







 MWC 2018
MWC 2018 2018
2018 Computex
Computex
⇣ Содержание
|
Опрос
|
реклама
Самое интересное в новостях
Царь-чипы для царь-задач
Производственный цикл классических процессоров подразумевает в наши дни их массовое, десятками, литографирование на единой пластине-заготовке с последующим разрезанием той на отдельные чипы — и уже их упаковкой в корпуса с удобными контактами. Только потом готовые корпусированные процессоры (центральные, графические и тензорные) занимают свои места на монтажных платах вычислительных систем — которые, в свою очередь, могут объединяться на более высоком уровне, образуя двухсокетные (и более) серверы, многопроцессорные платформы виртуализации, компьютерные кластеры и т. д. Подход калифорнийского стартапа Cerebras Systems с этой точки зрения весьма оригинален: его вычислители-размером-в-заготовку (wafer scale engine, WSE), как и явствует из названия, занимают целиком вписанный в 300-мм пластину квадрат площадью 46 225 мм², т. е. 215×215 мм. На первый взгляд, решение представляется вполне здравым — как раз с точки зрения серверных приложений. Домашнему ПК такой монструозный процессор вряд ли пригодится, а вот для решения серьёзных задач отсутствие необходимости тратить время и ресурсы сперва на разрезание и упаковку чипов помельче, а затем на налаживание между теми (в пределах серверной стойки и/или кластера) высокоскоростных межсоединений — существенный плюс. Уже в первом поколении царь-чипы — изготовленные в августе 2019 г. по «16-нм» техпроцессу на TSMC микро(макро?)процессоры WSE-1 — содержали 1,2 трлн транзисторов, часть которых отводилась на формирование ячеек локального ОЗУ суммарной ёмкостью 18 Гбайт. Актуальные же ныне WSE-3 (март 2024-го, «5 нм») могут похвастать сразу 4 трлн транзисторов и 44 Гбайт быстрой интегрированной оперативки — SRAM. Более того, если бы 450-мм (18-дюймовые) в диаметре заготовки успели к настоящему времени сделаться новой базой для чипмейкерского производства (что могло произойти ещё в середине 2010-х, но TSMC, IBM и GlobalFoundries тогда не решились на столь радикальную смену стандарта, опасаясь сдать тем самым ещё больше козырей на руки и без того первенствовавшим в ту пору Intel и Samsung), производительность экстенсивно увеличенного до 450 мм по диагонали WSE-3 сразу взлетела бы в 2,25 раза: чтобы сделать такой процессор мощнее, его достаточно всего лишь укрупнить. 
«Что-что вы там называете процессорами? Вот это — процессор!» (Источник: Cerebras) Словом, перевод дата-центров на царь-чипы сулит, как представляется, одни сплошные выгоды. Отчего же даже сейчас, в начале 2026-го, разработки Cerebras применяют на деле лишь в нескольких суперкомпьютерах, в ряде ЦОДов, прежде всего американских, да ещё планируют использовать в перспективных дата-центрах на Аравийском полуострове? Отзыв стартапом заявки о выходе на публичные торги, который прежде намечался на конец 2025 г., тоже несколько настораживает, хотя и связан, по заявлению самой компании, лишь с задержкой одобрения регуляторами документов об IPO, а не с какими бы то ни было техническими трудностями. Возникает вопрос: а на самом ли деле потребность ИТ-рынка, и компаний-гиперскейлеров прежде всего, в царь-чипах на сегодня имеется, — и если да, то насколько она велика? Ведь поскольку именно заводчики крупнейших дата-центров заказывают сегодня музыку в глобальном чипмейкерском производстве (и как раз их готовность платить за нужные им микросхемы буквально любые деньги провоцирует небывалый взлёт цен на DRAM и NAND), они и должны первыми прийти к выводу, что процессоры размером в обрезанную до квадрата целиковую пластину-заготовку удобнее и выгоднее классических при решении важнейших прикладных задач. Тогда-то время царь-чипов и придёт по-настоящему. ⇡#Всем на завистьОдно из главных ограничений, с которыми приходится как-то справляться микроэлектронщикам, что развивают классическую для индустрии полупроводниковую фотолитографию, — физический лимит на предельную площадь проекции фотомаски на заготовку (reticle limit), составляющий примерно 800 мм²; точнее, 33×26 мм. Именно таковы максимальные размеры области, которую может за один раз проэкспонировать современный EUV-степпер ASML, и, поскольку предел тут именно физический, т. е. определённый необходимостью гарантировать прохождение потока (почти) рентгеновских лучей с длиной волны 13,5 нм через сложную систему зеркал без нарушения параллельности траекторий отдельных фотонов в его составе, какими-то чисто инженерными ухищрениями преодолеть его не представляется возможным. По крайней мере, внутренняя «дорожная карта» самой ASML — а эта голландская компания далеко опередила все прочие предприятия мира в деле изготовления фотолитографов — по меньшей мере до 2030 г. не предусматривает выхода за указанный предел площади одиночного экспонирования. Соответственно, если на заготовке необходимо выполнить более крупный монолитный чип, его разбивают на умещающиеся в предел участки — для каждого из которых предназначен свой комплект фотомасок (именно комплект; процедура эта многопроходная, поскольку полупроводниковые микросхемы существенно многослойны). В случае царь-процессора Cerebras изрядная доля его узлов — вычислительных ядер с размещёнными рядом ячейками SRAM и коммуникационными шинами межсоединений — воспроизводится один к одному по всей его площади, так что по числу комплектов фотомасок разница с партией классических ЦП или ГП не слишком велика. 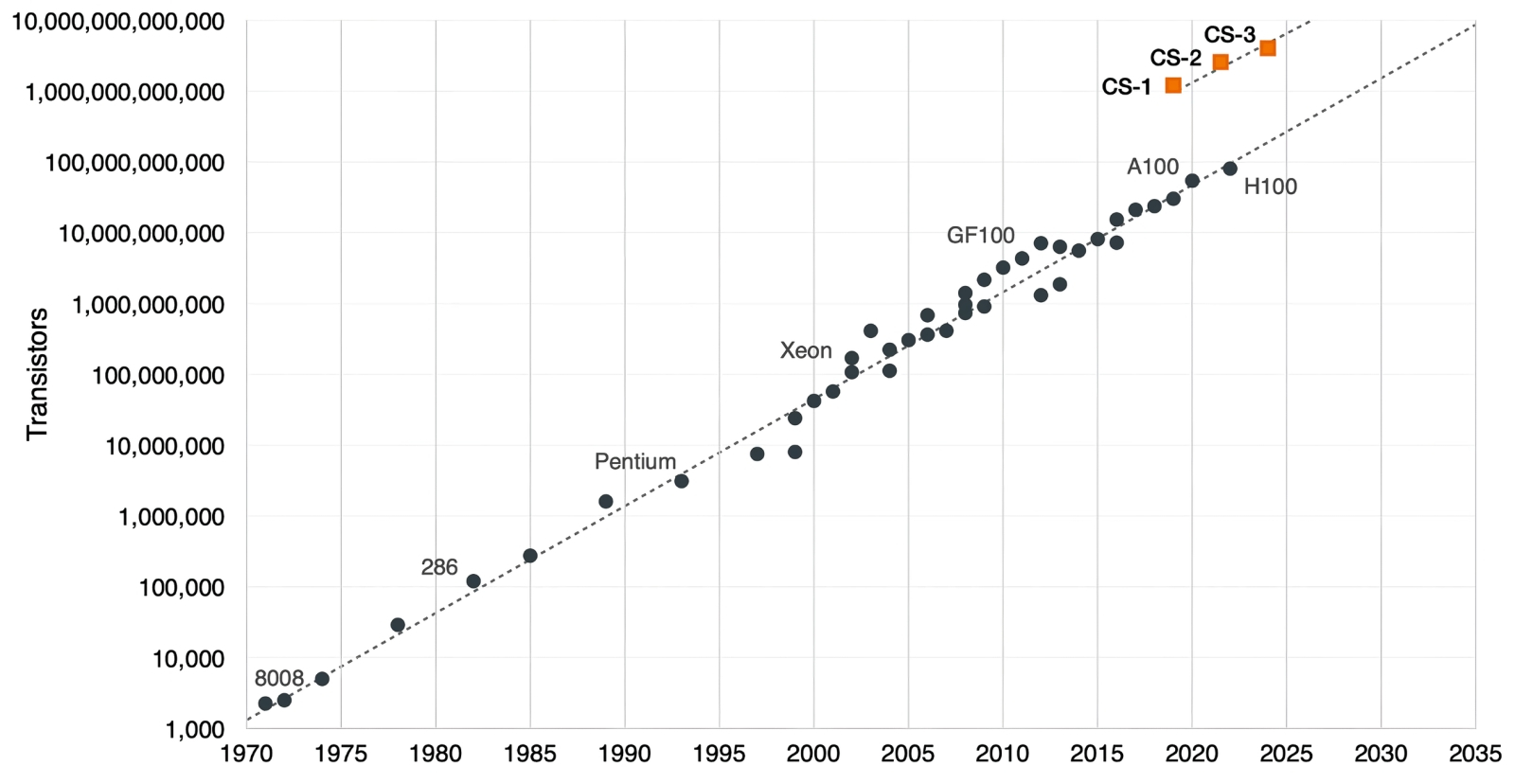
Хотя пресловутый «закон Мура» продолжает, невзирая на мрачные пророчества множества скептиков, в целом выполняться, чипы Cerebras — точнее, построенные на них серверы серии CS — уверенно воспаряют ещё выше над утверждённой этим самосбывающимся пророчеством прямой (источник: NextPlatform) Огромная площадь кристалла WSE-3 обеспечивает не просто количественное превосходство по числу вычислительных ядер над классическими по габаритам чипами —900 тыс. штук против почти 17 тыс. (плюс ещё 528 специализированных тензорных) у Nvidia H100, — но и качественное, когда речь заходит о быстроте обмена данными с памятью. Для ключевых в наши дни задач искусственного интеллекта — как тренировки, так и инференса — это едва ли не решающее преимущество. Благодаря тому, что множество ячеек SRAM на столь внушительном кристалле можно свободно размещать поближе к ядрам, характерная ширина полосы пропускания при обмене данными между первыми и вторыми достигает в случае WSE-3 21 Пбайт/с, тогда как для H100 — только 0,003 Пбайт/с. Обширные габариты чипа позволяют и шину внутренних межсоединений (fabric) сделать неимоверно скоростной просто за счёт физического наращивания числа параллельных каналов: до 214 Пбит/с против 0,0576 Пбит/с у всё того же H100. Не случайно ведущий тайваньский, а заодно и глобальный чипмейкер, TSMC, что непосредственно изготавливает царь-процессоры по заказу Cerebras, разработал специально для подобных изделий особую технологию System-on-Wafer (SoW); правда, помимо самого калифорнийского стартапа, воспользовался ею к настоящему времени ещё всего только один заказчик — Tesla. А ведь царь-чипы способны вдобавок ко всему прочему объединяться в кластеры: в случае WSE-3 — до 2048 узлов, состоящих из полнофункциональных вычислителей CS-3, что обеспечивает пиковую производительность на уровне 256 Эфлопс. Сила! Основали Cerebras, впервые громко заявившую о себе в 2019-м, когда был изготовлен и протестирован WSE-1, специалист по микропроцессорной разработке Шон Лай (Sean Lie) и Эндрю Фельдман (Andrew Feldman), ранее создатель и глава поглощённого AMD ещё в 2011-м разработчика микросерверов Sea Micro. Сегодня, из 2026-го, этот шаг кажется весьма прозорливым (даже с учётом того, что доминирует на рынке ИИ-ориентированных вычислителей до сих пор всё-таки Nvidia — со своими вполне классическими по габаритам ГП): Лай и Фельдман с самого начала рассчитывали создать систему, пригодную именно для тренировки и исполнения моделей искусственного интеллекта. Уже в те времена пригодность актуального «железа» для машинного обучения проверяли с использованием бенчмарка MLPerf, который фиксировал скорость тренировки модельной нейросети (с исходно нулевыми весами) до такого состояния, когда та оказывалась способна решать, не выходя за пределы заданных погрешностей, ряд практических задач: распознавания образов, визуальной идентификации объектов (отдельно на больших и на малых изображениях), а также обработки команд на естественном языке. Так вот, типичные для той поры аппаратные платформы — суперкомпьютеры классической архитектуры, по сути; ведь ставшие чуть позже основой ИИ-вычислений Nvidia A100 появились только в 2020-м, — тратили на полное прохождение MLPerf по несколько часов. За что приходилось, в свою очередь, выкладывать десятки миллионов американских долларов: суперкомпьютерное время никогда не было дешёвым. 
Схема вычислителя CS-1 на основе царь-чипа WSE-1: энергопотребление самого такого процессора — 15 кВт, ещё 4 кВт уходит на питание жидкостной системы охлаждения, ещё около 1 кВт приходится на неизбежные тепловые потери; итого — 20 кВт на один-единственный, пусть и способный в одиночку справиться с эмуляцией огромной нейростети, компьютер (источник: Cerebras) Разработчики систем машинного обучения прекрасно отдавали себе отчёт в том, что, если им захочется обучить подлинно универсальную большую языковую модель (БЯМ), придётся затратить месяцы, если не годы времени работы таких систем, — что с чисто экономической точки зрения представлялось попросту нереалистичным. Перед находившейся в то время на ранней (если сравнивать с сегодняшним её состоянием) стадии развития ИИ-отраслью стояла насущная задача: поднять производительность аппаратных средств обработки глубоких нейросетей на 2-4 десятичных порядка разом. Так что царь-чип WSE-1, с ходу обещавший тысячекратный рост производительности как раз для хорошо распараллеливаемых вычислений — того самого перемножения матриц, на котором базируются все нынешние БЯМ, — был сразу же воспринят более чем благосклонно. Ещё бы: 2 трлн транзисторов, 200 тыс. программируемых вычислительных ядер, 18 Гбайт локальной сверхбыстрой (коммуницирующей с ядрами по шине 9 Пбайт/с) памяти SRAM, — да ещё и наличие нативной, «из коробки», совместимости со знаковыми для ИИ-разработчиков окружениями TensorFlow и PyTorch, а заодно и оптимизации для работы с разреженными (sparse) матрицами. Не секрет, что в задачах машинного обучения сплошь и рядом попадаются матрицы, значительную долю элементов которых составляют нули. Соответственно, если при умножении такой матрицы на скаляр или вектор сразу записывать в итоговый регистр нулевое значение произведения чего угодно с расположенным в данной ячейке нулём (а не отправлять ноль вместе с другим сомножителем на процессорное ядро из ОЗУ, возвращая затем всё тот же ноль обратно в ячейку памяти), удастся сэкономить немало процессорных циклов. Так, производительность WSE-1 при работе с 16-разрядными числами с плавающей запятой для плотных матриц (FP16 Dense) составляла 2,65 Пфлопс, а для разреженных (FP16 Sparse) — 26,5 Пфлопс; преимущество на целый десятичный порядок! 
Разработчикам WSE-1 пришлось самим проектировать и корпус для своего царь-чипа, и готовую справляться с его чудовищным теплорассеянием систему охлаждения, — до них такие задачи никто не решал (источник: Cerebras) ⇡#Зримые достоинстваНеоптимальность фоннеймановских систем для решения задач машинного обучения — и прежде всего для работы с по-настоящему крупными матрицами — отмечается давным-давно. Проблема только в том, что именно в базирующиеся на принципах фон Неймана полупроводниковые компьютеры вложены за много десятилетий такие объёмы инвестиций, что догнать их за разумное время сколь угодно перспективным вычислителям иных типов чрезвычайно непросто. Предложенная Cerebras идея царь-чипа представлялась в конце 2010-х вполне разумным компромиссом: с одной стороны, для изготовления такой микросхемы применимы уверенно поставленные на поток технологии; с другой — объём памяти SRAM уже первой его версии, WSE-1 (18 Гбайт), позволял целиком загружать туда любую актуальную на тот момент БЯМ — и не тратить тем самым драгоценные процессорные циклы на перенос промежуточных данных из внешнего ОЗУ (DRAM) к вычислительным ядрам и обратно. Правда, развитие генеративных моделей оказалось настолько стремительным, что это бесспорное преимущество царь-процессоров довольно скоро потеряло актуальность: в 18 Гбайт для них начало становиться тесновато, а увеличивать объём SRAM за счёт сокращения числа вычислительных ядер было бы крайне нерационально. По этой причине уже в 2021 г. следующее поколение компьютеров Cerebras, CS-2, обзавелось внешней (по отношению к самому царь-чипу) подсистемой хранения данных MemoryX и контроллером межсоединений (fabric machine) SwarmX. Зона MemoryX образована модулями памяти DRAM и NAND, поскольку далеко не все перцептроны в составе глубокой нейросети задействованы единомоментно в процессе её обучения, и потому не всем им необходимо располагаться в максимальной близости от вычислительных ядер. Правда, переход к использованию внешней памяти ощутимо сказался на скорости обмена данными в пределах вычислительного кластера. Для объединения машин CS-2 использовалась среда переноса данных SwarmX на основе каналов 100GbE с применением технологии RoCE RDMA, что позволяло достичь пропускной способности в 150 Тбит/с. Для сравнения: NVLink 6.0, обеспечивающий соединения между узлами платформы Nvidia Rubin в крупномасштабных конфигурациях (74 ГП в стойке), за счёт сверхплотной среды обмена all-to-all mesh позволяет передавать до 260 Тбайт/с. 
Представленная вместе с CS-2 зона межсоединений SwarmX позволяет входящим в состав кластера вычислителям совместно работать с единой для всех них областью памяти MemoryX (источник: Cerebras) Тем не менее операция матричного умножения с использованием весьма скоростной внутренней памяти продолжает оставаться выдающимся достоинством царь-чипа. Ещё в версии WSE-2 он был способен в один присест, не разбивая входные данные на группы, производить умножение с участием матриц размерами до 100 тыс. × 100 тыс. ячеек, т. е. не тратить время и ресурсы на оптимизацию такого рода операций. Ускорителям же Nvidia, тензорным чипам Google и прочим микросхемам традиционных габаритов приходится прибегать к сложному «трёхмерному распараллеливанию» вычислений (3D parallelism) — что затягивает процедуры матричного умножения, увеличивает расход энергии и повышает прочие сопутствующие издержки. Вычислители CS-3 поставляются сегодня коммерческим заказчикам в кластерах с объёмами зон MemoryX 24 или 36 Тбайт, а гиперскейлерам — в ещё более крупных: от 120 до 1200 Тбайт. Соответственно, клиенты поскромнее получают возможность загружать в память такого кластера целиком БЯМ с 720 млрд параметров, а наиболее крупные — с 24 триллионами параметров, что заведомо превосходит прикладной характерный размер GPT-5, скажем. Хотя формально её архитектура «ансамбль экспертов» (Mixture-of-Experts, MoE) подразумевает суммарно 52 трлн параметров, для ответа на каждый конкретный запрос задействуются не более 1,8 трлн; примерно столько же, сколько целиком содержит GPT-4. Гиперкластер из предельно возможного числа машин CS-3 (2048 единиц) будет включать 1,8432 млрд вычислительных ядер и до 1200 Тбайт MemoryX (которую можно, кстати, масштабировать независимо — в отличие от гибрида Nvidia Grace Hopper), что обеспечит итоговую производительность с разреженными 16-разрядными данными в 256 Эфлопс. Что это означает на практике: экстремистская Meta✴* обучала свою модель Llama 2 с 70 млрд параметров на кластере, содержавшем 16 тыс. ускорителей Nvidia A100, примерно месяц, — тогда как гиперкластер на базе CS-3 справился бы с той же задачей менее чем за сутки. 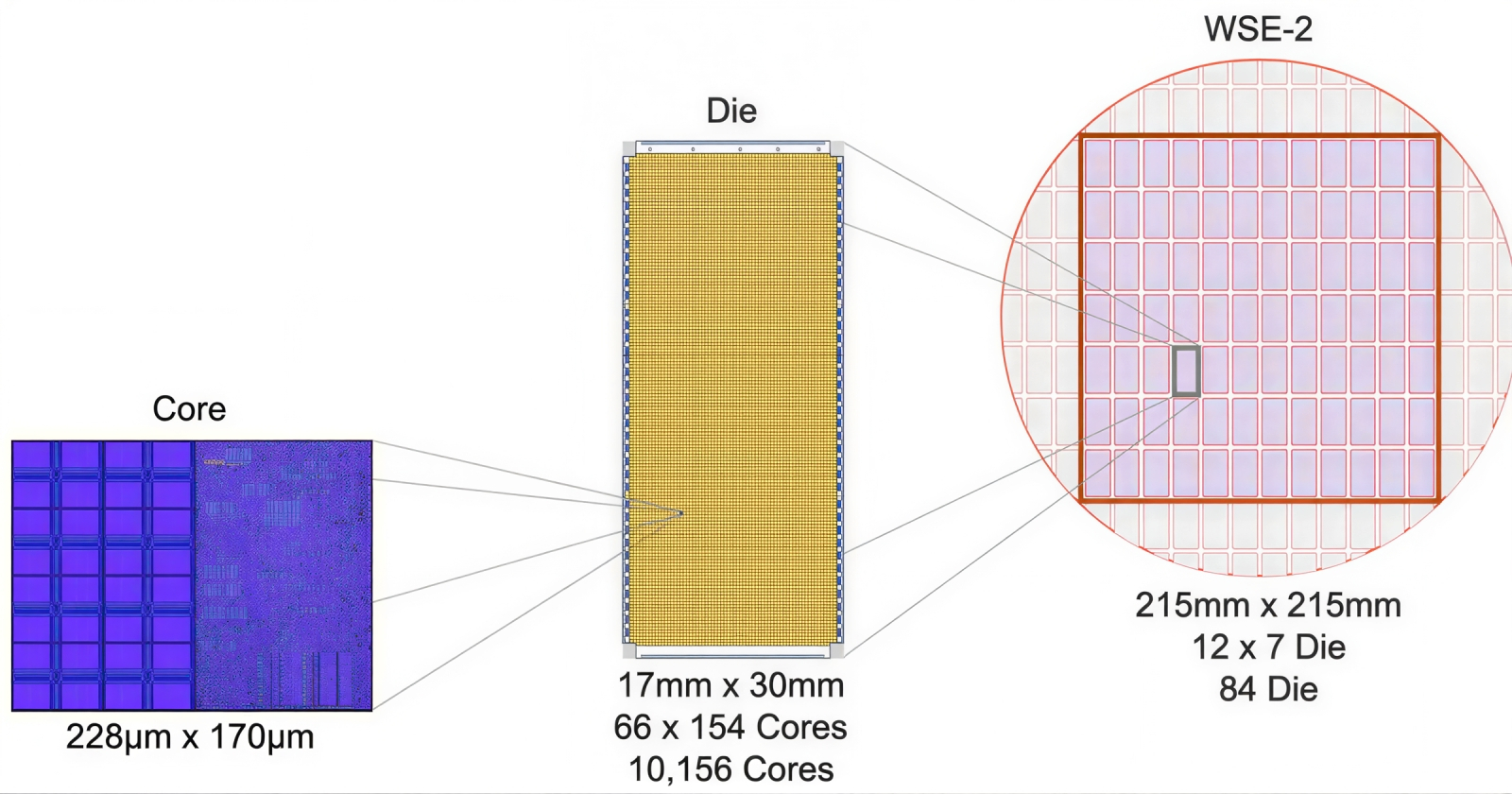
Чип WES-2 состоит из элементарных узлов — вычислительных ядер вместе с ячейками SRAM (слева) размерами 228×170 мкм, сведённых в матричные блоки (die, в центре) 17×30 мм, каждый из которых литографируется с одним и тем же комплектом фотомасок, так что в итоге выходит квадратный царь-процессор со стороной 215 мм (источник: Cerebras) Ещё в 2021 г. эксперты утверждали, будто кластер из вычислителей CS-2 (предыдущего поколения) позволит обучать ИИ-модели, результат работы которых будет сопоставим с выдаваемым человеческим мозгом. Основанием для столь громких заявлений стала предельная теоретическая ёмкость зоны MemoryX для такого кластера — 2,4 Пбайт, что позволяет разместить в памяти до 120 трлн параметров, а в человеческом мозге содержится как раз около 80 млрд нейронов с примерно 100 трлн связей между ними, — числа вполне сравнимые. Правда, как выяснилось, принципы работы биологической нервной ткани несколько отличны от безыскусного матричного умножения, но это не умаляет иных достоинств архитектуры Cerebras второго, а после и третьего поколения: технологии потоковой передачи весовых коэффициентов Weight Streaming, дезагрегации вычислительной среды на общую память и вычислительные блоки, независимость масштабирования размеров и скорости работы кластера благодаря системе межсоединений SwarmX. Откровенно радует заказчиков и едва ли не идеальное линейное масштабирование CS-кластеров, когда при удвоении количества серверов время обучения моделей сокращается практически в те же самые два раза. В середине 2023 г., когда ажиотаж вокруг ИИ не утихал уже более полугода, Cerebras заявила о готовности сформировать на базе вычислителей CS-2 суперкомпьютер Condor Galaxy 1 (CG-1), ориентированный на решение задач именно искусственного интеллекта. В марте 2024-го были анонсированы царь-чипы WSE-3, тоже предназначенные прежде всего для тренировки перспективных БЯМ — именно перспективных, поскольку актуальные на то время передовые модели вроде GPT-4 или Google Gemini отставали по количеству рабочих параметров от верхнего предела, доступного для суперкластера CS-3 (те самые 24 трлн), на десятичный порядок величины. К середине того же года стала практически очевидной ориентация новых машин Cerebras именно на тренировку, а не на инференс ИИ-моделей, что вполне логично, поскольку для исполнения готовой БЯМ фиксированной архитектуры можно обойтись куда менее монструозным «железом», тогда как задача обучения требует значительно бóльших аппаратных ресурсов. Хотя предназначенная главным образом как раз для инференса облачная платформа Cerebras Inference была анонсирована в августе 2024-го как «самая производительная в мире», у неё быстро стали появляться не менее выдающиеся конкуренты (тоже на чипах своей разработки, только более традиционных по габаритам): накал соперничества в этой области крайне велик. И всё равно, как ни парадоксально, индустриальные бенчмарки MLPerf Inference по-прежнему отдают пальму первенства решениям Nvidia — даже с учётом непрерывного наращивания производительности Cerebras Inference. 
В конце 2022 г., когда ChatGPT стал оглушительно популярным, в американской Санта-Кларе вошёл в строй вычислительный комплекс Andromeda — кластер из 16 CS-2, объединённых средой передачи данных SwarmX с пропускной способностью 96,8 Тбит/с и дополненных 284 серверами на базе AMD EPYC 7713 для предварительной обработки данных (источник: Cerebras) ⇡#Размер и его значениеПод конец 2024 г. Cerebras совместно с Сандийскими национальными лабораториями (SNL) Министерства энергетики США обучили тестовую ИИ-модель с 1 трлн параметров, используя один-единственный вычислитель CS-3 с 55 Тбайт памяти MemoryX — и заодно подтвердили практически линейную масштабируемость таких систем: при использовании затем кластера из 16 CS-3 время, затраченное на то же самое обучение, сократилось в 15,3 раза. Раз с вычислительной точки зрения царь-процессоры действительно настолько хороши, остаётся всего один небольшой вопрос: как у них обстоят дела с экономической эффективностью? Увы, ответ на него выходит не самым однозначным. Точных данных о том, сколько заказчики платят за полностью укомплектованный кластер CS-3, нет, но достаточно обоснованные оценки указывают на 5-6 млрд долл., — примерно 23,4 млн за 1 Эфлопс. В то же время экстремистская Meta✴* выделила на полмиллиона ГП Nvidia H100 (со всей необходимой обвязкой, разумеется) для своей платформы 25 млрд долл., выведя тем самым производительность той на уровень 1 Зфлопс (тоже для разреженных данных FP16, как и в случае CS-3), т. е. выложила за каждый 1 Эфлопс около 25 млн долл. Практически точное совпадение! Однако спешить не надо: если начать разбираться, какими именно данными оперируют современные БЯМ, выясняется, что у подхода Cerebras всё-таки есть определённые ограничения в плане практической применимости. Ограничения эти — оборотная сторона бесспорных достоинств архитектуры царь-чипов, в первую очередь чрезвычайно близкого расположения огромных объёмов SRAM и вычислительных ядер. Как уже было сказано, оптимизация обработки разреженных данных в этих условиях обеспечивает практически десятикратный прирост производительности. Но у классических по габаритам чипов, которые вынуждены в любом случае тратить больше времени на перемещение данных между ОЗУ и логическими контурами, выигрыш от sparse-оптимизации будет заведомо меньше. И поскольку разработчики классических тензорных или нейропроцессоров исходно принимают это обстоятельство в расчёт, получается, что с неразреженными (и слабо разреженными) матрицами их изделия управляются лучше — в том числе за счёт использования более тонких техпроцессов и иных оптимизаций на аппаратном уровне, — чем даже «5-нм» царь-чипы WSE-3. 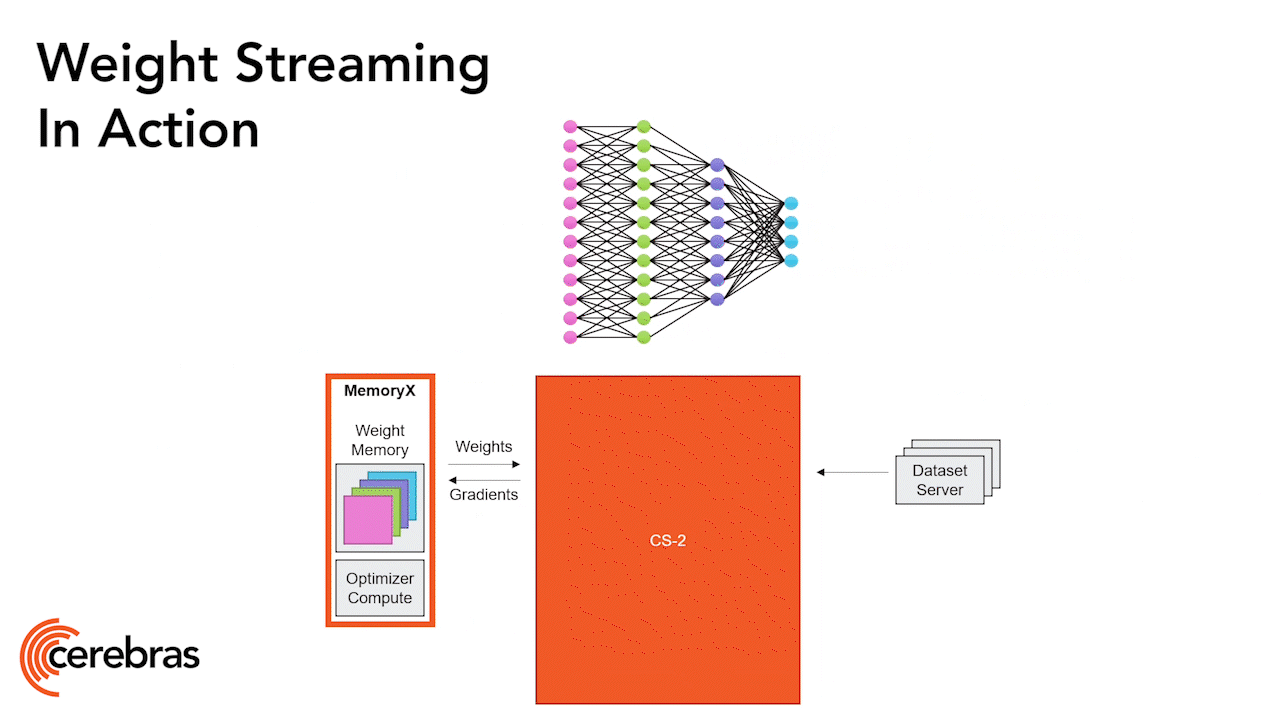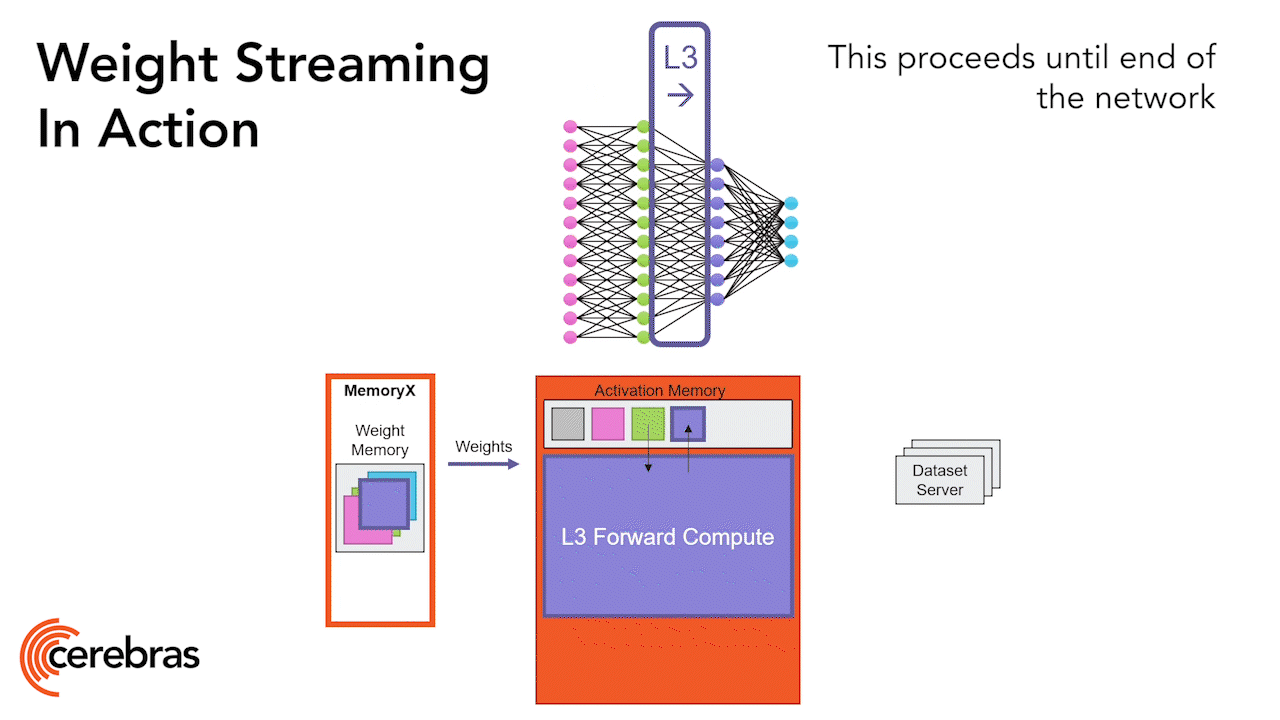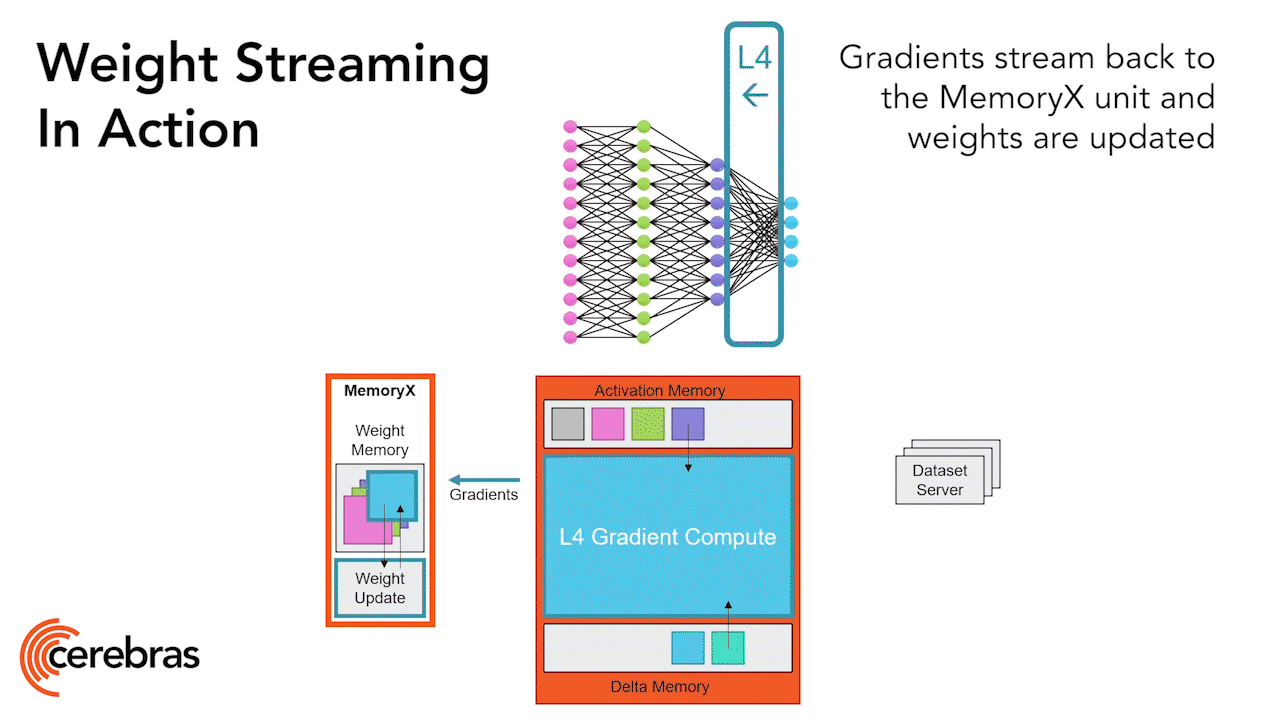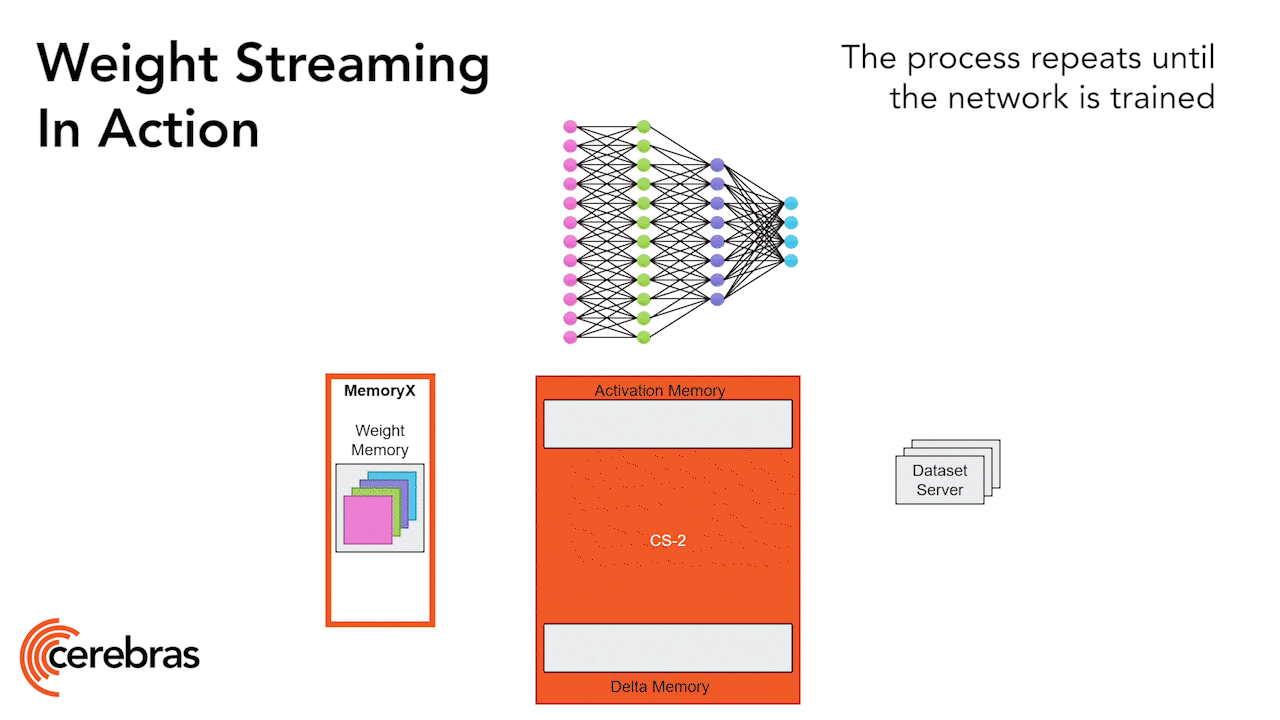
Общий принцип обработки глубокой нейросети царь-чипом (в данном случае WES-2): веса хранятся во внешней по отношению к чипу среде MemoryX, а на самом этом устройстве происходит обработка (вычисление значений на выходах перцептронов) нейросети послойно, причём итоговые величины сразу же отправляются обратно в MemoryX, не загромождая внутреннюю память (источник: Cerebras) Вот пример: для Nvidia H100 производительность при работе с данными FP16 Dense достигает 495 Тфлопс, тогда как в случае FP16 Sparse она практически удваивается — до 990 Тфлопс. Выходит, если данные характеризуются слабой разреженностью, система на чипах Nvidia будет трудиться над ними примерно вдвое дольше. Чипы же Cerebras настолько блестяще оптимизированы именно для умножения разреженных матриц, что переход к плотным данным снижает их производительность сразу на десятичный порядок, — об этом мы упоминали в самом начале. Выходит, если возвращаться к оценке стоимости 1 Эфлопс для кластера CS-3 и для сопоставимой по мощности системы на процессорах H100, то при резком снижении разреженности входных данных эта стоимость в первом случае возрастает почти десятикратно, а во втором — лишь примерно вдвое. Но разреженные матрицы характерны в основном для тренировочных наборов данных, тогда как в случае инференса чаще приходится иметь дело с FP16 Dense. Более того, сегодня всё шире применяются урезанные форматы представления информации для ИИ-моделей — FP8 и ещё более огрублённые, — а под них поневоле более гибкие продукты Nvidia оптимизированы куда лучше, чем жестоковыйные в архитектурном плане царь-решения Cerebras. 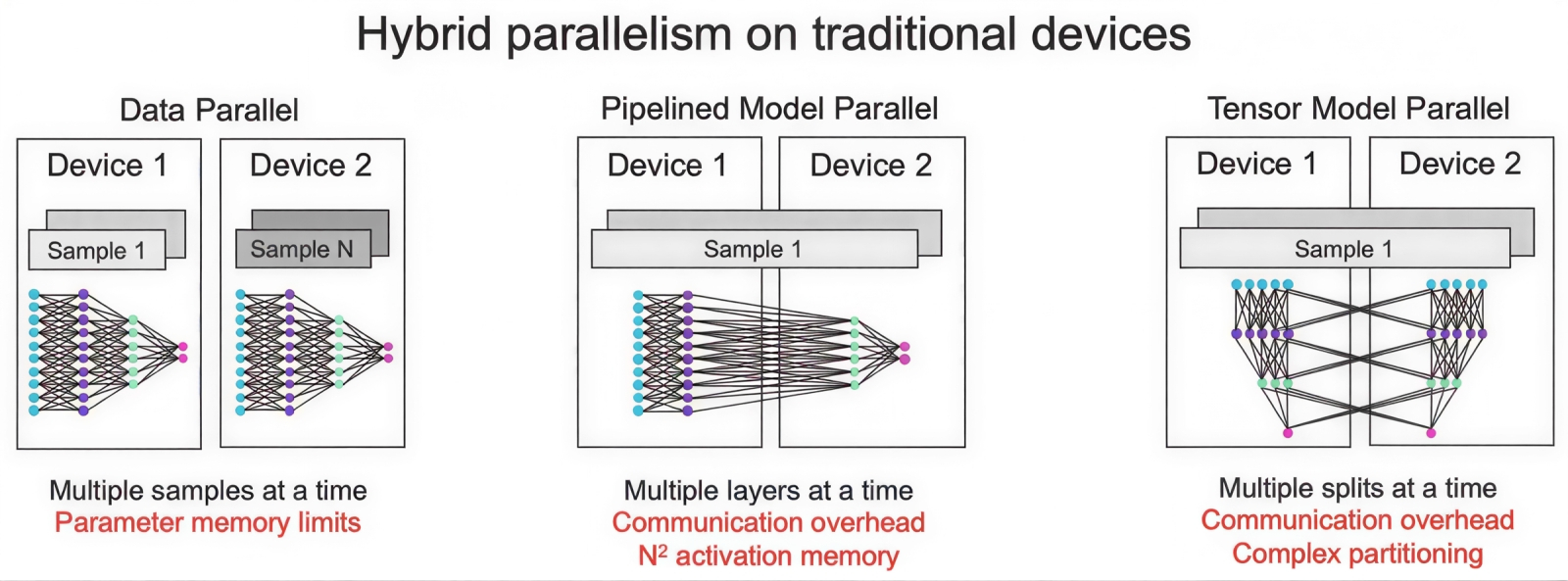
Как масштабировать обработку нейросетей, если одно вычислительное устройство не в состоянии вместить все необходимые данные? Практикуются три основных подхода: параллелизация данных (но для этого нужно располагать устройствами, способными во внутренней памяти перемножать огромные матрицы, — а это и есть WSE), конвейерная параллелизация с последовательной обработкой слоёв, что требует огромных ресурсов памяти, и тензорная параллелизация с разнесением фрагментов каждого слоя (продольных «срезов» глубокой нейросети) по соседним вычислителям; здесь необходимы чрезвычайно высокоскоростные межсоединения между вычислительными узлами, — всё тот же NVLink, например (источник: Cerebras) Оборотной стороной того факта, что царь-чипы WSE не нуждаются в сложных средствах реализации параллелизма на уровне моделей и тензоров — только на уровне данных, — оказывается отсутствие у них гибкости, необходимой для решения задач, для которых их аппаратная структура не оптимальна. Примерно то же самое характерно для всех специализированных ИИ-вычислителей: скажем, великолепно справляющийся с огрублёнными форматами представления данных (BF16, FP8, INT8) Google TPU v7p Ironwood, ориентированный на ИИ-инференс, не способен решать требующие высокой точности (FP32) задачи научных вычислений — с которыми прекрасно ладят и кластеры на основе всё тех же H100, и классические суперкомпьютеры вроде El Capitan. Приходится вновь признавать, что сила Nvidia — в чрезвычайно удачном сочетании весьма универсального по возможностям «железа» и блестяще реализующего его возможности ПО; сочетании, противопоставить что-то которому у конкурентов выходит пока что по отдельным направлениям — и временами очень неплохо выходит, — но не по всей их совокупности. Бывшие сотрудники Cerebras сравнивают вычислители этой компании с болидами «Формулы-1»: да, работают великолепно, и скорость выдают несравненную, но заливать им в бак следует только топливо совершено определённого состава (т. е. стремительно устаревающие классические трансформенные ИИ-модели вроде тех, что образуют семейство LLaMA), и на неоптимизированных трассах толку от них маловато. Прибавим сюда производственные трудности: невозможно изготовить чип, диагональ которого равна диаметру 300-мм пластины, без единого дефекта: соответственно, часть вычислительных ядер и/или ячеек SRAM на каждом царь-процессоре не будет функционировать должным образом. Это не проблема на программном уровне — нерабочие узлы просто исключаются из рабочего процесса, — однако производительность при наличии дополнительного программного контроля в любом случае оказывается ниже, чем если бы сигналы просто направлялись на соответствующие участки заведомо работоспособных логических схем. Кроме того, гомогенность образующих WSE базовых элементов (вычислительные ядра, SRAM, контроллеры памяти) не позволяет делать царь-чип по-настоящему сложным — например, организовать на его периферии подлинно широкополосный контроллер ввода-вывода. Да, решения Cerebras хороши для своего круга задач, — недаром инвесторы вкладывают и в них, и в другие нишевые проекты вроде Etched или SambaNova сотни миллионов долларов. Такие специализированные ускорители ценны даже просто как средство снизить зависимость от Nvidia — от которой на давшем изрядный крен в сторону ИИ современном ИТ-рынке слишком уж много стало зависеть. Но чем сложнее становятся генеративные модели, тем более значимой оказывается универсальность работающих с ними (как на этапе обучения, так и в ходе инфренеса) аппаратных средств, а на этом направлении соперничать с «чёрно-зелёными», которые десятилетиями развивали свои аппаратно-программные платформы высокоплотных параллельных вычислений в едином комплексе, невероятно сложно.
⇣ Содержание
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.
Материалы по теме
|
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.





