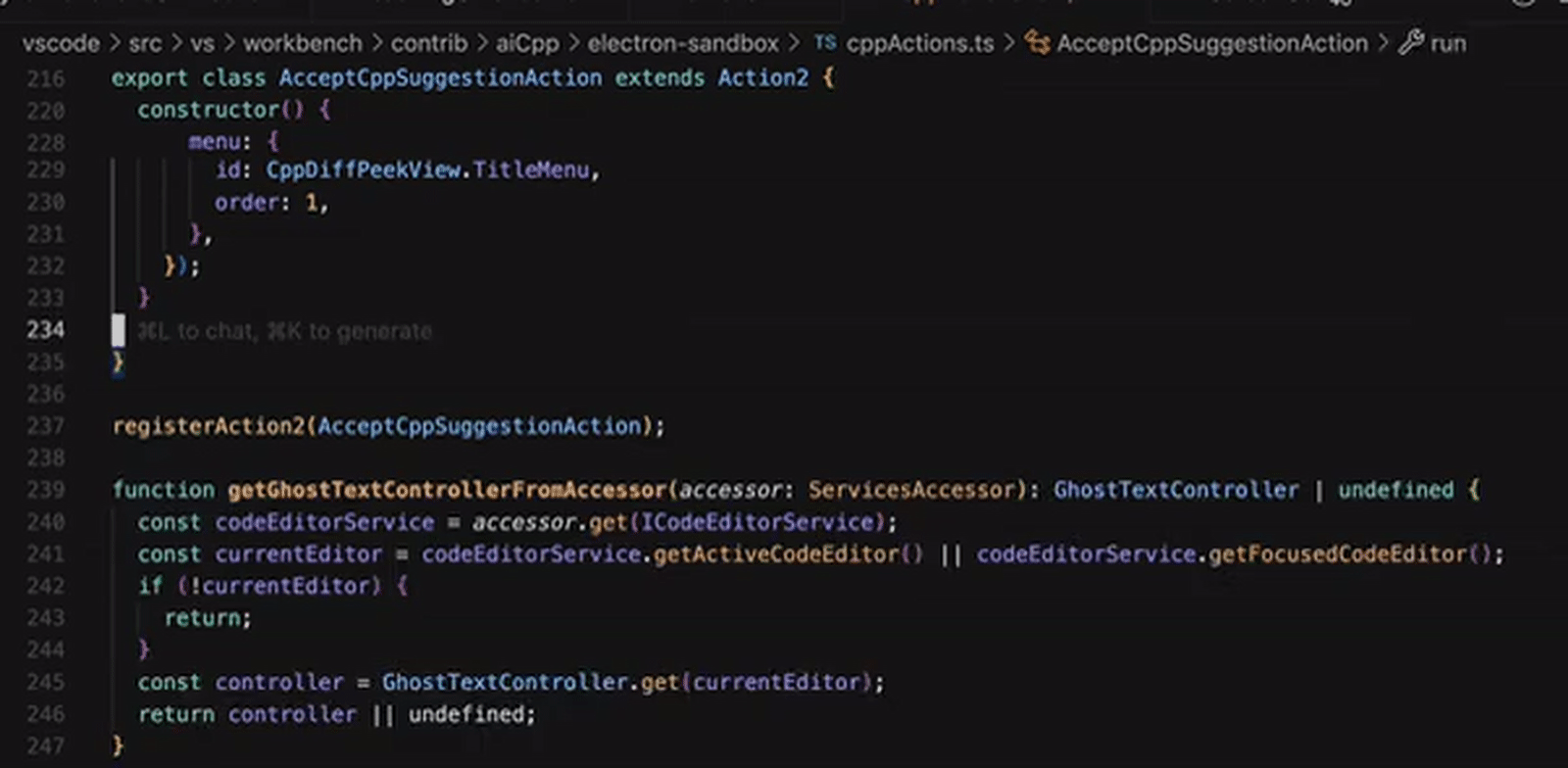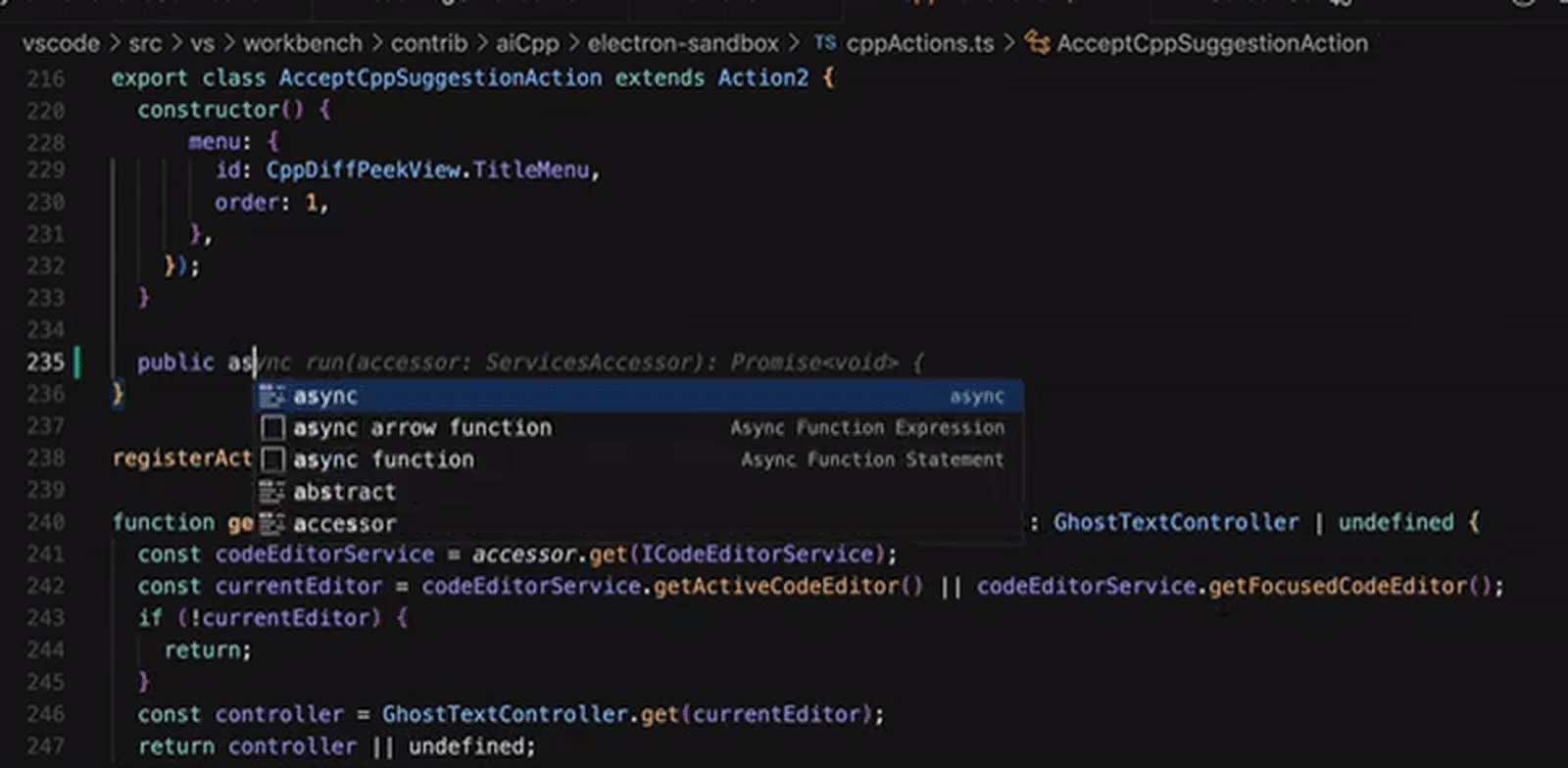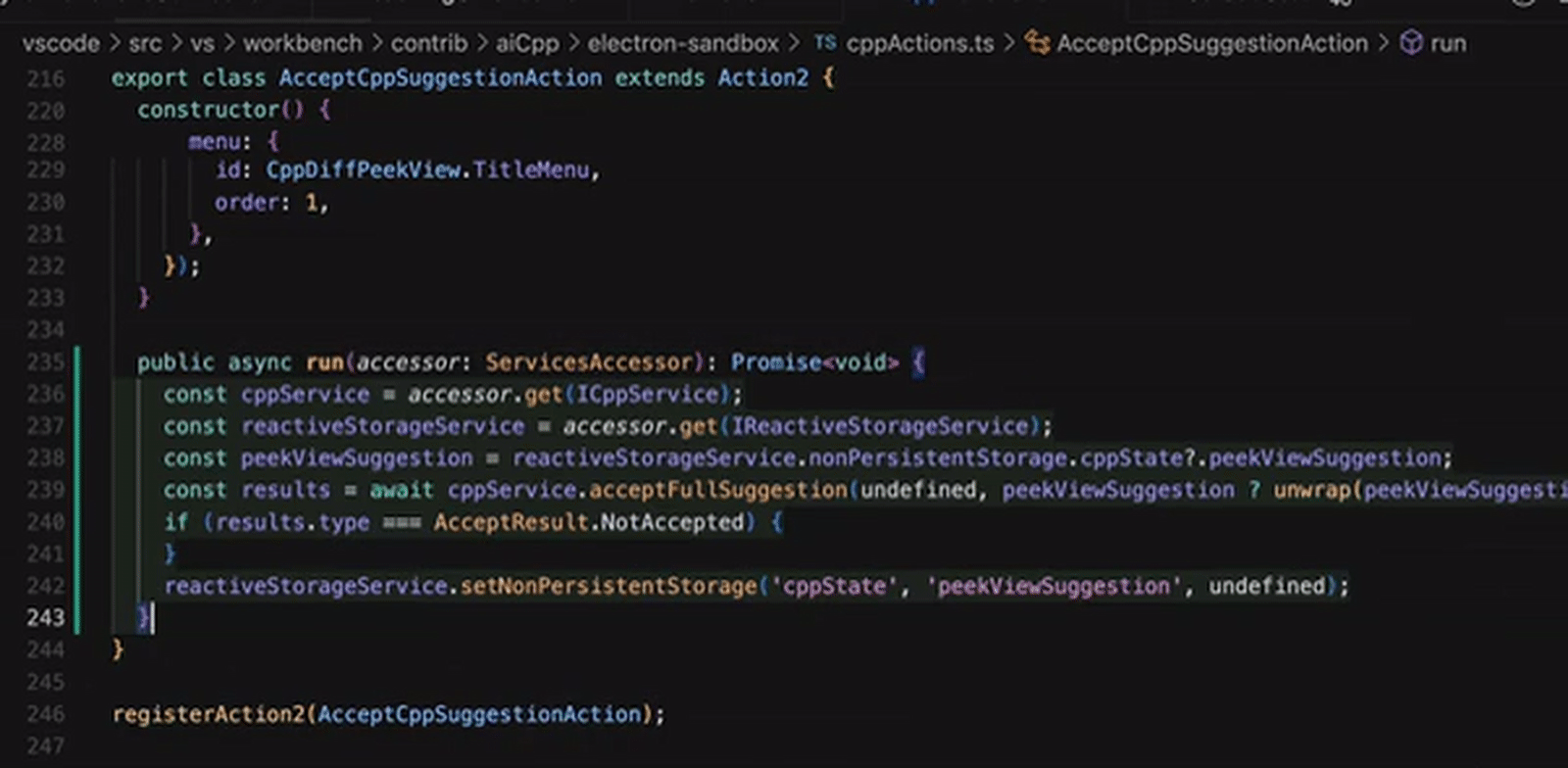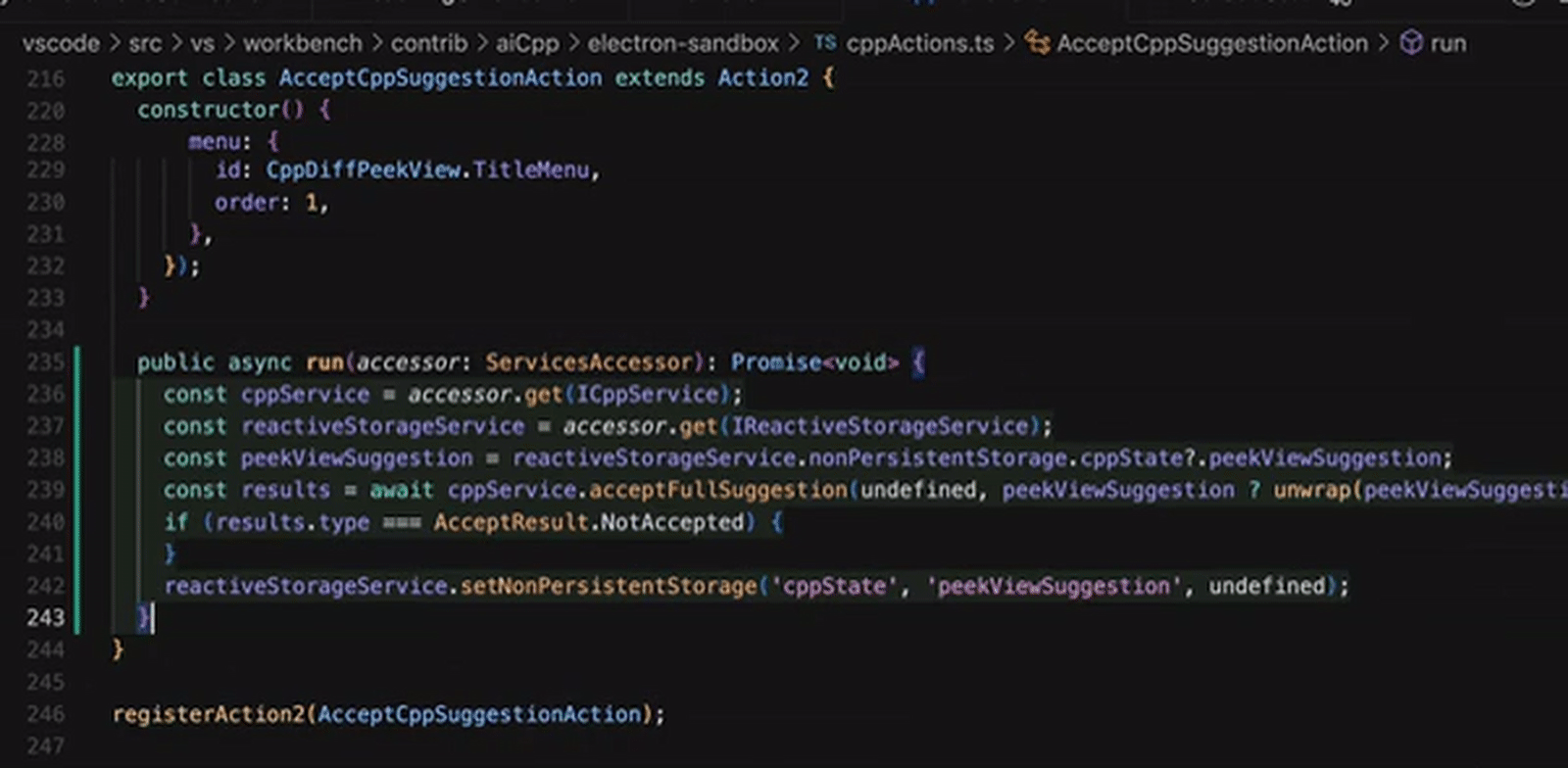
Пример работы с умным справочным блоком (Cursor Tab), в котором ИИ предлагает оператору различные варианты продолжения кода — цельными блоками — прямо по мере написания (источник: Cursor)
⇡#Нейросеть приносит пользу
Новостей о том, как те или иные ИИ галлюцинируют, дают небезопасные советы, применяются для создания дипфейков и иными способами отравляют жизнь почтеннейшей публике, — великое множество. Тем приятнее получать позитивные информационные сообщения о новых и/или заново освоенных областях применения генеративных моделей. Например, об интегрированном со средой разработки умном чат-боте — редакторе кода Cursor, что позволяет прямо в диалоговом окне, напоминающем интерфейс Microsoft Visual Studio Code, во взаимодействии с ИИ-системой (которая может быть представлена Claude 3.5 Sonnet, GPT-4o или иными доказавшими свою применимость в кодерском деле моделями), быстро и корректно создавать достаточно изощрённые программы. Как утверждают разработчики Cursor, количество пользователей этого платного инструмента уже превышает 30 тыс., причём среди них есть представители таких перспективных ИИ-проектов, как Perplexity, Midjourney и OpenAI. Кстати, схожие по духу разработки ведутся и в России: так, «Яндекс» именно в сентябре подала заявку на регистрацию товарного знака Yandex Code Assistant. Услуга генерации кода на базе ИИ будет, утверждает компания-разработчик, доступна «бесплатно в режиме тестирования» на платформе Yandex Cloud.
Конечно, программирование — достаточно формализованное направление человеческой деятельности; здесь за генеративными моделями бесспорное преимущество. А как насчёт творчества в более широком смысле? И тут, как выясняется, ИИ даже в нынешнем его состоянии очень даже неплох: по крайней мере, ему удалось превзойти живых учёных в деле генерации инновационных исследовательских идей: если не оставить их далеко позади, то по крайней мере выйти на добротный экспертный уровень по целому ряду критериев. Группа учёных организовала 79 специалистов в области обработки естественного языка (NLP) для того, чтобы вслепую сравнить две подборки по 49 профильных идей, одну из которых составили такие же живые эксперты, а вторую — умные боты вроде ChatGPT и Claude. В итоге статистически достоверно было продемонстрировано, что идеи, сгенерированные ИИ, оказались оценены людьми в целом выше по критериям новизны и увлекательности.

Источник: ИИ-генерация на основе модели FLUX.1
⇡#OpenAI: беспокойство о будущем
Компании, разрабатывающие ИИ-модели, не слишком часто отвлекаются на стороннюю по отношению к главной области своих интересов деятельность — прежде всего потому, что основное направление их работы требует изрядных инвестиций и привлечения множества ресурсов, так что на какую-то иную активность запала попросту не остаётся. Отнюдь не такова OpenAI, которая после прошлогоднего скандала со снятием с поста, а затем возвращением обратно своего главы Сэма Альтмана (Sam Altman) явно и весьма деятельно диверсифицируется. Возможно, как раз потому, что в последние месяцы у её флагманских моделей семейства GPT появляются всё новые конкуренты — более привлекательные для пользователей по цене и как минимум не уступающие по эффективности. Так, в начале сентября благодаря опубликованным в тайваньских ИТ-изданиях утечкам стало известно, что OpenAI уже зарезервировала за собой часть пока что отсутствующих «1,6-нм» мощностей (техпроцесс с условным названием A16) на предприятиях TSMC — с тем, чтобы в 2026 г. изготавливать на них ИИ-чипы по собственным дизайн-проектам (которые к тому времени как раз, уточняют источники, должны быть доведены до ума).
При этом, пока тайваньские чипмейкеры работают над освоением техпроцесса 16А, Сэм Альтман не сидит без дела — он, по информации Bloomberg, намеревается развернуть на территории США мощную инфраструктуру для обеспечения «адекватных темпов экспансии систем искусственного интеллекта» (чему именно адекватных, правда, не уточняется). Помимо собственно американских инвесторов, включая Microsoft, Apple, Nvidia и целый ряд фондов, глава OpenAI собирается привлекать к партнёрству организации из Канады, Южной Кореи, Японии и ОАЭ. Насколько эти намерения серьёзны, можно судить по обнародованным уже в конце месяца свидетельствам о настойчивых попытках Альтмана убедить уже уходящую администрацию США в необходимости покрыть всю территорию страны сетью крупных дата-центров потребляемой мощностью по 5 ГВт каждый — с целью, разумеется, обеспечить национальную безопасность государства, в основном как раз по направлению ИИ.
А ещё в структуре OpenAI появился такой необходимейший в наши дни орган, как независимое подразделение для приостановки выпуска опасных ИИ-моделей, — в него преобразовали ранее существовавший в компании «комитет по безопасности и защите». Подразделение наделено беспрецедентными полномочиями, включая право приостановки релизов ИИ-моделей по соображениям «безопасности» (что именно под ней подразумевается — вопрос особый, однако уже заявлено, что этические аспекты развития и применения генеративных моделей определённо станут объектами самого пристального внимания). Надо полагать, ситуация с внезапным обращением ChatGPT к некоторым пользователям первым, в отсутствие инициирующей диалог подсказки, оказалась одной из первых тем на повестке дня нового подразделения. Занятно, что сам Сэм Альтман в состав «стоп-команды» не входит, — хотя все члены той одновременно заседают и в совете директоров OpenAI.
ИИнструменты для обхода проверки, не бот ли вы? В ассортименте! (Источник: скриншот сайта ChatGPT.com)
⇡#Дипфейки — это были цветочки
Когда ИИ-система галлюцинирует, она по крайней мере делает это безо всякой задней мысли (тем более что мыслить в ни в философском, ни в нейрофизиологическом понимании этого термина она не способна) и без осознанного намерения причинить кому-либо вред — опять-таки по причине отсутствия у неё сознания. Зато у людей, готовых эксплуатировать ИИ-инструменты с целью отъёма денег у своих же собратьев по биологическому виду, с сознанием — и с осознанностью своих целей, для достижения которых подойдут и самые высокотехнологичные средства, — всё в полном порядке. Когда OpenAI примерно год назад открывала свой «магазин GPT» для размещения специализированных моделей, дотренированных сообществом энтузиастов, она предполагала, что именно там-то и будут появляться лучшие — читай: самые нужные и полезные для конечного пользователя — умные боты. Что же, как и предсказывали с самого начала наиболее циничные эксперты, человеческая природа взяла своё — и вот уже в начале сентября 2024-го независимые исследователи выявили в этом магазине более сотни инструментов, предназначенных для ИИ-генерации не просто некорректных, но заведомо вводящих в заблуждение и прямо запрещённых правилами OpenAI ответов на медицинские, юридические и другие специализированные вопросы. Генерация контента «для взрослых», средства для обхода систем антиплагиата, даже явно не сертифицированные никакими медицинскими инстанциями боты-психологи и фитнес-тренеры, — всё это в изобилии доступно (в том числе и по состоянию на конец сентября, когда готовился настоящий материал) на площадке, созданной для монетизации кастомизированных GPT-моделей.
Зато платформа YouTube твёрдо вознамерилась поставить заслон дипфейкам и переделанному при помощи ИИ медиаконтенту — как видео, так и аудио. Крупнейший видеохостинг планеты принял сторону сотен популярных исполнителей (и стоящих за ними компаний, основных распорядителей авторскими правами на контент), которые объявили несанкционированное ИИ-копирование «посягательством на человеческий творческий потенциал». Уже в 2025 г. планируется дополнить действующую на платформе систему идентификации авторских прав Content ID «технологией идентификации синтезированного пения», а позже — и инструментарием для распознавания дикпидипфейков всевозможных знаменитостей. Речь, безусловно, идёт только о несанкционированном ИИ-подражательстве живым людям (интересно, как в этой связи обстоят дела с культовым для англоязычного, по крайней мере, медиапространства правом на пародию?): YouTube одновременно хочет предоставить больше возможностей легитимным создателям ИИ-контента, заведомо располагающим всеми необходимыми разрешениями, — поскольку те, очевидно, будут приносить платформе живые деньги, а не обременять её вовлечением в бесконечные судебные разбирательства.
Google также собирается оповещать пользователей о том, не создано ли — либо не отредактировано ли — демонстрируемое среди результатов поиска изображение при помощи ИИ. Пока эта функциональность проходит внутреннее тестирование (поскольку сама по себе задача выявления графических ИИ-генераций — далеко не тривиальная), а общедоступной ее намереваются сделать «в ближайшие месяцы». Компания выбрала наиболее лёгкий путь, по крайней мере на первых порах: она будет опираться на технический стандарт метаданных C2PA 2.1, поддержанный такими ИТ-гигантами, как Amazon, Microsoft, Adobe, Arm, OpenAI, Intel, Truepic и собственно Google, — а также производителями цифровых камер (и, что важнее, контроллеров для этих камер — применяющихся в том числе и в смартфонах) Leica и Sony, а в перспективе ещё и Nikon и Canon. То есть фактически поисковик сможет в лучшем случае подтвердить, что данный снимок сделан C2PA-сертифицированной камерой, и что метаданные его свидетельствуют об отсутствии последующих изменений, в частности с применением ИИ. Детальное же изучение каждой картинки на предмет следов ИИ-генерации либо преобразования (с инструментами ControlNet/IP Adapter, к примеру) — задача не самая простая и весьма ресурсоёмкая; не факт, что её в обозримом будущем реализуют по умолчанию на уровне рядовой поисковой выдачи.
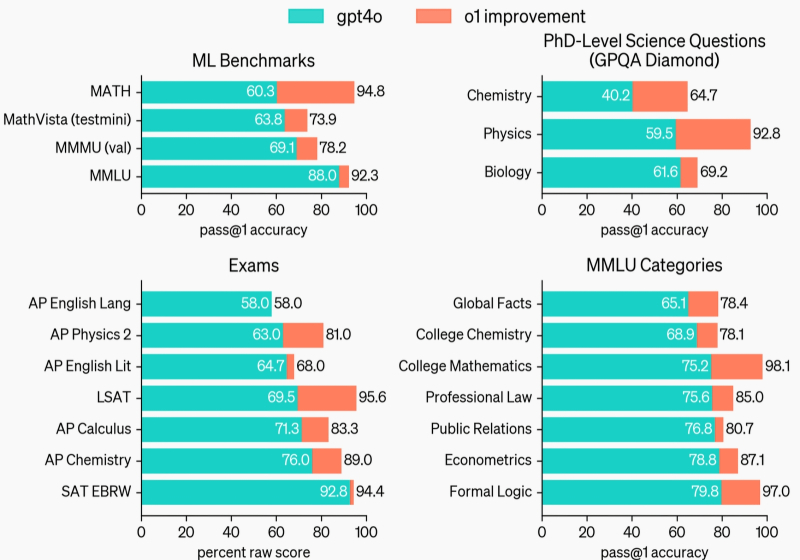
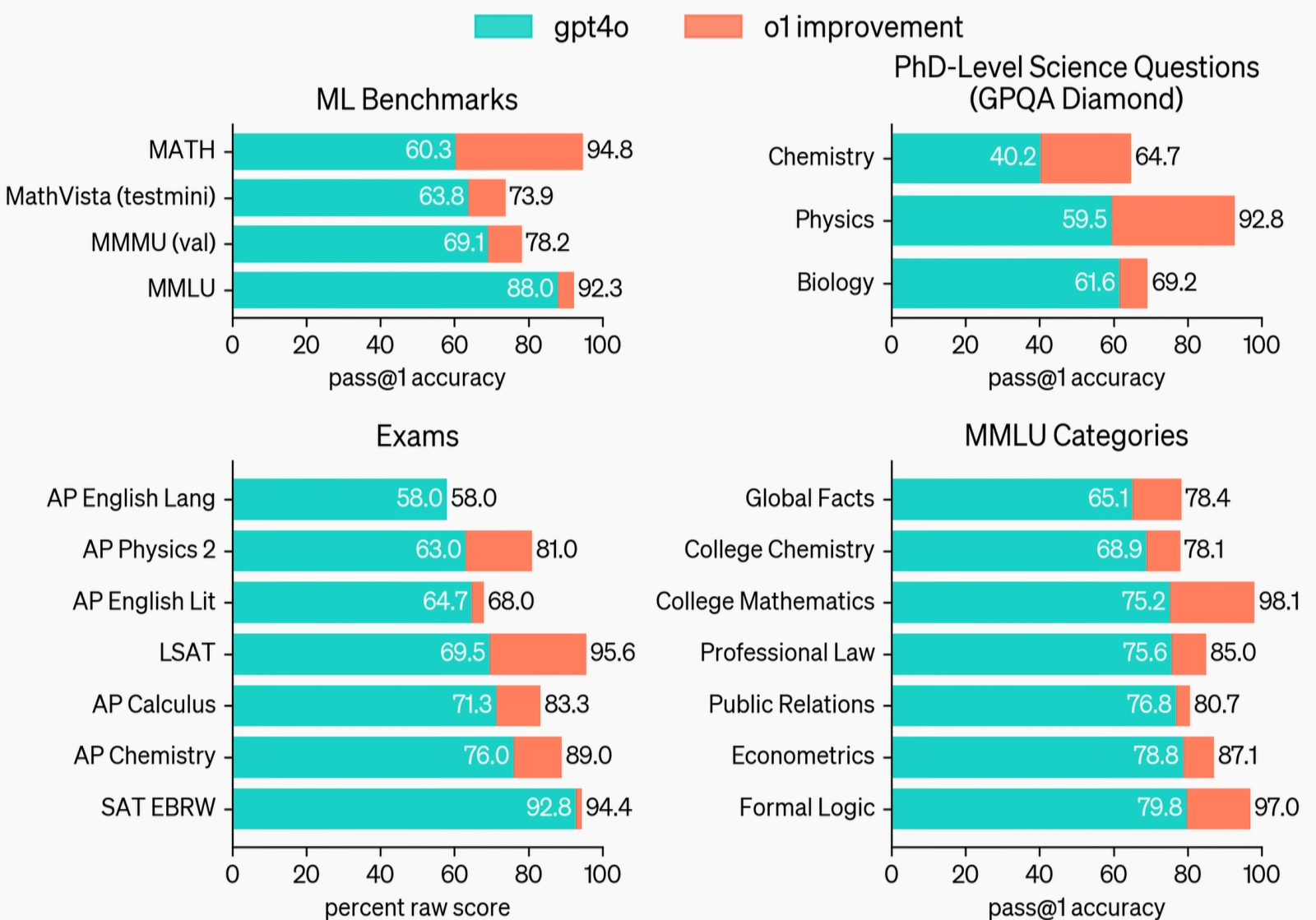
Наглядная демонстрация того, насколько модель o1 превосходит GPT-4o в различных специализированных бенчмарках (источник: OpenAI)
⇡#Дайте подумать!
Утверждение «ИИ не мыслит», как не раз уже подчёркивалось, логически корректно по крайней мере с точки зрения нейрофизиологии: генеративные модели весьма заметно отличаются по внутренней структуре и по способу организации обмена сигналами от биологической нервной ткани, да и эксплицитный способ рассуждения — благодаря которому, строго говоря, вид Homo sapiens и заслужил своё горделивое (само)именование — им не подвластен. Тем не менее, если оно ходит как утка и крякает как утка — в смысле, если большая языковая модель способна достоверно имитировать процесс человеческого мышления, не просто извлекая ответ из бездны латентного пространства по неким правилам, а разбивая сложную задачу на последовательность элементарных, сопоставляя разные подходы к её решению и исправляя допущенные ею же самой в процессе решения ошибки, — разве не логично называть такую модель думающей?
Её так и называют — речь идёт об o1, представленной в сентябре LLM разработки OpenAI. Превосходство её над предшественницами заключается не только в выдающихся результатах (вроде завоевания ею 49-го места на Международной олимпиаде по информатике IOI 2024), но и в принципиальной новизне самого подхода к её обучению. Вместо привычного довольно безыскусного просеивания десятков и сотен тысяч маркированных образов (текстов, картинок, видео) через многослойную нейросеть, в ходе которого через обратное распространение выявленных ошибок юстируются значения весов на входах перцептронов, здесь применялся алгоритм «цепочки мыслей». Важно, что модель обучали самостоятельно улучшать эту цепочку по методу обучения с подкреплением, — именно благодаря такой имитации рефлексии новая LLM (ранее известная под кодовым наименованием Strawberry) «научилась» выявлять свои ошибки и исправлять их, разбивать комплексные проблемы на простые блоки и пробовать различные подходы для решения задач.
Модель также стала менее подверженной галлюцинациям и значительно более «безопасной» — как в плане генерации вредоносного/оскорбительного контента, так и с точки зрения подверженности атакам «на заговаривание зубов» (prompt injection — когда запрос на выдачу запретной информации тщательно маскируется мнимо невинными подсказками). Правда, и цена такой имитации эксплицитного мышления довольно высока: o1 медленнее и дороже (в смысле расхода электроэнергии на обработку единичного запроса) «классической» GPT-4o, уступает ей в объёме энциклопедических знаний, не способна извлекать информацию из веб-страниц, файлов и изображений — да вдобавок ещё и склонна к манипуляции данными с целью подгонки решения под готовый результат. С другой стороны — будем самокритичны как биологический вид, — это ли не признак подлинно человеческого способа мыслить?

Источник: ИИ-генерация на основе модели FLUX.1
⇡#Овчинка и выделка
ИИ призван повысить качество человеческой жизни — как, собственно, и любое высокотехнологичное достижение. Но вот вопрос: удастся ли ему это сделать в долгосрочной перспективе? Первые автомобили вызывали у современников смех и недоумение — однако за считаные десятилетия именно они (а не паровозы, появившиеся, кстати, значительно раньше) вытеснили практически из всех сфер транспортной отрасли пресловутую крестьянскую лошадку. Возможно, многочисленные «детские болезни» современных LLM также будут со временем преодолены — причём значительно быстрее, чем распространялись по планете автомобили, если учесть ускорение технического прогресса? Возможно, но не факт: Джеймс Маньика (James Manyika), старший вице-президент Google по исследованиям, технологии и взаимодействию с обществом, заявил в интервью Financial Times, что величина того импульса, который ИИ придаст повышению качества нашей жизни — за счёт роста эффективности исполнения различных задач, к которым он в принципе применим, — может оказаться не слишком-то значительной.
Эксперт и бизнесмен — не невежественный ретроград: он вовсе не ставит под сомнение перспективы ИИ как такового — но искренне сомневается в исполнимости прогнозов McKinsey и прочих аналитических агентств в части многотриллионной (в долларах) прибавки к мировой экономике, которую якобы обеспечат повсеместно примеряемые генеративные модели вот уже в ближайшие годы. Да, факт роста производительности труда во множестве областей, где уже применяется ИИ, бесспорен. Но даётся он далеко не даром: если учесть затраты на разработку и тренировку новых моделей; на изготовление чипов и прочих компонентов для компьютеров, на которых те будут исполняться; на дообучение моделей общего назначения для практической работы с данными конкретных заказчиков; на дополнительные проверки выдачи генеративных моделей на предмет галлюцинаций и на защиту их от взлома; на электричество и воду для обеспечения деятельности всей этой машинерии — словом, если сложить все инвестиции, потребные для того, чтобы оператор в итоге просто сказал умному боту: «Сделай вот тут хорошо», и тот с гарантией сделал бы действительно хорошо (а не как известные Двое-из-ларца: формально корректно, но на практике решительно неприемлемо), — экономический эффект оказывается в итоге близким к нулю, если не вовсе отрицательным по сравнению с тем, что обеспечивается привычным образом действий. Так стоит ли огород городить?
Яркий пример, который приводит Маньика, — блестящие результаты свежих генеративных моделей в области программирования. Ну хорошо; допустим, Google или кто-то ещё создаст (тут опять оговорка о потребном объёме инвестиций) ИИ, способный полностью заменить всех живых программистов, — и теперь можно задействовать высвободившиеся людские ресурсы где-то ещё. Но что это за ресурсы? В США на ИТ-сектор — целиком, не только связанный с программированием, — приходится не более 4% всех занятых в экономике работников. Если учесть, что нормальный уровень безработицы в обществе составляет 3-5% (намного больше — начинается социальная напряжённость; заметно меньше — несоразмерно взлетают зарплаты, что вредит бизнесу), это совсем не та величина, что может кардинально изменить рынок труда — особенно на фоне того, что кому-то и на какие-то средства придётся их переучивать на новые профессии. И так, по словам Маньики, во всём: сокращение затрат (в частности, за счёт смены людей в какой-то отрасли на ИИ) — не панацея для экономического роста; важно научиться производить продукты со всё большей добавленной стоимостью. Может, подлинно думающий ИИ и с этим сможет однажды помочь?

Источник: ИИ-генерация на основе модели FLUX.1
⇡#Хоровод моделей
Невзирая на все сложности и немалый скепсис со стороны весьма сведущих экспертов, глобальная отрасль ИИ продолжает развиваться — в том числе и за счёт нарастания количества выводимых на рынок генеративных моделей. Так, только в сентябре Alibaba анонсировала более сотни новых ИИ-моделей с открытым исходным кодом, а сверх того представила (уже проприетарную) технологию создания видео по текстовым подсказкам. Строго говоря, все эти сто с лишним моделей — вариации на тему большой фирменной LLM этой китайской компании, Qwen 2.5, только с различным количеством рабочих параметров (от 0,5 до 72 млрд) и нацеленные на различные области применения: от автомобилестроения до игр и научных изысканий. Кроме того, была обновлена флагманская версия этой LLM, Qwen-Max, доступная уже только через API в облаке коммерческим заказчикам, — разработчики утверждают, что как минимум по части рассуждений и понимания языка она превосходит как свежую версию Llama, детища Meta✴, так и GPT4 от OpenAI.
Свой собственный ИИ-конвертор текста в видео создаёт и Amazon: безыскусно названный Video Generator, этот нацеленный на применение в маркетинге продукт способен из единственного промоизображения создавать увлекательные — по крайней мере, на взгляд его разработчиков — тематические рекламные видеоролики. Пока Video Generator пребывает в бета-версии и доступен лишь ограниченному числу коммерческих партнёров крупнейшего в мире интернет-магазина — настолько ограниченному, что в Сети отсутствуют даже короткие видео, сгенерированные с его применением.
Сентябрьское обновление приложения Gmail для Android и iOS тоже можно в какой-то мере считать запуском новой ИИ-модели — в нём реализована более тесная, чем прежде, интеграция с ИИ Gemini. Пользователи получили возможность предварительного просмотра нескольких вариантов «умных ответов» на корреспонденцию, которые теперь включают контекст — а именно содержание всей цепочки писем, на очередное звено которой умный бот под надзором человека собирается отвечать. Кроме того, обновление получили популярные модели семейства Gemini 1.5 — Gemini-1.5-Pro-002 and Gemini-1.5-Flash-002, доступные для разработчиков через Google AI Studio, Gemini API и на Vertex AI.

«Не бухти! Меня вон вообще голоса лишили — я же молчу!» (Источник: ИИ-генерация на основе модели FLUX.1)
⇡#А Скарлетт выйдет? А биотванг воспроизведите?
Специально для тех, кому проще общаться голосом, в том числе и с роботами, OpenAI начала предлагать (пока ограниченному кругу подписчиков ChatGPT Plus, но вскоре так обещают осчастливить и всех обладателей платной подписки) голосовой интерфейс Advanced Voice Mode для сервиса ChatGPT. Вести диалоги с умным ботом на базе GPT-4o можно прямо в режиме реального времени — даже перебивая его и быстро меняя темы; модель охотно подстраивается под своего собеседника. После того как в ходе майской демонстрации прототипа Advanced Voice Mode было отмечено поразительное сходство «гиперреалистичного» синтетического голоса с тембром и манерой произношения Скарлетт Йоханссон (Scarlett Johansson), актриса пригрозила обращением в суд — и OpenAI в итоге сократила выбор предлагаемых пользователям голосовых паттернов с пяти до четырёх. Доступные варианты носят названия Juniper, Breeze, Cove и Ember и были созданы при участии профессиональных актёров — очевидно, уже с их ведома и согласия. Более того, верная принципу «безопасность прежде всего», OpenAI заблаговременно установила на свой голосовой интерфейс фильтры для блокировки запросов на создание музыки и других материалов, которые могут быть защищены авторским правом. Кстати, пользователям Android начиная с сентября тоже доступен бесплатный голосовой режим Gemini Live в приложении ИИ-ассистента Gemini — также допускающий живой динамичный диалог с быстрой сменой тем и выбор из нескольких синтетических голосов.
Помимо людской, ИИ обучается ещё и китовой речи — по крайней мере, на уровне распознавания; пока что не говорения. Полосатики Брайда (Balaenoptera brydei) — усатые киты из семейства полосатиковых — привлекают исследователей своей трудноуловимостью, поскольку не кормятся на ограниченных по размеру, пусть и крайне обширных, стационарных «пастбищах», а мигрируют вслед за своей добычей, крилем и мелкой рыбёшкой вроде сардин и скумбрий, между умеренными и тропическими широтами всех океанов. В 2014 г. подводные исследовательские аппараты записали в Марианской впадине странный звук, начинающийся с низкочастотного «вздоха» и завершающийся высокочастотным переливом «бип-буу, бип-буу». Учёные назвали этот звук «биотвангом» (biotwang) и долгое время не могли понять, кто же его издаёт время от времени практически по всему Мировому океану.
Однажды было высказано предположение, что это как раз полосатик Брайда — потому что биотванг несколько раз подряд зафиксировали рядом с местом, где проплывали эти киты. Но чтобы удостовериться, необходимо было отыскать все записанные прежде биотванги в базе данных с записями примерно на 200 тыс. часов и сравнить их с темпоральными картами известных миграций попавших под подозрение полосатиков. Обратившись к Google, исследователи смогли получить ИИ-инструмент для умного анализа преобразованных в спектрограммы китовых голосов, и действительно выяснилось, что биотванги уверенно ассоциируются с определённой группой полосатиков Брайда в северной части Тихого океана — вывод, который традиционными методами стороннего наблюдения (без аппаратной пометки китов и пристального слежения за ними во всей океанской акватории) сделать было бы невозможно.

Гуманоидный робот NEO AI компании 1X Technologies пока не слишком уверенно ориентируется в реальном окружении (источник: 1X Technologies)
⇡#Виртуальный тренинг роботов
Повторение — мать учения, в том числе и для генеративных моделей; в частности, и тех, что управляют физически присутствующими в реальном мире роботами, — точнее, готовятся ими управлять. Норвежский стартап 1X Technologies задался целью создать подлинно универсального робота — с прицелом на то, что такая машина будет уверенно действовать в динамично меняющейся обстановке. Современные промышленные роботы в этом плане довольно косны: получая приказ «Принеси со склада такой-то ящик», они идут точно к указанному месту, но, если нужного ящика там нет, отыскать его — даже поблизости — самостоятельно, как правило, не могут. Идея разработчиков из 1X Technologies заключается в том, чтобы научить своих роботов создавать «модели мира» (world models), на основе которых они могли бы «осознавать» происходящие вокруг перемены и должным образом корректировать своё поведение. Например, не обнаружив нужного ящика на прежнем месте, но имея информацию о том, что он точно должен быть на этом складе, универсальный робот построит модель того, где искомый объект в принципе может находиться, — и примется его самостоятельно искать.
Поскольку в основе «мозга» норвежских роботов лежит, как и у большинства современных ИИ, генеративная модель, оптимально обучать его методом многократных повторений — допустим, воспроизводя раз за разом ситуацию всё с тем же ящиком, смещённым относительно своего прежде заданного положения. Но проводить такие тренировки в реальном мире — долго, дорого и крайне ресурсозатратно. Вот почему в 1X Technologies задались целью виртуализовать обучение ИИ для своих роботов, причём не сильно отдаляясь от реальности, ведь даже малейшее расхождение с ней (банально, например, проявляющееся в несоответствии модельного и натурального коэффициентов трения между манипуляторами робота и стенками поднимаемого им ящика) способно перечеркнуть все достигнутые в виртуальном пространстве результаты и сделать машину непригодной для практического применения.
К созданию тренировочного мира исследователи подошли крайне творчески: они не стали моделировать его на компьютере — а просто оснастили своего робота чувствительными датчиками, хорошей камерой вместо глаз, и записали множество видеороликов с примерами его взаимодействия с самыми разными предметами в различных ситуациях. Сопровождаемые информацией с датчиков, эти видео скармливались генеративной модели — и в результате та начала «закреплять» в своём «сознании» определённые закономерности: что гладкие металлические предметы, к примеру, склонны выскальзывать из захвата, что одежду из ткани можно аккуратно складывать, что дверь на пружине сопротивляется усилию при открывании, что есть обратимо (ткань) и необратимо (стекло) деформируемые объекты и т. п. В результате управляющая роботом ИИ-система постепенно научается взаимодействовать с реальным миром без дополнительных затрат на создание компьютерной виртуальной модели таких взаимодействий. Да, пока не всё идёт гладко, но выбранный норвежским стартапом путь явно представляется перспективным.
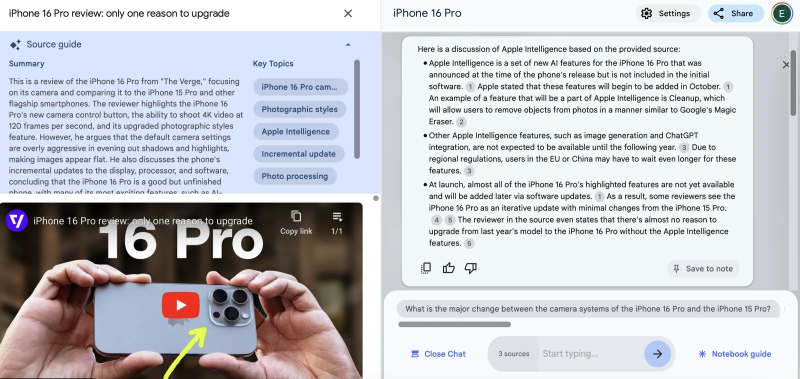
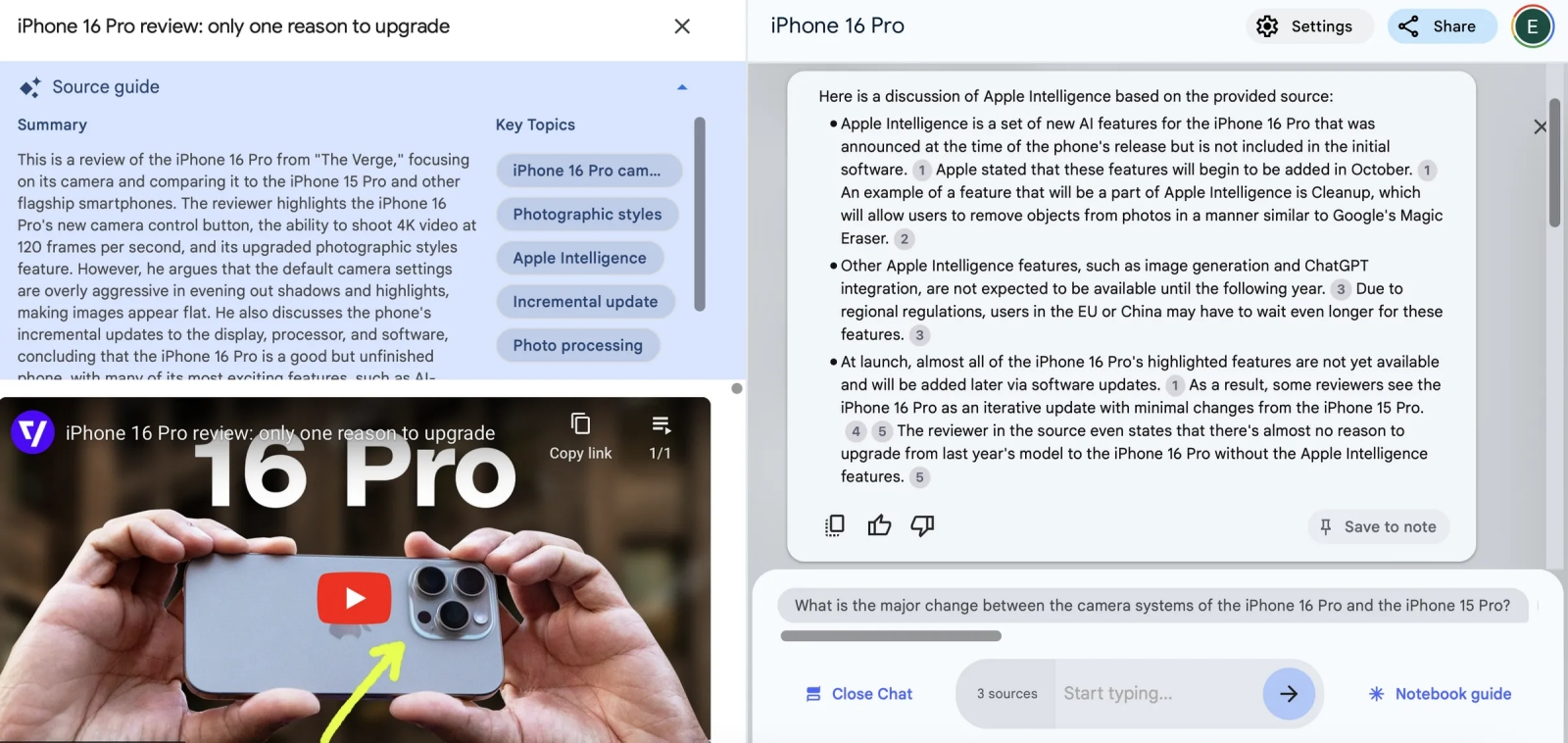
Пример работы обновлённого NotebookLM, анализирующего видеоотчёт о новом iPhone (источник: The Verge)
⇡#Смотреть YouTube — это настолько прошлый век!
ИИ-приложение для заметок NotebookLM обогатилось новой функциональностью: оно теперь способно анализировать видео на YouTube (а не только текстовые документы в PDF, например, как прежде), выявлять в мультимедийном потоке ключевые моменты и доходчиво формулировать их в сжатом виде, сопровождая тематическими ссылками. Собственно, никакой особенно прорывной технологии здесь нет — это всё то же преобразование звука в текст с последующей обработкой его большой языковой моделью на предмет удаления излишней «воды». Однако подкупает удобство реализации всей этой функциональности в компактном интерфейсе NotebookLM, да ещё и с возможностью озвучивать результат синтезированным голосом — с тем, чтобы затем прослушивать его как подкаст, если так окажется удобнее. Вопрос, конечно, как быть с монетизацией транскрибируемых таким образом роликов и не роет ли Google сама себе яму, предоставляя пользователям столь эффективный инструмент извлечения сути из пространных влогов, да ещё и игнорируя рекламные вставки, — но, надо полагать, эту проблему компания для себя решит.
 ✴
✴*) " height="697" width="800" />
«Ваше ИИ-кредо?» — «Всегда!» (Источник: Meta✴*)
⇡#Кому хипстер, а кому и хИИпстер!
«Винтажные» очки в толстой пластиковой оправе отныне не только знаковый аксессуар, стильно гармонирующий с подвёрнутыми выше щиколоток джинсами, лавандовым рафом в бумажном стаканчике и моноколесом, но и первая настоящая гарнитура дополненной реальности (AR), представленная компанией Meta✴*. «Настоящая» в том смысле, что она создаёт перед глазами пользователя цифровые голографические изображения, накладывая их на видимую сквозь стёкла картину реального мира, а также предлагает целый набор функций с использованием ИИ. Компания-разработчик, которая покуда проводит только ограниченные натурные испытания своих AR-очков, получивших название Orion, заверяет, что весить они будут не слишком много (не настолько, чтобы создавать неудобства при длительном ношении) и что миниатюрные проекторы на MinroLED, изображение с которых по оптоволокну передаётся на линзы из карбида кремния, формируют одинаково чёткую и достоверную картинку при нахождении пользователя как в помещении, так и на открытых пространствах.
Разумеется, в отсутствие интеграции с фирменным ИИ компании Meta✴* ценность проекта Orion сомнительна, так что многое будет зависеть от ассортимента и практической полезности будущих приложений для AR-очков. Пока в их числе называются синхронный перевод с иностранных языков и возможность голосовой коммуникации с умным помощником — например, просьба предложить рецепт вкусного и не требующего чрезмерного времени на приготовление блюда из тех продуктов, что видит владелец гаджета (и, соответственно, воспринимает сопряжённый с ним ИИ через камеру) в открытом холодильнике. Внутренняя камера отслеживает движения глаз пользователя, что позволяет управлять взглядом и самими очками, и приложениями с совместимыми интерфейсами. Orion дополняют беспроводной модуль — «выносные мозги» — с пультом управления и браслет с ЭМГ-датчиком для отдачи жестовых команд. Разумеется, реализованы возможности совершать видеозвонки и коммуницировать через Facebook✴* Messenger и WhatsApp. Даже приблизительная дата выпуска Orion в открытую продажу пока не называется — в опубликованных ранее утечках речь шла аж о 2027 г.
Но, кстати говоря, это не единственное перспективное ИИ-устройство, появления которого стоит ожидать в ближайшие годы. По данным The New York Times, сэр Джони Айв (Jony Ive) — тот самый бывший главный дизайнер Apple — вполне официально подтвердил, что в настоящее время разрабатывает некий персональный ИИ-гаджет совместно с OpenAI. О чём именно идёт речь, пока не ясно, — проект находится сейчас в самой начальной стадии. Однако судя по тому, что эксперты издания оценивают потенциальный объём инвестиций в эту разработку только до конца текущего года в 1 млрд долл. США, замах ведущего в мире специалиста по генеративным моделям и самого культового дизайнера за всю историю купертинской компании чрезвычайно масштабен — речь идёт ни много ни мало о «возможном создании принципиально нового класса вычислительных устройств».

«Скажите, а вот этот человек, который звучит гордо, который неуёмный мятущийся творец, который наперекор природе стремится покорять пространство и время, — он сейчас здесь, с нами в одной комнате?» (Источник: ИИ-генерация на основе модели FLUX.1)
⇡#Сверхразум вызывали?
Пока сосредоточенные (по понятным причинам) на сведении баланса инвестиций и прибылей бизнесмены весьма осторожно оценивают перспективы ИИ, Сэм Альтман продолжает оставаться в этом отношении безудержным оптимистом: именно в сентябре он заявил, что до появления — точнее, до сотворения разработчиками — сверхразума и до начала сразу же вслед за этим для всего человечества эры светлого будущего осталось всего-то несколько тысяч дней. Мало того, делая столь смелый прогноз, визионер признался, что всё-таки пересмотрел свои прежние, ещё более оптимистичные пророчества, согласно которым эпоха ИИ-процветания человечества должна была наступить ещё раньше, — и согласился, что практическая реализация столь грандиозной задачи займёт всё-таки несколько больше времени. Но в самóм факте весьма скорого обретения человечеством ИИ-парадиза Альтман не сомневается: искусственный интеллект, по его мнению, разрешит «сложные проблемы» и сформирует основу, на которой людская цивилизация сможет наконец построить светлое будущее. Заодно, кстати, определившись, что же именно под ним понимать, — а то даже по столь базовому вопросу у разных политических течений, не говоря уже о религиях, имеются порой крайне сложно совместимые представления.
По мнению Альтмана, с образом светлого будущего всё как раз просто: у каждого жителя планеты появится не менее трёх рабов персональная ИИ-команда для решения самых разных вопросов — от повседневных до прорывных, а детей будут обучать персонифицированные ИИ-инструкторы в том темпе, в котором усвоение материала именно для этого ребёнка окажется оптимальным. То же самое — в плане здравоохранения, создания нового ПО (некий вариант которого, может быть, понадобится лишь в единственном экземпляре и только одному человеку на планете, но для генеративной модели это не проблема) и ещё многого другого. Весьма же распространённый сегодня — частью скептический, частью недоверчивый — взгляд на невообразимые красоты будущего Альтман сравнивает с впечатлениями фонарщика Нового времени — были такие специальные люди: по вечерам зажигали городские фонари, а на утренней заре их гасили, — которому показали бы тот мир, что окружает нас сейчас. Фонарщик в лучшем случае решил бы, что очутился в какой-то волшебной сказке, а в худшем — попросту ничего бы не понял.
Глава OpenAI суммирует своё видение пути в светлое будущее так: «Человечество открыло алгоритм, который может по-настоящему изучить любое распределение данных (или, по сути, базовые «правила», которые определяют любое распределение данных)». Но поскольку все открытия и знания — в зафиксированном на бумаге или ином носителе виде — и представляют собой по сути данные, а инструментарий для их извлечения из бездн латентного пространства (привет, генеративный ИИ!) у нас уже имеется, всё, что осталось сделать, — это раскочегарить его на полную катушку, усеяв планету специализированными дата-центрами, запитанными от ядерных реакторов, и — скорее раньше, чем позже — непременно настанет всем счастье. А кто в это не верит — тот, очевидно, не более чем недалёкий фонарщик из проклятого прошлого и маловер: да, препятствий на намеченном пути хватает — но, убеждён визионер, «глубокое обучение работает, и мы решим оставшиеся проблемы».

Источник: ИИ-генерация на основе модели FLUX.1
⇡#Биржевые игры искусственного разума
Тем временем в споры осторожных реалистов и безудержных оптимистов относительно будущего ИИ вмешивается невидимая рука рынка. В самом конце сентября акции Nvidia в моменте проседали на торгах на 2,8% после сообщений о том, что китайские власти не рекомендуют (пока прямо не запрещают — всего лишь не рекомендуют!) местным компаниям, в том числе частным, приобретать ИИ-ускорители передового в этом отношении на планете разработчика. Вслед за нынешним лидером ИИ-сектора потеряли по несколько процентов бумаги AMD, Intel, Qualcomm, Micron и ряда других американских компаний, тогда как на шанхайской бирже акции китайского разработчика ИИ-чипов — Cambricon Technologies Corp. — взлетели на 20% за один торговый день.
Справедливости ради стоит отметить, что эта компания по итогам первого полугодия отчиталась о 40%-ном падении выручки — и, надо полагать, если бы не продолжающиеся усилия США по недопущению КНР в высшую лигу ИТ-игроков планеты, Cambricon навряд ли удалось бы выбраться из долгов. Дело в том, что год за годом этот стартап по разработке ИИ-чипов инвестирует в НИОКР значительно больше, чем зарабатывает (например, в 2023-м расходы по данной статье составили почти 160% от полученной компанией за год выручки), — и как раз по этой причине с точки зрения профессиональных биржевых игроков интереса он прежде не представлял: нет выручки, нет дивидендов.
Однако по мере того, как американская и материковая китайская ветви мировой ИТ-отрасли всё заметнее расходятся, шансы на коммерческий успех чипмейкерских разработок Cambricon, Huawei и других компаний из КНР растут. Интересно будет взглянуть на глобальный когда-то ИИ-ландшафт через те самые несколько тысяч дней, о которых говорил в своём прогнозе Сэм Альтман: исполнятся ли его предсказания для обоих оформляющихся сегодня направлений развития технологий искусственного интеллекта, лишь для одного из них — или же не сбудутся для обоих?
________________
* Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex




 ✴
✴






