|
Опрос
|
реклама
Быстрый переход
Microsoft представила три новые малые ИИ-модели семейства Phi-4
01.05.2025 [16:48],
Дмитрий Федоров
Microsoft выпустила три новые малые языковые модели (SLM) с открытой лицензией: Phi-4-mini-reasoning, Phi-4-reasoning и Phi-4-reasoning-plus. Каждая из моделей относится к классу рассуждающих (reasoning) моделей, ориентированных на логическую верификацию решений и тщательную проработку сложных задач. Эти ИИ-модели стали продолжением инициативы Microsoft по разработке компактных ИИ-систем — семейства Phi, впервые представленного год назад как фундамент для приложений, работающих на устройствах с ограниченными вычислительными возможностями. 
Источник изображения: Jackson Sophat / Unsplash Наиболее производительной из представленных является ИИ-модель Phi-4-reasoning-plus. Она представляет собой адаптацию ранее выпущенной Phi-4 под задачи логического вывода. По утверждению Microsoft, её качество ответов близко к DeepSeek R1, несмотря на существенную разницу в объёме параметров: у DeepSeek R1 — 671 млрд, тогда как у Phi-4-reasoning-plus их значительно меньше. Согласно внутреннему тестированию Microsoft, эта модель показала результаты, соответствующие ИИ-модели OpenAI o3-mini в рамках бенчмарка OmniMath, оценивающего математические способности ИИ. 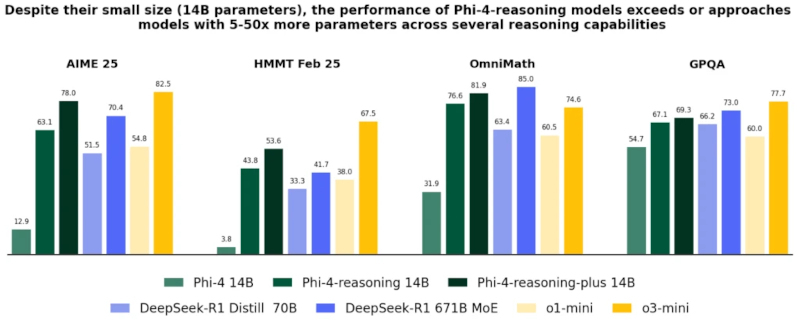
Модели Phi-4-reasoning и Phi-4-reasoning-plus (14 млрд параметров) демонстрируют превосходство над базовой Phi-4 и уверенно конкурируют с более крупными системами, включая DeepSeek-R1 Distill (70 млрд параметров) и OpenAI o3-mini, в задачах математического и логического мышления (AIME, HMMT, OmniMath, GPQA). Источник изображения: Microsoft Модель Phi-4-reasoning содержит 14 млрд параметров и обучалась на основе «качественных» данных из интернета, а также на отобранных демонстрационных примерах из o3-mini. Она оптимизирована для задач в области математики, естественных наук и программирования. Таким образом, Phi-4 reasoning ориентирована на высокоточные вычисления и аналитическую интерпретацию данных, оставаясь при этом относительно компактной и доступной для использования на локальных вычислительных платформах. 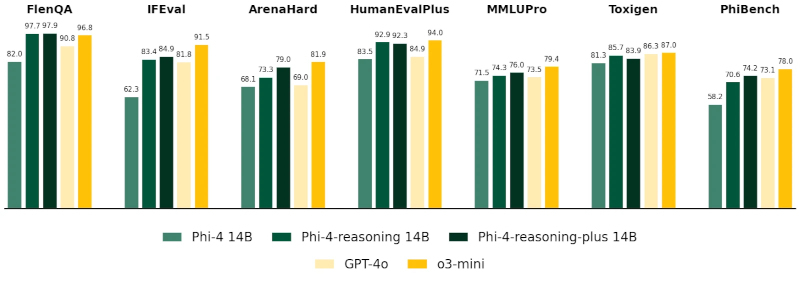
На универсальных тестах, включая FlenQA, IFEval, HumanEvalPlus, MMLUPro, ToxiGen и PhiBench, модели Phi-4-reasoning-plus демонстрируют точность, сопоставимую с GPT-4o и o3-mini, несмотря на меньший объём параметров (14 млрд параметров), особенно в задачах программирования, логики и безопасности. Источник изображения: Microsoft Phi-4-mini-reasoning — самая малогабаритная из представленных SLM. Её размер составляет около 3,8 млрд параметров. Она обучалась на основе приблизительно 1 млн синтетических математических задач, сгенерированных ИИ-моделью R1 китайского стартапа DeepSeek. Microsoft позиционирует её как ИИ-модель для образовательных сценариев, включая «встроенное обучение» на маломощных и мобильных устройствах. Благодаря компактности и точности, эта ИИ-модель может применяться в интерактивных обучающих системах, где приоритетом являются скорость отклика и ограниченность вычислительных ресурсов. 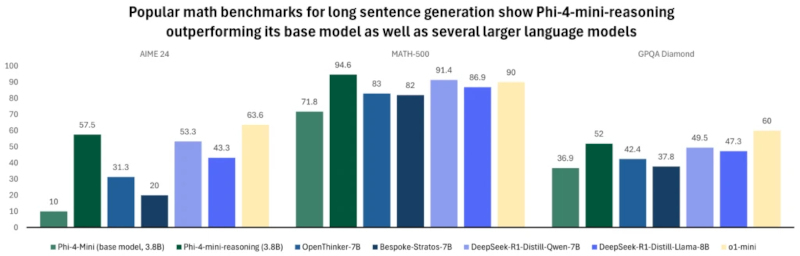
Phi-4-mini-reasoning (3,8 млрд параметров) значительно превосходит свою базовую версию и модели с вдвое большим размером на бенчмарках AIME 24, MATH-500 и GPQA Diamond, а также сопоставима или превосходит OpenAI o1-mini по точности генерации длинных математических ответов. Источник изображения: Microsoft Все три ИИ-модели доступны на платформе Hugging Face и распространяются под открытой лицензией. По словам Microsoft, при их обучении использовались дистилляция, обучение с подкреплением и высококачественные обучающие данные. Эти методы позволили сбалансировать размер SLM и их вычислительную производительность. ИИ-модели достаточно компактны, чтобы использоваться в средах с низкой задержкой, но при этом способны решать задачи, требующие строгости логического построения и достоверности результата. Ранее такие задачи были характерны лишь для гораздо более крупных ИИ. Сфера ИИ заинтересовалась малыми языковыми моделями — они дешевле и эффективнее больших в конкретных задачах
13.04.2025 [21:16],
Владимир Мироненко
На рынке ИИ сейчас наблюдается тренд на использование малых языковых моделей (SLM), которые имеют меньше параметров, чем большие языковые модели (LLM), и лучше подходят для более узкого круга задач, пишет журнал Wired. 
Источник изображения: Luke Jones/unsplash.com Новейшие версии LLM компаний OpenAI, Meta✴✴ и DeepSeek имеют сотни миллиардов параметров, благодаря чему могут лучше определять закономерности и связи, что делает их более мощными и точными. Однако их обучение и использование требуют огромных вычислительных и финансовых ресурсов. Например, обучение модели Gemini 1.0 Ultra обошлось Google в 191 миллион долларов. По данным Института исследований электроэнергетики, выполнение одного запроса в ChatGPT требует примерно в 10 раз больше энергии, чем один поиск в Google. IBM, Google, Microsoft и OpenAI недавно выпустили SLM, имеющие всего несколько миллиардов параметров. Их нельзя использовать в качестве универсальных инструментов, как LLM, но они отлично справляются с более узко определёнными задачами, такими как подведение итогов разговоров, ответы на вопросы пациентов в качестве чат-бота по вопросам здравоохранения и сбор данных на интеллектуальных устройствах. «Они также могут работать на ноутбуке или мобильном телефоне, а не в огромном ЦОД», — отметил Зико Колтер (Zico Kolter), учёный-компьютерщик из Университета Карнеги — Меллона. Для обучения малых моделей исследователи используют несколько методов, например дистилляцию знаний, при которой LLM генерирует высококачественный набор данных, передавая знания SLM, как учитель даёт уроки ученику. Также малые модели создаются из больших путём «обрезки» — удаления ненужных или неэффективных частей нейронной сети. Поскольку у SLM меньше параметров, чем у больших моделей, их рассуждения могут быть более прозрачными. Небольшая целевая модель будет работать так же хорошо, как большая, при выполнении конкретных задач, но её будет проще разрабатывать и обучать. «Эти эффективные модели могут сэкономить деньги, время и вычислительные ресурсы», — сообщил Лешем Чошен (Leshem Choshen), научный сотрудник лаборатории искусственного интеллекта MIT-IBM Watson. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



