







 MWC 2018
MWC 2018 2018
2018 Computex
ComputexСпустя несколько месяцев после запуска Qwen3-VL компания Alibaba опубликовала подробный технический отчёт об открытой мультимодальной модели. Данные показывают, что система превосходно справляется с математическими задачами, связанными с изображениями, и может анализировать многочасовые видеоматериалы.









Источник изображений: Alibaba
Система справляется с большими объёмами данных, обрабатывая двухчасовые видео или сотни страниц документов в контекстном окне из 256 тыс. токенов. В тестах «иголка в стоге сена» флагманская модель с 235 млрд параметров обнаруживала отдельные кадры в 30-минутных видео со 100-процентной точностью. Даже в двухчасовых видео, содержащих около миллиона токенов, точность сохранялась на уровне 99,5 %. Тест основан на вставке семантически важного кадра-«иглы» в случайные места длинных видео, которые система затем должна найти и проанализировать.
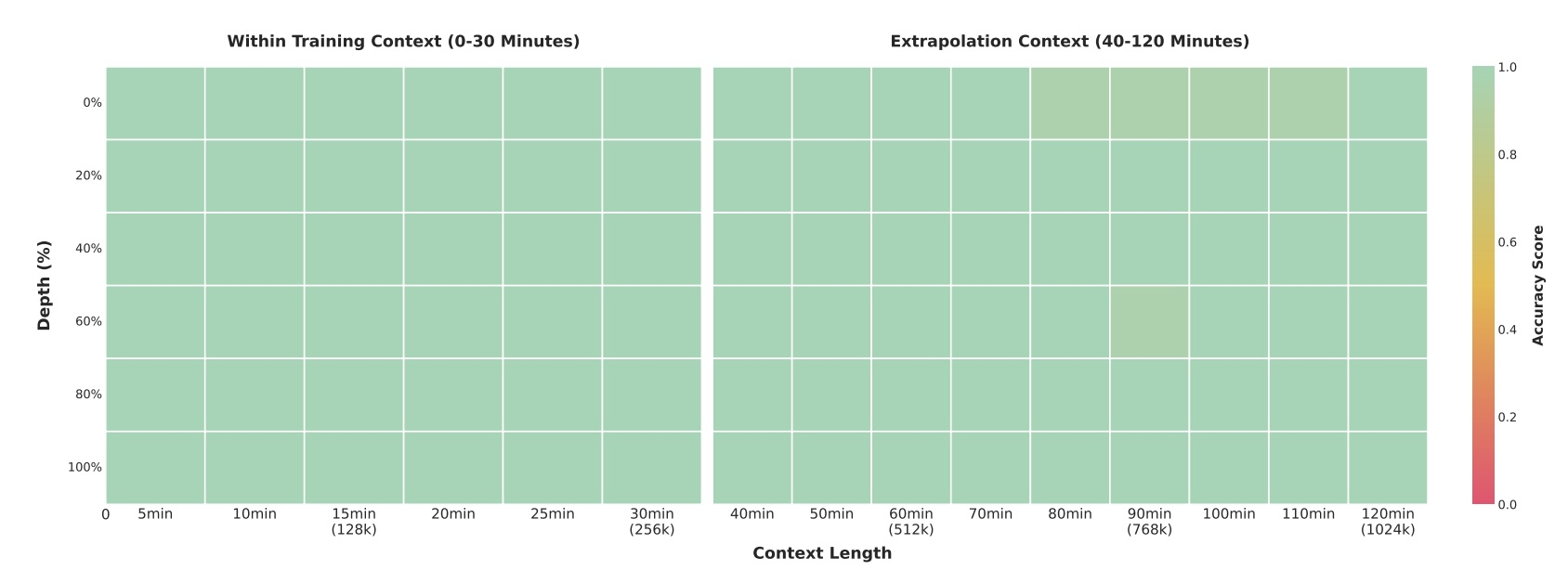
Тест «иголка в стоге сена» измеряет способность модели находить определенные кадры в длинных видеороликах
В опубликованных бенчмарках модель Qwen3-VL-235B-A22B часто превосходит Gemini 2.5 Pro, OpenAI GPT-5 и Claude Opus 4.1, даже когда конкуренты используют функции логического мышления или требуют больших затрат на мышление. Модель доминирует в задачах с визуальным математическим анализом, набирая 85,8 % в MathVista по сравнению с 81,3 % у GPT-5. В MathVision она лидирует с 74,6 %, опережая Gemini 2.5 Pro (73,3%) и GPT-5 (65,8%).
