В ноябре 2000 года в продажу поступил новый процессор Pentium 4, который реализовал принципиально новую микроархитектуру x86 со времён Pentium Pro. До выхода P4 на рынке преобладало ядро P6, представленное процессорами Pentium II и Pentium III. За это время люди, обращавшие внимание на этот рынок, усвоили одну вещь: народ покупает мегагерцы. Intel учла этот факт и команда Willamette, работавшая в Санта-Кларе, руководствовалась именно гонкой мегагерц. Это можно увидеть как в рекламе Pentium 4, так и в технической литературе, где недавно были опубликованы детали разработки процессора. В нашей статье вы узнаете, что преемник наиболее успешной микроархитектуры x86 - это созданный с нуля процессор, работающий на запредельных частотах.
Мы рассмотрим возможные решения и варианты дизайна, взятые разработчиками при создании этого мегагерцового монстра. Особое внимание придется уделить инновациям, тому, как они вписываются в общую философию дизайна этого процессора и взаимодействуют с конечными приложениями. Мы рассмотрим сверх-длинный конвейер, структуру кэша с отслеживаниями (trace cache), арифметико-логическое устройство, работающее с удвоенной скоростью и другие аспекты процессора.
Лучше всего рассматривать данную статью, как статью о процессоре P4, где G4e используется лишь для сравнения и объяснения новых технологий. На примере G4е продемонстрировано как "стандартно" работает та или иная технология. Затем мы перейдем к отличиям ее реализации в P4.
Перед тем как детально рассматривать Pentium 4, полезно вспомнить основы дизайна процессоров.
Основной поток команд
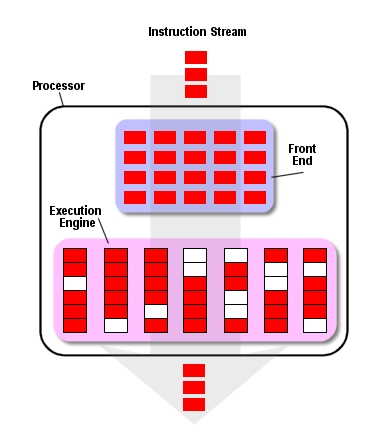
Когда разговор идёт о процессорах, основными понятиями считаются препроцессор (front end) и постпроцессор (back end, execution engine). Когда инструкции забираются из кэша или из оперативной памяти, их необходимо декодировать и отправить на выполнение. Эти три операции (получение инструкций, декодирование и отправка на выполнение) происходят на препроцессоре (front end).
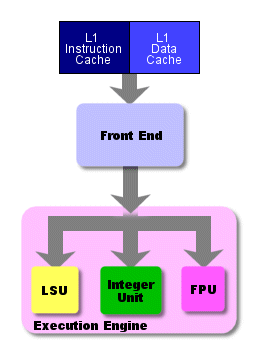
Так выглядит основной поток команд в процессоре
Команды приходят из кэша на препроцессор и поступают затем на постпроцессор, где и выполняются. Как только команды будут обработаны постпроцессором, результат их выполнения попадает обратно в оперативную память. Процесс, когда команды ЗАБИРАЮТСЯ из кэша, ДЕКОДИРУЮТСЯ во внутреннюю форму, понятную процессору, ВЫПОЛНЯЮТСЯ и результат ЗАПИСЫВАЕТСЯ в оперативную память, и составляет основной четырёхступенчатый конвейер. Примерно этому учат на различных курсах в ВУЗах разработчиков процессоров. Каждую из этих ступеней команда должна проходить ровно за один такт. Ровно за один такт каждая ступень выполняет всю свою логику и пересылает команду на следующую ступень. Поэтому чем быстрее каждая из ступеней выполняет свои функции, тем быстрее работает весь процессор и тем выше его тактовая частота.
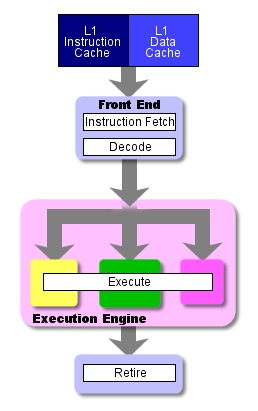
Четырёхступенчатая конвейерная обработка
Эта схема представляет "стандартный" путь прохождения команд через процессор, и как мы только что заметили, на выполнение одной команды здесь требуется ровно один цикл. Большинство процессоров действительно выполняют команды за один цикл (в P4 даже существуют команды, выполняемые за половину цикла), но существуют сложные команды, которые проходят стадию ВЫПОЛНЕНИЯ за несколько циклов. Для согласования при выполнении таких сложных инструкций различные устройства задействуют свои собственные исполнительные конвейеры (некоторые - одноступенчатые, некоторые - многоступенчатые), так что они могут добавить ещё несколько ступеней к основному конвейеру процессора.
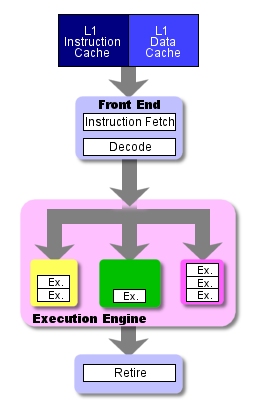
Четырёхступенчатая конвейерная обработка
с конвейерами на стадии ВЫПОЛНЕНИЯ
Поясним наши слова. Когда мы говорим о количестве ступеней в конвейере процессора, мы имеем в виду идеальный процессор, где каждая инструкция проходит ступень ВЫПОЛНЕНИЯ ровно за один такт, но большинство инструкций проходят несколько ступеней ВЫПОЛНЕНИЯ в различных функциональных устройствах.
Философия дизайна P4 и G4e
В отличие от классического варианта, когда весь конвейер состоит из четырёх ступеней (как описано выше), в большинстве современных процессоров всё выглядит несколько по-другому. Например, в G4e вместо классических четырёх ступеней, конвейер разбивается на семь ступеней, что позволяет ему работать на более высокой тактовой частоте при одинаковом технологическом процессе. На каждой из ступеней выполняется меньшее количество работы, но при этом работа выполняется за меньшее количество времени. Так как каждая ступень всегда выполняется ровно за один такт, то более короткие ступени приводят к меньшей продолжительности тактов и возможности работы на более высокой тактовой частоте. В P4 с целыми двадцатью ступенями в основном конвейере эта тактика доведена до крайности. Взгляните на следующую диаграмму. Здесь представлена относительная частота последних шести процессоров Intel с архитектурой x86. (Предполагается, что технологический процесс всех процессоров одинаков).
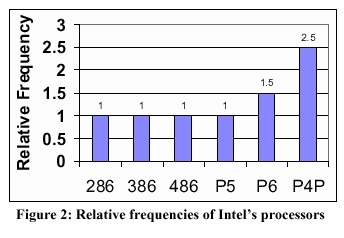
Давайте посмотрим, как Intel объясняет эту картину.
На этой диаграмме видно, что глубина конвейера у процессоров 286, Intel 386™ , Intel 486™ и Pentium® (P5) одинакова. То есть если бы они были выполнены по одной кремниевой технологии, частота у них была бы одинаковой. Все они выполняют одинаковое количество логических операций на каждой из ступеней. В архитектуре P6 конвейер удлинён. При этом на каждой из ступеней выполняется меньшее количество логических операций, что позволяет существенно увеличить частоты и производительность. В архитектуре P6 количество ступеней в конвейере увеличено примерно в два раза по сравнению с предыдущими моделями. Это позволило достичь увеличения частоты в полтора раза при одинаковом технологическом процессе. В процессоре P4 была использована архитектура NetBurst, у которой количество ступеней в два раза выше по сравнению с конвейером P6.
Как мы видим, Pentium 4 жертвует довольно многим для увеличения тактовой частоты. И хотя Intel и пытается обыграть этот факт несколько по-другому, большая глубина конвейера - одна из таких "жертв".
Многие объяснят большую разницу в глубине конвейеров P4 и G4e тем, что современным x86 процессорам, таким как Athlon, PIII и P4 приходится разбивать большие, сложные x86 инструкции на маленькие, легко выполняемые инструкции. Действительно, такая операция по разбиению инструкций добавляет новые ступени в конвейер P4, но они добавляются не к основным двадцати ступеням. (Процессору все еще необходимо транслировать инструкции в чops, но как мы увидим позднее, кэш с отслеживанием позволяет проводить транслирование и декодирование вне основного конвейера P4).
Такое радикальное отличие в глубине конвейеров G4e и P4 отражено и в философии дизайна самих процессоров. Задача обоих процессоров - выполнить максимальное количество инструкций за минимальное время, но подход к этой задаче у обоих процессоров разный. Подход G4e можно обозначить как "много коротких конвейеров". Разработчики просто добавили несколько дополнительных устройств к постпроцессору для выполнения инструкций, а препроцессор должен параллельно обеспечивать эти устройства инструкциями. Для того чтобы разбить линейный поток команд на максимальное количество параллельных инструкций (instruction-level parallelism (ILP)), препроцессор G4e сначала перемещает серию команд на чип. Затем его логика вне очереди (out-of-order, OOO) проверяет взаимозависимости и посылает инструкции на параллельное выполнение на девять функциональных устройств исполнительного модуля. Каждое из функциональных устройств обладает довольно маленьким конвейером, поэтому инструкции проходят эту ступень за небольшое количество циклов. На последних ступенях конвейера инструкции преобразуются обратно в линейный вид (как в оригинальной программе), затем результат записывается в память.
В каждый момент G4e может одновременно выполнять до 16 инструкций, находящихся на различных ступенях выполнения. Как мы увидим позднее, окно инструкций у G4e имеет довольно небольшой размер по сравнению с P4. Итак, G4e получает на процессор небольшое количество инструкций, распределяет их на параллельное выполнение и выполняет их за минимальное количество циклов.
Так работает G4e
В P4 реализован другой подход. На ступени выполнения там используется меньшее количество функциональных устройств. Но каждое из них обладает более длинным и более быстрым конвейером. Это означает, что каждое функциональное устройство имеет большее количество доступных для выполнения тактов (execution slots) и таким образом способно одновременно выполнять довольно много инструкций. Так, скажем, вместо трёх устройств для выполнения операций с плавающей точкой, работающих медленно, но параллельно, P4 имеет только одно такое устройство, которое может быстрее одновременно выполнять большее количество инструкций на различных ступенях.
Важно отметить, что для того, чтобы полностью загружать быстрые конвейерные функциональные устройства в P4, препроцессор должен обладать большим буфером, способным вмещать в себя и планировать огромное количество инструкций. Процессор P4 может одновременно выполнять на различных ступенях до 126 инструкций. Отсюда следует, что для внеочередного выполнения процессор должен анализировать значительно большее количество инструкций на взаимозависимость, а затем преобразовывать их для быстрой передачи функциональным устройствам.

Так работает P4
Для лучшего понимания сути вопроса можно обратиться к аналогии в индустрии фастфуд. В МакДональдс вы можете либо прийти пешком, либо приехать. В первом случае, вы увидите шесть коротеньких очередей. Вы можете встать в любую, и подождать своей очереди, чтобы вас обслуживал один человек. Во втором случае, вы попадёте в одну большую очередь. Но очередь будет обслуживаться быстрее, так как там работает несколько человек. Первому вы сделаете заказ, а у второго вы этот заказ заберёте. Так как процесс обслуживания разбивается на несколько этапов, то большее количество посетителей смогут получить еду в одной большой очереди. Так вот, G4e использует первый вариант, а P4 - второй.
Опасность длинных конвейеров
В определённых типах приложений схема работы P4 имеет преимущества, здесь можно назвать 3D-приложения и потоковые мультимедийные приложения. Но такая схема и многим рискует. Неприятности начинаются тогда, когда у процессора не хватает инструкций или данных для конвейера в кэше L1. Вы наверняка заметили пустые такты в рисунке про работу G4e. (Пустые такты обозначены белым цветом, а такты с инструкциями - красным). Эти пустые такты, называемые "конвейерными пузырьками" ("pipeline bubbles") появляются, когда процессору не хватает инструкций для выполнения. Эти пузырьки должны пройти все ступени до конца конвейера, таким образом, тратится впустую драгоценное время процессора.
Если сравнить P4 c G4e, то при попадании такого пузырька в многоступенчатый конвейер P4 тратится намного больше времени на то, чтобы этот пузырёк исчез. Так, попав в двадцатиступенчатый конвейер P4, один пузырёк затратит 20 тактов до своего выхода (даже ещё больше, если этот пузырёк находится в одном из длинных конвейеров FPU). А в семиступенчатом конвейере G4e он затратит всего лишь 7 тактов. 20 тактов - большие расходы. Даже если бы тактовая частота P4 была в два раза больше G4e, всё равно пузырёк бы исчезал быстрее в G4e.

Чем больше ступеней в конвейере, тем с большими проблемами сталкивается процессор при недостатке инструкций. Так как разработчики P4 при создании новой архитектуры руководствовались мегагерцами, то им пришлось много поработать над избежанием этих пузырьков. Мы уже обсудили очень длинные очереди на препроцессоре P4. Именно здесь P4 задействует большое количество транзисторов чтобы уменьшить негативный эффект многоступенчатого конвейера. В G4e эти транзисторы используются для создания дополнительных исполнительных модулей.
Обзор архитектуры G4e и его конвейера.
На большой диаграмме можно рассмотреть основы архитектуры G4e и особенности реализации ступеней конвейера на препроцессоре и функциональных устройствах.
Перед тем как попасть на конвейер G4e, инструкции должны попасть в кэш инструкций на 32 тысячи записей. 64 кб кэш L1 состоит из кэша инструкций и кэша данных равного размера. Далее инструкция передается из кэша L1 дальше, на следующие ступени препроцессора, а затем на стадию выполнения. Здесь она выполняется одним из восьми функциональных устройств процессора (не считая устройства предсказания ветвлений, о котором мы поговорим позднее).
Как уже было отмечено ранее, G4e вместо классических четырёх ступеней, разбивает конвейер на семь небольших ступеней.
|
|
G4 |
|
G4e |
| Препроцессор |
1 |
Выборка |
1 |
Выборка1 |
| 2 |
Выборка2 |
|
Декодирование/Отправка |
|
Декодирование/Отправка |
| 4 |
Выдача |
| Постпроцессор |
|
Выполнение |
|
Выполнение |
| 4 |
Завершение/Запись |
|
Завершение |
|
Запись |
Давайте взглянем на основные ступени конвейера G4e. Не смотря на то, что их больше четырёх, их предназначение вполне понятно. Понимание этого конвейера, больше похожего на конвейер RISC, даст нам основу для предстоящего разговора о более длинном конвейере P4.
Ступени 1 и 2 - выборка инструкций (Instruction fetch). Эти две ступени предназначены в основном для извлечения инструкций из кэша L1. G4e способен выбрать из кэша L1 четыре инструкции за один такт и передать их на следующую ступень. Будем надеяться, что в кэше L1 есть требуемые инструкции. В случае если в кэше L1 инструкции не найдены, процессор начинает искать их в более медленном кэше L2, что добавляет до девяти тактов задержки ко времени работы конвейера.
Ступень 3 - декодирование/диспетчеризация (decode/dispatch). Как только инструкция выбрана, она поступает на один из двенадцати входов очереди инструкций, где она будет декодирована. Именно на стадии декодирования процессор определяет, что это за инструкция, и куда именно отсылать её на выполнение. Как только инструкция декодирована, она отправляется на нужную очередь выдачи.
Декодер G4e может отправлять на следующую ступень до трёх инструкций за один такт.
Ступень 4 - выдача (Issue) Существует три очереди выдачи для трёх типов инструкций, выполняемых G4e. Первая очередь - для инструкций с плавающей точкой (Floating-Point Issue Queue, FIQ). Вторая очередь - для операций с векторами (the Vector Issue Queue, VIQ). Она обрабатывает операции с векторами (Vector/Altivec). Третья очередь - для выполнения общих инструкций (General Instruction Queue, GIQ). Она отвечает за всё остальное. Как только инструкция выходит из очередей выдачи, она попадает на выполняющий процессор (execution engine).
Ступень выдачи также использует резервации (reservation stations - буферы, содержащие команды, которые уже декодированы, но еще не выполнены), которые прикреплены к различным исполнительным устройствам. Заметим, что на картинке они не изображены. Это были бы маленькие белые квадратики над каждой из групп функциональных устройств. Именно на этой ступени линейный поток команд разбивается на независимые порции, и инструкции распределяются на доступные исполнительные устройства. Здесь происходит "внеочередная проверка", в основном, в резервациях. Резервации выполняют всю "грязную работу" по распределению инструкций для исполнительных устройств, к которым они прикреплены. Очереди выдачи, несмотря на их FIFO-характер, могут посылать инструкции в резервации изменяя их порядок по отношению друг к другу.
Очередь для операций с векторами имеет четыре входа. Она может принимать до двух инструкций за один такт из устройства отправки. Очередь для выполнения общих инструкций имеет шесть входов. Она может принимать до трёх инструкций за такт. У очереди для операций с плавающей точкой - 2 входа, и она может принимать лишь одну инструкцию за такт.
Ступень 5 - выполнение (Execute). Эта ступень достаточно проста. Здесь инструкция попадает из очереди выдачи на нужное функциональное устройство и там выполняется. Операции с плавающей точкой попадают на FPU, векторные операции попадают на одно из четырёх устройств Altivec, целочисленные операции попадают в арифметико-логическое устройство (ALU), и инструкции по загрузке или хранению (LOADs or STOREs) попадают на устройство загрузки или хранения (LOAD/STORE Units, LSU). Об этих устройствах мы поговорим более детально, когда будем обсуждать стадию выполнения.
Ступени 6 и 7 - завершение и обратная запись (Complete and Write-Back). На этих двух ступенях инструкции собираются в исходный порядок (в каком они попали в процессор), а их результат записывается в память. Важно, чтобы инструкции были собраны правильно, для "прозрачности" внеочередного выполнения инструкций извне. Для нормального функционирования приложению должно казаться, что все инструкции выполняются последовательно.
Пример всех путешествий инструкций по процессору G4e можно увидеть в этом анимированном GIFе. Предупреждаем, его размер - 355К.
Перед тем как перейти к детальному рассмотрению ступени выполнения G4e обратимся к одному аспекту препроцессора, к устройству обработки ветвлений. (branch processing unit)
Устройство обработки ветвлений BPU и предсказание ветвлений
Если взглянуть на левую часть препроцессора G4e, то можно заметить устройство, расположенное рядом со ступенями выборки и декодирования/отправки. Это устройство обработки ветвлений (branch processing unit, BPU). Оно выполняет руководящую функцию и управляет препроцессором (а, следовательно, и всем остальным процессором). Как только декодер встречает условную инструкцию ветвления, он посылает её на устройство обработки ветвлений. Устройству обработки ветвлений, в свою очередь, требуется отослать эту инструкцию на одно из устройств выполнения, чтобы оценить условие исполнения ветви. Как только BPU определяет, что данная ветвь верна, оно должно вычислить адрес следующего блока кода, который нужно выполнять. Этот адрес ("branch target") должен быть передан препроцессору, чтобы тот начал выборку кода по новому адресу.
Старые процессоры простаивали пока происходила оценка условия ветвления. Условие же могло оцениваться довольно долго - при этом могли выполнятся довольно сложные вычисления. Современные же процессоры используют так называемые "спекулятивные вычисления" ("speculative execution"). Эта техника предсказывает, какую из ветвей выполнять далее, и начинает выполнять эту ветвь до того, как было оценено условие. При таком предсказании используются различные техники "предсказания ветвлений". О них мы поговорим чуть позднее. Спекулятивные вычисления используются для избежания появления пузырьков в конвейере в результате задержек при оценке условий.
При неправильных предсказания такая техника не играет на руку. Если процессор уже начал спекулятивно выполнять все эти инструкции, если он уже загрузил их в конвейер, а потом выяснилось, что их выполнять не надо, процессор должен высвободить весь конвейер. Затем он должен выбрать правильные инструкции по правильному адресу и начать весь процесс выполнения заново. Освобождение конвейера от неправильных инструкций означает, что работа по предсказанию пошла насмарку. Более того, существует задержка (а следовательно в конвейере появляются новые пузырьки), связанная с вычислением правильной ветви и загрузкой нового потока команд в препроцессор. Всё это может значительно сократить производительность, в особенности при интенсивном ветвлении в коде.
Как вы уже вероятно догадались, чем длиннее конвейер в процессоре, тем дороже обходится ошибочное предсказание. Ранее мы уже показали как задержки в потоке команд и сопутствующие им пузырьки могут снизить производительность процессоров с длинными конвейерами, поэтому нет смысла говорить о том, как плачевно отражаются двадцать ступеней конвейера в процессоре P4 на операциях с ветвлением и как долго приходится ожидать выборки новых инструкций из кэша. Кроме того, следует учитывать и то, что чем длиннее конвейер, тем большее количество спекулятивных инструкций можно загрузить в процессор, и соответственно тем больше работы пропадёт даром при ошибочном предсказании.
Минимальные потери неправильного предсказания в P4 - 19 тактов для кода, если он находится в кэше L1. Это только минимум. При других обстоятельствах потери могут быть значительно больше, особенно если в кэше L1 нет кода правильной ветви. (В этом случае потери достигают 30 тактов). Потери же семиступенчатого конвейера G4e при неправильных предсказаниях оказываются значительно меньше. Но всё равно, его потери все же больше, чем у классического предшественника G4. Так, в G4е они составляют 6 тактов, а потери G4 - 4 такта.
Существует два вида предсказаний: статические и динамические. Статические предсказание просты, и берут за основу предположение, что большинство обратных ветвлений происходит в повторяющихся циклах, когда инструкция ветвления используется для определения продолжения цикла или выхода из него. Чаще всего цикл продолжается, так что компьютер будет снова повторно выполнять код цикла. По этой причине статическое предсказание считает что все обратные ветвления всегда выполняются. Если же ветвление указывает на блок кода, который существует дальше в программе, то статическое предсказание не будет выполнять такую ветвь.
Статические предсказания очень быстры, так как при этом не требуется дополнительных проверок или вычислений. Но эффективность таких предсказаний довольно сильно варьируется. В случае, когда в программе много циклов, статические предсказания прекрасно работают. В противном случае, производительность значительно снижается. Для разрешения проблем, связанных с предсказаниями, разработчики процессоров используют различные алгоритмы предсказания ветвлений. Алгоритмы "динамического предсказания ветвлений" обычно задействуют одну из таблиц - для хранения истории предсказаний ветвлений (Branch History Table, BHT) или для хранения адресов инструкций (Branch Target Buffer, BTB). Либо используется сразу оба типа таблиц. В таблицы записывается информация о результатах уже выполненных ветвлений. В BHT содержатся все условные переходы, что встретились устройству предсказания ветвлений за несколько последних циклов. Кроме того, здесь хранятся биты, показывающие вероятность повторного выбора той же самой ветви. Биты расставляются на основании статистики предыдущих переходов. В стандартной 2-битной схеме истории ветвления существует четыре вероятности: ветвь часто выполняется (strongly taken), ветвь выполняется (taken), ветвь не выполняется (not taken), и ветвь часто не выполняется (strongly not taken). Когда препроцессор встречает инструкцию ветвления, уже содержащуюся в BHT, устройство предсказания ветвлений использует информацию для решения о выполнении спекулятивной инструкции.
Для того, чтобы вынести решение о спекулятивном выполнении ветви, устройство должно знать точное местоположение кода в кэше L1 по направлению ветвления, назовем его целью ветвления. Цели уже выполненных ветвлений хранятся в BTB. Когда выполняется ветвление, BPU просто берёт цель ветвления из таблицы и указывает препроцессору начать выборку инструкций по этому адресу. Будем считать, что в таблице уже имеется адрес той ветви, что мы пытаемся выполнить, и будем считать, что он правильный. В противном случае мы столкнёмся с проблемой. Не будем вдаваться в подробности о влиянии BTB на производительность, просто скажем, что чем больше таблица, тем лучше.
Чтобы справиться с задержками и неправильными предсказаниями, G4e и P4 используют оба метода (статический и динамический) для предсказания ветвлений. Если в BHT нет инструкции ветвления, то оба процессора будут использовать статическое предсказание для выбора дальнейших действий. Если же инструкция в BHT есть, то оба процессора воспользуются динамическим предсказанием. Заметим, что в P4 таблица истории довольно велика - до 4096 записей, что вполне достаточно для хранения информации о большинстве ветвлений средней программы. Заметим также, что доля успешных предсказаний у его предшественника, PIII составляет около 91%. Утверждают, что у P4 эта цифра ещё больше, так как он использует более эффективные алгоритмы предсказаний. Кроме того, P4 использует BTB для хранения предсказанных адресов ветвления. В документации Intel BHT и BTB обозначены как "the front-end BTB."
Таблица истории G4e умещает до 2048 записей. В G4 это число составляло 512. Мы не обладаем данными об успешности предсказаний этого процессора, но думаем, что она довольно хороша. G4e обладает кэшем адресов инструкций (Branch Target Instruction Cache, BTIC) на 128 записей, эквивалент BTB в P4. В G4 этот кэш был размером всего в 64 записи.
Однако следует отметить, что оба процессора расходуют на предсказания ветвлений больше ресурсов, чем их предшественники. Причиной тому являются их длинные конвейеры, которые при ошибочных предсказаниях снижают производительность процессора.
У P4 есть ещё один финт (очень сомнительный) - "подсказки программного уровня" ("software branch hints") - небольшие префиксы, которые помещаются компилятором или программистом перед условными операторами ветвления. С помощью этих префиксов устройство предсказания может судить о предполагаемом направлении ветвления. Информации об эффективности этих префиксов крайне мало, и Intel рекомендует ими не злоупотреблять, так как это может привести к увеличению программного кода.
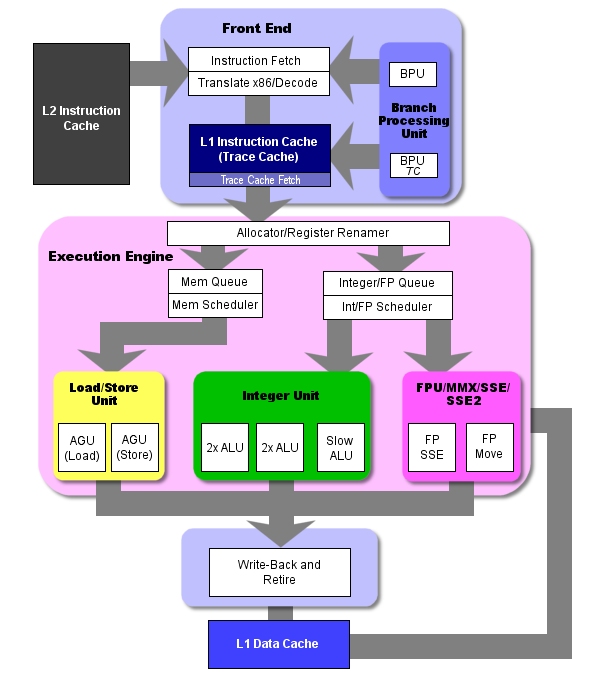
Архитектура P4. Кэш с отслеживаниями (trace cache)
Хотя конвейер P4 является намного более длинным, он выполняет те же функции что и G4e. На следующем рисунке изображена архитектура P4. Можно сравнить этот рисунок с архитектурой G4e. Из-за сложности архитектуры и ограничений в пространстве, мы не изображаем здесь каждую из ступеней конвейера, как это было сделано в рисунке с архитектурой G4e. Тем не менее, мы сгруппировали связанные ступени воедино, чтобы вы смогли представить всю схему процессора и схему потока команд.
Обратите внимание на то, что кэш L1 разделён, и его кэш инструкций находится фактически на препроцессоре. Он называется кэшем с отслеживаниями (trace cache) и является одной из важных инноваций в P4. Этот кэш оказывает сильное влияние и на конвейер, и на основной поток инструкций. Поэтому перед тем как детально обсуждать конвейер P4 мы рассмотрим, что представляет собой этот кэш.
В процессорах с микроархитектурой x86, таких как PIII или Athlon, инструкции поступают в декодер из кэша инструкций, в декодере они разбиваются на меньшие части, более единообразные, с которыми проще работать. Их также называют микрокомандами (mops). Фактически эти инструкции применяются при внеочередном выполнении команд, исполнительный модуль выполняет их планирование, исполнение и сброс.
Такое разбиение случается всякий раз, когда процессор выполняет инструкцию, поэтому на эту операцию в начале конвейера отводится несколько ступеней. (Заметим, что на следующих двух рисунках эти ступени объединены. То есть выборка инструкций занимает несколько ступеней, транслирование - несколько ступеней, декодирование - несколько , и так далее)
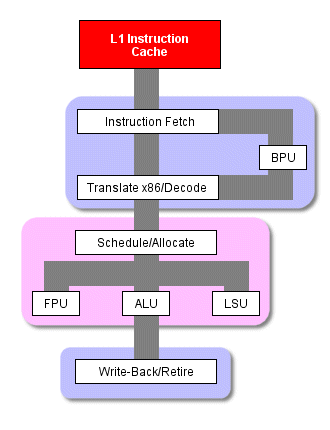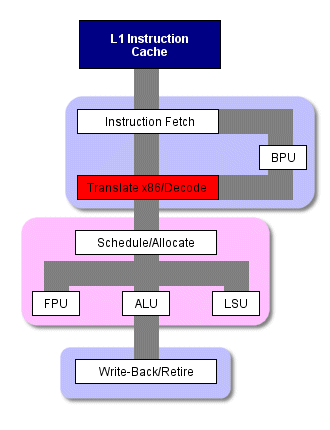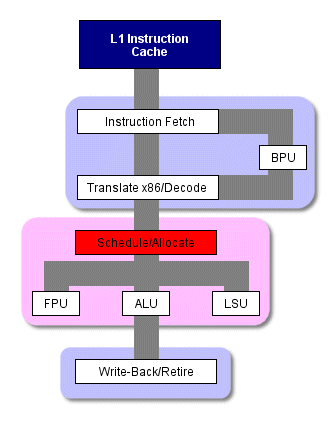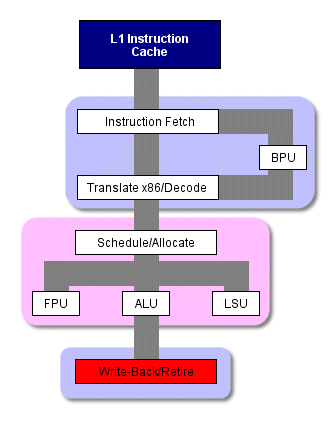
Стандартная схема работы x86 процессора
Если взять кусочек кода, повторно выполняющийся всего несколько раз по ходу программы, то для него такая потеря нескольких тактов мало что означает. Но для кусочка кода, где инструкции исполняются тысячи и тысячи раз (например, в цикле в мультимедийном приложении, выполняющем несколько операций над большим файлом),
количество повторных трансляций и декодирований может отнимать ощутимые ресурсы. Для того чтобы избежать таких циклов, процессор P4 повторно не разбивает x86 инструкции на микрокоманды при их выполнении.
Кэш инструкций P4 принимает транслированные и декодированные микрокоманды, готовые к передаче на внеочередное выполнение, и формирует из них мини-программы, называемые "отслеживаниями" ("traces"). Именно эти мини-программы (а не x86 код, созданный компилятором) и выполняет P4 в том случае, если происходит попадание в L1 кэш (процент попадания - более 90%). До тех пор, пока требуемый код находится в кэше L1, схема выполнения выглядит следующим образом.
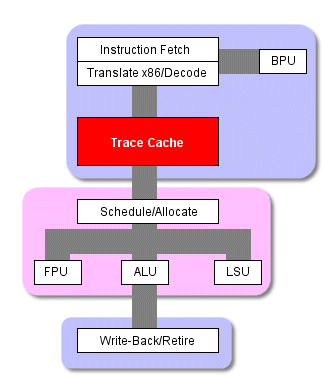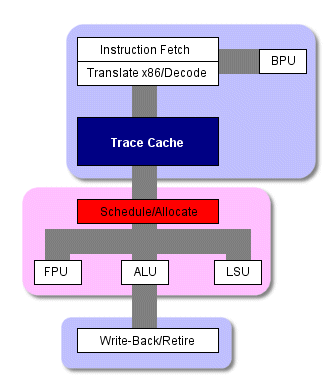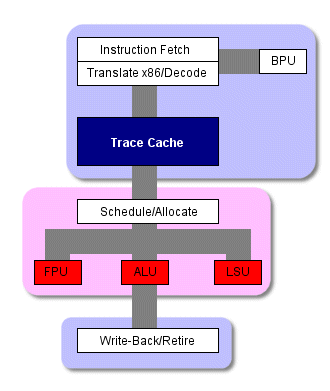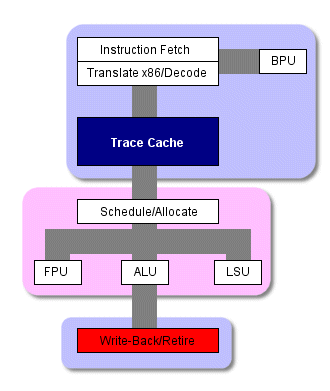
Схема работы процессора P4
По мере выполнения препроцессором накопленных отслеживаний, кэш с отслеживаниями посылает до трех микрокоманд за такт напрямую на внеочередной модуль выполнения, сейчас процессору уже не нужно проводить команды через логику трансляции или декодирования. И только в случае промаха кэша L1 препроцессор нарушит этот порядок и начнёт выбирать и декодировать инструкции из кэша L2. В этом случае к началу основного конвейера добавляется ещё восемь ступеней. Как вы видите, кэш с отслеживаниями может избавить от довольно большого количества тактов при выполнения программы.
Кэш с отслеживаниями работает в двух режимах. "Исполнительный режим" ("Execute mode") проиллюстрирован выше. Здесь кэш снабжает логику выполнения инструкциями. В этом режиме он обычно и работает. Когда наступает промах кэша L1, кэш переходит в "режим построения отслеживающих сегментов" ("trace segment build mode") В этом режиме препроцессор выбирает x86 инструкции из кэша L2, транслирует их в микрокоманды, создаёт отслеживающий сегмент, который затем перемещается в кэш с отслеживаниями и далее выполняется.
На рисунке видно, когда работает кэш с отслеживаниями - устройство предсказания ветвлений не участвует в работе, равно как не работают и ступени выборки/декодирования инструкций. На самом деле отслеживающий сегмент - это нечто большее, чем просто кусок транслированного и декодированного кода x86, выданного компилятором и полученного препроцессором из кэша L2. В действительности, при создании мини-программы кэш с отслеживаниями все же использует предсказание ветвлений. Он может добавить в мини-программу (где содержится предназначенный для выполнения код) код, который только предполагается к выполнению при предсказании ветвления. Поэтому если у вас есть кусок x86 кода с ветвлением, кэш с отслеживаниями построит отслеживание из инструкций до ветвления, включая саму инструкцию ветвления. Затем он продолжит спекулятивно строить мини-программу вдоль предсказанной ветви.
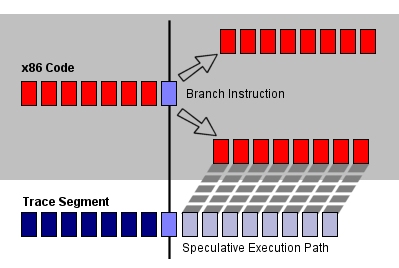
Такое спекулятивное выполнение даёт кэшу с отслеживаниями два больших преимущества по сравнению с обычным кэшем инструкций. Во-первых, в стандартном процессоре для работы устройства предсказания ветвлений требуется некоторое время. При обработке условной инструкции ветвления, BPU должно определить, какую из ветвей нужно спекулятивно выполнять, найти адрес кода после ветвления и так далее. Весь этот процесс добавляет, по крайней мере, ещё один такт задержки для каждой условной инструкции ветвления. Такая задержка часто не может быть заполнена выполнением другого кода, что приводит к появлению нежелательного пузырька. В случае же использования кэша с отслеживаниями, код после ветвления уже готов к выполнению сразу же после инструкции ветвления, поэтому показанных задержек не возникает.
Второе преимущество также связано с возможностью хранения спекулятивных ветвей. Когда стандартный кэш инструкций L1 считывает строку кэша из памяти, он прекращает считывание при попадании на инструкцию ветвления, поэтому оставшаяся часть строки остается пустой. Если инструкция ветвления находится вначале строки кэша L1, то в считанной строчке будет находиться только одна эта инструкция. При использовании кэша с отслеживаниями считанные строчки могут содержать как инструкции ветвления, так и спекулятивный код после них. Таким образом, в 6-командных строчках не возникает потерянного места.
Кстати, большинство компиляторов сталкиваются именно с описанными двумя проблемами: с задержками в инструкциях ветвления и с неполными строками кэша. Как мы видим, кэш с отслеживаниями по-своему позволяет решать эти проблемы. Если программы оптимизированы с учетом этих возможностей, то они будут быстрее выполняться.
Ещё один интересный эффект, производимый этим кэшем на препроцессор P4 заключается в том, что пропускная способность ступеней транслирования и декодирования x86 команд не зависит от пропускной способности ступени диспетчеризации. Если вспомнить процессор K7, то он расходует множество транзисторов на усиленный блок декодирования x86 макрокоманд, что позволяет за цикл декодировать достаточно много громоздких x86 инструкций в макрокоманды (MacroOps, K7 вариант mops в P4) для загрузки исполнительного модуля. В случае же P4 наличие кэша с отслеживаниями означает, что большая часть кода забирается из кэша с отслеживаниями уже в виде готовых микрокоманд, так что здесь отпадает надобность в трансляторах и декодерах с высокой пропускной способностью.
Процессор начинает декодирование только лишь в случае промаха кэша L1. Поэтому он разработан таким образом, чтобы декодировать только одну x86 инструкцию за такт. Это составляет всего треть от максимальной теоретической пропускной способности декодера Athlon, но кэш с отслеживаниями в P4 позволяет ему достичь или даже обойти производительность Athlon (2,5 диспетчеризации за такт).
Стоит обратить внимание и на то, как кэш с отслеживаниями обращается с очень длинными x86 инструкциями из нескольких циклов. Вы, вероятно, знаете, что большинство x86 инструкций декодируются примерно в две или три микрокоманды. Но встречаются и такие инструкции (к счастью, редко), которые декодируются в сотни микрокоманд, например, инструкции по строковой обработке. Как и в Athlon, в P4 существует специальное ПЗУ микрокода, которое обрабатывает эти громоздкие инструкции, что позволяет разгрузить аппаратный декодер для работы только с небольшими, быстрыми инструкциями. Каждый раз, когда встречается громоздкая инструкция, ПЗУ находит готовую последовательность микрокоманд и выдаёт их дальше в по очереди. Чтобы не засорять кэш с отслеживаниями этими длинными последовательностями микрокоманд, разработчики поступили следующим образом. Как только при создании отслеживающего сегмента кэш с отслеживаниями встречает такую большую x86 инструкцию, вместо того, чтобы разбивать её на последовательность микрокоманд, он вставляет в отслеживающий сегмент метку (tag), которая указывает на место в ПЗУ, содержащее последовательность микрокоманд данной инструкции. Позднее, в режиме выполнения, когда кэш с отслеживаниями будет передавать поток инструкций на ступень выполнения, при попадании на такую метку, он временно приостановит работу и на время передаст управление потоком инструкций микрокоду ПЗУ. Здесь уже ПЗУ будет выдавать в поток инструкций требуемую последовательность микрокоманд (как определено меткой). После этого, оно возвратит управление обратно, и кэш с отслеживаниями продолжит передавать инструкции. Исполнительному модулю безразлично, откуда поступает поток инструкций (из кэша или из ПЗУ). Для него все это выглядит как непрерывный поток команд.
Единственным недостатком кэша с отслеживаниями является его размер. Кэш слишком мал. Мы не знаем точных размеров этого кэша инструкций. Знаем только, что он может содержать до 12 тысяч микрокоманд. Intel уверяет, что это примерно эквивалентно обычному кэшу команд на 16-18 тысяч инструкций. Но так как кэш с отслеживаниями работает совсем иначе, нежели стандартный кэш инструкций L1, то для того, чтобы оценить, как его размер влияет на производительность всей системы, нельзя обойтись простым сравнением его размера с кэшем другого процессора. Впрочем, это тема для отдельной беседы.
В итоге отметим следующее. Во-первых, кэшу с отслеживаниями всё же необходима короткая ступень выборки инструкций, ведь сначала необходимо выбрать микрокоманды из кэша, а уже за тем пересылать их дальше. Если вы посмотрите на основной исполнительный конвейер P4, то вы заметите эту ступень. Во-вторых, кэш с отслеживаниями обладает своими средствами (мини-BTB и BPU) для предсказания ветвлений внутри кэша с отслеживаниями. Поэтому нельзя говорить, что кэш с отслеживаниями ликвидирует механизм предсказания ветвлений. Кэш просто смягчает отражение негативных последствий ветвлений на производительности.
Архитектура P4. Конвейер
Давайте вернёмся к рассмотрению основного исполнительного конвейера P4. Но сначала следует пояснить некоторые вещи применительно к приведенным диаграммам и таблицам. С препроцессором P4 все в порядке: логика планирования, переименования и другая логика внеочередного выполнения переведена на постпроцессор. Но вы также можете заметить, что с G4e все обстоит несколько иначе. В информации по G4 ступень очереди выдачи считается частью препроцессора, а резервации - частью постпроцессора, поэтому ступень выдачи конвейера G4 (а она имеет отношение к внеочередному выполнению) как бы соединяет постпроцессор и препроцессор.
Ступени 1 и 2 Trace Cache next Instruction Pointer, кэш с отслеживаниями получает указатель на следующие инструкции. На этих ступенях в логику кэша передаётся указатель на следующую инструкцию в кэше с отслеживаниями.
Ступени 3 и 4 Trace Cache Fetch, выборка в кэше с отслеживаниями. На этих двух ступенях происходит выборка инструкций из кэша. Затем эти инструкции будут отосланы на внеочередное выполнение.
Ступень 5 Drive. Это первая из двух передаточных ступеней конвейера. Каждая из них предназначена для передачи сигналов из одной части процессора в следующую. Процессор работает настолько быстро, что иногда сигналы не могут пройти весь путь за один тактовый импульс, поэтому в P4 выделено несколько ступеней конвейера для передачи сигнала по чипу. Отметим, что раньше нам эта ступень в конвейерах не встречалось. Как мне кажется, Intel первой внедрила эту ступень в конвейерную технологию. Без такого рода ступеней невозможно достичь таких высоких частот.

1 - 5 ступени
Ступени 6, 7, 8 Allocate and Rename , распределение и переименование. На этих ступенях происходит распределение микроархитектурных ресурсов регистров. Большинство из вас, наверное, знает, что с помощью переименования регистров можно добиться бесконфликтного существования большего количества регистров в микроархитектуре, чем это определено архитектурой набора команд (instruction set architecture, ISA). Эти дополнительные регистры как раз распределяются и используются на этой стадии. Отметим, что в P4 таких дополнительных регистров 128.
Ступени распределения/переименования могут выпустить три микрокоманды за такт на следующую ступень конвейера.
Ступень 9, Queue, очередь. Отметим, что между ступенями распределения/переименования и распределяющей логикой существуют две очереди. Это очередь микрокоманд памяти, и очередь арифметических микрокоманд. Именно в эти очереди и распределяются микрокоманды перед тем, как попасть на один из четырёх портов диспетчера, работающего в качестве шлюза к функциональным устройствам стадии выполнения.
Ступени 10, 11, 12 Schedule, распределение/планирование. На этих ступенях инструкции поступают из устройства распределения (Allocator) в одну из четырёх очередей распределения. В качестве грубого аналога этим очередям можно привести три разные очереди в G4e, которые ведут в три различных функциональных устройства (или в группу связанных функциональных устройств). Далее мы процитируем Intel где и подытожим функции этой ступени.
Распределитель микрокоманд (sheduler) следит за входным регистровым операндом (register operands) микрокоманд и определяет, какую из микрокоманд уже можно выполнять. Это суть внеочередного выполнения команд. Распределитель микрокоманд позволяет посылать на ступень выполнения микрокоманды как только они будут готовы (изменяя нормальных порядок), и при этом поддерживает нормальный ход программы. Микроархитектура NetBurst использует два устройства, с помощью которых происходит распределение микрокоманд: сам распределитель, и очередь микрокоманд.
Ниже представлена схема четырёх распределителей:
Memory Scheduler, распределитель памяти - это устройство распределяет операции по работе с памятью для устройств Load/Store Unit, LSU.
Fast ALU Scheduler, быстрый распределитель арифметико-логического устройства - это устройство распределяет арифметико-логические операции (простые целочисленные и логические операции), чтобы послать их потом на ALU P4, работающее на двойной скорости. Сразу скажем, что в P4 есть целых два ALU, работающих на двойной скорости.
Slow ALU/General FPU Scheduler (медленный распределитель ALU/распределитель операций с плавающей точкой) - это устройство распределяет остальные операции ALU и операции с плавающей точкой.
Simple FP Scheduler, распределитель простых операций с плавающей точкой - распределяет простые операции с плавающей точкой и операции по доступу к памяти с плавающей точкой.
Все эти распределители используют четыре входа диспетчеризации, о которых мы расскажем чуть позднее.

Ступени с шестой по двенадцатую
Ступени 13 и 14 - Dispatch, диспетчеризация. На этих ступенях инструкции попадают на один из четырёх портов диспетчеризации (dispatch ports), а затем - на выполнение. Эти порты выполняют функцию шлюзов к функциональным устройствам. За один такт через эти порты может пройти до шести микрокоманд. Это больше, чем может выполнить препроцессор (3 микрокоманды за такт). Это также больше, чем может сбросить постпроцессор (Тоже 3 микрокоманды за такт). Это даёт некоторую свободу в случае вспышки активности.
На этой диаграмме представлены четыре порта диспетчеризации и типы инструкций, которые они могут принять. Если указать на диаграмме распределители, то они были бы размещены над четырьмя портами.
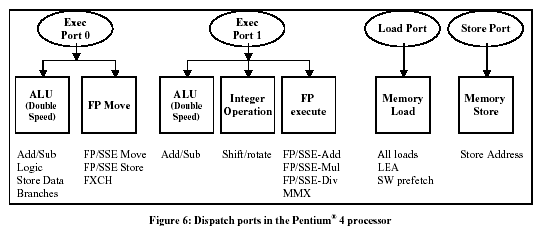
Порты диспетчеризации (Dispatch ports)
Ступени 15 и 16 - Register Files, блок регистров
После того, как инструкции пройдут порты диспетчеризации, они попадают на две эти ступени. Здесь инструкции загружаются в блок регистров для дальнейшего выполнения.
Ступень 17 - Execute, выполнение. На этой ступени инструкции выполняются в функциональных устройствах. (Вообще говоря, это и есть самая главная стадия, ради которой и приходится проделывать весь этот длинный путь. Если это инструкция ADD, то цифры складываются, если это LOAD, то в память загружаются какие-то данные, если это MUL, то цифры перемножаются и так далее)

Ступени с 13 по 17
Ступень 18 - Flags, флаги. Если результат выполнения инструкции требует изменения состоянии флагов, именно на этой ступени и выполняется эта операция.
Ступень 19 - Branch Check, проверка ветвления. На этой ступени P4 проверяет выполнение условия ветвления и определяет, напрасно были затрачены 19 тактов, или всё-таки нет. То есть препроцессор узнает, сбылось ли предсказание ветвления.
Ступень 20. Drive, вторая передаточная ступень. Мы уже встречали первую передаточную ступень. Эта ступень выполняет те же функции распространения сигнала по чипу.
Ступени 18 - 20
Как вы заметили, 20-ступенчатый конвейер P4 выполняет ту же работу в том же порядке, что и 7-ступенчатый конвейер G4. Однако разбиение конвейера на большее число ступеней позволяет P4 достичь больших тактовых частот.
На этом закончим... Мы довольно подробно рассмотрели работу P4 и G4e и некоторые детали этих двух архитектур с тем, чтобы понять, как работает каждый из процессоров.
В обзоре использованы материалы Arstechnica, Intel и Apple.
Дополнительные материалы:
 AMD Thoroughbred Athlon XP. Стресс-тест
AMD Athlon XP : Thoroughbred
Intel Celeron 1700 на ядре P4
Intel Celeron 1300 против AMD Duron 1200
AMD Hammer
AMD Athlon XP 2000+ против Intel 0,13 мкм P4 Northwood
Практическое руководство по разгону Athlon XP, тестирование Athlon XP 2000+
AMD Athlon XP 1900+
Intel Pentium III 1266 (Tualatin)
Intel Xeon 1.7 GHz
Intel Pentium 4 1.4GHz
AMD Athlon XP: производительность выше мегагерц!
Степпинги процессоров AMD
Intel Pentium III 700E
Intel Pentium III 600E
AMD Thoroughbred Athlon XP. Стресс-тест
AMD Athlon XP : Thoroughbred
Intel Celeron 1700 на ядре P4
Intel Celeron 1300 против AMD Duron 1200
AMD Hammer
AMD Athlon XP 2000+ против Intel 0,13 мкм P4 Northwood
Практическое руководство по разгону Athlon XP, тестирование Athlon XP 2000+
AMD Athlon XP 1900+
Intel Pentium III 1266 (Tualatin)
Intel Xeon 1.7 GHz
Intel Pentium 4 1.4GHz
AMD Athlon XP: производительность выше мегагерц!
Степпинги процессоров AMD
Intel Pentium III 700E
Intel Pentium III 600E
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex






 Подписаться
Подписаться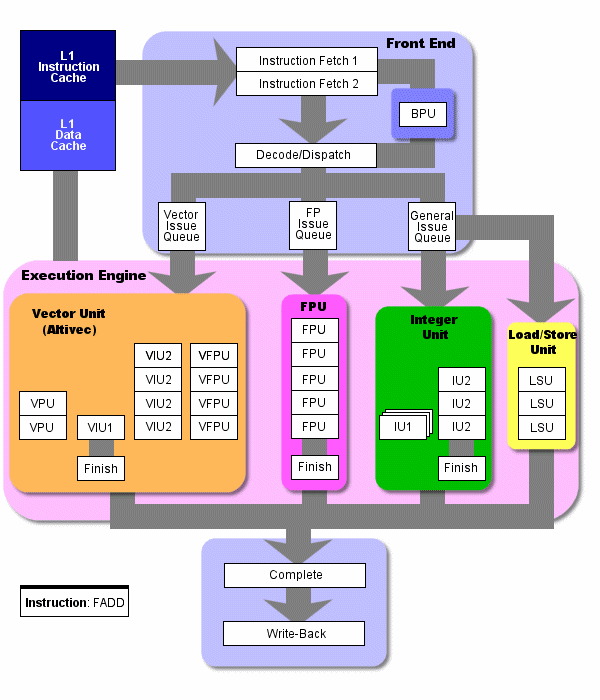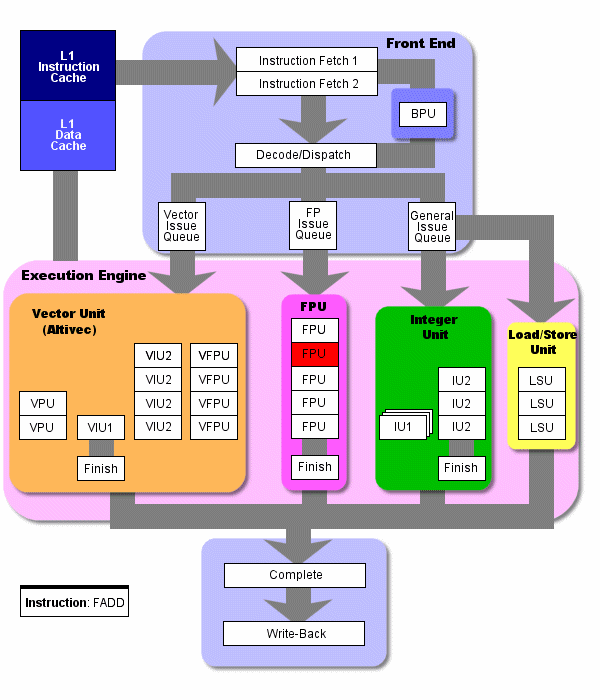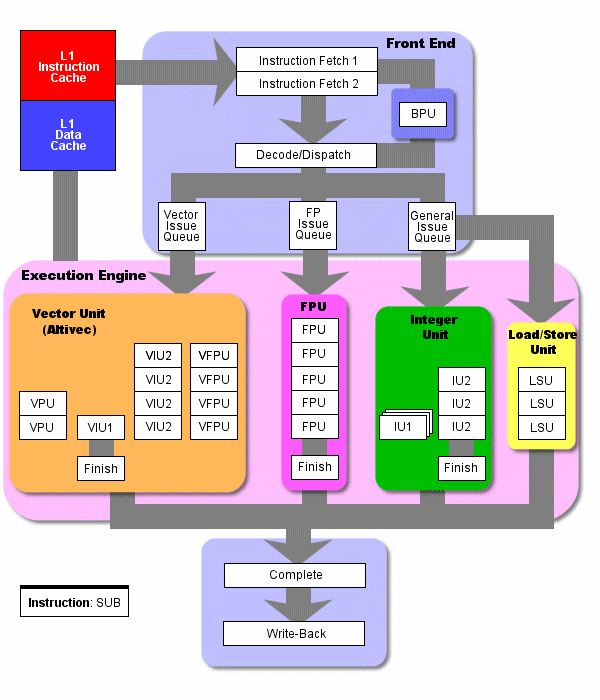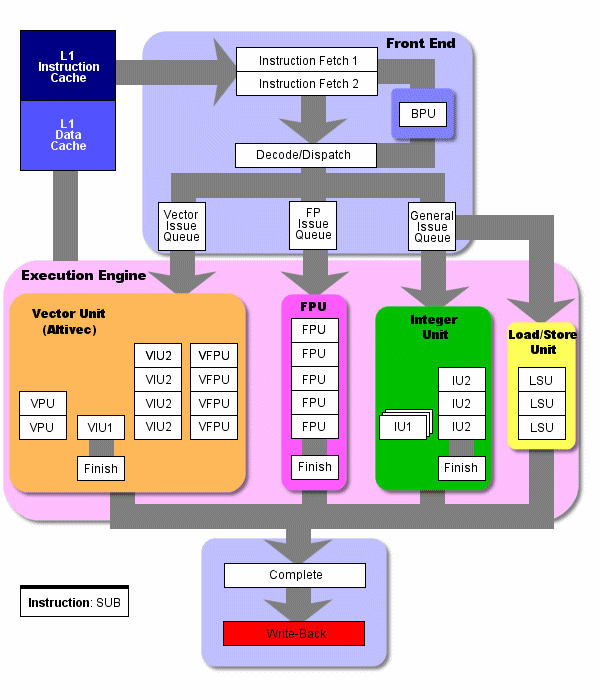{kind=link}