Философия дизайна P4 и G4e
В отличие от классического варианта, когда весь конвейер состоит из четырёх ступеней (как описано выше), в большинстве современных процессоров всё выглядит несколько по-другому. Например, в G4e вместо классических четырёх ступеней, конвейер разбивается на семь ступеней, что позволяет ему работать на более высокой тактовой частоте при одинаковом технологическом процессе. На каждой из ступеней выполняется меньшее количество работы, но при этом работа выполняется за меньшее количество времени. Так как каждая ступень всегда выполняется ровно за один такт, то более короткие ступени приводят к меньшей продолжительности тактов и возможности работы на более высокой тактовой частоте. В P4 с целыми двадцатью ступенями в основном конвейере эта тактика доведена до крайности. Взгляните на следующую диаграмму. Здесь представлена относительная частота последних шести процессоров Intel с архитектурой x86. (Предполагается, что технологический процесс всех процессоров одинаков).
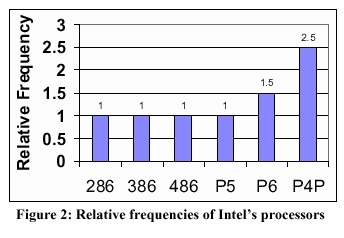
Давайте посмотрим, как Intel объясняет эту картину.
На этой диаграмме видно, что глубина конвейера у процессоров 286, Intel 386™ , Intel 486™ и Pentium® (P5) одинакова. То есть если бы они были выполнены по одной кремниевой технологии, частота у них была бы одинаковой. Все они выполняют одинаковое количество логических операций на каждой из ступеней. В архитектуре P6 конвейер удлинён. При этом на каждой из ступеней выполняется меньшее количество логических операций, что позволяет существенно увеличить частоты и производительность. В архитектуре P6 количество ступеней в конвейере увеличено примерно в два раза по сравнению с предыдущими моделями. Это позволило достичь увеличения частоты в полтора раза при одинаковом технологическом процессе. В процессоре P4 была использована архитектура NetBurst, у которой количество ступеней в два раза выше по сравнению с конвейером P6.
Как мы видим, Pentium 4 жертвует довольно многим для увеличения тактовой частоты. И хотя Intel и пытается обыграть этот факт несколько по-другому, большая глубина конвейера - одна из таких "жертв".
Многие объяснят большую разницу в глубине конвейеров P4 и G4e тем, что современным x86 процессорам, таким как Athlon, PIII и P4 приходится разбивать большие, сложные x86 инструкции на маленькие, легко выполняемые инструкции. Действительно, такая операция по разбиению инструкций добавляет новые ступени в конвейер P4, но они добавляются не к основным двадцати ступеням. (Процессору все еще необходимо транслировать инструкции в чops, но как мы увидим позднее, кэш с отслеживанием позволяет проводить транслирование и декодирование вне основного конвейера P4).
Такое радикальное отличие в глубине конвейеров G4e и P4 отражено и в философии дизайна самих процессоров. Задача обоих процессоров - выполнить максимальное количество инструкций за минимальное время, но подход к этой задаче у обоих процессоров разный. Подход G4e можно обозначить как "много коротких конвейеров". Разработчики просто добавили несколько дополнительных устройств к постпроцессору для выполнения инструкций, а препроцессор должен параллельно обеспечивать эти устройства инструкциями. Для того чтобы разбить линейный поток команд на максимальное количество параллельных инструкций (instruction-level parallelism (ILP)), препроцессор G4e сначала перемещает серию команд на чип. Затем его логика вне очереди (out-of-order, OOO) проверяет взаимозависимости и посылает инструкции на параллельное выполнение на девять функциональных устройств исполнительного модуля. Каждое из функциональных устройств обладает довольно маленьким конвейером, поэтому инструкции проходят эту ступень за небольшое количество циклов. На последних ступенях конвейера инструкции преобразуются обратно в линейный вид (как в оригинальной программе), затем результат записывается в память.
В каждый момент G4e может одновременно выполнять до 16 инструкций, находящихся на различных ступенях выполнения. Как мы увидим позднее, окно инструкций у G4e имеет довольно небольшой размер по сравнению с P4. Итак, G4e получает на процессор небольшое количество инструкций, распределяет их на параллельное выполнение и выполняет их за минимальное количество циклов.
