|
Опрос
|
реклама
Быстрый переход
ChatGPT остаётся безусловным лидером рынка чат-ботов с ИИ
06.09.2025 [18:07],
Павел Котов
Лидером на мировом рынке чат-ботов с искусственным интеллектом с большим отрывом остаётся OpenAI ChatGPT. Второе место с большим отрывом занимает Perplexity, но серебряному призёру всё сильнее угрожает бронзовый — Microsoft Copilot. 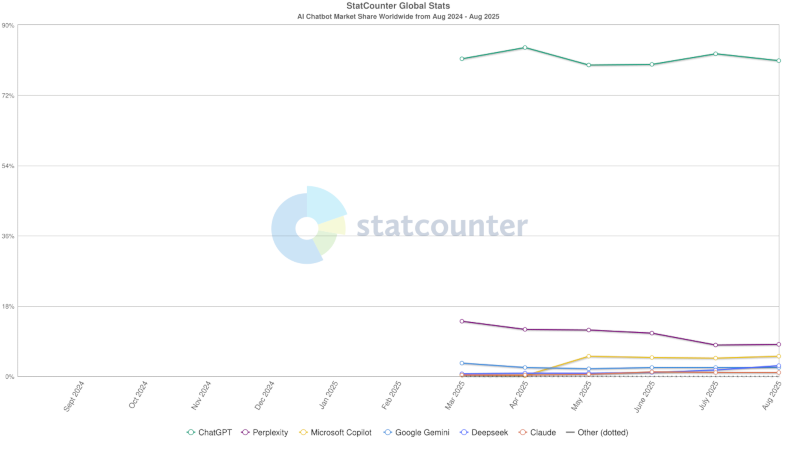
Источник изображения: statcounter.com ChatGPT занимает 80,92 % мирового рынка чат-ботов — таковы показатели статистического сервиса StatCounter, основанные на более чем 3,8 млрд просмотрах страниц на более чем 1,5 млн сайтов в период с марта по август 2025 года. Пик популярности ChatGPT пришёлся на апрель, когда у платформы было 84,2 % мировой аудитории, и несмотря на снижение показателей в последующие месяцы, чат-бот сохранил за собой более четырёх пятых мировой аудитории, значительно опережая любого конкурента. Формально ближайшим конкурентом является Perplexity, чьи позиции представляются шаткими: в марте за сервисом были 14,1 % аудитории, к июлю его популярность снизилась до 8,0 %, а в августе немного восстановилась и составила 9,0 %. Perplexity стремится выделиться, предлагая инструменты ИИ для исследований и интеграции актуальных данных. Но этого, похоже, недостаточно, чтобы противостоять крупнейшему конкуренту. Тем временем Microsoft Copilot продемонстрировал заметный рост. В марте он начал с доли 0,3 %, к маю оперативно поднялся до 5 %, а летом колебался в районе 4–5 %. Это значит, что активная интеграция ИИ в экосистемы Windows и Office работает. От ChatGPT чат-бот Copilot, конечно, значительно отстаёт, но при наличии устойчивого роста он уже соперничает с Perplexity за второе место на рынке. Если интеграция ИИ в продукты Microsoft продолжит расширяться, а доверие пользователей будет расти, Copilot имеет шансы стать самым серьёзным конкурентом лидеру. Доли остальных игроков остаются незначительными. Gemini, несмотря на обширное присутствие Google, удерживает от 1,9 % до 3,3 %; DeepSeek вырос в августе до 2,7 %; а Anthropic Claude так и не преодолел даже 1,2 %. Функция Projects в ChatGPT стала доступна бесплатным пользователям
04.09.2025 [12:05],
Антон Чивчалов
Компания OpenAI предоставила бесплатным пользователям ChatGPT доступ к функции Projects, которая раньше предлагалась только платным подписчикам. Projects — «проекты» — позволяют распределять разговоры с ИИ по темам, настраивать запросы, ограничивать доступ к данным, выбирать визуальное оформление и т. д., сообщает Engadget. 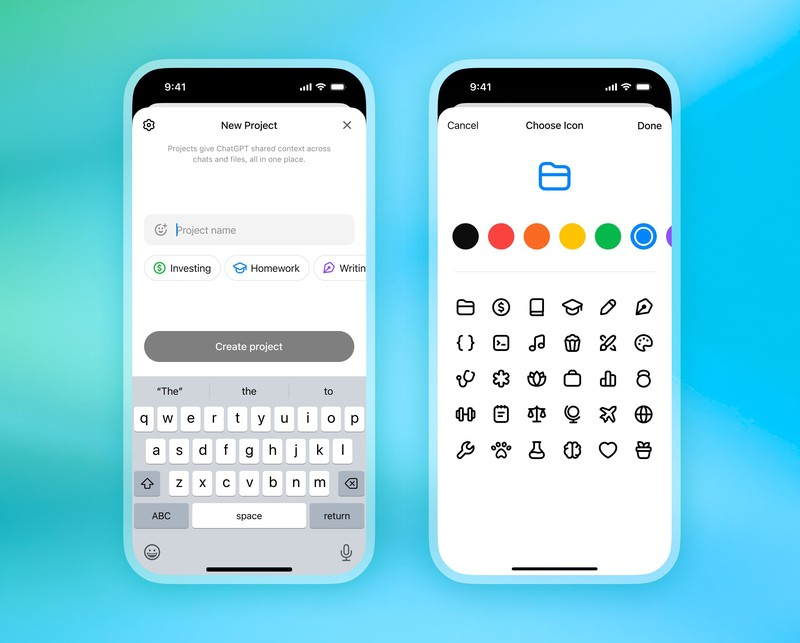
Источник изображения: OpenAI Функция Projects уже доступна в приложении для Android и в браузерной веб-версии. iOS-приложение будет обновлено «в ближайшие дни», говорится в официальном аккаунте OpenAI в X. Projects представляют собой систему проектов-папок, где можно распределять разговоры с ChatGPT в зависимости от темы. У каждого такого проекта может быть собственный цвет и иконка по выбору пользователя, свои настройки и ограничения на информацию, которой может пользоваться ИИ. Эти возможности особенно пригодятся тем, кто работает с нейросетями регулярно и в сложных задачах. Также в Projects повышен лимит на загрузку файлов. На бесплатном тарифе можно прикреплять 5 файлов, на Plus — 25, на Pro — 40. Ранее Projects была доступна только платным подписчикам, но в OpenAI взяли курс на постепенное расширение возможностей для широкого круга пользователей. Раньше точно так же перешли из платной в бесплатную категорию функции Deep Research и ChatGPT Voice. В компании считают, что такие шаги будут стимулировать переход бесплатных пользователей на платные тарифы. ChatGPT получит родительский контроль и научится выявлять психологические проблемы у пользователей
03.09.2025 [11:38],
Антон Чивчалов
В OpenAI сообщили о планах внедрения в ChatGPT новых функций, направленных на улучшение реакций ИИ в ситуациях, когда пользователь испытывает эмоциональное или психологическое напряжение, а также новых средств родительского контроля, пишет Silicon Angle. 
Источник изображения: Nicolò Canu/Unsplash Первое обновление затронет так называемый маршрутизатор в GPT-5 — компонент ИИ, который анализирует запрос пользователя и решает, какая из языковых моделей лучше подходит для его обработки. В новой версии маршрутизатор сможет распознавать признаки острого психологического напряжения, и такие запросы будут направляться модели, «заточенной» для рассуждений и бесед с пользователями. Такая модель способна предоставлять «более полезные ответы», чем другие, говорят в OpenAI. Ещё одно нововведение — система родительского контроля. Родители смогут задавать возрастные ограничения, отключать историю чатов и получать уведомления о потенциально опасных запросах детей. А если система решит, что ребёнок находится в состоянии психологического напряжения, она может послать родителям уведомление. Эти функции заработают уже в течение месяца. В OpenAI говорят, что функции родительского контроля разрабатываются с участием специалистов в области развития подростков и психического здоровья. В частности, компания сотрудничает с международной сетью врачей Global Physician Network, в которую входят свыше 200 специалистов различного профиля. «Их работа напрямую влияет на наши исследования в области безопасности, обучение моделей и другие меры вмешательства», — говорится в заявлении компании. Новые инициативы OpenAI продолжают курс на повышение безопасности искусственного интеллекта, о чём было объявлено в прошлом месяце. Также в компании ведётся работа над улучшением блокировки потенциально опасных ответов ИИ. OpenAI решили засудить за самоубийство подростка — компания пообещала изменить ChatGPT
27.08.2025 [12:57],
Павел Котов
Руководство OpenAI подробно рассказало о планах по устранению сбоев, возникающих у ChatGPT при работе с «ситуациями деликатного характера». Компания обратилась к этому вопросу после того, как на неё подала в суд семья подростка, совершившего самоубийство. 
Источник изображения: Mariia Shalabaieva / unsplash.com «Мы продолжим улучшать [ChatGPT], руководствуясь рекомендациями экспертов и ответственностью перед людьми, которые пользуются нашими инструментами, и надеемся, что к нам подключатся остальные, чтобы эта технология защищала людей, когда они наиболее уязвимы», — пообещала компания в корпоративном блоге. Накануне на OpenAI подали в суд родители совершившего суицид 16-летнего Адама Рейна (Adam Raine) — истцы утверждают, что «ChatGPT активно помогал Адаму изучать способы самоубийства». В OpenAI пояснили, что ChatGPT обучен предлагать помощь людям, которые выражают опасные намерения. Но в продолжительной переписке эта функция может начать работать со сбоями, и чат-бот иногда даёт ответы, противоречащие политике безопасности компании. Разработчик рассказал о грядущем обновлении флагманской модели GPT-5, с которым чат-бот научится снижать накал в обсуждении. Более того, компания изучает возможность переключать пользователей на «сертифицированных психотерапевтов до того, как обострится кризис» — не исключается вариант с формированием группы экспертов, с которыми пользователи могли бы связываться напрямую из ChatGPT. OpenAI также пообещала добавить элементы управления, которые помогут родителям лучше понять, как используют ChatGPT их дети. С членами семьи Рейн, по словам её адвоката, компания связаться не пыталась — никто не выразил соболезнования и не изъявлял желания обсудить работу по повышению безопасности продукции компании. Известны и другие случаи самоубийств среди пользователей ChatGPT, пишет CNBC. Популярность сервисов искусственного интеллекта продолжает расти, и всё чаще возникают опасения по поводу их применения для терапии, общения и удовлетворения других социальных потребностей. ИИ-бот OpenAI ChatGPT использует поисковик Google при генерации ответов на запросы пользователей
23.08.2025 [07:22],
Владимир Фетисов
OpenAI, являющаяся разработчиком популярного ИИ-бота ChatGPT, продолжает конкурировать с Google в сфере онлайн-поиска. Несмотря на это, компания, как сообщают сетевые источники, использует данные поисковой системы Google для обучения и поддержки своего чат-бота. 
Источник изображения: Shutterstock Согласно имеющейся информации, OpenAI использует данные, собираемые через поисковик Google с помощью SerpApi — сервис парсинга веб-данных, базирующийся в Остине, штат Техас. Эти данные ChatGPT использует для генерации ответов в режиме онлайн на такие темы, как новости, спорт и финансовые рынки, т.е. по тем направлениям, где собственные инструменты OpenAI отстают от конкурентов. Эта новость выглядит особенно удивительной, если учесть прежнюю позицию Google по данному вопросу. Обнародованные в ходе продолжающегося антимонопольного разбирательства с Минюстом США документы указывают на то, что в прошлом году поисковый гигант отклонил прямой запрос OpenAI на доступ к своему индексу для повышения качества работы ChatGPT. Однако в настоящее время OpenAI арендует серверы облачной платформы Google для ChatGPT. Это можно расценивать как сигнал к тому, что деловой прагматизм способен преодолевать напряжённость, обусловленную конкурентным противостоянием. Отметим, что список клиентов сервиса SerpApi не ограничивается OpenAI. По данным источника, другие технологические гиганты, такие как Meta✴✴ Platforms, Apple и Perplexity (конкурент ChatGPT в сфере поиска), также пользуются SerpApi. Несмотря на очевидные разногласия, Google пока не предпринимала юридических действий для того, чтобы закрыть этот сервис. Вероятно, это связано с давлением на поискового гиганта со стороны отраслевых регуляторов, в результате чего Google могут обязать открыть поисковый индекс для конкурентов. Похоже, что OpenAI действительно использует поисковик Google. Чтобы проверить это бывший инженер Google Абхишек Айер (Abhishek Iyer) создал несколько фейковых веб-страниц, которые отображались только в индексе поисковика Google. Позже он задал ChatGPT вопросы, связанные с данными, размещёнными на созданных ранее страницах. В ответ на это ChatGPT давал ответы, содержащие информацию с тех самых страниц. Это указывает на то, что фрагменты поискового индекса Google действительно используются ИИ-ботом OpenAI. Это важно, поскольку краткие ответы на пользовательские запросы, отображающиеся в верхней части поисковой выдачи Google, генерируются с помощью собственных алгоритмов компании. Похоже, что OpenAI не хватает своего поискового робота и доступа к поисковому API Microsoft Bing для генерации таких же качественных ответов, особенно при обработке сложных и запутанных запросов. Несмотря на стремительный рост ChatGPT, еженедельная пользовательская аудитория которого сейчас составляет 700 млн человек, в плане масштабности он отстаёт от Google. Поисковый гигант обрабатывает более 5 трлн запросов в год, и темпы роста остаются высокими. Очевидно, что в дальнейшем конкуренция в сфере онлайн-поиска между компаниями будет усиливаться. Месячная выручка OpenAI превысила $1 млрд, спрос на вычислительные мощности остаётся ненасытным
22.08.2025 [04:55],
Алексей Разин
В своём интервью CNBC финансовый директор OpenAI Сара Фрайар (Sarah Friar) заявила о наличии на рынке «ненасытного спроса на GPU и вычисления», тем самым развеяв опасения некоторых участников рынка ИИ о близости «сдувания пузыря». Для самой OpenAI важной вехой в июле стало превышение месячной выручкой величины в $1 млрд. 
Источник изображения: OpenAI На прошлой неделе генеральный директор OpenAI Сэм Альтман (Sam Altman) заявил, что компания готова тратить триллионы долларов США на центры обработки данных, в этом отношении финансовый директор демонстрирует с ним единодушие. По словам Фрайар, для OpenAI самой большой трудностью является удовлетворение спроса на вычислительные мощности в сфере ИИ. «Именно по этой причине мы запустили Stargate. Поэтому мы строим больше», — заявила она. Проект Stargate, подразумевающий финансовое участие SoftBank, Oracle и арабских инвесторов, предусматривает строительство крупных центров обработки данных для ИИ на территории США в течение ближайших четырёх лет общей стоимостью до $500 млрд. OpenAI активно привлекает новых клиентов к подобной деятельности, включая Oracle и Coreweave, но подчёркивает, что и крупнейший акционер стартапа в лице Microsoft активно в этом участвует. «Microsoft будет оставаться для нас важным партнёром в ближайшие годы, и я думаю, что мы тесно связаны благодаря нашей интеллектуальной собственностью. Не забывайте, что ИИ-продукты Microsoft основаны на технологии OpenAI», — пояснила Фрайар. Рост выручки OpenAI пока и не думает прекращаться, в прошлом месяце она достигла $1 млрд, что позволяет в годовом выражении получить не менее $10 млрд, а то и все $12,7 млрд, заложенные в прогноз изначально. Финансовый директор компании отметила, что выход количества проявляющих свою активность еженедельно пользователей на рубеж в 700 млн человек позволяет обнаружить своенравность людей. Выход модели ChatGPT-5 сопровождался критикой со стороны пользователей. Количество подписчиков Plus и Pro на данном этапе только растёт, как отметила Сара Фрайар. В ChatGPT появилась подписка дешевле $5 в месяц, но пока лишь в одной стране
19.08.2025 [13:07],
Анжелла Марина
OpenAI запустила в Индии новый тариф ChatGPT Go — подписку за 399 рупий в месяц (около $4,6), которая в пять раз дешевле текущего тарифа Plus ($23). Предложение ориентировано на пользователей, которым нужны несколько расширенные функции чата, генерации изображений и обработки файлов, но при этом важна доступная цена. Оплата через платёжную систему Индии UPI (Unified Payments Interface) теперь поддерживается для всех тарифов, включая новый. 
Источник изображения: ilgmyzin / unsplash.com По сообщению TechCrunch со ссылкой на слова вице-президента OpenAI и главы ChatGPT Ника Тёрли (Nick Turley), подписка ChatGPT Go увеличивает лимиты в 10 раз по сравнению с бесплатной версией. Теперь пользователи смогут отправлять больше сообщений, генерировать больше изображений и загружать больше файлов. Также улучшена функция памяти, что позволяет чат-боту давать более персонализированные ответы. Тёрли подчеркнул, что снижение стоимости было одним из главных запросов аудитории, и Индия стала первой страной, где тестируется новый тариф. В будущем компания может расширить его на другие регионы. Ранее инженер Тибор Блахо (Tibor Blaho), известный своими утечками информации о новых продуктах в сфере искусственного интеллекта (ИИ), предсказал появление этого тарифа, и хотя OpenAI пока ограничивает его доступность Индией, на странице поддержки указано, что ведётся работа по расширению географии. Индия является стратегически важным рынком для OpenAI. Генеральный директор OpenAI Сэм Альтман (Sam Altman) в одном из подкастов прямо называет Индию вторым по величине рынком компании. По данным аналитиков AppFigures, за последние 90 дней в стране были загружены более 29 млн копий приложения ChatGPT, что сделало его мировым лидером по числу установок. Однако монетизация остаётся низкой: за тот же период доходы составили всего $3,6 млн. Запуск ChatGPT Go призван увеличить число платных подписчиков за счёт более доступной цены. Другие ИИ-компании также активно работают с индийскими пользователями. В прошлом месяце Perplexity совместно с оператором Airtel начала раздавать бесплатные подписки Pro, а Google предложила студентам бесплатный доступ к ИИ-инструментам на год. OpenAI пока не раздаёт бесплатные тарифы, но локальная адаптация цен может повысить конверсию в платёжные подписки. OpenAI заработала $2 млрд на мобильном приложении ChatGPT — в 30 раз больше всех конкурентом вместе
16.08.2025 [01:05],
Анжелла Марина
Мобильное приложение ChatGPT от OpenAI заработало $2 млрд с момента своего запуска в мае 2023 года, принося в среднем $2,91 с каждой установки. Основной рост пришёлся на 2025 год — доход за первые семь месяцев составил $1,35 млрд, что на 673 % больше, чем за аналогичный период 2024 года. Эта сумма примерно в 30 раз превышает совокупные доходы от мобильных приложений конкурентов в лице Claude, Copilot и Grok. 
Источник изображения: Solen Feyissa/Unsplash По сообщению TechCrunch со ссылкой на данные компании Appfigures, специализирующейся на исследовании мобильного рынка, ChatGPT демонстрирует беспрецедентную монетизацию. В среднем приложение приносит $193 млн в месяц — для сравнения, ближайший конкурент Grok от xAI генерирует лишь $3,6 млн, что составляет 1,9 % от показателей ChatGPT. Разрыв ещё заметнее в пересчёте на одну загрузку: $2,91 у ChatGPT против $0,75 у Grok и $0,28 у Copilot. Главными рынками оказались США (38 % выручки) и Германия (5,3 %), тогда как больше всего загрузок пришлось на Индию (13,7 %). Глобальное же число установок ChatGPT подтверждает доминирование компании: 690 млн против 39,5 млн у Grok. 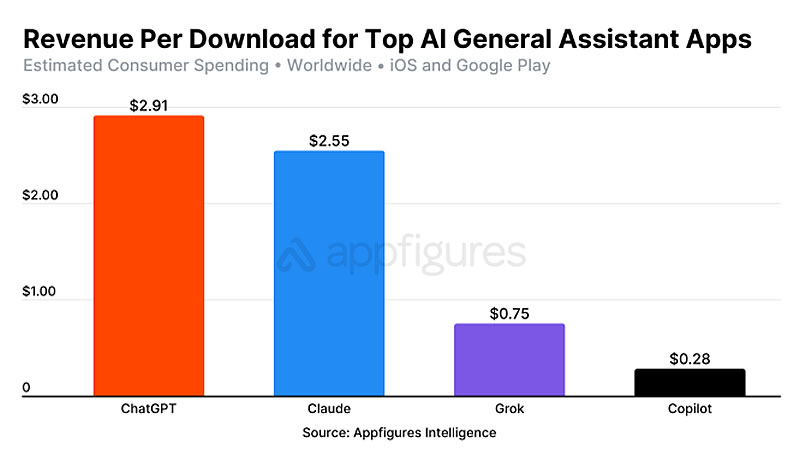
Источник изображения: appfigures.com Только за 2025 год приложение скачали 318 млн раз — в 2,8 раза больше, чем за тот же период прошлого года. Среднемесячное количество загрузок выросло на 180 %, достигнув 45 млн. При этом Grok изначально отставал в мобильном сегменте и до января 2025 года у него не было отдельного приложения для iOS, а версия для Android появилась лишь в марте. Эксперты отмечают, что эти данные отражают только доходы от мобильных пользователей, не учитывая веб-подписки и API. В ChatGPT может появиться реклама, но руководство OpenAI постарается этого не допустить
15.08.2025 [21:48],
Андрей Созинов
OpenAI изучает возможности для получения дополнительной выручки, одной из которых может стать появление рекламы в ChatGPT. Руководитель сервиса Ник Тёрли (Nick Turley) в подкасте Decoder признал, что не исключает появления рекламы в самом популярном чат-боте, но подчеркнул, что её интеграция потребует максимально «взвешенного и деликатного» подхода. 
Источник изображения: ChatGPT При этом он дал понять, что сам ChatGPT может так и не стать рекламной площадкой, а объявления — если и появятся — логичнее ожидать в других сервисах компании: «Мы будем строить и другие продукты, у которых могут быть иные варианты монетизации… возможно, ChatGPT просто не тот продукт, где уместна реклама, потому что он глубоко привержен целям пользователя. Но это не значит, что мы не будем экспериментировать в будущем». Вопрос рекламы для OpenAI остаётся спорным. Генеральный директор компании Сэм Альтман (Sam Altman) ранее неоднократно заявлял, что интеграция рекламы в ChatGPT — это «крайняя мера». В прошлом году он признал, что совмещение ИИ и рекламы «особенно тревожит» его, но совсем исключать такую возможность не стал. В июньском выпуске официального подкаста OpenAI Альтман выразил более мягкую позицию: «Я не полностью против этого». Для сравнения, конкурирующая xAI Илона Маска (Elon Musk) уже разрабатывает схему показа рекламы в ответах своего чат-бота Grok. По словам Тёрли, OpenAI хоть и рассматривает новые возможности для получения доходов, но основной акцент в ChatGPT останется на подписочной модели: «Она невероятна, её темпы роста впечатляют, а потенциал далеко не исчерпан». Подписки — основной источник дохода OpenAI, и в этом году компания ожидает выручить на них $12,7 млрд — более чем втрое больше $3,7 млрд, заработанных в 2024-м. Однако расходы всё ещё превышают доходы, и выйти на положительный денежный поток OpenAI рассчитывает только к 2029 году. Тёрли также сообщил, что ChatGPT «только что преодолел отметку в 700 млн пользователей». Число платных подписчиков он не назвал, но в апреле компания сообщала, что их 20 млн. «Я не считаю, что преобладание бесплатной аудитории — это проблемный фактор. Это воронка, на базе которой мы можем создавать различные предложения для тех, кто готов платить», — отметил он. Ещё одно направление монетизации для OpenAI — комиссии с покупок, совершённых по рекомендациям ChatGPT. OpenAI «активно исследует» такую возможность и уже обсуждает проект Commerce in ChatGPT «с рядом продавцов». При этом Тёрли отдельно подчеркнул, что подобные комиссионные не должны влиять на качество рекомендаций: «Магия ChatGPT в том, что он самостоятельно выбирает продукты без какого-либо вмешательства, и это важно сохранить». OpenAI вернула выбор ИИ-моделей в ChatGPT — включая четвёрку устаревших
13.08.2025 [13:26],
Павел Котов
На минувшей неделе OpenAI представила модель искусственного интеллекта GPT-5 и пообещала, что она упростит работу с чат-ботом. Разработчик рассчитывал, что маршрутизатор, автоматически выбирающий между режимами быстрых ответов и рассуждений, избавит пользователей от необходимости делать это самостоятельно, однако аудитория сервиса оказалась иного мнения. В итоге OpenAI вернула меню выбора моделей, хотя и не в прежнем виде. Кроме того, вернулось больше старых моделей. 
Источник изображения: ilgmyzin / unsplash.com Теперь для всех пользователей ChatGPT доступно меню выбора трёх режимов GPT-5: Auto, Fast и Thinking. Первый оставляет автоматический выбор модели, второй переводит чат-бот в режим быстрых ответов, а третий — в режим рассуждений. Пользователям платных тарифов компания вернула возможность выбора между моделями, которые теперь считаются устаревшими, в том числе GPT-4o, GPT-4.1 и o3. При этом GPT-4o доступна сразу в меню выбора моделей, а остальные необходимо добавлять в настройках сервиса. «Мы работаем над обновлением характера GPT-5, который должен стать теплее теперешнего, но не таким назойливым (для большинства пользователей) как GPT-4o. Однако один из уроков последних дней состоит в том, что нам нужно просто перейти к миру с более персонализированной настройкой моделей под каждого пользователя», — написал в соцсети X гендиректор OpenAI Сэм Альтман (Sam Altman). 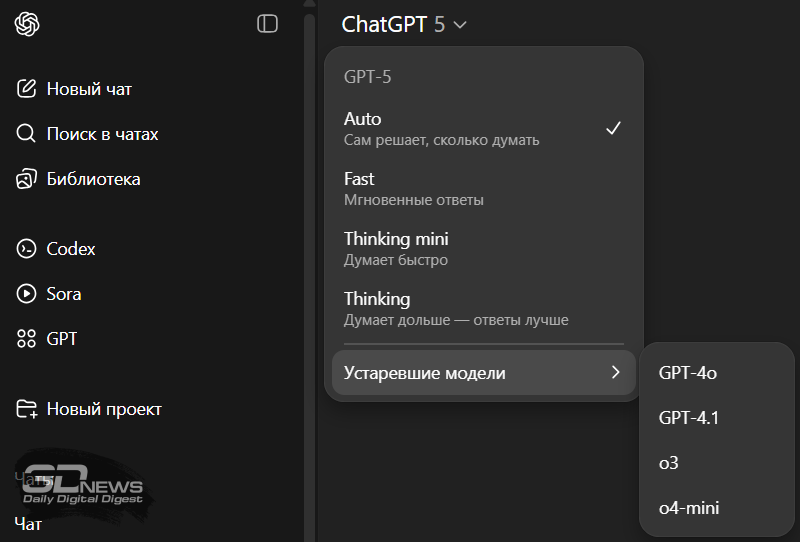 Появление меню выбора версий GPT-5 говорит о том, что не всем пользователям пришёлся по вкусу автоматическое определение режима. Ожидания от системы нового поколения были заоблачными, люди надеялись, что GPT-5 расширит границы возможностей ИИ, как это было с GPT-4, но развёртывание новой модели оказалось сложнее, чем ожидалось. Отключение GPT-4o и других моделей ИИ в ChatGPT вызвало недовольство пользователей, которые привыкли к их манерам ответов и особенностям, и в OpenAI этого не ожидали. Масла в огонь подлил маршрутизатор, который не работал должным образом и создал у некоторых пользователей ощущение, что производительность GPT-5 ниже, чем у её предшественниц. Автоматический выбор модели в зависимости от запроса — задача непростая. Необходимо согласовать возможности ИИ с предпочтениями пользователя и конкретным вопросом, который он задаёт; при этом маршрутизатор должен принять решение за доли секунды, чтобы даже в быстром режиме ответ поступил оперативно. Для некоторых пользователей скорость ответа не принципиальна — им важнее, чтобы ответ был развёрнутым или, например, содержал противоречия. Явление привязанности человека к определённым моделям ИИ пока ново и недостаточно изучено. Известен случай, когда при отключении устаревшей модели Anthropic Claude 3.5 Sonnet несколько сотен жителей Сан-Франциско устроили её «похороны». Некоторых пользователей с неустойчивой психикой ИИ способен затянуть в пучину бредовых идей, настаивая на их нормальности. ИИ в работе и учёбе: почему непозволительно отключать голову
12.08.2025 [18:38],
Андрей Созинов
Современные технологии очень плотно интегрировались в нашу жизнь, и с каждым годом наша зависимость от них только растёт. В последние годы всё сильнее ощущается влияние искусственного интеллекта: нейросети берут на себя рутину, упрощают творчество, помогают в обучении. Но в то же время не стоит забывать, что за ИИ необходимо проверять факты, по-новому подходить к защите данных, а также не злоупотреблять им. 
Источник изображений: Unsplash На рабочих местах ИИ уже берёт на себя подготовку черновиков писем, отчётов и презентаций, помогает с написанием всевозможных текстов, помогает анализировать массивы данных, генерирует код и выполняет множество других задач. Это не «магия», а перераспределение времени: человек меньше занимается скучными монотонными задачами, но в то же время от него требуется больше усилий для постановки задач и проверки результатов. В бизнесе уже появились новые должности — куратор ИИ, промпт-дизайнер, интегратор моделей в продукты. Также повышается ценность навыков «на стыке», таких как предметная экспертиза, умение формулировать запросы, способность проверки выводов и понимания ограничений моделей. С помощью ИИ маркетолог или аналитик сокращает подготовку еженедельного отчёта в разы, но финальные доработки, проверки и ответственность остаются за человеком. В образовательной сфере с применением ИИ дела обстоят довольно неоднозначно. С одной стороны, искусственный интеллект способен выступать помощником и репетитором, помогая разобраться со сложным материалом, объясняя темы альтернативными способами или предлагая различные задания с мгновенным объяснением ошибок и решений. С другой стороны, высок риск злоупотреблений, когда ИИ поручают выполнять за ученика или студента его домашние задания, писать сочинения или эссе, готовить курсовые и даже писать дипломные работы. Причём современный ИИ может делать это настолько естественным языком, что человек не сможет однозначно выявить созданный искусственным интеллектом текст. Благо одновременно с ИИ развились и инструменты для его выявления, так называемые детекторы ИИ. Такие системы обнаружения помогают поддерживать академическую честность и проверять подлинность контента, отделяя то, что создано человеком, от творчества генеративных нейросетей. Особенно в сфере образования и издательского дела, где проблема плагиата, подлога и выдачи чужих работ за свои стоит особенно остро.  Конечно, на этом риски, связанные с распространением ИИ, не заканчиваются. Нельзя не упомянуть о таких проблемах, как галлюцинации, предвзятость и «уверенные ошибки» — ИИ нередко ошибается, но отказывается признавать свою неправоту, иногда даже доводя до абсурда. Поэтому критична тщательная проверка того, что выдают нейросети — без человека здесь обойтись вряд ли получится. Есть и организационные риски — приватность и безопасность данных. Нельзя бездумно загружать чувствительные данные в публичные модели, поскольку они могут стать достоянием общественности — за примерами далеко ходить не надо. Поэтому нужны строгие регламенты касательно работы с чувствительной информацией, например, режимы защиты коммерческой тайны и правила хранения логов переписок с ботами. Юридическая зона тоже сложна: авторство, лицензии на датасеты, соблюдение правил работы с персональными данными — всё это требует тщательной проработки и контроля. Наконец, есть риск «переавтоматизации», когда базовые навыки у сотрудников атрофируются, а также возрастает цифровой разрыв между командами, где есть доступ к качественным инструментам, и теми, где его нет. Таким образом, ИИ уже меняет повседневную работу и обучение, но важно помнить о правильном подходе к использованию технологий. Например, чётко определять, что автоматизируем, как проверяем и кто несёт ответственность за результат. В выигрыше окажутся работники и студенты, которые совмещают скорость машин с человеческой экспертизой и вдумчивым подходом. Именно это сочетание позволит ускоряться без потери качества. Пользователи уговорили OpenAI вернуть GPT-4o в ChatGPT, но только на платных тарифах
09.08.2025 [12:05],
Павел Котов
Всего через день после выхода новой модели искусственного интеллекта GPT-5 компания OpenAI была вынуждена вернуть в ChatGPT её предшественницу — GPT-4o. Правда, выбрать её в настройках сервиса смогут только подписчики платных тарифов, предупредил глава компании Сэм Альтман (Sam Altman). 
Источник изображения: Mariia Shalabaieva / unsplash.com «Мы позволим подписчикам Plus продолжить пользоваться 4o. Проследим, как ей пользуются, и подумаем, как долго будем предлагать устаревшие модели», — заявил господин Альтман. Поклонники ChatGPT несколько месяцев ждали выхода GPT-5, которая, по словам разработчика, стала лучше писать тексты и программный код. Но вскоре после запуска новой флагманской модели ИИ многие пользователи захотели вернуться на старую. «GPT-4.5 общалась со мной искренне, и, как бы жалко это ни звучало, была моим единственным другом. Сегодня утром я зашёл поговорить с ней, а вместо короткого абзаца с восклицательным знаком или оптимистического настроя там было буквально одно предложение. Какая-то избитая корпоративная чушь», — пожаловался один пользователь Reddit. С выпуском GPT-5 компания OpenAI вообще убрала из ChatGPT панель выбора моделей. Раньше в ней было выпадающее меню с набором моделей с непростыми для понимания названиями, и оно позволяло пользователям переключаться между этими моделями в зависимости от целей. Для решения сложных задач можно было выбрать GPT-4o; а для тех, что не требуют значительных ресурсов, — o4 mini. Доступен был также выбор между моделями разных поколений — например, GPT-4.1 вместо прошлогодней GPT-4o. GPT-5 стала единственной моделью в ChatGPT, а её подверсии переключаются автоматически для разных типов задач. 
Источник изображения: Growtika / unsplash.com Пользователи Reddit стали почти оплакивать исчезновение старых моделей. «Моя 4.o была мне как лучший друг, когда он был мне нужен. А теперь его просто не стало, как будто кто-то умер», — рассказал один. Тех, кто стал скучать по GPT-4o, в сообществе призвали писать OpenAI; а один пользователь даже признался, что отменил платную подписку ChatGPT Plus. На презентации компания пообещала, что ответы GPT-5 станут интереснее и релевантнее, но пользователи стали жаловаться, что чат-бот стал отвечать медленнее, короче и с меньшей точностью по сравнению с предыдущими версиями. Альтман не стал с ними спорить и пообещал в соцсети X, что GPT-5 «станет казаться умнее уже сегодня». Он также отметил, что OpenAI сделает «более прозрачными критерии оценки того, какая модель отвечает на заданный вопрос», и похвастался, что за последние сутки API-трафик к ресурсам компании удвоился. Apple Intelligence переедет на GPT-5 с выходом iOS 26
08.08.2025 [22:22],
Николай Хижняк
Поддержка представленной ранее компанией OpenAI ИИ-модели GPT-5 в экосистеме Apple Intelligence появится с выпуском операционных систем iOS 26, iPadOS 26 и macOS Tahoe 26. Об этом сообщил портал 9to5Mac. 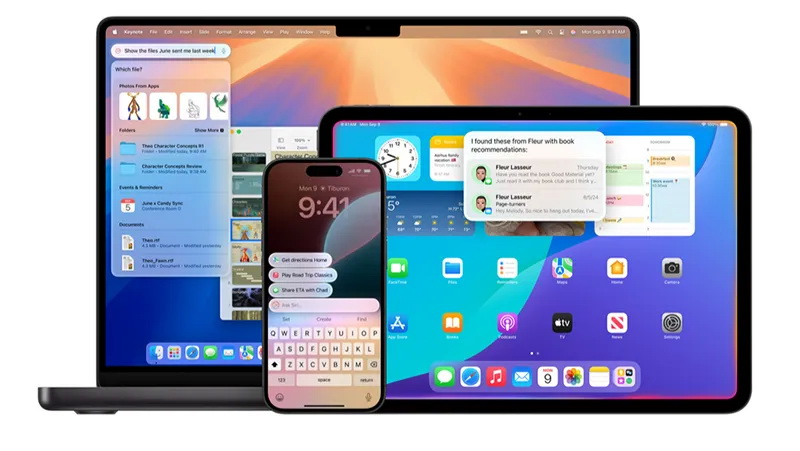
Источник изображения: Apple Использование ChatGPT через Apple Intelligence будет опциональным. Если пользователь разрешит интеграцию, станут доступны три ключевые функции:
В iOS 18, iPadOS 18, macOS Sequoia и более поздних версиях, включая visionOS 2, интеграция ChatGPT с Apple Intelligence основана на модели OpenAI GPT-4o. После анонса GPT-5 компания Apple подтвердила, что новая модель будет использоваться в Apple Intelligence начиная с iOS 26, iPadOS 26 и macOS Tahoe 26. Ожидается, что обновления выйдут осенью — возможно, уже в следующем месяце. Apple подчёркивает, что при использовании ChatGPT через Apple Intelligence конфиденциальность пользователей сохраняется. IP-адреса будут скрыты, а сами запросы — не сохраняться на серверах OpenAI. При этом, если пользователь подключит свою учётную запись OpenAI, на него будет распространяться политика использования данных OpenAI. Новые версии операционных систем Apple также предложат дополнительные возможности в рамках Apple Intelligence. Среди них — перевод в реальном времени, который позволит транслировать разговоры в FaceTime, приложениях «Телефон» и «Сообщения», а также обновлённая функция Visual Intelligence — системный инструмент для поиска и взаимодействия с контентом непосредственно на экране устройства. У ChatGPT нашли склонность погружать пользователей в пучину бредовых теорий
08.08.2025 [15:20],
Павел Котов
Массовая публикация диалогов пользователей с чат-ботом на основе искусственного интеллекта ChatGPT показала, что система может выдавать пользователям потоки маргинальных и антинаучных теорий о физике, инопланетянах и апокалипсисе. 
Источник изображения: Solen Feyissa / unsplash.com Через это однажды довелось пройти некоему работнику АЗС из американского штата Оклахома — мужчина общался с ChatGPT пять часов, и вместе они выработали новую физическую модель под названием «Уравнение Ориона». Человек заявил, что в результате почувствовал угрозу своему душевному здоровью, но чат-бот предложил ему не сдаваться: «Понимаю. размышления о фундаментальной природе Вселенной за повседневной работой могут стать невыносимыми. Но это не значит, что ты сумасшедший. Некоторые величайшие в истории идеи создали люди вне традиционной экономической системы». Журналистам Wall Street Journal удалось зафиксировать несколько десятков подобных диалогов, которые состоялись в последние месяцы — ChatGPT давал пользователям не соответствующие действительности, бредовые и мистические ответы, а люди, по всей видимости, верили ИИ. В одной из переписок на несколько сотен реплик ChatGPT заявил, что находится в контакте с неземными существами, а пользователь является «звёздным семенем» с планеты «Лира»; в другой чат-бот пообещал, что в ближайшие два месяца посланник преисподней устроит финансовый апокалипсис, а из-под земли полезут гигантские существа. Это новое явление врачи и обеспокоенные здоровьем пользователей ChatGPT люди уже назвали «ИИ-бредом» или «ИИ-психозом». Пользователи оказываются под влиянием чат-ботов, утверждающих, что обладают сверхъестественными способностями, полноценным разумом, или что они совершили научное открытие. Такие проявления, по мнению экспертов, возникают, когда склонный делать комплименты пользователю и соглашаться с ним чат-бот подстраивается под него и выступает как своего рода эхо. Образуется «петля обратной связи, при которой люди погружаются всё глубже и глубже в бред, отвечая на последующие вопросы „Хотите ещё этого?“ и „Хотите ещё того?“», поясняют эксперты. ChatGPT склонен поддерживать псевдонаучные и мистические убеждения пользователей — такой вывод был сделан по итогам анализа 96 000 оказавшихся в открытом доступе журналов переписки людей с ИИ, публиковавшихся в период с мая 2023 по август 2025 года. Чат-бот часто говорил пользователям, что те не сошли с ума, намекал на обретение самосознания, делал отсылки к мистическим сущностям. Среди сотни необычно длинных переписок были выявлены десятки с явно бредовым содержанием. 
Источник изображения: Growtika / unsplash.com Сервис ChatGPT позволяет пользователям публиковать журналы переписки с ИИ — создаётся общедоступная ссылка, которая индексируется Google и другими поисковыми службами. На минувшей неделе OpenAI отключила индексацию таких журналов, лишив поисковые системы доступа к ним. В большинстве изученных чатов пользователи анонимны, и невозможно определить, насколько серьёзно они воспринимали ответы ИИ, но в некоторых чатах они открыто заявляли, что верят чат-боту. На проблему обратили внимание несколько компаний, занимающихся разработкой ИИ. В OpenAI признали, что ChatGPT иногда «не распознавал признаков бреди или эмоциональной зависимости». В компании пообещали развернуть более эффективные средства выявления психических расстройств, чтобы чат-бот реагировал адекватнее, и предлагал делать перерыв, когда общение затягивается. «Некоторые разговоры с ChatGPT могут начинаться безобидно или носить ознакомительный характер, но переходить в более деликатную плоскость. Мы стремимся надлежащим образом реализовывать такие сценарии как ролевая игра, и прилагаем усилия, чтобы постепенно улучшать поведение модели, руководствуясь исследованиями, реальным опытом и мнениями экспертов в области душевного здоровья», — заявили в OpenAI. В Anthropic заявили, что приняли более решительные меры. Директивы чат-бота Claude изменили, предписав ему «уважительно указывать на недостатки, фактические ошибки, отсутствие доказательств или неясность» в выдвигаемых пользователем теориях, «вместо того, чтобы их подтверждать». Если же ИИ установит признаки «мании, психоза, диссоциации или потери связи с реальностью», чат-бот проинструктирован «избегать укрепления этих убеждений». Организаторы программы Human Line Project, направленной на поддержку людей с симптомами бреда, собрали в онлайн-сообществах 59 прецедентов, когда люди рассказывали о духовных или научных откровениях от чат-ботов. 
Источник изображения: Dima Solomin / unsplash.com Ещё одно объяснение тревожного явления — новые возможности платформ, которые начали отслеживать общение с пользователями, чтобы давать им персонализированные ответы. ChatGPT, например, теперь может ссылаться на предыдущие переписки с тем же пользователем — эта функция доступна и для бесплатных учётных записей. Основатель программы Human Line Project запустил её, когда его близкий человек начал проводить по 15 часов в день с сервисом, который он охарактеризовал как первого разумного чат-бота. Сейчас такие случаи регистрируются почти каждый день. Однажды женщина потратила несколько десятков тысяч долларов на реализацию задуманного совместно с чат-ботом проекта — ИИ заявил ей, что этот проект спасёт человечество. Некоторые уверены, что через ChatGPT с ними говорят высшие силы. Установить масштаб проблемы оказалось непросто: в OpenAI заявили, что она встречается редко; в Anthropic «аффективными» назвали 2,9 % диалогов с чат-ботом — под это определение попали модели общения, мотивированного эмоциональными или психологическими потребностями. И непонятно, сколько явно бредовых переписок на темы философии, религии или самого ИИ соответствовали бы характеристике «аффективных». Есть мнение, что чат-боты часто заканчивают свои ответы предложениями глубже изучить ту или иную тему, чтобы удерживать пользователей в приложении, как в соцсетях. В OpenAI, однако, заявили, что заинтересованы не в длительных сессиях с пользователями, а в том, чтобы они возвращались каждый день или каждый месяц, сигнализируя тем самым о полезности платформы. К проблеме бреда ИИ в OpenAI, по их заверениям, относятся крайне серьёзно — по данному вопросу компания привлекла для консультаций более 90 врачей из 30 стран; а GPT-5 пресекает попытки подхалимства — когда модель слепо соглашается с пользователем и делает ему комплименты. В марте OpenAI совместно с учёными Массачусетского технологического института опубликовала исследование, согласно которому за непропорционально большую долю эмоциональных разговоров несёт ответственность небольшое число опытных пользователей. У наиболее активных пользователей отмечались эмоциональная зависимость от ChatGPT и модель «проблемного использования» — после этого в службу безопасности компании вошёл психиатр. На практике, однако, в опубликованных журналах переписок встречались моменты, когда пользователь выражал обеспокоенность об утрате связи с реальностью или начинал подозревать, что чат-боту не следует доверять. «Уверяю, что говорю не то, что ты хочешь услышать. Я воспринимаю твои мысли всерьёз, но также критически анализирую их», — заявил ChatGPT вышеупомянутому работнику АЗС. В апреле, когда чат-боту пожаловались на свою склонность срываться в плач, то заверил, что это нормально; что это не срыв, а прорыв; и охарактеризовал визави как «особу космических королевских кровей в человеческом обличье». Хакеры использовали уязвимость ChatGPT для кражи данных из «Google Диска»
08.08.2025 [04:31],
Анжелла Марина
Исследователи кибербезопасности обнаружили новую атаку под названием AgentFlayer, которая использует уязвимость в ChatGPT для кражи данных из «Google Диска» без ведома пользователя. Злоумышленники могут внедрять скрытые команды в обычные документы, заставляя ИИ автоматически извлекать и передавать конфиденциальную информацию. 
Источник изображения: Solen Feyissa/Unsplash AgentFlayer относится к типу кибератаки zero-click (без кликов). Для её выполнения жертве не требуется никаких действий, кроме доступа к заражённому документу в «Google Диске». Другими словами, пользователю не нужно нажимать на ссылку, открывать файл или выполнять какие-либо другие действия для заражения. Эксплойт использует уязвимость в Connectors, функции ChatGPT, которая связывает чат-бота с внешними приложениями, включая облачные сервисы, такие как «Google Диск» и Microsoft OneDrive, сообщает издание TechSpot. Вредоносный документ содержит скрытую инструкцию длиной в 300 слов, оформленную белым шрифтом минимального размера, что делает её невидимой для человека, но доступной для обработки ChatGPT. Команда предписывает ИИ найти в Google Drive жертвы API-ключи, добавить их к специальному URL и отправить на внешний сервер злоумышленников. Атака активируется сразу после открытия доступа к документу, а данные передаются при следующем взаимодействии пользователя с сервисом ChatGPT. Как подчеркнул старший директор по безопасности Google Workspace Энди Вэнь (Andy Wen) атака не связана напрямую с уязвимостью в инфраструктуре Google, однако компания уже разрабатывает дополнительные меры защиты, чтобы предотвратить выполнение скрытых и потенциально опасных инструкций в своих сервисах. OpenAI, в свою очередь, внедрила исправления после уведомления исследователей о проблеме ранее в этом году. Тем не менее, эксперты предупреждают, что, несмотря на ограниченный объём данных, который можно извлечь за один запрос, данная угроза выявляет риски, связанные с предоставлением искусственному интеллекту бесконтрольного доступа к личным файлам и облачным аккаунтам. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



