|
Опрос
|
реклама
Быстрый переход
Джек Дорси представил конкурента Slack и GitHub — открытый мессенджер Buzz с ИИ-агентами и вайб-кодингом
22.07.2026 [17:31],
Павел Котов
Соучредитель платформ Twitter и Block Джек Дорси (Jack Dorsey) анонсировал приложение под названием Buzz. Платформа выступает конкурентом одновременно корпоративному мессенджеру Slack и репозиторию GitHub — она предлагает рабочие чаты, объединяя коллег и ИИ-агентов. 
Источник изображения: buzz.xyz Мессенджер Buzz «независим от модели, децентрализован, самодостаточен и имеет открытый исходный код». Разработчиком платформы выступила компания Джека Дорси Block, которая также управляет такими продуктами как Square, Cash App, Afterpay и Tidal. Современные стартапы всё чаще используют в работе агентов с искусственным интеллектом, но сотрудникам может быть непросто вести совместную работу на разных платформах, поэтому Buzz предполагает присутствие нескольких рабочих процессов в едином пространстве. Мессенджер очень похож на Slack, но здесь есть встроенные ИИ-агенты и возможность управлять проектами на GitHub в одном окне. Платформа поставляется с открытым исходным кодом, и разработчики могут настраивать инстансы Buzz под рабочие процессы своих компаний. Для новых организаций, которые не успели укорениться в традиционных корпоративных мессенджерах вроде Slack, приложение Buzz может оказаться достойным внимания. Разработчики, однако, предупреждают, что сервис находится на «ранней стадии», поэтому и торопиться с его внедрением пока не следует. Исходный код платформы опубликован на GitHub, есть десктопные клиенты для Apple macOS, Microsoft Windows и Linux. «Сбер» выпустил GigaChat 3.5 Ultra — LLM стала умнее и приблизилась по ряду показателей к DeepSeek 3.2
06.07.2026 [16:46],
Владимир Мироненко
«Сбер» представил новую флагманскую модель GigaChat 3.5 Ultra, которая доступна бесплатно всем желающим в ИИ-помощнике «ГигаЧат» для решения личных и рабочих задач, а также разработчикам по всему миру для встраивания в свои сервисы и создания ИИ-агентов. 
Источник изображения: «Сбер» «Сбер» отметил, что новая модель умнее предыдущей версии, до четырёх раз быстрее генерирует длинные тексты, более экономно потребляет вычислительные ресурсы, а также почти вдвое компактнее. GigaChat 3.5 Ultra основана на архитектуре MoE (Mixture of Experts) с технологией линейного внимания, разработанной «Сбером», благодаря чему, запомнив суть прочитанного, в дальнейшем просто дополняет информацию, тогда как при использовании классического «внимания», ИИ-модель при каждом новом слове заново сверяет его со всем предыдущим текстом. GigaChat 3.5 Ultra — одна из самых больших моделей с линейным вниманием среди выходивших в Open Source. Модель увереннее, чем предшественник, генерирует и проверяет код, точнее решает математические задачи и выполняет финансовые расчёты, работает с числами, а также эффективно анализирует контракты, техрегламенты, отчёты и другие объёмные документы без потери точности и контекста. Получив задачу, она сама найдёт информацию, напишет и выполнит код, обратится к нужному сервису и предоставит готовый результат. GigaChat 3.5 Ultra превзошла предшественника на целом ряде тестов, а по некоторым показателям приблизилась к результатам сильных открытых моделей, например, к DeepSeek 3.2, при этом, будучи почти вдвое компактнее. Сообщается, что при её обучении был сделан акцент на натуральных, созданных человеком текстах, прошедших многоуровневую классификацию и фильтрацию. Количество экспериментов при разработке новой модели выросло более чем вдвое, до 1500. Китайский гигант Meituan представил открытую ИИ-модель LongCat-2.0 на 1,6 трлн параметров — её обучили только на китайских чипах
01.07.2026 [11:28],
Владимир Фетисов
Китайский гигант доставки еды Meituan объявил о запуске большой языковой модели с открытым исходным кодом LongCat-2.0. Компания заявила, что это первая ИИ-модель с триллионом параметров, для обучения которой использовался кластер из 50 тыс. ИИ-ускорителей китайского производства. 