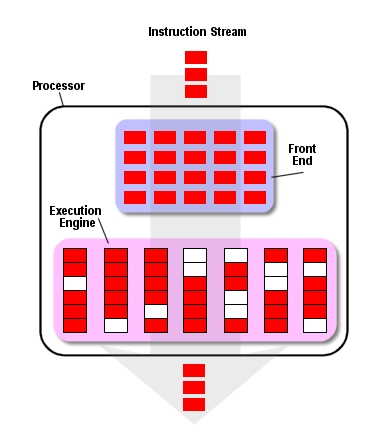
Так работает G4e
В P4 реализован другой подход. На ступени выполнения там используется меньшее количество функциональных устройств. Но каждое из них обладает более длинным и более быстрым конвейером. Это означает, что каждое функциональное устройство имеет большее количество доступных для выполнения тактов (execution slots) и таким образом способно одновременно выполнять довольно много инструкций. Так, скажем, вместо трёх устройств для выполнения операций с плавающей точкой, работающих медленно, но параллельно, P4 имеет только одно такое устройство, которое может быстрее одновременно выполнять большее количество инструкций на различных ступенях.
Важно отметить, что для того, чтобы полностью загружать быстрые конвейерные функциональные устройства в P4, препроцессор должен обладать большим буфером, способным вмещать в себя и планировать огромное количество инструкций. Процессор P4 может одновременно выполнять на различных ступенях до 126 инструкций. Отсюда следует, что для внеочередного выполнения процессор должен анализировать значительно большее количество инструкций на взаимозависимость, а затем преобразовывать их для быстрой передачи функциональным устройствам.

Так работает P4
Для лучшего понимания сути вопроса можно обратиться к аналогии в индустрии фастфуд. В МакДональдс вы можете либо прийти пешком, либо приехать. В первом случае, вы увидите шесть коротеньких очередей. Вы можете встать в любую, и подождать своей очереди, чтобы вас обслуживал один человек. Во втором случае, вы попадёте в одну большую очередь. Но очередь будет обслуживаться быстрее, так как там работает несколько человек. Первому вы сделаете заказ, а у второго вы этот заказ заберёте. Так как процесс обслуживания разбивается на несколько этапов, то большее количество посетителей смогут получить еду в одной большой очереди. Так вот, G4e использует первый вариант, а P4 - второй.
Опасность длинных конвейеров
В определённых типах приложений схема работы P4 имеет преимущества, здесь можно назвать 3D-приложения и потоковые мультимедийные приложения. Но такая схема и многим рискует. Неприятности начинаются тогда, когда у процессора не хватает инструкций или данных для конвейера в кэше L1. Вы наверняка заметили пустые такты в рисунке про работу G4e. (Пустые такты обозначены белым цветом, а такты с инструкциями - красным). Эти пустые такты, называемые "конвейерными пузырьками" ("pipeline bubbles") появляются, когда процессору не хватает инструкций для выполнения. Эти пузырьки должны пройти все ступени до конца конвейера, таким образом, тратится впустую драгоценное время процессора.
Если сравнить P4 c G4e, то при попадании такого пузырька в многоступенчатый конвейер P4 тратится намного больше времени на то, чтобы этот пузырёк исчез. Так, попав в двадцатиступенчатый конвейер P4, один пузырёк затратит 20 тактов до своего выхода (даже ещё больше, если этот пузырёк находится в одном из длинных конвейеров FPU). А в семиступенчатом конвейере G4e он затратит всего лишь 7 тактов. 20 тактов - большие расходы. Даже если бы тактовая частота P4 была в два раза больше G4e, всё равно пузырёк бы исчезал быстрее в G4e.

Чем больше ступеней в конвейере, тем с большими проблемами сталкивается процессор при недостатке инструкций. Так как разработчики P4 при создании новой архитектуры руководствовались мегагерцами, то им пришлось много поработать над избежанием этих пузырьков. Мы уже обсудили очень длинные очереди на препроцессоре P4. Именно здесь P4 задействует большое количество транзисторов чтобы уменьшить негативный эффект многоступенчатого конвейера. В G4e эти транзисторы используются для создания дополнительных исполнительных модулей.
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex




