Архитектура P4. Конвейер
Давайте вернёмся к рассмотрению основного исполнительного конвейера P4. Но сначала следует пояснить некоторые вещи применительно к приведенным диаграммам и таблицам. С препроцессором P4 все в порядке: логика планирования, переименования и другая логика внеочередного выполнения переведена на постпроцессор. Но вы также можете заметить, что с G4e все обстоит несколько иначе. В информации по G4 ступень очереди выдачи считается частью препроцессора, а резервации - частью постпроцессора, поэтому ступень выдачи конвейера G4 (а она имеет отношение к внеочередному выполнению) как бы соединяет постпроцессор и препроцессор.
Ступени 1 и 2 Trace Cache next Instruction Pointer, кэш с отслеживаниями получает указатель на следующие инструкции. На этих ступенях в логику кэша передаётся указатель на следующую инструкцию в кэше с отслеживаниями.
Ступени 3 и 4 Trace Cache Fetch, выборка в кэше с отслеживаниями. На этих двух ступенях происходит выборка инструкций из кэша. Затем эти инструкции будут отосланы на внеочередное выполнение.
Ступень 5 Drive. Это первая из двух передаточных ступеней конвейера. Каждая из них предназначена для передачи сигналов из одной части процессора в следующую. Процессор работает настолько быстро, что иногда сигналы не могут пройти весь путь за один тактовый импульс, поэтому в P4 выделено несколько ступеней конвейера для передачи сигнала по чипу. Отметим, что раньше нам эта ступень в конвейерах не встречалось. Как мне кажется, Intel первой внедрила эту ступень в конвейерную технологию. Без такого рода ступеней невозможно достичь таких высоких частот.

1 - 5 ступени
Ступени 6, 7, 8 Allocate and Rename , распределение и переименование. На этих ступенях происходит распределение микроархитектурных ресурсов регистров. Большинство из вас, наверное, знает, что с помощью переименования регистров можно добиться бесконфликтного существования большего количества регистров в микроархитектуре, чем это определено архитектурой набора команд (instruction set architecture, ISA). Эти дополнительные регистры как раз распределяются и используются на этой стадии. Отметим, что в P4 таких дополнительных регистров 128.
Ступени распределения/переименования могут выпустить три микрокоманды за такт на следующую ступень конвейера.
Ступень 9, Queue, очередь. Отметим, что между ступенями распределения/переименования и распределяющей логикой существуют две очереди. Это очередь микрокоманд памяти, и очередь арифметических микрокоманд. Именно в эти очереди и распределяются микрокоманды перед тем, как попасть на один из четырёх портов диспетчера, работающего в качестве шлюза к функциональным устройствам стадии выполнения.
Ступени 10, 11, 12 Schedule, распределение/планирование. На этих ступенях инструкции поступают из устройства распределения (Allocator) в одну из четырёх очередей распределения. В качестве грубого аналога этим очередям можно привести три разные очереди в G4e, которые ведут в три различных функциональных устройства (или в группу связанных функциональных устройств). Далее мы процитируем Intel где и подытожим функции этой ступени.
Распределитель микрокоманд (sheduler) следит за входным регистровым операндом (register operands) микрокоманд и определяет, какую из микрокоманд уже можно выполнять. Это суть внеочередного выполнения команд. Распределитель микрокоманд позволяет посылать на ступень выполнения микрокоманды как только они будут готовы (изменяя нормальных порядок), и при этом поддерживает нормальный ход программы. Микроархитектура NetBurst использует два устройства, с помощью которых происходит распределение микрокоманд: сам распределитель, и очередь микрокоманд.
Ниже представлена схема четырёх распределителей:
Memory Scheduler, распределитель памяти - это устройство распределяет операции по работе с памятью для устройств Load/Store Unit, LSU.
Fast ALU Scheduler, быстрый распределитель арифметико-логического устройства - это устройство распределяет арифметико-логические операции (простые целочисленные и логические операции), чтобы послать их потом на ALU P4, работающее на двойной скорости. Сразу скажем, что в P4 есть целых два ALU, работающих на двойной скорости.
Slow ALU/General FPU Scheduler (медленный распределитель ALU/распределитель операций с плавающей точкой) - это устройство распределяет остальные операции ALU и операции с плавающей точкой.
Simple FP Scheduler, распределитель простых операций с плавающей точкой - распределяет простые операции с плавающей точкой и операции по доступу к памяти с плавающей точкой.
Все эти распределители используют четыре входа диспетчеризации, о которых мы расскажем чуть позднее.

Ступени с шестой по двенадцатую
Ступени 13 и 14 - Dispatch, диспетчеризация. На этих ступенях инструкции попадают на один из четырёх портов диспетчеризации (dispatch ports), а затем - на выполнение. Эти порты выполняют функцию шлюзов к функциональным устройствам. За один такт через эти порты может пройти до шести микрокоманд. Это больше, чем может выполнить препроцессор (3 микрокоманды за такт). Это также больше, чем может сбросить постпроцессор (Тоже 3 микрокоманды за такт). Это даёт некоторую свободу в случае вспышки активности.
На этой диаграмме представлены четыре порта диспетчеризации и типы инструкций, которые они могут принять. Если указать на диаграмме распределители, то они были бы размещены над четырьмя портами.
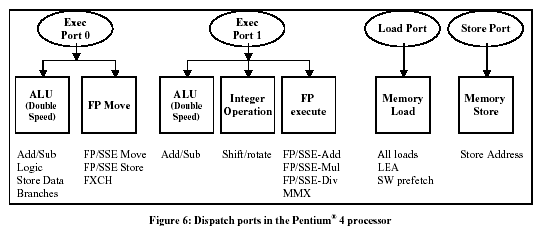
Порты диспетчеризации (Dispatch ports)
Ступени 15 и 16 - Register Files, блок регистров
После того, как инструкции пройдут порты диспетчеризации, они попадают на две эти ступени. Здесь инструкции загружаются в блок регистров для дальнейшего выполнения.
Ступень 17 - Execute, выполнение. На этой ступени инструкции выполняются в функциональных устройствах. (Вообще говоря, это и есть самая главная стадия, ради которой и приходится проделывать весь этот длинный путь. Если это инструкция ADD, то цифры складываются, если это LOAD, то в память загружаются какие-то данные, если это MUL, то цифры перемножаются и так далее)

Ступени с 13 по 17
Ступень 18 - Flags, флаги. Если результат выполнения инструкции требует изменения состоянии флагов, именно на этой ступени и выполняется эта операция.
Ступень 19 - Branch Check, проверка ветвления. На этой ступени P4 проверяет выполнение условия ветвления и определяет, напрасно были затрачены 19 тактов, или всё-таки нет. То есть препроцессор узнает, сбылось ли предсказание ветвления.
Ступень 20. Drive, вторая передаточная ступень. Мы уже встречали первую передаточную ступень. Эта ступень выполняет те же функции распространения сигнала по чипу.
Ступени 18 - 20
Как вы заметили, 20-ступенчатый конвейер P4 выполняет ту же работу в том же порядке, что и 7-ступенчатый конвейер G4. Однако разбиение конвейера на большее число ступеней позволяет P4 достичь больших тактовых частот.
На этом закончим... Мы довольно подробно рассмотрели работу P4 и G4e и некоторые детали этих двух архитектур с тем, чтобы понять, как работает каждый из процессоров.
В обзоре использованы материалы Arstechnica, Intel и Apple.
Дополнительные материалы:
 AMD Thoroughbred Athlon XP. Стресс-тест
AMD Athlon XP : Thoroughbred
Intel Celeron 1700 на ядре P4
Intel Celeron 1300 против AMD Duron 1200
AMD Hammer
AMD Athlon XP 2000+ против Intel 0,13 мкм P4 Northwood
Практическое руководство по разгону Athlon XP, тестирование Athlon XP 2000+
AMD Athlon XP 1900+
Intel Pentium III 1266 (Tualatin)
Intel Xeon 1.7 GHz
Intel Pentium 4 1.4GHz
AMD Athlon XP: производительность выше мегагерц!
Степпинги процессоров AMD
Intel Pentium III 700E
Intel Pentium III 600E
AMD Thoroughbred Athlon XP. Стресс-тест
AMD Athlon XP : Thoroughbred
Intel Celeron 1700 на ядре P4
Intel Celeron 1300 против AMD Duron 1200
AMD Hammer
AMD Athlon XP 2000+ против Intel 0,13 мкм P4 Northwood
Практическое руководство по разгону Athlon XP, тестирование Athlon XP 2000+
AMD Athlon XP 1900+
Intel Pentium III 1266 (Tualatin)
Intel Xeon 1.7 GHz
Intel Pentium 4 1.4GHz
AMD Athlon XP: производительность выше мегагерц!
Степпинги процессоров AMD
Intel Pentium III 700E
Intel Pentium III 600E
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex




