







 MWC 2018
MWC 2018 2018
2018 Computex
ComputexВы помните о судьбе легендарного Змея-Горыныча? Если всерьез думаете, что он пал от руки известного террориста Ильи Муромца, то попробуйте с мечом и щитом (без установки с управляемыми противотанковыми ракетами) одолеть танк «Леопард». Да и не смог бы Илья до него добраться по причине своего беспробудного пьянства. Бедный Змей был обречен. Как, по-вашему, долго проживет многоголовое огнедышащее чудовище со скверным характером и тягой к тотальному уничтожению? Правильно, до первого выяснения отношений между своими головами.
Введение, или правила игры
Начинать статью, посвященную MP, следует обязательно с задач, которые будут поставлены перед системой. Все вычислительные задачи, которые можно запрограммировать, можно разделить на два типа: параллелизуемые и непараллелизуемые. Отличие их состоит в том, что параллелизуемые задачи могут быть аддитивно разбиты на непересекающиеся задачи меньшей длины. Существует формула
где i и j – мультииндексы.
Она представляет собой общий вид всех параллелизуемых задач (ну или почти общий, если быть совсем точным, но я не буду этого касаться), к ней сводятся произведения матриц, интегралы, различные уравнения и многое другое. Из нее можно выделить 2 типа разделения задачи: на уровне данных и на уровне вычислений. Далее я буду рассматривать задачу, разделяемую на уровне вычислений, как более сложную и интересную
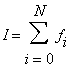
где значения {fi}будут браться из некого наперед заданного массива. Задача, разделяемая на уровне данных, записывается общей формулой
где i=1..N, и представляет собой вычисление массива {Ai} по известной формуле f и массиву {ai}. Это не нарушает общности рассмотрения, поскольку любой другой вариант можно представить комбинацией двух и более разделяемых задач. Замечу, что если вычислительная задача не сводится к этому виду, то она не параллелизуема.
Программирование подобных задач осуществляется с помощью специальных дополнительных функций, реализованных в стандартах MPI или OpenMP. Я не буду заострять на них свое внимание, поскольку сначала важнее показать, что нужно программировать, а лишь затем следует заострять внимание на конкретной реализации в языке. При этом программисту не требуется даже знать конкретной методики распараллеливания задачи. Ему требуется только внести несколько дополнительных команд в исходный код, и все необходимые операции сделает компилятор. Для подсчета суммы программный модуль summa() с директивами OpenMP выглядит так
double summa(long f[], int N)
{
register double s;
register int i;
s = 0;
#pragma omp parallel for /*распараллеливание цикла*
for (i = 0; i =< N; i ++){
s + = f[i];
}
return s;
}
Следует учесть при прочтении данной программы, что она писалась для 64х разрядных процессоров. Обычно для физических целей крайне редко требуется точность выше второго знака (бывают случаи, когда порядок величины определяют экспериментально с 50%-ной погрешностью), а это позволяет использовать исключительно целочисленные операции. Читателям, заинтересовавшимся непосредственно методиками работы с API OpenMP или MPI, следует обратиться к сайту Лаборатории Параллельных Вычислений по адресу http://parallel.ru и официальным сайтам http://www.openmp.org и http://www.mpi-forum.org.
AMD Athlon, или археология для программиста
Многие читали, что процессоры AMD Athlon в многопроцессорных конфигурациях используют метод распределенной памяти с общим адресным пространством, или NUMA. Это выражается в том, что каждый процессор может быстро и напрямую адресоваться только в свою область памяти, причем, как правило, эти апаратно разделены. Например, каждому процессору отвечает свой модуль памяти. Различные вычислительные модули (процессор+контроллер памяти+память) связывает специальный протокол. Для Athlon это протокол «точка-точка». В более сложных вариантах (например, компьютеры Cray) для связи отдельных модулей используются специальные сетевые протоколы и дополнительные коммутационные модули, помимо вычислительных.
Как разделить в этом случае задачу? Очень просто, достаточно вспомнить об аддитивности поставленной задачи, и просто разделить данные (в нашем случае это значения fi) на несколько блоков. Затем просуммировать отдельные блоки и результаты этих суммирований сложить между собой. Например, для нашей задачи множество F={fi, i=1..N}
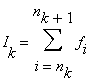
а окончательный результат получается как
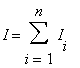
Существует много методик, которые позволяют определить размер отдельного блока. Обычно все блоки выбираются одного размера, равного половине памяти отдельного модуля. Если размер памяти для отдельного модуля составляет 256MB, то размер блока берется 128MB. Однако, существует большое количество ситуаций, когда фиксированный размер блока данных неудобен, а то и просто невозможен. Например, данные поступают в вычислительную систему в реальном времени, или одновременно считается несколько вычислительных задач. Тогда на каждом процессоре дополнительно запускается демон (или сервис на MSрусском языке), который регулирует размер блока и управляет его загрузкой в память модуля с внешнего устройства (магнитная лента, LAN, жесткий диск).
Общение процессоров между собой происходит через буфер. Если процессору 1 требуется передать данные процессору 2, то эти данные заносятся в буферную область памяти модуля 1. В том случае если процессор 2 производит операции чтения/записи со своей памятью, то данные в буфере ожидают окончания этих операций. Когда доступ к памяти 2 открывается, данные из буфера передачи помещаются в память 2. Во время этой операции, доступ к памяти процессора 2 закрыт. Если обоим процессорам требуется обменяться данными, то преймущество имеет процессор 1. Таким образом, достигается отсутствие конфликтов при работе с памятью и простоев при отсутсвии необходимых данных. Так же не требуется постоянной синхронизации и упорядочевания вычислений для отдельной задачи, в результате этого задача легко масштабируется, например, переносится на кластер.
Intel Xeon, или разделение сиамских близнецов
Реклама Intel гласит "Наше главное достоиство – общая память". Попробуем посмотреть, так ли велико это достоиство. В предыдущей главе, я показал, как распареллелить задачу для системы с распределенной памятью. А теперь определимся с общей. Казалось бы, здесь все проще, давай только в каждый процессор данные, а окончательные результаты нужно просуммировать в конце. Однако столь радужные возможности немедленно упираются в небольшое (в смысле размера) ограничение, то есть в общую шину памяти. Она ведь одна на двоих.
Для ее совместного использования существует протокол SMP. Он помогает нескольким процессорам адресоваться в общий участок памяти. Пока процессоры делают это по очереди, сложностей не возникает. Но если же несколько процессоров одновременно обращаются к памяти, то возникает коллизия. Коллизия разрешается тем, что процессоры посылают следующий запрос на данные в другое время. А что они делают в то время, когда у них нет данных из памяти? Как правило, ничего. Самый прямолинейный путь уменьшения коллизий – это увеличение кэша. По нему и пошли инженеры Intel, создавая свое детище Xeon. Кратное увеличение кэша действительно позволяет уменьшить количество коллизий.
Но действенна ли эта мера? Допустим, что существует некий процессор с динамически изменяемым размером кэша c. В простейшем приближении вероятность нахождения в таком кэше нужных данных равна
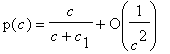
В том случае, если процессор не находит данных в кэше, то он обращается в память. Пусть t0 это время чтения слова из памяти, а t1 – время отдельного вычисления без обращения к памяти. Тогда вероятность обращения к памяти процессора равна
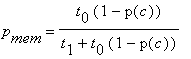
А теперь найдем вероятность парной коллизии для m процессоров
Для хорошо запрограммированной задачи из класса описанных выше, отношение t0/t1 составляет примерно 1. Непарные коллизии учитывать не будем.
Теперь перейдем к жизненной ситуации, p(c0)=60% или Intel Pentium 3 (практически эта величина сильно зависит от программиста, но мне интересен случай «бесконечно умного программиста»). И посмотрим, что произойдет если размер кэша станет равным nc0, а количество процессоров m равным 2n. Результат представим в виде таблицы.
| m | p(nc0) | pcollision |
| 2 | 60% | 8% |
| 4 | 75% | 12% |
| 8 | 86% | 37% |
| 16 | 92% | 58% |
Итак, получилась вероятность коллизии в простейшем случае. На практике ситуация гораздо сложнее. Например, часть кэша занимают данные не относящиеся к непосредственно выполняемой задаче. Или возникновение процессорного прерывания обрабатовается всеми процессорами, а не только одним ведущим, как в случае распределенной памяти. В случае коллизии, как я уже писал выше, процессоры останавливаются. Время простоя процессора в случае коллизии в среднем порядка t0. Даже для 2х процессорных схем этот промежуток времени весьма внушителен. Наконец, вероятность сбоя в такой системе растет экспоненциально с числом процессоров.
Вообще говоря, эта схема получается довольно забавной. Отказываясь от разделяемой памяти, процессоры Xeon получают взамен больший кэш, который заменяет им вышеупомянутую разделяемую память. И теперь задача компилятора и программиста состоит не в разделении данных между модулями, а между кэшами что, на мой взгляд, гораздо сложнее. Масштабирование этой схемы так же усложнено, поскольку при разбиении задачи компилятором и при разрешениях коллизий процессорами полагается, что этих процессоров 2r (2, 4, 8, 16 или 32).
HyperThreading, или что думает Змей-Горыныч
До сегодняшнего дня мне, как и большинству людей не занятых на производстве Intel, не встречались процессоры, которые понимают HT (HyperThreading), программы, которые используют HT, и компиляторы, способные создавать такие программы для таких процессоров. Но эта технология меня сразу сильно заитересовала.
В современных процессорах существует несколько параллельно работающих вычислительных устройств ALU. Однако эти устройства большую часть времени простаивают по нескольким причинам.
- Узкая шина памяти не позволяет быстро загружать массивы данных в процессорный кэш.
- Процессорный кэш не позволяет хранить в себе большие массивы данных.
- Архитектура x86 не позволяет загружать несколько блоков данных параллельно из кэша.
- Архитектура x86 не позволяет программам обращаться к отдельным ALU.
Все это больные места архитектуры x86 в целом и производители процессоров проявляют чудеса терапевтических методов для их решения. Одим из этих методов и является HT.
HyperThreading позволяет частично решить проблему №4. Используя HT, операционная система представляет один процессор как два, работающих в схеме SMP. Теоретически это позволит загрузить простаивающие ALU. Теперь вернемся на землю, и попробуем понять, как же эти виртуальные процессоры будут работать вместе. На программном уровне все хорошо, используя методики работы SMP, программа будет загружать, то один, то другой процессор.
Но как же все это будет происходить на физическом уровне реального процессора, он ведь совершенно не осведомлен о наполеоновских планах маркетинговых отделов. Работа с общей памятью неизбежно связана с коллизиями, для их уменьшения их количества в семействе Xeon и сделан такой большой кэш. Для разрешения коллизий предусмотрен механизм случайных простоев. Технология HT позволяет производить несколько различных вычислений на одном процессоре из одного кэша. Значит, теперь коллизии перенесутся из медленной памяти в быстрый кэш. Обращений к кэшу, чем памяти больше в несколько раз. И количество коллизий неизбежно возрастет в несколько раз. Но время простоя процессора в случае обнаружения коллизии при этом не уменьшится, а если и уменьшится, то незначительно. Следовательно, процессор большую часть времени будет тратить на разрешение коллизий.
Для решения вновь возникшей проблемы инженеры Intel использовали уже классический для них подход, введение дополнительного кэша, который назвали L2. В нем должны хранится данные для отдельных ALU. А старый процессорный кэш переименовали в L3. При этом естественно увеличилась длина конвеера обработки данных и усложнилась архитектура. Мне не известна методика работы этого кэша, а потому не удалось построить математическую модель и оценить эффективность его работы. Но, по моему мнению, L2 будет, вряд ли во много раз эффективнее процессорного кэша L3. А ведь для приведения количества коллизий к разумным величинам, требуется увеличения вероятности обнаружения данных в L2 по сравнению с L3, по крайней мере, в 3 раза. Если этого не произойдет, то время простоя процессора только увеличится.
Теперь предположим, что реклама права, а прогнозы маркетологов оправдались (ведь есть же люди, которые слушают политиков и прогноз погоды), и HT заработал. Да еще увеличил при этом объем производимых полезных вычислений (т.н. производительность) для отдельно взятого ALU. Но проблема №4 не зря имеет свой номер. Ведь даже если программа получит возможность выбирать свободное ALU, то вряд ли эта программа сможет передавать данные на несколько ALU одновременно! Ведь проблемы за номерами 1, 2 и 3 практически не позволяют это делать. И конфликт возникнет не на стадии доступа к кэшу L3 со стороны ALU, а гораздо раньше, при попытке загрузить данные в этот кэш из памяти. Ведь и сейчас, шина памяти не справляется с потоком данных, а при увеличении задействованных ALU этот поток еще возрастет. В качестве вывода можно сказать, что в лучшем случае HT не будет работать вообще. Например, как сейчас в Pentium 4.
Выводы
Мне несколько раз приходилось объяснять, что многопроцессорные компьютеры не пригодны для домашнего использования. Надеюсь, эта статья объяснит этим людям цели и задачи, которые могут быть поставлены перед такими компьютерами. Именно по этой причине я не привожу никаких тестов, они обманчивы. Допустим, некий программный код выполняется на друх процессорах на 40% быстрее, чем на одном (это очень хороший код). Однако не следует ожидать, что, запустив игрушку на двухпроцессорной машине, вы получите прирост fps. Во-первых, мне известна только одна игра, которая идет на двух процессорах одновременно, это Quake III Arena. Во-вторых, игра только замедлится. Ведь каждый раз, когда вы нажимаете на кнопку или двигаете мышь, то генерируете прерывание, которое останавливает оба процессора. А затем обоим процессорам требуется не только решать задачу, но ее делить, что требует дополнительных ресурсов.
Если же вы занимаетесь математикой, то вам следует все же учесть, что описанные задачи чревычайно сложны и ресурсоемки. И решать их дома просто невозможно.





