







 MWC 2018
MWC 2018 2018
2018 Computex
Computex
⇣ Содержание
|
Опрос
|
реклама
Самое интересное в новостях
Репортаж с NVIDIA GPU Technology Conference
Основные события конференции NVIDIA GPU Technology Conference, которая проходила с 24 по 27 марта в Сан-Хосе, штат Калифорния (один из наиболее известных городов Кремниевой долины), мы кратко освещали в новостных заметках. Главный пункт мероприятия — презентация CEO и основателя компании NVIDIA Дженсена Хуанга, в ходе которой было представлено четыре продукта: графическая архитектура Pascal, видеоадаптер GeForce GTX TITAN Z, платформа Jetson TK1 и рабочая станция для рендеринга Iray VCA. Кроме того, пользуясь возможностью лично присутствовать на GTC, мы выяснили некоторые подробности об инициативах NVIDIA, которых не найти в официальных презентациях и пресс-релизах, участвовали в сессиях для разработчиков и партнеров NVIDIA, которые используют GPU в различных научных и практических задачах. Настало время свести воедино наиболее интересное из того, что мы видели и слышали на GTC. ⇡#PascalДженсен Хуанг продемонстрировал рабочий прототип модуля на основе архитектуры GPU, которая придет на смену использующимся ныне Kepler и Maxwell, — Pascal. Название Volta, которое ранее было зарезервировано за преемником Maxwell, отошло более поздней итерации. Если судить по графику, Pascal принесет радикальное увеличение производительности на ватт по сравнению с Kepler и Maxwell.  Плата прототипа занимает немногим больше места, чем две кредитные карты. Отсутствие видимых разъемов на ней объясняется тем, что модуль соединяется с материнской платой при помощи переходника (riser card). Это означает, что форм-фактор прототипа иной, нежели у существующих карт расширения для шины PCI-E. NVIDIA будет выпускать компактные модули Pascal для установки в серверные корпуса, для чего нужно будет заручиться поддержкой производителей такого оборудования.  Модуль Pascal предназначен для работы с шиной NVLINK, которая в данном случае заменяет PCI-Express как средство коммуникации между GPU и CPU, обещая увеличение пропускной способности в 5-12 раз по сравнению с PCI-E 3.0 и одновременно — трехкратное увеличение энергоэффективности. Топология NVLINK строится на базе блока из восьми линий двусторонней направленности. Отдельно взятый GPU Pascal имеет несколько таких Point-to-Point-соединений, которые можно сгруппировать вместе, образовав высокоскоростной канал связи с CPU, а можно выделить часть из них для коммуникации между графическими процессорами. 