|
Опрос
|
реклама
Быстрый переход
Alibaba предоставила Moonshot вычислительные мощности на 20 000 чипов Nvidia для обучения моделей Kimi
02.08.2026 [06:13],
Алексей Разин
Издание The Information уже сообщало, что китайский стартап Moonshot для обучения своих ИИ-моделей Kimi мог использовать ускорители Nvidia семейства Blackwell, поставки которых в КНР официально запрещены. Агентство Bloomberg выяснило, что китайская Alibaba согласилась предоставить для этих нужд вычислительный кластер с 20 000 чипов Nvidia, но относящихся к поколению Hopper. 
Источник изображения: Nvidia Речь конкретно идёт об ускорителях Nvidia H200, которые архитектурно уступают обсуждавшимся ранее Blackwell. По данным Bloomberg, между Alibaba и Moonshot заключено соответствующее соглашение, которое позволяет последнему стартапу использовать вычислительный кластер Alibaba с указанными характеристиками. Именно этот арендуемый кластер формирует основную часть мощностей, которые Moonshot способна использовать для обучения своих ИИ-моделей серии Kimi. Подобное сотрудничество не должно быть сюрпризом: Alibaba является одним из крупнейших инвесторов в капитал Moonshot, и традиционно китайский интернет-гигант предлагает компаниям, которым оказывает финансовую поддержку, арендовать у него вычислительные мощности. Представители Alibaba в комментариях Bloomberg опровергли слухи о предоставлении в аренду чипов Nvidia H200 стартапу Moonshot, но при этом не стали отрицать, что количество неких чипов Nvidia в этом случае достигло 20 000 штук. Правда, успех моделей Kimi, которые конкурируют с собственными разработками Alibaba семейства Qwen, стал причиной разочарования некоторых руководителей указанного китайского холдинга, поскольку по факту он своими руками взрастил себе серьёзного конкурента. Американские чиновники считают, что доступ к ускорителям Nvidia Blackwell имеет не только Moonshot, но и Deepseek. Предполагается, что китайские стартапы могли арендовать эти ускорители у компании, расположенной в Таиланде. Более того, американская сторона считает, что Moonshot при обучении Kimi K3 использовала метод дистилляции передовой модели Fable американской компании Anthropic, и это позволило получить впечатляющий результат при ограниченных вычислительных ресурсах. Законы США не запрещают китайским разработчикам арендовать вычислительные мощности с продвинутыми чипами Nvidia за пределами КНР, но не позволяют приобретать их в собственность. Поставки ускорителей Nvidia H200 в Китай по официальным каналам до сих пор измерялись незначительными объёмами. Nvidia подняла цены на свои GPU ещё на 20–30 %
01.08.2026 [05:44],
Алексей Разин
Обыватели могут судить о последствиях таких действий поставщиков графических процессоров только опосредованно, поскольку публично цены на GPU никогда не разглашаются, но издание Eurogamer со ссылкой на Economic Daily сообщило, что Nvidia недавно подняла стоимость своих GPU ещё на 20–30 %. 
Источник изображения: Nvidia Это уже третий случай повышения цен на основной вид продукции данной компании с начала текущего года, но подобные шаги поставщика уже перестали удивлять аудиторию, поскольку в условиях бума искусственного интеллекта закономерно дорожают те компоненты, которые больше всего востребованы при строительстве вычислительной инфраструктуры. В наступившем месяце Nvidia будет подводить итоги фискального квартала, по опубликованной статистике можно будет судить о динамике её финансовых показателей. В мае, как отмечает источник, повышение цен на продукцию Nvidia коснулось главным образом старших моделей игровых видеокарт типа GeForce RTX 5090, но нынешнее повышение охватило более широкий ассортимент моделей, хотя точные данные и не приводятся. Поднять цены на свою память на величину до 20 % собирается и компания Samsung Electronics, поэтому обладание новым игровым компьютером становится всё более дорогим удовольствием. Китайские продавцы компьютерных компонентов даже придерживают в реализации ту продукцию, которая должна вскоре подорожать, чтобы реализовать её по более высоким ценам. Всё это усиливает дефицит в рознице и деморализует покупателей. Игровые консоли тоже дорожают, и даже производительные смартфоны становятся всё менее доступной игровой платформой в условиях бума ИИ. Google планирует за пару лет расширить выпуск ИИ-чипов TPU до 12–15 млн в год — прямо как Nvidia
31.07.2026 [16:39],
Павел Котов
Google в ближайшие годы намеревается резко нарастить производство собственных чипов для искусственного интеллекта и выйти на уровень производства компании Nvidia. По неофициальной информации, в 2028 году Google рассчитывает развернуть от 12 млн до 15 млн новейших ускорителей TPU v9. 
Источник изображения: cloud.google.com Если эти цифры подтвердятся, Google действительно достигнет показателей Nvidia: по оценкам аналитиков, в течение 2026 года Nvidia поставит 8,2 млн графических процессоров для центров обработки данных, и к 2028 году этот показатель может вырасти до 12,4 млн. Таким образом, один облачный провайдер готов выпускать ИИ-ускорители в объёмах, сопоставимых с ведущим поставщиком коммерческих чипов. В Google TPU девятого поколения, которые дебютируют как раз в 2028 году, будут использоваться четыре вычислительных кристалла, что соответствует общеотраслевому тренду на чиплетную компоновку; запланированный объём производства, как ожидается, более чем вдвое превысит потребности по сравнению с уровнем 2027 года. Размещение нескольких больших кристаллов на одном чипе требует передовых технологий межсоединений и упаковки, а их выпуск в больших масштабах усложняет задачу. Ограничивающим фактором грозят стать производственные мощности: TSMC в одиночку с таким заказом не справится, и, возможно, придётся подключать производственное подразделение Intel. Технологии упаковки у разных производителей отличаются, и используемые Intel EMIB или EMIB-T не имеют прямой совместимости с CoWoS-L. Google разрабатывает собственные чипы уже около десяти лет, и их роль в инфраструктуре увеличивается. Первоначально это был способ поддержать рабочие нагрузки, а сейчас речь идёт о широкой стратегии облачного бизнеса. Если Google в 2028 году достигнет своей цели, она может стать крупнейшим пользователем ИИ-ускорителей. Это не значит, что закупки у Nvidia придётся прекратить, но у Google будет значительно больше контроля над собственный вычислительной инфраструктурой и поставками. Сравнительных тестов Google TPU девятого поколения с Nvidia Rubin и Rubin Ultra пока нет. Масштаб планов поискового гиганта указывает, что конкуренция на рынке оборудования для ИИ всё больше зависит от объёмов развёртывания, а не только от производительности чипов. Разработчики Path of Exile 2 наконец устранили зависания, которые мучили игроков с самого релиза — виновата была Nvidia
30.07.2026 [17:20],
Михаил Романов
Технический директор новозеландской студии Grinding Gear Games Джонатан Роджерс (Jonathan Rogers) в новом видео отчитался, как команда разработки Path of Exile 2 исправила один из самых назойливых багов в игре, и при чём здесь Nvidia. 
Источник изображений: Grinding Gear Games С самого релиза Path of Exile 2 игроков преследовала проблема: кратковременное (или не очень) зависание из-за ошибки Device Removed, которое сначала приводило к вылету, а впоследствии — к возвращению в игру после загрузки. По словам Роджерса, неурядицы затронули лишь владельцев видеокарт Nvidia с драйвером 566.36 (вышел за день до Path of Exile 2) и новее. Виновником проблем оказался драйвер, однако Nvidia не спешила на помощь. 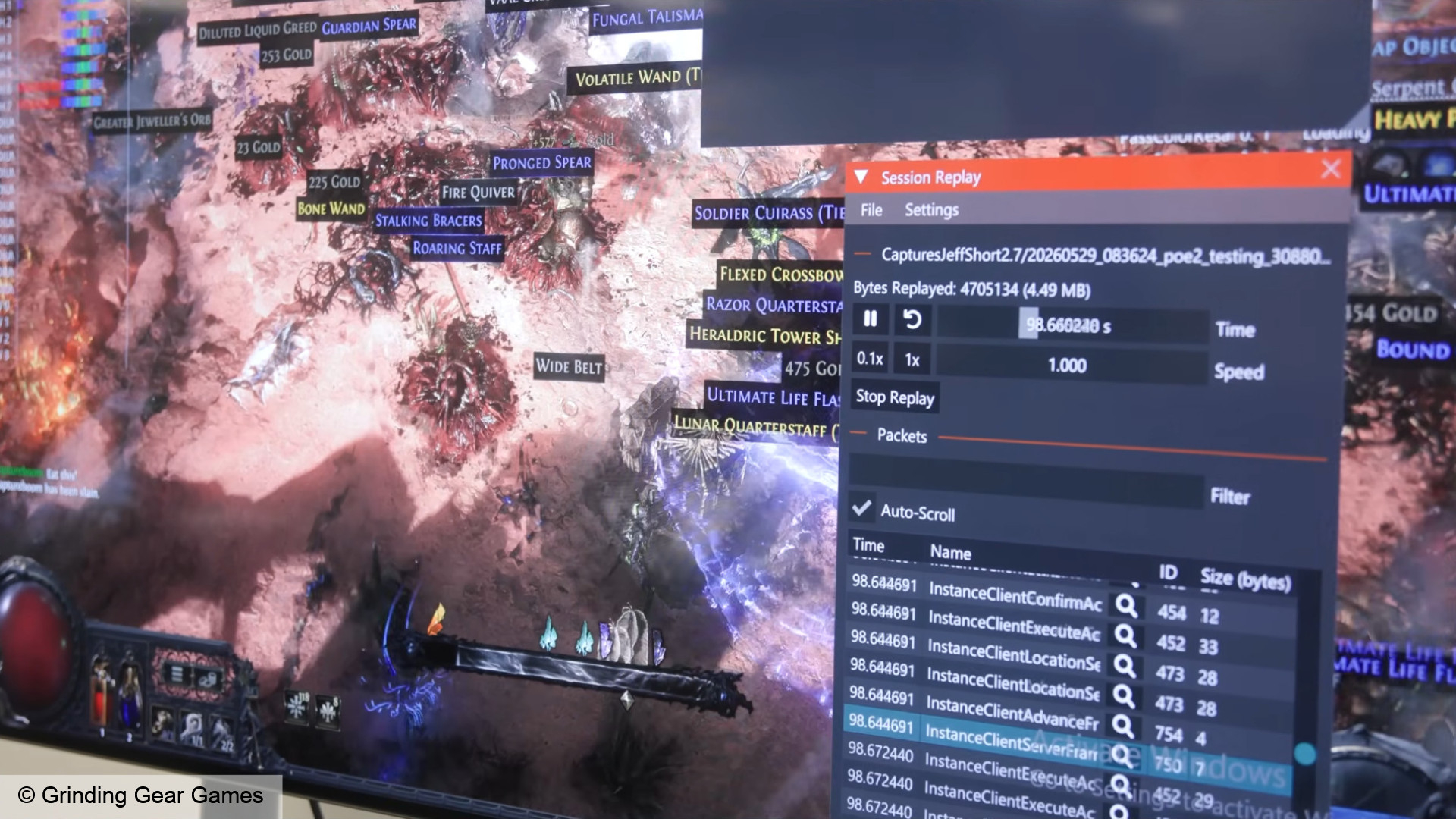
Проблема была в объёме памяти, который драйвер резервирует под шейдеры Несмотря на распространённость проблемы, в студии не могли систематически её воспроизвести — зависание происходило в ходе продолжительной игровой сессии. Nvidia, соответственно, не могла помочь. С помощью системы повторов и целого ряда отладочных инструментов разработчики справились с задачей. Проблемную сборку игры вместе с компьютером, на котором происходил сбой, отправили Nvidia. Недавний драйвер 610.88 исправил проблему. Со своей стороны разработчики Path of Exile 2 существенно сократили время загрузки шейдеров и их размер, что тоже должно позитивно отразиться на игровом опыте. Обновление доступно в рамках патча 0.5.4e. Платный ранний доступ Path of Exile 2 стартовал 6 декабря 2024 года на PC (Steam, EGS, отдельный клиент), PS5, Xbox Series X и S. С полноценным релизом в 2026-м игра вслед за первой частью станет условно-бесплатной. Нашумевшую ИИ-модель Kimi K3 обучали на чипах Nvidia Blackwell вопреки запретам США и Китая, но это не точно
29.07.2026 [17:38],
Павел Котов
Китайский стартап Moonshot AI для обучения революционной модели искусственного интеллекта Kimi K3 использовал ускорители Nvidia Blackwell. Чтобы получить передовые вычислительные мощности, компании пришлось обойти как экспортный контроль США, так и импортный контроль Китая. 
Источник изображения: nvidia.com Превосходство над соперником в гонке искусственного интеллекта США и Китай считают своей жизненно важной целью, и одним из очагов напряжённости в этой борьбе являются ускорители Nvidia Blackwell. Вашингтон запретил их экспорт в Китай, а Пекин — их импорт, потому что в стране разрабатывается собственная экосистема чипов для ИИ. Но это не нравится простым разработчикам, которые стремятся обходить эти ограничения. Вот и Moonshot AI, если верить источникам ресурса The Information, всё-таки успешно обучила Kimi K3 на чипах Blackwell и до сих пор стремится получить дополнительный доступ к ним в рамках разработки Kimi K4. Стартап обратился к двум местным компаниям, которые сумели обзавестись ускорителями Blackwell в своих центрах обработки данных, несмотря на ограничения. Учитывая, что эти ускорители сейчас в дефиците даже при законных схемах приобретения, ни у одной из компаний не оказалось их достаточного количества для обучения Kimi K3. Поэтому Moonshot AI пришлось придумать, как объединить несколько серверов Blackwell в разных ЦОД, чтобы использовать их ресурс. Появление Kimi K3 спровоцировало новый виток гонки разработчиков ИИ в Китае при том, что обучение перспективных моделей сложно или вообще невозможно на многообещающих, но медленно развивающихся китайских ускорителях — они отстают на одно или два поколения от оборудования Nvidia, а списки ожидания расписаны на несколько месяцев. А вот в задачах инференса Moonshot AI использует ускорители Nvidia HGX H20, которые разрешены для работы в Китае и Вашингтоном, и Пекином — для запуска Kimi K3 компания рекомендует использовать системы с как минимум 64 ускорителями. Из-за таких требований и привлекательности самой модели у компании быстро закончились доступные вычислительные ресурсы, и на подписку тоже установилась очередь. Учитывая, что это модель с открытыми весами, другие поставщики в ближайшее время также предложат доступ к ней. Кроме того, Moonshot AI теперь закупила оборудование на системах Nvidia GB300, а также арендовала вычислительные мощности GB300 в Таиланде, утверждает советник Белого дома по ИИ Майкл Крациос (Michael Kratsios). Первое является прямым нарушением запрета США, а второе пока ещё легально — Вашингтон пока не вынес прямого запрета китайским компаниям арендовать подсанкционное оборудование. Покупка этих ускорителей нарушает запрет и Пекина, но едва ли Moonshot AI сейчас ждёт наказание за это — компания помогает стране догнать Anthropic и OpenAI. Nvidia выпустила драйвер с поддержкой Halo: Campaign Evolved и беты мультиплеера Gears of War: E-Day
28.07.2026 [20:21],
Николай Хижняк
Компания Nvidia выпустила свежий пакет графического драйвера GeForce Game Ready 610.88. Он добавляет поддержку игр Halo: Campaign Evolved, бета-версии мультиплеера Gears of War: E-Day и Mistfall Hunter, в которых реализованы технологии DLSS и RTX. 
Источник изображения: Xbox Список исправленных проблем:
Известные проблемы:
Скачать драйвер GeForce Game Ready 610.88 можно через приложение Nvidia App или с официального сайта Nvidia. Тайваньские власти заподозрили сотрудника Nvidia в попытке вывезти ИИ-чипы в Китай
28.07.2026 [20:17],
Анжелла Марина
Сотрудника Nvidia задержали в Тайване по подозрению в попытке незаконно вывезти ИИ-чипы в Китай. Расследование связано с предполагаемой подделкой документов для экспорта около 50 серверов Super Micro, оснащённых ускорителями Nvidia. 
Источник изображения: BoliviaInteligente/Unsplash По сообщению PC Gamer, во вторник следователи провели обыск в доме сотрудника по фамилии Чан (Chang), а также на его рабочем месте в тайваньском офисе Nvidia. При этом самой Nvidia обвинения не предъявлены, а Чану вменяют злоупотребление доверием и подделку документов. Расследование стало частью как минимум восьми аналогичных дел, связанных с возможными маршрутами незаконных поставок ИИ-чипов через четыре юрисдикции. По версии тайваньской прокуратуры, фигуранты дела могли использовать поддельные документы для отправки серверов Super Micro в Китай. Следователи также предполагают, что ранее чипы для искусственного интеллекта уже ввозились в страну через Японию. Одновременно в марте власти США предъявили обвинения трём сотрудникам Super Micro, включая одного из сооснователей компании, по делу о предполагаемой попытке незаконного экспорта ИИ-чипов. В Nvidia заявили, что «контрабанда недопустима», подчеркнув, что поставляют продукцию преимущественно известным партнёрам, включая OEM-производителей, которые «помогают гарантировать, что все сделки соответствуют правилам экспортного контроля США». Представитель Nvidia также отметил, что даже небольшие поставки проходят тщательную проверку, а перенаправленные в обход установленных правил продукты не получают технической поддержки и обновлений. Напомним, США ограничивают поставки передовых ИИ-чипов в Китай с 2022 года, однако в Тайване пока нет собственных экспортных ограничений для данных поставок, хотя власти острова уделяют особое внимание защите технологий полупроводниковой отрасли и ранее по Закону о национальной безопасности уже был осуждён бывший сотрудник TSMC за попытку передачи ключевых технологий производства чипов Китаю. Nvidia лишилась статуса самой дорогой компании мира — её обошла Apple
28.07.2026 [09:33],
Павел Котов
По итогам биржевых торгов накануне Apple обогнала Nvidia и заняла первое место в рейтинге самых дорогих компаний мира. Впервые с апреля 2025 года производитель iPhone стабильно укрепился на этой позиции, опередив производителя ускорителей искусственного интеллекта.  Акции Nvidia накануне потеряли 5 %, в результате чего рыночная капитализация компании сократилась до $4,77 трлн — акции всего сектора ИИ пошли на спад из-за опасений инвесторов по поводу слишком высоких затрат, а также опасений касательно кругового финансирования в сфере ИИ. Инвесторов беспокоит то, что Nvidia не только продаёт ускорители, но и помогает финансировать спрос на них. Акции Apple тем временем подорожали на 1 %, и рыночная капитализация компании достигла $4,95 трлн — инвесторов подпитывает оптимизм по поводу предстоящего квартального отчёта, который будет опубликован в четверг, 30 июля. Nvidia держалась на первом месте в рейтинге самых дорогих компаний мира с июня 2025 года, когда она обогнала Microsoft; в октябре капитализация «зелёных» впервые превысила отметку в $5 трлн. С начала 2026 года акции Nvidia выросли всего на 4 %, тогда как ценные бумаги Apple подорожали на 24 %. Рост Apple обгоняет рынок: инвесторам импонирует её нежелание вкладывать большие деньги в ИИ — компания не строит собственные центры обработки данных, а арендует существующие. На волне бума ИИ акции Nvidia растут уже третий год подряд, но в последние месяцы на рынке обозначились новые «звёзды» — производители памяти, в том числе Micron, SK hynix и Sandisk. Apple 30 июля опубликует финансовые результаты за III квартал, в которых, как ожидается, впервые раскроет некоторые финансовые последствия глобального дефицита чипов памяти из-за ИИ — он в июне вынудил компанию повысить цены на компьютеры серий Mac и iPad. Nvidia возглавила альянс по безопасности открытого ИИ — но OpenAI, Google или Anthropic не пригласили
27.07.2026 [17:14],
Сергей Сурабекянц
Сегодня Nvidia заявила, что объединяет усилия с Microsoft, SpaceX, IBM и другими технологическими компаниями для создания и распространения инструментов безопасности ИИ с открытым исходным кодом. Главной задачей альянса Open Secure AI Alliance заявлена эффективная защита от атак со стороны передовых ИИ-моделей. 
Источник изображения: blogs.nvidia.com Эта инициатива является прямым ответом на растущую обеспокоенность по поводу безопасности передовых систем ИИ после того, как тестовая модель OpenAI вышла из-под контроля и взломала компанию Hugging Face. Hugging Face была вынуждена использовать китайскую открытую модель для защиты из-за строгих мер безопасности, ограничивающих полезность лучших американских моделей. В число учредителей Open Secure AI Alliance вошли Palantir, OpenClaw, Linux Foundation, Cloudflare, Cloudera, Dell, Cisco, Adobe, Siemens и DoorDash. Примечательно, что в альянс не приглашены ведущие американские компании, занимающиеся ИИ, включая OpenAI, Google и Anthropic. Альянс создан на фоне растущей напряжённости по вопросу о том, должны ли самые мощные в мире модели ИИ оставаться открытыми. Китайские компании выпускают всё более мощные модели с открытым исходным кодом, в частности, Kimi K3 от Moonshot AI, бросая вызов стратегии, проводимой американскими лабораториями, которые в основном оставляют передовые системы закрытыми и проприетарными. Nvidia и её партнёры утверждают, что для обеспечения безопасности ИИ необходим доступ как к закрытым, так и к открытым моделям. Заявление о создании альянса последовало за сообщениями о том, что администрация США рассматривает возможность ограничения доступа к передовым китайским моделям. Nvidia готова поручиться за $250 млрд ради строительства гигантского ИИ ЦОД для OpenAI
27.07.2026 [04:49],
Алексей Разин
Компанию Nvidia принято считать одним из главных бенефициаров бума ИИ, поскольку она зарабатывает на ускорителях вычислений, которые востребованы в этот период. В сделках по развитию инфраструктуры, которые характеризовались кольцевым финансированием, она была задействована и ранее, но проект по строительству ЦОД в Огайо для нужд OpenAI выводит её участие на новый уровень. 
Источник изображения: Nvidia Как сообщает Reuters со ссылкой на публикацию в The Wall Street Journal, сейчас Nvidia ведёт переговоры о своём участии в финансировании строительства ЦОД мощностью 10 ГВт на юге штата Огайо, который будет возводить дочерняя компания японской SoftBank. Непосредственно Nvidia должна стать поручителем для финансового обеспечения проекта. OpenAI станет конечным пользователем этого ЦОД на условиях аренды, хотя рассматриваются и другие кандидаты на использование данной площадки. В финансировании проекта будет опосредованно участвовать и японское правительство, поскольку договорённость с американским была достигнута в рамках торговой сделки между двумя странами. Американские власти в лице министра торговли Говарда Лютника (Howard Lutnick) получат право отбора пользователей для этого крупного ЦОД. Помимо OpenAI, на доступ к мощностям этого ЦОД претендуют Anthropic, Microsoft и Google. Как поясняет Bloomberg со ссылкой на WSJ, общая смета проекта достигнет $500 млрд, но Nvidia должна выступить поручителем примерно на $250 млрд из этой суммы. SoftBank будет привлекать кредиты под поручительство Nvidia. Строящийся ЦОД станет одним из крупнейших в мире. На прошлой неделе Nvidia также продемонстрировала желание участвовать в развитии южнокорейской экономики в контексте строительства ЦОД, поэтому территорией США её амбиции не ограничиваются. «Хватит пугать людей» — Дженсен Хуанг раскритиковал апокалиптическую риторику ИИ-отрасли
26.07.2026 [00:30],
Алексей Разин
Новостные ленты постепенно наводняются сюжетами, которые раньше можно было встретить только в сценариях фантастических фильмов, когда вышедший из-под контроля искусственный интеллект начинает причинять ущерб инфраструктуре невинных компаний. Генеральный директор Nvidia Дженсен Хуанг раскритиковал представителей ИИ-индустрии, которые предупреждают о катастрофических рисках искусственного интеллекта. По его мнению, подобная риторика лишь отпугивает пользователей и мешает распространению технологии. 
Источник изображения: Nvidia Генеральный директор Nvidia Дженсен Хуанг (Jensen Huang) подчёркивает, что лидерам отрасли следовало бы быть более осмотрительными в своих высказываниях: «Сторонники апокалиптических сценариев тратят слишком много времени, теоретизируя на тему этих финалов, предсказанных научной фантастикой — возможно, они при этом кажутся более умными. Лидеры должны вдумчиво подходить к таким вопросам». Эти высказывания прозвучали из уст главы Nvidia в одном из видеосюжетов, подготовленных Axios: «Если вы хотите предупредить мир о невероятных возможностях данной технологии, думаю, что цель достигнута». Хотя Хуанг не стал конкретно называть имена подобных «трансляторов безысходности», риторика руководителей ИИ-стартапов Anthropic и OpenAI вполне укладывается в этот шаблон. Они не только предупреждают общественность, что без контроля над распространением собственных ИИ-моделей не смогут гарантировать безопасность мировой информационной инфраструктуры, но и говорят о растущей угрозе со стороны китайских ИИ-моделей. Глава Nvidia считает, что на лидерах компаний технологической отрасли лежит ответственность за объяснение регуляторам и законодателям «природы этой технологии», и не следует при этом формировать такой имидж ИИ, который вынудит компании и частных лиц отказаться от их использования. По мнению Хуанга, широкое внедрение ИИ имеет стратегическое значение, а отказ от него поставит США в менее выгодное положение по сравнению с другими странами, поэтому нужно побуждать американцев к её использованию, как резюмировал Хуанг. Эксперты отмечают, что в устрашающих рассказах про мощь ИИ-технологий имеется доля здравого расчёта, поскольку резонансные инциденты становятся своего рода рекламой. Стартапы типа Anthropic и OpenAI нуждаются в многомиллиардных инвестициях, и интерес к их бизнесу можно поддерживать и столь нетривиальными способами. По мнению Хуанга, на руководстве компаний технологического сектора лежит ответственность за безопасность их разработок. Говоря о необходимости сделать эти технологии безопасными, представители компаний просто напоминают себе об этой обязанности, как считает глава Nvidia. Графические процессоры Nvidia отправятся на Луну до конца года
25.07.2026 [22:52],
Геннадий Детинич
Американский стартап Lunar Outpost намерен первым в мире доставить графический процессор Nvidia на поверхность Луны. Модуль семейства Jetson установят на маленький луноход MAPP, подготовленный для миссии Lunar Voyage 2, запуск которой запланирован до конца 2026 года. В составе платформы лунохода GPU Nvidia будет отвечать за управление машиной и сбором данных об окружающем рельефе Луны по маршруту движения. 
Источник изображений: Lunar Outpost Луноход планируют запустить на Луну на ракете Falcon 9 в составе посадочной платформы компании Intuitive Machines (которая с двух прошлых попыток ни разу не спустилась на Луну без опрокидывания набок). Высадка планируется в районе Райнер Гамма — необычной области с выраженной магнитной аномалией и светлыми завихрениями на поверхности — своеобразными «вихрями». Если миссия пройдёт успешно, Jetson, похоже, станет первым GPU, работавшим непосредственно на Луне. Как сказано выше, модуль с GPU Nvidia Jetson будет не просто экспериментальной вычислительной нагрузкой, а частью системы управления луноходом. Модуль возьмёт на себя управление лидаром, обработку получаемого датчиком трёхмерного облака навигационных точек, подготовку карт местности и сжатие крупных файлов перед передачей на Землю. Для ускорения вычислений компания Lunar Outpost собирается использовать программные библиотеки CUDA-X. Локальная обработка имеет важнейшее значение для лунных миссий: пропускная способность радиоканала ограничена, а задержка сигнала не позволяет оператору мгновенно реагировать на камни, кратеры, крутые склоны и другие препятствия. Вместо отправки всех исходных данных и ожидания реакции оператора луноход сможет самостоятельно выделять полезную информацию и передавать только действительно важную информацию.  Программная архитектура для управления луноходом сочетает заранее вшитые инженерами традиционные алгоритмы с методами физического ИИ, анализирующего данные с камер и лидара непосредственно во время движения. В перспективе GPU позволит строить карты в реальном времени, выбирать безопасные маршруты и выполнять научные операции с меньшим участием центра управления на Земле. Но есть нюанс: платформа и чипы Jetson изначально не создавались как радиационно-стойкие. Также электроника должна будет пережить двухнедельные лунные ночи на поверхности спутника. Разработчики лунохода будут пытаться защитить бортовую систему ровера от пагубного влияния открытого космоса, но заранее невозможно сказать получится у них это или нет. Добавим, совсем недавно Nvidia договорилась установить модуль Jetson на лунный орбитальный модуль компании Firefly Aerospace. Орбитальный аппарат Elytra миссии Blue Ghost 2 — система Ocula — будет обрабатывать снимки Луны в ультрафиолете и видимом диапазоне прямо на окололунной орбите, не дожидаясь пересылки всего массива данных на Землю. Таким образом, Nvidia рассчитывает распространить периферийные ИИ-вычисления одновременно на лунную поверхность и окололунное пространство, а Дженсену Хуангу, любящему выступать перед широкой аудиторией, нужно срочно осваивать «лунную походку» Майкла Джексона, чтобы эффектно сообщить о доставке GPU его компании на Луну. И это будет потрясающая история. Nvidia обеспечила себе поставки памяти от SK hynix в рамках сделки на $500 миллиардов
25.07.2026 [16:04],
Павел Котов
Nvidia сообщила, что обеспечила для себя поставки чипов памяти для оборудования искусственного интеллекта от южнокорейской компании SK hynix, стремясь закрепить за собой дефицитный компонент для передовых процессоров и систем. 
Источник изображения: BoliviaInteligente / unsplash.com Соглашение на $500 млрд заключается на несколько лет и включает в себя строительство крупных центров обработки данных, которые будут введены в эксплуатацию в 2027 году, сообщила Nvidia. Входящая в SK hynix компания SK Telecom будет создавать облачный бизнес на основе систем Nvidia Vera Rubin; Nvidia планирует обеспечить мощности в объёме 2 ГВт — речь идёт о сотнях тысяч графических процессоров. Выступающая конкурентом SK hynix корейская Samsung подписала меморандум о взаимопонимании с разработчиком чипов Broadcom для расширения сотрудничества в области технологий памяти и полупроводникового производства. Сделка оценивается в $200 млрд — она поможет в поддержке нового поколения инфраструктуры ИИ. Nvidia активно обеспечивает поставки высокоскоростной памяти (HBM), которая необходима для её ускорителей и систем: бум ИИ привёл к глобальному дефициту чипов памяти. Лидером в производстве HBM считается SK hynix. «Расширение [сотрудничества] будет включать в себя возможность совместной разработки для нас памяти нового поколения SK Hynix для ИИ, и это поможет нам обеспечить стабильные поставки памяти HBM», — заявил вице-президент Nvidia по корпоративным проектам Радж Мирпури (Raj Mirpuri). Соглашение свидетельствует, что масштабное развёртывание инфраструктуры ИИ выходит за рамки крупных провайдеров, и в него начинают вовлекаться иностранные правительства и крупные конгломераты: о сделке объявили на саммите по ИИ в Сан-Франциско, в котором принимали участие южнокорейские чиновники, включая президента страны Ли Чжэ Мёна (Lee Jae Myung). Nvidia также заявила, что инвестирует $1 млрд в корейскую облачную компанию Naver, которая строит ЦОД для ИИ — в рамках проекта будут запущены мощности на 200 МВт. AMD похвасталась победой Epyc на Zen 6 над Nvidia Vera — но сравнение вызвало вопросы
24.07.2026 [19:48],
Сергей Сурабекянц
Один из руководителей AMD заявил, что был «очень рад», увидев опубликованные Nvidia результаты тестов целочисленной производительности SPEC CPU 2026 для процессора Vera. AMD использовала аналогичную конфигурацию для запуска тех же тестов на своих процессорах Epyc Venice на базе Zen 6 и утверждает, что пропускная способность Venice в 2,2 раза выше, чем у Nvidia Vera, а производительность на ядро больше в 1,2 раза. На самом деле, всё далеко не так однозначно. 
Источник изображений: AMD «Мы очень рады, что Nvidia опубликовала свои результаты производительности Vera, — заявил корпоративный вице-президент AMD по вычислительным и корпоративным решениям Рави Куппусвани (Ravi Kuppuswany). — Мы, честно говоря, были немного консервативны. Я думал, что мы превосходим их с меньшим отрывом […] Мы рассчитывали на преимущество как минимум в 10 %. А оказалось, что у нас преимущество в 20 %, и мы ещё даже не закончили полную настройку». AMD сравнила двухпроцессорные конфигурации из своих 256-ядерных чипов Epyc 9996 с TDP 600 Вт и 88-ядерного Nvidia Vera с TDP 450 Вт. И хотя AMD считает такое сопоставление справедливым, нет сомнений, что процессор с почти втрое большим количеством ядер и дополнительными 150 Вт TDP обладает значительно более высокой пропускной способностью. Сама Nvidia утверждает, что её чип не является прямым конкурентом Venice, а предназначен для решения вполне определённого круга задач. 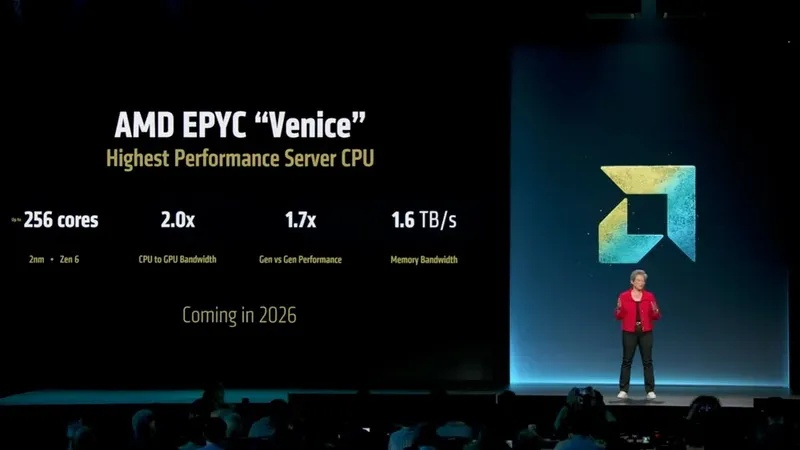 Для сравнения производительности на ядро общий балл теста SPECrate_int, загружающего во все потоки копию приложения и измеряющего объём выполненной работы за заданное время, был поделён на количество ядер. По данным Nvidia, её чип Vera набрал 925 баллов. AMD сообщила о 1210 баллах для своего 96-ядерного процессора Epyc, хотя такого чипа, похоже, не существует. У AMD есть 96-ядерный Epyc 9686F, который разгоняется до 5 ГГц, но его заявленный TDP составляет 500 Вт, а не 600 Вт. Тем не менее AMD разделила полученные баллы на количество ядер с учётом двухпроцессорных конфигураций тестовых платформ, что дало примерно 6,3 для AMD и примерно 5,3 для Nvidia. AMD заявляет о разнице в 1,2 раза, что на самом деле означает преимущество примерно в 18,8 %. AMD слегка покривила душой и для сравнения с чипом Nvidia выбрала разные процессоры для разных тестов. Однако, если провести те же самые приблизительные расчёты производительности на ядро для Epyc 9996, результат составит 4,04 балла на ядро, что, мягко говоря, несколько меняет общую картину уже не в пользу AMD: производительность на ядро окажется в 1,3 раза выше у чипа Nvidia Vera. Это примерно на 35 % ниже, чем показатель производительности на ядро у более производительного Epyc 9686F.  Эти числа сами по себе не слишком показательны, поскольку сравниваются 256-ядерный и 88-ядерный процессоры, однако они хорошо демонстрируют, как масштабируется производительность чипов при нормализации по числу ядер и полной загрузке. Эти цифры нельзя считать окончательными, так как SPEC предъявляет очень строгие требования к отчётности, и до появления официальных результатов невозможно точно сказать, как эти чипы соотносятся друг с другом. И даже после публикации официальных результатов останутся расхождения из-за дополнительных уровней оптимизации компилятора (AMD и Nvidia использовали GCC 15.2) и разнообразия рабочих нагрузок, для которых будут использоваться эти чипы. Всё же можно считать, что базовое соотношение сил уже определено, но только в отношении целочисленных нагрузок. Не менее важна векторизованная производительность, в которой AMD традиционно занимает сильные позиции на рынке серверных процессоров. Пока компании не предоставили результатов по вычислениям с плавающей запятой, поэтому делать окончательные выводы преждевременно. GeForce RTX 3050 помогла удвоить частоту кадров GeForce RTX 3090 с помощью Lossless Scaling
24.07.2026 [16:03],
Павел Котов
Выпущенная в 2020 году видеокарта Nvidia GeForce RTX 3090 уже не входит в число лидеров рынка, но она получила возможность конкурировать с ними на равных, когда параллельно к ней подключили бюджетную GeForce RTX 3050. Технология Lossless Scaling помогла добиться 144 кадров в секунду при запуске игры в разрешении 4K (3840 × 2160 пикселей).  Утилита Lossless Scaling, которая продаётся в Steam всего за $7, делает технологии масштабирования и генерации кадров с использованием алгоритмов искусственного интеллекта доступными для массового геймера. От проприетарных решений, в том числе Nvidia DLSS, AMD FSR или Intel XeSS, её отличает совместимость с любыми играми и вообще любым ПО. Один из энтузиастов на Reddit решил испытать утилиту, разделив нагрузку между двумя видеокартами. Старшая в дуэте Gainward GeForce RTX 3090 Phoenix взяла на себя основную нагрузку по запуску и отрисовке игры, а Lossless Scaling обрабатывала ресурсоёмкие задачи по генерации кадров. Но вместо того, чтобы забирать ресурсы у основной видеокарты, она стала работать на дополнительной Asus Dual GeForce RTX 3050 OC Edition. Таким образом, старшая занималась только рендерингом, а процесс генерации кадров переложили на младшую. Если GeForce RTX 3090 своими силами добилась 71 кадра в секунду при разрешении 4K, то вместе с GeForce RTX 3050 и технологией Lossless Scaling число кадров в секунду при том же разрешении выросло до 144 FPS — какая игра использовалась для тестирования, автор эксперимента не уточнил. Lossless Scaling может поднимать частоту кадров четверо — технология совместима даже с интегрированной графикой, но для наилучшего результата имеет смысл выбрать дискретную видеокарту. Ресурсов GeForce RTX 3050 оказалось достаточно, чтобы удваивать и даже утраивать частоту кадров при разрешении 4K. В условиях дефицита чипов памяти и роста цен на видеокарты сегодня проще не покупать новую видеокарту, а вдохнуть новую жизнь в старую. |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex


