|
Опрос
|
реклама
Быстрый переход
Nvidia утверждает, что все её крупнейшие клиенты уже используют серверы на основе Vera Rubin
22.07.2026 [08:51],
Алексей Разин
Компания Nvidia на этой неделе провела мероприятия для прессы, клиентов и партнёров, целью которых была демонстрация её готовности поставлять потребителям новейшие серверные компоненты и готовые системы. Решения на основе ускорителей поколения Vera Rubin, по словам руководства Nvidia, уже доставлены основным крупным клиентам компании и начинают использоваться. 
Источник изображения: Nvidia Данные комментарии прозвучали из уст вице-президента Nvidia Иэна Бака (Ian Buck), который в компании отвечает за направление центров обработки данных. Во время брифинга в штаб-квартире Nvidia он заявил: «Мы абсолютно находимся на стадии полномасштабного производства. Это оборудование уже установлено у всех наших крупнейших потребителей». Инвесторы и клиенты Nvidia с некоторым опасением следили за этапом масштабирования производства серверных систем поколения Vera Rubin, поскольку новая продукция всегда таит вероятные сложности и потенциальные задержки. Представители Nvidia заявляют, что в этом отношении переживать не о чем. Оборудование нового поколения будет не только производительнее предыдущего, его будет проще вводить в эксплуатацию. Более того, компоновка новых серверов рассчитана с учётом упрощения процедуры сборки: количество кабельных подключений максимально сокращено, чтобы перевести операции на использование роботов, а не людей. Система жидкостного охлаждения также сокращает потребность в свободном пространстве внутри корпуса и количестве установленных вентиляторов. Один из лидеров рынка ИИ — американский стартап OpenAI, собирается начать масштабную эксплуатацию систем семейства Vera Rubin в текущем квартале, как отметили представители Nvidia. Уже сейчас эти системы используются компаниями Google, CoreWeave, Microsoft, Meta✴✴ Platforms и Dell Technologies. В окрестностях штаб-квартиры Nvidia в Калифорнии построена специальная экспериментальная площадка с новейшим серверным оборудованием, которое клиенты могут протестировать и оценить на пригодность к своим нуждам. OpenAI как раз сейчас проводит подобные испытания. По данным CoreWeave, системы поколения Vera Rubin способны выдавать в десять раз больше токенов по сравнению с предшественниками. Представители Nvidia также настаивают, что центральные процессоры Vera оказываются в 1,8 раза быстрее в программировании на Python по сравнению с конкурирующими AMD Turin. Представители последней из компаний возразили, что сравнение с более новыми процессорами Venice не будет демонстрировать подобного разрыва. Тайваньская Wistron начнёт выпускать для Nvidia в США серверы с новейшими чипами Vera Rubin
22.07.2026 [07:01],
Алексей Разин
Нынешний президент США Дональд Трамп (Donald Trump) пытался привлечь тайваньского контрактного производителя электроники Foxconn на американскую землю ещё в 2017 году, и ту попытку нельзя назвать удачной. Тем не менее, сейчас производством серверного оборудования на территории США готова заниматься не только Foxconn, но и конкурирующая Wistron, которая построила завод в Техасе. 
Источник изображения: Nvidia Как сообщает Nikkei Asian Review, техасская площадка Wistron занимает площадь более 30 000 квадратных метров, и это первое предприятие компании на территории США. На его строительство было потрачено $700 млн. На церемонии открытия завода представители Wistron продемонстрировали первый модуль Nvidia GB300, собранный на его территории. Сперва здесь будет освоен выпуск серверных систем на основе Grace Blackwell, а позже завод начнёт выпускать решения поколения Vera Rubin. В течение пары лет данное предприятие станет одним из самых важных в инфраструктуре Wistron, по словам представителей компании. Глава и основатель Nvidia Дженсен Хуанг (Jensen Huang) также посетил церемонию открытия завода Wistron в Техасе, подчеркнул, что спрос на ИИ-серверы невероятно высок, а потому они должны производиться повсеместно. Компании сообща восстанавливают передовое производство на территории США, создают квалифицированные рабочие места и развивают локальные цепочки поставок, по словам главы Nvidia. Компании Foxconn и Wistron являются главными производителями печатных плат с ускорителями вычислений Nvidia, до недавних пор американские клиенты последней были вынуждены полагаться на поставки с Тайваня. На предприятии Wistron будут выпускаться не только печатные платы и готовые ускорители на базе GPU, но и целые серверные системы. Конкурирующая Foxconn также вскоре собирается запустить своё локальное предприятие по выпуску серверного оборудования для Nvidia в Хьюстоне, штат Техас. Площадка Wistron располагается в городе Форт-Уэрт. Если учесть, что TSMC развивает обработку кремниевых пластин в Аризоне, и там же будет заниматься упаковкой ИИ-чипов, на территории США появится почти самодостаточная инфраструктура для изготовления компонентов вычислительных систем. Правда, среди поставщиков памяти типа HBM полным циклом производства в США обладает только Micron, но она тоже расширяет свои мощности, да и местные власти собираются принудить корейских Samsung и SK hynix локализовать производство памяти в стране. Samsung запустила массовое производство SSD с PCIe 6.0 — они не для ПК
08.07.2026 [11:13],
Павел Котов
Samsung начала массовый выпуск передовых твердотельных накопителей для центров обработки данных — они будут использоваться в оборудовании на платформе Nvidia Vera Rubin. Новинки предлагают ёмкость до 64 Тбайт и скоростной интерфейс PCIe 6.0. 
Источник изображений: sasmung.com Твердотельный накопитель корпоративного класса Samsung PM1763 был представлен на конференции Nvidia GTC. Компания Samsung продемонстрировала его вместе с высокоскоростной памятью нового поколения HBM4 и модулем SOCAMM2 с низким потреблением энергии — они вошли в комплексный пакет для ЦОД с системами искусственного интеллекта.  В накопителе используются новейшие чипы флеш-памяти Samsung V-NAND типа TLC и контроллер, который производится по нормам 4 нм и обеспечивает скорость записи более чем вдвое выше, чем у предшественника, отметил корейский производитель. SSD Samsung PM1763 разработан для снижения задержки данных в системах с современными процессорами и ИИ-ускорителями. Для поддержания высоких скоростей во время обучения и инференса ИИ накопитель предусматривает систему жидкостного охлаждения. PM1763 оснащены интерфейсом PCIe 6.0. В основу положены чипы флеш-памяти TLC NAND. Заявлена скорость последовательного чтения до 28 400 Мбайт/с, и скорость последовательной записи до 21 000 Мбайт/с. Скорость операций ввода/вывода в секунду при произвольном чтении данных блоками по 4 Кбайт составляет до 6,8 млн IOPS, при произвольной записи — до 950 тыс. IOPS. По итогам I квартала Samsung, по данным TrendForce, занимала наибольшую долю на рынке корпоративных SSD — 35 %. За ней следовали SK hynix, Micron, Kioxia и её партнёр в лице Sandisk. Nvidia и SK hynix подписали соглашение о долгосрочном сотрудничестве в «широком спектре технологий»
08.06.2026 [04:46],
Алексей Разин
Основатель и бессменный лидер Nvidia Дженсен Хуанг (Jensen Huang) во время своего визита в Южную Корею не стал ограничиваться заявлениями о том, что все три крупнейших поставщика HBM4 прошли сертификацию и будут снабжать ускорители Vera Rubin эти типом памяти. Компания SK hynix была выделена из числа партнёров Nvidia, поскольку именно с ней было заключено долгосрочное соглашение о сотрудничестве. 
Источник изображения: Nvidia Стороны будут на протяжении нескольких лет сотрудничать в сфере разработки и производства чипов, как можно понять из публикации Bloomberg. По всей видимости, данное соглашение усиливает роль SK hynix в создании новых поколений HBM и других видов памяти, которые Nvidia сочтёт привлекательными для применения. К слову, данные новости не уберегли акции SK hynix от снижения в цене на 10 % на торгах в понедельник, поскольку коррекция на фондовом рынке, которая в США наблюдалась в пятницу, эхом отразилась на азиатских площадках в первый рабочий день новой недели. По словам Хуанга, сотрудничество между Nvidia и SK hynix будет охватывать широкий спектр технологий, от передовых ИИ-моделей до агентских решений и физического воплощения ИИ. Все эти задачи потребуют использования памяти, причём разных типов. Центральные процессоры Vera, как добавил глава Nvidia, также будут использовать память DRAM производства SK hynix. Второе полугодие и весь следующий год, по словам Хуанга, будут очень насыщенными с точки зрения взаимодействия Nvidia и SK hynix. SK hynix за ближайшие пять лет удвоит производственные мощности по выпуску памяти
02.06.2026 [11:18],
Алексей Разин
Значимость производителей памяти подчёркивается хотя бы тем фактом, что председатель совета директоров южнокорейской SK Group Чхэ Тхэ Вон (Chey Tae-won) оказался приглашён на отраслевую выставку Computex 2026 на Тайване, где сделал несколько важных заявлений. В частности, он пообещал удвоить мощности SK hynix по производству памяти за последующие пять лет. 
Источник изображения: SK hynix Он же в марте этого года, как напоминает Reuters, сообщил о возможности сохранения дефицита памяти на мировом рынке до 2030 года. SK hynix, которая в составе упоминаемого южнокорейского конгломерата занимается выпуском памяти, нуждается в расширении круга своих партнёров на Тайване, и дело не должно ограничиваться одной лишь TSMC, как отметил глава холдинга. Чхэ Тхэ Вон выразил надежду, что SK hynix сможет остаться крупнейшим поставщиком HBM для ускорителей Nvidia Vera Rubin. Как известно, на этот статус претендует конкурирующая Samsung Electronics, но SK hynix явно не собирается сдаваться без боя. На прошлой неделе капитализация SK hynix впервые в истории превысила $1 трлн, что говорит об уверенности инвесторов в способности этого производителя памяти развивать бизнес в условиях бума ИИ. По данным Counterpoint Research, в первом квартале текущего года SK hynix сохраняла за собой 58 % мирового рынка HBM, а Samsung и Micron досталось по 21 %. Память в серверах Nvidia подорожала на 435 % при переходе от Blackwell к Vera Rubin — стойку оценили в $7,8 млн
22.05.2026 [12:18],
Павел Котов
Одна серверная стойка Nvidia VR200 NVL72 нового поколения на архитектуре Vera Rubin обойдётся облачному оператору примерно в $7,8 млн, подчитали в Morgan Stanley. Для сравнения, GB300 NVL72 стоит около $4 млн. Стойка нового поколения VR200 NVL72 содержит больше DRAM и NAND — на память приходятся около 25 % общей стоимости. 