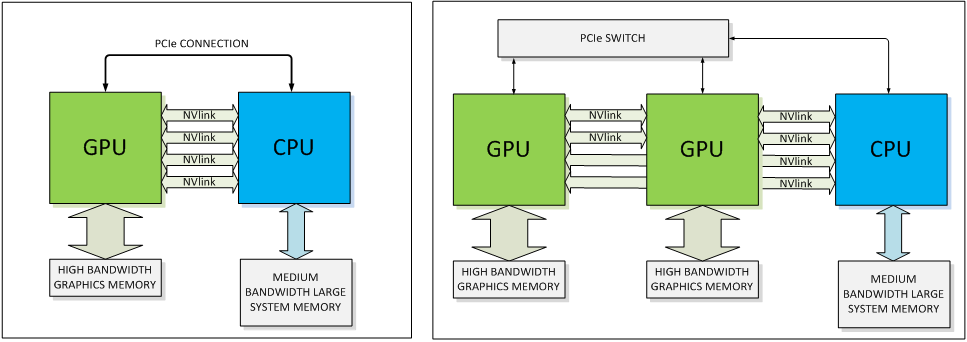 Связь GPU и CPU одновременно осуществляется по интерфейсу PCI-E, дабы сохранить преемственность с существующей моделью программирования. Посредством PCI-Express осуществляются транзакции, инициированные на стороне CPU, посредством NVLINK — напротив, транзакции, инициированные GPU. Сам протокол NVLINK, как было сказано представителями разработчика, не совместим с протоколом PCI-Express, но в случае отсутствия поддержки NVLINK со стороны CPU Pascal может работать в legacy-режиме — на PCI-Express. Планируется выпуск плат для профессионального рынка как в представленном компактном форм-факторе, так и в виде привычных плат расширения PCI-E.  NVIDIA уже заручилась поддержкой IBM, которая внедрит NVLINK в будущих поколениях процессоров Power. С другими производителями CPU ведутся переговоры по этому поводу. Также в архитектуре Pascal NVIDIA впервые применяет Stacked DRAM (или 3D Memory, в терминологии самой NVIDIA). Такие чипы представляют собой несколько микросхем DRAM, соединенных между собой еще на стадии производства полупроводниковой пластины (wafer). Согласно одному из слайдов, посвященных Pascal, его шина будет в два-четыре раза шире по сравнению с текущим поколением GPU, вплоть до тысяч битов. Кроме того, Stacked DRAM обладает в четыре раза меньшим энергопотреблением по сравнению с обычной памятью. Чипы размещаются на одной подложке (interposer) с GPU, что облегчает разводку сложнейшей шины. NVIDIA, по всей видимости, будет поставлять партнерам interposer с заранее установленным GPU и видеопамятью. 18 чипов, окружающих подложку GPU на плате прототипа, представляют собой компоненты системы питания. 3DRAM будет применяться во всем диапазоне продуктов на базе архитектуры Pascal, включая мобильные GPU. 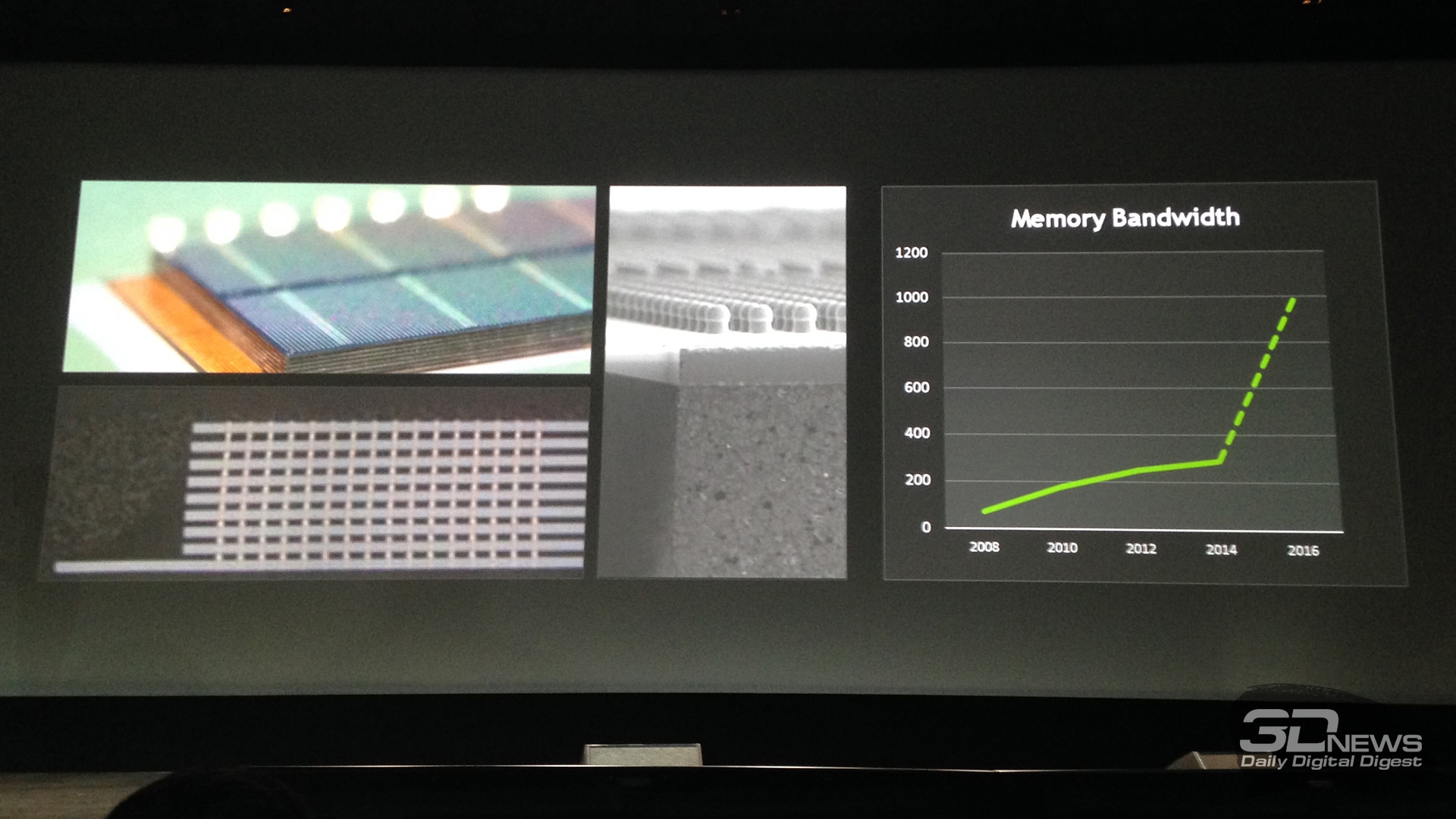 Отметим, что NVIDIA пока не раскрывает никаких подробностей о потребительских продуктах на базе GPU Pascal. Будет ли в десктопных видеоадаптерах применяться шина NVLINK, остается неизвестным, как и любые подробности касательно архитектуры самого графического процессора. ⇡#GeForce GTX TITAN ZВслед за Pascal была анонсирована «двухголовая» видеокарта, представляющая собой комбинацию двух чипов GK110 с полностью функциональным набором ядер CUDA — 2880. Впрочем, если судить по тому, что заявленная производительность TITAN Z составляет 8 TFOPS, а единственный адаптер GeForce TITAN Black имеет вычислительную мощность 5,1 TFLOPS, сдвоенный адаптер должен работать на пониженных частотах.  На GTC мы успели сделать несколько эксклюзивных кадров TITAN Z. Адаптер выполнен в симметричном корпусе с единственным вентилятором системы охлаждения — он напоминает GeForce GTX 690, за исключением того, что TITAN Z занимает не два, а три корпусных слота. В апреле ожидается более подробная информация об устройстве и возможность получить тестовый семпл для полноценного обзора.   Рекомендованная розничная цена GeForce GTX TITAN Z для рынка США составляет $2 999. Это практически в три раза больше, чем стоимость единственной платы GTX TITAN Black. По всей видимости, TITAN Z, как и вся линейка TITAN, предназначен не столько для геймеров, сколько для тех пользователей, которые требуют поддержки расчетов с двойной точностью (FP64), но по каким-либо причинам не согласны на покупку NVIDIA Tesla, которая является специализированным акселератором вычислений.  ⇡#Jetson TK1Третий из крупных анонсов GTC — платформа для разработчиков Jetson TK1 на базе SoC Tegra K1. Цель NVIDIA — подстегнуть разработку встраиваемых систем, использующих GPU для параллельных вычислений, включая те задачи, в которых ранее использовались чипы FPGA, ASIC и DSP.  GPU в составе чипа обладает архитектурой Kepler и содержит 192 ядра CUDA. Таким образом, Jetson TK1 является идейным наследником предыдущего комплекта для разработчиков под названием Kayla, который был представлен на прошлогодней GTC и представлял собой двухчиповое решение на базе Tegra 3 и дискретного GPU GK208. К слову, в следующей итерации платформы Tegra — Erista — будет использоваться GPU на архитектуре Maxwell. 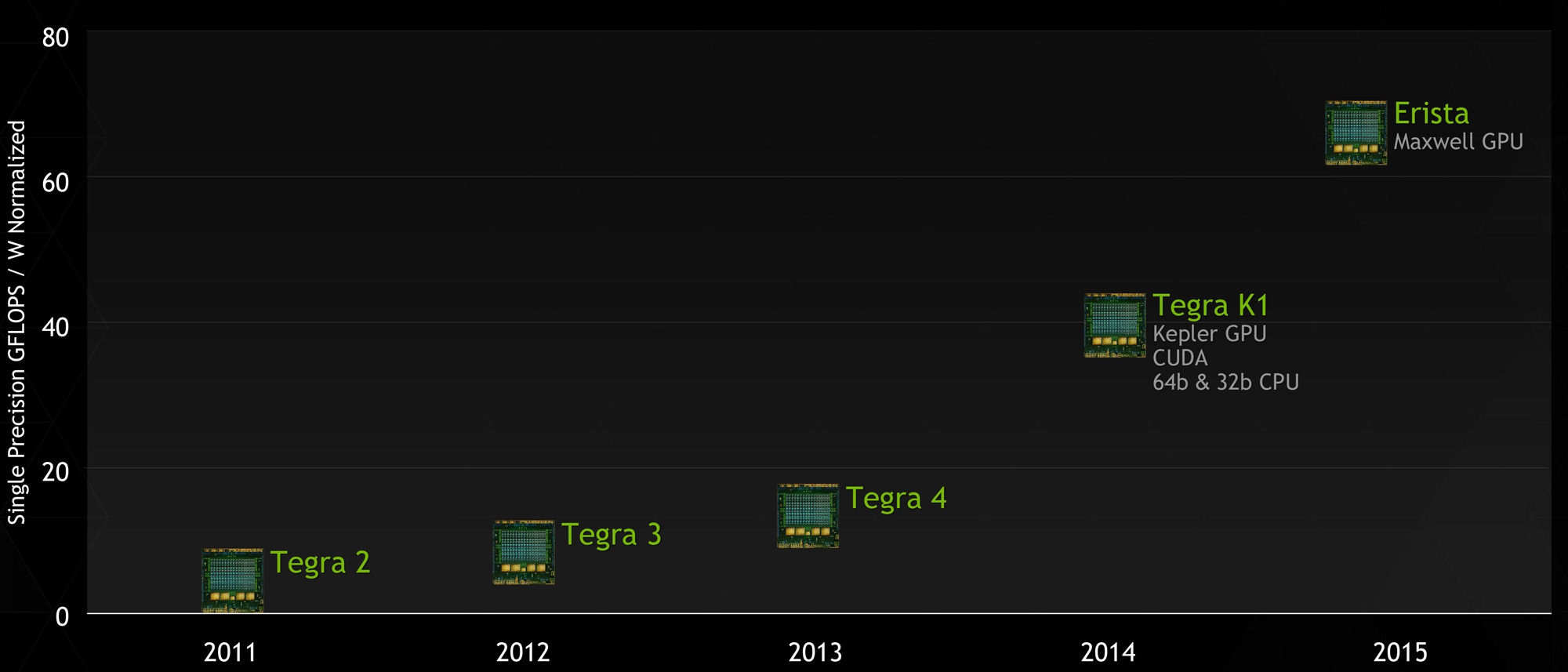 На плате Jetson TK1 распаяно 2 Гбайт RAM, 16 Гбайт flash-памяти, слот для SD-карт и порт SATA. Для коммуникации с внешними устройствами предусмотрены разъемы USB 3.0, HDMI 1.4, Gigabit Ethernet и COM-порт. На SoC нет предустановленного кулера, но благодаря тому, что энергопотребление Tegra K1 не превышает 10 Вт, разработчики могут решить эту задачу самостоятельно. Jetson поддерживает полный набор инструментов программирования под API CUDA 6.0. Платформа работает под управлением 32-битной версии Ubuntu 13.04 для архитектуры Tegra. Кроме того, NVIDIA портировала на ARM-библиотеки VisionWorks, которые содержат алгоритмы так называемого машинного зрения — оно применяется в робототехнике, автомобильных компьютерах, системах дополненной реальности и так далее. Jetson TK1 предназначен для разработки приложений под Tegra K1, которые затем будут перенесены на готовые устройства произвольного форм-фактора. С другой стороны, многие готовы использовать Jetson TK1 как он есть, особенно в таких случаях, когда нет ограничений на габариты. Устройство можно заказать на сайте NVIDIA за $192. Поставки начнутся в апреле. Тогда же, как можно предположить, партнеры NVIDIA получат первые партии SoC Tegra K1. Помимо платы Jetson, представленной на GTC, NVIDIA выпустила аналогичный комплект Jetson Pro, предназначенный специально для установки в автомобили. В отличие от Jetson TK1, Jetson Pro комплектуется относительно старым SoC Tegra 3, но обладает слотом PCI-E для опциональной установки дискретного GPU.  В ходе GTC были продемонстрированы примеры практического применения Tegra K1 во встраиваемых компьютерах. NVIDIA переделала приборные панели нескольких авто, полностью заменив механические органы управления бортовыми системами огромным сенсорным дисплеем. Отдельный экран занимает место приборной панели.   К слову, электрокар Tesla Model S в штатной поставке оснащается бортовым компьютером на базе Tegra с 17-дюймовым экраном.  Но CUDA во встраиваемых решениях имеет и более интересные применения, нежели рендеринг пользовательского интерфейса. На GTC мы увидели модифицированную Audi, которая обладает возможностями автопилота. С помощью библиотек VisionWorks на Tegra K1 реализуются функции машинного зрения для помощи человеку в процессе вождения. Бортовой компьютер находит свободное место для парковки в ряду машин, может отслеживать разделительные полосы на дороге. Камера, обращенная внутрь салона, наблюдает за тем, не уснул ли водитель за рулем.   ⇡#Iray VCAIray VCA (Visual Computing Appliance) — сетевая рабочая станция в формате 19-дюймовой стойки, предназначенная для ускорения трассировки лучей в рендерере NVIDIA Iray. Iray используется в таких приложениях, как CATIA от Dassault Systemes и 3ds Max от Autodesk. В состав VCA входят восемь полностью функциональных процессоров GK110 (2880 ядер CUDA в каждом). С помощью интерфейса InfiniBand несколько Iray VCA можно объединить в кластер. С точки зрения железа Iray VCA сопоставим с другим продуктом NVIDIA — GRID VCA. Разница в том, что GRID VCA выполняет функции виртуализации GPU в формате «один GPU — один пользователь». Напротив, Iray VCA объединяет вычислительные возможности нескольких GPU в рамках одной задачи. Его основное назначение — рендеринг фотореалистичных изображений методом трассировки лучей (Ray Tracing). Ray Tracing используется не только в графическом дизайне, но и в промышленности. К примеру, производители автомобилей таким образом создают физически достоверные модели машин, с помощью которых можно исследовать некоторые параметры проекта без необходимости производить материальный прототип.  Речь идет не о статичных изображениях или предварительно отрендеренных видеороликах, а о манипуляции моделью в реальном времени, как это происходит в компьютерных играх. Правда, в отличие от игр, в силу чрезвычайно высокой ресурсоемкости метода Ray Tracing, для этой задачи требуется одновременно нескольких десятков GPU. Honda первой построила кластер из 25 Iray VCA, который позволяет выполнять трассировку лучей в реальном времени для моделирования автомобилей — как внешнего дизайна, так и всех деталей, которые находятся внутри.  Предварительная розничная цена Iray VCA на рынке США составляет $50 000. Вместе с оборудованием клиент получает лицензию на NVIDIA Iray, а также ПО Iray VCA Cluster Manager. VCA также найдет применение для анализа больших объемов геологических данных при помощи ПО NVIDIA IndeX.  Достоинства Ray Tracing по сравнению с растеризацией — методом рендеринга, используемым в играх, — были наглядно показаны в презентации Pixar, которая также участвовала в GTC. Посмотрите на список локальных источников света, которые дизайнер был вынужден расставлять вручную, чтобы получить аппроксимацию реалистичного освещения без применения Ray Tracing.  Трассировка лучей позволяет обойтись несколькими «физическими» источниками, распространение света от которых симулируется с учетом отражения от поверхностей всех предметов в кадре.  Рендеринг методом Ray Tracing имеет особенность: сначала формируется очень шумная картинка, которая проясняется с течением времени. Это не проблема для Pixar, поскольку видео записывается «в офлайне», но для создания моделей автомобилей, которыми можно манипулировать в реальном времени, требуются именно такие мощности, какими обладает кластер NVIDIA Iray VCA.  ⇡#Подробности о DirectX 12После консультации с сотрудниками NVIDIA мы подготовили дополнение к предварительному обзору грядущего API от Microsoft, который мы сделали ранее по горячим следам. Прежде всего, стало известно, что спецификации API уже финализированы в достаточной степени, чтобы два из трех ведущих производителей GPU (NVIDIA и Intel) выпустили драйвер под DirectX 12 для закрытого использования. Таким образом, разработчики приложений могут заранее приступить к внедрению DX12. Напомним, что Mircosoft пообещала появление первых игр с поддержкой DX12 в конце 2015 года. AMD пока задерживается с драйвером для собственных GPU. 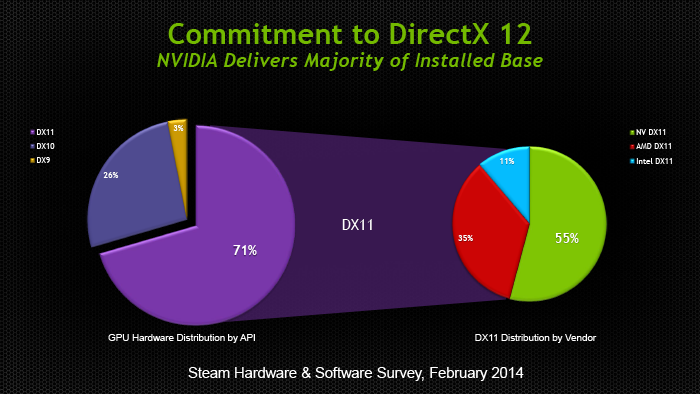 Мы получили ответ на вопрос, почему DirectX 12 часто описывают как более низкоуровневый API по сравнению с DirectX 11. Runtime-библиотека Direct3D больше не выполняет некоторые функции управления ресурсами, свойственные ей в предыдущей версии. Теперь приложение само должно следить за тем, по каким адресам в памяти расположены ресурcы. С одной стороны, эта модель более эффективна, поскольку приложение «знает», как и для чего используются ресурсы. Runtime-библиотека в модели Direct3D 11 вынуждена предсказывать такие вещи на основании поступающих от приложения вызовов. В DX12 разработчики игровых движков получат возможность лучше дифференцировать свои продукты. С другой стороны, писать код под DirectX 12 для неопытных разработчиков станет сложнее. Есть уточняющий комментарий к диаграмме распределения нагрузки между потоками CPU в 3DMark, который ранее был опубликован в блоге на MSDN. В разделе DirectX 12 из диаграмм пропал компонент драйвера, исполняемый в Kernel Mode. На самом деле он никуда не делся, просто, по всей видимости, его исключили для простоты представления, или же этот компонент стал настолько «тонким», что неразличим в использованном масштабе. 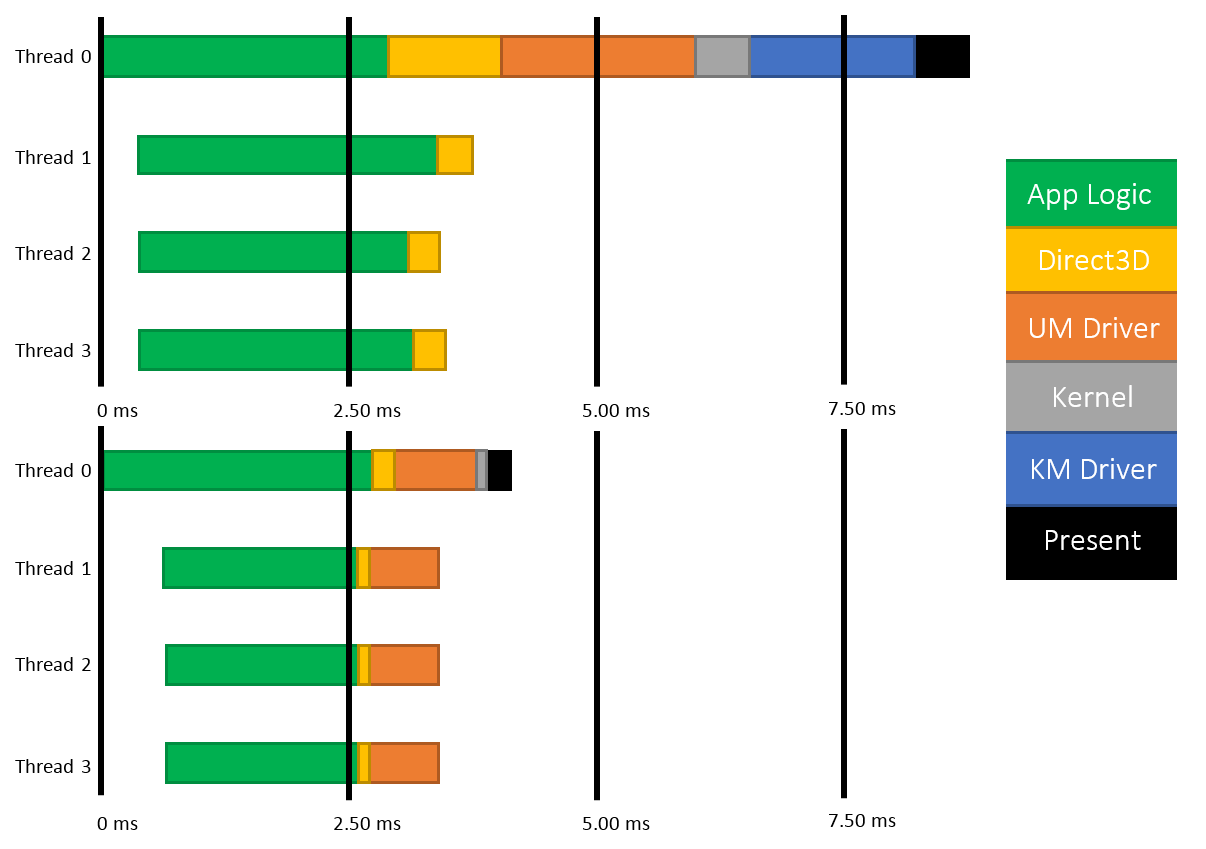 Кроме того, у NVIDIA есть результаты измерений, которые напрямую отражают снижение расхода производительности (overhead) при смене состояний конвейера Direct3D, что является одним из главных достоинств DirectX 12. В наиболее благоприятном случае достигается разница в 3,8-4,3 раза. 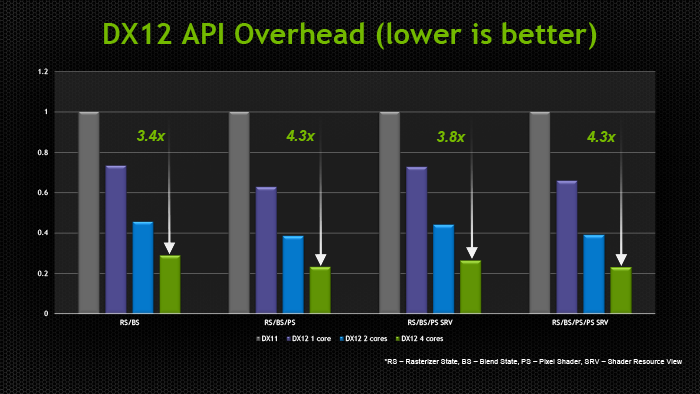 Наконец, стоит прокомментировать, что подразумевается под совместимостью с DirectX 12 существующих графических процессоров, поддерживающих DirectX 11. Номер DirectX, с одной стороны, указывает на версию runtime-библиотеки, в которой-то и произошли самые большие изменения на этот раз. С другой стороны, есть feature level, который определяет набор функций, доступных GPU. К примеру, библиотекой Direct3D 11.2 поддерживаются feature levels от 9_1 до 11_1, которые соответствуют графическим процессорам, выпущенным в разное время «под DirectX 9, 10 и 11». Точно так же все это оборудование будет использоваться и библиотекой Direct3D 12. В то же время Direct3D 12 принесет новый feature level. Полный список нововведений пока не разглашается, но известны три из них. Pixel Shader Ordering представляет собой механизм контроля за доступом пиксельного шейдера к ресурсам в определенном порядке, что предотвращает появление артефактов при отрисовке прозрачных объектов. Это подобие расширения PixelSync, которое Intel ранее ввела для GPU Iris. Еще одна аппаратная функция — Conservative Rasterization — обеспечивает более эффективное отсечение невидимых поверхностей на ранних стадиях рендеринга. 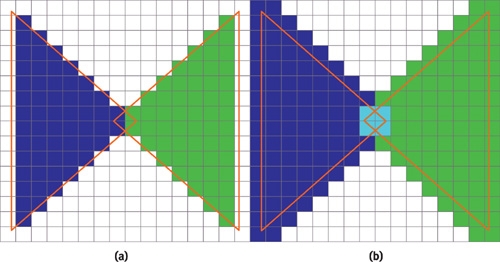 а) стандартная растеризация, б) консервативная растеризация Список закрывает поддержка новых форматов сжатых ресурсов — ASTC (ранее представлен ARM, поддерживается официальным расширением OpenGL) и JPEG. Ну а пока еще не существует коммерческих продуктов на основе DirectX 12, NVIDIA работает над оптимизацией драйвера GPU под DirectX 11. В одном из следующих релизов существенно сокращен overhead при смене состояний конвейера, что отражается на производительности в задачах, интенсивно нагружающих CPU. 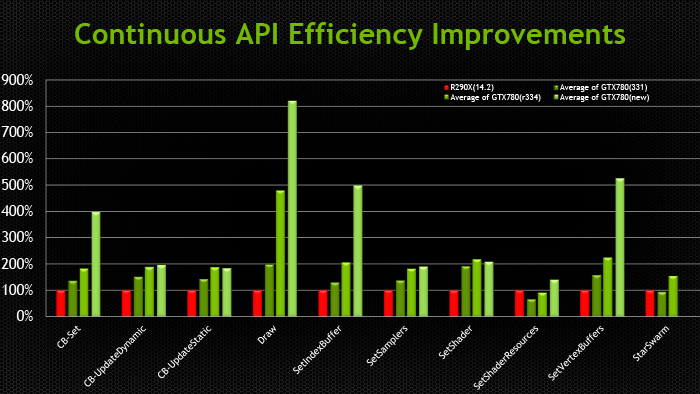 В бенчмарке Star Swarm, чрезвычайно тяжелом для CPU за счет генерации фантастического количества draw calls, GeForce GTX 780 Ti под DirectX 11 оставляет позади Radeon R9 290X, работающий под Mantle. Кроме того, поскольку Star Swarm настолько завязан на производительность CPU, бонус, который Radeon R9 290X получает от Mantle, и отставание от GTX 780 Ti в режиме DirectX 11, указывает на серьезные недостатки существующего драйвера AMD под DX11. 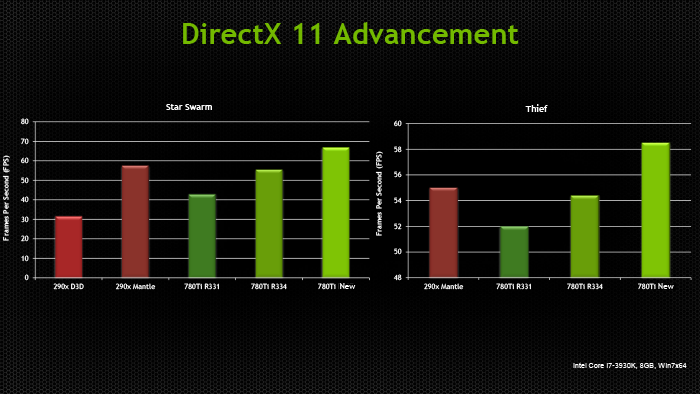 ⇡#Компьютерные игры как средство развития когнитивных способностейВ одной из основных презентаций GTC была представлена перспективная инициатива — повысить когнитивные способности людей и поддержать последние в период старения при помощи задач, сходных с компьютерными играми, или даже полноценных игр, сконструированных на базе научной модели. Известно, что с возрастом когнитивные способности человека неуклонно снижаются. К примеру, одновременное выполнение нескольких задач, требующих концентрации внимания, у 20-летних испытуемых вызывает на 27% больше ошибок, чем при выполнении одной задачи, а на восьмом десятке разница достигает уже 63%. 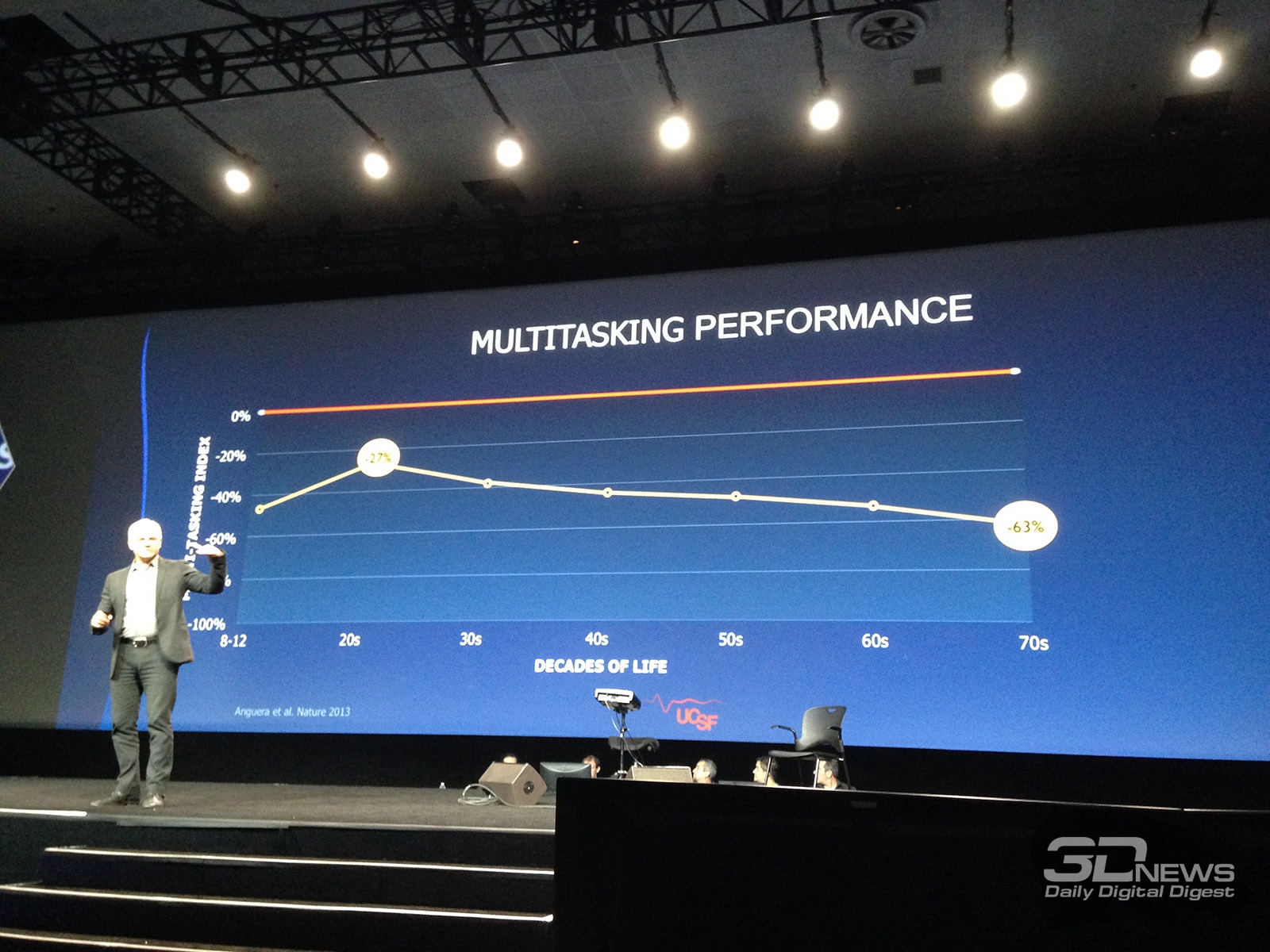 Существует множество способов в той или иной степени компенсировать угасание когнитивных способностей, из которых чаще всего применяется фармакологическая терапия. Но этот метод имеет ряд существенных издержек: неточное определение источника проблем, недостаточный учет индивидуальных особенностей пациента, длительный цикл «воздействие — оценка результатов».  Адам Газзали (Adam Gazzaley, профессор нейрологии, физиологии и психиатрии, директор UCSF Neuroscience Imaging Center) исследует способы терапии и профилактики снижения когнитивных способностей путем тренировки в интерактивной среде, которую смело можно назвать компьютерной игрой. В исследовании Газзали, опубликованном журналом Nature, уже получены результаты испытаний ранней версии такой программы под названием NeuroRacer. В этом подобии автосимулятора требуется одновременно управлять машинкой и реагировать нажатием клавиш на появление определенных сигналов. Тренировка в NeuroRacer на протяжении месяца позволила пожилым испытуемым существенно повысить не только успешность в самой игре, но и способности, измеренные отдельно, — удержание внимания и рабочую память. 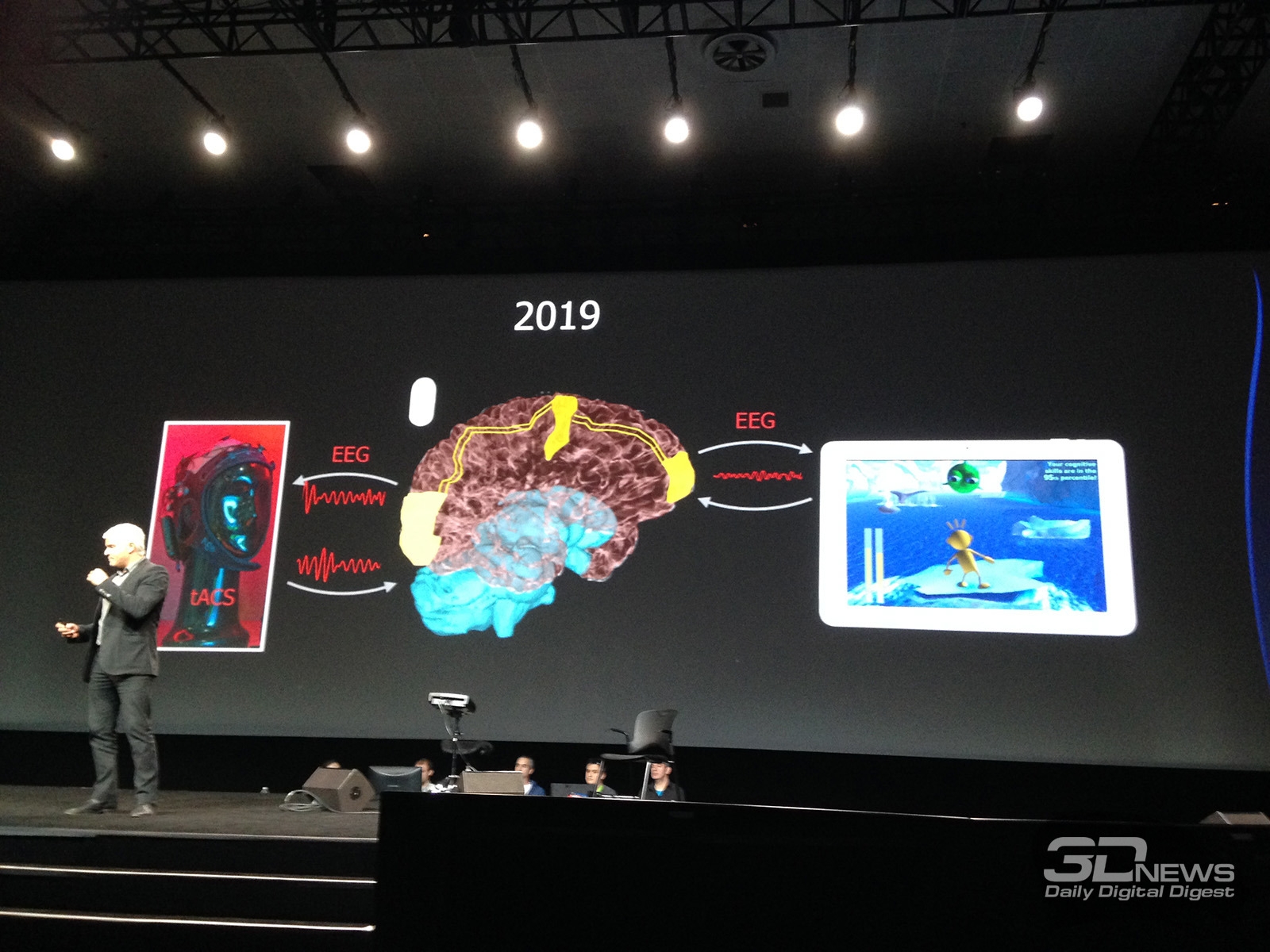 Адам Газзали показал, что уже сегодня можно использовать для тех же целей более насыщенное игровое окружение, в том числе — на мобильных устройствах. Этим сейчас занимается команда Akili Interactive Labs, куда входит Газзали. Игра Project:EVO для платформ iOS и Android проходит испытание и валидацию на различных выборках испытуемых. В будущем дополнительно к непосредственной активности пользователя предлагается регистрировать его ЭЭГ (электроэнцефалограмму) и даже применять стимуляцию мозга посредством пропускания малых токов через кожу черепа. Аналогичная игра Neuro Drummer построена на идее связи когнитивных способностей и ритмической активности. На сцену вышел перкуссионист Микки Харт (Mickey Hart), известный своей работой в группе Grateful Dead, чтобы продемонстрировать следующий опыт. На испытуемом были надеты очки виртуальной реальности Oculus Rift и шапка для регистрации ЭЭГ. Под музыкальную «минусовку» Микки играл на виртуальной ударной установке, тем самым управляя событиями в игровой среде. Зрители наблюдали за тем, что происходит в очках Микки. Одновременно на экран выводилась визуализация активности мозга, выполненная программой Glass Brain. Анализ данных ЭЭГ в реальном времени выполнялся на GPU NVIDIA. В будущих версиях Neuro Drummer появятся более разнообразные когнитивные задачи — запоминание, классификация и так далее.  ⇡#ИтогиФокус конференции в этом году полностью сместился из области графики к параллельным вычислениям средствами GPU. Четыре главных продукта, которые были анонсированы в презентации Дженсена Хуанга (архитектура Pascal, GeForce GTX TITAN Z, платформа Jetson TK1 и установка Iray VCA), так или иначе предназначены для вычислительных задач в не меньшей степени, чем для 3D-рендеринга. Даже Pascal был представлен в форме модуля для корпоративных систем, а TITAN Z, как и его предшественники в семействе TITAN, позиционируется как «просьюмерский» графический адаптер, отличительной чертой которого является поддержка вычислений двойной точности. Благодаря SoC Tegra K1 архитектура Kepler, а следовательно — API CUDA, распространилась во всей линейке устройств, которые выпускает NVIDIA. Нельзя сказать, что процессоры Tegra пользуются сногсшибательным успехом в мобильном сегменте, но появление K1 по меньшей мере подготовило плацдарм для вторжения NVIDIA в другую область — встраиваемые системы, где на базе параллельных вычислений реализуются функции машинного зрения, дополненной реальности и прочие некогда абсолютно фантастические инициативы. С чисто технологической точки зрения не менее значим другой анонс — архитектура Pascal, а именно одна из ее особенностей — высокоскоростная шина NVLINK для коммуникации между GPU и CPU. Презентация проприетарного аппаратного интерфейса — довольно дерзкий ход со стороны NVIDIA, но нельзя не приветствовать его как средство дальнейшей интеграции центрального и графического процессоров. Интересно, что в недавнем интервью с инженером ПО из Intel мы говорили о похожих вещах: машинном зрении, системах-на-чипе, параллельных вычислениях. AMD, будучи одновременно производителем GPU и процессоров на архитектуре x86, также ведет разработки в этой области. Архитектура и функции компьютеров меняются на наших глазах.
⇣ Содержание
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.
Материалы по теме
|
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.