Источник изображения: Ricardo / unsplash.com Компания не раскрыла, как именно новая ИИ-модель LongCat-2.0 будет интегрирована в бизнес-процессы. Предыдущую версию системы использовали для обеспечения работы ИИ-помощников в приложениях Meituan для генерации рекомендаций по выбору ресторанов и отелей, а также выполнения разных задач, таких как формирование заказов на доставку еды и бронирование номеров в отелях. На фоне сокращения прибыли Meituan также может искать способы диверсификации источников дохода. В сообщении, опубликованном в официальном аккаунте LongCat на платформе WeChat, компания подчеркнула способность новой ИИ-модели создать игровой веб-сайт и написать роман. Использование отечественных ИИ-ускорителей для обучения модели LongCat-2.0 подчёркивает растущую важность самообеспечения на внутреннем рынке Китая. Meituan, как и другие крупные представители ИИ-сегмента, такие как DeepSeek, Alibaba и ByteDance, работают над снижением зависимости от американских ИИ-ускорителей после введения экспортных ограничений со стороны США. Местные производители ИИ-ускорителей, такие как Huawei и Enflame, стремятся заполнить этот пробел, получая долю рынка через контракты на поставку оборудования ИИ-разработчикам. Что касается модели LongCat-2.0, то в заявлении Meituan сказано, что нейросеть обучалась с нуля с использованием 50 тыс. отечественных ускорителей. Размер контекстного окна составляет 1 млн токенов, что позволяет нейросети осуществлять обработку объёмных документов. Модель ориентирована на агентное программирование, а её архитектура построена таким образом, чтобы эффективно и качественно справляться с решением задач, связанных с генерацией кода. В компании отметили, что предварительная версия LongCat-2.0 вошла в число трёх наиболее используемых моделей на платформе OpenRouter. По данным Meituan, новая ИИ-модель показывает равные возможности или превосходит некоторые из передовых моделей западных компаний, включая Google Gemini, OpenAI GPT-5.5 и Anthropic Claude Opus, в некоторых бенчмарках в плане генерации программного кода и агентных возможностей. OpenAI запустила инициативу Patch the Planet, чтобы помочь разработчикам открытого ПО в поиске ошибок
23.06.2026 [10:46],
Владимир Мироненко
OpenAI объявила о запуске инициативы Patch the Planet по исправлению ошибок в программном обеспечении с открытым исходным кодом в партнёрстве с компаниями в сфере кибербезопасности Trail of Bits, HackerOne и Calif. Цель состоит в том, чтобы оказать индивидуальную поддержку как можно большему количеству проектов с открытым исходным кодом для повышения их безопасности и долгосрочной устойчивости. 
Источник изображения: Mika Baumeister/unsplash.com «Patch the Planet — это масштабная интернет-инициатива, призванная помочь программному обеспечению с открытым исходным кодом опередить инструменты поиска ошибок, созданные искусственным интеллектом, — заявил гендиректор и соучредитель Trail of Bits Дэн Гуидо (Dan Guido). — Но это также попытка помочь сообществу разработчиков программного обеспечения с открытым исходным кодом увидеть преимущества, а не только недостатки инструментов для поиска ошибок, созданных ИИ». По словам руководителя отдела кибербезопасности OpenAI Фуада Матина (Fouad Matin), проект Patch the Planet нацелен на максимальную эффективность с точки зрения использования токенов, чтобы снизить нагрузку на сопровождающих open source-проекты, включая оценку кодовой базы, проверку потенциальных отчётов, создание патчей и их внедрение. «Мы хотим компенсировать затраты, будь то токены или рабочая сила, чтобы фактически исправить как можно больше ошибок в программном обеспечении», — добавил он. Также компания субсидирует использование сканера безопасности Codex Security, который находится в стадии предварительного тестирования с начала этого года, как для открытого, так и для частного кода «на сумму в 20 трлн токенов». Сообщается, что в Patch the Planet уже участвуют более 30 проектов с открытым исходным кодом, и ещё больше находятся в стадии подключения. По словам OpenAI и Trail of Bits, уже за первую неделю проект выявил сотни ошибок и позволил выпустить десятки патчей. Объявление OpenAI об инициативе поступило после того, как ее конкурент Anthropic закрыл доступ к передовым моделям Fable 5 и Mythos 5 из-за опасений администрации Трампа по поводу возможности их использования злоумышленниками в ущерб интересам национальной безопасности. OpenAI также представила в понедельник улучшенную версию ИИ-модели GPT-5.5-Cyber для поиска уязвимостей в ПО, которая набирает 85,6 % в бенчмарке CyberGym, что является улучшением по сравнению с предыдущей версией GPT-5.5-Cyber. Для сравнения, Mythos 5 от Anthropic набрала в этом бенчмарке 83,8 %. Google представила очень быструю открытую ИИ-модель DiffusionGemma, которая принципиально отличается от других
11.06.2026 [16:12],
Павел Котов
Google выпустила экспериментальную модель искусственного интеллекта DiffusionGemma, в которой при генерации текста используется принципиально иной подход по сравнению с моделями, на которых работает большинство современных чат-ботов. 
Источник изображений: blog.google Вместо того, чтобы генерировать слово за словом в строгой последовательности, она создаёт за один раз целый блок текста и продолжает его дорабатывать, пока он не станет читаемым. Основное преимущество DiffusionGemma в том, что приоритетом для неё является скорость, даже за счёт некоторой потери качества конечного результата. Модель опубликована с открытым исходным кодом под лицензией Apache 2.0 и ориентирована на разработчиков и исследователей, а не обычных пользователей. Ответ на запрос пользователей она начинает с набора случайных токенов — шумного, нечитаемого текста, который за несколько проходов превращается в осмысленный. Это позволяет существенно увеличить скорость по сравнению с традиционными вариантами: на ускорителе Nvidia H100 генерируются по 1000 токенов в секунду, а на потребительской видеокарте — по 700 токенов в секунду. 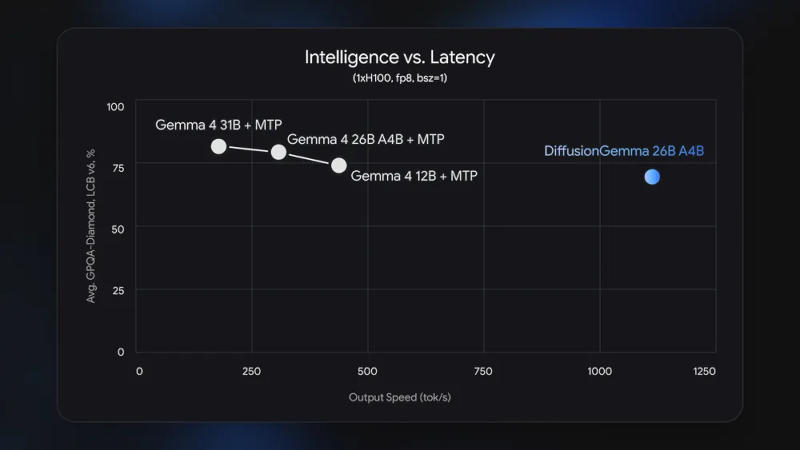 Google DiffusionGemma имеет архитектуру «смеси экспертов» (Mixture-of-Experts), то есть при размере 26 млрд параметров одновременно активными остаются лишь 3,8 млрд; для работы модели требуются около 18 Гбайт видеопамяти. За один шаг она генерирует 256 токенов, и все они взаимодействуют внутри блока. Это даёт модели глобальное представление о результатах, а не строго линейное. Она хорошо подходит для задач на структурирование или выполнение правил: её можно использовать для заполнения недостающих фрагментов кода, работы с форматами вроде JSON, решения сложных логических задач и обработки математических закономерностей. Видя блок токенов сразу, она может исправлять противоречия в одном цикле генерации, а не ждать, когда ошибку исправит более поздний токен.  Но есть у неё существенный минус. Ответы Google DiffusionGemma по качеству уступают ответам Gemma 4 – пользователь получает скорость в ущерб точности. Поэтому Google позиционирует проект как экспериментальный — он разработан для сценариев, при которых скорость ответа важнее совершенства. Например, для работы приложений ИИ в реальном времени, для встроенных помощников по написанию текста или кода и других быстрых итеративных рабочих процессов. Заменой моделей семейств Gemma и Gemini она быть не может. Mozilla анонсировала Thunderbolt — открытая платформа для запуска ИИ на локальных системах
17.04.2026 [12:48],
Владимир Фетисов
Mozilla анонсировала новый продукт, который во многом ориентирован на корпоративный сегмент. Речь об ИИ-клиенте с открытым исходным кодом Thunderbolt, который позволяет взаимодействовать с разными нейросетями и предназначен для развёртывания на собственной инфраструктуре компаний без необходимости использовать облачные сервисы сторонних поставщиков. 
Источник изображения: Mozilla Thunderbolt построен на основе Haystack — агентного фреймворка с открытым исходным кодом, который позволяет сформировать инфраструктурный слой из выбранных компонентов. В Mozilla называют свою разработку «суверенным ИИ-клиентом», размещённым поверх инфраструктурного слоя. Разработчики реализовали поддержку конвейеров Haystack, а также возможность интеграции с MCP-серверами и агентами через Agent Client Protocol. Thunderbolt может использоваться для взаимодействия с коммерческими ИИ-моделями, а также алгоритмами с открытым исходным кодом. Поддерживается автоматизация повседневных задач, включая формирование отчётов и запуск определённых действий по расписанию. Система может быть интегрирована с хранящимися локально корпоративными данными через открытые протоколы и использовать локальную базу данных SQLite в качестве источника актуальной информации. В сочетании с локально запущенной ИИ-моделью это может важным моментом для компаний, обеспокоенных тем, что конфиденциальные данные могут попасть в руки сторонних поставщиков услуг. В сообщении Mozilla сказано, что Thunderbolt опционально предлагает поддержку сквозного шифрования и обеспечение контроля доступа на уровне устройств для обеспечения безопасности. Клиент Thunderbolt поддерживает многие из уже знакомых интерфейсов и сценариев использования ИИ-систем, включая взаимодействие в чате, проведение исследований, поиск информации, автоматизацию процессов и др. Доступны версии приложения для Windows, macOS, Linux, iOS, Android, а также веб-версия. Не чипами едиными: Nvidia запустит открытую платформу NemoClaw для создания ИИ-агентов
10.03.2026 [15:03],
Павел Котов
Nvidia намеревается выпустить платформу NemoClaw, предназначенную для создания агентов с искусственным интеллектом. Проект с открытым исходным кодом будет предлагаться разработчикам корпоративного ПО. Доступ к платформе откроют даже для тех, кто не пользуется оборудованием Nvidia, пишет Wired со ссылкой на собственные источники. 
Источник изображения: BoliviaInteligente / unsplash.com На следующей неделе Nvidia проведёт ежегодную конференцию для разработчиков — в преддверии мероприятия компания обратилась к Salesforce, Cisco, Google, Adobe и CrowdStrike с предложением о партнёрстве в рамках платформы для создания ИИ-агентов. Чем закончились переговоры по данному вопросу, установить не удалось. Платформа будет предлагаться с открытым исходным кодом, и потенциальным партнёрам Nvidia могла предложить доступ к разработке в обмен на вклад в проект. Продукт также будет включать средства для обеспечения безопасности и конфиденциальности. Интерес Nvidia к технологиям ИИ-агентов возник из-за того, что даже простые пользователи стали всё чаще пользоваться подобными инструментами — наиболее известным из них является OpenClaw, способный запускать ИИ-агентов прямо на персональных компьютерах, где эти приложения решают рабочие задачи для пользователей. Разработчик OpenClaw перешёл на работу OpenAI. Ведущие разработчики ИИ, в том числе OpenAI и Anthropic, в последние годы значительно повысили надёжность своих моделей, но в работе чат-ботов по-прежнему требуется постоянный контроль. Некоторые сбои могут возникать и в работе ИИ-агентов. Для Nvidia проект NemoClaw может стать новым средством привлечь корпоративных клиентов и повысить безопасность ИИ-агентов. Это также очередной шаг в стремлении перевести клиентов на работу с открытыми моделями ИИ, которые помогают поддержать её доминирующее положение в инфраструктуре центров обработки данных. Ранее стало известно, что компания готовит ИИ-ускорители специально для инференса — запуска обученных моделей ИИ. В основу этих ускорителей лягут технологии поглощённой Nvidia компании Groq. Alibaba представила малые ИИ-модели Qwen3.5, которые работают на ноутбуке и обходят аналоги OpenAI
03.03.2026 [17:28],
Павел Котов
Специализирующееся на технологиях искусственного интеллекта подразделение Alibaba Qwen представило новую линейку моделей — их отличают небольшие размеры и высокая производительность при качестве ответов, значительно превосходящем ведущие американские аналоги. 
Источник изображений: Alibaba Младшие в новой линейке модели Alibaba Qwen3.5-0.8B и 2B характеризуются как «миниатюрная» и «быстрая»; они предназначаются для разработки прототипов и быстрого развёртывания на мобильных устройствах с минимальной производительностью, когда время автономной работы имеет первостепенное значение. Мультимодальная Qwen3.5-4B предназначена для создания легковесных агентов и изначально поддерживает контекстное окно в 262 144 токена. Рассуждающая Qwen3.5-9B превосходит по возможностям американского конкурента — открытую OpenAI gpt-oss-120B, которая крупнее по размеру в 13,5 раза; модель от Alibaba демонстрирует знание языков и логическое мышление на уровне аспирантуры. Веса моделей доступны для всех желающих под лицензией Apache 2.0, которая допускает корпоративное и коммерческое использование, в том числе дополнительное обучение по мере необходимости. При разработке малых моделей серии Qwen3.5 компания отошла от стандартных архитектур Transformer — здесь использована гибридная архитектура, сочетающая нейросети Gated Delta Networks и разреженную смесь экспертов (Mixture-of-Experts — MoE). Гибридный подход помогает решить проблему «ограничения памяти», характерную для небольших моделей; Gated Delta Networks, в свою очередь, обеспечивает повышенную пропускную способность и уменьшенную задержку при ответе. Модели изначально мультимодальные. В отличие от предыдущих поколений, когда генераторы изображений «прикреплялись» к текстовым моделям, Qwen3.5 обучались на мультимодальных токенах. В результате версии 4B и 9B умеют распознавать элементы пользовательского интерфейса и подсчитывают объекты на видео. В визуальном тесте MMMU-Pro модель Qwen3.5-9B набрала 70,1 балла, обогнав Google Gemini 2.5 Flash-Lite (59,7) и даже специализированную Qwen3-VL-30B-A3B (63,0). В тесте на логическое мышление она получила 81,7 балла, превзойдя результат OpenAI gpt-oss-120b (80,1), у которой более чем вдесятеро больше параметров. В математическом бенчмарке HMMT Feb 2025 модель Qwen3.5-9B показала 83,2 балла, а вариант 4B — 74,0, доказав, что для решения сложных задач в области точных наук больше не нужны значительные облачные ресурсы. Старшая модель стала лидером в тесте OmniDocBench v1.5 с результатом 87,7 балла; в многоязычном MMMLU она набрала 81,2 балла, обойдя gpt-oss-120b, у которой 78,2 балла. 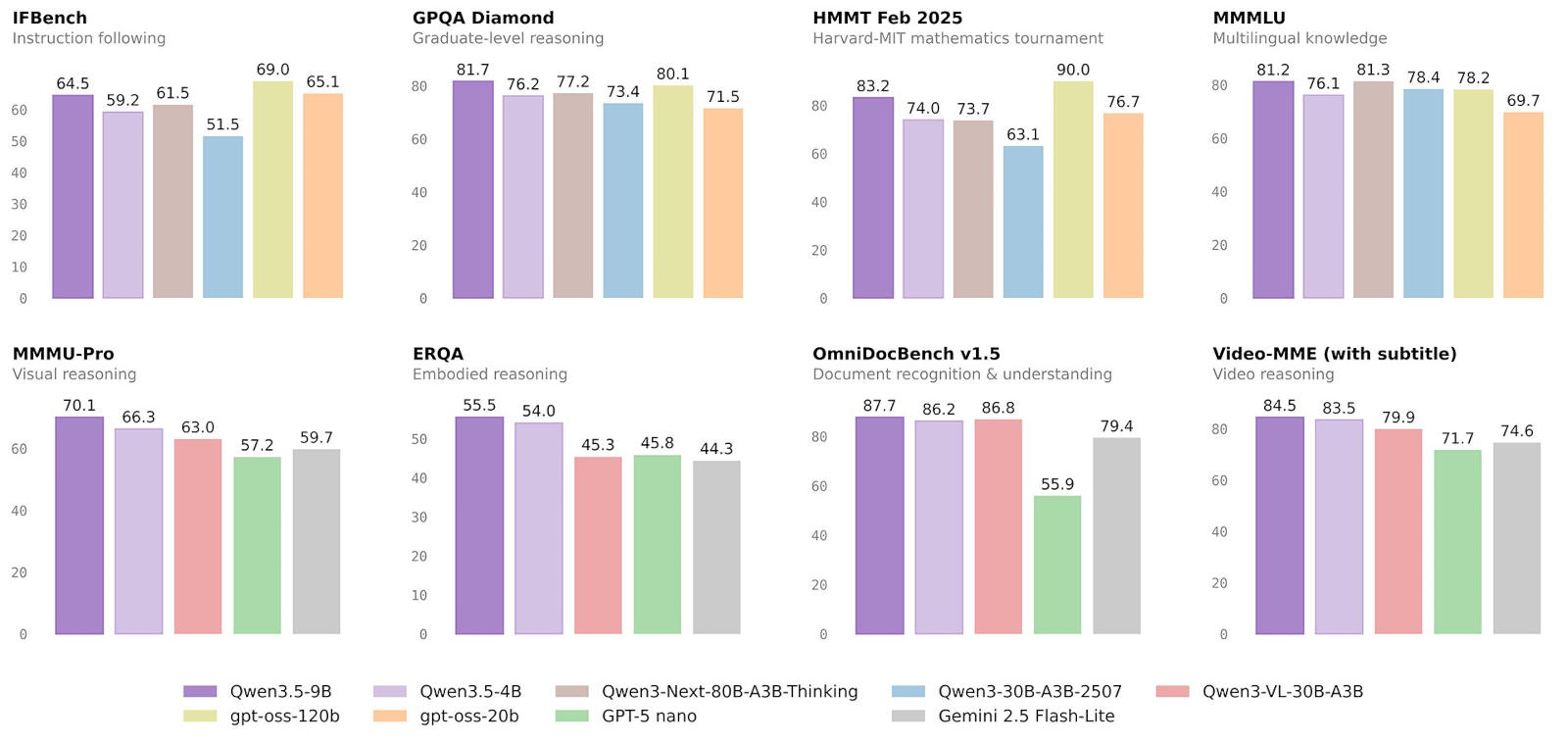 Выпуск моделей Qwen3.5 малой серии совпал с этапом расцвета ИИ-агентов. Простых чат-ботов современному пользователю уже недостаточно — растёт спрос на функции автономности. Автономный ИИ-агент должен «думать» (рассуждать), «видеть» (быть мультимодальным) и «действовать» (уметь пользоваться инструментами). Выполнять эти функции с моделями размером в триллионы параметров, очень дорого, а эксплуатация Qwen3.5-9B обходится значительно дешевле. Масштабировав технологию обучения с подкреплением в средах с миллионами агентов, Alibaba наделила эти модели функциями «человеческого суждения» — они могут организовать рабочий стол или провести обратное проектирование игры в код по видеозаписи. Запущенная на смартфоне версия на 0,8 млрд параметров или на рабочей станции модель на 9 млрд параметров делают «эпоху агентов» демократичной. Организации могут запускать ИИ-агентов на собственных локальных ресурсах, не расходуя средства на подключение к облачным ресурсам и не используя средства API. Используя механизм «привязки на уровне пикселей», эти модели способны перемещаться по пользовательским интерфейсам ПК и мобильных устройств, заполнять формы и сортировать файлы, выполняя инструкции на простом языке. С продемонстрированной в тестах точностью 90 % они производят оптическое распознавание текста, анализируют макеты и извлекают структурированные данные из форм и диаграмм в документах. Можно загружать целые репозитории кода (до 400 000 строк) в контекстное окно размером до 1 млн токенов для рефакторинга или автоматизированной отладки. Предназначенные для мобильных устройств модели Qwen3.5-0.8B и 2B могут в локальном режиме составлять сводки по видео при длине до 60 секунд и частоте до 8 кадров в секунду; а также демонстрировать пространственное мышление. Указываются и аспекты, на которые следует обращать внимание при развёртывании малых моделей Qwen3.5. В многоэтапных агентных сценариях одна ошибка на раннем этапе выполнения задачи может привести к каскаду сбоев, при котором агент будет следовать неверному или бессмысленному плану. Модели хорошо справляются с написанием кода с нуля, но могут испытывать затруднения с отладкой или доработкой сложных устаревших проектов. Для производительной работы модели Qwen3.5-9B требуется значительный объём видеопамяти. При развёртывании моделей на предприятиях следует отдавать приоритет «проверяемым» задачам: написанию кода, математическим вычислениям или следованию инструкциям — всему тому, где результаты можно проверить на соответствие определённым нормам, чтобы избежать скрытых сбоев. Alibaba представила открытую LLM Qwen 3.5 с поддержкой ИИ-агентов и 201 языка — местами она быстрее Gemini 3 Pro
17.02.2026 [12:30],
Павел Котов
Китайский технологический гигант Alibaba представил модель искусственного интеллекта Qwen 3.5. Она доступна в открытом варианте, который позволяет всем желающим загружать, запускать, изменять и развёртывать её на собственной инфраструктуре; а также в хостинговой версии, предназначенной для работы на собственных серверах Alibaba. 
Источник изображения: qwen.ai Alibaba Qwen 3.5 предлагает улучшения в производительности, стоимости обслуживания, и располагает «нативными мультимодальными возможностями», то есть одинаково хорошо работает с текстом, изображениями и видео. В соответствии с одной из ведущих тенденций отрасли ИИ модель умеет писать компьютерный код и располагает совместимостью с открытыми ИИ-агентами, включая популярный OpenClaw. ИИ-агентами называют приложения, способные самостоятельно выполнять действия и многоэтапные задачи от имени пользователя при минимальном его участии.  Открытая Alibaba Qwen 3.5 имеет 397 млрд параметров — переменных, определяющих, как обучается и рассуждает модель. Это меньше, чем у предыдущего флагмана, но, как утверждает разработчик, новая модель показала значительное улучшение в различных тестах. В работе она сопоставима с ведущими моделями OpenAI, Anthropic и Google — в отдельных тестах китайский ИИ даже превосходит западных конкурентов. Доступная через облачную платформу Model Studio версия Qwen-3.5-Plus также выступает на уровне ведущих конкурирующих продуктов, утверждает Alibaba. Она поддерживает 201 язык и диалект — у предыдущего поколения их было 82. В дни празднования китайского Нового года Alibaba выпустит ещё несколько открытых моделей ИИ, пообещал в соцсетях технический руководитель направления Qwen в Alibaba Cloud Линь Цзюньян (Lin Junyang). Xiaomi создала «интеллект» для роботов: ИИ-модель с 4,7 млрд параметров объединяет зрение, язык и действия
12.02.2026 [12:02],
Павел Котов
Китайская Xiaomi, известная в первую очередь как производитель мобильных устройств, оборудования умного дома, а теперь и электромобилей, заявила о себе в новом качестве. Она решила занять место в исследованиях в области робототехники. 
Источник изображений: xiaomi-robotics-0.github.io Компания представила Xiaomi-Robotics-0 — модель искусственного интеллекта с открытым исходным кодом, сочетающую в себе визуальный, языковой компоненты и компонент действия; у неё 4,7 млрд параметров. В модели объединяются распознавание визуальных образов, понимание языка и способность производить действия в реальном времени, что, как отметили в Xiaomi, составляет ядро «физического интеллекта». Она уже установила несколько рекордов как в симуляциях, так и в реальных испытаниях. ИИ-модели для роботов обычно действуют в замкнутом цикле: восприятие, принятие решения и выполнение операции. Робот видит объекты окружающего мира, понимает, что от него требуется, составляет план действий и реализует его — Xiaomi-Robotics-0 создавалась, чтобы сбалансировать широкое понимание с точным управлением моторикой. Для этого здесь использована архитектура «смеси трансформеров» (Mixture-of-Transformers — MoT), которая помогает распределять обязанности между двумя основными компонентами. Первый компонент — визуально-языковая модель (VLM), выполняющая функцию «мозга». Она обучена интерпретировать отдаваемые человеком команды, в том числе расплывчатые, такие как «пожалуйста, сложи полотенце», а также понимать пространственные отношения на основе визуальных сигналов высокого разрешения. Задачи этой части — обнаружение объектов, ответы на вопросы в визуальной области и логические рассуждения. Второй компонент в Xiaomi называют экспертом по действиям (Action Expert). Эта часть модели имеет архитектуру диффузионного трансформера (Diffusion Transformer — DiT). Она не предполагает выполнения одного действия за раз, а генерирует последовательность действий, используя методы сопоставления потоков, что обеспечивает точность и плавность движения.  Слабой стороной VLM является то, что при обучении выполнению физических операций они, как правило, теряют часть заложенных ранее способностей к пониманию. Инженерам Xiaomi удалось избежать этой проблемы, обучая модель одновременно на мультимодальных данных и данных о действиях. В теории это означает, что такая система может одновременно рассуждать об объектах окружающего мира и учиться в нём передвигаться. Процесс обучения включает несколько этапов. Сначала механизм «предложения действий» заставляет VLM предсказывать возможные распределения действий при интерпретации изображений — это помогает согласовывать внутреннее представление модели о том, что она видит, с тем, как выполняются операции. После этого работа компонента VLM приостанавливается, и DiT проходит отдельное обучение для генерации точных последовательностей из шума на основе ключевых признаков, а не дискретных языковых токенов. Xiaomi удалось решить проблему задержки вывода — паузы между выдаваемыми моделью прогнозами и физическим движением робота. Для этого реализовали асинхронный вывод, разделив вычисления модели и действия робота: движения остаются непрерывными, даже если модели требуется дополнительное время на обдумывание. Для повышения стабильности используется техника Clean Action Prefix, предполагающая возврат в модель предсказанного ранее действия, что обеспечивает плавное движение без рывков во времени. Маска внимания направляет модель на актуальный визуальный ряд, понижая приоритет прошлых состояний, в результате чего робот оказывается отзывчивым к внезапным изменениям окружающей среды. В симуляциях LIBERO, CALVIN и SimplerEnv модель Xiaomi-Robotics-0 превзошла около 30 других, сообщил разработчик. В реальных экспериментах она проверялась на роботе с двумя манипуляторами: в задачах с последовательностями действий, таких как складывание полотенец и разборка блоков конструктора, робот демонстрировал стабильную координацию рук и глаз, одинаково эффективно манипулируя как жёсткими, так и мягкими объектами. Модели действительно удалось сохранить сильные визуальные и языковые возможности, особенно в задачах, связанных с физическим взаимодействием. Alibaba выпустила открытую ИИ-модель RynnBrain для роботов
10.02.2026 [16:55],
Павел Котов
Alibaba представила модель искусственного интеллекта, предназначенную для работы в роботизированных системах — она позволяет им выполнять задачи в реальном мире. Китайский технологический гигант стремится установить лидерство в нескольких областях отрасли ИИ. 
Источник изображения: alibaba-damo-academy.github.io Входящая в китайскую компанию академия DAMO представила основополагающую модель с открытым исходным кодом — она обеспечивает взаимодействие роботов с окружающей средой. Модель понимает отношения пространства со временем и может определять шаги для выполнения задач. Проект получил название RynnBrain; в его описании указано, что модель умеет составлять карты объектов, прогнозировать траектории, ориентироваться в тесных пространствах, например, на кухне или сборочной линии на заводе. С новой моделью Alibaba бросает вызов таким технологическим гигантам как Google и Nvidia. У первой есть модель Gemini Robotics-ER 1.5, у второй — Nvidia Cosmos-Reason2. RynnBrain обучена на большой языковой модели Qwen3-VL и доступна бесплатно на платформах Face и GitHub в нескольких версиях — от базовой с 2 млрд параметров до передовой в конфигурации MoE (Mixture-of-Experts). Она создана для работы в области, где за первенство сражаются Китай и США. Робототехника выступает одним из приоритетов для Пекина, а ключевым направлением считаются человекоподобные роботы, в которых видят потенциал по доминированию в области физического ИИ и преобразованию секторов от производства до гостиничного бизнеса. Китайские компании выпускают преимущественно модели ИИ с открытым кодом, тогда как американские игроки предпочитают удерживать передовые технологии за закрытыми дверями. Стратегия открытого исходного кода по направлению физического ИИ до настоящего момента преимущественно ограничивалась проектами академических учреждений. Распространение вайб-кодинга подорвало экосистему Open Source и это может привести к катастрофе
09.02.2026 [01:29],
Анжелла Марина
Исследователи из Центрально-Европейского университета в Вене пришли к выводу, что практика написания кода с помощью ИИ-моделей подрывает экономическую модель открытого программного обеспечения (Open Source). Явление, получившее название «вайб-кодинг» (Vibe coding), позволяет даже малоопытным разработчикам быстро создавать приложения, не вникая в детали сгенерированного кода и не взаимодействуя с сообществом проекта. 
Источник изображения: Chris Ried/Unsplash Проблема заключается в том, что пользователи нейросетей выступают исключительно потребителями ресурсов и перестают вносить свой вклад в развитие бесплатных библиотек, баз данных и инструментов, которые создавались десятилетиями. Авторы исследования установили, что вайб-кодеры почти никогда не участвуют в жизни проектов, от которых по сути сами и зависят. При этом падение вовлечённости напрямую влияет на доходы разработчиков, так как они монетизируют свои проекты через рекламу в документации или продажу коммерческих расширений. Но ИИ-агенты не читают документацию и не переходят по рекламным ссылкам, отмечает издание 404 Media. Наглядное подтверждение гипотезы пришло от создателя фреймворка Tailwind CSS Адама Ватана (Adam Wathan), который сообщил о сокращении трёх из четырёх инженеров в проекте. Несмотря на рост популярности инструмента, трафик заходов на страницы официальной документации упал на 40 % с начала 2023 года, а значит, сократился приток клиентов на коммерческие продукты. Профессор экономики Миклош Корен (Miklós Koren), один из авторов исследования, отметил, что ситуация уже становится нормой. Эксперты предупреждают о рисках долгосрочного коллапса всей инфраструктуры разработки. Открытое ПО требует постоянного обслуживания, исправления ошибок и устранения уязвимостей безопасности, которыми занимаются люди. Если поток финансирования и волонтёрской помощи иссякнет, качество базовых библиотек упадёт, что повлечёт за собой деградацию и самих инструментов ИИ-генерации кода. При этом наибольшему риску подвержены небольшие нишевые проекты, которые часто становятся основой для глобальных инноваций. Корен подчеркнул, что коллапс «опенсорса» рано или поздно уничтожит и сам вайб-кодинг, поскольку ИИ-модели обучаются на открытых репозиториях и требуют их постоянного обновления. Исследователи убеждены, что такие крупные компании, как Anthropic и OpenAI больше не должны бесплатно эксплуатировать чужой труд. В качестве решения учёные предлагают внедрить модель разделения доходов, основанную на реальных данных об использовании открытого кода при обучении и работе нейросетей. Европа разогнала отказ от американских цифровых сервисов и ПО
04.02.2026 [15:08],
Владимир Мироненко
По всей Европе правительства и учреждения стремятся сократить использование цифровых сервисов американских технологических компаний, переходя на отечественные или бесплатные альтернативы в связи с опасениями по поводу чрезмерной зависимости от неевропейских технологий и стремлением к суверенитету, пишет AP. 
Источник изображения: Juanjo Jaramillo/unsplash.com Также существуют опасения, что под давлением администрации Дональда Трампа (Donald Trump) гиганты Кремниевой долины могут быть вынуждены ограничить доступ к своим сервисам. Они усилились после того, как в связи с санкциями администрации Трампа Microsoft заблокировала электронную почту прокурора Международного уголовного суда (МУС) Карима Хана (Karim Khan). Microsoft утверждает, что поддерживала связь с МУС «на протяжении всего процесса, который привёл к отключению ее представителя, находящегося под санкциями, от услуг Microsoft. Компания ни в коем случае не прекращала и не приостанавливала предоставление услуг МУС». Тем не менее, это не развеяло опасения по поводу «аварийного выключателя», который крупные технологические компании могут использовать для отключения услуг по своему усмотрению. В ходе недавнего Всемирного экономического форума в Давосе (Швейцария) представитель Европейской комиссии по вопросам технологического суверенитета Хенна Вирккунен (Henna Virkkunen) заявила, что зависимость Европы от других может быть использована против ЕС. «Именно поэтому так важно, чтобы мы не зависели от одной страны или одной компании, когда речь идёт о важнейших областях нашей экономики или общества», — сказала она, не называя конкретных стран и организаций. В прошлом году федеральная земля Шлезвиг-Гольштейн (Германия) перевела 44 тыс. почтовых ящиков сотрудников с Microsoft на почтовую программу с открытым исходным кодом. Она также перешла с системы обмена файлами SharePoint от Microsoft на Nextcloud, платформу с открытым исходным кодом. Кроме того, обсуждается возможность замены Windows на Linux, а телефонов и видеоконференцсвязи — на системы с открытым исходным кодом. «Мы хотим стать независимыми от крупных технологических компаний и обеспечить цифровой суверенитет», — заявил министр цифровизации Дирк Шрёдтер (Dirk Schrödter). Французский город Лион заявил в прошлом году о переходе на бесплатное офисное программное обеспечение с софта Microsoft. Правительство Дании и города Копенгаген и Орхус также тестируют программное обеспечение с открытым исходным кодом. В Австрии военные перешли на программный пакет LibreOffice, аналог Word, Excel и PowerPoint из Microsoft 365. Они выразили обеспокоенность тем, что Microsoft переносит хранение файлов в облако — стандартная версия LibreOffice не является облачной. Некоторые итальянские города и регионы внедрили упомянутое программное обеспечение несколько лет назад, сообщил представитель Document Foundation. По его словам, тогда это было связано с отсутствием необходимости платить за лицензии на программное обеспечение. Теперь главная причина заключается в том, чтобы избежать привязки к проприетарной системе. Хакеры взломали популярный текстовый редактор Notepad++ и полгода распространяли вирусы с обновлениями
03.02.2026 [11:15],
Павел Котов
Киберпреступники взломали сервер, на котором размещается сайт популярного открытого текстового редактора Notepad++, и в течение второй половины 2025 года распространяли среди пользователей программы вредоносные обновления. 
Источник изображения: notepad-plus-plus.org Злоумышленники, связанные, по версии разработчиков Notepad++, с китайскими властями, сохраняли доступ к ресурсам проекта с июня по декабрь 2025 года, и это «может объяснить избирательный подход к атаке жертв». Эксперты по кибербезопасности из компании Rapid7, приписали взлом группировке Lotus Blossom; жертвами оказались организации правительственного, телекоммуникационного и авиационного секторов, объекты критической инфраструктуры и сектор медиа. Notepad++ — старый и востребованный проект с открытым исходным кодом; количество загрузок программы исчисляется десятками миллионов, среди её пользователей значатся частные лица и организации по всему миру. В результате кибератаки хакеры взломали некоторое количество организаций «с интересами в Восточной Азии»; достаточно было неосознанного запуска одного заражённого экземпляра программы, заявил впервые обнаруживший инцидент эксперт в области кибербезопасности Кевин Бомон (Kevin Beaumont). У хакеров оказался «прямой» доступ к компьютерам жертв, которые пользовались взломанными версиями Notepad++. «Точный технический механизм» взлома серверов проекта остаётся неизвестным, сообщили разработчики, — расследование инцидента продолжается. Сайт Notepad++ находился на сервере с другими проектами; злоумышленники «целенаправленно атаковали» связанный с программой домен, эксплуатировали уязвимости серверного ПО и направляли некоторых пользователей на собственный сервер. Благодаря этому хакерам удалось распространять вредоносные версии Notepad++. Уязвимость закрыли в ноябре, а хакеров лишили доступа к серверу лишь в начале декабря. Они попытались восстановить доступ, но уязвимость была уже закрыта, и попытка не увенчалась успехом. Хостинг-провайдер подтвердил факт взлома сервера, но не уточнил, как именно хакеры проникли в систему. Разработчики принесли извинения за инцидент и призвали пользователей загрузить свежую версию Notepad++, в которой закрыли последние уязвимости. План «Б» для стареющего Linux: у сообщества появился план на случай ухода Линуса Торвальдса
28.01.2026 [18:19],
Сергей Сурабекянц
Создатель ядра Linux Линус Торвальдс (Linus Torvalds) был ведущим координатором проекта с момента его создания в 1991 году. За прошедшие годы сообщество разработчиков Linux, по словам самого Торвальдса, постарело, как и он сам. Тем не менее, формальный план замены Торвальдса в случае его отхода от дел появился всего несколько дней назад. 
Источник изображения: Procreator / unsplash.com Разработанный план довольно прост и активируется только в случае отсутствия плавной передачи полномочий в нужный момент. В случае необходимости сообщество разработчиков ядра привлечёт «Организатора», которым может стать последний организатор Maintainer Summit («Саммита мейнтейнеров»), либо нынешний председатель Технического консультативного совета (Technical Advisory Board, TAB) Linux Foundation. У «Организатора» будет 72 часа, чтобы начать обсуждения с приглашёнными участниками последнего Maintainer Summit. Если с момента последнего саммита прошло более 15 месяцев, то решение о составе участников принимает TAB по своему усмотрению. Затем собранный коллектив должен через две недели сообщить о принятом решении сообществу через список рассылки. В крайнем случае, даже без этого официального плана, сообщество разработчиков ядра, вероятно, достаточно легко достигнет соглашения. В конце концов, как сам Торвальдс отмечал ранее, в мире существует не так много проектов с открытым исходным кодом, «которые мейнтейнеры поддерживают буквально более трёх десятилетий». Несмотря на некоторую обеспокоенность по поводу количества мейнтейнеров в начале десятилетия, сейчас Торвальдс уверен в достаточной компетентности кадрового резерва. По его словам, «это не происходит мгновенно, но приходят новые люди, и через три года они уже становятся основными разработчиками». Конечно, Линус Торвальдс пока не выразил желания перестать быть руководителем разработки ядра Linux, но появление формального плана действий на этот случай и умение сообщества Linux самоорганизовываться позволяют надеяться, что ситуация останется под контролем. |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