Источник изображения: Nvidia В корпусах VR200 NVL72 компания Nvidia намеревается продавать процессоры Vera по $5000 и ускорители искусственного интеллекта Rubin по $55 000 за штуку. В стойках используются уже знакомые клиентам корпуса Oberon, но внутри установлены более сложные компоненты коммутации, сетевых подключений, печатные платы, системы охлаждения, изменились даже технологии упаковки чипов — всё это влияет на стоимость систем и складывается в ценник $7,8 млн за стойку. Только компоненты памяти в стойке VR200 NVL72 обходятся около $2 млн или на 435 % больше, чем в GB300 NVL72. 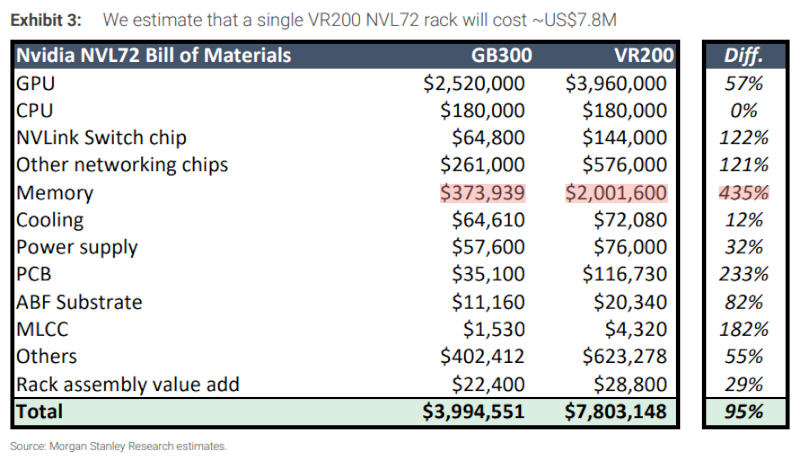
Источник изображения: x.com/Aaronwei3n На каждую стойку нового поколения приходятся 54 Тбайт памяти LPDDR5X — втрое больше, чем 17 Тбайт у GB200 NVL72. Nvidia, по оценкам SemiAnalysis, в I квартале платила по $8 за 1 Гбайт LPDDR5X, и дальше этот показатель может только вырасти, особенно если речь идёт о дорогих в производстве и тестировании модулях SOCAMM2. Таким образом, память для GB200 NVL72 обходится в $136 000 на каждую машину; в случае VR200 NVL72 это уже $408 000, а при росте цены до $10 за 1 Гбайт это будут уже $540 000 — даже без учёта наценки самой Nvidia. Кроме того, в каждой стойке VR200 NVL72 содержится память 3D NAND на сумму не менее $1 млн, тогда как в GB200 NVL72 её практически не было. В результате $2 млн за память на стойку Vera Rubin NVL72 представляется вполне предсказуемым показателем: здесь есть большие объёмы LPDDR5X и 3D NAND, не говоря уже о высокоскоростной HBM4 на самих ускорителях Rubin — и это в условиях дефицита и колоссальных цен на чипы памяти. ИИ продолжает раздувать бизнес Nvidia — квартальная выручка взлетела на 85 % до небывалых $81,6 млрд
21.05.2026 [05:58],
Алексей Разин
Квартальный отчёт Nvidia стоит особняком не только хронологически, он также позволяет оценить динамику бума ИИ, который толкает выручку компании вверх с конца 2022 года. По итогам прошлого квартала Nvidia нарастила свою выручку на 85 % до рекордных $81,6 млрд, превзойдя ожидания аналитиков. В сегменте ЦОД выручка выросла на 92 % до $75,2 млрд. 
Источник изображений: Nvidia Таким образом, серверное направление бизнеса Nvidia в очередной раз побило рекорд, последовательно увеличив выручку на 21 %. Общая выручка также выросла на 20 % по сравнению с предыдущим кварталом, поэтому именно серверный сегмент определял динамику развития всего бизнеса компании в первом фискальном квартале, завершившемся в конце апреля. Соответственно, на серверный сегмент пришлось более 92 % общей выручки Nvidia. 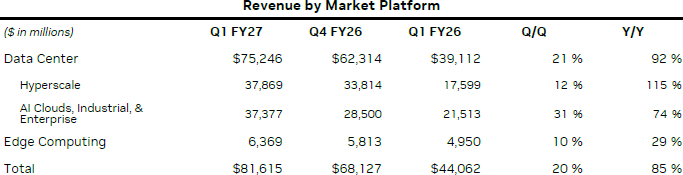 Внутри сегмента ЦОД выручка почти поровну разделилась между гиперскейлерами ($37,9 млрд) и всеми прочими клиентами ($37,3 млрд), включая корпоративных, облачных, государственных и промышленных. В первом случае выручка увеличилась год к году на 115 %, во втором — на 74 %. Помимо ЦОД, компания в своей отчётности упоминает и сегменте периферийных вычислений, выручка в котором увеличилась на 29 % до $6,4 млрд. По словам финансового директора компании Колетт Кресс (Colette Kress), если спрос на рабочие станции с решениями семейства Blackwell был высоким, то дефицит памяти навредил продажам ПК своими высокими ценами. Сетевые решения для ЦОД увеличили профильную выручку Nvidia в три раза до рекордных $14,8 млрд. Поставки ускорителей семейства Vera Rubin компания планирует начать во второй половине текущего года. Генеральный директор Nvidia признался, что эти ускорители наверняка будут в дефиците на протяжении основной части своего жизненного цикла. Отдельно подчёркивается, что за прошедший квартал в Китай не было поставлено ни одного ускорителя с архитектурой Hopper, тогда как год назад соответствующая выручка достигла $4,6 млрд. Несмотря на принципиальное согласие властей США на поставку в КНР ускорителей H200, китайская сторона не разрешила их импорт. Тем не менее, китайский рынок в целом принёс Nvidia в прошлом квартале $4,55 млрд — на 53 % меньше, чем годом ранее. Для сравнения, американская выручка Nvidia за год почти утроилась до $63,8 млрд, и это закономерно с учётом высокой концентрации в США облачных гигантов, которые закупают компоненты Nvidia для своих ЦОД. Колетт Кресс добавила, что не уверена, будет ли разрешён импорт ускорителей H200 в Китай.  Если рассматривать разделение по функциональным сегментам, то вычислительные и сетевые решения увеличили выручку Nvidia на 88 % до $74,6 млрд, а направление графических решений прибавило 58 % до $7,1 млрд. В этом году Nvidia рассчитывает выручить $20 млрд на поставках центральных процессоров, что сделает одним из крупнейших поставщиков этого вида компонентов в денежном выражении. Ёмкость всего рынка CPU руководство компании оценивает в $200 млрд, и эта сумма не входит в тот $1 трлн, который Nvidia рассчитывает выручить на поставках ускорителей Blackwell и Rubin в период с 2025 по 2027 годы. Основатель Nvidia Дженсен Хуанг (Jensen Huang) ожидает, что центральные процессоры Vera станут вторым по величине источником выручки после ускорителей Blackwell и Rubin. В текущем квартале Nvidia рассчитывает выручить до $91 млрд, и это в среднем выше консенсус-прогноза аналитиков, но в данные ожидания компания не закладывает каких-либо поступлений от реализации серверных решений на китайском рынке. Норма прибыли Nvidia в текущем квартале сохранится на уроне 75 %. Было бы неверно утверждать, что операционные расходы компании не увеличиваются — в минувшем квартале они возросли на 52 %, но операционная прибыль всё равно увеличилась на 147 % до $53,5 млрд, а чистая прибыль достигла $58,3 млрд по методике GAAP, взлетев более чем в три раза в годовом сравнении. По итогам текущего года Nvidia может выручить более $370 млрд, если верить некоторым прогнозам. Это будет в 22 раза больше, чем за шесть лет до этого. SRAM какой-то: Nvidia представила чип Groq 3 LPU для ускорения инференса ИИ-моделей на уровне токенов
17.03.2026 [14:45],
Дмитрий Федоров
На прошедшей в этом году конференции GTC генеральный директор Nvidia Дженсен Хуанг (Jensen Huang) сообщил, что в этом году платформа Vera Rubin получит расширение. Nvidia использует для этого интеллектуальную собственность, приобретённую у Groq. В состав Rubin вошёл новый чип Nvidia Groq 3 LPU. Компания определяет его как ускоритель инференса. Его задача — выдавать токены в большом объёме и с низкой задержкой. 
Источник изображений: Nvidia Платформа Rubin уже включает шесть компонентов, из которых Nvidia собирает стоечные системы и затем масштабирует их до ИИ-фабрик. Это GPU Rubin, CPU Vera, коммутаторы внутрисистемного масштабирования NVLink 6, интеллектуальный сетевой адаптер ConnectX-9, процессор обработки данных BlueField-4 и коммутатор межсистемного масштабирования Spectrum-X с совместно интегрированной оптикой. Groq 3 LPU стал новым элементом этой платформы и ещё одним строительным блоком Rubin при масштабном развёртывании.  Groq 3 LPU отличается от большинства ИИ-ускорителей схемой памяти. Обычно такие системы используют HBM в качестве рабочего уровня памяти. Каждый Groq 3 LPU содержит 500 Мбайт SRAM. Для сравнения, каждый GPU Rubin оснащён 288 Гбайт HBM4. По ёмкости разница велика. По пропускной способности соотношение иное: SRAM обеспечивает до 150 Тбайт/с, а HBM4 — около 22 Тбайт/с. Для ИИ-задач, чувствительных к пропускной способности, рост этого показателя даёт преимущество при инференсе. Именно поэтому Nvidia вводит Groq 3 в состав Rubin.  Стойка Groq 3 LPX включает 256 чипов Groq 3 LPU. Такая система располагает 128 Гбайт SRAM. Её суммарная пропускная способность достигает 40 Пбайт/с. Для объединения чипов внутри стойки предусмотрен выделенный интерфейс внутрисистемного масштабирования. Его пропускная способность составляет 640 Тбайт/с на стойку.  Вице-президент Nvidia по гипермасштабируемым решениям Иэн Бак (Ian Buck) назвал Groq LPX сопроцессором для Rubin. По его словам, он повысит производительность декодирования «на каждом слое ИИ-модели на каждом токене». Nvidia связывает это решение со следующим рубежом ИИ — мультиагентными системами. Речь идёт о сценариях, где нужно обеспечивать интерактивную работу при инференсе моделей с триллионами параметров и окнами контекста в миллионы токенов.  Когда ИИ-агенты всё чаще обмениваются данными друг с другом, а не с человеком в окне чат-бота, меняется и порог приемлемого отклика. Скорость, достаточная для человека, оказывается слишком низкой для ИИ-агента. Бак описывает переход от мира, где разумным считался уровень 100 токенов в секунду, к уровню 1 500 токенов в секунду и выше для межагентного обмена.  Добавление Groq 3 LPU должно усилить позиции Rubin в сегменте низколатентного инференса. В тексте в качестве конкурента названа Cerebras. Компания использует процессоры Wafer-Scale Engine (WSE), выполненные на целой кремниевой пластине, где большие объёмы SRAM объединены с вычислениями для низколатентного инференса на продвинутых моделях. OpenAI также привлекала мощности Cerebras для обслуживания части передовых моделей из-за выгодных характеристик задержки этой платформы.  Иэн Бак также допустил, что появление Groq 3 LPU может сократить роль ускорителя инференса Rubin CPX. Он сказал, что сейчас Nvidia сосредоточена на интеграции стойки Groq 3 LPX с Rubin. Дополнительных подробностей он не привёл. При этом оба чипа рассчитаны на сходное усиление инференса, но Groq LPU не требует большого объёма памяти GDDR7, который нужен каждому модулю Rubin CPX. Micron запустила массовое производство памяти HBM4 для Nvidia Vera Rubin
17.03.2026 [10:41],
Алексей Разин
Поскольку на этой неделе Nvidia официально представила свою ИИ-платформу Vera Rubin, компания Micron Technology не нашла причин для дальнейшего сокрытия факта сотрудничества с ней в области поставок памяти типа HBM4. Было объявлено, что этот третий по счёту поставщик приступил к серийному производству микросхем HBM4 в 12-ярусном исполнении. 
Источник изображения: Micron Technology В одном стеке HBM4 при такой компоновке содержится 36 Гбайт памяти, которая способна передавать информацию со скоростью более 1 Гбит/с на контакт, обеспечивая совокупную пропускную способность на уровне 2,8 Тбайт/с. По сравнению с HBM3E той же марки, это соответствует росту пропускной способности в 2,3 раза и улучшению энергетической эффективности более чем на 20 %, как отмечает Tom’s Hardware. Micron Technology также отправила своим клиентам образцы 16-ярусных чипов HBM4 объёмом 48 Гбайт. По сравнению с 12-ярусным стеком, они обеспечивают увеличение удельной ёмкости на 33 %. Одновременно Micron объявила о начале массового производства твердотельных накопителей семейства 9650, обеспечивающих поддержку новейшего интерфейса PCI Express 6.0. Данные накопители обеспечивают скорость последовательного чтения до 28 Гбайт/с и 5,5 млн операций ввода-вывода в секунду на операциях произвольного чтения. По сравнению с накопителями, оснащаемыми интерфейсом PCI Express 5.0, это обеспечивает вдвое более высокое быстродействие на операциях чтения, энергоэффективность также увеличивается в два раза. Данные накопители оптимизированы для использования в составе стоек BlueField-4 STX, относящихся к платформе Vera Rubin. Кроме того, Micron представила модули памяти типа SOCAMM2 объёмом 192 Гбайт, также оптимизированные для решений Nvidia семейства Vera Rubin, включая стойки NVL72 и обособленные платформы на основе центральных процессоров Vera. Эти модули памяти будут предлагаться в диапазоне ёмкостей от 48 до 256 Гбайт. Платформа Vera Rubin поддерживает до 2 Тбайт оперативной памяти, а пропускная способность на один процессор достигает 1,2 Тбайт/с при использовании данной памяти. Все три новинки Micron уже производятся серийно и могут поставляться для нужд Nvidia и её партнёров, выпускающих решения семейства Vera Rubin. Nvidia показала полный стек Vera Rubin — от GPU до сетей для ИИ-фабрик нового поколения
17.03.2026 [10:01],
Алексей Разин
Являясь одним из лидеров в сфере вычислительной инфраструктуры для систем искусственного интеллекта, Nvidia комплексно подходит к развитию собственных платформ, а потому вместе с ускорителями поколения Vera Rubin предложила ряд сопутствующих аппаратных решений. 
Источник изображений: Nvidia Как отмечается в корпоративном пресс-релизе, платформа Vera Rubin открывает новые рубежи в развитии агентского искусственного интеллекта. В массовом производстве сейчас находятся семь новых чипов Nvidia, позволяющих эффективно масштабировать так называемые ИИ-фабрики. В число семи аппаратных новинок Nvidia вошли графические процессоры Rubin, центральные процессоры Vera, коммутаторы NVLink 6, сетевые решения ConnectX-9 SuperNIC, специализированные процессоры BlueField-4 и Ethernet-коммутаторы Spectrum-6, а также созданные с помощью разработок одноимённого поглощённого стартапа процессоры Groq для ускорения инференса при работе с ИИ-агентами. В совокупности они работают, как ИИ-суперкомпьютер, как отмечается в материалах Nvidia для прессы на официальном сайте компании, позволяя ускорять создание профильных технологий на всех этапах жизненного цикла ИИ-систем. Основатель и глава Nvidia Дженсен Хуанг (Jensen Huang) заявил, что с выходом платформы Vera Rubin наступил переломный момент в развитии агентского ИИ, поскольку данная платформа будет способствовать самому масштабному развёртыванию инфраструктуры в истории. Руководители OpenAI и Anthropic прокомментировали анонс Vera Rubin в предсказуемо хвалебных выражениях, подчёркивая значение этого события для всей ИИ-отрасли. Разработчики ИИ-моделей теперь смогут совершенствовать их и делать это быстрее, чем на аппаратных решениях прошлого поколения. Структура ЦОД теперь строится на готовых модулях, как считают в Nvidia, которые содержат всё необходимое для эффективного масштабирования вычислительных мощностей с учётом постоянного роста сложности решаемых задач. Клиенты могут сочетать готовые модули ЦОД с учётом специфики своей деятельности. Например, в одной стойке Vera Rubin NVL72 находятся 72 графических процессора Rubin и 36 центральных процессоров Vera, соединённых скоростной шиной NVLink 6 и сетевыми контроллерами ConnectX-9 SuperNIC, а также специализированные процессоры BlueField-4, которые разгружают центральные процессоры от задач работы с сетевым трафиком. По сравнению с решениями поколения Blackwell новые системы Vera Rubin справляются с обучением сложных моделей силами в четыре раза меньшего количества GPU. Пропускная способность в пересчёте на ватт потребляемой энергии в задачах инференса у Vera Rubin до десяти раз выше, а затраты на один токен в десять раз ниже. В кластерах стойки NVL72 масштабируются при помощи Quantum-X800 InfiniBand и Spectrum-X Ethernet. Центральные процессоры Vera, по словам представителей Nvidia, хорошо себя проявляют в задачах обучения с подкреплением и агентских ИИ-нагрузках. Компания может объединять в одной стойке до 256 таких процессоров, оснащённых системой жидкостного охлаждения. С прочими компонентами кластера они могут сообщаться при помощи сетевых решений Spectrum-X. По сравнению с некими традиционными CPU, на которые ссылается Nvidia, её процессоры Vera могут справляться с ИИ-задачами на 50 % быстрее.  Специализированные чипы Groq 3 LPX обеспечивают эффективную работу с агентскими ИИ-нагрузками при минимальных задержках. В сочетании с другими чипами, входящими в состав платформы Vera Rubin, они обеспечивают увеличение пропускной способности в задачах инференса до 35 раз на один мегаватт потребляемой мощности, а потенциал выручки при использовании моделей с триллионом параметров увеличивается в десять раз. В состав одной стойки входит 256 чипов LPU, 128 Гбайт интегрированной на них памяти SRAM, а пропускная способность достигает 640 Тбайт/с. В сочетании с прочими компонентами платформы Vera Rubin, чипы LPU достигают максимальной эффективности как по быстродействию, так и по энергопотреблению, а также использованию ресурсов памяти. Стойки LPX будут доступны клиентам Nvidia со второй половины текущего года. Стойка BlueField-4 STX специализируется на унификации адресного пространства GPU между элементами кластера. Обработка хранимой в кеше информации в операциях инференса ускоряется до пяти раз, при этом обеспечивается высокая энергоэффективность по сравнению с системами на классической архитектуре. Достигается общий для кластера контекст, обеспечивающий быстрое взаимодействие с ИИ-агентами и более эффективно масштабируемыми ИИ-сервисами. Отдельная стойка Spectrum-6 SPX отвечает за скоростной обмен данными по интерфейсу Ethernet. Она может содержать не только коммутаторы Spectrum-X Ethernet, но и коммутаторы Nvidia Quantum-X800 InfiniBand в зависимости от потребностей конкретной конфигурации. В исполнении с кремниевой фотоникой и интеграцией на уровне упаковки чипов эффективность передачи информации возрастает в пять раз, а надёжность по сравнению с традиционными подключаемыми решениями увеличивается в десять раз. «Космические вычисления уже здесь»: Nvidia представила модуль Space-1 Vera Rubin для орбитальных ИИ-серверов
17.03.2026 [00:33],
Николай Хижняк
Генеральный директор Nvidia Дженсен Хуанг (Jensen Huang) анонсировал на конференции GTC 2026 космический модуль Nvidia Space-1 Vera Rubin Module. По словам Хуанга, модуль обеспечивает до 25 раз большую вычислительную мощность для задач искусственного интеллекта, чем сервер с ускорителями H100. 
Источник изображения: Nvidia По словам Nvidia, в настоящее время шесть коммерческих космических компаний используют её платформы в орбитальной и наземной средах: Aetherflux, Axiom Space, Kepler Communications, Planet Labs PBC, Sophia Space и Starcloud. При этом Kepler использует в своей спутниковой группировке платформу Jetson Orin для управления данными с помощью ИИ. «Nvidia Jetson Orin внедряет передовые технологии ИИ непосредственно на наши спутники, позволяя нам интеллектуально управлять данными и маршрутизировать их по всей нашей группировке», — заявила Мина Митри (Mina Mitry), генеральный директор компании, в официальном пресс-релизе Nvidia. В октябре прошлого года основатель Amazon и Blue Origin Джефф Безос (Jeff Bezos) предсказал, что орбитальные центры обработки данных гигаваттного уровня появятся через 10–20 лет. В качестве основных преимуществ таких платформ он назвал непрерывное солнечное электроснабжение и упрощённую систему охлаждения в космосе. Starcloud, один из шести партнёров Nvidia, уже строит, как он сам описывает, специально разработанные орбитальные центры обработки данных, предназначенные для выполнения задач обучения моделей ИИ и вывода данных на орбите. «Космические вычисления, последний рубеж, уже здесь», — сказал Дженсен Хуанг, добавив, что «обработка данных с помощью ИИ в космических и наземных системах обеспечивает сбор данных в реальном времени, принятие решений и автономность, превращая орбитальные центры обработки данных в инструменты исследований, а космические аппараты — в системы с автономным управлением». Глава Nvidia не сказал, когда космический модуль Vera Rubin станет доступен для развёртывания. Компания уже предлагает в качестве космических платформ IGX Thor, Jetson Orin и RTX Pro 6000 Blackwell Server Edition. Meta✴ закупит миллионы ИИ-чипов у Nvidia, включая центральные Arm-процессоры Grace и Vera
18.02.2026 [04:51],
Алексей Разин
Компания Meta✴✴ Platforms готова расширить свою вычислительную инфраструктуру ИИ путём закупки дополнительных объёмов компонентов Nvidia, которые будут включать как GPU нового поколения, так и целые стойки семейства Vera Rubin, равно как и центральные процессоры Nvidia Grace. 
Источник изображения: Nvidia Как поясняет CNBC, исторически Meta✴✴ в развитии своей ИИ-инфраструктуры отличалась всеядностью, закупая ускорители AMD и процессоры Google, а также разрабатывая собственные. Помимо вычислительных решений Nvidia, на новом этапе расширения своей облачной инфраструктуры Meta✴✴ готова использовать и сетевые решения этой марки. Кроме того, чипы Nvidia помогут ей реализовать ИИ-функции в мессенджере WhatsApp. Новая сделка между компаниями подразумевает закупку миллионов чипов Nvidia для нужд Meta✴✴ Platforms. На каких условиях это будет сделано, не уточняется. В январе Meta✴✴ объявила о намерениях потратить до $135 млрд на развитие ИИ в текущем году. По мнению аналитиков Creative Strategies, в случае с новой сделкой речь идёт о десятках миллиардов долларов США. Новость об этой сделке вызвала рост курса акций Nvidia и Meta✴✴, а вот акции AMD упали в цене на 4 %. Компоненты Nvidia компания Meta✴✴ уже использует в своей инфраструктуре не менее десяти лет, но никогда ранее она не приобретала у неё центральные процессоры в отдельности от специализированных модулей, где те обычно соседствуют с GPU. Представители Nvidia подтвердили, что Meta✴✴ станет первым клиентом, приступившим к масштабному использованию центральных процессоров Grace. Эти чипы больше заточены под агентские ИИ-нагрузки и работу с инференсом. В 2027 году Meta✴✴ планирует перейти на использование нового поколения процессоров Vera разработки Nvidia. В общей сложности до 2028 года Meta✴✴ планирует направить на развитие вычислительных мощностей в США около $600 млрд. Из 30 центров обработки данных, запланированных Meta✴✴ к строительству в ближайшие годы, 26 будут расположены на территории США. Крупнейшими станут гигаваттный Prometheus в Огайо и 5-ГВт Hyperion в Луизиане. Коммутаторы Spectrum-X производства Nvidia также будут применяться Meta✴✴ в своей инфраструктуре, а ещё последняя внедрит технологии безопасности первой для развития функций ИИ в WhatsApp. Новых GeForce RTX пока не будет, — а заодно Nvidia сократит выпуск существующих видеокарт на 30–40 %
06.02.2026 [10:07],
Алексей Разин
Бум систем ИИ вызвал не только дефицит памяти, но и высокий спрос на ускорители вычислений Nvidia, поэтому для этой компании выгоднее сосредоточиться именно на последней категории продукции. Как отмечает The Information со ссылкой на собственные источники, впервые в своей новейшей истории Nvidia может пережить текущий год без анонса новых моделей игровых видеокарт. 
Источник изображения: Nvidia Существующие квоты на микросхемы памяти Nvidia намеревается использовать для комплектации востребованных и более прибыльных ускорителей вычислений. Долгое время Nvidia считалась поставщиком игровых решений, но на фоне бума ИИ её приоритеты могли измениться, даже если руководство публично будет настаивать на обратном. Некоторые источники даже сообщают, что и объёмы выпуска игровых видеокарт существующего поколения (GeForce RTX 50) сокращаются из-за дефицита памяти. Нехватка самих видеокарт уже вызвала рост розничных цен по всему миру. Представители Nvidia прокомментировали эту публикацию The Information лишь дежурной фразой о том, что спрос на видеокарты GeForce RTX остаётся высоким, а доступность памяти ограничена. Поставки видеокарт данного семейства продолжаются, а с производителями памяти компания старается работать над улучшением ситуации с доступностью компонентов. По неофициальным данным, первоначально Nvidia в этом году планировала представить обновлённое семейство видеокарт с условным обозначением Kicker, чьи характеристики незначительно бы превосходили GeForce RTX 50, и разработка нового семейства фактически завершена. В декабре руководство компании якобы заявило заинтересованным специалистам, что вывод Kicker на рынок отложен на неопределённый срок. Имеющуюся в условиях дефицита память решено было направить на удовлетворение спроса в серверном сегменте. Скорее всего, анонс более серьёзно обновлённого семейства видеокарт GeForce RTX 60 с архитектурой Rubin, который был запланирован на конец следующего года, тоже будет сдвинут «вправо». В серверном сегменте ускорители с архитектурой Rubin уже выпускаются, они будут доступны клиентам Nvidia со второй половины текущего года. За первые девять месяцев прошлого фискального года игровая выручка компании составляла лишь 8 % от совокупной, хотя до выхода ChatGPT осенью 2022 года эта доля достигала 35 %. Кроме того, на ускорителях вычислений Nvidia зарабатывает гораздо больше (до 65 %), чем на игровых видеокартах в удельном измерении (лишь 40 %). Samsung начнёт выпускать память типа HBM4 для Nvidia в следующем месяце
26.01.2026 [04:51],
Алексей Разин
В первой половине этого месяца появлялась информация о том, что начало массового выпуска памяти типа HBM4 откладывается до конца первого квартала по причинам, связанным с компанией Nvidia. Эту неделю агентство Reuters начало с сообщения о готовности Samsung начать производство HBM4 в следующем месяце. 
Источник изображения: Nvidia Получать эти чипы предсказуемо будет Nvidia, поскольку они требуются для производства ускорителей вычислений семейства Rubin. В случае с предыдущими поколениями ускорителей Nvidia приоритетным поставщиком HBM оставалась SK hynix, но Samsung уже давно идёт к цели по превращению в серьёзного поставщика HBM4, желая наверстать упущенное и как минимум догнать конкурента. Каким будет объём первых партий HBM4 в исполнении Samsung, не уточняется. Южнокорейское издание Korea Economic Daily сегодня сообщило, что память HBM4 в исполнении Samsung прошла квалификационные тесты Nvidia и AMD, а потому формально этот производитель имеет возможность начать её поставки первому из клиентов в следующем месяце. Первые образцы HBM4 были отправлены Samsung для тестирования в лабораториях Nvidia ещё в сентябре прошлого года. SK hynix в октябре сообщила, что завершила переговоры о поставках HBM на 2026 год с основными клиентами. Ради удовлетворения спроса на память данного семейства SK hynix со следующего месяца начнёт поставки кремниевых пластин для производства памяти на новое предприятие M15X в Южной Корее. Samsung и SK hynix отчитаются о результатах прошлого квартала в этот четверг, наверняка на мероприятиях по этому поводу что-то будет сказано в отношении сроков поставок HBM4. Глава Nvidia в начале этого месяца подтвердил, что производство чипов для ускорителей Vera Rubin уже началось. Соответственно, медлить с выпуском HBM4 для этой платформы особой нужды нет. Поставки первых систем на ускорителях Nvidia Rubin стартуют в конце лета
20.01.2026 [14:33],
Алексей Разин
В этом месяце глава и основатель Nvidia Дженсен Хуанг (Jensen Huang) продемонстрировал ускорители вычислений поколения Rubin, заявив о начале их массового производства. Между тем, серверная продукция обычно длительное время добирается до конечных пользователей, а потому и поставки систем на семейства Vera Rubin партнёры Nvidia собираются начать лишь к концу этого лета. 
Источник изображения: Nvidia Об этом сообщает Commercial Times со ссылкой на комментарии вице-президента тайваньского производителя серверного оборудования Quanta Computer Майка Янга (Mike Yang), которые тот сделал на прошлой неделе на праздничном корпоративном мероприятии. Гиганты облачных вычислений начнут получать соответствующие системы на базе ускорителей Nvidia Rubin в августе текущего года. На тот момент отгрузки не будут массовыми, а потому Quanta Computer и не рассчитывает на получение существенной выручки от поставок первых систем на базе Vera Rubin. Основная часть клиентов компании, по словам её представителя, уже эксплуатирует системы поколения Grace Blackwell (GB200 и GB300), что при условии родства архитектур с Vera Rubin позволит им достаточно быстро и безболезненно обновить в случае необходимости аппаратную базу. В официальных документах Nvidia осенью прошлого года сроки производства Vera Rubin упоминались достаточно размыто — под его начало отводился весь 2026 год. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex


