







 MWC 2018
MWC 2018 2018
2018 Computex
Computex
⇣ Содержание
|
Опрос
|
реклама
Самое интересное в новостях
AMD 760MP и Athlon MP - двухпроцессорный рай
Технология Athlon MP Как вы, наверное, помните из нашей статьи про Athlon 4, в ядре Palomino появилось несколько улучшений, что позволяет ему иногда демонстрировать заметное преимущество в производительности по сравнению со своим предшественником. Так как Athlon MP использует то же самое ядро Palomino, что и Athlon 4, в нем присутствуют те же самые улучшения. Единственное, что не анонсировано в Athlon MP - это PowerNow!, хотя эта технология поддерживается процессором. Как вы, наверное, помните из нашей статьи про Athlon 4, в ядре Palomino появилось несколько улучшений, что позволяет ему иногда демонстрировать заметное преимущество в производительности по сравнению со своим предшественником. Так как Athlon MP использует то же самое ядро Palomino, что и Athlon 4, в нем присутствуют те же самые улучшения. Единственное, что не анонсировано в Athlon MP - это PowerNow!, хотя эта технология поддерживается процессором.
Athlon MP является первым не-мобильным процессором от AMD, использующим полный набор Intel SSE инструкций (Streaming SIMD Extensions). Таким образом, Athlon MP может запускать оптимизированный под 3DNow! или SSE код, впрочем, это совсем не означает, что он будет запускать SSE код так же быстро, как и Pentium III/Pentium 4. AMD называет новые инструкции (3DNow!+SSE) технологией 3DNow! Professional. Кстати, в линейку Hammer, скорее всего, будет включена поддержка SSE2. Второе преимущество Athlon MP заключается в улучшенном механизме упреждающей выборки данных. Эта возможность позволяет процессору автоматически использовать свободные ресурсы FSB для упреждающей выборки данных. Процессор заранее запрашивает необходимые, по его мнению, данные из памяти, еще до запроса к ним. Таким образом, Athlon MP требует высокоскоростную FSB и шину памяти, но с другой стороны, он лучше чем обычный Athlon может использовать высокую пропускную способность, что обеспечивает ему преимущество в производительности. Как мы уже отмечали в анализе тестов Pentium 4, упреждающая выборка данных хорошо работает с приложениями, которые значительно нагружают пропускную способность, так как такой трафик легче поддается предсказанию. К этим приложениям относятся программы по редактированию видео, или, что более близко к теме данной статьи, программы по созданию 3D графики и серверы баз данных. Упреждающая выборка довольно полезна в случае Athlon MP, так как чипсет обеспечивает высокую пропускную способность FSB, которая лучше задействуется при включении упреждающей выборки. Впрочем, позднее мы более подробно на этом остановимся. Следующее улучшение в Athlon MP связано с тремя новыми возможностями буфера быстрого преобразования адреса (Translation Look-aside Buffer, TLB). Как следует из технической документации AMD на ядро Palomino, эти возможности сводятся к следующему. 1. В TLB кэша данных L1 было увеличено число строк с 32 до 40. Как мы уже говорили в статье про Athlon 4, задачей TLB является кэширование преобразованных адресов памяти. Процесс преобразования адресов необходим для доступа процессора в основную память. Кэширование ускоряет процесс обращения к памяти. Увеличение числа строк в TLB кэша данных L1 повышает вероятность успешного попадания в TLB (вероятность нахождения нужного адреса). Как вы помните, TLB кэша данных L1 у Pentium III содержал даже больше 40 строк. Исключающая архитектура означает, что записи TLB кэша L1 не дублируются в TLB кэша L2. Таким образом, происходит экономия строк в TLB кэша L2, благодаря которой TLB может кэшировать больше адресов. Минусом исключающей архитектуры является повышение латентности, связанное с отсутствием дублей адресов в TLB кэша L2. Lehmen comments: В Athlon’ах и Duron’ах это было всегда... С помощью опережающей загрузки адрес может быть загружен в TLB еще перед тем как инструкция, запросившая адрес, закончит свое выполнение (конечно, если соответствующий адрес уже не содержался в TLB). В старых ядрах Athlon опережающая перезагрузка была невозможна, что приводило к некоторой потере производительности. В соответствии с AMD, улучшение будет заметно, прежде всего, в "high-end приложениях". Тем самым AMD подтвердила, что улучшения в TLB у Athlon MP будут наиболее важны при выполнении "high-end приложений". Впрочем, ниже в наших тестах мы посмотрим, так это или не так. Тем более мы произвели несколько действительно "high-end" тестов. Когерентность кэша - это важноПредставьте себе, что в вашем офисе существуют два программиста. Они находятся в соседних комнатах и работают над одним и тем же проектом. Плюс нам дан секретарь, который находится в конце коридора. Естественно, для повышения эффективности работы программисты должны постоянно друг с другом общаться. Предположим, они не могут говорить напрямую друг с другом и пишут записки. Тогда у них есть два пути для передачи записок. Первый заключается в том, что одному из программистов придется зайти в комнату к другому и передать записку. Второй путь предполагает использование посредника, секретаря, для доставки этих записок. Конечно, первый путь является более удобным и эффективным. Как вы уже, наверное, догадались, аналогичный процесс связи происходит и между двумя процессорами. В примере с нашими программистами, каждый из них должен знать, какие задания выполнил другой программист. Для этого они должны непрерывно между собой общаться. Но, по нашему условию, они не могут говорить. Такая же проблема существует и в общении между процессорами в MP системе. Как один процессор узнает, что содержится в кэше другого? В большинстве многопроцессорных систем, каждый процессор отслеживает запросы по FSB и возвращает данные, если они находятся в кэше процессора. Для примера, возьмем систему на базе двух процессоров Athlon MP: CPU0 и CPU1. Сначала CPU0 запрашивает блок данных, содержащийся в основной памяти и не содержащийся в кэше CPU0 или CPU1. Блок данных считывается из основной памяти, проходит через северный мост и попадает на запрашивавший процессор CPU0. После этого CPU0 запрашивает еще один блок данных, который теперь содержится в L2 кэше CPU1. CPU1 всегда отслеживает запросы данных на FSB (такой процесс называется слежкой, snooping). Соответственно, сейчас CPU1 отсылает данные из своего кэша. У CPU0 существует два пути для получения данных: CPU1 записывает блок в основную память и CPU0 потом его считывает, или CPU1 передает данные напрямую на CPU0. 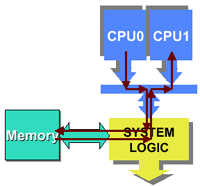 При использовании разделяемой FSB (на рисунке выше) все процессоры системы разделяют одно и то же соединение к северному мосту. Общение между процессорами осуществляется через основную память, что соответствует первому способу из перечисленных выше. При использовании FSB типа "точка-точка" каждый процессор использует свое выделенное соединение к северному мосту, и общение осуществляется через северный мост без привлечения основной памяти. Конечно, использование FSB типа "точка-точка" или разделяемой FSB зависит от чипсета и не зависит напрямую от процессора. Процессор лишь должен поддерживать устанавливаемый чипсетом протокол. В случае 760MP и Athlon MP используется шина типа "точка-точка". Такой тип шины позволяет уменьшать трафик шины памяти, так как все межпроцессорное общение происходит без участия основной памяти. Для того чтобы вы поняли важность этого момента, учтите, что все многопроцессорные чипсеты для процессоров Intel используют разделяемую FSB. Не исключением является и недавно выпущенный i860 для Intel Xeon. Конечно, многие могут поспорить, что перенаправление всего межпроцессорного трафика через северный мост не особо сильно влияет на производительность. Впрочем, по всей видимости, такая возможность выступает как желательный фактор для повышения производительности, а не как обязательное требование. 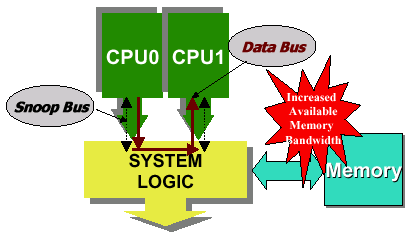 Еще одно преимущество EV6 FSB у Athlon MP заключается в том, что она содержит два однонаправленных порта адреса (адрес на вход и адрес на выход) и один двунаправленный порт данных на каждом соединении. Это означает, что Athlon MP может "подглядывать" в поисках требуемых данных одновременно с выполнением запроса. AGTL+ FSB у Pentium 4 использует только один двунаправленный порт адреса и один двунаправленный порт данных. Таким образом, в одно время Pentium 4 может только отсылать или только принимать адрес. Снова обратимся к нашей системе на Athlon MP. Пусть CPU0 владеет блоком данных в своем кэше, и CPU1 имеет те же самые данные в своем кэше. Далее CPU1 изменяет эти данные у себя, и после этого CPU0 будет пытаться прочитать данные у CPU1. В текущем положении данные в кэше CPU0 не являются актуальными, так как они были изменены после того как CPU0 поместил их в свой кэш. Для решения таких проблем процессоры должны обладать когерентным друг с другом кэшем. Количество протоколов когерентности можно пересчитать по пальцам, однако существует множество их вариаций. Впрочем, наиболее часто используется протокол записи с аннулированием (write invalidate). Если не вдаваться в детали, то в случае возникновения конфликта когерентности этот протокол указывает, какому кэшу необходимо аннулировать свои данные. Аннулирование происходит по адресное шине, так что двухпортовая адресная шина EV6 снова играет нам на руку, позволяя одновременно с аннулированием запрашивать какие-либо полезные данные. Существует множество вариаций протокола записи с аннулированием, но чаще всего встречается протокол MESI. Аббревиатура происходит от первых букв четырех состояний, которые может принимать строка кэша (Modified, Exclusive, Shared, Invalid). Ниже приведено описание каждого состояния.
Протокол MESI используется в большинстве x86 процессоров, включая AMD K6, Intel Pentium III, Pentium 4 и Xeon. Даже процессоры PowerPC реализуют протокол когерентности MESI. Однако Athlon MP (включая все предыдущие варианты Athlon и Duron) использует протокол MOESI с пятью состояниями строки. Пятое состояние строки в протоколе MOESI называется "собственная" (owned). Состояние включается, если запрашиваемые данные находятся в кэше процессора, они были изменены и копия в памяти недостоверна. Реализация протокола когерентности MOESI более трудоемка и требует включения в процессор большего количества транзисторов. Однако такой протокол прекрасно работает с двумя адресными портами FSB "точка-точка" у Athlon MP и действительно повышает эффективность работы шины. Изначально протокол когерентности MOESI предназначался для использования в high-end серверных процессорах типа Sun UltraSPARC II, однако появившийся в 1999 году Athlon, как видите, не остался в стороне.
⇣ Содержание
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.
Материалы по теме
|
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.











