







 MWC 2018
MWC 2018 2018
2018 Computex
Computex
⇣ Содержание
|
Опрос
|
реклама
Самое интересное в новостях
Не генеративным ИИ единым
Алгоритм можно определить как раз и навсегда заданный (в частности, программным кодом) конкретный способ решения довольно строго определённой прикладной задачи. Неимоверная популярность искусственного интеллекта в наши дни обусловлена в немалой степени как раз тем, что тот способен решать весьма нечётко очерченные проблемы — вроде «идентифицируй в толпе, которую снимает камера наружного наблюдения с не самой совершенной оптикой, человека по сделанному в студии портретному фото», «нарисуй забавного котика» или «поясни, что не так с этим фрагментом кода на Python». Вместе с тем сами принципы построения ИИ-систем как раз подчиняются весьма чётко прописанным закономерностям, известным как способы (иногда также называемые алгоритмами) машинного обучения (МО). В наши дни у всех на слуху генеративный искусственный интеллект — способ организации МО, реализованный в таких популярных моделях и сервисах, как ChatGPT, Midjourney, Kling и т. п. Почему же так вышло, что все прочие алгоритмы машинного обучения оказались с точки зрения широкой публики в тени генеративного — и изменится ли эта ситуация в ближайшем будущем? 
Даже лучшие на сегодня генеративные модели не всегда уверенно справляются с задачами различения. Подсказка для этой картинки: «Prince Crocodile meets Pauper Alligator» (источник: ИИ-генерация на основе модели Flux) ⇡#МО? ИИ?Строго говоря, машинное обучение можно рассматривать как подраздел искусственного интеллекта в широком смысле — включающего, к примеру, и такую далёкую пока что от практической реализации сферу, как «сильный» ИИ, способный самостоятельно формулировать для себя задачи и отыскивать пути их решения. Подход же МО не предполагает со стороны вычислительной системы какой бы то ни было аналитики, не говоря уже об осознанности (что бы под той ни подразумевалось в приложении к компьютерной эмуляции нейросети) производимых над данными действий. Машинное обучение — не более чем автоматизированное извлечение закономерностей из большого массива данных по определённым правилам. Сами же эти правила, в свою очередь, определяются целями, которые ставили перед собой разработчики данной конкретной модели МО, подготавливая для её обучения тренировочный массив данных. Одно из наиболее общепринятых делений задач, решаемых средствами МО, — дихотомическое, т. е. строго на две группы: либо для классификации (различения по неким признакам) обрабатываемых объектов/сущностей, либо для порождения (генерации — в частности, визуальной) цифровых образов таких объектов по определённым подсказкам. Соответственно, первую обширную категорию моделей называют дискриминативными (разделяющими), вторую — генеративными (созидающими). Впрочем, если бы дело этим и ограничивалось, особого повода углубляться в вопрос дальше бы и не было. Интуитивно понятно, что, скажем, модель, сортирующая по разным папкам фото крокодилов и аллигаторов, — дискриминативная; та же, что способна создать по лапидарной подсказке явственно различимые специалистом-зоологом фотореалистичные изображения крокодила и аллигатора, — напротив, генеративная. Цели и задачи систем двух этих типов самоочевидным образом разнятся: дискриминативные модели применяют к полученным откуда-то извне данным для их классификации; генеративные — наоборот, для порождения новой информации (тех же картинок, видеороликов, аудио) по заданному шаблону. 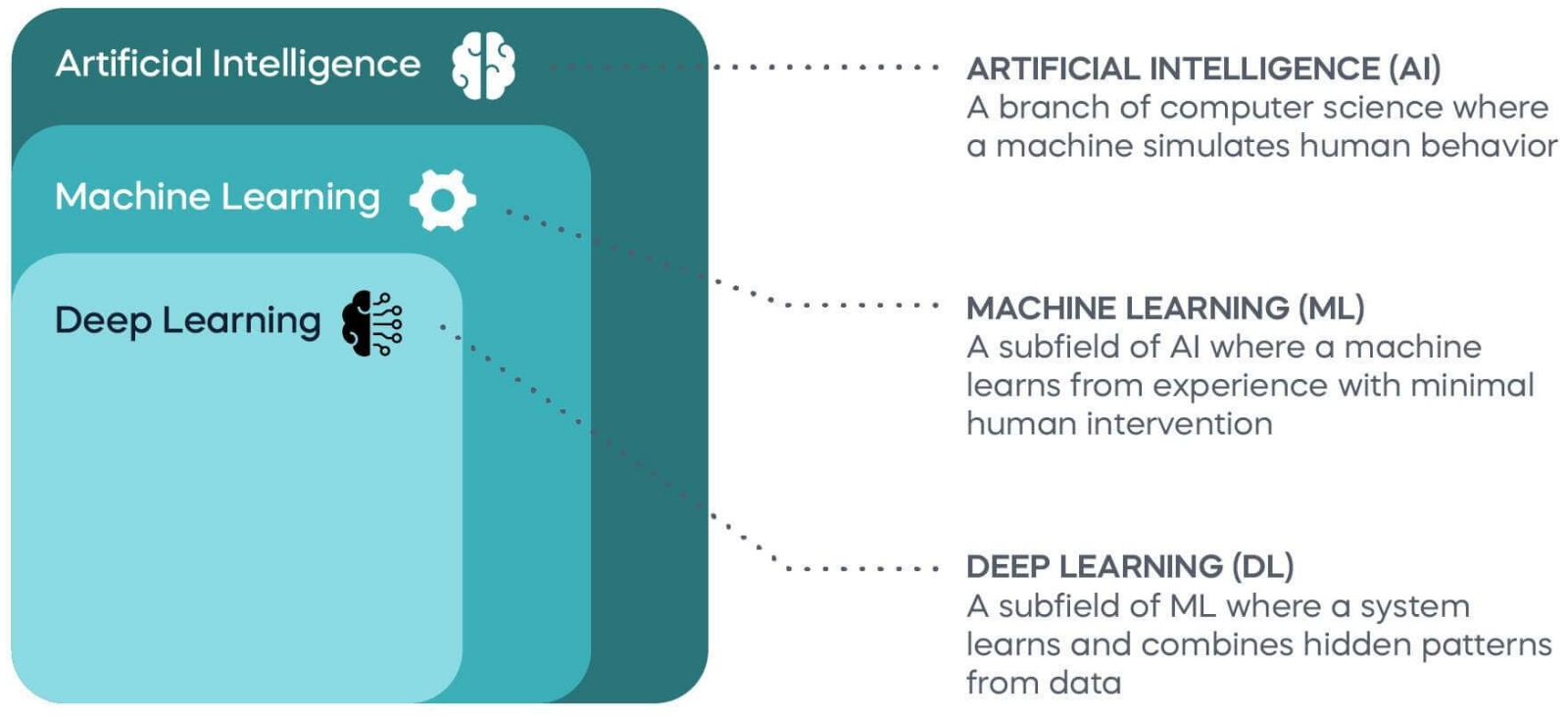
Взаимное соотнесение областей глубокого, машинного обучения и искусственного интеллекта (источник: 365 Data Science) В любом случае МО подразумевает изначальное обучение, сводящееся к перелопачиванию компьютерной системой — цифровой эмуляцией более или менее сложной нейросетевой структуры — массива данных с тем, чтобы выявить в том определённые закономерности. Выявить, что важно, имплицитным образом, т. е. без явного их выражения, поддающегося стройному и логичному (алгоритмическому) описанию. Интересно, что и в живом мозге имплицитное научение, как было подтверждено нейробиологами на практике, основано на отличных от эксплицитного (логического) мышления процессах — и протекает независимо от него. Грубо говоря, иностранному языку можно обучать эксплицитно, предлагая для заучивания слова с их переводом и разъясняя тонкости чужого синтаксиса, — а можно имплицитно, методом «полного погружения» в инородную речевую среду. Тот и другой способы приведут в итоге, по мере накопления обучаемым достаточного объёма данных, к практическому результату; качество же и скорость освоения чужого языка в каждом случае будут определяться индивидуальными особенностями данного конкретного мозга. Поскольку в нынешнем своём состоянии ИИ к эксплицитным рассуждениям в любом случае не способен, сила его генеративных моделей (точнее, конечно, было бы говорить о генеративном машинном обучении, но термин GenAI уже устоялся) — как раз в имплицитном характере реализации ими всех тех замечательных способностей, которыми так искренне восхищается широкая общественность вот уже почти два года. А именно: к созданию статичных и движущихся картинок, к сочинению музыки, к поддержанию содержательной (с точки зрения человека, то бишь информационно и эмоционально насыщенной) беседы на естественном языке и т. п. Отметим, что до недавнего времени сравнительно живым разработчикам всё равно приходилось прилагать немалые усилия для разметки (сопровождения исчерпывающим текстовым описанием) исходных массивов данных — тех, к примеру, изображений, на которых модель обучалась преобразовывать слова-подсказки в визуальные образы. Однако сегодня уже по сути состоялся переход от классического «обучения с учителем» (supervised learning), когда человеку необходимо было собственноручно индексировать скармливаемые модели массивы тренировочных данных, к самообучению (self-supervised learning) — использующему имплицитную генерацию меток для неструктурированных данных. Именно благодаря самообучению наиболее продвинутые генеративные модели, начиная с GPT 3.5 (ставшей основой для нашумевшего осенью 2022-го ChatGPT), распахнули перед человечеством недоступные прежде горизонты — что, собственно, и подтверждается немалым ажиотажем, не утихшим до сих пор. 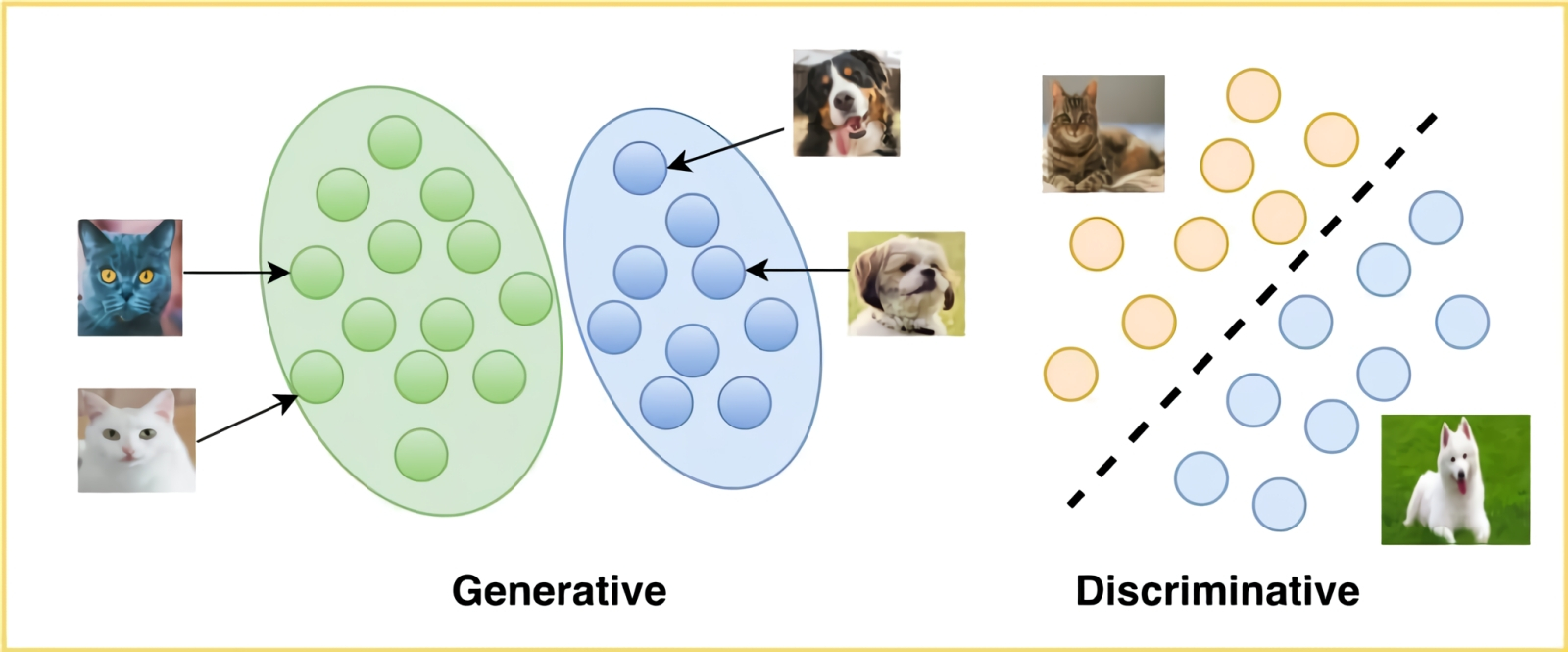
Наглядная разница между генеративными и дискриминативными моделями МО (источник: Big Vision LLC) Собственно, неохватная величина ресурсов (условных человеко-часов), которые требовалось затрачивать на разметку тренировочных массивов данных вручную, и сдерживала долгое время развитие генеративных моделей. С тренировкой дискриминативных, применяемых для классификации разнородных сущностей (кошка — собака, мотоцикл — автомобиль и т. п.), всё несколько проще: здесь ведущему обучение оператору достаточно отмечать сделанный системой МО выбор как корректный или некорректный, способствуя тем самым через обратную связь перекалибровке весов на входах модельных перцептронов. Генеративный же ИИ способен сам создавать — точнее, порождать, отталкиваясь от имплицитно «ухваченных» образов, — достаточно сложные сущности. Синтетический голос, например, по тембру почти (пока — почти) неотличимый от принадлежащего тому или иному человеку. Или визуальный образ того же самого человека, статичный либо движущийся. Или текст, написанный в заданной манере и на заданную тему. Понятное дело, выдача моделей GenAI не обходится без галлюцинаций — такова уж природа имплицитного «знания». Но выгоды от использования систем МО, построенных на самообучении, настолько значительны, что сознательное принятие вероятности их галлюцинирования во многих случаях представляется вполне разумной платой. ⇡#Сама, сама, самаО том, как реализуется на практике обучение с учителем (supervised learning) для дискриминативной модели, мы рассказывали уже в одном из прежних материалов на тему искусственного интеллекта. На вход системы — грубо говоря, многослойного перцептрона — подаётся массив предварительно размеченных данных: условно, карточки с написанными от руки цифрами, каждую из которых сопровождает та же самая цифра в машиночитаемом виде. Система пропускает разбитый на пиксели рукописный образ через свои перцептроны и в соответствии с имеющимися на их входах изначально весами выдаёт некий результат: «догадку» о том, что за цифру ему предъявили. Результат затем (в данном случае автоматически, хотя исходно карточки размечал вручную оператор, — это важно) сопоставляется с машиночитаемым значением данной цифры с той же самой карточки, и если система сработала некорректно, то через процесс обратного распространения ошибки (backpropagation) веса на входах определённых перцептронов несколько подправляются, после чего процедура повторяется вновь. И так — до тех пор, пока конкретная реализация модели МО не научится с приемлемой точностью идентифицировать все рукописные цифры их обучающего массива. После чего можно подавать ей на вход написанные уже другой рукой и с иным начертанием цифры — и с довольно большой вероятностью она их также станет распознавать корректно. 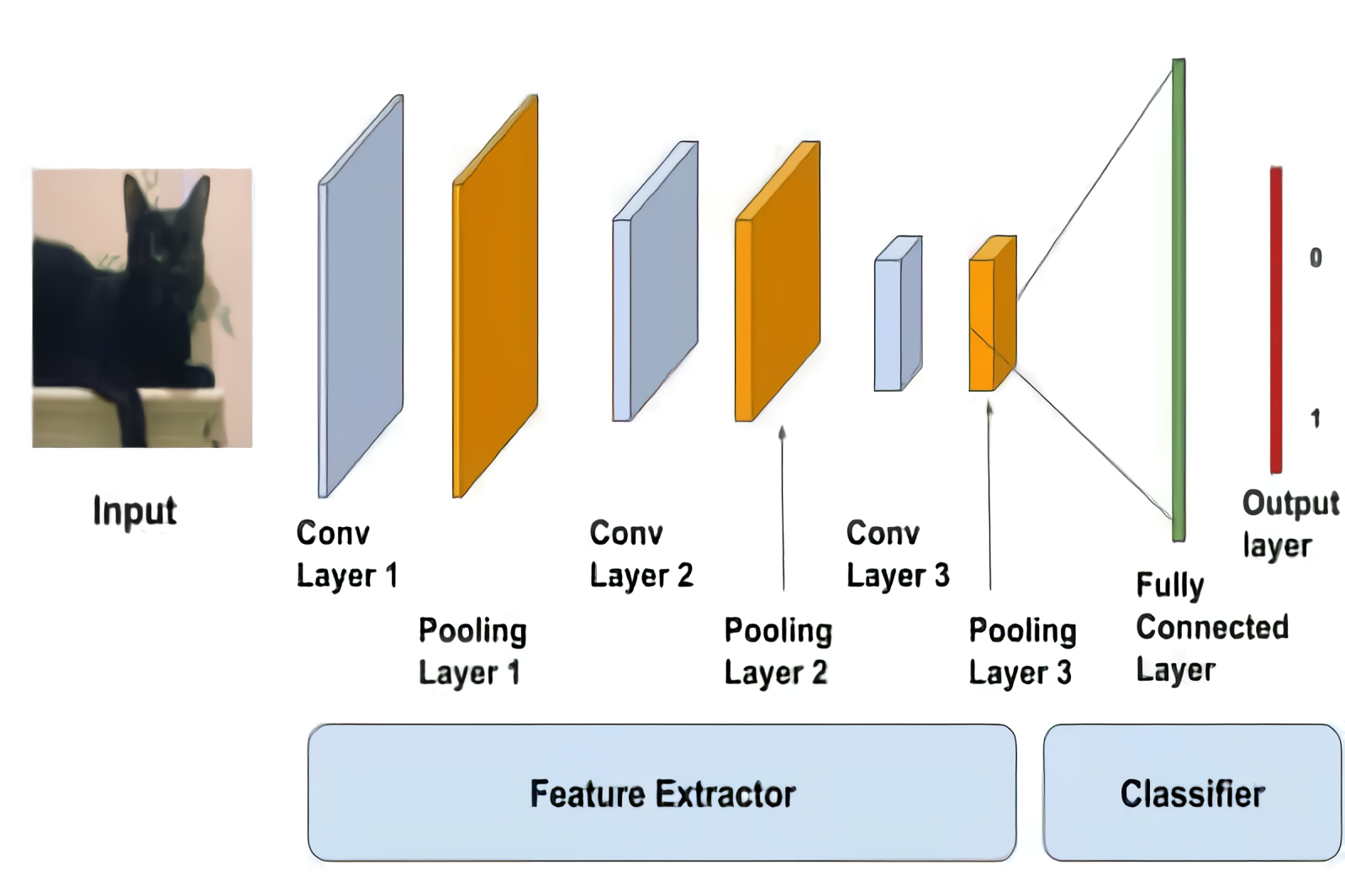
Архитектура глубокой нейросети предусматривает блоки как определителя характерных особенностей, так и классификатора — два в одном (источник: Big Vision LLC) Эта несложная по описанию процедура на деле чревата немалым числом проблем — таких, в частности, как недоадаптация и переадаптация (underfitting и overfitting соответственно). В нашем примере почерк формировавшего обучающий массив человека может оказаться столь вычурным, что, обучившись великолепно отождествлять написанные им цифры, система будет испытывать немалые затруднения с распознаванием иных примеров. Но в целом дискриминативное обучение с учителем — это надёжная классика МО: к примеру, давным-давно применяемые антиспам-фильтры для электронной почты строятся на основе именно таких моделей, проходящих к тому же — в идеале — непрерывное дообучение всякий раз, когда очередной пользователь нажимает в интерфейсе своего почтового клиента на значок «Это спам». Помимо отнесения предъявленной сущности к чётко определённым категориям («крокодил — аллигатор», «тройка — семёрка — туз»), что обычно и характеризуется как классификация (classification), обученная с учителем дискриминативная модель может выдавать и величины из непрерывного ряда — скажем, оценивать плотность людского потока (чел./мин) на входе станции метрополитена в зависимости от времени суток, даты, погодных условий и т. п.; тогда речь идёт о решении задачи регрессии (regression). Для построения моделей МО, специализирующихся на классификации и регрессии, применяют соответствующие алгоритмы, и они находят самое широкое применение в самых разнообразных практических приложениях — в системах компьютерного зрения, например. Однако, как мы уже отмечали, у обучения с учителем есть существенный минус — оно требует либо непосредственного присутствия оператора рядом с тренируемой системой (с тем, чтобы сообщать ей, верно или нет она в каждом конкретном случае произвела классификацию/регрессию), либо предварительной разметки им же массива тренировочных данных. Можно ли обучать модель МО без учителя? Да, разумеется; и такая процедура — unsupervised learning — также реализуется целым кустом алгоритмов. Задачи обучения без учителя сводятся в две обширные группы: это кластеризация (clustering) и уменьшение размерности (dimensionality reduction). Кластеризация подразумевает отнесение объектов к неким классам — но, в отличие от классификации при обучении с учителем, ни число этих классов, ни специфика каждого из них не заданы изначально. МО с кластеризацией особенно востребовано в торговле и маркетинге, поскольку позволяет с неплохой точностью стратифицировать, к примеру, клиентов по типам их предпочтений и паттернам поведения, причём сделать это имплицитно — без немалых инвестиций в предварительное изучение рынка традиционными средствами. Уменьшение же размерности смыкается с классическими для компьютерной отрасли алгоритмическими задачами архивации, а также с известным из математики методом главных компонентов — здесь также сокращается объём принимаемых системой в расчёт входных данных без ущерба для результата их обработки. Важное приложение моделей МО, обученных без учителя по методу уменьшения размерности, — предобработка избыточно информативных массивов данных для ускорения работы других алгоритмов машинного обучения. 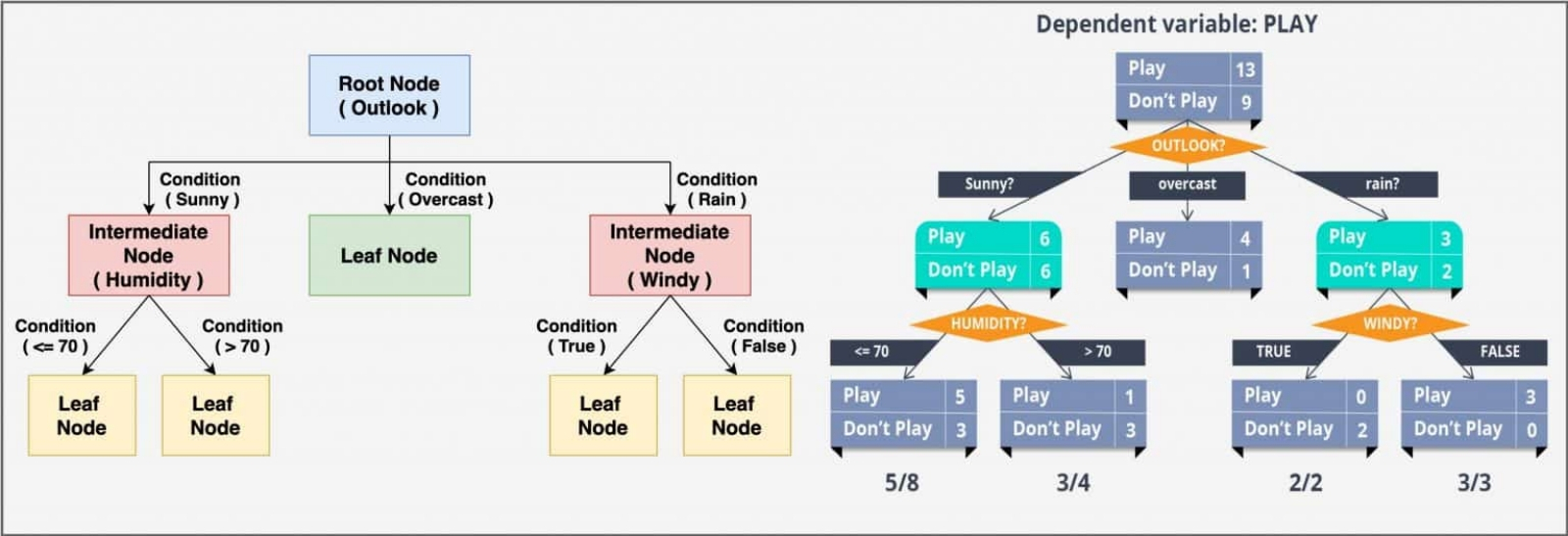
Древо решений — один из непараметрических алгоритмов обучения с учителем, применяемый для решения задач как классификации, так и регрессии (источник: Big Vision LLC) Вернёмся теперь к машинному самообучению (self-supervised learning, SSL), которое часто определяют как достаточно свежий, гибридный подход к МО — использующий обучение без учителя для работы над такими проблемами, что прежде решались исключительно через обучение с учителем. По сути, самообучение подразумевает формирование самой же системой МО размеченного набора данных (labeled dataset) для формирования подкрепляющих сигналов обратной связи (supervisory signals), на основе которых и происходит тренировка модели. Иными словами, анализируя массив неразмеченных данных, SSL-модель сама выявляет признаки (метки), по которым их можно упорядочить и которые затем использует для решения задач классификации/регрессии. Самый, наверное, доходчивый пример использования SSL для тренировки моделей МО, имеющих дело с текстом (не исключая и пресловутый ChatGPT), — это выборочное маскирование слов в предложениях. Исходный массив данных представлен просто текстами, взятыми в цифровом виде, — главное, чтобы созданы они были людьми, а не другими МО-системами (иначе вероятность галлюцинаций в выдаче тренируемой на таком массиве модели существенно возрастёт). Модель получает от самой же себя на входе предложения с выборочно пропущенными словами — и, пропуская их через многослойную перцептронную сеть, формирует «догадку» о том, какое слово должно стоять на месте пропуска. После чего сопоставляет исходный текст со сгенерированным — и, если совпадения нет, применяет стандартный метод обратного распространения ошибки для коррекции весов, после чего всё повторяется снова. Точно так же можно самообучать модель, к примеру, рисованию в стиле определённого художника — в этом случае выборочно затеняться будут фрагменты его оригинальных полотен, представленных в тренировочном массиве, — или же сочинению музыки избранного жанра (тут маскированию подвергаются отдельные такты и их последовательности). ⇡#Ну не разорваться жеСходство SSL с обучением без учителя очевидно — в обоих случаях для тренировки модели используют неразмеченные данные, так что поиск внутренних закономерностей и связей реализуется имплицитно, без привлечения заданных извне (и тем более верифицируемых оператором) классификаций. Но не менее явственны и различия: прежде всего, SSL обладает предсказательной силой, пусть и отягощённой возможностью галлюцинаций. Скажем, одно из широко распространённых применений обученных без учителя МО-моделей — это выдача рекомендаций клиентам онлайн-магазинов в духе «С этом товаром часто покупают…» — поскольку такая система способна быстро выявить в большом массиве данных о совершённых покупках значимые корреляции между парами разнородных на первый взгляд товарных позиций. Применение же SSL-модели даёт возможность интерактивного машинного взаимодействия с каждым конкретным клиентом: если по всей выборке вместе с товаром А значимо часто покупают товар Б, но именно данный пользователь и раз, и другой проигнорировал выданную ему системой подсказку, гораздо разумнее не продолжать ломиться в открытую дверь, раздражая вдобавок клиента назойливостью, а предложить в пару к А какую-нибудь иную товарную позицию, с более низким показателем корреляции, — возможно, этот вариант сработает? 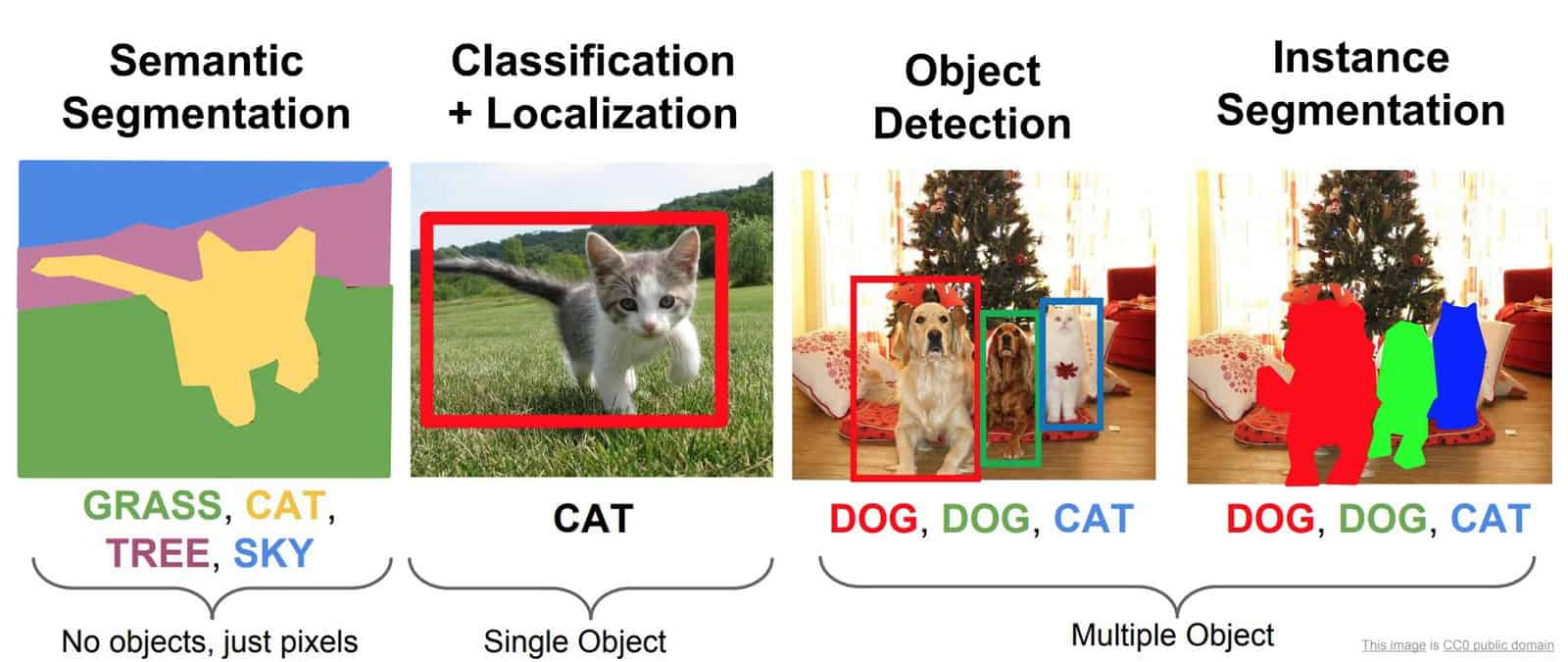
Четыре главные задачи, решаемые системами машинного зрения: семантическая сегментация, классификация с локализацией, выделение объектов и сегментация по образцам (источник: Wikimedia Commons) Таким образом, SSL схожи и с моделями, обученными с учителем, поскольку точно так же апеллируют к неким фундаментальным для тренировочной выборки данных закономерностям (англоязычный термин — ground truth), только не заданным живым оператором, а выбранным из входного неразмеченного массива данных имплицитно. Автооптимизация самообучаемой модели через обратное распространение ошибки производится в соответствии с теми же принципами градиентного спуска в многомерном пространстве, что и для моделей, обучающихся с учителем. Это делает возможным применение SSL для решения проблем классификации и регрессии — причём, поскольку поиск закономерностей в тренировочном массиве самообучаемая модель ведёт имплицитно, «ухваченные» ею категории могут либо вовсе не соответствовать тем, которыми оперировали бы размечающие тот же массив люди, либо заметно от них отличаться. В этом, собственно, одна из важнейших причин непостижимости «логики» SSL в целом и генеративного ИИ в частности: формально какие-то закономерности система в исходных данных нащупывает и в своих дальнейших действиях ими руководствуется, но вот средств как-то выразить их в доступной человеческому восприятию форме у неё нет. По крайней мере, в базовом варианте реализации SSL; прикручивание к ней «объясняющих модулей» — отдельное и чрезвычайно увлекательное направление развития МО. Пример задачи из области машинного зрения, для которой обучение с учителем выходит запредельно ресурсоёмким, — сегментация по образцам (instance segmentation), в ходе которой определяется, какие в точности пикселы изображения относятся к данному конкретному образцу объекта. Скажем, на кадре с видеокамеры высокого разрешения, где человек стоит на фоне автомобиля или другого человека, для многих прикладных приложений необходимо чётко определять не просто сами грубые контуры этих объектов (эта задача, object detection, как раз неплохо решается более простыми моделями), но то, какому из них принадлежит каждая конкретная точка в составе картинки. Можно представить себе объём трудозатрат на ручную попиксельную разметку даже одного кадра в Full HD, — а ведь для формирования у модели, обучаемой с учителем, достоверно эффективных закономерностей потребуется не одна сотня, если не сотня тысяч таких кадров. SSL же подобные задачи решают куда эффективнее — как раз из-за отсутствия необходимости в привлечении живых операторов. 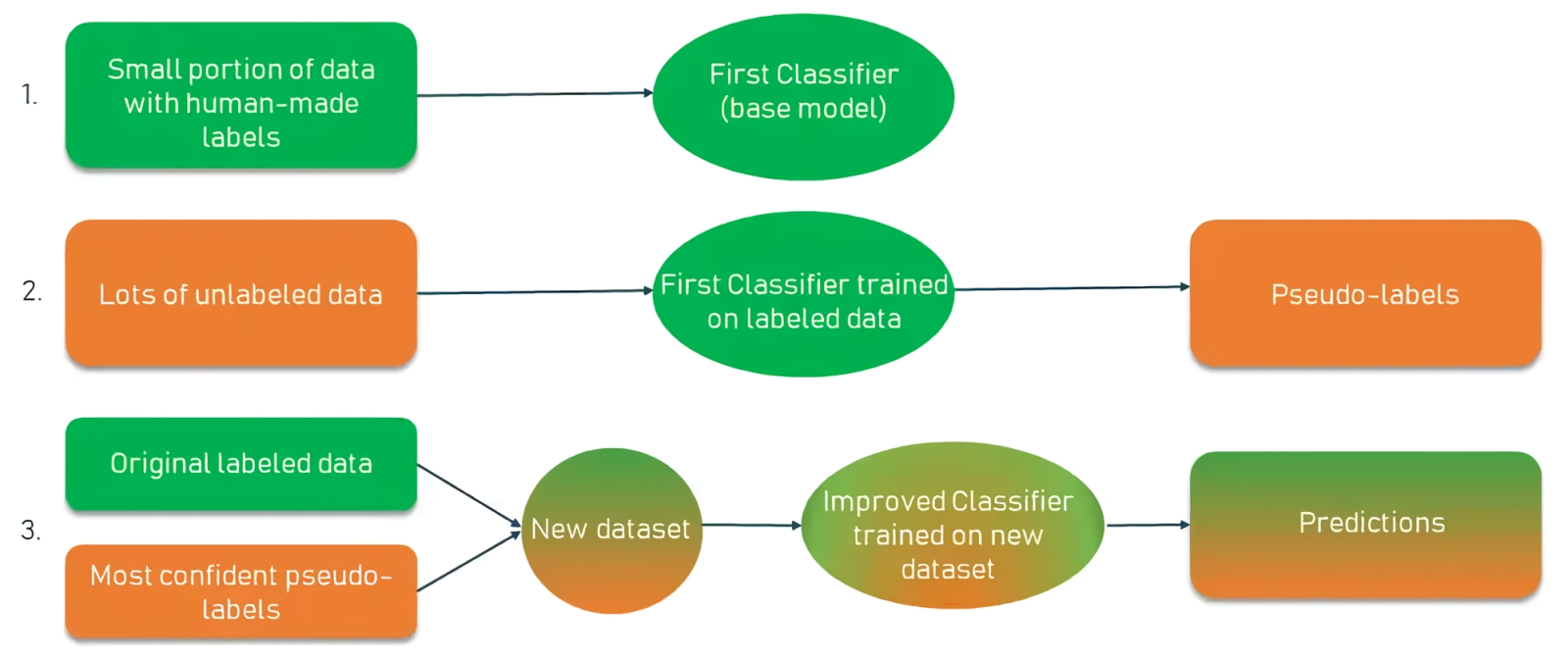
Методика самотренировки полусамообучаемой модели (источник: AltexSoft) Известны также полусамообучаемые (semi-supervised) модели, опирающиеся в ходе тренировки частью и на размеченные, и на не размеченные людьми данные. Их часто применяют там, где полагаться целиком и полностью на самообучение неразумно: например, в современных системах распознавания речи. Размеченный людьми массив — аудиозаписи, транскрибированные вручную, — для таких систем составляет десятки, максимум сотни часов; на его основе модель тренируется переводить голос в текст с понятными ограничениями — по словарному запасу, по манере произношения соответствующих дикторов и т. п. Затем к этому массиву добавляется другой, уже неаннотированный, более обширный — в сотни и даже тысячи часов, и обучение продолжается уже в самостоятельном режиме. В результате получается система, способная довольно уверенно транскрибировать речь самых разных людей на самые различные темы — и с приемлемо низким уровнем неизбежных, увы, ошибок. Естественным развитием SSL стало самопредсказуемое обучение (self-predictive learning, SPL), иначе называемое аутоассоциативным самообучением (autoassociative self-supervised learning). Это примерно то, о чём говорил когда-то основоположник палеонтологии и изобретатель сравнительно-анатомического метода Жорж Кювье (Georges Cuvier): «Дайте мне одну кость, и я восстановлю по ней животное». Метод SLP позволяет натренировать модель МО так, что по предложенным ей фрагментам некоего объекта она с достаточной степенью достоверности смоделирует недостающие его части — и, соответственно, весь объект целиком. SLP находит самое широкое применение в разнообразных генеративных моделях — в частности, тех, что используют для дорисовки изображений (outpainting) за пределы исходно занимаемого теми холста. Вариационные автокодировщики (variational autoencoders, VAE), которые ответственны за «трансляцию» изображения, сформированного в латентном пространстве современными генеративными моделями для преобразования текста в картинки, в постижимый человеком графический формат, также относятся к категории SLP. Равно как и авторегрессивные модели (autoregressive models), «предсказатели будущего на основе прошлого», — именно они лежат в основе таких широко известных сегодня больших языковых моделей, как GPT, LLaMa и Claude. 
Обе хороши! (Источник: ИИ-генерация на основе модели Flux) Словом, дискриминативные и генеративные модели МО идут сегодня рука об руку — и, строго говоря, в подавляющем большинстве наиболее значимые в наши дни реализации «генеративного ИИ» представляют собой как раз комбинированные, гибридные системы. Иногда в особый класс выделяют модели, реализующие обучение с подкреплением (reinforcement learning, RL), — их особенность в том, что оперируют они в процессе тренировки не с набором подготовленных заранее данных, размеченных либо нет, а непосредственно с некой средой. Формально здесь прослеживается полная аналогия с обучением с учителем, только в роли учителя выступает не человек, нажимающий на кнопки «корректно» или «некорректно», а сама среда, на которую агент (в данном случае — обучаемая с подкреплением МО-система) оказывает воздействие, получая в ответ обратную связь. Ну, скажем, именно RL-система лучше всего годится для создания искусственного геймера — который будет получать отрицательное подкрепление, если совершит неверное действие в игре и его аватар пострадает, и позитивное, если сделает всё как надо. Какое же из направлений МО наиболее предпочтительно для создания в будущем «настоящего» (в смысле — сильного) ИИ? Эксперты называют в числе наиболее многообещающих методов и RL, и SLP, но основной упор делают на объяснимые модели машинного обучения — такие, «образ мыслей» которых не будет оставаться загадкой для создающих, тренирующих и эксплуатирующих их биологических специалистов. Кроме того, придётся справиться с целым рядом вызовов — включая нехватку данных для обучения новых сверхкрупных языковых моделей, контаминацию этих самых данных «вторичными» (т. е. теми, что сгенерировали уже действующие генеративные ИИ), а также возможные архитектурные затруднения: неиллюзорен риск того, что виртуальная реализация «сильных» моделей МО в памяти фон неймановских компьютеров окажется делом избыточно затратным — и потребует оперативного перехода к нейроморфным аппаратным системам специализированных архитектур. Так или иначе, это направление развития высоких технологий явно продолжит оставаться приоритетным в обозримой перспективе — а значит, имеет смысл ожидать сравнительно скорых результатов и новых достижений в области машинного обучения. Материалы по теме
⇣ Содержание
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.
Материалы по теме
|
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.