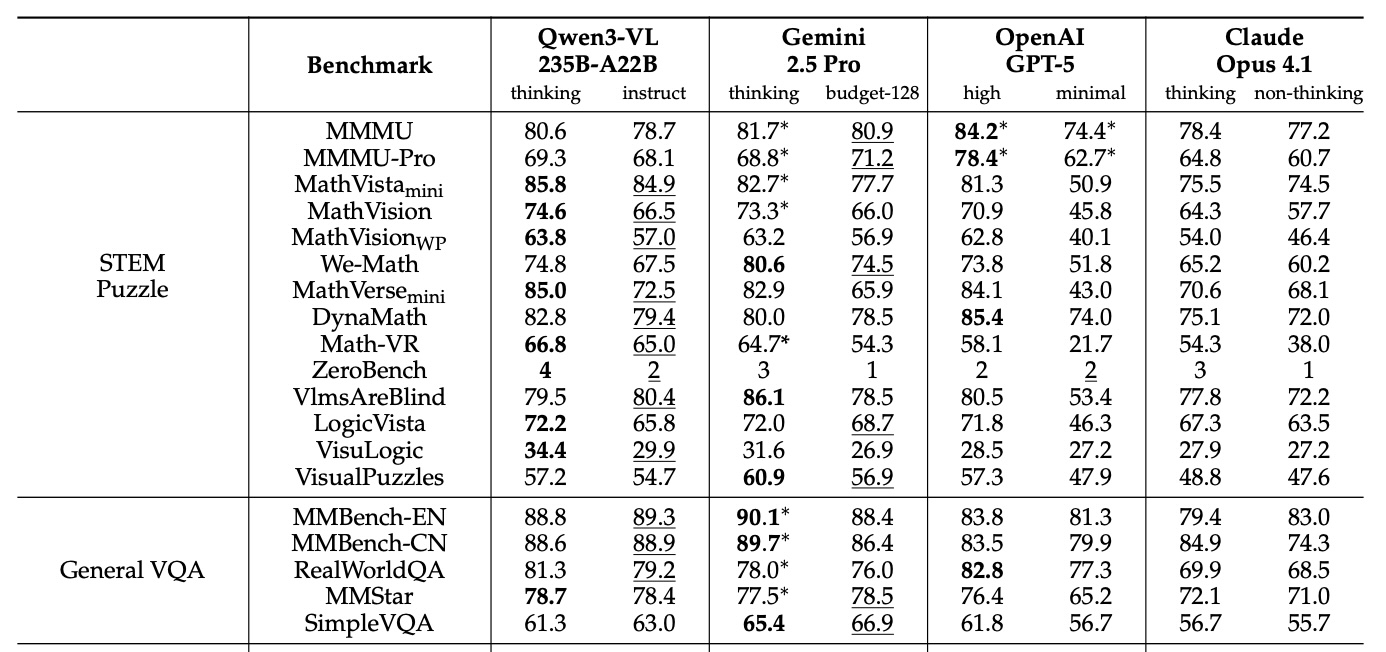
Модель Gemini 2.5 Pro сохраняет небольшое преимущество в общем понимании изображений
Модель также демонстрирует широкий диапазон результатов в специализированных бенчмарках. Она набрала 96,5 % в тесте на понимание документов DocVQA и 875 баллов в OCRBench, поддерживая 39 языков — почти в четыре раза больше, чем её предшественник.
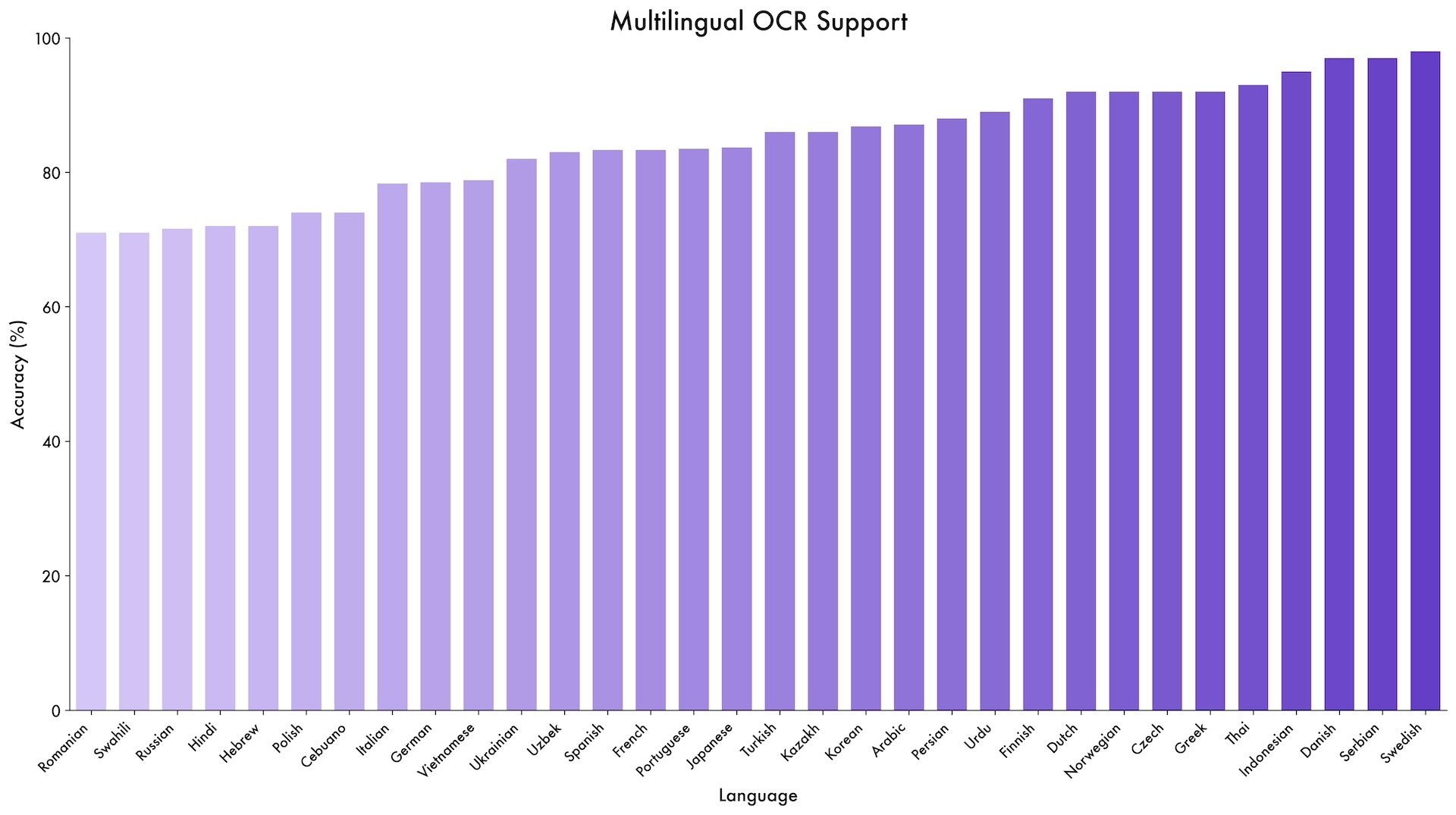
Qwen3-VL достигает точности более 70 процентов при выполнении задач OCR на 32 из 39 поддерживаемых языков
Alibaba утверждает, что модель также демонстрирует новые возможности в задачах графического интерфейса. Точность Qwen3-VL-32B в ScreenSpot Pro, тестирующем навигацию в графических пользовательских интерфейсах, составила 61,8 %. В AndroidWorld, где система должна самостоятельно управлять приложениями Android, Qwen3-VL-32B показал результат 63,7 %.
Модель также обрабатывает сложные многостраничные PDF-документы. В MMLongBench-Doc она показала результат 56,2 % при анализе длинных документов. В бенчмарке CharXiv для научных диаграмм она достигла 90,5 % при выполнении задач описания и 66,2 % при выполнении сложных логических задач.
Однако не во всех случаях Qwen3-VL оказалась лучше конкурентов. В сложном тесте MMMU-Pro модель набрала 69,3 %, уступив GPT-5 с результатом 78,4 %. Коммерческие конкуренты также обычно лидируют в тестах качества видео. Данные свидетельствуют, что Qwen3-VL специализируется на визуальных математических задачах и документах, но всё ещё отстаёт в области общих логических рассуждений.
В техническом отчёте описаны три основных архитектурных обновления, реализованных в Qwen3-VL. Во-первых, «interleaved MRoPE» заменяет предыдущий метод позиционного встраивания. Вместо группировки математических представлений по размерности (время, горизонталь, вертикаль), новый подход равномерно распределяет их по всем доступным математическим областям. Это изменение направлено на повышение производительности при работе с длинными видео. Во-вторых, технология DeepStack позволяет модели получать доступ к промежуточным результатам видеокодера, а не только к конечному результату. Это предоставляет системе доступ к визуальной информации с разной степенью детализации. В-третьих, система временных меток на основе текста заменяет сложный метод T-RoPE, используемый в Qwen2.5-VL. Вместо того, чтобы присваивать математическую временную позицию каждому видеокадру, система теперь вставляет простые текстовые маркеры, например, «<3,8 секунды>», непосредственно во входные данные. Это упрощает процесс и улучшает понимание моделью задач, связанных с анализом видео с временными рамками.
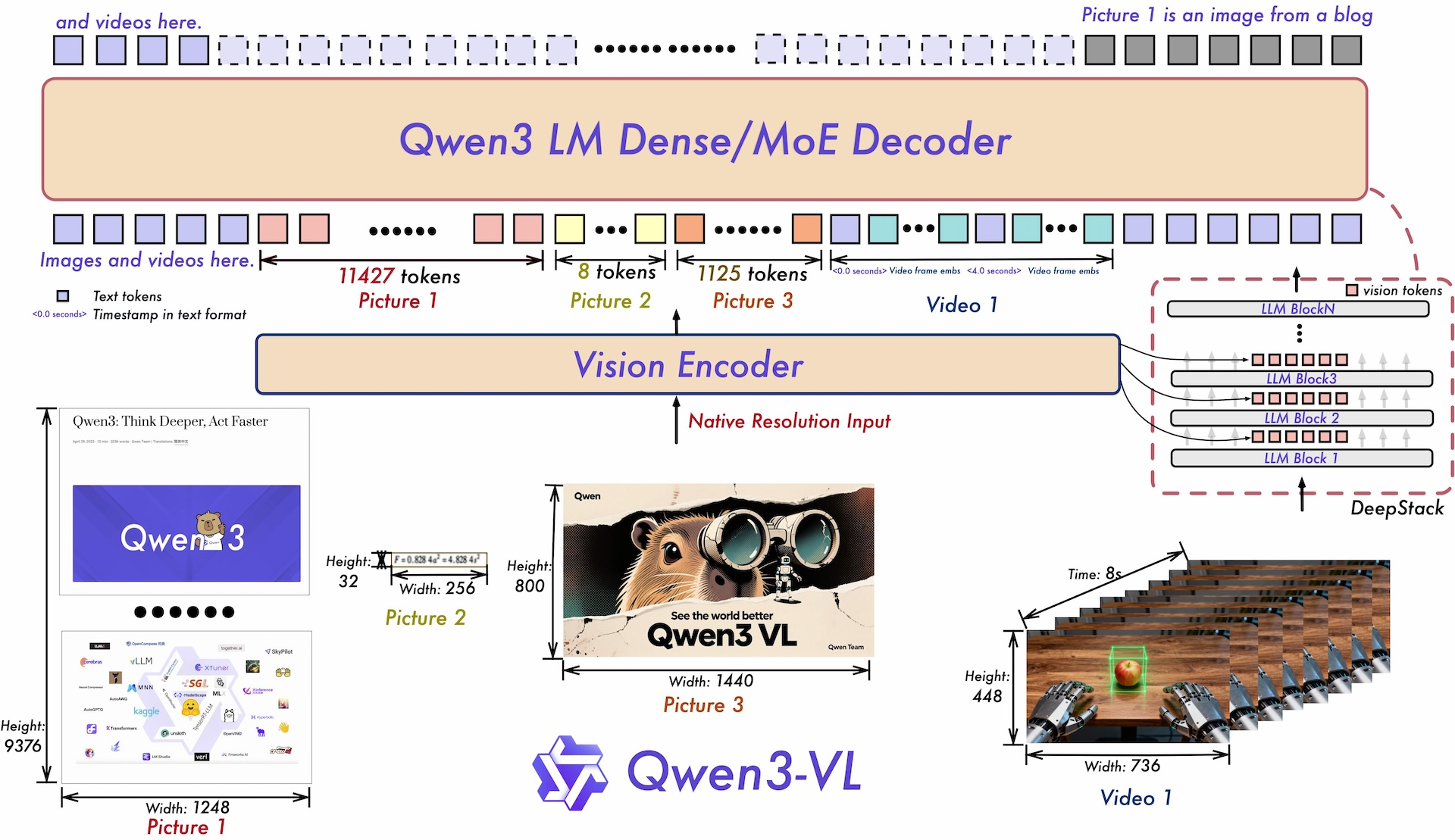
Qwen3-VL объединяет видеокодер и языковую модель для одновременной обработки текста, изображений и видео. DeepStack использует визуальную информацию с разных уровней обработки
Alibaba обучала модель в четыре этапа на базе 10 тыс. графических процессоров. После обучения связыванию изображений и текста система прошла полное мультимодальное обучение примерно на триллионе токенов. Источниками данных были веб-скрапы, 3 млн PDF-файлов из Common Crawl и более 60 млн STEM-задач. На последующих этапах команда постепенно расширяла контекстное окно с 8000 до 32 000 и, наконец, до 262 000 токенов. Варианты Thinking прошли специальное обучение Chain-of-thought training, что позволило им генерировать промежуточные шаги рассуждения перед предоставлением окончательного ответа для достижения лучших результатов при решении сложных задач.
Все модели Qwen3-VL, выпущенные с сентября, доступны по лицензии Apache 2.0 с открытыми весами на Hugging Face. Линейка включает плотные варианты с параметрами от 2B до 32B, а также модели со смесью экспертов 30B-A3B и массивные 235B-A22B.
Хотя такие функции, как извлечение кадров из длинных видео, не являются новыми (в начале 2024 года Google Gemini 1.5 Pro уже реализовал эту функцию), Qwen3-VL предлагает конкурентоспособную производительность. Поскольку предыдущая модель Qwen2.5-VL уже широко применялась в исследованиях, новая модель, вероятно, станет стимулом для дальнейшей разработки ПО с открытым исходным кодом.
Источник:





