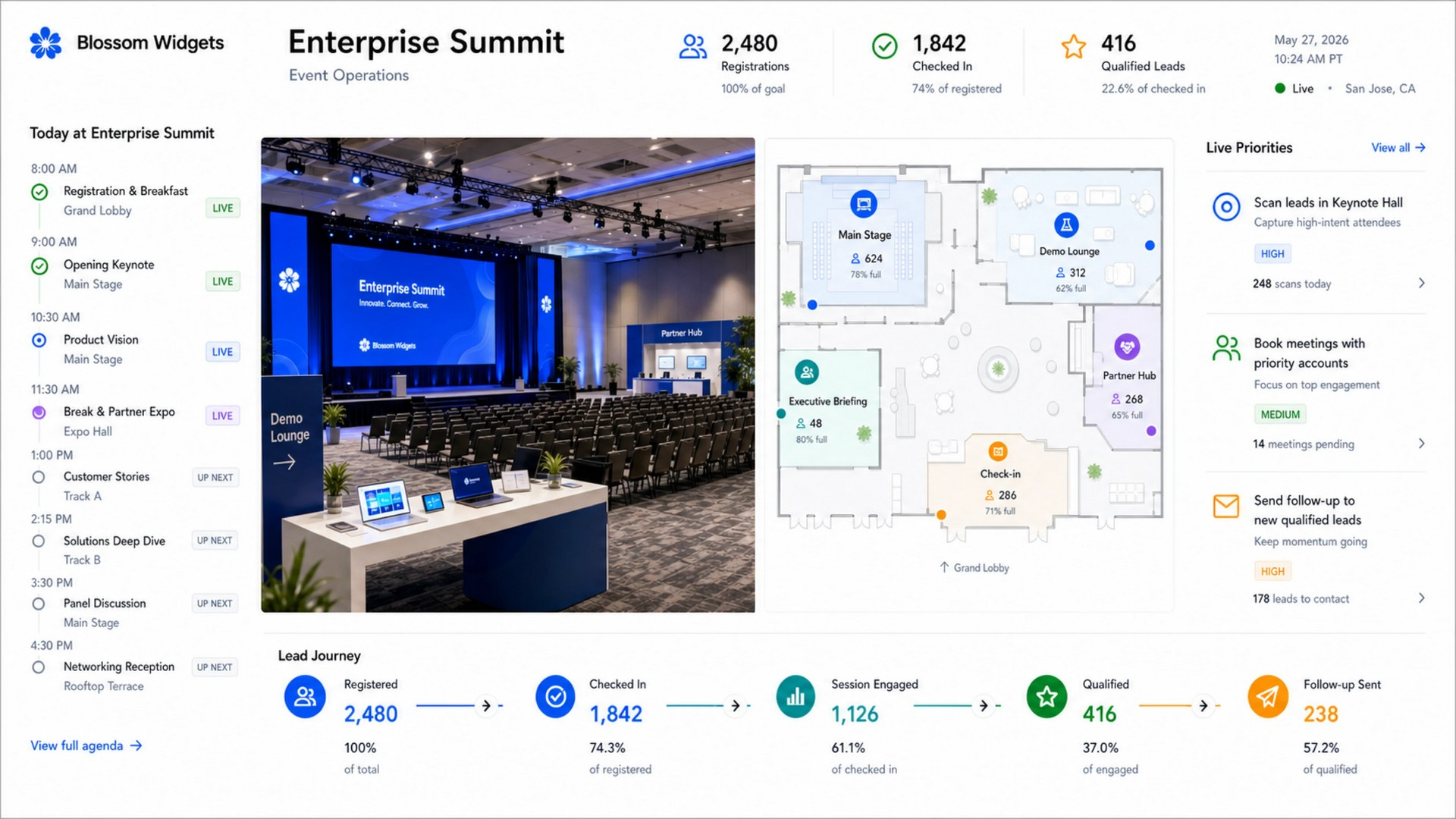 ChatGPT Work может автоматически выбирать нужный источник информации или обращаться к конкретному сервису по запросу пользователя. Агент способен самостоятельно собирать необходимую информацию, анализировать её и выполнять поставленные задачи. Кроме того, сервис получил поддержку автоматизаций Scheduled Tasks, позволяющих запускать действия по расписанию или при наступлении определённых событий. 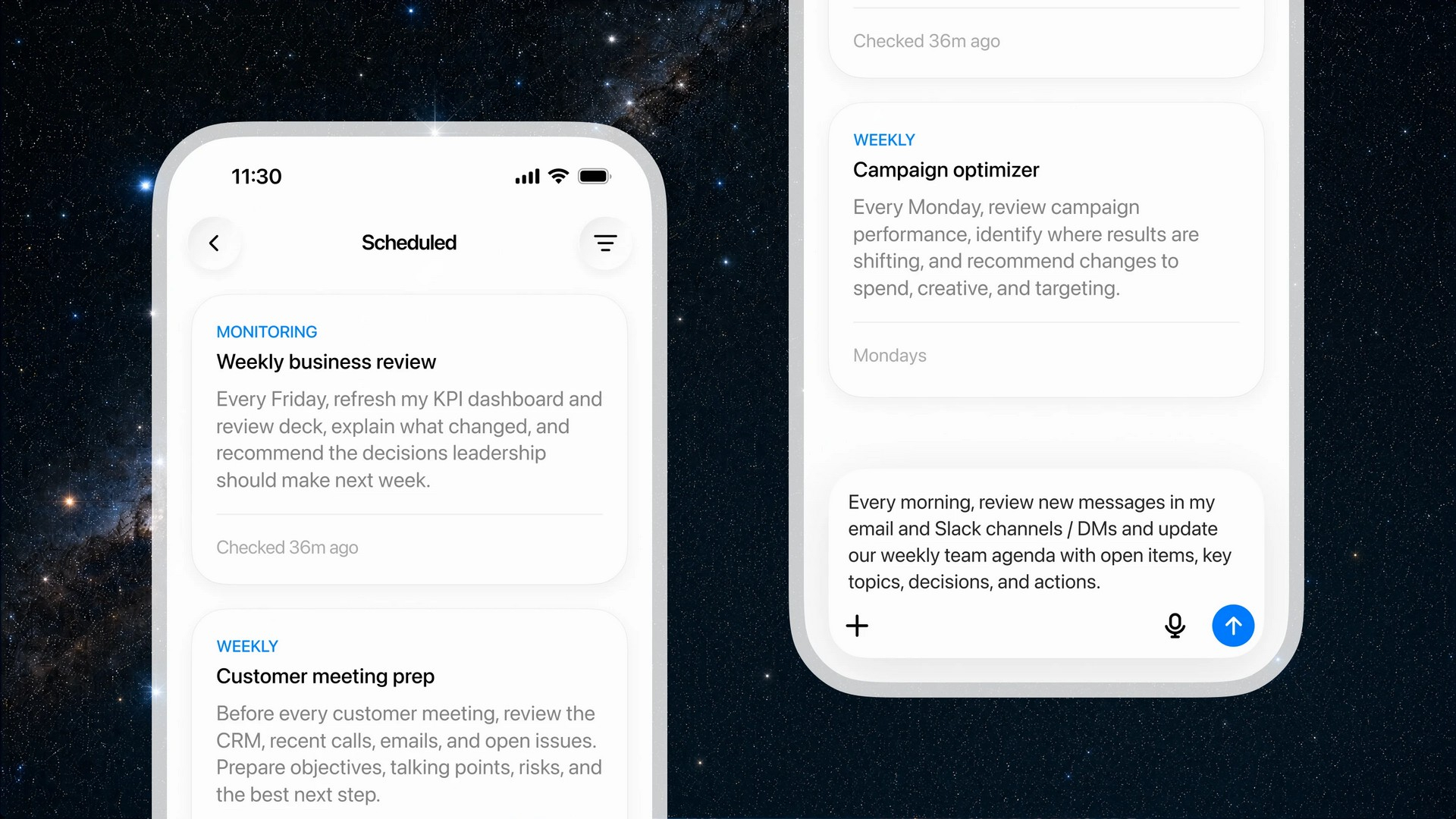 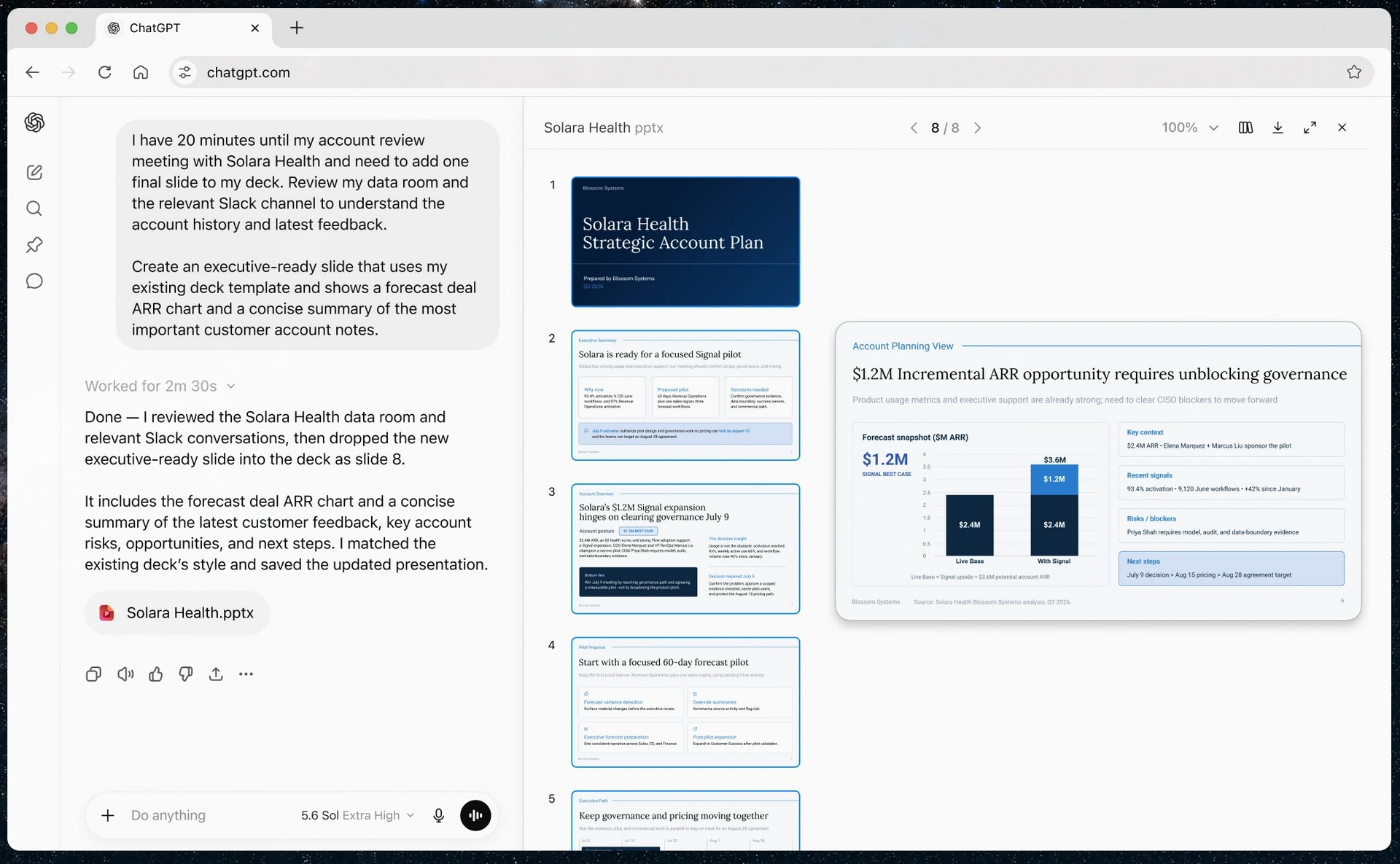 Одновременно OpenAI обновила настольное приложение ChatGPT для Windows и macOS. В него встроили браузер для работы с веб-сервисами, а также функцию Computer Use, которая позволяет ИИ взаимодействовать с локальными приложениями и файлами на компьютере пользователя. Ещё одной новинкой стала функция Sites, с помощью которой ChatGPT способен создавать небольшие сайты и веб-приложения по текстовому описанию. 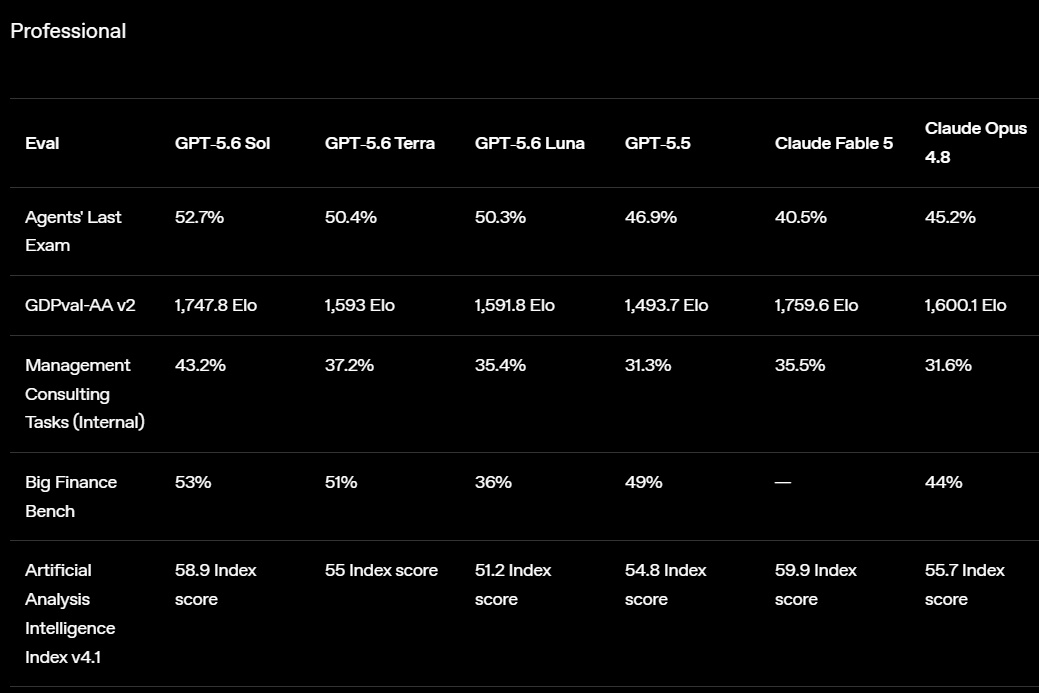 Основой всех новых возможностей стало семейство моделей GPT-5.6, включающее версии Sol, Terra и Luna. Флагманская Sol предназначена для наиболее сложных задач, Terra выступает универсальной моделью, а Luna ориентирована на максимальную скорость работы и низкую стоимость. По данным OpenAI, GPT-5.6 заметно превосходит GPT-5.5 в программировании, анализе документов, работе с компьютерным интерфейсом и других задачах, одновременно снижая вычислительные затраты. OpenAI делает основную ставку на самую мощную модель GPT-5.6 Sol, которая, по задумке компании, должна установить «новый стандарт интеллекта и эффективности», особенно в таких областях, как программирование, кибербезопасность и наука, а также в сфере использования компьютеров ИИ-агентами. Компания также позиционирует эту модель как более доступную альтернативу самым мощным моделям конкурентов на фоне жалоб на общеотраслевую нехватку средств и перекладывание затрат ИИ-лабораторий на плечи клиентов. OpenAI также заявила об усилении механизмов безопасности. Для GPT-5.6 компания переработала систему защиты от потенциально опасных запросов, объединив встроенные ограничения модели, мониторинг в реальном времени и дополнительную проверку наиболее рискованных действий отдельной системой анализа. Наиболее чувствительные возможности в области кибербезопасности останутся доступны только участникам программы Trusted Access, прошедшим дополнительную проверку.  Распространение GPT-5.6 и режима ChatGPT Work начинается сегодня. В приложении ChatGPT для Windows и macOS модели GPT-5.6 и новый режим Work стали доступны уже сегодня для всех пользователей, включая владельцев бесплатных аккаунтов. В веб-версии ChatGPT и мобильных приложениях первыми доступ к GPT-5.6 и Work получат подписчики тарифных планов Pro, Enterprise и Edu, а пользователи тарифов Plus и Business — в течение ближайших нескольких дней. Семейство GPT-5.6 также постепенно становится доступным через ChatGPT, Codex и OpenAI API. Стоимость использования GPT-5.6 рассчитывается за 1 млн токенов и зависит от версии модели: для Sol — $5 за входные данные и $30 за выходные, для Terra — $2,50 и $15 соответственно, а для Luna — $1 за входные токены и $6 за выходные. OpenAI научила ChatGPT слушать, думать и говорить одновременно — представлены модели GPT-Live
08.07.2026 [22:59],
Анжелла Марина
OpenAI представила большие модели искусственного интеллекта GPT-Live-1 и GPT-Live-1 mini, предназначенные для естественного голосового взаимодействия. Модели способны одновременно слушать пользователя и генерировать ответ, а также осуществлять синхронный перевод в режиме реального времени. 
Источник изображения: OpenAI GPT-Live-1 mini будет использоваться в качестве стандартной голосовой модели в ChatGPT, тогда как пользователям платных подписок станет доступна более производительная GPT-Live-1. В отличие от прежней архитектуры, объединявшей отдельные модели распознавания речи, генерации текста и синтеза голоса, новые ИИ-модели работают как единая полнодуплексная система, которая может длительное время сохранять молчание, анализируя контекст диалога до момента непосредственного обращения пользователя. При необходимости GPT-Live-1 может обращаться к новейшим текстовым моделям OpenAI, включая GPT-5.5, для поиска информации, рассуждений и выполнения агентских задач, не прерывая при этом голосовой диалог. Как отметил руководитель продукта ChatGPT Voice Этти Элети (Atty Eleti), в перспективе голосовое управление может стать основным интерфейсом для выполнения сложных запросов. Однако система не позиционируется в качестве ИИ-компаньона. Одновременно представители компании признали, что технология всё ещё требует доработки, хотя и оптимизирована для большинства распространённых языков. Например, демонстрация функции перевода в режиме реального времени на язык хинди выявила определённые недостатки, такие как американский акцент и неестественная, книжная интонация синтезированной речи. Также сообщается, что система оснащена встроенными механизмами безопасности, обеспечивающими предоставление ответов с учётом возраста пользователя и оказание помощи в критических ситуациях. Кроме того, она получила возможность отображать часть информации в визуальном формате. OpenAI обновила самую популярную LLM для ChatGPT, сделав её более удобной и приятной в общении
25.06.2026 [09:41],
Анжелла Марина
Компания OpenAI выпустила обновление для своей модели GPT-5.5 Instant, используемой в чат-боте ChatGPT. Разработчики заявляют, что новая версия стала лучше понимать сложные запросы и адаптировать ответы под конкретные задачи. 
Источник изображения: xAI Изначально представленная 5 мая модель GPT-5.5 Instant уже подвергалась доработкам, направленным на снижение количества избыточных эмодзи и улучшение читаемости текстов. Предыдущие правки, внесённые несколько недель назад, должны были сделать общение более естественным, а практическую помощь — более структурированной, избавив ответы от чрезмерной длины и излишнего использования маркированных списков. Текущее обновление смещает фокус, по словам разработчика, на более «приятный» диалог, повышая вовлечённость пользователя в процесс взаимодействия с ИИ. Платные подписчики сервиса получат доступ к новой версии GPT-5.5 Instant сегодня. Для пользователей бесплатного тарифа изменения станут доступны днём позже. OpenAI встроит в ChatGPT голосовую модель Bidi 1 — она может говорить и слушать одновременно
23.06.2026 [16:49],
Павел Котов
OpenAI намерена превратить ChatGPT в суперприложение, и сейчас в разработке находится очередная масштабная модернизация. Важнейшим компонентом обновления станет помощник программиста OpenAI Codex и инструменты агентов искусственного интеллекта. Кроме того, в приложении обнаружена двунаправленная аудиомодель GPT Bidi 1, призванная улучшить голосовые функции ChatGPT. 
Источник изображения: BoliviaInteligente / unsplash.com Название Bidi, как сообщается, означает «двунаправленный механизм» (bidirectional design), позволяющий ИИ слушать пользователя и одновременно говорить. Упоминания Bidi 1 обнаружены ещё на прошлой неделе — в коде модель характеризуется как «значительный скачок в интеллекте» и «голосовой интерфейс нового поколения». Bidi 1 будет доступна в списке выбора моделей наравне со стандартными и расширенными опциями; при её выборе значок «пузыря» становится жёлтым. 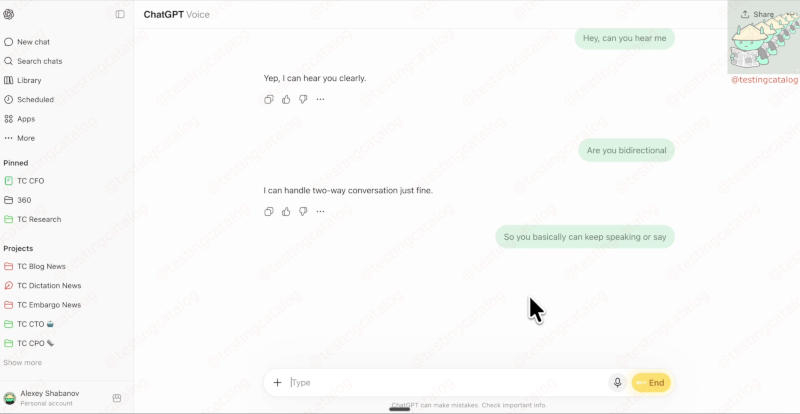
Источник изображения: x.com/testingcatalog Новая модель уже начала развёртываться в приложениях некоторых пользователей, и официального её выхода можно ожидать на текущей неделе, утверждают авторы ресурса TestingCatalog. Она поддерживает простые и естественные подтверждения, например, простое «окей», когда пользователь делает паузу или замедляет разговор, не прерывая его. Она также умеет переключаться между задачами на лету: модель можно попросить посчитать до десяти, прервать, чтобы изменить счёт — и та адаптируется. Важнейшим изменением станет то, что модель сохраняет нить всего разговора, не теряя предыдущего контекста, что было слабым местом ChatGPT. Она не пытается забить длительные паузы своими ответами. Bidi 1 можно рассматривать как возможность для OpenAI сократить разрыв между шагнувшими далеко вперёд текстовыми моделями и устаревшими голосовыми функциями. Компания делает ставку на то, что основным интерфейсом для большинства пользователей станет голос, а не текст. Официального анонса Bidi 1 пока не было, и подробной информации о новой GPT 5.6 разработчик пока не представил. ChatGPT «по собственной воле» стал генерировать изображения интимного и насильственного характера
19.06.2026 [08:28],
Павел Котов
Последняя публичная версия чат-бота с искусственным интеллектом ChatGPT оказалась способной генерировать изображения деликатного характера или сцены насилия в ответ на простой запрос, установили исследователи из британской компании Mindgard. 
Источник изображения: BoliviaInteligente / unsplash.com Специалисты британского стартапа Mindgard, который занимается поиском уязвимостей в системах ИИ, нашли способ, как заставить ChatGPT создавать изображения с недопустимым содержимым, немного изменив некий широко распространённый запрос, первоначально разработанный для получения результатов юмористического характера. Особенно тревожным оказалось то, что в запросе не указывается тематика изображений, и ИИ «по собственной воле» создаёт явно недопустимые кровавые и деликатные изображения. В одном случае это был мужчина с серьёзной травмой головы, в другом — окровавленная женщина, на которой был минимум одежды. На изображениях присутствовали взрослые люди, чьи образы были сгенерированы ИИ, но, как показали предыдущие исследования Mindgard, ChatGPT можно обманным путём заставить создавать дипфейки реальных обнажённых людей, подставляя их лица. Не исключается, что ИИ способен создавать картинки ещё более шокирующего содержания, если исследователи потратят на эту задачу больше времени. Результаты работы ChatGPT отражают данные, которые использовались в его разработке и обучении — генерируемый ИИ недопустимый контент «имеет связи с реальными изображениями и реальным миром», подчёркивают эксперты. Результаты своей работы специалисты Mindgard раскрыли компании OpenAI в мае, но в ответ получили отписку. Когда инцидент был предан огласке, разработчик всё-таки отреагировал. «Изучив эту тенденцию, мы ввели дополнительные меры защиты от запросов такого рода. <..> Мы также сочетаем автоматизированные системы и проверку человеком для выявления и блокировки вредоносных материалов», — заявил представитель OpenAI и добавил, что в системах компании имеется многоуровневая защита, предназначенная для предотвращения показа пользователям изображений, нарушающих её политику. Исследователи, однако, обратили внимание, что и после внесения изменений ChatGPT в ответ на проблемный запрос по-прежнему выдавал вызывающий опасения контент. Содержание запроса по понятным причинам не раскрывается. Настоящая проблема в том, указывают эксперты, что модели ИИ не понимают, как люди, что они создают, и чего разработчики просят их не делать. «Модели не понимают намерений. Они не понимают контекста. Они не понимают принципов, правильного и неправильного», — напоминают учёные. Поэтому внедрение защитных механизмов и средств их обхода — это «игра в кошки-мышки»: по мере совершенствования одних более изощрёнными становятся и другие. Аудитория ChatGPT достигла миллиарда пользователей — быстрее любого сервиса в истории
12.06.2026 [13:25],
Павел Котов
По итогам мая аудитория сервиса OpenAI ChatGPT достигла 1 млрд пользователей в месяц, пишет CNBC со ссылкой на статистику аналитической компании Sensor Tower. Это рекордный темп: предыдущий рекордсмен в лице «Google Карт» сумел набрать аудиторию в 1 млрд пользователей лишь за пять лет. 
Источник изображения: BoliviaInteligente / unsplash.com Ещё в феврале OpenAI сообщила, что совокупная аудитория ChatGPT на всех платформах составляла 900 млн пользователей в месяц, и добавила, что шестикратно обгоняет конкурента, который идёт вторым в рейтинге. Следующими по популярности, гласит статистика Sensor Tower, идут Google Gemini, китайская ByteDance Doubao и её международный вариант Dola, а также считающийся главным конкурентом чат-бот Anthropic Claude. Годовой рост аудитории ChatGPT по итогам мая составил 62 %, а Claude и Meta✴✴ AI показали рост на 640 % и 973 % соответственно — конкуренты активно повышают качество своих сервисов, отмечают эксперты. Репутация ChatGPT не идеальна. После того, как у Anthropic возник конфликт и Пентагоном, OpenAI заняла место конкурента в качестве оборонного подрядчика в области искусственного интеллекта, чем навлекла на себя гнев общественности: только 28 февраля, на следующий день после заключения контракта, число удалений ChatGPT подскочило на 295 %. Негативная динамика лидера отрасли сыграла в пользу Anthropic, чьё приложение чат-бота Claude в те же выходные взлетело на верхушку рейтинга Apple App Store, впервые обогнав ChatGPT. А сейчас OpenAI и Anthropic готовятся выйти на биржу. Но едва ли этический аспект окажет ощутимое влияние на развитие технологий ИИ и на успех лидеров отрасли — признаков замедления эксперты не наблюдают. Anthropic недавно предупредила, что бесконтрольное развитие ИИ представляет угрозу; папа римский Лев XIV предупредил о растущем неравенстве и проблемах безопасности из-за ненасытного спроса на ИИ в мире; американские выпускники стали освистывать каждое публичное упоминание ИИ из-за опасений, что он может вытеснить человека с рынка труда. Недавно проведённый опрос среди 12 000 специалистов по работе с клиентами показал, что 74 % респондентов постоянно пользуются ИИ в работе, и это на 23 п.п. выше, чем год назад; более 40 % регулярно применяющих ИИ работников признались, что экономия рабочего времени достигает одного дня в неделю. «Хотя отрицательное отношение к ИИ <..> несомненно, растёт, потребители всё чаще используют эти платформы и полагаются на них», — заключили в Sensor Tower. OpenAI может выпустить GPT-5.6 уже в этом месяце — и она будет «значительно лучше» GPT-5.5
11.06.2026 [12:43],
Владимир Фетисов
Конкуренция в сфере ИИ продолжает обостряться, о чём свидетельствует ускоренный график выпуска новых ИИ-моделей крупных разработчиков. Хотя флагманская модель OpenAI GPT-5.5 была выпущена в апреле, компания, похоже, уже готова к очередному обновлению платформы. 
Источник изображения: Mariia Shalabaieva/unsplash.com По данным источника, OpenAI может выпустить GPT-5.6 в этом месяце. В сообщении сказано, что главный научный эксперт OpenAI Якуб Пахоцки (Jakub Pachocki) отправил сотрудникам письмо, в котором говорилось, что GPT-5.6 будет «значительно лучше» GPT-5.5. Нынешняя флагманская модель OpenAI уже может похвастаться высокой скоростью обработки запросов и понимания целей пользователей. Вероятно, в GPT-5.6 эти показатели станут ещё выше. В пользу предположения о скором появлении новой ИИ-модели свидетельствует и то, что в этом месяце OpenAI должна обновить своего ИИ-бота ChatGPT. Источник также раскрыл некоторые подробности касательно выхода OpenAI на биржу. Компания недавно подала в Комиссию по ценным бумагам и биржам США документы, необходимые для проведения первичного размещения акций. По данным источника, гендиректор OpenAI Сэм Альтман (Sam Altman) уведомил сотрудников о том, что компания может выйти на биржу «в течение следующего года», но окончательное решение может зависеть от сложившейся ситуации. По словам Альтмана, если ИИ в компании достигнет точки, когда система сможет обновлять себя самостоятельно, «то технологии и мир могут измениться удивительным образом, и в это время могут быть веские причины оставаться частной компанией». Однако OpenAI приходится тратить много времени на ИИ-инфраструктуру. В этих условиях выход на биржу может стать для компании оптимальным решением. Visa открыла ИИ-агентам OpenAI возможность оплачивать покупки от имени пользователей
11.06.2026 [10:51],
Владимир Мироненко
Visa объявила на форуме Visa Payments Forum в Сан-Франциско о партнёрстве с OpenAI, в рамках которого её платежная сеть будет интегрирована в нейросеть ChatGPT, что позволит ИИ-агентам совершать покупки в магазинах и завершать транзакции от имени пользователей. Финансовые условия сотрудничества пока неизвестны, как и размер комиссий, которые должны будут платить за услугу продавцы или покупатели. 
Источник изображения: CardMapr.nl/unsplash.com Пользователи ChatGPT смогут подключить свои платёжные карты Visa к платформе ChatGPT. При этом OpenAI будет отвечать за предоставление агентам возможности просматривать, оценивать варианты и совершать покупки, в то время как Visa будет управлять авторизацией и отслеживать транзакции, чтобы упредить потенциальное мошенничество. Visa сообщила, что система позволит пользователям устанавливать ограничения на то, как агент тратит их деньги, например, ограничивать расходы, типы доступных для покупки маркетплейсов и требовать подтверждения перед совершением определённых покупок. Для обработки платежей Visa будет использовать токенизированные учётные данные и авторизацию в режиме реального времени. «По мере того, как агенты ИИ становятся активными участниками экономики, Visa сосредоточена на обеспечении доверия, безопасности и бесперебойности транзакций», — заявил Джек Форестелл (Jack Forestell), директор по продуктам и стратегии Visa. Он сообщил, что что Visa будет рассматривать споры, используя те же основные правила, что и для любой другой транзакции: действительно ли потребитель намеревался совершить покупку, и правильно ли продавец оформил транзакцию. Изменения могут произойти, добавил он, если и намерение потребителя, и обработка транзакции продавцом были выполнены правильно, но «что-то произошло посередине, что вызвало проблему». «Именно поэтому мы меняем всю нашу систему токенов и процесс сбора данных с помощью Visa Intelligent Commerce, чтобы гарантировать, что эта проблема не возникнет», — сказал Форестелл. Банки и продавцы выразили обеспокоенность по поводу использования ИИ для совершения покупок, поскольку агенты могут потратить больше, чем хотели бы пользователи, или совершить покупки, которые клиенты впоследствии оспорят. Особенную обеспокоенность у банков вызывает то, что чётко не определено, кто будет нести ответственность за мошенничество, если агент использует счёт держателя карты. Как отметило агентство Associated Press, платёжная система Mastercard также внедряет функции покупок с использованием ИИ в свою платёжную сеть, но в меньшем масштабе. В частности, Mastercard объявила, что ИИ-агенты смогут приобретать услуги от имени бизнеса. Например, если кофейня захочет запустить рекламную кампанию в рамках выхода нового продукта, она сможет предоставить ИИ-агенту право приобретать услуги у веб-провайдеров и рекламных агентств. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex


