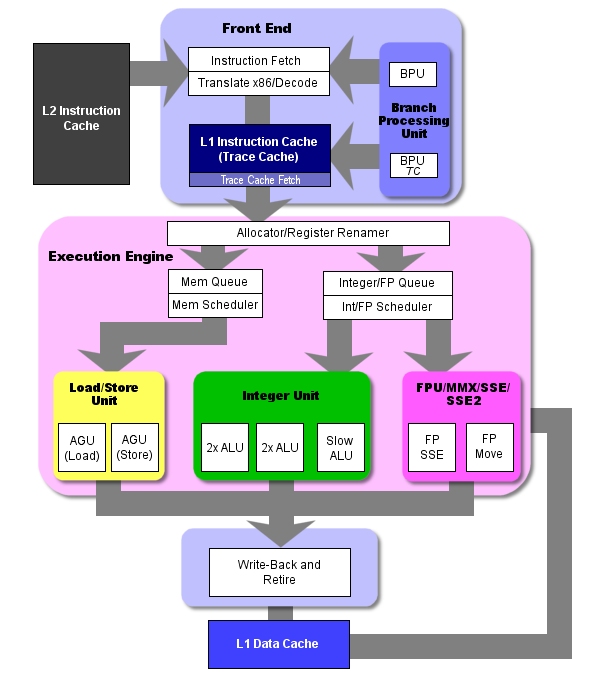
Архитектура P4. Кэш с отслеживаниями (trace cache)
Хотя конвейер P4 является намного более длинным, он выполняет те же функции что и G4e. На следующем рисунке изображена архитектура P4. Можно сравнить этот рисунок с архитектурой G4e. Из-за сложности архитектуры и ограничений в пространстве, мы не изображаем здесь каждую из ступеней конвейера, как это было сделано в рисунке с архитектурой G4e. Тем не менее, мы сгруппировали связанные ступени воедино, чтобы вы смогли представить всю схему процессора и схему потока команд.
Обратите внимание на то, что кэш L1 разделён, и его кэш инструкций находится фактически на препроцессоре. Он называется кэшем с отслеживаниями (trace cache) и является одной из важных инноваций в P4. Этот кэш оказывает сильное влияние и на конвейер, и на основной поток инструкций. Поэтому перед тем как детально обсуждать конвейер P4 мы рассмотрим, что представляет собой этот кэш.
В процессорах с микроархитектурой x86, таких как PIII или Athlon, инструкции поступают в декодер из кэша инструкций, в декодере они разбиваются на меньшие части, более единообразные, с которыми проще работать. Их также называют микрокомандами (mops). Фактически эти инструкции применяются при внеочередном выполнении команд, исполнительный модуль выполняет их планирование, исполнение и сброс.
Такое разбиение случается всякий раз, когда процессор выполняет инструкцию, поэтому на эту операцию в начале конвейера отводится несколько ступеней. (Заметим, что на следующих двух рисунках эти ступени объединены. То есть выборка инструкций занимает несколько ступеней, транслирование - несколько ступеней, декодирование - несколько , и так далее)
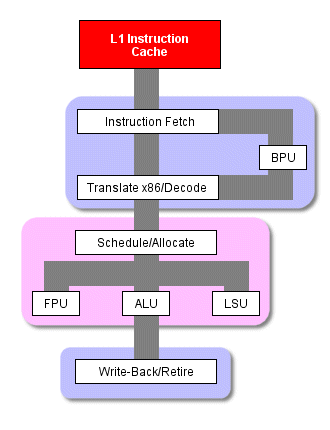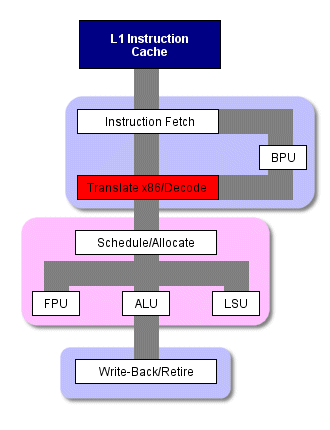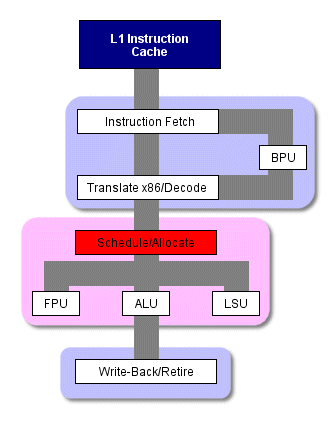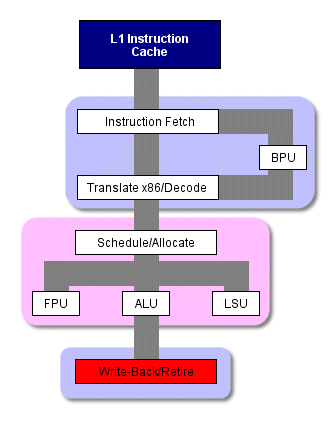
Стандартная схема работы x86 процессора
Если взять кусочек кода, повторно выполняющийся всего несколько раз по ходу программы, то для него такая потеря нескольких тактов мало что означает. Но для кусочка кода, где инструкции исполняются тысячи и тысячи раз (например, в цикле в мультимедийном приложении, выполняющем несколько операций над большим файлом),
количество повторных трансляций и декодирований может отнимать ощутимые ресурсы. Для того чтобы избежать таких циклов, процессор P4 повторно не разбивает x86 инструкции на микрокоманды при их выполнении.
Кэш инструкций P4 принимает транслированные и декодированные микрокоманды, готовые к передаче на внеочередное выполнение, и формирует из них мини-программы, называемые "отслеживаниями" ("traces"). Именно эти мини-программы (а не x86 код, созданный компилятором) и выполняет P4 в том случае, если происходит попадание в L1 кэш (процент попадания - более 90%). До тех пор, пока требуемый код находится в кэше L1, схема выполнения выглядит следующим образом.
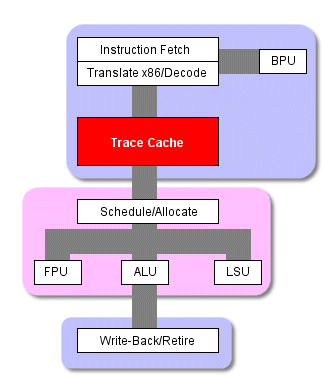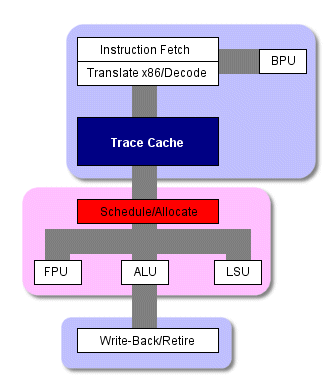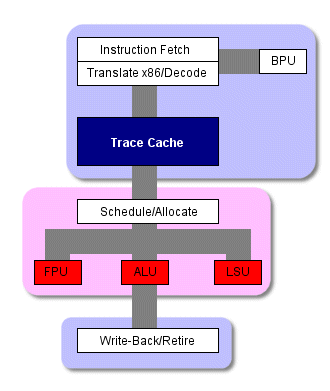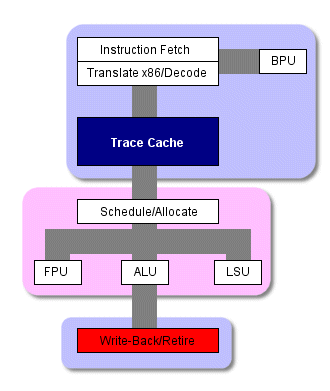
Схема работы процессора P4
По мере выполнения препроцессором накопленных отслеживаний, кэш с отслеживаниями посылает до трех микрокоманд за такт напрямую на внеочередной модуль выполнения, сейчас процессору уже не нужно проводить команды через логику трансляции или декодирования. И только в случае промаха кэша L1 препроцессор нарушит этот порядок и начнёт выбирать и декодировать инструкции из кэша L2. В этом случае к началу основного конвейера добавляется ещё восемь ступеней. Как вы видите, кэш с отслеживаниями может избавить от довольно большого количества тактов при выполнения программы.
Кэш с отслеживаниями работает в двух режимах. "Исполнительный режим" ("Execute mode") проиллюстрирован выше. Здесь кэш снабжает логику выполнения инструкциями. В этом режиме он обычно и работает. Когда наступает промах кэша L1, кэш переходит в "режим построения отслеживающих сегментов" ("trace segment build mode") В этом режиме препроцессор выбирает x86 инструкции из кэша L2, транслирует их в микрокоманды, создаёт отслеживающий сегмент, который затем перемещается в кэш с отслеживаниями и далее выполняется.
На рисунке видно, когда работает кэш с отслеживаниями - устройство предсказания ветвлений не участвует в работе, равно как не работают и ступени выборки/декодирования инструкций. На самом деле отслеживающий сегмент - это нечто большее, чем просто кусок транслированного и декодированного кода x86, выданного компилятором и полученного препроцессором из кэша L2. В действительности, при создании мини-программы кэш с отслеживаниями все же использует предсказание ветвлений. Он может добавить в мини-программу (где содержится предназначенный для выполнения код) код, который только предполагается к выполнению при предсказании ветвления. Поэтому если у вас есть кусок x86 кода с ветвлением, кэш с отслеживаниями построит отслеживание из инструкций до ветвления, включая саму инструкцию ветвления. Затем он продолжит спекулятивно строить мини-программу вдоль предсказанной ветви.
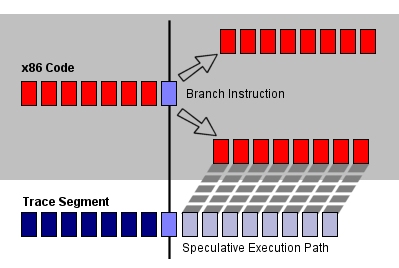
Такое спекулятивное выполнение даёт кэшу с отслеживаниями два больших преимущества по сравнению с обычным кэшем инструкций. Во-первых, в стандартном процессоре для работы устройства предсказания ветвлений требуется некоторое время. При обработке условной инструкции ветвления, BPU должно определить, какую из ветвей нужно спекулятивно выполнять, найти адрес кода после ветвления и так далее. Весь этот процесс добавляет, по крайней мере, ещё один такт задержки для каждой условной инструкции ветвления. Такая задержка часто не может быть заполнена выполнением другого кода, что приводит к появлению нежелательного пузырька. В случае же использования кэша с отслеживаниями, код после ветвления уже готов к выполнению сразу же после инструкции ветвления, поэтому показанных задержек не возникает.
Второе преимущество также связано с возможностью хранения спекулятивных ветвей. Когда стандартный кэш инструкций L1 считывает строку кэша из памяти, он прекращает считывание при попадании на инструкцию ветвления, поэтому оставшаяся часть строки остается пустой. Если инструкция ветвления находится вначале строки кэша L1, то в считанной строчке будет находиться только одна эта инструкция. При использовании кэша с отслеживаниями считанные строчки могут содержать как инструкции ветвления, так и спекулятивный код после них. Таким образом, в 6-командных строчках не возникает потерянного места.
Кстати, большинство компиляторов сталкиваются именно с описанными двумя проблемами: с задержками в инструкциях ветвления и с неполными строками кэша. Как мы видим, кэш с отслеживаниями по-своему позволяет решать эти проблемы. Если программы оптимизированы с учетом этих возможностей, то они будут быстрее выполняться.
Ещё один интересный эффект, производимый этим кэшем на препроцессор P4 заключается в том, что пропускная способность ступеней транслирования и декодирования x86 команд не зависит от пропускной способности ступени диспетчеризации. Если вспомнить процессор K7, то он расходует множество транзисторов на усиленный блок декодирования x86 макрокоманд, что позволяет за цикл декодировать достаточно много громоздких x86 инструкций в макрокоманды (MacroOps, K7 вариант mops в P4) для загрузки исполнительного модуля. В случае же P4 наличие кэша с отслеживаниями означает, что большая часть кода забирается из кэша с отслеживаниями уже в виде готовых микрокоманд, так что здесь отпадает надобность в трансляторах и декодерах с высокой пропускной способностью.
Процессор начинает декодирование только лишь в случае промаха кэша L1. Поэтому он разработан таким образом, чтобы декодировать только одну x86 инструкцию за такт. Это составляет всего треть от максимальной теоретической пропускной способности декодера Athlon, но кэш с отслеживаниями в P4 позволяет ему достичь или даже обойти производительность Athlon (2,5 диспетчеризации за такт).
Стоит обратить внимание и на то, как кэш с отслеживаниями обращается с очень длинными x86 инструкциями из нескольких циклов. Вы, вероятно, знаете, что большинство x86 инструкций декодируются примерно в две или три микрокоманды. Но встречаются и такие инструкции (к счастью, редко), которые декодируются в сотни микрокоманд, например, инструкции по строковой обработке. Как и в Athlon, в P4 существует специальное ПЗУ микрокода, которое обрабатывает эти громоздкие инструкции, что позволяет разгрузить аппаратный декодер для работы только с небольшими, быстрыми инструкциями. Каждый раз, когда встречается громоздкая инструкция, ПЗУ находит готовую последовательность микрокоманд и выдаёт их дальше в по очереди. Чтобы не засорять кэш с отслеживаниями этими длинными последовательностями микрокоманд, разработчики поступили следующим образом. Как только при создании отслеживающего сегмента кэш с отслеживаниями встречает такую большую x86 инструкцию, вместо того, чтобы разбивать её на последовательность микрокоманд, он вставляет в отслеживающий сегмент метку (tag), которая указывает на место в ПЗУ, содержащее последовательность микрокоманд данной инструкции. Позднее, в режиме выполнения, когда кэш с отслеживаниями будет передавать поток инструкций на ступень выполнения, при попадании на такую метку, он временно приостановит работу и на время передаст управление потоком инструкций микрокоду ПЗУ. Здесь уже ПЗУ будет выдавать в поток инструкций требуемую последовательность микрокоманд (как определено меткой). После этого, оно возвратит управление обратно, и кэш с отслеживаниями продолжит передавать инструкции. Исполнительному модулю безразлично, откуда поступает поток инструкций (из кэша или из ПЗУ). Для него все это выглядит как непрерывный поток команд.
Единственным недостатком кэша с отслеживаниями является его размер. Кэш слишком мал. Мы не знаем точных размеров этого кэша инструкций. Знаем только, что он может содержать до 12 тысяч микрокоманд. Intel уверяет, что это примерно эквивалентно обычному кэшу команд на 16-18 тысяч инструкций. Но так как кэш с отслеживаниями работает совсем иначе, нежели стандартный кэш инструкций L1, то для того, чтобы оценить, как его размер влияет на производительность всей системы, нельзя обойтись простым сравнением его размера с кэшем другого процессора. Впрочем, это тема для отдельной беседы.
В итоге отметим следующее. Во-первых, кэшу с отслеживаниями всё же необходима короткая ступень выборки инструкций, ведь сначала необходимо выбрать микрокоманды из кэша, а уже за тем пересылать их дальше. Если вы посмотрите на основной исполнительный конвейер P4, то вы заметите эту ступень. Во-вторых, кэш с отслеживаниями обладает своими средствами (мини-BTB и BPU) для предсказания ветвлений внутри кэша с отслеживаниями. Поэтому нельзя говорить, что кэш с отслеживаниями ликвидирует механизм предсказания ветвлений. Кэш просто смягчает отражение негативных последствий ветвлений на производительности.
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex