







 MWC 2018
MWC 2018 2018
2018 Computex
Computex
⇣ Содержание
|
Опрос
|
реклама
Самое интересное в новостях
Домашний бульдозер. Обзор процессора AMD FX-8150
Из чего складывается производительность процессора? Раньше в ходу была формула, описывающая быстродействие как произведение количества исполняемых за один такт инструкций и частоты, на которой этот процессор функционирует. Теперь в этой формуле появился и третий сомножитель — количество вычислительных ядер. Поэтому разработчик процессоров, желающий выпустить быстрый продукт, имеет для этого несколько путей. Однако не всё так просто. Увеличение количества исполняемых вычислительным ядром за такт инструкций — довольно сложная задача. Классический x86 программный код предполагает последовательное исполнение команд, а потому, чтобы добиться их параллельной обработки, в процессор необходимо заложить высокоэффективные блоки предсказания переходов и переупорядочивания инструкций, реализация которых требует немалых инженерных усилий. При этом усложнение микроархитектуры сказывается на физических размерах кристалла и приводит к ограничениям при наращивании количества ядер. Так что если производитель собирается сделать процессор с большим числом ядер, то микроархитектуру нужно, наоборот, стараться упростить. Непросто всё и с тактовой частотой. Ставка на её рост вновь потребует внесения изменений во внутренние блоки процессора и удлинения его исполнительного конвейера. В итоге получается следующее: чтобы процессор мог завоевать медальку за производительность, его разработчики должны изрядно попотеть над одновременной оптимизацией целого ряда параметров. Проблема заключается ещё и в том, что любой из выбранных путей улучшения быстродействия процессора может оказаться удачным лишь для частных случаев. Далеко не все программы могут эффективно работать с большим количеством ядер. Какие-то алгоритмы не позволяют корректно предсказывать переходы и переупорядочивать инструкции. А в некоторых случаях производительность не растёт и с увеличением тактовой частоты, потому что в системе находятся какие-то другие узкие места. Подобрать оптимальный баланс непросто, да и что считать критерием оптимальности? Мы можем лишь сопоставить производительность процессоров в конечном числе программ и выбрать из них быстрейший для данного конкретного случая. Однако это совершенно не гарантирует, что, применив другой набор тестового инструментария, мы не получим совершенно противоположные оценки. Столь пространное вступление приведено здесь потому, что сегодня нам предстоит знакомство с новой серией процессоров AMD FX — флагманским продуктом компании AMD, широко известным под кодовым именем Zambezi. В основе этого процессора лежит весьма неоднозначная микроархитектура Bulldozer, которая уже успела собрать немалый букет нелестных отзывов. Но дело вовсе не в том, что эта микроархитектура совсем плоха. Подбирая наилучший баланс характеристик, разработчики неверно оценили потребности большинства пользователей и сделали в «базовой формуле» основной упор не на тот сомножитель. В итоге изначальный замысел по выпуску высокопроизводительного решения нового поколения пошёл кувырком и заинтригованные обещаниями прорыва приверженцы AMD получили совсем не то, что ожидали. Однако является ли это серьёзным и объективным поводом для разочарования? Об этом и поговорим в данном материале. ⇡#Считаем ядра: восемь или четыре?Работая над новым дизайном для производительных процессоров, AMD решила поставить во главу угла количество вычислительных ядер. Это вполне логичный выбор, основанный на том, что с годами многопоточного программного обеспечения становится всё больше и больше и разработка микроархитектуры, рассчитанной на многолетнее развитие, должна учитывать в первую очередь не текущее состояние рынка, а наблюдаемые тенденции. Восемь ядер, предусмотренных в базовом варианте нового процессора, — это то, чем AMD и собиралась покорить рынок, на котором пока что были представлены только чипы, максимальное количество ядер в которых ограничивалось шестью. (Здесь мы говорим только о настольных компьютерах. — прим. ред.) При этом брать ядра старой микроархитектуры K10 разработчики не захотели. Они не только имеют слишком большой физический размер, но и, как можно судить по Llano, не склонны к функционированию на высоких тактовых частотах даже после перевода на современную 32-нм технологию. К тому же они не поддерживают многих современных возможностей, таких как, например, AVX-инструкции. Поэтому, для сборки восьмиядерников AMD сделала новую микроархитектуру — Bulldozer. Представители компании предпочитают говорить, что её разработка велась с чистого листа, но на самом же деле в ядрах Bulldozer можно найти немало отсылок к другой представленной в этом году микроархитектуре — Bobcat, ориентированной на применение в компактных и энергоэффективных устройствах. Впрочем, родство между Bulldozer и Bobcat — достаточно отдалённое, и упоминаем мы о нем лишь для того, чтобы стала понятна общая идея — в Bulldozer объединено много сравнительно несложных ядер. При этом речь идёт совсем не о примитивном совмещении на одном полупроводниковом кристалле восьми простых ядер. При таком раскладе получившийся процессор обладал бы совсем невысокой однопоточной производительностью, и это стало бы достаточно серьёзной проблемой, так как программ, не дробящих нагрузку на несколько вычислительных потоков, не так уж и мало. Поэтому, во-первых, ядра были оптимизированы под работу на высоких тактовых частотах. А во-вторых, они были спарены в двухъядерные модули, способные совместно использовать свои ресурсы во благо обслуживания одного потока. В итоге получилась достаточно любопытная конструкция: входная часть исполнительного конвейера у такого двухъядерного модуля — общая, а в дальнейшем обработка инструкций делится между двумя наборами исполнительных устройств. 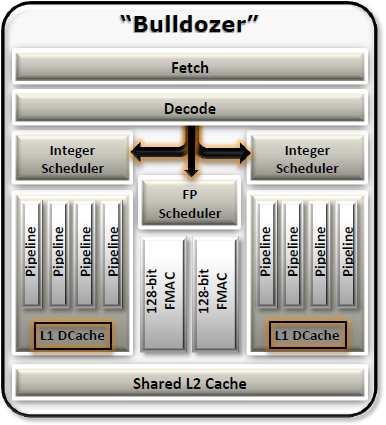 Основа конструкции Bulldozer — условно называемый двухъядерным модуль Напомним, процесс обработки данных в современном процессоре включает несколько этапов: выборку x86-инструкций из кеш-памяти, их декодирование — перевод во внутренние макрооперации, выполнение, запись результатов. Первые два этапа в модуле Bulldozer производятся для пары ядер совместно, а далее для целочисленных инструкций выполнение распределяется по двум ядрам-кластерам либо, в случае вещественной арифметики, оно осуществляется в общем для двух ядер блоке операций с плавающей точкой. Модули Bulldozer рассчитаны на обработку четырёх инструкций за такт, причём, благодаря технологии макрослияния, некоторые пары x86-инструкций могут рассматриваться процессором как одна операция. Это значит, что в целом двухъядерный модуль Bulldozer по своей мощности подобен одному ядру современных интеловских процессоров, которые также могут обрабатывать по четыре инструкции за такт и при этом тоже поддерживают макрослияния. Однако между модулем Bulldozer и ядром Sandy Bridge есть существенные различия, способные поставить их примерно одинаковую теоретическую скорость под сомнение. Ввиду того, что модуль новых процессоров AMD содержит остатки двух равноправных ядер, максимальную производительность он может продемонстрировать только при обработке пары потоков. Если же на него ложится однопоточная нагрузка, то скорость её обслуживания будет ограничиваться числом исполнительных устройств внутри одного такого кластера. А их там, учитывая желание AMD упростить отдельные ядра, не так уж и много — в полтора раза меньше, чем в процессорах с микроархитектурой Sandy Bridge или K10. То есть по два арифметических ALU и по два адресных AGU. 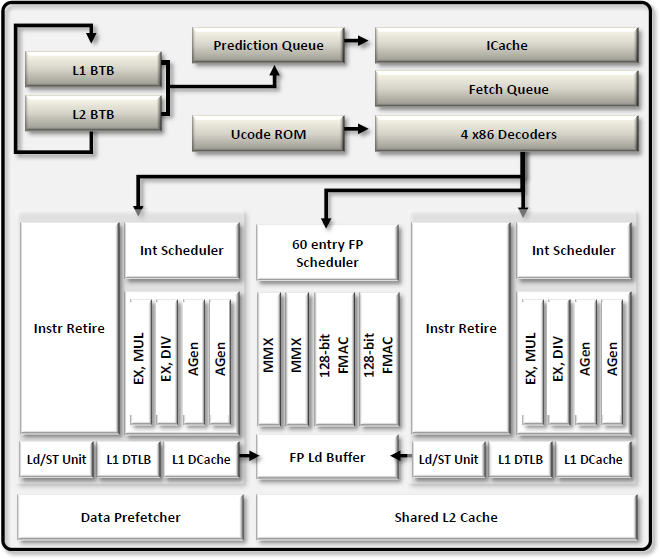 Так выглядит функциональное устройство модуля, построенного на микроархитектуре Bulldozer. От двух ядер осталось лишь два набора целочисленных исполнительных устройств Относительно невысокую сложность имеет и общий на процессорный модуль блок операций с плавающей точкой. В него входит два 128-битных исполнительных устройства FMAC, которые для обработки 256-битных инструкций могут объединяться в единое целое. Казалось бы, и здесь исполнительных устройств не так много, особенно с учётом того, что делятся они на пару ядер. Но зато они — более универсальные, чем в предшествующих и конкурирующих микроархитектурах, где применяются отдельные умножители и сумматоры. И благодаря этому в определённых случаях при работе с вещественными числами двухъядерный модуль Bulldozer может обеспечивать сравнимую и даже более высокую производительность, чем, например, одно ядро Sandy Bridge. 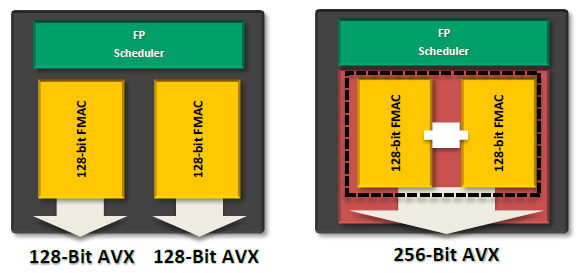 Аналогичная идея объединения 128-битных устройств для работы с 256-битными инструкциями используется и в Sandy Bridge Однако свои самые сильные стороны модуль Bulldozer должен проявлять при двухпоточной нагрузке. Одно ядро Sandy Bridge тоже способно обрабатывать два вычислительных потока, для этого в нём имеется технология Hyper-Threading. Однако все инструкции при этом направляются на один набор исполнительных устройств, что на практике вызывает многочисленные коллизии. В модуле Bulldozer же сохранено два независимых целочисленных кластера, которые могут исполнять потоки параллельно, а суммарное количество исполнительных устройств в них превышает число таких устройств в ядре Sandy Bridge в полтора раза. 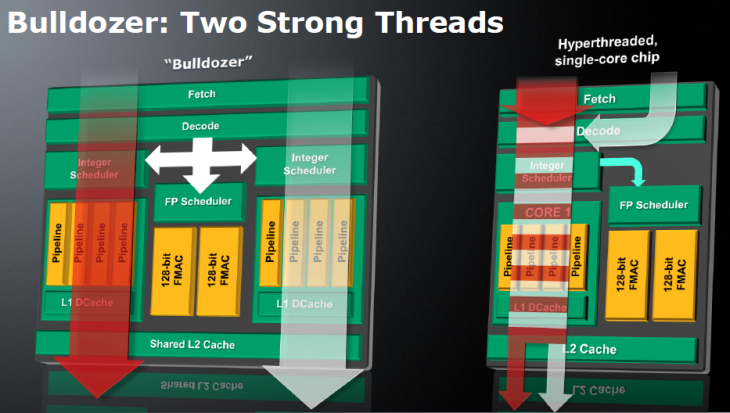 Слева — модуль Bulldozer, справа — некое конкурирующее ядро с поддержкой Hyper-Threading. На самом деле на Sandy Bridge оно не очень-то и похоже, но суть проблемы иллюстрация передаёт В результате модуль Bulldozer обладает более высокой пиковой производительностью, нежели ядро Sandy Bridge, но раскрыть эту производительность несколько сложнее. Ядро Sandy Bridge интеллектуально загружает собственные ресурсы благодаря продвинутой внутрипроцессорной логике, самостоятельно разбирающей однопоточный код и исполняющей его параллельно на полном наборе своих исполнительных устройств. В Bulldozer же задача эффективного использования исполнительных устройств частично перекладывается на программиста, который должен разбить свой код на два потока — полноценная загрузка всех мощностей модуля станет возможной лишь тогда. И вот что характерно. Рассматривая двухъядерный модуль процессора Bulldozer, мы всё время сопоставляли его с одним ядром Sandy Bridge, и при этом нам удавалось проводить вполне корректные параллели. Это заставляет задуматься — не стоит ли считать «восьмиядерность» новой микроархитектуры порождением фантазии маркетологов? AMD говорит, что считать ядра следует по количеству целочисленных кластеров, аргументируя это тем, что модуль способен обеспечить до 80 % производительности двух независимых ядер. Однако не следует забывать, что ядра, положенные в основу Bulldozer, существенно проще ядер других процессоров. Поэтому количество двухъядерных модулей — характеристика, отражающая производительность Bulldozer куда адекватнее. 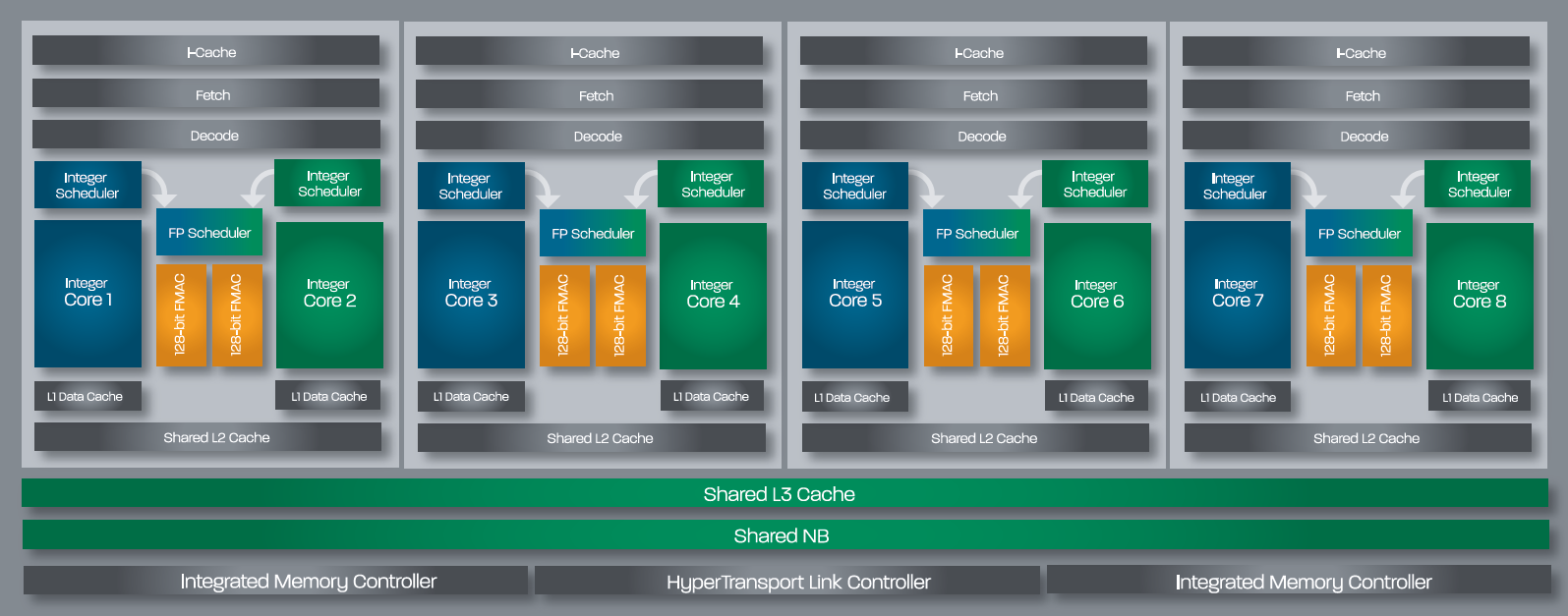 Найди максимальное количество процессорных ядер и получи работу в маркетинговом отделе AMD ⇡#Кеш-памятьОрганизация кеш-памяти в процессорах Bulldozer также «привязана» не столько к отдельным ядрам, сколько к двухъядерным модулям. Фактически на каждое ядро выделен лишь собственный кеш данных первого уровня, все остальные уровни кеш-памяти относятся либо к модулю в целом, либо к процессору:
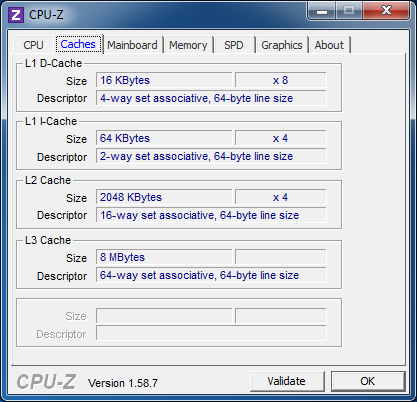 Следующая таблица описывает соотношение объёмов кеш-памяти процессоров восьмиядерных Bulldozer, четырёхядерных Sandy Bridge и Thuban (шестиядерных Phenom II X6, построенных на микроархитектуре K10).
Как видно по таблице, AMD сделала ставку на вместительные кеши верхних уровней, что может быть действительно полезно в случае серьёзной многопоточной нагрузки. Однако кеш-память в новых процессорах в целом работает медленнее, чем у предшествующих и конкурирующих продуктов. Это легко обнаруживается при измерении практической латентности.
Большие задержки при обращении к данным в Bulldozer могут быть компенсированы лишь высокой тактовой частотой этих CPU. Что, впрочем, и планировалось изначально — по частотам новые восьмиядерники должны были превосходить Phenom II на 30 %. Однако AMD так и не смогла спроектировать полупроводниковые кристаллы, способные стабильно работать при столь высоких значениях частоты. В результате высокая латентность кеш-памяти способна нанести системам на базе Bulldozer определённый урон. Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.
Материалы по теме
|
||||||||||||||||||||||||||||||||||||||||||||||||
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.





