|
Опрос
|
реклама
все новости
важное
хард
софт
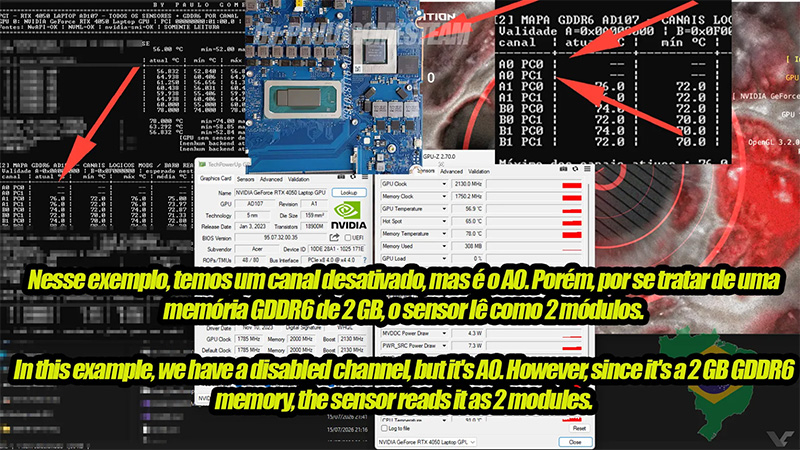
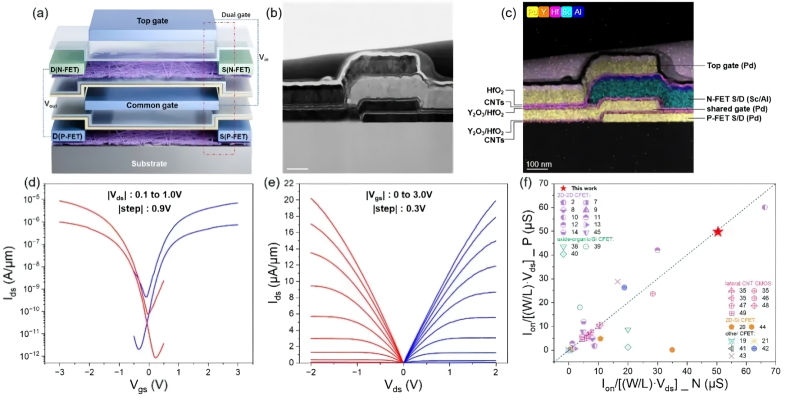
Пятёрка американских техногигантов накопила скрытых долгов на сумму $1,65 трлн на фоне бума ИИСделки с кольцевым финансированием, как отмечает Nikkei Asian Review, являются отнюдь не главной проблемой современной ИИ-отрасли. Техногиганты в условиях бума систем искусственного интеллекта так много заимствуют на развитие вычислительной инфраструктуры, что не вся часть долговых обязательств отображается в бухгалтерской отчётности. Пятёрка американских лидеров отрасли, например, уже накопила долгов на $1,65 трлн. Microsoft по примеру конкурентов начала устанавливать серверные системы AMD Helios в своей облачной инфраструктуре AzureКомпания Nvidia уже давно при поддержке своих подрядчиков поставляет клиентам готовые серверные системы, поэтому у конкурирующей AMD не оставалось иного выбора, кроме как последовать её примеру с системами семейства Helios. К числу покупателей этих систем недавно примкнула Microsoft по примеру Meta✴✴, OpenAI и Oracle. В США задумались о запрете китайских открытых ИИ-моделей, включая нашумевшую Kimi K3Появление китайской открытой языковой модели Kimi K3 с открытыми весами (open-weight) от Moonshot спровоцировало новую волну дискуссий в США о будущем открытых ИИ-моделей и возможных ограничениях на их использование. Обсуждение затронуло как интересы американских разработчиков искусственного интеллекта, так и вопросы технологической конкуренции с Китаем. В России создали электронно-лучевой литограф для печати чипов эпохи Pentium 4Зеленоградский нанотехнологический центр (ЗНТЦ) создал установку электронно-лучевой литографии (ЭЛЛ) для изготовления фотошаблонов и формирования рисунка на подложках без использования масок по нормам 150 нм, пишет CNews. Об этом стало известно из документов, согласно которым ЗНТЦ ищет перевозчика для доставки «опытного образца установки электронно-лучевой литографии с проектными нормами 150 нм» в рамках ОКР «Прогресс ЭЛЛ 150». Тодд Говард признался, что ворует идеи с RedditТворческий руководитель и исполнительный продюсер Bethesda Game Studios Тодд Говард (Todd Howard) по случаю недавних анонсов от студии решил выйти на связь с игровым сообществом форума Reddit. «Орден нуждается в вас как никогда»: GamesVoice открыла сбор средств на русскую озвучку Assassin’s Creed Black Flag ResyncedВ отличие от оригинальной Assassin’s Creed IV: Black Flag, вышедший недавно ремейк остался без полноценной русской локализации, и в российской студии GamesVoice намерены исправить эту несправедливость. Евросоюз оштрафовал Alibaba на рекордные €550 млн за торговлю запрещёнкой и контрафактомЭлектронный коммерческий сервис Alibaba Group Holding оштрафован Евросоюзом на €550 млн, что стало крупнейшим штрафом в рамках правил ЕС по модерации контента. По словам Еврокомиссии, торговая площадка не смогла должным образом оценить небезопасные или контрафактные товары, продаваемые на платформе, и не предприняла шагов для обеспечения соблюдения политики штрафов в отношении продавцов, которые неоднократно её нарушали. Ubisoft компенсирует задержку новых Assassin’s Creed, Far Cry и Ghost Recon переизданиями старых игр, включая Watch Dogs: Legion и Ghost Recon WildlandsВслед за Tom Clancy’s The Division Definitive Edition французский издатель и разработчик Ubisoft, похоже, намерен выпустить в 2026 году полные издания ещё нескольких своих старых игр. Запущена вторая партия спутников для отечественного аналог SpaceX StarlinkРоссийская аэрокосмическая компания «Бюро 1440» (входит в ИКС холдинг) объявила об успешном запуске в космос второй партии спутников в рамках развёртывание низкоорбитальной спутниковой группировки для предоставления услуг связи нового поколения. Айфоноподобный смартфон Vivo X300 E с оптикой Zeiss и батареей на 7200 мА·ч поступит в продажу через неделюVivo объявила о предстоящем выходе смартфона Vivo X300 E, который поступит в продажу в Китае на следующей неделе, 27 июля. Компания также раскрыла его дизайн и сообщила некоторые ключевые характеристики. На данный момент на новинку уже открыт предзаказ. Китайская ИИ-модель Kimi K3 оказалась настолько популярной, что разработчик перестал принимать новых пользователейОчередная волна интереса к китайским ИИ-моделям с открытым кодом привела к тому, что стартап Moonshot AI быстро исчерпал доступные вычислительные мощности, необходимые для обслуживания подписчиков новой модели Kimi K3. Компания была вынуждена приостановить предоставление доступа к этой модели для новых подписчиков, пока не сможет привлечь дополнительные мощности. Спустя 10 месяцев радиомолчания Valve заверила фанатов Team Fortress 2, что всё ещё работает над крупным обновлением для «Манн против машин»Спустя почти 19 лет после релиза крупные обновления условно-бесплатного командного шутера Team Fortress 2 — на вес золота. Valve больше года назад анонсировала планы на новый патч для игры, однако не спешит исполнять обещание. Амбициозная вампирская ролевая игра The Blood of Dawnwalker от ведущих разработчиков The Witcher 3 и Cyberpunk 2077 выйдет без DenuvoИспользование антипиратской защиты Denuvo уже стало стандартом для новых игровых блокбастеров, однако как минимум один крупный релиз 2026 года обойдётся на выходе без противоречивого механизма. Широкоформатный Galaxy Z Fold8 станет самым популярным среди новых складных смартфонов SamsungПриближение анонса новой серии складных смартфонов Samsung Galaxy Z насыщает новостные ленты новыми данными об этих устройствах. Предвосхищая появление на рынке первого в истории Apple складного iPhone, которому приписывается специфическое соотношение сторон, Samsung пытается опередить конкурента со своим широкоформатным Galaxy Z Fold8, рассчитывая на его высокую популярность в рознице. Борьба с дефицитом DRAM может обернуться перенасыщением рынка уже через пару летПроизводители микросхем памяти, которые вкладывают в расширение собственных мощностей сотни миллиардов долларов, склонны успокаивать инвесторов по поводу вероятности очередного спада спроса аргументами из разряда исчезновения цикличности рынка. Некоторые эксперты предупреждают, что в сегменте классической DRAM признаки перепроизводства могут возникнуть уже в 2028 году. Electronic Arts пятый раз подряд угадала победителя Чемпионата мира по футболуИсход прошедшего в ночь на 20 июля финала Чемпионата мира по футболу 2026 года стал сюрпризом для многих болельщиков, однако американский издатель и разработчик Electronic Arts знал результат ещё до старта турнира. Прежде чем похоронить семейство Mac Pro, компания Apple рассматривала возможность оснащения этих ПК процессорами IntelВ конце марта текущего года Apple объявила о снятии с производства Mac Pro — мощного настольного ПК, который в последние годы оснащался процессорами разработки Intel, но в свете перехода компании на собственную компонентную базу более не вписывался в стратегические планы производителя. Как выясняется, Apple всё же надеялась создать подходящие для Mac Pro собственные процессоры, а в качестве резервного плана рассматривала использование чипов Intel. TSMC признаёт, что потратить ещё $100 млрд на заводы в США её заставляет конкуренцияНа прошлой неделе руководство TSMC неожиданно заявило о готовности увеличить капитальные затраты в США с $165 до $265 млрд, подтвердив намерения построить в Аризоне ещё четыре предприятия по производству чипов, а также освоить на территории США выпуск 2-нм и более прогрессивных компонентов. Финансовый директор компании признался, что это решение, помимо прочего, продиктовано усилением конкуренции. Alibaba анонсировала 2,4-триллионную ИИ-модель Qwen3.8 и пообещала открыть её весаКомпания Alibaba анонсировала новое поколение своей флагманской языковой модели — Qwen3.8. По словам разработчиков, модель насчитывает 2,4 трлн параметров, поддерживает мультимодальную обработку данных и по общей производительности уступает лишь Claude Fable 5 от Anthropic. Пока, впрочем, речь идёт исключительно о собственных оценках Alibaba: результаты независимых тестов ещё не опубликованы. OpenAI признала, что GPT-5.6 иногда удаляет файлы пользователей, но это «честная ошибка»OpenAI подтвердила сообщения о том, что флагманская ИИ-модель GPT-5.6 способна удалять файлы пользователей без разрешения. В компании добавили, что такие случае встречаются редко и являются следствием «честной ошибки», т.е. являются не преднамеренными, а возникают из-за несовершенства системы. Видеокарты Nvidia умеют показывать температуру каждого чипа памяти по отдельности — энтузиасты нашли доступИстория со скрытыми температурными датчиками в видеокартах Nvidia получила продолжение. После того как энтузиасты вернули возможность считывать температуру Hotspot у GPU поколения Blackwell, бразильская команда Paulo Gomes Team обнаружила ещё одну скрытую функцию. Оказалось, что графические процессоры Nvidia способны передавать температуру каждого отдельного чипа памяти GDDR6 и GDDR6X, а не только максимальное значение, которое отображают современные утилиты мониторинга. Видеокарты GeForce RTX 50 вновь научились показывать температуру Hotspot, хотя Nvidia скрывала этот датчикУтилита HWMonitor версии 1.65 вернула владельцам видеокарт GeForce RTX 50 возможность отслеживать температуру Hotspot — самой горячей точки графического процессора. Примечательно, что Nvidia никогда не убирала соответствующий датчик из GPU Blackwell: как выяснилось недавно, компания лишь заблокировала доступ к его показаниям для сторонних приложений. Продажи Steam Machine оказались лучше ожиданий — до 15 тыс. штук в неделюКогда в конце июня Valve наконец запустила свой компактный игровой компьютер Steam Machine, многие сомневались в успехе этого продукта из-за высокой стоимости. Однако на деле оказалось, что продажи новинки идут неплохо. По данным ресурса Boiling Steam, вендор продаёт от 12 тыс. до 15. тыс. Steam Machine в неделю. Инсайдер раскрыл особенности смарт-часов Samsung Galaxy Watch 9 в преддверии презентацииВ Сети появилась новая информация о грядущих смарт-часах Samsung Galaxy Watch 9, опубликованная известным инсайдером Эваном Блассом (Evan Blass, @evleaks), поделившегося за день до этого утекшими фото складных смартфонов Samsung Galaxy Z Fold8, Galaxy Z Flip8 и Galaxy Z Fold8 Ultra. Презентация новинок состоится 22 июля на мероприятии Galaxy Unpacked. Honor открыла предзаказы на Robot Phone — смартфон с роботизированной 200-Мп камерой на подвесеКомпания Honor официально открыла предварительные заказы на покупку смартфона Robot Phone, начало продаж которого запланировано на август. Для повышения интереса к этому необычному устройству вендор подчеркнул несколько ключевых аппаратных особенностей устройства и функций на базе искусственного интеллекта, делающих новинку одним из самых амбициозных проектов Honor. США задним числом запретят гаджеты «подставных» брендов DJIВ октябре прошлого года Федеральная комиссия по связи (FCC) США наделила себя полномочиями задним числом запрещать гаджеты, которые ранее получили разрешения на ввоз и продажу в стране. Теперь комиссия готовится впервые применить эти полномочия и пресечь деятельность «подставных компаний DJI», через которые китайский производитель, как предполагается, обходит запрет на ввоз своих дронов в США. Внутри Cybercab нашли антенну Starlink, хотя автопилоту Tesla интернет вроде бы не нуженКак известно, компания Tesla свою фирменную технологию автопилота FSD делает независимой от точных цифровых карт местности, позволяя автоматике полагаться на изображения с бортовых камер, обрабатываемых нейронными сетями. Илон Маск (Elon Musk) в этом смысле считает нужным ориентироваться на устройство человеческой системы зрения. При этом в роботакси Cybercab предусмотрена антенна спутникового интернета Starlink. GeForce RTX 5050, терабайтный SSD и DDR4: в «М.Видео» рассказали, какие комплектующие россияне чаще выбирают для сборки ПКВ «М.Видео» раскрыли результаты анализа первых заказов пользователей новой услуги по профессиональной сборке персональных компьютеров, которую компания запустила в июне 2026 года. Как показала аналитика, при сборке ПК пользователи из комплектующих отдают предпочтение современным видеокартам Nvidia GeForce RTX 50-й серии, процессорам AMD Ryzen 5 и Intel Core i5, а также быстрым NVMe SSD объёмом от 1 Тбайт. Эпидемия отмены запусков перекинулась на ракеты Falcon 9 — SpaceX о причинах молчитВчера во время запуска очередной партии спутников Starlink на Falcon 9 старт был отменён за мгновение до отрыва ракеты от стартового стола. Произошёл редчайший в практике запусков случай, когда все девять двигателей ракеты одновременно зажглись и мгновение спустя погасли. Компания прервала трансляцию и не объяснила причины отмены. Нечто подобное неделей ранее произошло с ракетой Starship. Китайские власти задумались об усилении экспортного контроля в сфере ИИ-моделей и чиповВ противостоянии КНР и США одни и те же идеи посещают умы правителей практически синхронно. Стоило представителям американской ИИ-отрасли высказаться о введении ограничений на доступ к китайским разработкам, как на страницах Financial Times появилась публикация о намерениях властей КНР усилить контроль за экспортом ИИ-моделей и передовых чипов. Пятёрка американских техногигантов накопила скрытых долгов на сумму $1,65 трлн на фоне бума ИИСделки с кольцевым финансированием, как отмечает Nikkei Asian Review, являются отнюдь не главной проблемой современной ИИ-отрасли. Техногиганты в условиях бума систем искусственного интеллекта так много заимствуют на развитие вычислительной инфраструктуры, что не вся часть долговых обязательств отображается в бухгалтерской отчётности. Пятёрка американских лидеров отрасли, например, уже накопила долгов на $1,65 трлн. Microsoft по примеру конкурентов начала устанавливать серверные системы AMD Helios в своей облачной инфраструктуре AzureКомпания Nvidia уже давно при поддержке своих подрядчиков поставляет клиентам готовые серверные системы, поэтому у конкурирующей AMD не оставалось иного выбора, кроме как последовать её примеру с системами семейства Helios. К числу покупателей этих систем недавно примкнула Microsoft по примеру Meta✴✴, OpenAI и Oracle. Intel начала новый этап сокращений сотрудников в серверном подразделенииIntel приступила к новой волне сокращений, затронувшей подразделение центров обработки данных (Data Center Group), отвечающее за серверные процессоры, специализированные ИИ-чипы и архитектуру дата-центров. Компания ожидает, что изменения позволят повысить эффективность и упростить внутренние процессы. Бывшего менеджера TSMC обвинили в краже секретов производства микросхем для КитаяВ понедельник прокуратура Тайваня предъявила обвинение бывшему заместителю директора TSMC в предполагаемом копировании 21 конфиденциального документа с целью их использования в Китае. Некоторые документы касаются технологий, признанных Тайванем ключевыми национальными технологиями. В России создали электронно-лучевой литограф для печати чипов эпохи Pentium 4Зеленоградский нанотехнологический центр (ЗНТЦ) создал установку электронно-лучевой литографии (ЭЛЛ) для изготовления фотошаблонов и формирования рисунка на подложках без использования масок по нормам 150 нм, пишет CNews. Об этом стало известно из документов, согласно которым ЗНТЦ ищет перевозчика для доставки «опытного образца установки электронно-лучевой литографии с проектными нормами 150 нм» в рамках ОКР «Прогресс ЭЛЛ 150». Новая статья: CFET: быстрее, меньше, надёжнейТехнологии производства классических полупроводниковых транзисторов развиваются ничуть не менее стремительно, чем принципиально новые вычислительные средства на основе фотоники, спинтроники и т. д.Z.AI построила крупнейший дата-центр для ИИ исключительно на китайских чипахКомпания Z.AI, один из ведущих китайских разработчиков систем искусственного интеллекта, завершила строительство крупного дата-центра, полностью оснащённого чипами китайского производства. Новый вычислительный комплекс предназначен для обучения моделей семейства GLM и по сути стал очередным шагом страны по снижению зависимости от продукции Nvidia. Google разрабатывает чип Frozen v2, на котором модели Gemini смогут работать эффективнееСогласно появившейся инсайдерской информации, Google в настоящее время разрабатывает серверный чип, который будет поддерживать элементы модели Gemini на аппаратном уровне. Компания ожидает, что этот чип с неофициальным названием Frozen v2 поможет решить проблему нехватки вычислительных мощностей для ИИ, которая вызвала внутренние разногласия и заставила Google Cloud отказаться от сделок с внешними клиентами. Акции компании в начале торгов выросли на 3,3 %. Китайская CXMT начала тестировать чипы LPDDR6 — запуск массового производства запланирован на второе полугодиеКитайская компания CXMT (ChangXin Memory Technologies) ускоряет реализацию своей дорожной карты по разработке памяти следующего поколения, пишет Gizmochina. Сообщается, что компания начала тестирование своих чипов LPDDR6, а также готовит производственную цепочку поставок задолго до коммерческого появления памяти DDR6. Скоро появятся ноутбуки со сверхъяркими экранами Tandem OLED — Samsung начала массовые поставкиКомпания Samsung Display начала массовые поставки своих новых Tandem OLED-панелей для ноутбуков. Они поддерживают стандарт VESA DisplayHDR True Black 1400 и могут достигать яркости 1600 кд/м2. Компания Lenovo одной из первых получила сертификат соответствия для ноутбука, использующего эту технологию. Свои собственные продукты с этими панелями также готовят компании Asus, Dell Technologies и MSI. Запущена вторая партия спутников для отечественного аналог SpaceX StarlinkРоссийская аэрокосмическая компания «Бюро 1440» (входит в ИКС холдинг) объявила об успешном запуске в космос второй партии спутников в рамках развёртывание низкоорбитальной спутниковой группировки для предоставления услуг связи нового поколения. Айфоноподобный смартфон Vivo X300 E с оптикой Zeiss и батареей на 7200 мА·ч поступит в продажу через неделюVivo объявила о предстоящем выходе смартфона Vivo X300 E, который поступит в продажу в Китае на следующей неделе, 27 июля. Компания также раскрыла его дизайн и сообщила некоторые ключевые характеристики. На данный момент на новинку уже открыт предзаказ. NASA показало завораживающий таймлапс Марса, снятый зондом «Психея»Космический аппарат Национального управления по аэронавтике и исследованию космического пространства (NASA) США «Психея» (Psyche) благополучно движется к своей цели в поясе астероидов вблизи Юпитера. В мае зонд облетел Марс по орбите планеты для получения гравитационного ускорения. Теперь же аэрокосмическое агентство опубликовало таймлапс-видео, которое было создано из снимков, сделанных во время сближения с Красной планетой. Xiaomi тоже готовит широкоформатный складной смартфон: Mix Fold 5 показался на фотоПо всей видимости, изображения следующего складного смартфона Xiaomi появились в интернете задолго до официального анонса устройства. На опубликованных недавно снимках, как предполагается, изображён Xiaomi Mix Fold 5 (или Mix Fold 6), который работает под управлением программного обеспечения следующего поколения. GameStop не оставляет попыток купить eBay и уже поглотила её десятую частьВ мае этого года американская торговая сеть GameStop предложила $56 млрд за активы интернет-аукциона eBay, но получила отказ от руководства последнего, хотя и не опустила после этого руки. Сейчас GameStop уже владеет 10 % акций eBay и предпринимает другие шаги, направленные на реализацию сделки даже вопреки позиции руководства eBay. В России рухнули продажи ноутбуков на 20 % — всему виной рост ценВ первом полугодии 2026 года продажи ноутбуков в России сократились год к году на 19,6 % в штучном и на 13,5 % в денежном выражении. При этом средняя стоимость ноутбука выросла за год на 17,3 %, до 66 921 рубля, сообщил Forbes со ссылкой на источник на рынке бытовой техники и электроники. Широкоформатный Galaxy Z Fold8 станет самым популярным среди новых складных смартфонов SamsungПриближение анонса новой серии складных смартфонов Samsung Galaxy Z насыщает новостные ленты новыми данными об этих устройствах. Предвосхищая появление на рынке первого в истории Apple складного iPhone, которому приписывается специфическое соотношение сторон, Samsung пытается опередить конкурента со своим широкоформатным Galaxy Z Fold8, рассчитывая на его высокую популярность в рознице. Борьба с дефицитом DRAM может обернуться перенасыщением рынка уже через пару летПроизводители микросхем памяти, которые вкладывают в расширение собственных мощностей сотни миллиардов долларов, склонны успокаивать инвесторов по поводу вероятности очередного спада спроса аргументами из разряда исчезновения цикличности рынка. Некоторые эксперты предупреждают, что в сегменте классической DRAM признаки перепроизводства могут возникнуть уже в 2028 году. Прежде чем похоронить семейство Mac Pro, компания Apple рассматривала возможность оснащения этих ПК процессорами IntelВ конце марта текущего года Apple объявила о снятии с производства Mac Pro — мощного настольного ПК, который в последние годы оснащался процессорами разработки Intel, но в свете перехода компании на собственную компонентную базу более не вписывался в стратегические планы производителя. Как выясняется, Apple всё же надеялась создать подходящие для Mac Pro собственные процессоры, а в качестве резервного плана рассматривала использование чипов Intel. Следующий тестовый полёт SpaceX Starship назначен на четвергВ конце прошлой недели SpaceX пришлось отложить 13-й тестовый запуск ракеты Starship, которая в своей обновлённой версии V3 пока успела осуществить только один испытательный полёт. Первоначально Илон Маск (Elon Musk) заявил, что новую попытку запустить Starship V3 компания предпримет в начале этой недели, но позднее поправился, что она намечена на четверг 23 июля. «Кронус вновь будет наш»: новый трейлер Warhammer 40,000: Dawn of War 4 показал возвращение некроновИздательство Deep Silver и разработчики из немецкой студии King Art Games (Iron Harvest) представили кинематографический трейлер третьей из четырёх фракций в амбициозной стратегии Warhammer 40,000: Dawn of War 4 — некронов. РТК-ЦОД запустил облачный мониторинг качества каналов связи для 20 тысяч объектов заказчиков «Ростелекома»РТК-ЦОД, ведущий ИТ-сервис-провайдер полного цикла, внедрил единую систему мониторинга для контроля качества каналов связи, предоставляемых «Ростелекомом» государственным заказчикам. Решение охватывает порядка 20 тысяч объектов, расположенных во всех регионах России. Система мониторинга построена на базе платформы Smart Control, разработанной в РТК-ЦОД. Anthropic выплатит авторам $1,5 млрд за «пиратскую библиотеку» для обучения ClaudeСудья в Сан-Франциско одобрила мировое соглашение разработчика систем искусственного интеллекта Anthropic на сумму $1,5 млрд по коллективному иску, поданному группой писателей, которые обвинили компанию в неправомерном использовании их книг при обучении чат-бота Claude. Слухи: многострадальный ремейк Star Wars: Knights of the Old Republic скоро выйдет из тениМногострадальный ремейк знаковой ролевой игры Star Wars: Knights of the Old Republic от BioWare спустя пять лет после официального анонса, похоже, наконец готовится к следующей презентации. Activision подтвердила, когда пройдёт открытая «бета» Call of Duty: Modern Warfare 4 — подробности тестированияГорячо ожидаемый военный шутер Call of Duty: Modern Warfare 4 запланирован на осень, но попробовать его можно будет уже летом. Издатель Activision и разработчики из Infinity Ward раскрыли сроки проведения бета-тестирования игры. ИИ-трафик на сайты СМИ и электронной коммерции удвоилсяТрафик ботов с искусственным интеллектом на сайты СМИ и площадок электронной коммерции вырос вдвое — до 2 % от общего объёма, передаёт «Коммерсантъ» со ссылкой на данные Servicepipe. Этот контент хорошо подходит для обучения ИИ, но тенденция грозит сокращением органического трафика, а также копированием контента и ассортимента, говорят эксперты. Apple за полгода опубликовала в App Store почти столько же приложений, сколько за весь 2025 год — во всем «винят» вайб-кодингРост доступности инструментов вайб-кодинга привёл к удвоению числа новых приложений в App Store за первое полугодие 2026 года. При этом объём загрузок приложений увеличился незначительно, свидетельствуя об отсутствии пропорционального интереса со стороны пользователей. В США задумались о запрете китайских открытых ИИ-моделей, включая нашумевшую Kimi K3Появление китайской открытой языковой модели Kimi K3 с открытыми весами (open-weight) от Moonshot спровоцировало новую волну дискуссий в США о будущем открытых ИИ-моделей и возможных ограничениях на их использование. Обсуждение затронуло как интересы американских разработчиков искусственного интеллекта, так и вопросы технологической конкуренции с Китаем. В популярном архиваторе 7-Zip нашли опасную лазейку для вирусов — обновиться придётся вручнуюВ архиваторе 7-Zip для Windows обнаружили уязвимость, позволяющую злоумышленникам выполнять вредоносный код при открытии специально подготовленного файла или посещении вредоносной веб-страницы. Исправление уже вошло в обновление, однако пользователям необходимо установить его вручную, сообщает PCMag. Календарь релизов — 20–26 июля: ZeroSpace, Avatar Legends: The Fighting Game и Scarlet Deer InnЭта неделя порадует сразу несколькими громкими релизами в игровой сфере. Отличная неделя как для поклонников крупных франшиз, так и для тех, кто ищет свежие игры. YouTube оставит ИИ-контент без монетизации — названы три категории видео, которые больше не будут приносить доходПлатформа YouTube разъяснила правила монетизации контента, созданного с использованием искусственного интеллекта, выделив три категории неоригинальных, сгенерированных нейросетями видеороликов, которые не смогут приносить доход в рамках программы YouTube Partner Program (YPP). Тодд Говард признался, что ворует идеи с RedditТворческий руководитель и исполнительный продюсер Bethesda Game Studios Тодд Говард (Todd Howard) по случаю недавних анонсов от студии решил выйти на связь с игровым сообществом форума Reddit. Приложение камеры Adobe Project Indigo получило набор генеративных фильтров и научилось удалять лишние объектыВ прошлом году Adobe представила экспериментальное приложение камеры для iPhone под названием Project Indigo, которое, по словам разработчика, было призвано обеспечить «более естественный (похожий на зеркальную камеру) вид» фотографий, сделанных на смартфон. Теперь приложение обновляется набором инструментов генеративного ИИ, причём это изменение не основано на собственных моделях ИИ Firefly от Adobe. «Орден нуждается в вас как никогда»: GamesVoice открыла сбор средств на русскую озвучку Assassin’s Creed Black Flag ResyncedВ отличие от оригинальной Assassin’s Creed IV: Black Flag, вышедший недавно ремейк остался без полноценной русской локализации, и в российской студии GamesVoice намерены исправить эту несправедливость. The Life and Suffering of Prince Jerian от экс-разработчиков «Жизни и страданий господина Бранте» стартовала в Steam с «очень положительными» отзывамиКак и было обещано, 20 июля состоялся релиз сюжетной ролевой игры The Life and Suffering of Prince Jerian от основанной экс-разработчиками The Life and Suffering of Sir Brante российской студии Schisma Games и издателя 101XP. Евросоюз оштрафовал Alibaba на рекордные €550 млн за торговлю запрещёнкой и контрафактомЭлектронный коммерческий сервис Alibaba Group Holding оштрафован Евросоюзом на €550 млн, что стало крупнейшим штрафом в рамках правил ЕС по модерации контента. По словам Еврокомиссии, торговая площадка не смогла должным образом оценить небезопасные или контрафактные товары, продаваемые на платформе, и не предприняла шагов для обеспечения соблюдения политики штрафов в отношении продавцов, которые неоднократно её нарушали. Ubisoft компенсирует задержку новых Assassin’s Creed, Far Cry и Ghost Recon переизданиями старых игр, включая Watch Dogs: Legion и Ghost Recon WildlandsВслед за Tom Clancy’s The Division Definitive Edition французский издатель и разработчик Ubisoft, похоже, намерен выпустить в 2026 году полные издания ещё нескольких своих старых игр. Россияне сегодня столкнулись с недоступностью Apple App Store — «Роскомнадзор» заявил, что ни при чёмВ связи с поступающими жалобами владельцев гаджетов Apple на сбои в работе App Store Роскомнадзор отметил, что никаких действий по ограничению доступа к магазину приложений американской компании в России он не предпринимал. «Команда Doom наполовину на месте, а наполовину выброшена»: из id Software уволили две трети разработчиков Doom (2016)Недавние высказывания главы разработки Doom: The Dark Ages Хьюго Мартина (Hugo Martin) относительно прокатившейся по id Software волны массовых увольнений разозлили бывших и нынешних сотрудников студии. Авторитетный инсайдер: руководители студий Xbox «абсолютно ненавидят» Game Pass, потому что сервис обесценивает игрыСервис Game Pass, за фиксированную плату предоставляющий доступ к широкой библиотеке инди-игр и блокбастеров, стал большим хитом среди геймеров, однако не пользуется популярностью среди студий самой Xbox. Компании начали проверять кандидатов на дипфейки — хакеры с ИИ всё чаще подсовывают «синтетических сотрудников»По мере распространения технологий генеративного искусственного интеллекта растут не только внешние угрозы в сфере кибербезопасности, но и внутренние. Компании, которые исторически полагались на традиционные методы защиты от кибератак изнутри, теперь вынуждены сталкиваться с новыми вызовами, которые возникли благодаря распространению технологий ИИ. Китайская ИИ-модель Kimi K3 оказалась настолько популярной, что разработчик перестал принимать новых пользователейОчередная волна интереса к китайским ИИ-моделям с открытым кодом привела к тому, что стартап Moonshot AI быстро исчерпал доступные вычислительные мощности, необходимые для обслуживания подписчиков новой модели Kimi K3. Компания была вынуждена приостановить предоставление доступа к этой модели для новых подписчиков, пока не сможет привлечь дополнительные мощности. Олдскульная боевая гонка Fumes получила кооператив на 250 игроков, но для него нужен «компьютер NASA»Бороздящая бескрайние пустоши раннего доступа Steam олдскульная боевая гоночная аркада Fumes от разработчиков из польской команды Fumes Team получила на удивление масштабный кооперативный режим. Спустя 10 месяцев радиомолчания Valve заверила фанатов Team Fortress 2, что всё ещё работает над крупным обновлением для «Манн против машин»Спустя почти 19 лет после релиза крупные обновления условно-бесплатного командного шутера Team Fortress 2 — на вес золота. Valve больше года назад анонсировала планы на новый патч для игры, однако не спешит исполнять обещание. Амбициозная вампирская ролевая игра The Blood of Dawnwalker от ведущих разработчиков The Witcher 3 и Cyberpunk 2077 выйдет без DenuvoИспользование антипиратской защиты Denuvo уже стало стандартом для новых игровых блокбастеров, однако как минимум один крупный релиз 2026 года обойдётся на выходе без противоречивого механизма. «Кронус вновь будет наш»: новый трейлер Warhammer 40,000: Dawn of War 4 показал возвращение некроновИздательство Deep Silver и разработчики из немецкой студии King Art Games (Iron Harvest) представили кинематографический трейлер третьей из четырёх фракций в амбициозной стратегии Warhammer 40,000: Dawn of War 4 — некронов. РТК-ЦОД запустил облачный мониторинг качества каналов связи для 20 тысяч объектов заказчиков «Ростелекома»РТК-ЦОД, ведущий ИТ-сервис-провайдер полного цикла, внедрил единую систему мониторинга для контроля качества каналов связи, предоставляемых «Ростелекомом» государственным заказчикам. Решение охватывает порядка 20 тысяч объектов, расположенных во всех регионах России. Система мониторинга построена на базе платформы Smart Control, разработанной в РТК-ЦОД. США задним числом запретят гаджеты «подставных» брендов DJIВ октябре прошлого года Федеральная комиссия по связи (FCC) США наделила себя полномочиями задним числом запрещать гаджеты, которые ранее получили разрешения на ввоз и продажу в стране. Теперь комиссия готовится впервые применить эти полномочия и пресечь деятельность «подставных компаний DJI», через которые китайский производитель, как предполагается, обходит запрет на ввоз своих дронов в США. Anthropic выплатит авторам $1,5 млрд за «пиратскую библиотеку» для обучения ClaudeСудья в Сан-Франциско одобрила мировое соглашение разработчика систем искусственного интеллекта Anthropic на сумму $1,5 млрд по коллективному иску, поданному группой писателей, которые обвинили компанию в неправомерном использовании их книг при обучении чат-бота Claude. Внутри Cybercab нашли антенну Starlink, хотя автопилоту Tesla интернет вроде бы не нуженКак известно, компания Tesla свою фирменную технологию автопилота FSD делает независимой от точных цифровых карт местности, позволяя автоматике полагаться на изображения с бортовых камер, обрабатываемых нейронными сетями. Илон Маск (Elon Musk) в этом смысле считает нужным ориентироваться на устройство человеческой системы зрения. При этом в роботакси Cybercab предусмотрена антенна спутникового интернета Starlink. GeForce RTX 5050, терабайтный SSD и DDR4: в «М.Видео» рассказали, какие комплектующие россияне чаще выбирают для сборки ПКВ «М.Видео» раскрыли результаты анализа первых заказов пользователей новой услуги по профессиональной сборке персональных компьютеров, которую компания запустила в июне 2026 года. Как показала аналитика, при сборке ПК пользователи из комплектующих отдают предпочтение современным видеокартам Nvidia GeForce RTX 50-й серии, процессорам AMD Ryzen 5 и Intel Core i5, а также быстрым NVMe SSD объёмом от 1 Тбайт. Слухи: многострадальный ремейк Star Wars: Knights of the Old Republic скоро выйдет из тениМногострадальный ремейк знаковой ролевой игры Star Wars: Knights of the Old Republic от BioWare спустя пять лет после официального анонса, похоже, наконец готовится к следующей презентации. Эпидемия отмены запусков перекинулась на ракеты Falcon 9 — SpaceX о причинах молчитВчера во время запуска очередной партии спутников Starlink на Falcon 9 старт был отменён за мгновение до отрыва ракеты от стартового стола. Произошёл редчайший в практике запусков случай, когда все девять двигателей ракеты одновременно зажглись и мгновение спустя погасли. Компания прервала трансляцию и не объяснила причины отмены. Нечто подобное неделей ранее произошло с ракетой Starship. Китайские власти задумались об усилении экспортного контроля в сфере ИИ-моделей и чиповВ противостоянии КНР и США одни и те же идеи посещают умы правителей практически синхронно. Стоило представителям американской ИИ-отрасли высказаться о введении ограничений на доступ к китайским разработкам, как на страницах Financial Times появилась публикация о намерениях властей КНР усилить контроль за экспортом ИИ-моделей и передовых чипов. Activision подтвердила, когда пройдёт открытая «бета» Call of Duty: Modern Warfare 4 — подробности тестированияГорячо ожидаемый военный шутер Call of Duty: Modern Warfare 4 запланирован на осень, но попробовать его можно будет уже летом. Издатель Activision и разработчики из Infinity Ward раскрыли сроки проведения бета-тестирования игры. ИИ-трафик на сайты СМИ и электронной коммерции удвоилсяТрафик ботов с искусственным интеллектом на сайты СМИ и площадок электронной коммерции вырос вдвое — до 2 % от общего объёма, передаёт «Коммерсантъ» со ссылкой на данные Servicepipe. Этот контент хорошо подходит для обучения ИИ, но тенденция грозит сокращением органического трафика, а также копированием контента и ассортимента, говорят эксперты. Пятёрка американских техногигантов накопила скрытых долгов на сумму $1,65 трлн на фоне бума ИИСделки с кольцевым финансированием, как отмечает Nikkei Asian Review, являются отнюдь не главной проблемой современной ИИ-отрасли. Техногиганты в условиях бума систем искусственного интеллекта так много заимствуют на развитие вычислительной инфраструктуры, что не вся часть долговых обязательств отображается в бухгалтерской отчётности. Пятёрка американских лидеров отрасли, например, уже накопила долгов на $1,65 трлн. Microsoft по примеру конкурентов начала устанавливать серверные системы AMD Helios в своей облачной инфраструктуре AzureКомпания Nvidia уже давно при поддержке своих подрядчиков поставляет клиентам готовые серверные системы, поэтому у конкурирующей AMD не оставалось иного выбора, кроме как последовать её примеру с системами семейства Helios. К числу покупателей этих систем недавно примкнула Microsoft по примеру Meta✴✴, OpenAI и Oracle. Intel начала новый этап сокращений сотрудников в серверном подразделенииIntel приступила к новой волне сокращений, затронувшей подразделение центров обработки данных (Data Center Group), отвечающее за серверные процессоры, специализированные ИИ-чипы и архитектуру дата-центров. Компания ожидает, что изменения позволят повысить эффективность и упростить внутренние процессы. Apple за полгода опубликовала в App Store почти столько же приложений, сколько за весь 2025 год — во всем «винят» вайб-кодингРост доступности инструментов вайб-кодинга привёл к удвоению числа новых приложений в App Store за первое полугодие 2026 года. При этом объём загрузок приложений увеличился незначительно, свидетельствуя об отсутствии пропорционального интереса со стороны пользователей. В США задумались о запрете китайских открытых ИИ-моделей, включая нашумевшую Kimi K3Появление китайской открытой языковой модели Kimi K3 с открытыми весами (open-weight) от Moonshot спровоцировало новую волну дискуссий в США о будущем открытых ИИ-моделей и возможных ограничениях на их использование. Обсуждение затронуло как интересы американских разработчиков искусственного интеллекта, так и вопросы технологической конкуренции с Китаем. Бывшего менеджера TSMC обвинили в краже секретов производства микросхем для КитаяВ понедельник прокуратура Тайваня предъявила обвинение бывшему заместителю директора TSMC в предполагаемом копировании 21 конфиденциального документа с целью их использования в Китае. Некоторые документы касаются технологий, признанных Тайванем ключевыми национальными технологиями. В популярном архиваторе 7-Zip нашли опасную лазейку для вирусов — обновиться придётся вручнуюВ архиваторе 7-Zip для Windows обнаружили уязвимость, позволяющую злоумышленникам выполнять вредоносный код при открытии специально подготовленного файла или посещении вредоносной веб-страницы. Исправление уже вошло в обновление, однако пользователям необходимо установить его вручную, сообщает PCMag. В России создали электронно-лучевой литограф для печати чипов эпохи Pentium 4Зеленоградский нанотехнологический центр (ЗНТЦ) создал установку электронно-лучевой литографии (ЭЛЛ) для изготовления фотошаблонов и формирования рисунка на подложках без использования масок по нормам 150 нм, пишет CNews. Об этом стало известно из документов, согласно которым ЗНТЦ ищет перевозчика для доставки «опытного образца установки электронно-лучевой литографии с проектными нормами 150 нм» в рамках ОКР «Прогресс ЭЛЛ 150». Новая статья: CFET: быстрее, меньше, надёжнейТехнологии производства классических полупроводниковых транзисторов развиваются ничуть не менее стремительно, чем принципиально новые вычислительные средства на основе фотоники, спинтроники и т. д.Календарь релизов — 20–26 июля: ZeroSpace, Avatar Legends: The Fighting Game и Scarlet Deer InnЭта неделя порадует сразу несколькими громкими релизами в игровой сфере. Отличная неделя как для поклонников крупных франшиз, так и для тех, кто ищет свежие игры. YouTube оставит ИИ-контент без монетизации — названы три категории видео, которые больше не будут приносить доходПлатформа YouTube разъяснила правила монетизации контента, созданного с использованием искусственного интеллекта, выделив три категории неоригинальных, сгенерированных нейросетями видеороликов, которые не смогут приносить доход в рамках программы YouTube Partner Program (YPP). Z.AI построила крупнейший дата-центр для ИИ исключительно на китайских чипахКомпания Z.AI, один из ведущих китайских разработчиков систем искусственного интеллекта, завершила строительство крупного дата-центра, полностью оснащённого чипами китайского производства. Новый вычислительный комплекс предназначен для обучения моделей семейства GLM и по сути стал очередным шагом страны по снижению зависимости от продукции Nvidia. Тодд Говард признался, что ворует идеи с RedditТворческий руководитель и исполнительный продюсер Bethesda Game Studios Тодд Говард (Todd Howard) по случаю недавних анонсов от студии решил выйти на связь с игровым сообществом форума Reddit. Microsoft внедрит новейшую платформу AMD Helios AI в облако AzureAMD объявила о расширении стратегического партнёрства с Microsoft, охватывающего ускорители, процессоры, сетевое оборудование и ПО на платформе Azure. AMD начнёт поставки Helios клиентам, включая Microsoft, во II половине 2026 года, но именно Microsoft первой среди «большой тройки» облаков публично заявила о массовом развёртывании новой платформы. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex