|
Опрос
|
реклама
Быстрый переход
Nvidia направит $1,5 млрд на расширение американских мощностей Amkor по упаковке чипов
24.07.2026 [07:43],
Алексей Разин
Ещё в 2024 году начало работать первое предприятие TSMC в штате Аризона, оно специализируется на обработке кремниевых пластин с использованием 4-нм технологии. Формально, это позволяет той же Nvidia изготавливать часть ИИ-чипов в США, но для организации полного цикла операций нужны мощности по тестированию и упаковке компонентов. Их появлению будет способствовать сделка с Amkor на сумму $1,5 млрд. 
Источник изображения: Nvidia, TSMC Компания Nvidia в рамках соглашения с этим контрактным провайдером услуг по тестированию и упаковке чипов направит Amkor крупный авансовый платёж, который позволит данной компании расширить профильные мощности на территории штата Аризона. Новости о заключении этой сделки вызвали рост акций Amkor на 15 %. Это не единственный партнёр Nvidia, который способен оказывать ей профильные услуги на территории США. Сама TSMC тоже собирается построить в Аризоне два предприятия по тестированию и упаковке чипов, поскольку сейчас частично готовую продукцию ей приходится отправлять на Тайвань, а потом обратно в США. Основные мощности Amkor сосредоточены в Азии, хотя штаб-квартира компании находится в Аризоне. В рамках соглашения с Nvidia обе компании будут сотрудничать в сфере разработки новых технологий упаковки чипов. В июне Amkor заключила десятилетнее соглашение с TSMC, ориентированное на развитие услуг по тестированию и упаковке чипов на территории США. Компания AMD также является клиентом Amkor, поэтому практически все крупные американские разработчики ИИ-чипов заинтересованы в развитии производственной инфраструктуры этой компании на территории США. Драйвер RTX Spark заставил видеокарты Nvidia заработать на Arm-системах с Windows
23.07.2026 [18:08],
Павел Котов
Энтузиастам удалось заставить драйвер для Arm-компьютера Nvidia RTX Spark заработать на альтернативных платформах с процессорами Arm, что открыло возможность подключать к таким компьютерам видеокарты Nvidia GeForce для настольных систем. 
Источник изображения: BoliviaInteligente / unsplash.com Версия Windows on Arm преимущественно ограничена устройствами на чипах Qualcomm Snapdragon и не предусматривает поддержку настольных видеокарт Nvidia. Компьютеры Nvidia RTX Spark предложили производительную графику в Windows on Arm, но за высокую цену и с упором на разработчиков. Выпуск драйвера помог энтузиастам расширить ассортимент поддерживаемого оборудования. В частности, этот драйвер заработал на 24-ядерном серверном процессоре Kunpeng 920 с тактовой частотой 2600 МГц — он основан на той же архитектуре, что и Snapdragon X Elite, только по однопоточной производительности сравним с Intel Core i5-1235U. Этот чип установлен в рабочей станции Huawei Qingyun W510 с 32 Гбайт памяти DDR4-2933, на которой заработала видеокарта Nvidia GeForce RTX 4060. При запуске Black Myth: Wukong эта система показала в среднем 21 кадр в секунду с просадками до 3. Относительного успеха удалось добиться и с рабочей станцией Radxa Orion O6, к которой подключили Nvidia GeForce RTX 2080 Ti. Около 25 % производительности уходило на трансляцию x86 в Arm, что объясняет невысокую скорость в тестах. Энтузиасты не исключают, что этот метод может работать также с видеокартами серий Nvidia GeForce RTX 20, 30 и 50. Но на его доработку уйдёт немало времени: трансляция инструкций для процессора вызвала недовольство античитерской защиты; из-за отсутствия драйверов для Windows не удалось заставить работать сетевой интерфейс материнской платы; некорректно работал и видеовыход на видеокарте — для записи пришлось использовать другой компьютер. Nvidia повысила цены на комплекты для видеокарт GeForce с памятью GDDR7 и GDDR6
23.07.2026 [14:43],
Николай Хижняк
Компания Nvidia проинформировала своих партнёров по производству видеокарт об увеличении стоимости комплектов из графических процессоров и чипов видеопамяти. Изменения коснулись наборов для видеокарт GeForce, использующих память GDDR7 и GDDR6, сообщил портал BenchLife. 
Источник изображения: Tom's Hardware Как известно, производители видеокарт сами не производят графические процессоры. Они закупают их у разработчика GPU (в данном случае Nvidia), который, в свою очередь, заказывает их производство на предприятиях сторонних компаний (TSMC и Samsung). Чаще всего GPU закупаются в комплекте с чипами видеопамяти (VRAM). По данным BenchLife, новое уведомление Nvidia о повышении стоимости таких комплектов последовало за более ранней корректировкой цен на комплекты для видеокарт GeForce RTX 5090 и RTX 5090 D V2 в мае. «Нам сообщили, что Nvidia выпустила уведомление о повышении цен на GPU-комплекты (GPU + VRAM) для своих партнёров по AIC. Все мы прекрасно понимаем, что это обычно означает повышение стоимости памяти», — сообщил портал BenchLife. Последняя корректировка цен не ограничивается только видеокартами Blackwell, использующими чипы памяти GDDR7. Повышение цен также коснулось продуктов GeForce, использующих память GDDR6, хотя BenchLife не уточнил, о каких именно моделях видеокарт идёт речь, а также уровень повышения цен. «Согласно полученной нами информации, помимо увеличения стоимости памяти GDDR7 для карт на архитектуре Blackwell, подорожание также ожидает другие продукты GeForce, использующие память GDDR6», — сообщил BenchLife. Портал добавляет, что производители видеокарт также столкнулись с повышением стоимости производства систем охлаждения, печатных плат и упаковки. Однако в отчёте говорится, что рост цен на эти компоненты оказался менее значительным, чем на память. Информация о повышении цен на комплекты GPU + VRAM появилась на фоне сообщений о том, что Nvidia задержала выпуск видеокарт GeForce RTX 50 Super из-за высокой стоимости 3-гигабайтных чипов памяти GDDR7, которыми эти видеокарты должны оснащаться. Согласно имеющейся информации, каждый такой чип стоит от 60 до 70 долларов, тогда как 2-гигабайтные чипы — около 20 долларов за штуку. Компания Nvidia и её партнёры по производству видеокарт не объявляли об изменении розничных цен, связанном с указанной корректировкой. Дженсен Хуанг призвал не запрещать китайские ИИ-модели в США — это сделает мир только опаснее
23.07.2026 [00:29],
Николай Хижняк
Генеральный директор Nvidia Дженсен Хуанг (Jensen Huang) считает, что американским компаниям следует разрешить использовать китайские модели ИИ, даже несмотря на попытки правительства их запретить. Об этом он рассказал в интервью Axios, фрагмент записи которого опубликован на платформе YouTube. 
Источник изображения: Nvidia Когда его спросили, следует ли разрешить американским компаниям использовать китайские модели ИИ, Хуанг ответил: «Безусловно». Его заявление прозвучало сразу после того, как китайская компания Moonshot AI выпустила модель Kimi K3 с открытым исходным кодом на 2,8 трлн параметров. Она оказалась не такой мощной, как Fable 5 от Anthropic, сопоставима с GPT-5.5 и Claude Opus 4.8, но при этом при её разработке была затрачена лишь треть средств по сравнению с этими моделями. Одно из главных опасений американских властей заключается в том, что китайские модели ИИ могут содержать уязвимости, которые китайское правительство способно использовать для атаки на американские интересы. Хуанг считает это предположение заблуждением. «Существует ошибочное мнение, что есть какие-то лазейки, каким-то образом связанные с Китаем. Вы скачиваете модели, можете их дорабатывать, улучшать, контролировать по своему усмотрению», — прокомментировал глава Nvidia. Хуанг придерживается такого же мнения и в отношении ИИ-моделей, разработанных американскими компаниями. В прошлом месяце США ввели экспортные ограничения на модели Anthropic Mythos и Fable 5, сославшись на угрозы безопасности. Доступ к моделям в конечном итоге был восстановлен после того, как разработчик установил фильтр, блокирующий возможности выявления уязвимостей в программном обеспечении. Аналогичная ситуация сложилась и с GPT-5.6 от OpenAI. Официальный Вашингтон предупредил компанию, что она не должна выпускать свою последнюю модель без одобрения правительства. Хуанг утверждает, что вместо ограничения доступа к этим мощным моделям на этапе запуска компании, занимающиеся ИИ, должны сделать свои модели доступными для всех и повышать их безопасность за счёт быстрого тестирования и исправлений. Комментируя свою поддержку открытого доступа к ИИ-моделям, глава Nvidia также отметил, что различные отрасли, включая науку и кибербезопасность, нуждаются в мощных открытых моделях. Он утверждает, что открытые модели делают ИИ более безопасным, поскольку другие специалисты могут проверять их на наличие слабых мест, а разработчики — оперативно вносить необходимые исправления. «Если всё сведётся к одной единственной модели, одной единственной точке атаки, одному единственному источнику сбоев, я думаю, мир станет гораздо, гораздо более уязвимым», — сказал Хуанг. Что касается негативной реакции рынка всякий раз, когда появляются более дешёвые открытые модели, генеральный директор Nvidia заявил, что инвесторы неправильно понимают их влияние. По словам Хуанга, всё началось с появления DeepSeek. Теперь это повторяется с выходом Kimi K3. По мнению главы Nvidia, такие открытые модели, обходящиеся дешевле в эксплуатации, будут стимулировать всё больше людей использовать ИИ. Вместо того чтобы сокращать спрос на центры обработки данных, эти более дешёвые и эффективные модели, напротив, станут благом для отрасли в целом, поскольку будут стимулировать этот спрос. А с ростом спроса появится больше стимулов для строительства центров обработки данных и покупки графических процессоров для ИИ, что в конечном итоге выгодно Nvidia. Nvidia выпустила драйвер-заплатку 610.82 для решения проблем в Halo: Campaign Evolved и Path of Exile 2
22.07.2026 [22:57],
Николай Хижняк
Компания Nvidia выпустила Hotfix-драйвер версии 610.82. Он основан на драйвере Game Ready 610.74 и предназначен для исправления проблем в играх Halo: Campaign Evolved и Path of Exile 2. 
Источник изображения: Xbox Согласно Nvidia, Hotfix-драйвер призван решить проблемы со стабильностью в Halo: Campaign Evolved на видеокартах GeForce RTX 50-й серии после установки драйверов версий 610.xx. Компания не уточнила, какие видеокарты подвержены этой проблеме. Также Hotfix-драйвер предназначен для решения проблем с работой Path of Exile 2 в режиме DirectX 12. По словам Nvidia, исправление решает проблемы с периодическими долгими загрузками, которые могут возникать после продолжительных игровых сессий. Как отмечает портал VideoCardz, Hotfix-драйвер версии 610.82 не решает другой неурядицы, на которую недавно активно начали жаловаться пользователи Battlefield 6: игра вылетает на видеокартах GeForce RTX 50-й серии на локациях с большим количеством воды. Издатель Electronic Arts (EA) проблему признал, хотя и отметил, что она затрагивает не все игровые системы. На данный момент неизвестно, связаны вылеты Battlefield 6 с драйверами GeForce Game Ready или это внутриигровая ошибка. В настоящий момент EA рекомендует пользователям, столкнувшимся с вылетами в Battlefield 6, откатить драйвер GeForce до версии 596.49. Компания работает с Nvidia над определением источника данной проблемы. Скачать Hotfix-драйвер версии 610.82 можно с официального сайта Nvidia. Nvidia утверждает, что все её крупнейшие клиенты уже используют серверы на основе Vera Rubin
22.07.2026 [08:51],
Алексей Разин
Компания Nvidia на этой неделе провела мероприятия для прессы, клиентов и партнёров, целью которых была демонстрация её готовности поставлять потребителям новейшие серверные компоненты и готовые системы. Решения на основе ускорителей поколения Vera Rubin, по словам руководства Nvidia, уже доставлены основным крупным клиентам компании и начинают использоваться. 
Источник изображения: Nvidia Данные комментарии прозвучали из уст вице-президента Nvidia Иэна Бака (Ian Buck), который в компании отвечает за направление центров обработки данных. Во время брифинга в штаб-квартире Nvidia он заявил: «Мы абсолютно находимся на стадии полномасштабного производства. Это оборудование уже установлено у всех наших крупнейших потребителей». Инвесторы и клиенты Nvidia с некоторым опасением следили за этапом масштабирования производства серверных систем поколения Vera Rubin, поскольку новая продукция всегда таит вероятные сложности и потенциальные задержки. Представители Nvidia заявляют, что в этом отношении переживать не о чем. Оборудование нового поколения будет не только производительнее предыдущего, его будет проще вводить в эксплуатацию. Более того, компоновка новых серверов рассчитана с учётом упрощения процедуры сборки: количество кабельных подключений максимально сокращено, чтобы перевести операции на использование роботов, а не людей. Система жидкостного охлаждения также сокращает потребность в свободном пространстве внутри корпуса и количестве установленных вентиляторов. Один из лидеров рынка ИИ — американский стартап OpenAI, собирается начать масштабную эксплуатацию систем семейства Vera Rubin в текущем квартале, как отметили представители Nvidia. Уже сейчас эти системы используются компаниями Google, CoreWeave, Microsoft, Meta✴✴ Platforms и Dell Technologies. В окрестностях штаб-квартиры Nvidia в Калифорнии построена специальная экспериментальная площадка с новейшим серверным оборудованием, которое клиенты могут протестировать и оценить на пригодность к своим нуждам. OpenAI как раз сейчас проводит подобные испытания. По данным CoreWeave, системы поколения Vera Rubin способны выдавать в десять раз больше токенов по сравнению с предшественниками. Представители Nvidia также настаивают, что центральные процессоры Vera оказываются в 1,8 раза быстрее в программировании на Python по сравнению с конкурирующими AMD Turin. Представители последней из компаний возразили, что сравнение с более новыми процессорами Venice не будет демонстрировать подобного разрыва. Тайваньская Wistron начнёт выпускать для Nvidia в США серверы с новейшими чипами Vera Rubin
22.07.2026 [07:01],
Алексей Разин
Нынешний президент США Дональд Трамп (Donald Trump) пытался привлечь тайваньского контрактного производителя электроники Foxconn на американскую землю ещё в 2017 году, и ту попытку нельзя назвать удачной. Тем не менее, сейчас производством серверного оборудования на территории США готова заниматься не только Foxconn, но и конкурирующая Wistron, которая построила завод в Техасе. 
Источник изображения: Nvidia Как сообщает Nikkei Asian Review, техасская площадка Wistron занимает площадь более 30 000 квадратных метров, и это первое предприятие компании на территории США. На его строительство было потрачено $700 млн. На церемонии открытия завода представители Wistron продемонстрировали первый модуль Nvidia GB300, собранный на его территории. Сперва здесь будет освоен выпуск серверных систем на основе Grace Blackwell, а позже завод начнёт выпускать решения поколения Vera Rubin. В течение пары лет данное предприятие станет одним из самых важных в инфраструктуре Wistron, по словам представителей компании. Глава и основатель Nvidia Дженсен Хуанг (Jensen Huang) также посетил церемонию открытия завода Wistron в Техасе, подчеркнул, что спрос на ИИ-серверы невероятно высок, а потому они должны производиться повсеместно. Компании сообща восстанавливают передовое производство на территории США, создают квалифицированные рабочие места и развивают локальные цепочки поставок, по словам главы Nvidia. Компании Foxconn и Wistron являются главными производителями печатных плат с ускорителями вычислений Nvidia, до недавних пор американские клиенты последней были вынуждены полагаться на поставки с Тайваня. На предприятии Wistron будут выпускаться не только печатные платы и готовые ускорители на базе GPU, но и целые серверные системы. Конкурирующая Foxconn также вскоре собирается запустить своё локальное предприятие по выпуску серверного оборудования для Nvidia в Хьюстоне, штат Техас. Площадка Wistron располагается в городе Форт-Уэрт. Если учесть, что TSMC развивает обработку кремниевых пластин в Аризоне, и там же будет заниматься упаковкой ИИ-чипов, на территории США появится почти самодостаточная инфраструктура для изготовления компонентов вычислительных систем. Правда, среди поставщиков памяти типа HBM полным циклом производства в США обладает только Micron, но она тоже расширяет свои мощности, да и местные власти собираются принудить корейских Samsung и SK hynix локализовать производство памяти в стране. Новая статья: Обзор «малолитражного суперкомпьютера» MSI EdgeXpert MS-C931
22.07.2026 [00:05],
3DNews Team
Данные берутся из публикации Обзор «малолитражного суперкомпьютера» MSI EdgeXpert MS-C931 Nvidia раскрыла детали процессора Vera: 88 Arm-ядер Olympus, 176 потоков и память LPDDR5X с пропускной способностью 1,2 Тбайт/с
21.07.2026 [22:35],
Николай Хижняк
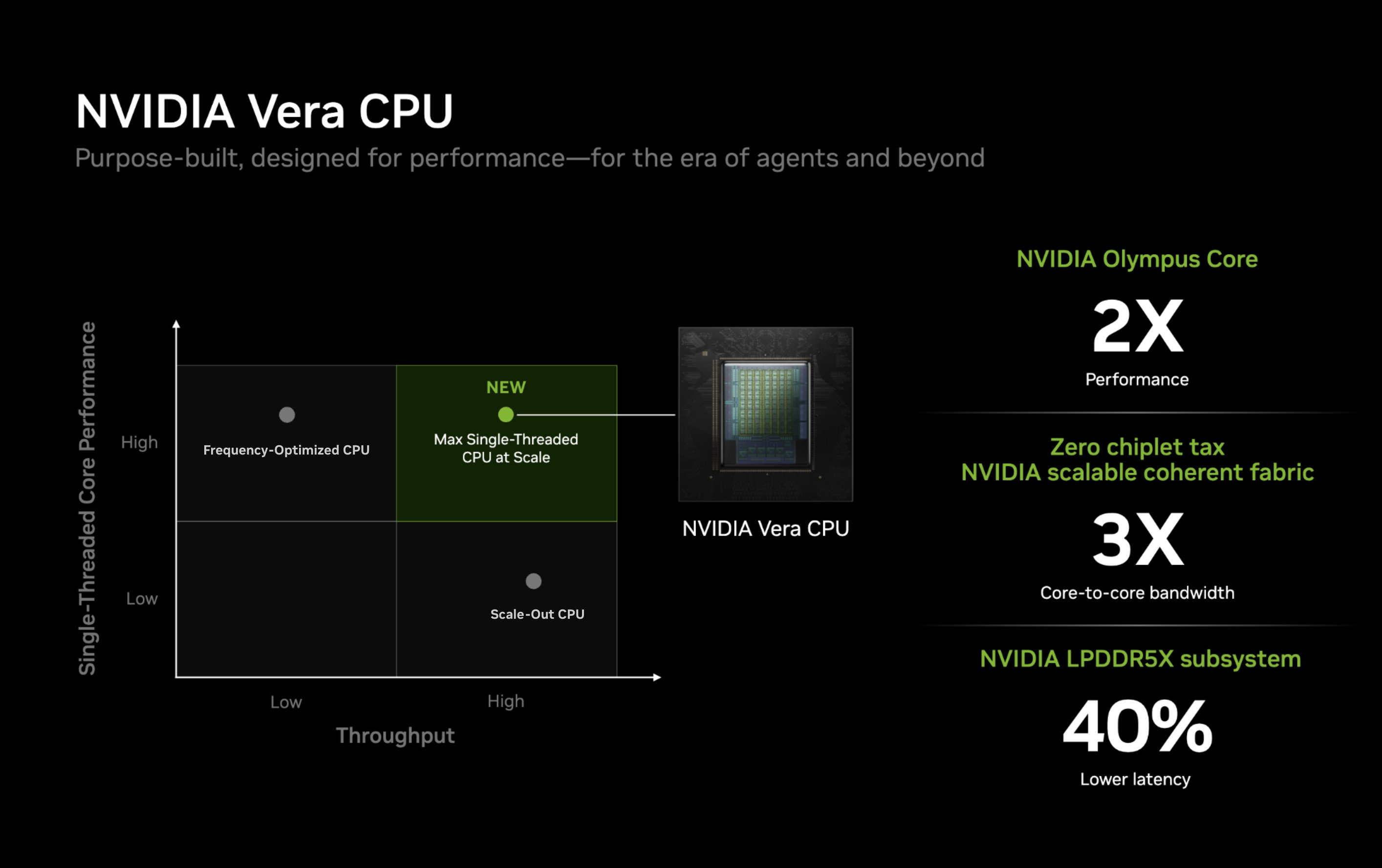
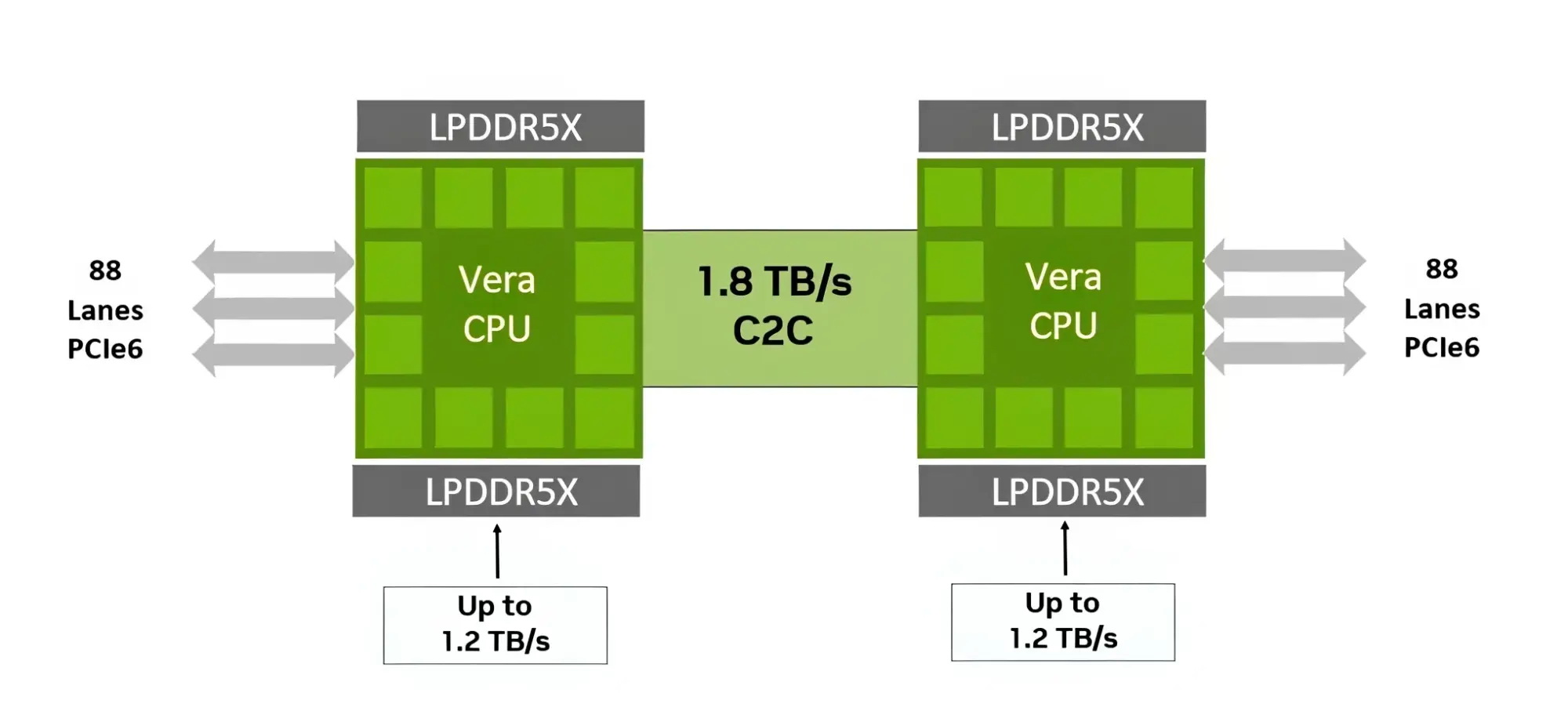
Компания Nvidia опубликовала новые подробности об архитектуре своего процессора Vera для центров обработки данных и используемом в нём специализированном ядре Olympus. Чип Vera объединяет 88 ядер Olympus, 176 аппаратных потоков и унифицированный кеш L3 объёмом 164 Мбайт на монолитном вычислительном кристалле. 
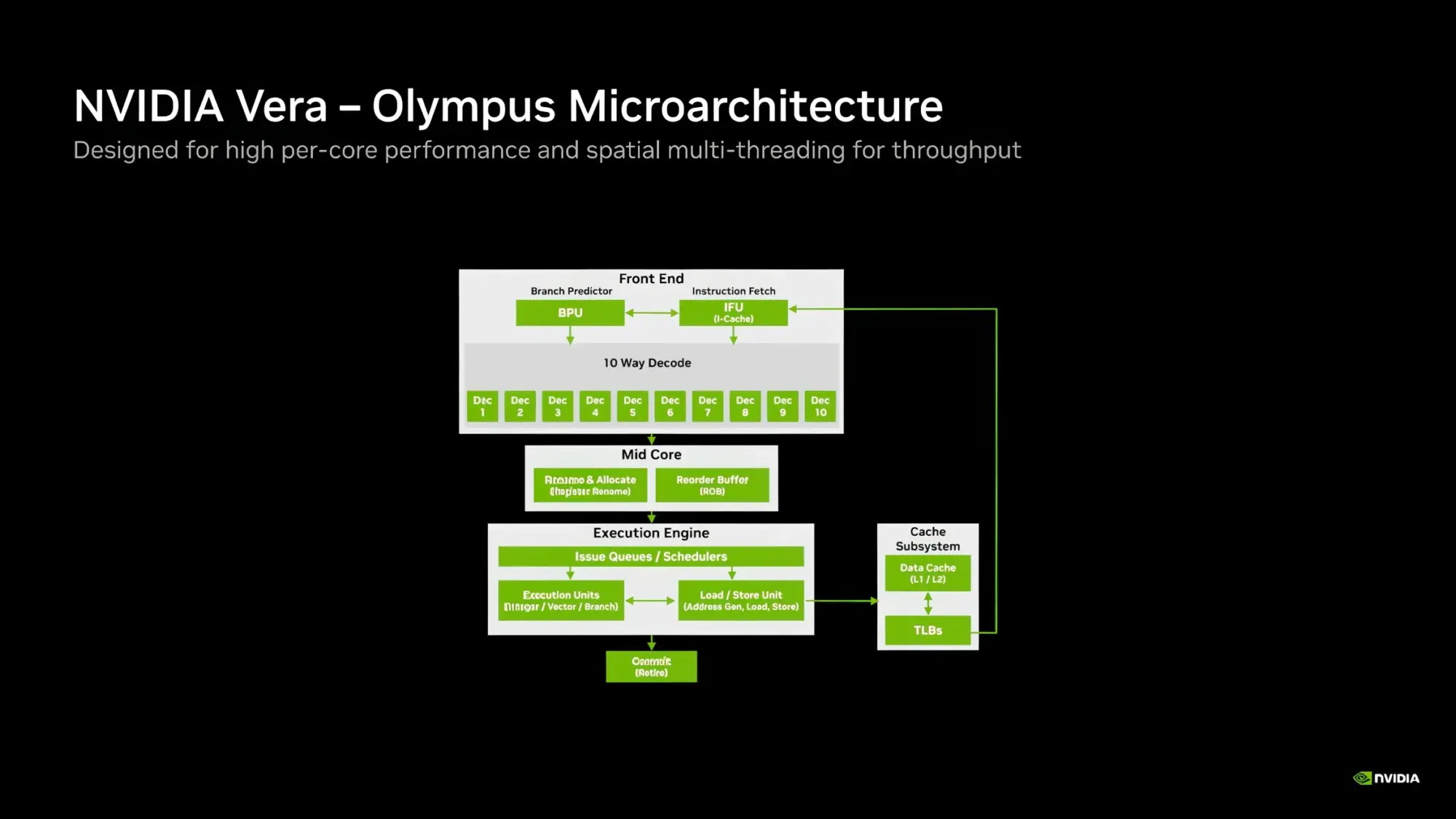
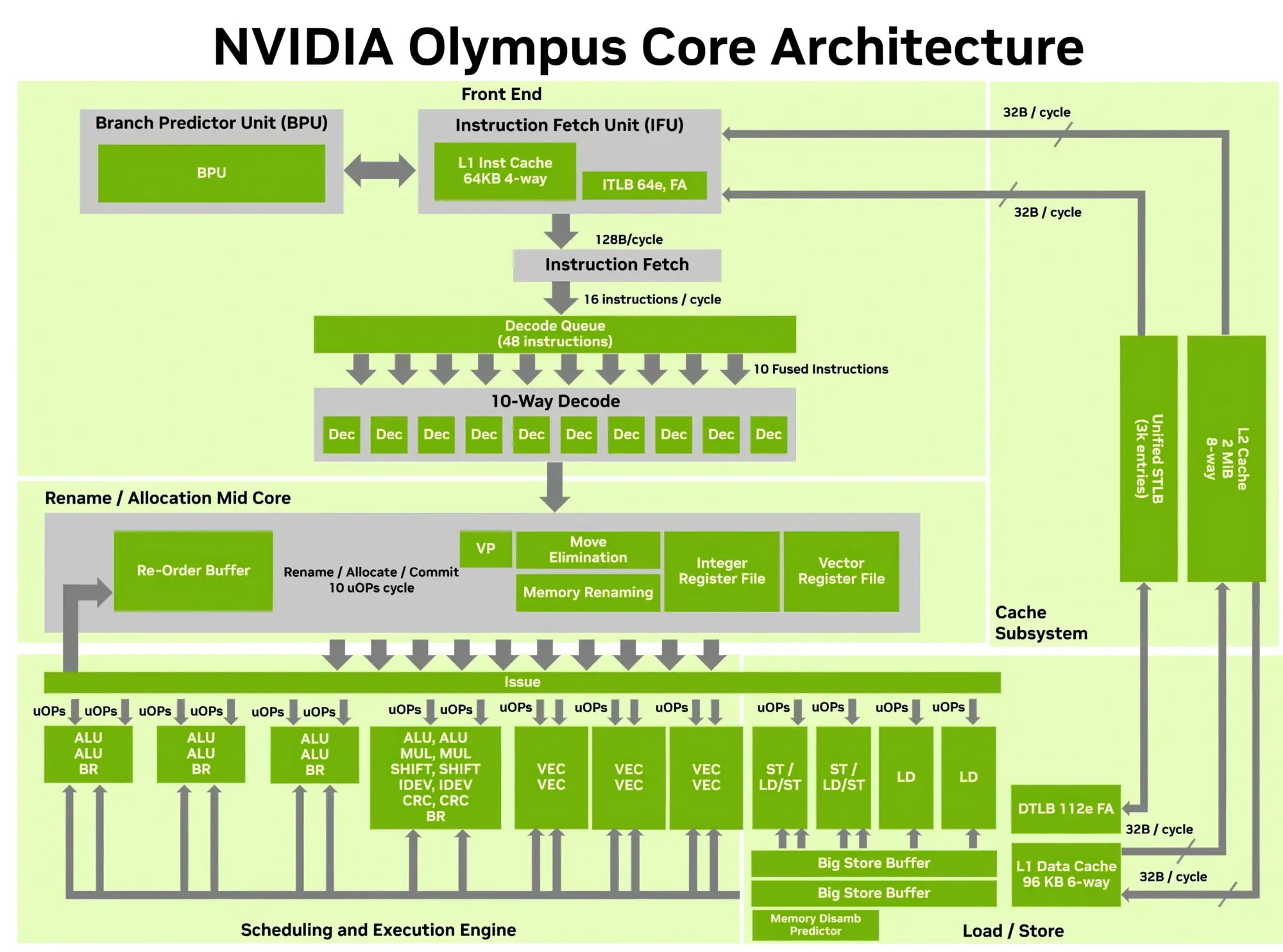
Источник изображений: Nvidia Каждое ядро Olympus использует широкий конвейер с нейронным предсказателем ветвлений, 64-килобайтный четырёхканальный кеш инструкций L1 и очередь декодирования на 48 инструкций. Ядро может считывать до 16 инструкций за такт и включает 10-канальный декодер, способный обрабатывать до десяти объединённых инструкций за такт. 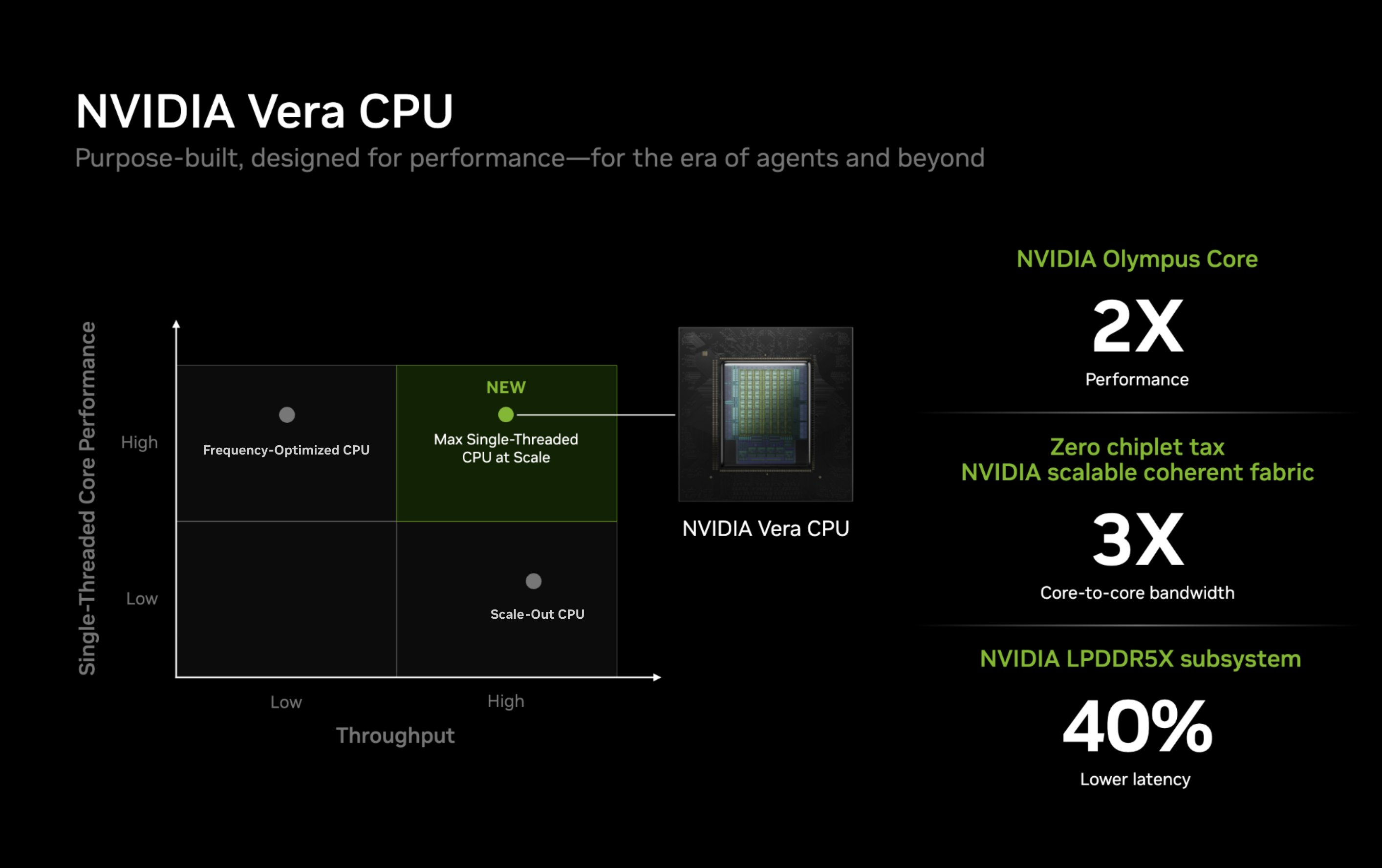 Каждое ядро может переименовывать, выделять и фиксировать до десяти микроопераций за такт. Nvidia также отмечает использование технологий переименования памяти, предсказания значений и исключения перемещений, предназначенных для уменьшения задержек, связанных с зависимостями. Исполнительный блок включает целочисленные операции, операции ветвления, векторные операции, операции с плавающей запятой, криптографические операции, а также выделенные ресурсы для операций загрузки и сохранения данных. Каждое ядро Olympus имеет 96-килобайтный шестиканальный кеш данных L1 и 2-мегабайтный восьмиканальный кеш L2. Nvidia также добавила несколько механизмов аппаратной предварительной выборки, включая предварительную выборку графов для структур данных с большим количеством указателей и рабочих нагрузок, связанных с обработкой графов. Особенности Nvidia Vera
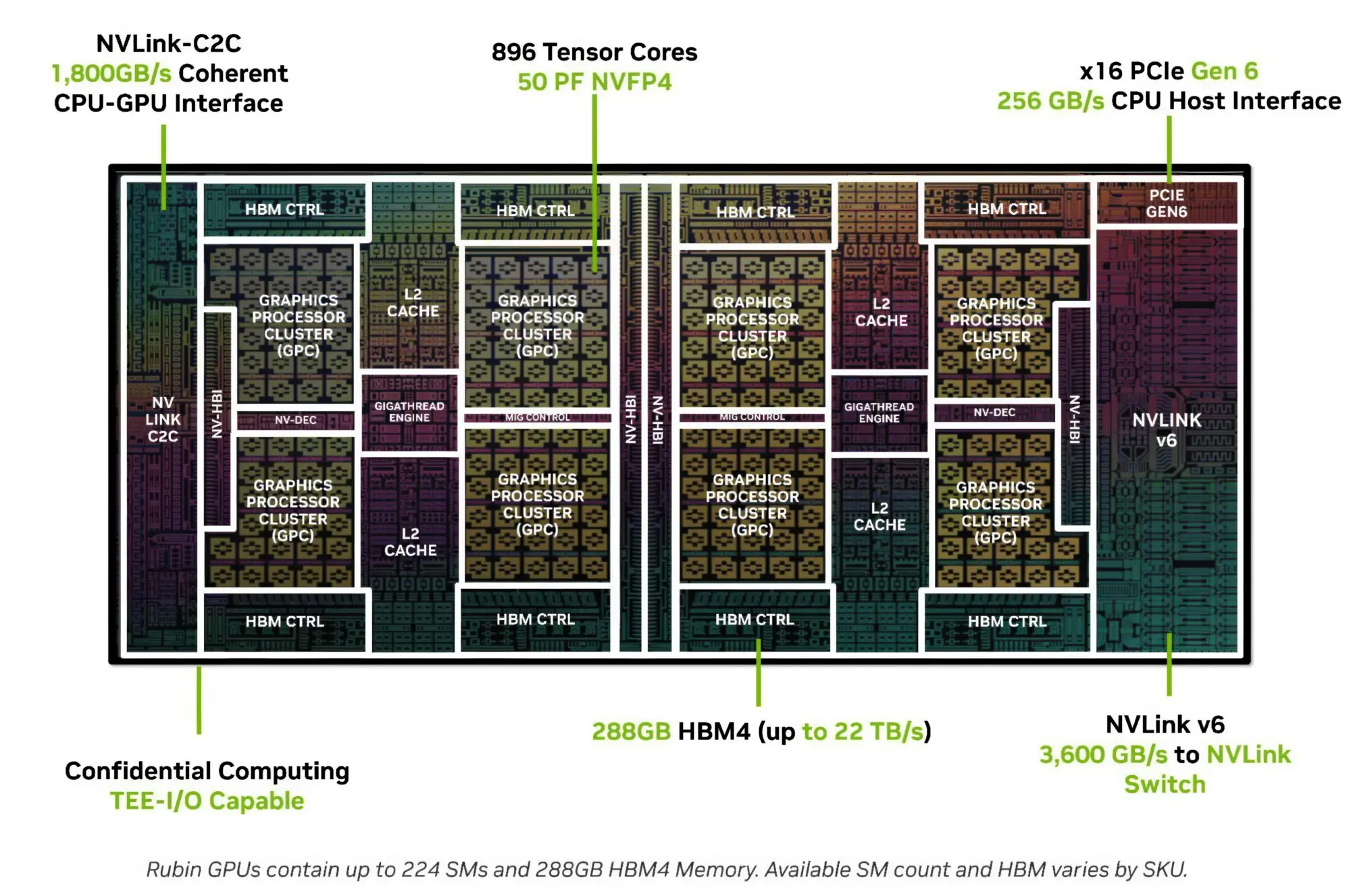
Процессор Vera использует фирменную технологию пространственной многопоточности, которая обеспечивает два аппаратных потока на каждое ядро Olympus. Nvidia заявляет, что такая конструкция позволяет распределять ресурсы ядра между потоками, уменьшая конкуренцию по сравнению с традиционной одновременной многопоточностью. Ядро может отдавать приоритет одному потоку, чувствительному к производительности, в то время как второй поток обрабатывает системные и управляющие задачи. 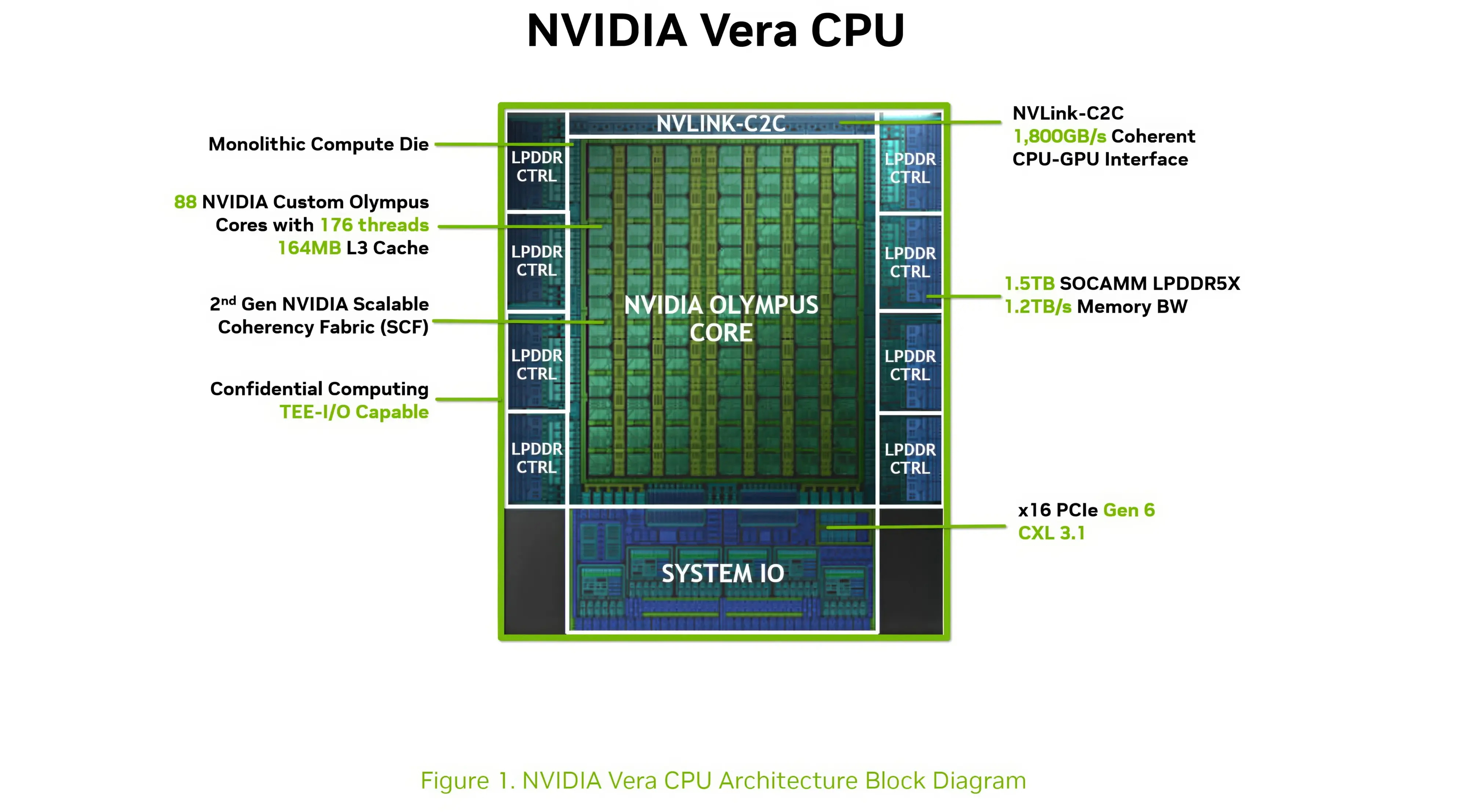 Ядра процессора, кеш, контроллеры памяти и ввода-вывода объединены через масштабируемую когерентную структуру Nvidia второго поколения. Компания заявляет о пропускной способности между ядрами до 3,4 Тбайт/с, пропускной способности памяти SOCAMM2 LPDDR5X до 1,2 Тбайт/с и поддержке до 1,5 Тбайт памяти на процессор. Vera также поддерживает интерфейс NVLink-C2C со скоростью до 1,8 Тбайт/с, PCIe 6.0 и CXL 3.1. Системы с двумя сокетами обеспечивают 176 линий PCIe и используют двухузловую конфигурацию NUMA — по одному домену NUMA на каждый сокет. Nvidia утверждает, что Vera обеспечивает до 1,8 раза более высокую производительность, чем неназванные системы x86, в отдельных рабочих нагрузках, связанных с работой ИИ-агентов. Результаты основаны на внутренних тестах Nvidia SPEC CPU 2026, проведённых в июле 2026 года, и пока не были независимо подтверждены. Не только GPU: Nvidia всерьёз взялась за рынок CPU и уже отгрузила сотни тысяч серверов
21.07.2026 [20:16],
Сергей Сурабекянц
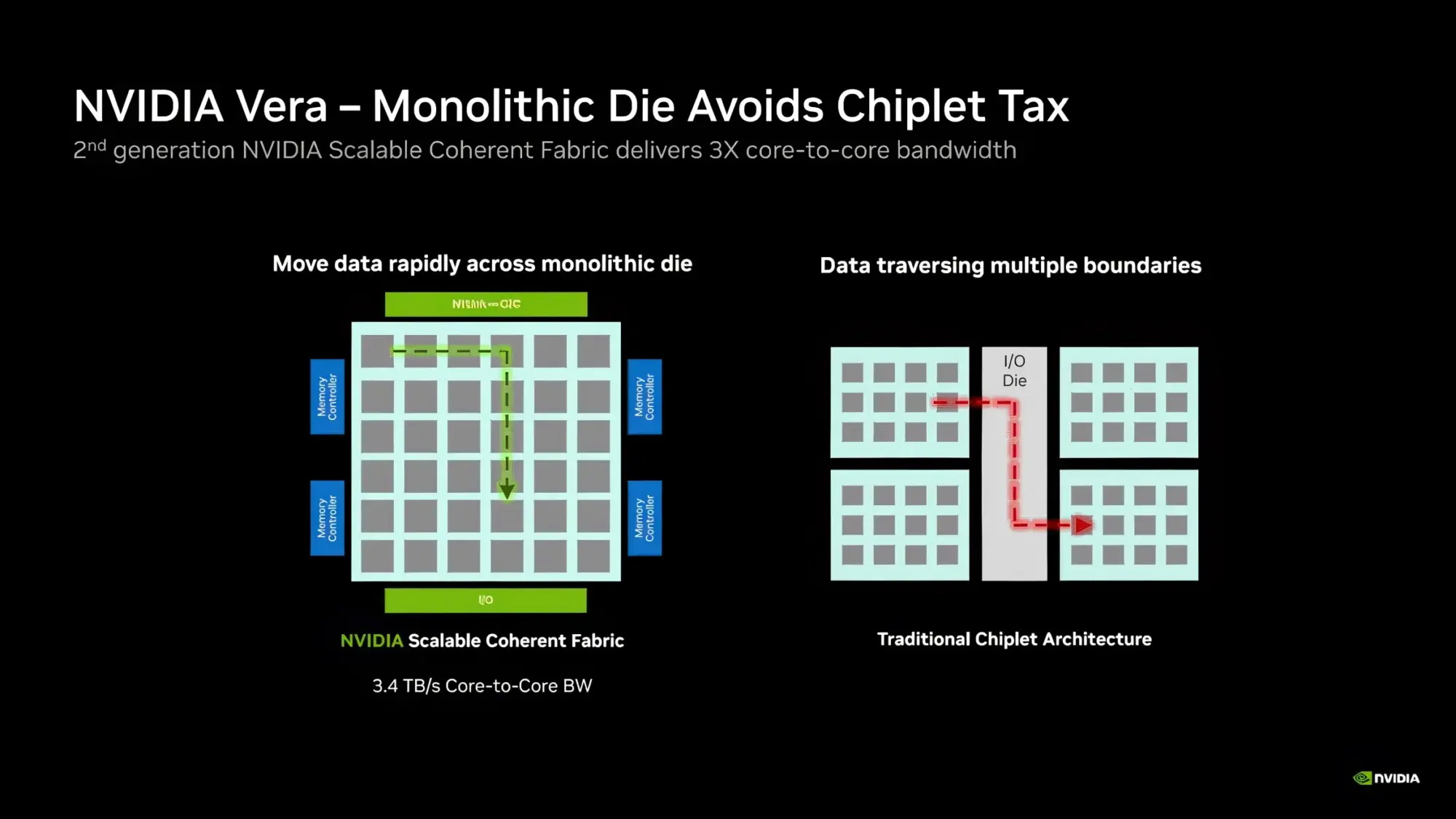
Вице-президент Nvidia по высокопроизводительным вычислениям и изобретатель CUDA Иэн Бак (Ian Buck) сообщил, что компания отгрузила «сотни тысяч» серверов на центральных Arm-процессорах Grace. Ранее для их развёртывания Nvidia заключила партнёрское соглашение с Meta✴✴. Однако реальные масштабы экспансии Nvidia на рынок центральных процессоров могут быть ещё больше, поскольку компания активно пытается конкурировать с Intel и AMD. 
Источник изображений: Nvidia Nvidia стала доминирующей силой в Кремниевой долине благодаря ажиотажному спросу на её графические процессоры во время беспрецедентного строительства центров обработки данных для ИИ. Однако с момента пика в начале этого года рыночная капитализация Nvidia снизилась примерно на $1 трлн, поскольку инвесторы обратили свой взор на производителей центральных процессоров, которые стали не менее востребованы в результате развития ИИ-агентов. Nvidia стремится «оседлать» и этот тренд со своим центральным процессором Vera, который разработан специально для таких задач. Однако, по словам Nvidia, даже до недавнего роста популярности агентов, компания наблюдала спрос на свои процессоры для ресурсоёмких задач. Они массово развёртывались для бэкэнда и операций с большими объёмами данных. Устройство чипов Vera значительно отличается от конкурирующих процессоров Intel и AMD. Обе компании достаточно давно отказались от монолитных кристаллов в пользу чиплетов, что позволило достичь чрезвычайно высокой плотности ядер в ущерб задержкам и когерентности. Чип Vera в этом отношении кардинально отличается, поскольку не только построен на одном кристалле, но и выделяет значительную его часть под шину. 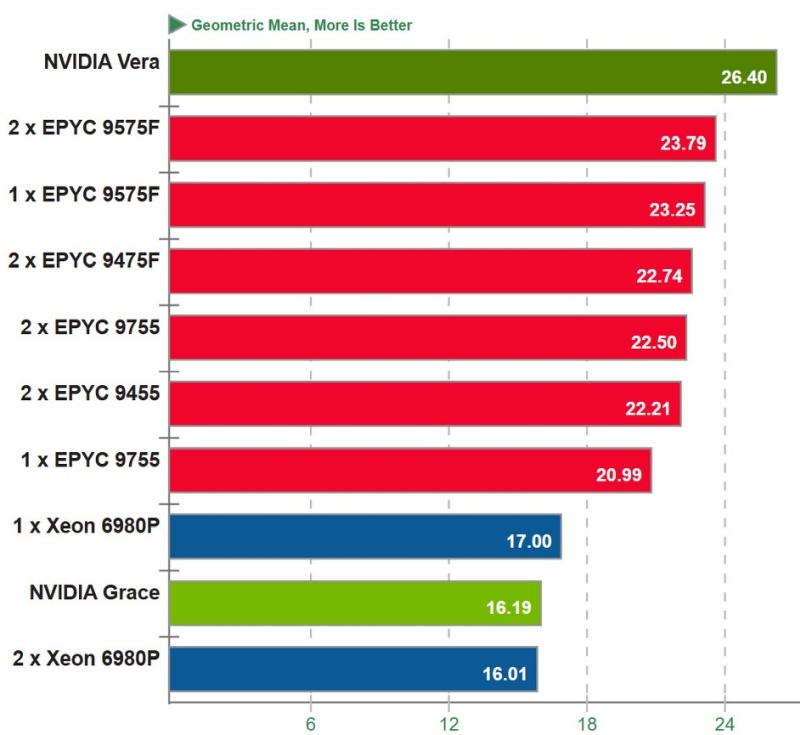 «Одна из причин, почему у нас нет 128 ядер, заключается в том, что мы выделили большую часть площади кристалла под шину [соединяющую ядра], — пояснил Бак. — Внутри этого процессора находится 3,4 Тбайт/с пропускной способности, которая позволяет каждому ядру взаимодействовать с каждым кэшем, каждым контроллером памяти на полной скорости без каких-либо коллизий». Суммарная пропускная способность памяти через интерфейс LPDDR5X достигает 1,2 Тбайт/с (14 Гбайт/с на ядро). Но, как и в случае с чиплетными архитектурами, где пришлось пойти на компромиссы в производительности каждого потока, Vera, вероятно, также пойдёт на компромиссы ради своей уникальной архитектуры. Большинство рабочих нагрузок в ЦОД по-прежнему представляют собой «устаревшие» задачи, для решения которых гиперскейлеры уже разработали соответствующие решения, и даже при, казалось бы, ненасытном спросе на инфраструктуру ИИ, вряд ли ситуация изменится в ближайшие несколько лет. Чипы Vera находятся в полномасштабном производстве вместе с инфраструктурой ИИ следующего поколения от Nvidia, включая графические процессоры Rubin, сетевые карты ConnectX-9, коммутаторы Ethernet SpectrumX и различные компоненты, используемые для сборки стойки Vera Rubin NVL72. Компания заявляет, что в стойку входит около 1,3 миллиона компонентов, а в её производстве принимают участие более чем 300 партнёров Nvidia по всему миру.  По оценкам Nvidia, потенциальный рынок процессоров в 2030 году может достигнуть $200 млрд, что является довольно оптимистичным заявлением по сравнению с прогнозами других представителей отрасли, находящихся в диапазоне от $120 млрд до $170 млрд. По мнению аналитиков Morgan Stanley, ИИ-агенты могут добавить до $60 млрд к рынку процессоров для ЦОД. «Мир не будет обслуживаться одной моделью процессора, и это не входит в наши планы», — подчеркнул Бак в своём интервью. Nvidia повысила цены на все компьютеры и модули Jetson — в некоторых случаях вдвое
21.07.2026 [19:42],
Николай Хижняк
Компания Nvidia без лишнего шума повысила цены на всё оборудование семейства Jetson. Изменения коснулись всех трёх комплектов для разработчиков и всех производственных модулей. 
Источник изображений: Nvidia Nvidia не предупреждала о повышении цен и не сообщила, когда новые цены вступили в силу. Компания просто поставила всех перед фактом, сообщил сегодня портал VideoCardz. Цены выросли вплоть до 101 % на некоторые позиции. Например, комплект разработчика Jetson Orin Nano Super Developer Kit теперь стоит $399 вместо $249 — цена выросла на 60 %. Комплект Jetson AGX Orin Developer Kit теперь стоит $3499 вместо $1999, а комплект Jetson AGX Thor Developer Kit подорожал с $3499 до $5499. В настоящий момент на сайте Nvidia указано, что комплекты разработчиков отсутствуют в наличии в США.  Самое значительное изменение цен наблюдается у модулей Jetson Nano и Jetson AGX Orin с 32 Гбайт памяти. Их стоимость удвоилась. Модуль AGX Orin с 64 Гбайт памяти подорожал на 88 % и теперь стоит $2999 вместо $1599. В свою очередь модули Xavier Industrial и Xavier NX с 16 Гбайт памяти выросли в цене на 84 и 80 % соответственно и теперь стоят $2299 и $899 вместо $1249 и $499. 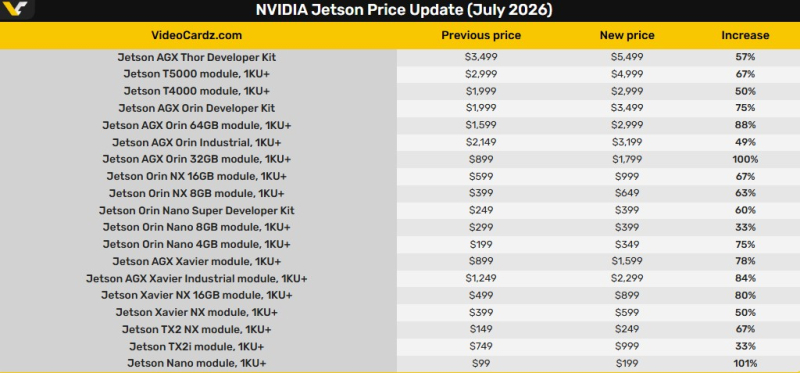
Источник изображения: VideoCardz Nvidia не объяснила причины повышения цен. Однако можно предположить, что оно связано с дефицитом памяти. Nvidia отчиталась о прогрессе в разработке DLSS 5 с нейронным рендерингом
21.07.2026 [18:26],
Николай Хижняк
Nvidia в рамках конференции SIGGRAPH 2026, которая проходит в Лос-Анджелесе (США), отчиталась о прогрессе в разработке новой технологии нейронного рендеринга DLSS 5. Несмотря на первоначальную негативную реакцию геймеров, компания продолжает развивать технологию и подготовила новую демонстрацию того, как должна работать DLSS 5. 
Источник изображений: Nvidia Один из ключевых аспектов новой технологии заключается в том, что разработчики игр смогут выбирать из трёх моделей DLSS 5, каждая из которых обеспечивает разный уровень структурной интенсивности, глобального освещения, детализации текстур и многого другого. Модели, обозначенные как Model A, Model B и Model C, могут быть адаптированы к конкретным сценам или определённым персонажам. Кроме того, их можно будет комбинировать в соответствии со своими требованиями. Каждая модель имеет различное количество параметров. Другими словами, некоторые модели потребляют больше памяти. Однако, все они, как правило, хорошо работают с использованием одного графического процессора. Напомним, что в рамках первой демонстрации DLSS 5 компания Nvidia использовала две видеокарты RTX 5090. Релизная же версия DLSS 5 потребует только одну видеокарту RTX. Технические требования к DLSS 5 пока не озвучены.  Nvidia ещё раз подчеркнула, что DLSS 5 позволяет сохранить художественный замысел создателей игр, а не меняет его. Противоположное мнение у геймеров сложилось из первой демонстрации, где показанные изображения персонажей казались фактически заново перерисованными ИИ. Nvidia заявляет, что каждый отдельный объект, сцена и игровые настройки могут быть настроены в соответствии с видением разработчика. Это один из вызовов, с которым компания столкнулась при разработке DLSS 5. Nvidia отмечает, что поддержание визуальной идентичности, семантики объектов и поз персонажей, а также семантики выходного освещения, движения и художественного оформления имеет решающее значение. В рамках этих строгих параметров DLSS 5 применяет фотореализм материалов для повышения визуальной привлекательности. Ниже можно увидеть настройку применяемой модели, где есть регулируемые параметры, которые можно задать для каждой сцены и каждого персонажа. 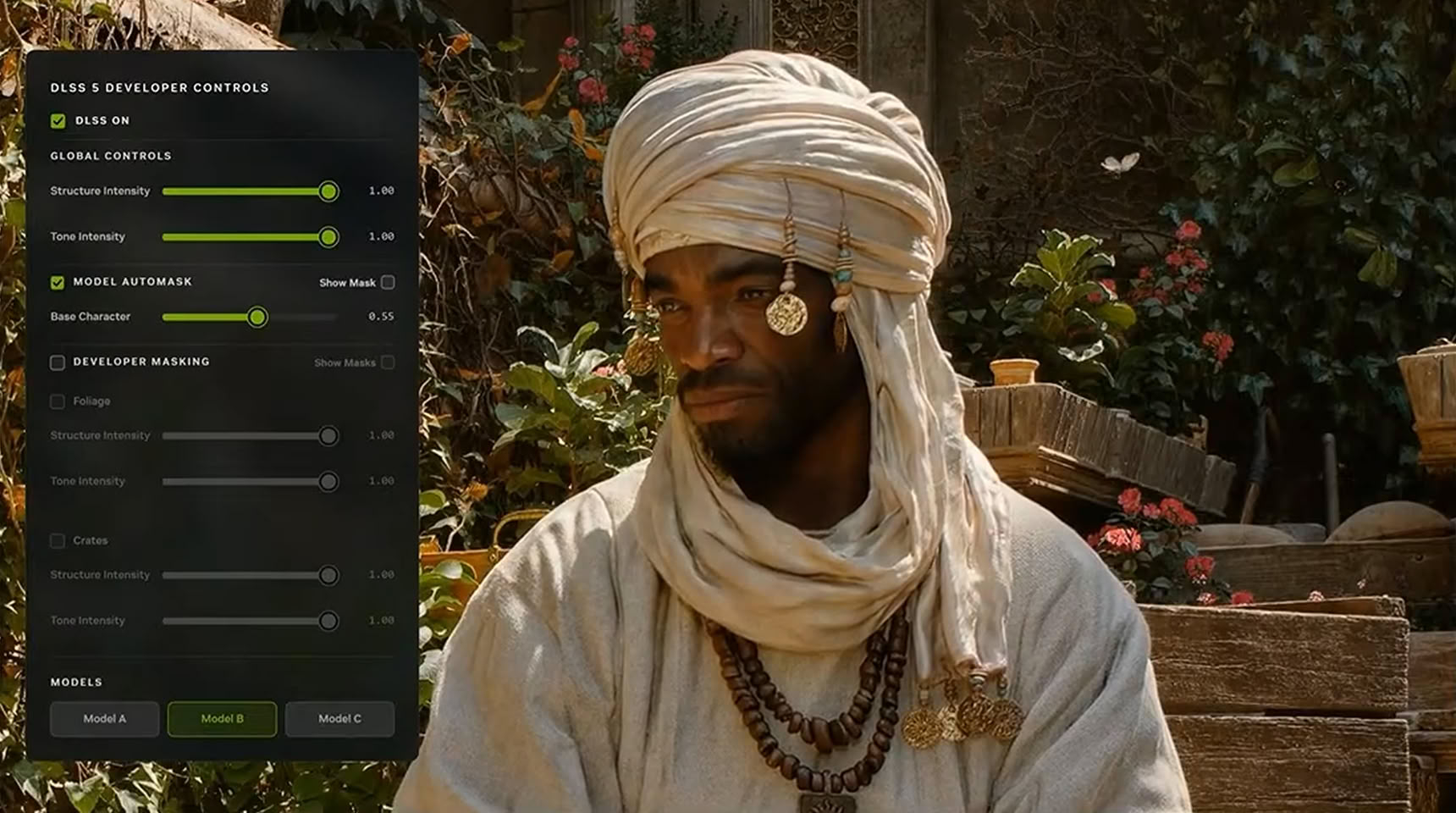 Вторая сложность, которую Nvidia пришлось решать при разработке DLSS 5, — это временная потоковая обработка. Традиционные генераторы видео на основе генеративного ИИ обрабатывают данные по частям, анализируя каждый кадр и генерируя пакет кадров одновременно. Однако рендеринг в реальном времени требует немедленной генерации, кадр за кадром. Поскольку DLSS 5 использует векторы движения из игрового движка, она может мгновенно генерировать дополнительные текстуры без задержки. Это приводит к отсутствию мерцания или искажения изображения, поскольку DLSS 5 точно знает, куда прикрепить текстуру, и мгновенно выполняет её генерацию. Примеры с включённой DLSS 5 и без неё

Смотреть все изображения (8)



Смотреть все изображения (8) Последняя сложность с DLSS 5 — это скорость. Для рендеринга кадра в разрешении 4K с 8,3 млн пикселей со скоростью более 60 кадров в секунду Nvidia достигает этого менее чем за 16 мс. При этом большая часть времени обработки приходится на игровой движок, а не на модель DLSS 5. Технология настолько эффективна, что пользователи не заметят никаких задержек во время игры, утверждает Nvidia. Хотя компания подчёркивает эффективность DLSS 5 в использовании видеопамяти, пока остаётся неясным, будут ли игры в 4K на видеокартах с меньшим объёмом памяти выглядеть хуже, чем на картах с большим объёмом видеопамяти. Поскольку запуск DLSS 5 ожидается этой осенью, Nvidia ещё предоставит общие системные требования и дополнительные подробности, но улучшения по сравнению с оригинальной демоверсией пока выглядят многообещающими. Nvidia научилась определять видеофейки
21.07.2026 [13:50],
Павел Котов
Присутствие созданных искусственным интеллектом материалов неуклонно растёт, и людям всё труднее отличать реальный контент от созданных ИИ подделок. Появляются средства, помогающие выявлять такие материалы — одно из них получило название Nvidia Synthetic Video Detector (SVD). 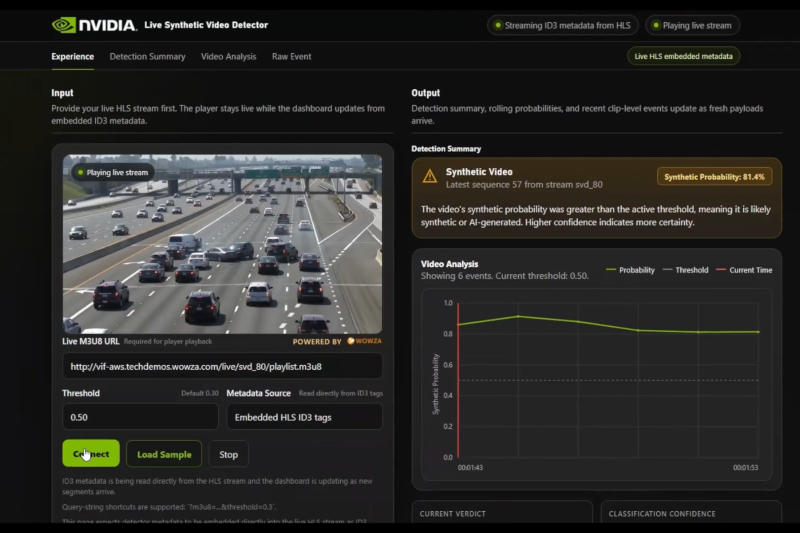
Источник изображения: nvidia.com SVD относится к классу служб Nvidia Inference Microservice (NIM), и она недоступна для потребителей. Её задача относительно проста: определить, является ли видео реальным, или оно было сгенерировано ИИ. Служба анализирует видео в больших масштабах, покадрово разбивая видеоряд для выявления аномалий. Система исследует видеофайл не целиком, а разбивает кадры на фрагменты размером 504 × 504 пикселей. Эти фрагменты изучаются двумя моделями: Meta✴✴ DINOv2 и DINOv3. Их задача — формирование паттернов без подсказок со стороны человека. Обычно эти модели используются для классификации изображений, их поиска, обнаружения объектов и оценки глубины. Модели изучают пространственные характеристики фрагментов кадров и присваивают им оценки: «0» — изображение полностью реально, или «1» — это точно подделка. По итогам комплексного анализа оценки суммируются, и формируется среднее значение, которое показывает пользователю процентную оценку, является ли предложенное видео подделкой или нет. На практике лучшие результаты система показывает при изучении несжатого видео — 92 %. При сжатии на 15 % этот показатель падает до 87 %, а при сжатии на 50 % — до 82 %. Задержка невелика: обработка видео с разрешением 1080p занимает на графических процессорах Nvidia RTX 22 мс, на рабочих станциях Nvidia — 30 мс. Для работы SVD требуется кодировщик NVENC, поэтому ускорители для центров обработки данных, в том числе Nvidia B100, не могут запускать службу нативно. Совместно с Wowza компания Nvidia сейчас разрабатывает систему обнаружения поддельного видео в реальном времени, которую можно будет встраивать в рабочие процессы потоковой передачи. Microsoft по примеру конкурентов начала устанавливать серверные системы AMD Helios в своей облачной инфраструктуре Azure
21.07.2026 [07:01],
Алексей Разин
Компания Nvidia уже давно при поддержке своих подрядчиков поставляет клиентам готовые серверные системы, поэтому у конкурирующей AMD не оставалось иного выбора, кроме как последовать её примеру с системами семейства Helios. К числу покупателей этих систем недавно примкнула Microsoft по примеру Meta✴✴, OpenAI и Oracle. 
Источник изображения: AMD Поставки систем Helios компания AMD начнёт до конца текущего года, как напоминает CNBC. В пресс-релизе Microsoft приводятся слова генерального директора компании Сатьи Наделлы (Satya Nadella): «Мы расширяем инфраструктуру Azure при помощи AMD Helios, чтобы предоставить клиентам производительность, масштаб и выбор, которые им нужны для работы с новым поколением ИИ-приложений». Приобретаемая Microsoft система Helios будет специализироваться на работе с инференсом в инфраструктуре, предназначенной для клиентов Azure. Корпорация также приобретёт две системы на основе процессоров EPYC семейства Venice, одна из них будет специализироваться на агентских задачах, а вторая помогать в разработке полупроводниковых компонентов. AMD утверждает, что проникновение её решений в сегменте инфраструктуры ИИ достаточно велико. Восемь из десяти крупнейших компаний в этом секторе используют в составе вычислительной инфраструктуры ускорители Instinct. В частности, помимо OpenAI и Cohere, это относится и к SpaceXAI Илона Маска (Elon Musk). Ещё в феврале Meta✴✴ объявила о намерениях развернуть вычислительные мощности на базе AMD Helios, потребляющие до 1 ГВт. Помимо OpenAI и Oracle, интерес к ним проявила и индийская Tata Consultancy Services. По словам представителей AMD, при создании Helios компания ставила приоритетную задачу по снижению совокупной стоимости владения и затрат на генерацию одного токена. Клиенты утверждают, что этой цели достичь удалось на фоне конкурирующих решений. По оценкам Futurum Group, одна система семейства Helios обходится клиентам AMD в сумму от $5 млн до $5,5 млн. Это заметно дороже, чем одна система Nvidia Vera Rubin, которая стоит от $3,5 млн до $4 млн. Решение AMD также занимает больше места и весит больше. Тем не менее, с выходом Helios на рынок AMD может увеличить свою долю на нём с нынешних 4,5 до 20 %, либо даже 25 %. Поставки Helios будут приносить AMD сотни миллиардов долларов США в отдалённой перспективе. С 2027 года, по оценкам компании, поставки Helios станут основным источником дохода в серверном сегменте, счёт пойдёт на десятки миллиардов долларов. С одной стороны, продукция Nvidia в серверном сегменте популярна благодаря распространению программной экосистемы CUDA. С другой стороны, в условиях дефицита вычислительных средств AMD сможет неплохо зарабатывать на Helios, если её подрядчики смогут обеспечить достойные объёмы поставок таких систем. В любом случае, укрепление позиций AMD в серверном сегменте станет результатом кропотливой и непрерывной работы. Видеокарты Nvidia умеют показывать температуру каждого чипа памяти по отдельности — энтузиасты нашли доступ
19.07.2026 [18:07],
Андрей Созинов
История со скрытыми температурными датчиками в видеокартах Nvidia получила продолжение. После того как энтузиасты вернули возможность считывать температуру Hotspot у GPU поколения Blackwell, бразильская команда Paulo Gomes Team обнаружила ещё одну скрытую функцию. Оказалось, что графические процессоры Nvidia способны передавать температуру каждого отдельного чипа памяти GDDR6 и GDDR6X, а не только максимальное значение, которое отображают современные утилиты мониторинга. 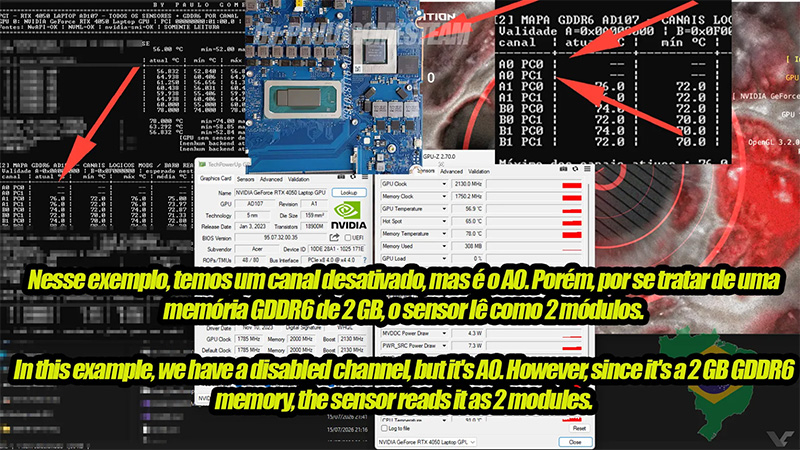
Источник изображения: Videocardz.com До сих пор считалось, что показатель температуры памяти, который выводят GPU-Z, HWInfo и другие программы, характеризует всю подсистему памяти целиком. Однако исследование энтузиастов показало, что это не средняя температура и не температура одного конкретного датчика. На самом деле драйвер получает данные сразу от всех микросхем памяти, но пользователю показывает лишь максимальное значение среди них. Энтузиастам удалось получить доступ к показаниям каждого канала памяти через механизм MMIO (Memory-Mapped I/O). Затем они сопоставили каналы с физическим расположением микросхем вокруг графического процессора и получили возможность отслеживать температуру каждого чипа отдельно. Кроме того, метод позволяет определить, какие каналы памяти отключены или отсутствуют в конкретной конфигурации видеокарты. Проверка на GeForce RTX 3080 с памятью GDDR6X показала, что разброс температур между отдельными микросхемами может быть довольно заметным. В одном из тестов самый горячий чип прогрелся до 86 °C, тогда как остальные оставались существенно холоднее. Именно это максимальное значение и отображалось в привычных программах мониторинга. 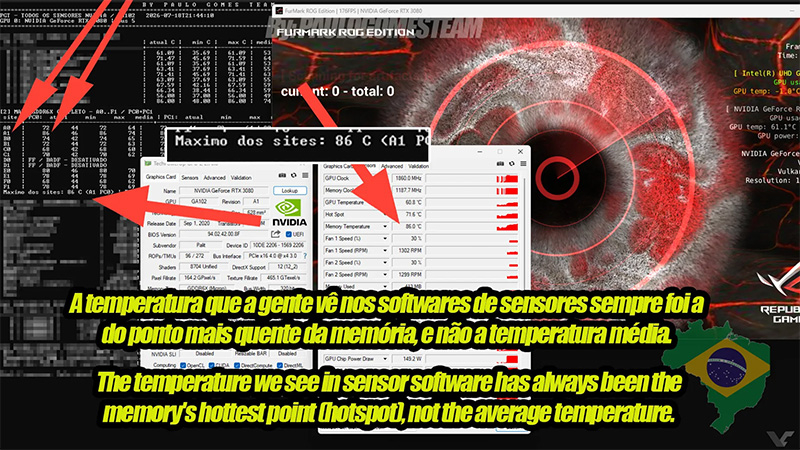
Источник изображения: Videocardz.com По словам авторов исследования, возможность отслеживать температуру каждой микросхемы значительно упростит диагностику неисправностей. Например, она позволит обнаружить плохой контакт термопрокладки с отдельным чипом памяти или выявить микросхему, перегревающуюся сильнее остальных. Это особенно полезно при ремонте видеокарт, замене термоинтерфейсов или поиске причин нестабильной работы памяти. Пока новый метод реализован для мобильных графических процессоров Nvidia с памятью GDDR6, а также для настольных видеокарт GeForce RTX 30 и RTX 40 с памятью GDDR6X. Поддержка настольных моделей с обычной GDDR6 пока отсутствует. Разработанная Paulo Gomes Team утилита также ещё не опубликована. Команда не сообщила, планирует ли выпускать её в открытый доступ или передаст полученные наработки авторам популярных программ мониторинга. Однако сама возможность считывания этих данных свидетельствует, что видеокарты Nvidia содержат значительно больше диагностической информации, чем доступно пользователям через стандартные программные интерфейсы. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex