







 MWC 2018
MWC 2018 2018
2018 Computex
ComputexСветлая мысль разместить больше памяти рядом с процессором пришла не в одну голову. Год назад о разработке концепции замены памяти HBM (DRAM) памятью HBF (флеш) сообщила компания SanDisk. На днях работу о таком подходе опубликовала компания SK Hynix. Флеш-память NAND попросту плотнее памяти DRAM, и с позиции увеличения места под токены для ИИ замена одной на другую даст впечатляющий результат в виде роста скорости принятия решений.




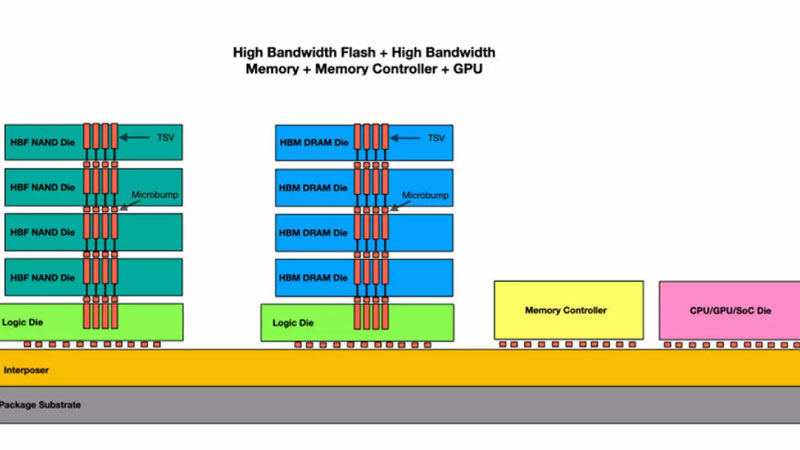
Источник изображения: SK Hynix
Не секрет, что современные платформы на базе центральных, графических и тензорных процессоров сталкиваются с серьёзным ограничением по объёму приданной им памяти High Bandwidth Memory (HBM), что сплошь и рядом происходит при работе с большими языковыми моделями. Например, модели вроде Llama 4 поддерживают до 10 млн токенов, что требует кэш объёмом до 5,4 Тбайт. Стандартные решения, такие как частичный сброс кэша на локальные SSD, приводят к значительным задержкам из-за низкой пропускной способности шины и медленного доступа к накопителям. В результате образуется узкое место по пропускной способности, что можно обойти только наращиванием массива ускорителей, а это — лишние деньги и энергопотребление.
Предложенная компанией SK hynix гибридная иерархия памяти или архитектура H³ (Hybrid³), объединяющая HBM и новый пока тип памяти High Bandwidth Flash (HBF) на одном интерпозере вместе с процессором, решает проблему нехватки памяти для токенов ИИ. Память HBM продолжит использоваться так же, как и раньше — для данных с высокой частотой записи и чтения (динамически генерируемый кэш), а HBF — для данных с интенсивным чтением.
Использование флеш-памяти HBF обеспечит до 16 раз большую ёмкость при пропускной способности, близкой к HBM, хотя задержка доступа останется выше на один или даже два порядка, износостойкость будет ниже, а энергопотребление может быть в 4 раза больше. В то же время массив гибридной памяти окажется единым для процессора, а грамотная маршрутизация запросов сведёт на нет все негативные последствия «тормозов» флеш-памяти.
Результаты моделирования на конфигурации Nvidia Blackwell GPU с 8 стеками HBM3E и 8 стеками HBF на интерпозере демонстрируют впечатляющие улучшения. При 1 млн токенов контекста производительность в токенах в секунду вырастает в 1,25 раза, при 10 млн токенов — уже в 6,14 раза по сравнению с чисто HBM-системой, а энергоэффективность становится выше в 2,69 раза. И если раньше для обработки запросов такого масштаба требовалось 32 GPU, то теперь работа может быть выполнена всего на 2 GPU с существенным снижением энергозатрат и общей стоимости системы. Ради такого стоит рискнуть и создать коммерческие решения, считают в компании.
Источник:





