Для начала мы бы хотели поговорить о том, что для AMD обозначает название Polaris. В прошлые годы компания избегала публичных терминов, позволяющих объединить различные GPU на основании общих архитектурных признаков. Хотя первые чипы, произведенные AMD по технологии 28 нм (линейка Radeon HD 7000), официально были выпущены под флагом Southern Islands, в выступлениях по поводу следующих новинок названия Sea Island, Pirate Islands и Volcanic Islands отошли на второй план, как будто производитель уже не хотел привлекать внимание к таким определениям.
Причины этого вполне понятны: хотя графические процессоры на архитектуре GCN во многом изменились и прогрессировали начиная с первых образцов, появившихся в 2011-2012 годах, AMD предпочла путь постепенных изменений, когда дополнения к архитектуре внедряются последовательно в одном GPU за другим. Вместо того, чтобы сразу обновить несколько продуктов в линейке (как это стремится делать NVIDIA), в эпоху 28 нм AMD выпускала по одному процессору в той позиции, где считала это необходимым, и наделяла его теми технологиями, которые были готовы к воплощению в кремнии на тот момент. В результате 300-е семейство Radeon оказался разношерстной линейкой дискретных ускорителей, в которую входят представители всех перечисленных «островов».
К счастью, пришествие Polaris проясняет ситуацию. Все чипы под этим наименованием представляют собой совершенно новую разработку и различаются только количественными характеристиками — числом вычислительных блоков и тактовой частотой. Предыдущее наименование — Arctic Islands — похоронено в недрах AMD, и впредь компания будет использовать звездные имена для обозначения архитектуры (из которых следующим итерациям принадлежат Vega и Navi).
Что касается собственно Polaris, то с помощью этой линейки AMD планирует освоить техпроцесс 14 нм FinFET, реализованный на производственных мощностях GlobalFoundries и Samsung, и наполнить массовый и «производительный» сегменты рынка дискретных GPU, в то время как верхнюю позицию займет процессор на архитектуре Vega. Как известно, отличительной чертой последнего будет поддержка памяти HBM2, и, судя по тому, сколько нововведений вобрали в себя чипы Polaris, на долю Vega вряд ли останется много изменений, помимо увеличения количества вычислительных блоков.
Согласно информации из официальных и неофициальных источников, подтвердить или опровергнуть наши предположения насчет Vega мы сможем в промежутке между октябрем текущего года и началом следующего, а пока AMD рада представить три новых продукта — Radeon RX 460, RX 470 и RX 480, основанных на GPU Polaris 10 и Polaris 11. Теперь мы можем раскрыть спецификации двух младших карт и опубликовать полный обзор Radeon RX 480.
⇡#Radeon RX 460, RX 470 и RX 480: технические характеристики, цены
Хотя AMD не делала заявлений по поводу новой номенклатуры своих десктопных ускорителей, очевидно, что названия изменились. Больше не используются цифры для кодирования сегмента производительности, к которому принадлежит карта (R7/R9), и среди представленных моделей нет ни одной с суффиксом. Хотя RX 470 и RX 480 построены на одном и том же чипе Polaris 10 и различаются числом активных вычислительных блоков, производитель развел их с помощью модельного номера — иначе старшая модель получила бы суффикс X. Впрочем, Radeon RX 460 также, судя по всему, несет частично заблокированный GPU. Поэтому если AMD в будущем сочтет нужным выпустить видеокарту на полноценном Polaris 11 в 400-й линейке, более вероятно, что ее назовут RX 465, нежели, к примеру, RX 460X.
Кроме того, если учесть состав новой линейки, которая пока не содержит моделей высшего сегмента, удачно выглядит прошлое решение не включать видеокарты Fury в 300-ю линейку — в противном случае возникла бы ситуация, когда более производительные продукты имеют меньшие модельные номера, чем середнячки.
Поговорим о спецификациях трех новинок. Radeon RX 480 — единственная карта, о которой пока есть полная информация. Она основана на полностью функциональном процессоре Polaris 10, который содержит 36 Compute Units (CU) и обладает 256-битной шиной памяти. Эти параметры выдают в новинке наследника Radeon R9 380X, но большее количество вычислительных блоков, повышенные тактовые частоты и всестороння оптимизация архитектуры обеспечивают производительность на уровне 5800 GFLOPS (согласно официальным данным), что ненамного отличается от того, что может предложить Radeon R9 390X (5913,6 GFLOPS). Как и плоды предыдущей итерации архитектуры GCN, Polaris 10 выполняет расчеты двойной точности (FP64) на скорости 1/32 от FP32.
К слову, тактовые частоты GPU в RX 480, ограниченные планкой 1266 МГц, не настолько высоки, как можно было бы ожидать от чипа, произведенного по техпроцессу 14 нм FinFET. В конце концов, AMD утверждает, что переход с узла 28 нм на 14 нм увеличил удельную производительность в 1,7 раз, а оптимизации архитектуры довели соотношение до 2,8. Однако в данном случае неизбежно сравнение с GeForce GTX 1070, который при такой же мощности и обладая более крупным GPU достигает частот вплоть до 1683 МГц.
| Производитель |
AMD |
| Модель |
Radeon HD 7970 GHz Edition |
AMD Radeon R9 380X |
Radeon R9 390 |
Radeon R9 390X |
Radeon RX 470 |
Radeon RX 480 |
| Графический процессор |
| Кодовое название |
Tahiti XT2 |
Antigua XT (Tonga XT) |
Grenada Pro (Hawaii Pro) |
Grenada XT (Hawaii XT) |
Polaris 11 |
Polaris 10 |
| Микроархитектура |
GCN 1.0 |
GCN 1.2 |
GCN 1.1 |
GCN 1.1 |
GCN 1.3 |
GCN 1.3 |
| Техпроцесс, нм |
28 |
28 |
28 |
28 |
14 FinFET |
14 FinFET |
| Число транзисторов, млн |
4313 |
5000 |
6200 |
6200 |
5700 |
5700 |
| Тактовая частота, МГц: Base Clock / Boost Clock |
1000/1050 |
970/— |
1000/— |
1050/— |
НД |
1120/1266 |
| Число потоковых процессоров |
2048 |
2048 |
2560 |
2816 |
2048 |
2304 |
| Число текстурных блоков |
128 |
128 |
160 |
176 |
128 |
144 |
| Число ROP |
32 |
32 |
64 |
64 |
32 |
32 |
| Оперативная память |
| Разрядность шины, бит |
384 |
256 |
512 |
512 |
256 |
256 |
| Тип микросхем |
GDDR5 SDRAM |
GDDR5 SDRAM |
GDDR5 SDRAM |
GDDR5 SDRAM |
GDDR5 SDRAM |
GDDR5 SDRAM |
| Тактовая частота, МГц (пропускная способность, Мбит/с на контакт) |
1500 (6000) |
1425 (5700) |
1500 (6000) |
1500 (6000) |
НД |
1750 (7000) / 2000 (8000) |
| Объем, Мбайт |
3072 |
4096 |
8192 |
8192 |
4096 |
4096/8192 |
| Шина ввода/вывода |
|
PCI Express 3.0 x16 |
PCI Express 3.0 x16 |
PCI Express 3.0 x16 |
PCI Express 3.0 x16 |
PCI Express 3.0 x16 |
| Производительность |
| Вычислительная мощность, FP32, GFLOPS |
4300 |
3973,1 |
5120 |
5913,6 |
>4000 |
5800 |
| Производительность FP32/FP64 |
1/4 |
1/16 |
1/8 |
1/8 |
1/16 |
1/16 |
| Пропускная способность оперативной памяти, Гбайт/с |
288 |
182,4 |
384 |
384 |
НД |
224 |
| Вывод изображения |
| Интерфейсы (макс разрешение @ частота кадров, Гц) |
VGA, DL DVI, HDMI 1.4a, DisplayPort 1.2 |
VGA, DL DVI, HDMI 1.4a, DisplayPort 1.2 |
VGA, DL DVI, HDMI 1.4a, DisplayPort 1.2 |
VGA, DL DVI, HDMI 1.4a, DisplayPort 1.2 |
DL DVI, HDMI 2.0b, DisplayPort 1.3/1.4 |
DL DVI, HDMI 2.0b, DisplayPort 1.3/1.4 |
| TDP, Вт |
250 |
190 |
275 |
275 |
НД |
150 |
| Розничная цена на момент выпуска (рекомендованная для США, без налогов), $ |
500 |
229 |
329 |
429 |
НД |
199/229 |
В качестве оперативной памяти RX 480 использует чипы GDDR5 с пропускной способностью 8 Гбит/с на контакт — это максимальная скорость, доступная сегодня для этого типа памяти, и большое подспорье для графических процессоров AMD, которые до этого момента никогда не переходили границу 6 Гбит/с в референсных продуктах. Впрочем, в этом пункте AMD сообщает кое-что мелким шрифтом: хотя референсные образцы RX 480, выпущенные AMD, комплектуются чипами 8 Гбит/с, партнерские карты имеют право опускаться вплоть до 7 Гбит/с.
Повышенная частота памяти все еще не может компенсировать уменьшенную до 256 бит ширину шины RAM в сравнении с предыдущими продуктами AMD, оснащенными 384- и 512-битными шинами памяти, но, как мы увидим далее, погрузившись в особенности архитектуры GCN нового поколения, разработчики приняли меры, чтобы компенсировать сравнительно низкую пропускную способность интерфейса за счет более эффективного использования последней.
Рекомендованная цена RX 480 для США составляет $199 за версию с 4 Гбайт RAM и 229 за версию с 8 Гбайт. Российские цены — 16 310 и 18 970 руб. соответственно.
Про модель RX 470 пока известен объем RAM (4 Гбайт), количество CU, которое позволяет рассчитать набор активных потоковых процессоров и текстурных блоков, и приблизительное быстродействие ускорителя, которое однозначно выше, чем у Radeon R9 380X, но ниже, чем у R9 390. 256-битная шина памяти осталась нетронутой, что приводит к цифрам 32 ROP. Ни энергопотребление, ни частоты, ни цену AMD пока не разглашает. Неизвестна и дата появления карт в продаже.
Что касается Radeon RX 460, то это, скорее всего, будет самая младшая из дискретных видеокарт Polaris, доступных в рознице. Известные спецификации ставят ее на один уровень с Radeon R7 260X, который, в отличие от R7 360, комплектовался полнофункциональным чипом Bonaire. Ожидаемо более высокие частоты и оптимизации ядра, конечно, делают новинку быстрее предшественника, однако RX 460 сам основан на частично заблокированном GPU, в то время как полная версия ядра включает 1024 потоковых процессора и 64 текстурных блока.
| Производитель |
AMD |
| Модель |
Radeon R7 260X |
Radeon R7 360 |
Radeon RX 460 |
| Графический процессор |
| Кодовое название |
Bonaire XTX |
Tobago (Bonaire Pro) |
Polaris 11 |
| Микроархитектура |
GCN 1.1 |
GCN 1.1 |
GCN 1.3 |
| Техпроцесс, нм |
28 |
28 |
14 FinFET |
| Число транзисторов, млн |
2080 |
2080 |
НД |
| Тактовая частота, МГц: Base Clock / Boost Clock |
1100/— |
1050/— |
НД |
| Число потоковых процессоров |
896 |
768 |
896 |
| Число текстурных блоков |
56 |
48 |
56 |
| Число ROP |
16 |
16 |
16 |
| Оперативная память |
| Разрядность шины, бит |
128 |
128 |
128 |
| Тип микросхем |
GDDR5 SDRAM |
GDDR5 SDRAM |
GDDR5 SDRAM |
| Тактовая частота, МГц (пропускная способность, Мбит/с на контакт) |
1625 (6500) |
1625 (6500) |
НД |
| Объем, Мбайт |
2048 |
2048 |
2048 |
| Шина ввода/вывода |
PCI Express 3.0 x16 |
PCI Express 3.0 x16 |
PCI Express 3.0 x8 |
| Производительность |
| Вычислительная мощность, FP32, GFLOPS |
1971,2 |
1612,8 |
>2000 |
| Производительность FP32/FP64 |
1/16 |
1/16 |
НД |
| Пропускная способность оперативной памяти, Гбайт/с |
104 |
104 |
НД |
| Вывод изображения |
| Интерфейсы (макс разрешение@частота кадров, Гц) |
VGA, DL DVI, HDMI 1.4a, DisplayPort 1.2 |
VGA, DL DVI, HDMI 1.4a, DisplayPort 1.2 |
DL DVI, HDMI 2.0b, DisplayPort 1.3/1.4 |
| TDP, Вт |
115 |
100 |
НД |
| Розничная цена на момент выпуска (рекомендованная для США, без налогов), $ |
139 |
109 |
НД |
Polaris 10 и Polaris 11
Теперь посмотрим на новые GPU более пристально. В целом схема графических процессоров соответствует принципам, заложенным в чипе Tahiti и затем усовершенствованным в Tonga и Fiji. 64 шейдерных ALU и 4 текстурные модуля входят в Compute Unit, а группы последних (8 в Polaris 11 и 9 в Polaris 10) вместе с растеризатором и геометрическим процессором образуют наиболее крупный строительный блок GPU — Shader Engine.
Общий Front-end архитектуры составляют диспетчеры команд различного назначения (для шейдеров и вычислительной нагрузки) вместе с хранилищем Global Data Share, используемым для синхронизации работы последних. На выходе из GPU мы видим набор контроллеров памяти и большой кеш L2.
Внешнюю относительно логики GPU часть кристалла (uncore) составляют контроллер интерфейсов дисплея, блоки DMA и XDMA (используется для работы CrossFire), кодировщик/декодировщик видео и интерфейс шины PCI Express. Заметьте, что на схеме нет блока TrueAudio — для этой технологии отныне будут использоваться вычислительные ресурсы шейдерных ALU.
Архитектура GCN 4-го поколения
Процессоры Polaris представляют крупнейшее обновление архитектуры Graphics Core Next, вобравшее в себя изменения на всех стадиях графического и вычислительного конвейера GPU. Для тех читателей, которые не следили за эволюцией графики от AMD слишком внимательно, различие между Polaris и GCN 4-го поколения (в журналистской среде ходит цифровое обозначение GCN 1.3, но AMD предпочитает нумеровать итерации архитектуры отдельными поколениями) может показаться запутанным, однако мы уточним, что Polaris, как и различные «острова» до этого обозначают семейства графических процессоров, а версия GCN указывает на особенности той логики, которая в микросхеме составляет собственно GPU.
Итак, вот какие свойства GCN 1.3 акцентирует AMD.
- Начиная с front-end чипа, мы видим, что GCN 1.3 включает ни много ни мало а семь планировщиков, распределяющих блоки инструкций (wavefronts в терминологии AMD, в то время как NVIDIA использует аналогичный термин warp) на исполнение в массиве Compute Units. Надо отметить, что современный вид этот раздел GPU принял еще в GCN 1.2 (Tonga и Fiji), и если AMD внесла сюда какие-либо изменения, то на блок-схеме их не заметить. Тем не менее AMD справедливо привлекает внимание к планировщикам в Polaris сейчас.
Наличие независимых планировщиков для графики (GCP — Graphics Command Processor) и вычислений общего назначения (ACE — Asynchronous Compute Engine) начиная с первых образцов архитектуры GCN наделяет процессоры AMD возможностью выполнять шейдерные и вычислительные инструкции одновременно, а в GCN 1.2 вместо четырех из восьми блоков ACE разработчики ввели два блока HWS (Hardware Scheduler), каждый из которых функционально эквивалентен двум ACE, но также позволяет прерывать исполнение одного потока инструкций, выделяя время для более приоритетных задач. К слову, хотя HWS впервые фигурируют в описании Fiji, чип Tonga получил их раньше, что подтверждают ускорители FirePro на его основе, в которых впервые была реализована полностью аппаратная виртуализация GPU.

Аппаратные планировщики, которые AMD сохранила в кремнии, не последовав примеру NVIDIA (которая сделала обратное еще в архитектуре Kepler), требуют места на кристалле, но сейчас эта возможность, доселе мало востребованная в потребительском секторе, позволит чипам AMD засиять. Два главных тренда в игровой графике этого года — DirectX 12 и VR — делают упор на асинхронные вычисления.
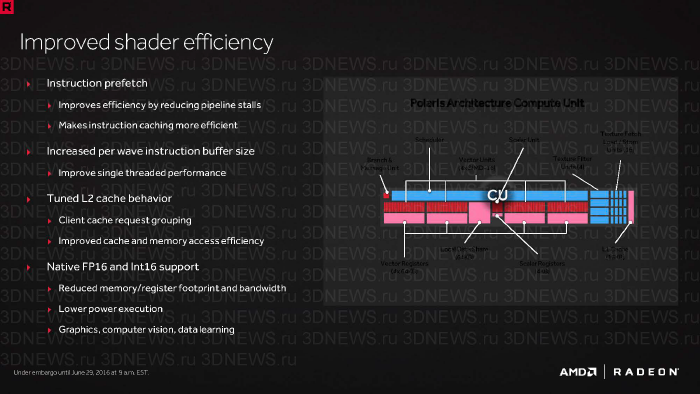
- Compute Unit в GCN 1.3 претерпел ряд изменений, связанных с предвыборкой и кешированием инструкций, обращениям к кешу L2, которые в совокупности повышают удельную производительность CU на 15% (по сравнению с чипом Hawaii). Функциональное нововведение заключается в поддержке вычислений половинной точности (FP16), которые используются в программах компьютерного зрения и машинного обучения.
- GCN 1.3 предоставляет прямой доступ к внутреннему набору инструкций (ISA) потоковых процессоров, за счет которого разработчики могут писать максимально «низкоуровневый» и быстрый код — в противоположность шейдерным языкам DirectX и OpenGL, абстрагированным от железа, на котором работает шейдерная программа. Функция на данный момент доступна в API DirectX 11, DX 12 и Vulkan.
- Но если какой-то аспект GCN и требовал повышенного внимания со стороны инженеров AMD, то это производительность GPU в обработке геометрии, в особенности — при тесселяции высокой степени. Геометрические процессоры в GCN 1.3 способны на ранних этапах конвейера исключать полигоны нулевого размера либо полигоны, не имеющие пикселов в проекции (проблема, которая усугубляется при использовании мультисемплинга как метода полноэкранного сглаживания), и получили кеш индексов, снижающий поглощение ресурсов при рендеринге мелкой дублирующейся геометрии.
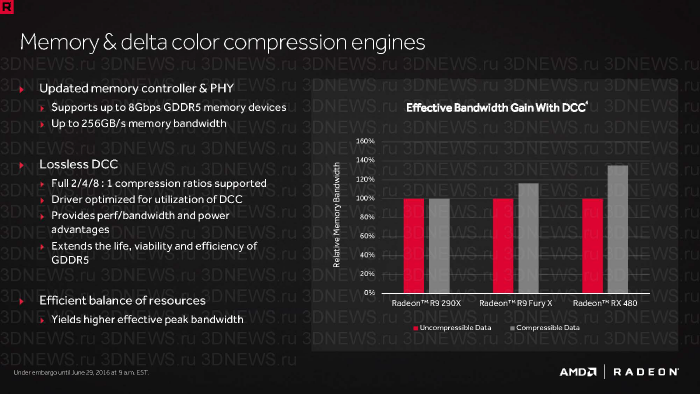
Обсуждая спецификации Radeon RX 480, мы упомянули, что, хотя Polaris 10 обладает сравнительно небольшой пропускной способностью шины RAM для ядра данной вычислительной мощности, видеокарта обладает такой скоростью обращения к данным, как если бы ПСП была увеличена на 40%. Вот что позволило достигнуть этой цели.
- Кеш L2 удвоенного объема: с 512 Кбайт до 1 Мбайт в Bonnaire и Polaris 11, с 1 Мбайт до 2 Мбайт в Tonga и Polaris 10.
- Дельта-компрессия цвета с отношениями вплоть до 8:1. Эта методика, представленная ранее в чипах Tonga и Fiji на базе архитектуры GCN 1.2, повысила свою эффективность в GCN 1.3 на 17%.
⇡#Uncore в Polaris: кодек видео и вывод изображения
Мультимедийные функции чипов Polaris столь же соответствуют передовым стандартам, как и основная часть GPU. От Fiji новому поколению достался декодер стандарта H.265 (HEVC), способный обрабатывать поток разрешением 4К с частотой 60 Гц, а предельная частота для блока H.264 в 4К увеличена до 120 Гц. Кодировщик также приобрел совместимость со стандартом HEVC — вплоть до 60 Гц в режиме 4К (и 4К с частотой 30 Гц в формате H.264). Дополнительно в кодировщик были внесены оптимизации для быстрого кодирования в два прохода (что неизбежно для получения качественного результата).
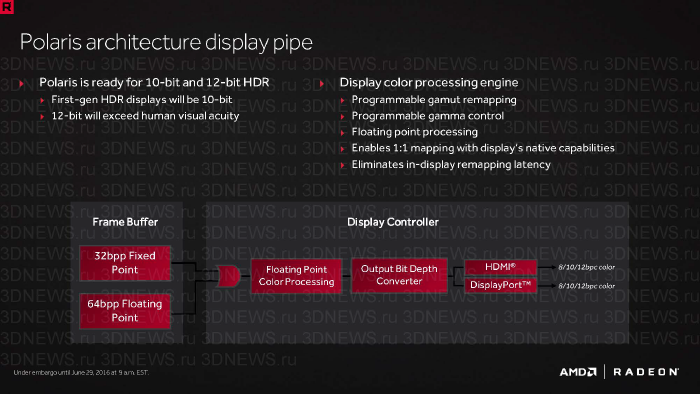
В плане вывода изображения видеокарты Polaris совместимы с интерфейсами DisplayPort 1.3/1.4 (последний будет финализирован в будущем) и HDMI 2.0b. Это значит, что на данный момент Polaris может выводить сигнал с разрешением 5120 × 2880 с частотой 60 Гц посредством DisplayPort и 3840 × 2160 при 60 Гц через HDMI.
Конвейер дисплея поддерживает передачу цвета с глубиной 10 и 12 бит на канал и позволяет выполнять аппаратно коррекцию гамма-кривой и цветового охвата под спецификации устройства вывода изображения. Все это необходимо для совместимости с HDR-экранами — сейчас это телевизоры с интерфейсом HDMI 2.0b, а мониторы приобретут такую функциональность по завершению работ над стандартом DisplayPort 1.4.
⇡#14 нм FinFET и оптимизации энергопотребления
Кристалл Polaris 10, содержащий 5,7 млрд транзисторов, обладает площадью 232 мм2, что позволяет оценить прирост плотности чипа в 65% по сравнению с Fiji — наиболее плотным GPU AMD, изготовленным по технологии 28 нм (8,9 млрд транзисторов, 596 мм2). Для сравнения, NVIDIA при переходе к техпроцессу 16 нм увеличила плотность на 72% (GM200 — 8 млрд транзисторов и 601 мм2, GP104 — 7,2 млрд транзисторов, 314 мм2).
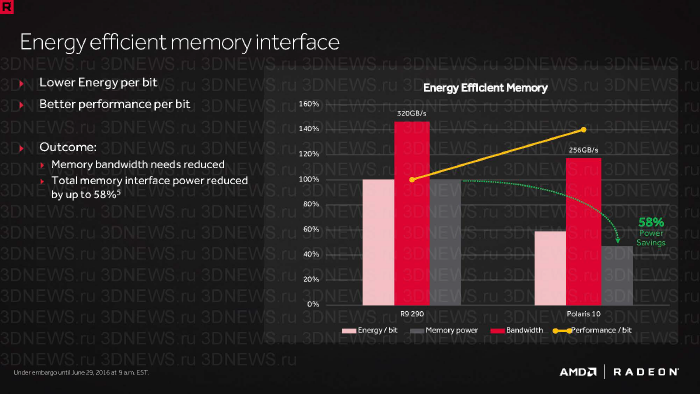
Как мы кратко упомянули выше, AMD увеличила производительность на ватт в 1,7 раза при наиболее благоприятном сценарии по сравнению с GCN прошлых итераций (для сравнения AMD взяла Radeon R9 290) за счет одной «грубой силы» — техпроцесса 14 нм FinFET и применения power gating и clock gating (отключения от питания и сброса частоты простаивающих вычислительных блоков). Дополнительные функции управления питанием позволили повысить заявленный результат до 2,8.
Впрочем, чип Hawaii (да еще и в частично заблокированной конфигурации, какую он имеет в R9 290) — легкая мишень для Polaris, т.к. в последующих Tonga и Fiji разработчики хорошо поработали над увеличением энергоэффективности. К тому же, в энергопотребление видеокарты вносит вклад RAM, а в RX 480, как мы увидим дальше, используются новые чипы с существенно пониженным напряжением питания (1 В против стандартных для GDDR5 1,5 В).
Если взять для сравнения Radeon R9 380X на ядре Tonga, то, опираясь на официальные значения TDP и производительность в наших собственных игровых тестах, то в RX 480 AMD увеличила энергоэффективность на 62%, однако и по сравнению с R9 290 энергоэффективность RX 480 увеличилась только на 72%, что не соответствует заявленным AMD показателям. Для NVIDIA, при сравнении результатов GeForce GTX 1080 и GTX 980, разница в производительности на Ватт между поколениями составляет 51%.
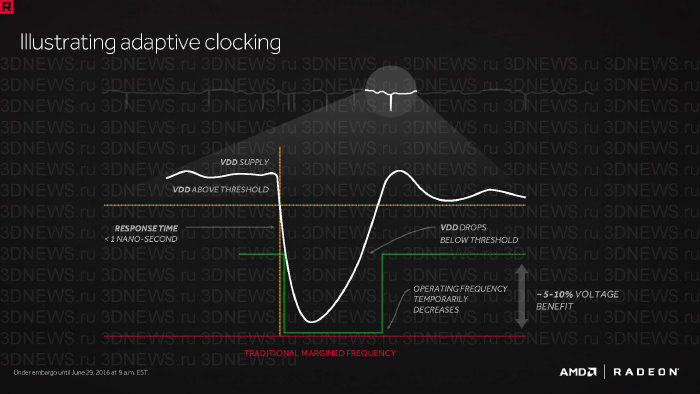
Задача инженеров, работающих над каждым новым поколением видеокарт, — снизить избыточный компонент в напряжении питания GPU, который неизбежно присутствует для того, чтобы компенсировать ряд негативных факторов — вариацию в токе утечки между различными экземплярами микросхемы, не вполне предсказуемый температурный режим, старение кремния, несовершенство компьютерного БП и преобразователя напряжения на плате.
Polaris демонстрирует новый способ использования высокоскоростного канала телеметрии, передающего данные о температуре и напряжениях компонентов видеокарты ШИМ-контроллеру преобразователя напряжения, а затем — логике внутри GPU. Теперь GPU умеет мгновенно (с задержкой меньше 1 нс) сбрасывать частоту при падении питающего напряжения, вызванного скачком тока на самой видеокарте или внешними причинами. В свою очередь, обратный канал связи передает ШИМ-контроллеру текущую частоту GPU. В результате целевое напряжение на GPU удалось снизить на 5-10%.
- Boot Time Calibration. При каждом запуске контроллер считывает данные с датчиков напряжения, дабы скорректировать вариации между экземплярами платы, установив минимально необходимый избыток напряжения.
- Калибровка также выполняется с целью компенсировать старение кремния, поскольку со временем микросхема требует большего напряжения для стабильной работы.
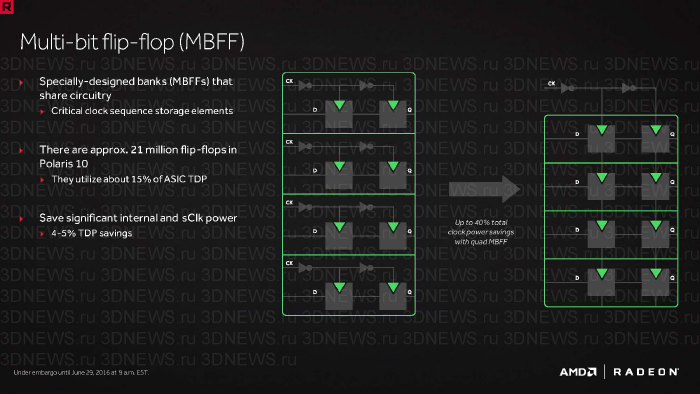
- Что касается схемотехники GPU, то инженеры AMD постарались максимизировать долю MBFF (Multi-bit flip-flop) — цепей, использующих общую тактующую схему для нескольких логических элементов, что в итоге привело к снижению мощности на 4-5%
- Все меры, направленные на экономию ПСП в Polaris и снижающие частоту обращений к внешней памяти, благоприятно влияют и на энергопотребление интерфейса GDDR5.
⇡#Поддержка функций рендеринга DirectX 12
Архитектура GCN изначально обладала наиболее полным набором возможностей, которые принес API DirectX 12, а во втором поколении (чипы Hawaii и Bonaire, которым комплектуются Radeon HD 7790, R9 260/260X и R9 360) удовлетворяет условиям feature level 12_0.
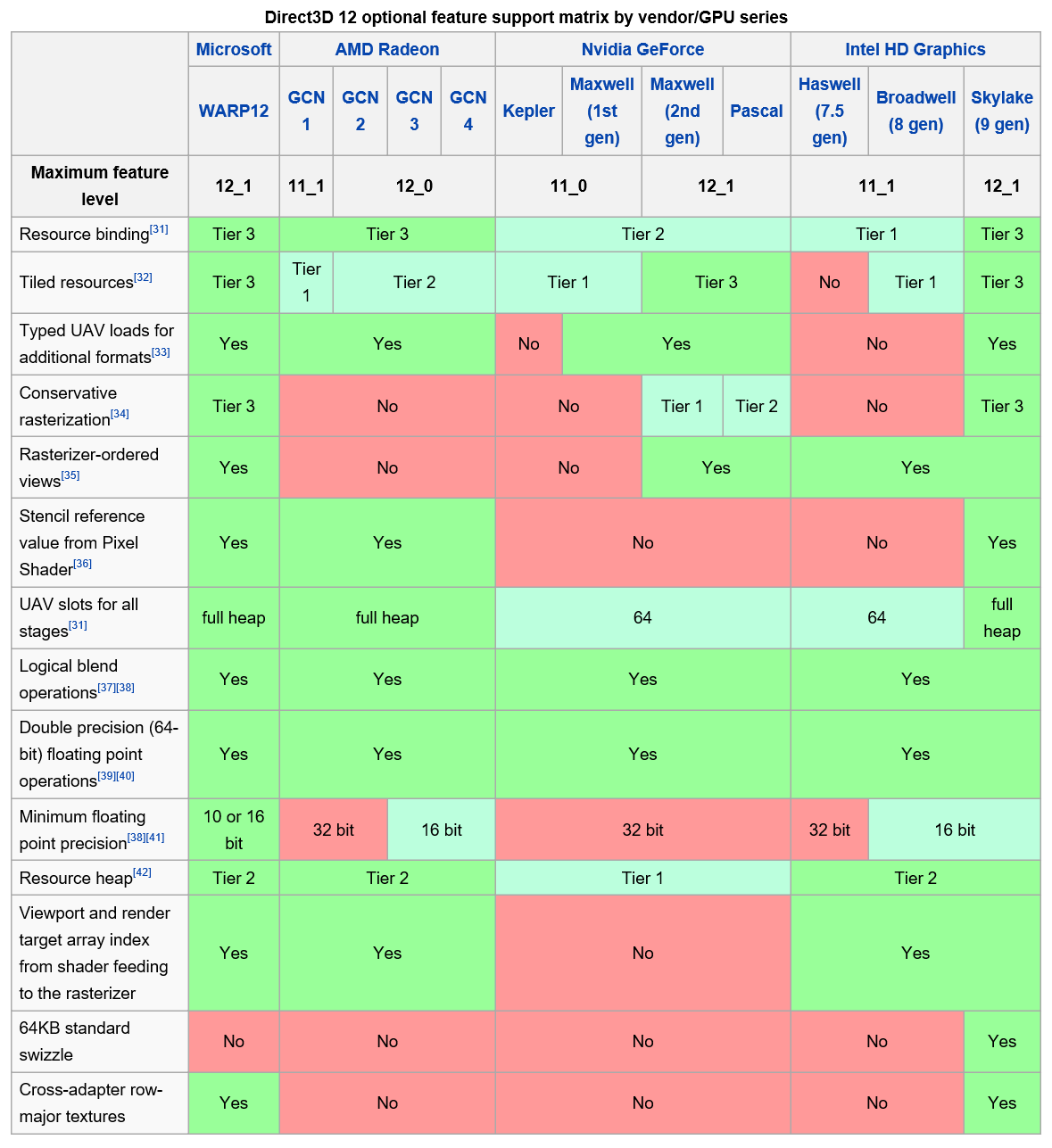
GCN версии 1.3 всех функций, не охваченных в прошлых итерациях, ввела поддержку вычисления половинной точности (FP16). AMD не сообщает о каких-либо иных изменениях в этой области (что было бы сказано в противном случае), с чем также согласна страница из «Википедии», снимок которой мы приводим здесь, вполне достоверная в плане информации о GCN предыдущих версий и конкурирующих архитектурах (за исключеним поддержки расчетов FP16 на GPU NVIDIA, хотя у Microsoft могут быть какие-либо дополнительные требования к аппаратной реализации последней).
Архитектура GCN лишена двух функций, необходимых для квалификации в более высоких feature levels, включение которых даже в базовой форме (tier 1) принесла бы GCN поддержку feature level 12_1.
- Conservative Rasterization. Данный метод растеризации полигонов предполагает, что каждый пиксел кадра, которого коснулась проекция полигона, считается принадлежащим этому полигону (в противном случае полигон должен покрыть определенную площадь внутри пиксела). Этот пункт имеет значение в таких ситуациях, как отрисовка теней или эффектов прозрачности, когда стандартная растеризация может приводить к появлению артефактов.
- Rasterizer-Ordered Views — функция, которая позволяет разработчику заблаговременно определить, в каком порядке произойдет рендеринг различных элементов сцены. В большинстве случаев это не имеет значения, т.к. элементы, расположенные глубже в сцене, все равно будут перекрыты более близкими. Однако в случаях с прозрачными текстурами неконтролируемый порядок рендеринга может вызывать артефакты: элементы, которые должны быть закрыть прозрачной текстурой, выступают вперед.
Учитывая, сколько непонимания вызывает информация о поддержке DirectX 12 в том или ином GPU, не лишним будет напомнить, что совместимость с самой runtime-библиотекой Direct3D 12 (которая как раз-таки несет критически важные изменения по сравнению с Direct3D 11) никак не связана с соответсвием тому или иному feaure level внутри этого стандарта. А по сумме критериев, определяющим feature level графического процессора в DirectX 12 (за вычетом двух указанных функций) архитектура GCN 1.3 не уступает железу NVIDIA и отчасти превосходит его.
⇡#Новое ПО для AMD Radeon
Прежде чем мы возьмем в руки саму видеокарту Radeon RX 480, поговорим о том, как AMD планирует развивать программное обеспечение своих продуктов.
Во-первых, компания обещает выпускать драйверы чаще, чем это происходило в последнее время. После долгого периода ежемесячных релизов, за 2015 год были выпущены только три версии Radeon Software, сертифицированных WHQL и девять бета-версий, содержащих оптимизации под конкретные игры. Отныне AMD обещает выпускать по шесть крупных обновлений драйверов в год, сертицифированных WHQL, и столько промежуточных версий, сколько требуется для поддержки свежих игр, сколько будет необходимо (последние по возможности также будут получать сертификат WHQL).
Одно из нововведений, подлежащих внедрению в будущих версиях, — технология frame pacing (направленная на снижение задержек в конфигурациях с множественными GPU) для API DirectX 12, уже пережившая несколько итераций обновления в драйвере для DX11.
Поскольку RX 480 позиционируется как доступный ускоритель для среды виртуальной реальности, AMD уделяет большое внимание этой теме. Существует фирменный набор библиотек и SDK под назвнанием LiquidVR (с поддержкой API DirectX 12 и Vulkan), предназначенный для управления функциями GPU, критичными для VR. Возможности GCN качественно мало изменились со времен первой итерации, поэтому следующие новшества доступны для всех продуктов на базе данной архитектуры.
Используя возможности кремния AMD, LiquidVR предлагает несколько сценариев одновременного выполнения графических и вычислительных задач.
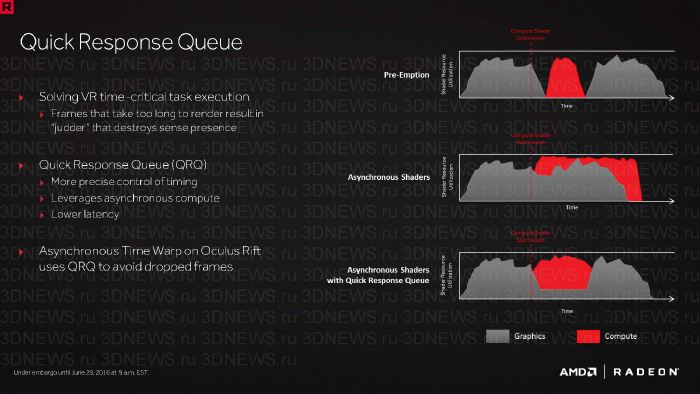
- Собственно асинхронные вычисления, когда аппаратные планировщики GCN автоматически распределяют ресурсы Compute Unit’ов между гетерогенными задачами.
- Прерывание (preemption) выполнения шейдерных инструкций в пользу вычислительных потоков, требующих завершения с низкой латентностью.
- Quick Response Curve (QRC) — приоритизация вычислительных потоков, посредством которой, к примеру, реализуется быстрый Time Warp в шлеме Oculus Rift. Эта функция, которую мы упоминаем не в первый раз, позволяет быстро смещать поле зрения при помощи шейдера пост-обработки при повороте головы игрока, не дожидаясь, пока следующий кадр будет готов к выводу на экран.
- Резервирование Compute Unit’ов для определенной задачи, будь то шейдер или иная вычислительная цепочка.
Variable Rate Shading (VRS) — технология рендеринга, направленная на экономию ресурсов филлрейта пикселов в среде VR. Известно, что для виртуальной реальности формируются кадры избыточной площади с тем, чтобы компенсировать искажения пропорций, вносимые линзами шлема. Линза оптически компрессирует краевые области кадра, разрешение в которых, таким образом, также оказывается избыточным. Дабы снять с GPU работу по заполнению пикселов, которые в итоге не имеют полезной функции, драйвер разделяет пространство кадра на несколько портов просмотра (viewports), среди которых периферические обладают сниженным разрешением относительно центрального.

Архитектура GCN по-прежнему не умеет проецировать геометрию под разным углом на различные порты просмотра, как это делает Pascal от NVIDIA, но по меньшей мере, VRS в этом аспекте выводит ускорители AMD на один уровень с Maxwell, где появилась технология Viewport Multicast, выполняющая, среди прочего, именно эту функцию. Однако в своей реализации AMD ввела уникальную на данный момент опцию: границы портов просмотра могут смещаться вслед за движением глаз игрока (при условии, что шлем имеет соответствующие датчики — таких пока нет ни в одном из коммерческих продуктов).
Как мы упомянули в анализе чипов Polaris, блок TrueAudio больше не присутствует в кремнии GPU. Как бы привлекательно технология не выглядела на бумаге, в итоге она не получила распространения за пределами считанных игровых наименований. Однако AMD не отказалась от идеи аппаратного ускорения звуковых эффектов. Вместо того, чтобы использовать для этой цели выделенный массив DSP, в TrueAudio Next обработка звука рассматривается как типичная вычислительная нагрузка для шейдерных ALU графического процессора. Следовательно, TrueAudio больше не является бесплатной технологией с точки зрения производительности GPU, но взамен приобрела большую гибкость. В частности, возможно позиционирование звука в пространстве.
Благодаря интересу к VR и тому факту, что AMD теперь предоставляет в распоряжение разработчиков не просто аппаратную функцию, а готовый API, новая реализация TrueAudio имеет шансы на более широкое распространение, нежели ее незаслуженно забытая предшественница.
⇡#AMD Radeon RX 480: конструкция
Radeon RX 480 мы изучим на примере референсного образца, произведенного AMD (хотя оригинальные версии карты уже подготовлены и, вероятнее всего, станут доступны в день запуска модели). Дизайн видеокарты выполнен в едином стиле с референсными версиями Radeon R9 Fury X и R9 Nano.
Довольно крупная система охлаждения с вентилятором радиального типа (турбинка) выходит за пределы площади печатной платы — непривычно компактной для GPU такой производительности, пусть даже с 256-битной шиной памяти. Тепло от графического процессора отводит простой алюминиевый радиатор с медной вставкой в основании, а чипы памяти и транзисторы преобразователя напряжения прижаты к раме кулера через термопрокладки.
⇡#Плата
Микросхемы оперативной памяти на плате расположены с лицевой стороны. Восемь штук при общем объеме 8 Гбайт означает, что мы имеем дело не только с более скоростной, чем прежде, разновидностью GDDR5, но и с более емкой — 8 Гбит на чип.
Что касается питания компонентов, то в референсном Radeon RX 480 используется шестифазная схема: 5 фаз для GPU и одна — для видеопамяти. Для дополнительного питания PCI Express плате хватает одного шестиконтактного разъема.
Следуя примеру видеокарт на процессоре Fiji, Radeon RX 480 не имеет выхода DVI и вместо этого оснащен тремя разъемами DisplayPort и одним HDMI.
⇡#Тестовый стенд, методика тестирования
| Конфигурация тестовых стендов |
|---|
| CPU |
Intel Core i7-5960X @ 4 ГГц (100 × 40) |
| Материнская плата |
ASUS RAMPAGE V EXTREME |
| Оперативная память |
Corsair Vengeance LPX, 2133 МГц, 4 × 4 Гбайт |
| ПЗУ |
Intel SSD 520 240 Гбайт + Crucial M550 512 Гбайт |
| Блок питания |
Corsair AX1200i, 1200 Вт |
| Система охлаждения CPU |
Thermalright Archon |
| Корпус |
CoolerMaster Test Bench V1.0 |
| Монитор |
NEC EA244UHD |
| Операционная система |
Windows 10 Pro X64 |
| ПО для GPU AMD |
Radeon Software Crimson Edition 16.6.1 Non-WHQL
RX 480: Radeon Software Crimson Edition 16.6.2 Non-WHQL
|
| ПО для GPU NVIDIA |
GeForce Game Ready Driver 368.39 WHQL |
Энергосберегающие технологии CPU во всех тестах отключены. В настройках драйвера NVIDIA в качестве процессора для вычисления PhysX выбирается CPU. В меню драйвера AMD настройка Tesselation переводится из состояния AMD Optimized в Use application settings.
| Бенчмарки: игры |
|---|
| Игра (в порядке даты выхода) |
API |
Настройки |
Полноэкранное сглаживание |
| 1920 × 1080 / 2560 × 1440 |
3840 × 2160 |
| Crysis 3 + FRAPS |
DirectX 11 |
Макс. качество. Начало миссии Swamp |
MSAA 4x |
Выкл. |
| Metro: Last Light, встроенный бенчмарк |
Макс. качество |
SSAA 4x |
| Battlefield 4 + FRAPS |
Макс. качество. Начало миссии Tashgar |
MSAA 4x + FXAA |
| Thief, встроенный бенчмарк |
Макс. качество |
SSAA 4x + FXAA |
| GRID Autosport, встроенный бенчмарк |
Макс. качество |
MSAA 4x |
| Middle-Earth: Shadow of Mordor, встроенный бенчмарк |
Макс. качество |
Не поддерживается |
| Alien: Isolation, встроенный бенчмарк |
Макс. качество |
SMAA T2X |
| Sid Meier's Civilization: Beyond Earth, встроенный бенчмарк |
Макс. качество |
SMAA T2X |
| Total War: Attila, встроенный бенчмарк |
Макс. качество |
MSAA 4x |
| GTA V, встроенный бенчмарк |
Макс. качество |
MSAA 4x + FXAA |
| Rise of the Tomb Raider, встроенный бенчмарк |
DirectX 12 |
Макс. качество, VXAO выкл. |
SSAA 4x |
| Far Cry Primal, встроенный бенчмарк |
DirectX 11 |
Макс. качество |
SMAA |
| Tom Clancy's The Division, встроенный бенчмарк |
Макс. Качество, HFTS выкл. |
SMAA 1x High |
| DOOM + FRAPS |
OpenGL |
Макс. Качество. Миссия Foundry |
TSSAA 8TX |
| Бенчмарки: вычисления |
|---|
| Программа |
Настройки |
| DXVA Checker |
Decode benchmark. H.264, H.265. Файлы 1920 × 1080p (битрейт видео ~3000 Кбит/с), 3840 × 2160p (битрейт видео ~7500 Кбит/с). Microsoft H264 Video Decoder, Microsoft H265 Video Decoder, ускорение на аппаратном кодеке GPU (DXVA2) |
| LuxMark 3.1 X64 |
Сцена Hotel Lobby (Complex Benchmark) |
| Sony Vegas Pro 13 |
Бенчмарк Sony для Vegas Pro 11, продолжительность — 65 с, рендеринг в XDCAM EX, 1920 × 1080@24p |
| CompuBench CL Desktop Edition X64, Ocean Surface Simulation |
— |
| CompuBench CL Desktop Edition X64, Particle Simulation – 64K |
— |
| SiSoftware Sandra 2016, Scientific Analysis |
Open CL, FP32/FP64 |
Участники тестирования
В тестировании производительности приняли участие следующие видеокарты:
⇡#Производительность: 3DMark
⇡#Производительность: игры
⇡#1920 × 1080, 2560 × 1440
| 1920 × 1080 |
|---|
|
Полноэкранное сглаживание |
AMD Radeon RX 480 (1266/8000 МГц, 8 Гбайт) |
AMD Radeon R9 380X (970/5700 МГц, 4 Гбайт) |
AMD Radeon R9 390 (1000/6000 МГц, 8 Гбайт) |
AMD Radeon R9 390X (1050/6000 МГц, 8 Гбайт) |
AMD Radeon R9 Fury (1000/1000 МГц, 4 Гбайт) |
NVIDIA GeForce GTX 960 (1126/7010 МГц, 2 Гбайт) |
NVIDIA GeForce GTX 970 (1050/7010 МГц, 4 Гбайт) |
NVIDIA GeForce GTX 980 (1126/7000 МГц, 4 Гбайт) |
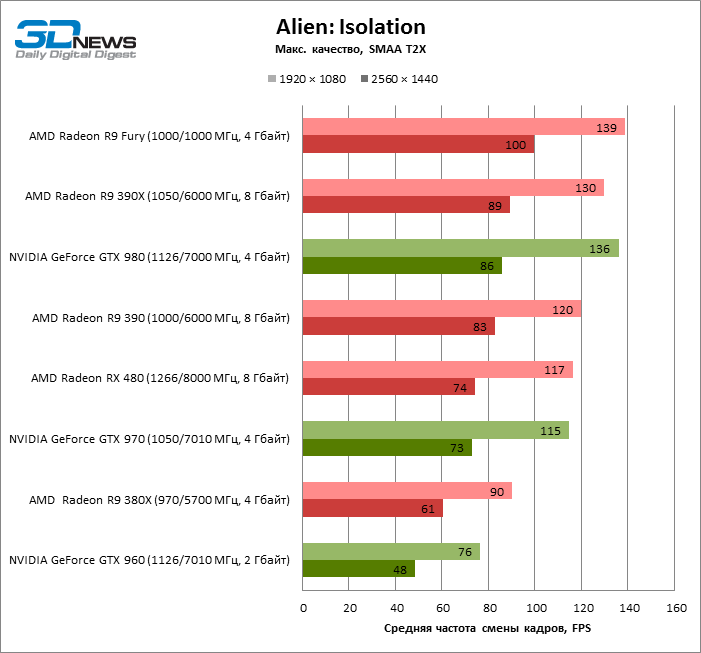
| Alien: Isolation |
SMAA T2X |
117 |
90 |
120 |
130 |
139 |
76 |
115 |
136 |
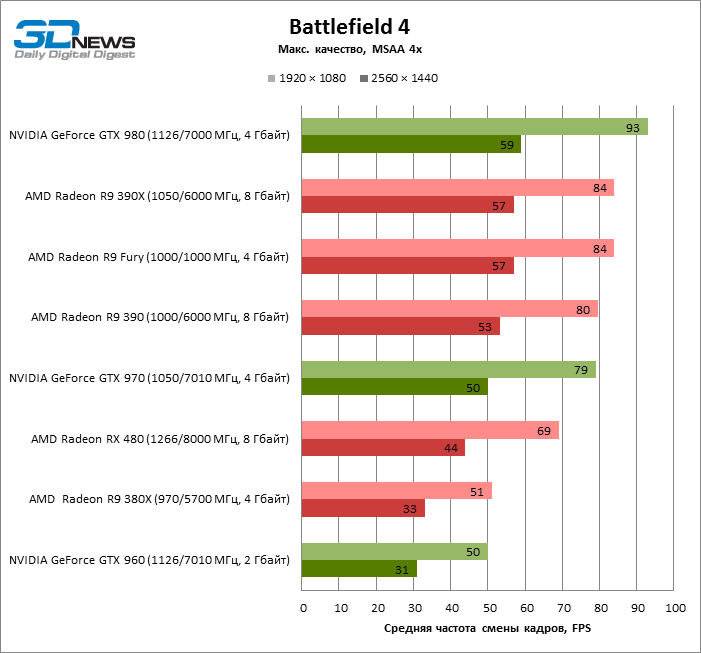
| Battlefield 4 |
MSAA 4x + FXAA |
69 |
51 |
80 |
84 |
84 |
50 |
79 |
93 |
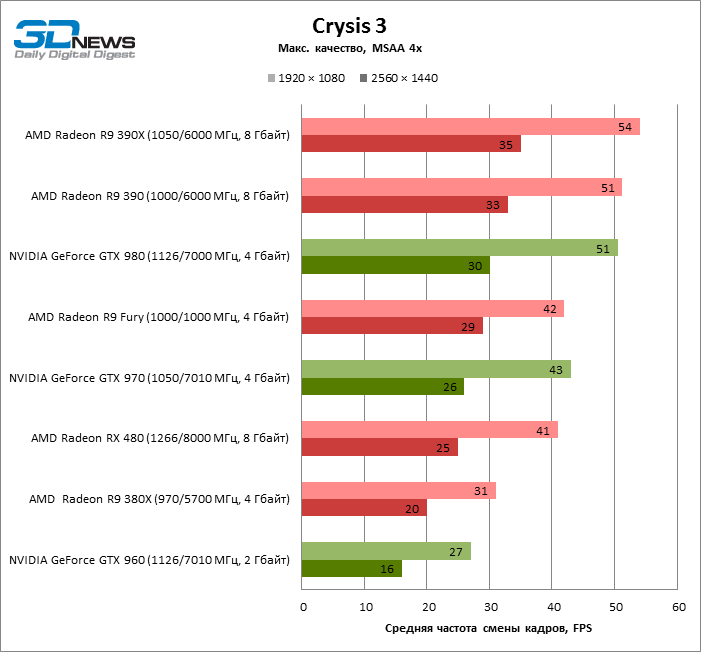
| Crysis 3 |
MSAA 4x |
41 |
31 |
51 |
54 |
42 |
27 |
43 |
51 |
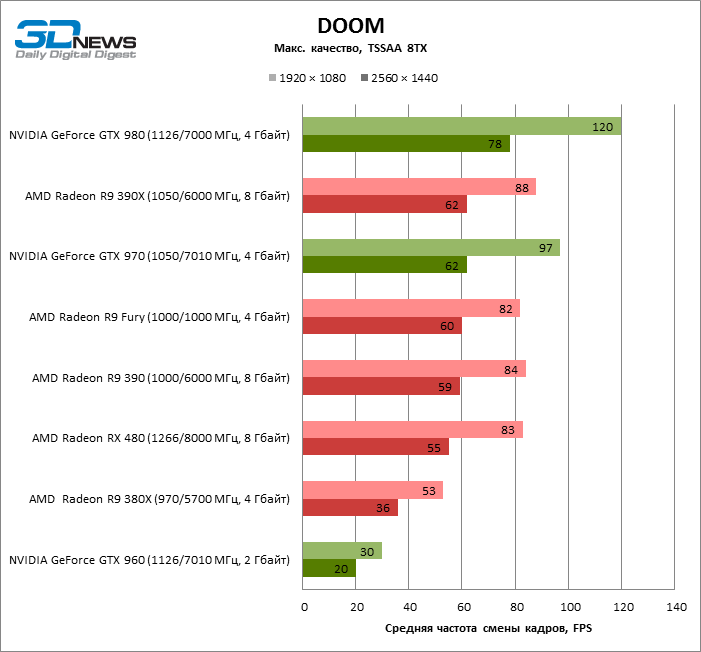
| DOOM |
TSSAA 8TX |
83 |
53 |
84 |
88 |
82 |
30 |
97 |
120 |
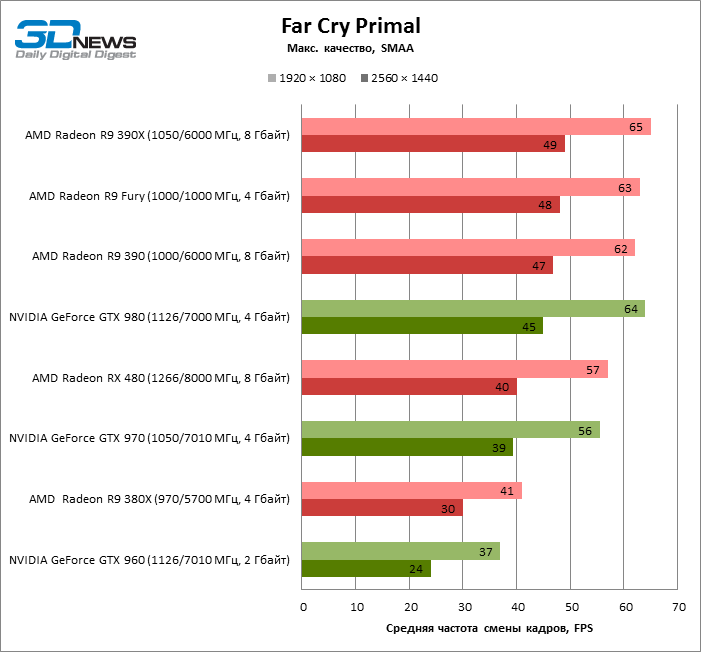
| Far Cry Primal |
SMAA |
57 |
41 |
62 |
65 |
63 |
37 |
56 |
64 |
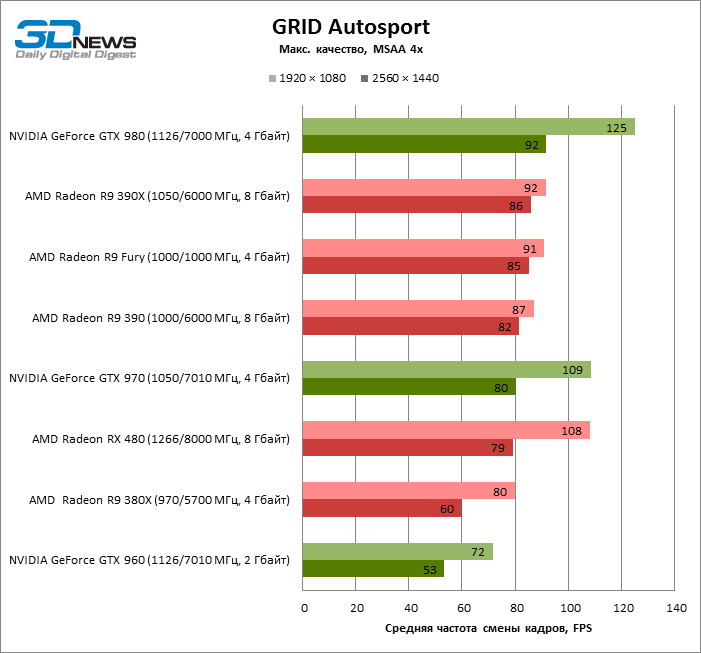
| GRID Autosport |
MSAA 4x |
108 |
80 |
87 |
92 |
91 |
72 |
109 |
125 |
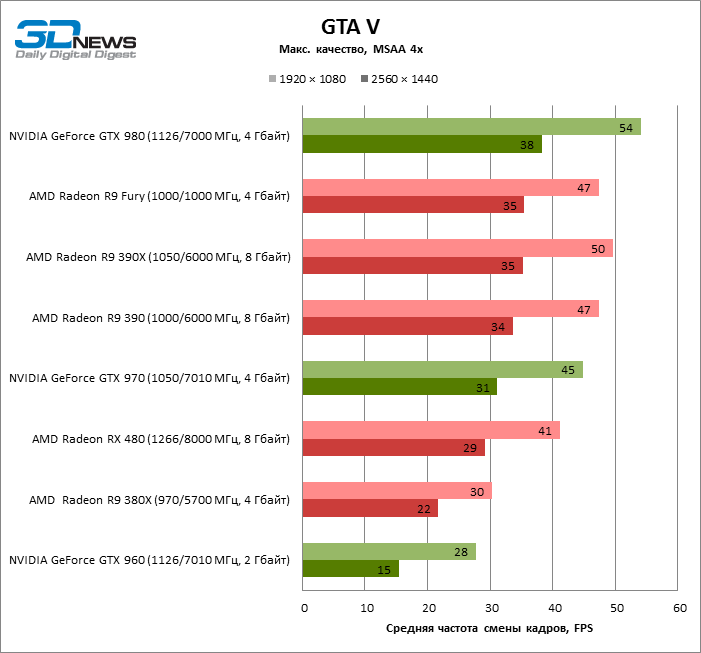
| GTA V |
MSAA 4x + FXAA |
41 |
30 |
47 |
50 |
47 |
28 |
45 |
54 |
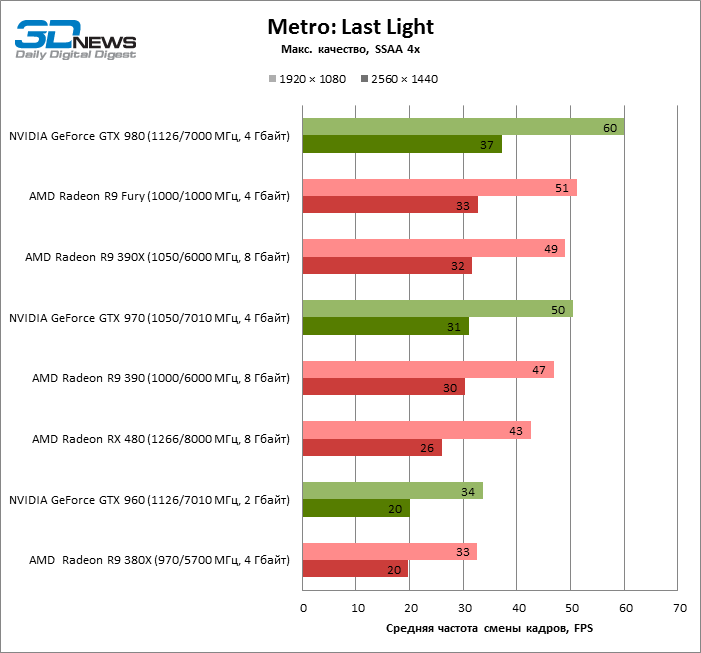
| Metro: Last Light |
SSAA 4x |
43 |
33 |
47 |
49 |
51 |
34 |
50 |
60 |
| Middle-Earth: Shadow of Mordor |
Не поддерживается |
79 |
57 |
64 |
88 |
85 |
31 |
72 |
83 |
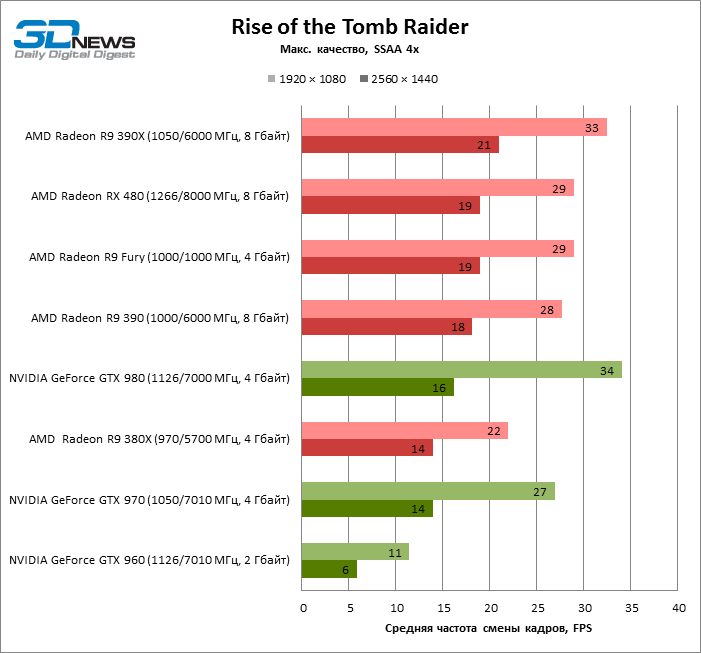
| Rise of the Tomb Raider |
SSAA 4x |
29 |
22 |
28 |
33 |
29 |
11 |
27 |
34 |
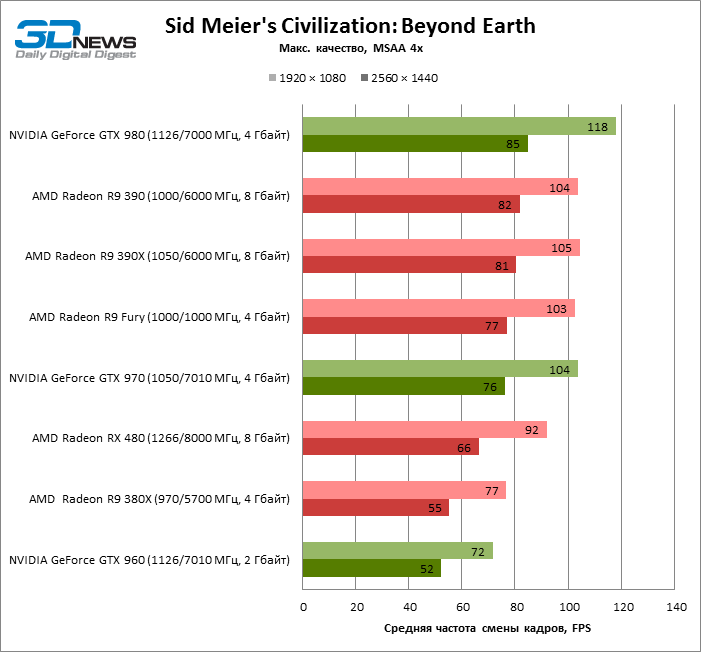
| Sid Meier's Civilization: Beyond Earth |
SMAA T2X |
92 |
77 |
104 |
105 |
103 |
72 |
104 |
118 |
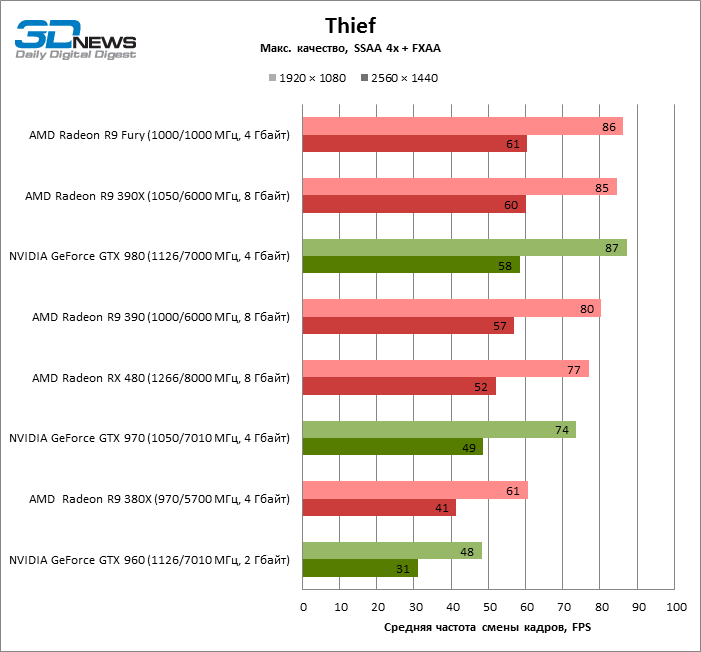
| Thief |
SSAA 4x + FXAA |
77 |
61 |
80 |
85 |
86 |
48 |
74 |
87 |
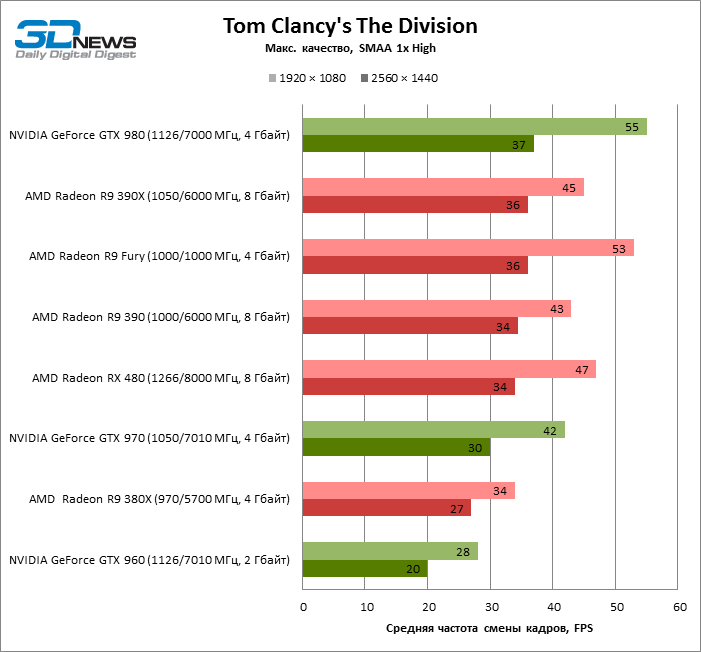
| Tom Clancy's The Division |
SMAA 1x High |
47 |
34 |
43 |
45 |
53 |
28 |
42 |
55 |
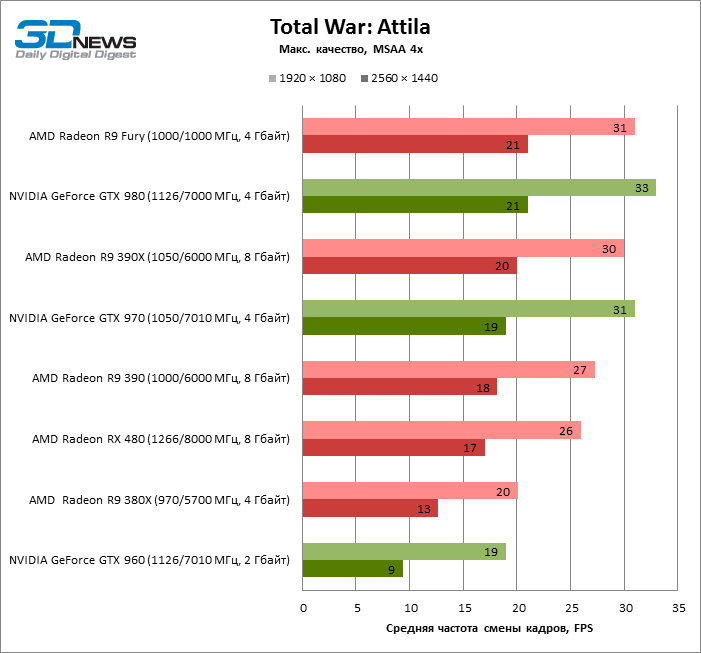
| Total War: Attila |
MSAA 4x |
26 |
20 |
27 |
30 |
31 |
19 |
31 |
33 |
|
Полноэкранное сглаживание |
AMD Radeon RX 480 (1266/8000 МГц, 8 Гбайт) |
AMD Radeon R9 380X (970/5700 МГц, 4 Гбайт) |
AMD Radeon R9 390 (1000/6000 МГц, 8 Гбайт) |
AMD Radeon R9 390X (1050/6000 МГц, 8 Гбайт) |
AMD Radeon R9 Fury (1000/1000 МГц, 4 Гбайт) |
NVIDIA GeForce GTX 960 (1126/7010 МГц, 2 Гбайт) |
NVIDIA GeForce GTX 970 (1050/7010 МГц, 4 Гбайт) |
NVIDIA GeForce GTX 980 (1126/7000 МГц, 4 Гбайт) |
| Alien: Isolation |
SMAA T2X |
100% |
77% |
103% |
111% |
119% |
66% |
99% |
117% |
| Battlefield 4 |
MSAA 4x + FXAA |
100% |
74% |
115% |
122% |
122% |
72% |
114% |
135% |
| Crysis 3 |
MSAA 4x |
100% |
76% |
125% |
132% |
102% |
66% |
105% |
123% |
| DOOM |
TSSAA 8TX |
100% |
64% |
101% |
106% |
99% |
36% |
117% |
145% |
| Far Cry Primal |
SMAA |
100% |
72% |
109% |
114% |
111% |
65% |
98% |
112% |
| GRID Autosport |
MSAA 4x |
100% |
74% |
80% |
85% |
84% |
66% |
101% |
116% |
| GTA V |
MSAA 4x + FXAA |
100% |
74% |
115% |
121% |
115% |
67% |
109% |
132% |
| Metro: Last Light |
SSAA 4x |
100% |
77% |
110% |
115% |
120% |
79% |
118% |
141% |
| Middle-Earth: Shadow of Mordor |
Не поддерживается |
100% |
72% |
81% |
111% |
108% |
39% |
91% |
105% |
| Rise of the Tomb Raider |
SSAA 4x |
100% |
76% |
96% |
112% |
100% |
40% |
93% |
118% |
| Sid Meier's Civilization: Beyond Earth |
SMAA T2X |
100% |
84% |
113% |
114% |
112% |
78% |
113% |
129% |
| Thief |
SSAA 4x + FXAA |
100% |
79% |
104% |
110% |
112% |
63% |
96% |
113% |
| Tom Clancy's The Division |
SMAA 1x High |
100% |
72% |
91% |
96% |
113% |
60% |
89% |
117% |
| Total War: Attila |
MSAA 4x |
100% |
77% |
105% |
115% |
119% |
73% |
119% |
127% |
| Макс. |
|
|
84% |
125% |
132% |
122% |
79% |
119% |
145% |
| Среднее |
|
|
75% |
104% |
112% |
110% |
62% |
104% |
123% |
| Мин. |
|
|
64% |
80% |
85% |
84% |
36% |
89% |
105% |
| 2560 × 1440 |
|---|
|
Полноэкранное сглаживание |
AMD Radeon RX 480 (1266/8000 МГц, 8 Гбайт) |
AMD Radeon R9 380X (970/5700 МГц, 4 Гбайт) |
AMD Radeon R9 390 (1000/6000 МГц, 8 Гбайт) |
AMD Radeon R9 390X (1050/6000 МГц, 8 Гбайт) |
AMD Radeon R9 Fury (1000/1000 МГц, 4 Гбайт) |
NVIDIA GeForce GTX 960 (1126/7010 МГц, 2 Гбайт) |
NVIDIA GeForce GTX 970 (1050/7010 МГц, 4 Гбайт) |
NVIDIA GeForce GTX 980 (1126/7000 МГц, 4 Гбайт) |
| Alien: Isolation |
SMAA T2X |
74 |
61 |
83 |
89 |
100 |
48 |
73 |
86 |
| Battlefield 4 |
MSAA 4x + FXAA |
44 |
33 |
53 |
57 |
57 |
31 |
50 |
59 |
| Crysis 3 |
MSAA 4x |
25 |
20 |
33 |
35 |
29 |
16 |
26 |
30 |
| DOOM |
TSSAA 8TX |
55 |
36 |
59 |
62 |
60 |
20 |
62 |
78 |
| Far Cry Primal |
SMAA |
40 |
30 |
47 |
49 |
48 |
24 |
39 |
45 |
| GRID Autosport |
MSAA 4x |
79 |
60 |
82 |
86 |
85 |
53 |
80 |
92 |
| GTA V |
MSAA 4x + FXAA |
29 |
22 |
34 |
35 |
35 |
15 |
31 |
38 |
| Metro: Last Light |
SSAA 4x |
26 |
20 |
30 |
32 |
33 |
20 |
31 |
37 |
| Middle-Earth: Shadow of Mordor |
Не поддерживается |
53 |
40 |
52 |
63 |
61 |
21 |
49 |
58 |
| Rise of the Tomb Raider |
SSAA 4x |
19 |
14 |
18 |
21 |
19 |
6 |
14 |
16 |
| Sid Meier's Civilization: Beyond Earth |
SMAA T2X |
66 |
55 |
82 |
81 |
77 |
52 |
76 |
85 |
| Thief |
SSAA 4x + FXAA |
52 |
41 |
57 |
60 |
61 |
31 |
49 |
58 |
| Tom Clancy's The Division |
SMAA 1x High |
34 |
27 |
34 |
36 |
36 |
20 |
30 |
37 |
| Total War: Attila |
MSAA 4x |
17 |
13 |
18 |
20 |
21 |
9 |
19 |
21 |
|
Полноэкранное сглаживание |
AMD Radeon RX 480 (1266/8000 МГц, 8 Гбайт) |
AMD Radeon R9 380X (970/5700 МГц, 4 Гбайт) |
AMD Radeon R9 390 (1000/6000 МГц, 8 Гбайт) |
AMD Radeon R9 390X (1050/6000 МГц, 8 Гбайт) |
AMD Radeon R9 Fury (1000/1000 МГц, 4 Гбайт) |
NVIDIA GeForce GTX 960 (1126/7010 МГц, 2 Гбайт) |
NVIDIA GeForce GTX 970 (1050/7010 МГц, 4 Гбайт) |
NVIDIA GeForce GTX 980 (1126/7000 МГц, 4 Гбайт) |
| Alien: Isolation |
SMAA T2X |
100% |
82% |
111% |
120% |
134% |
65% |
98% |
115% |
| Battlefield 4 |
MSAA 4x + FXAA |
100% |
75% |
121% |
130% |
130% |
70% |
114% |
134% |
| Crysis 3 |
MSAA 4x |
100% |
80% |
132% |
140% |
116% |
64% |
104% |
120% |
| DOOM |
TSSAA 8TX |
100% |
65% |
108% |
113% |
109% |
36% |
113% |
142% |
| Far Cry Primal |
SMAA |
100% |
75% |
117% |
123% |
120% |
60% |
99% |
113% |
| GRID Autosport |
MSAA 4x |
100% |
76% |
103% |
109% |
108% |
68% |
102% |
116% |
| GTA V |
MSAA 4x + FXAA |
100% |
75% |
116% |
121% |
122% |
53% |
107% |
132% |
| Metro: Last Light |
SSAA 4x |
100% |
76% |
116% |
122% |
125% |
77% |
119% |
143% |
| Middle-Earth: Shadow of Mordor |
Не поддерживается |
100% |
75% |
99% |
118% |
115% |
39% |
92% |
109% |
| Rise of the Tomb Raider |
SSAA 4x |
100% |
74% |
96% |
111% |
100% |
31% |
74% |
85% |
| Sid Meier's Civilization: Beyond Earth |
SMAA T2X |
100% |
83% |
124% |
121% |
116% |
79% |
115% |
128% |
| Thief |
SSAA 4x + FXAA |
100% |
79% |
109% |
115% |
116% |
60% |
93% |
112% |
| Tom Clancy's The Division |
SMAA 1x High |
100% |
79% |
101% |
106% |
106% |
59% |
88% |
109% |
| Total War: Attila |
MSAA 4x |
100% |
75% |
107% |
118% |
124% |
55% |
112% |
124% |
| Макс. |
|
|
83% |
132% |
140% |
134% |
79% |
119% |
143% |
| Среднее |
|
|
76% |
111% |
119% |
117% |
58% |
102% |
120% |
| Мин. |
|
|
65% |
96% |
106% |
100% |
31% |
74% |
85% |
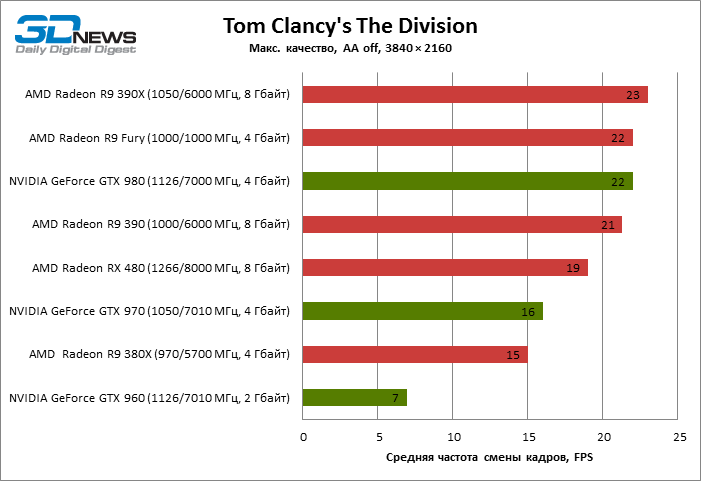
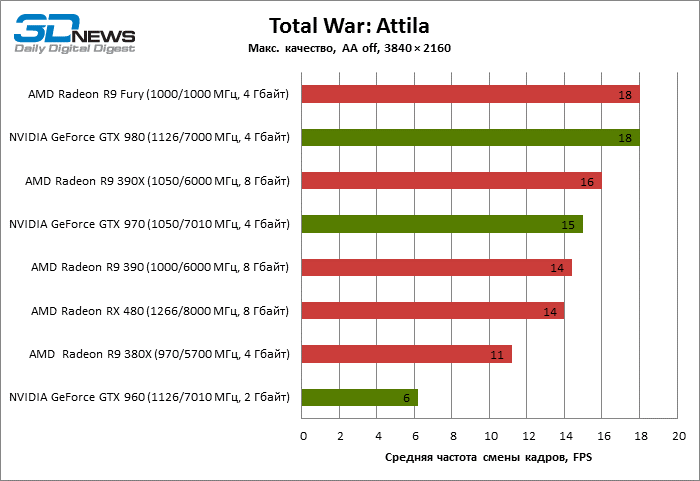
⇡#3840 × 2160
| 3840 × 2160 |
|---|
|
Полноэкранное сглаживание |
AMD Radeon RX 480 (1266/8000 МГц, 8 Гбайт) |
AMD Radeon R9 380X (970/5700 МГц, 4 Гбайт) |
AMD Radeon R9 390 (1000/6000 МГц, 8 Гбайт) |
AMD Radeon R9 390X (1050/6000 МГц, 8 Гбайт) |
AMD Radeon R9 Fury (1000/1000 МГц, 4 Гбайт) |
NVIDIA GeForce GTX 960 (1126/7010 МГц, 2 Гбайт) |
NVIDIA GeForce GTX 970 (1050/7010 МГц, 4 Гбайт) |
NVIDIA GeForce GTX 980 (1126/7000 МГц, 4 Гбайт) |
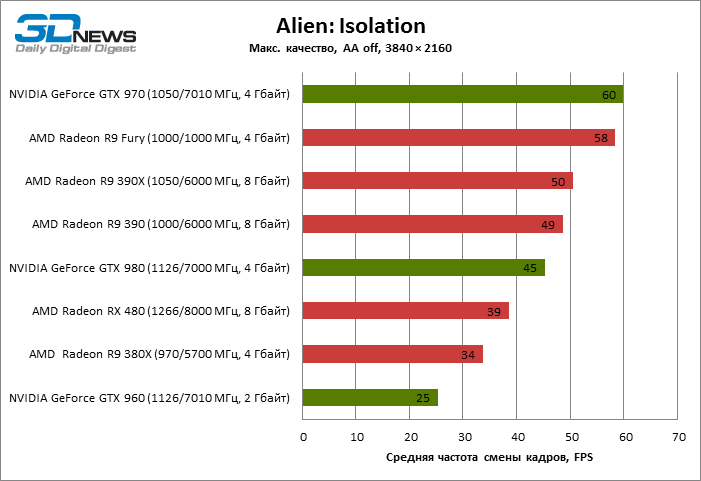
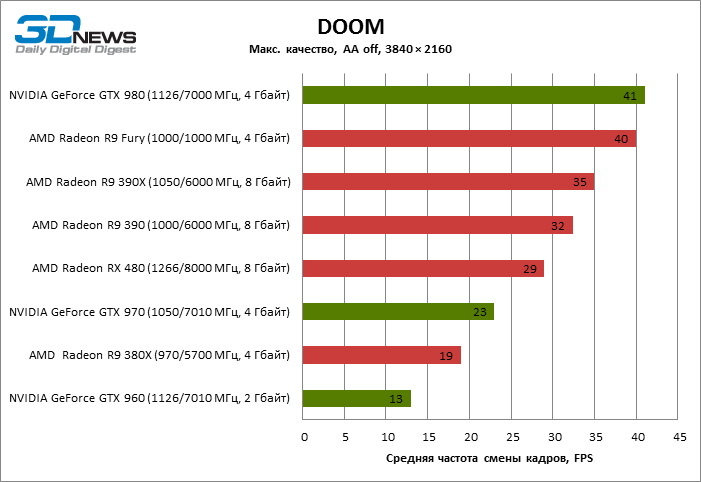
| Alien: Isolation |
Выкл. |
39 |
34 |
49 |
50 |
58 |
25 |
60 |
45 |
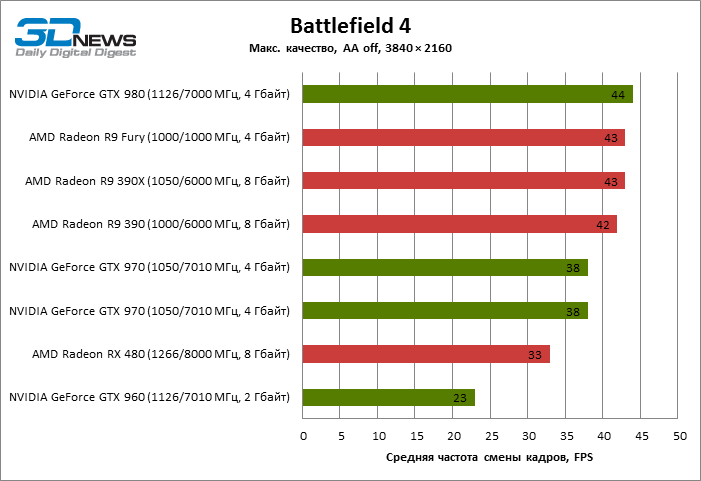
| Battlefield 4 |
33 |
26 |
42 |
43 |
43 |
23 |
38 |
44 |
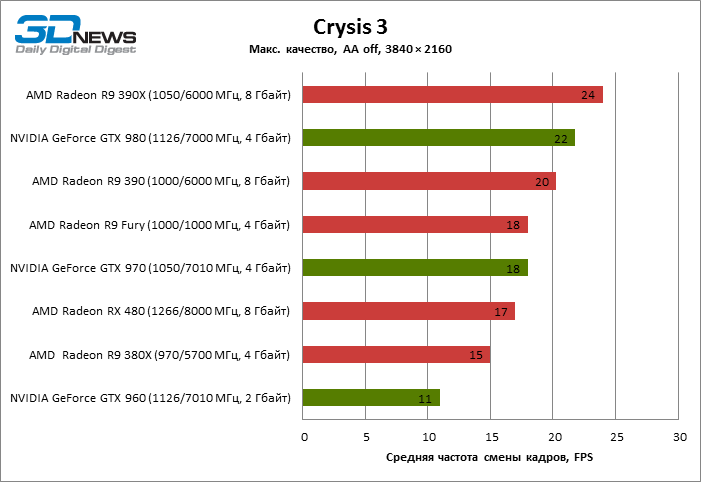
| Crysis 3 |
17 |
15 |
20 |
24 |
18 |
11 |
18 |
22 |
| DOOM |
29 |
19 |
32 |
35 |
40 |
13 |
23 |
41 |
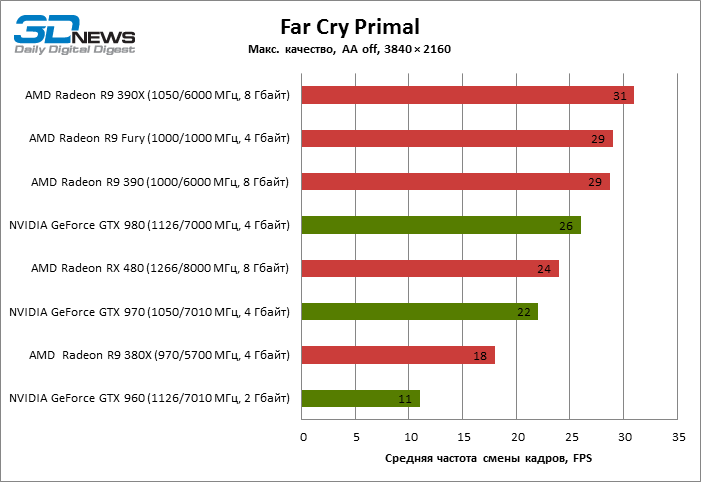
| Far Cry Primal |
24 |
18 |
29 |
31 |
29 |
11 |
22 |
26 |
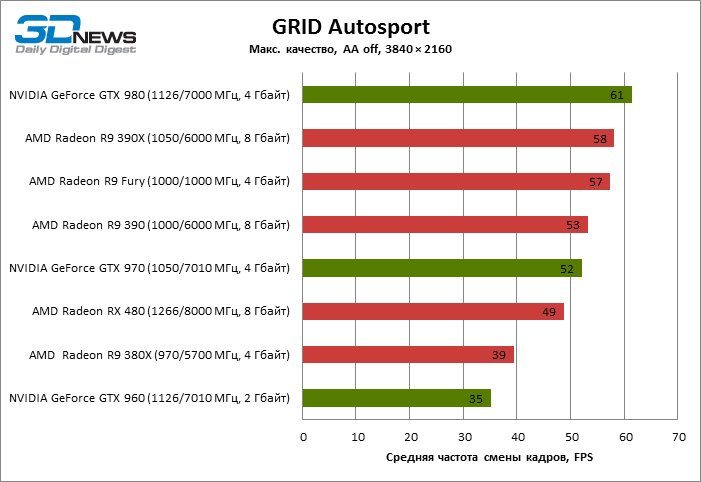
| GRID Autosport |
49 |
39 |
53 |
58 |
57 |
35 |
52 |
61 |
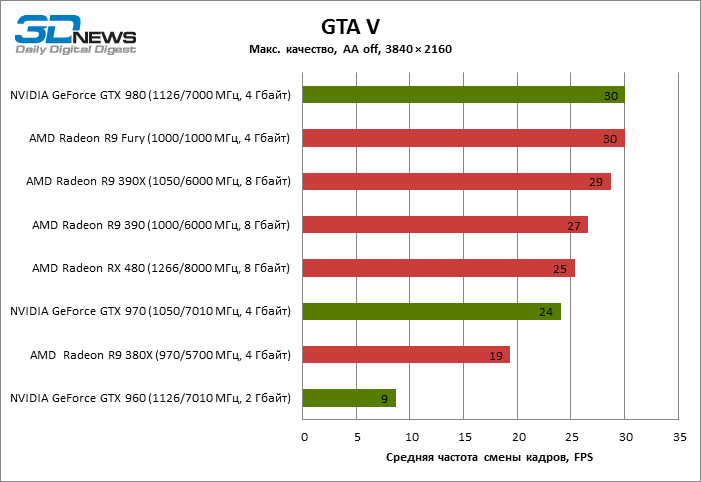
| GTA V |
25 |
19 |
27 |
29 |
30 |
9 |
24 |
30 |
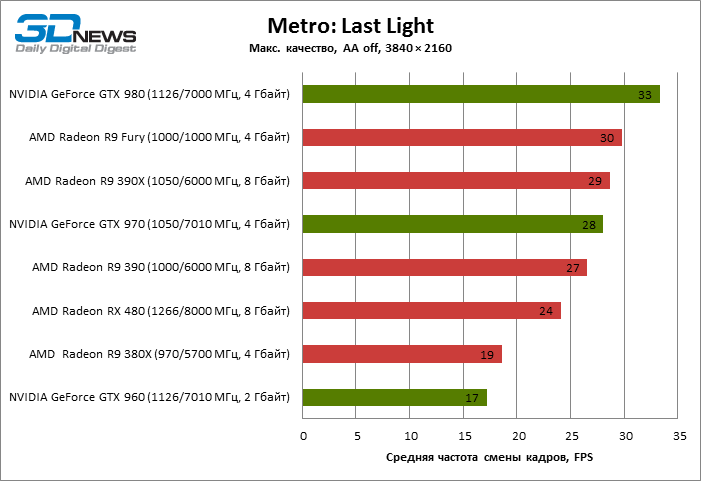
| Metro: Last Light |
24 |
19 |
27 |
29 |
30 |
17 |
28 |
33 |
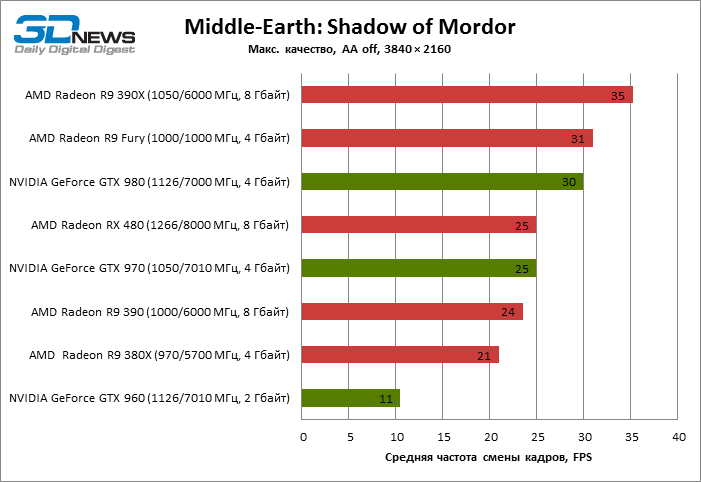
| Middle-Earth: Shadow of Mordor |
25 |
21 |
24 |
35 |
31 |
11 |
25 |
30 |
| Rise of the Tomb Raider |
21 |
15 |
19 |
26 |
22 |
4 |
19 |
19 |
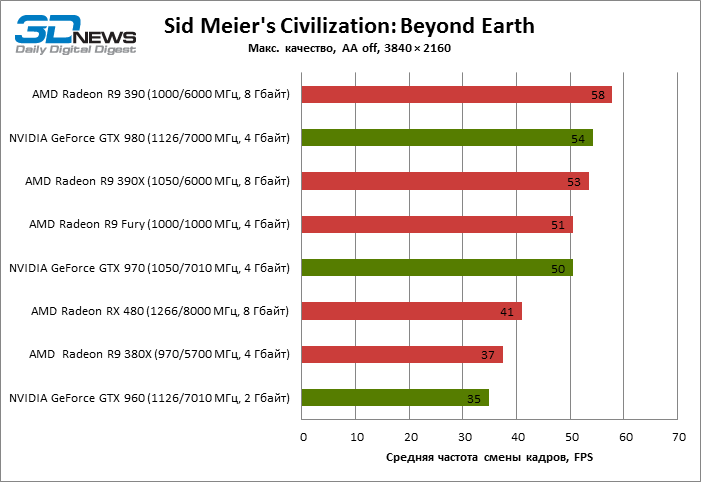
| Sid Meier's Civilization: Beyond Earth |
41 |
37 |
58 |
53 |
51 |
35 |
50 |
54 |
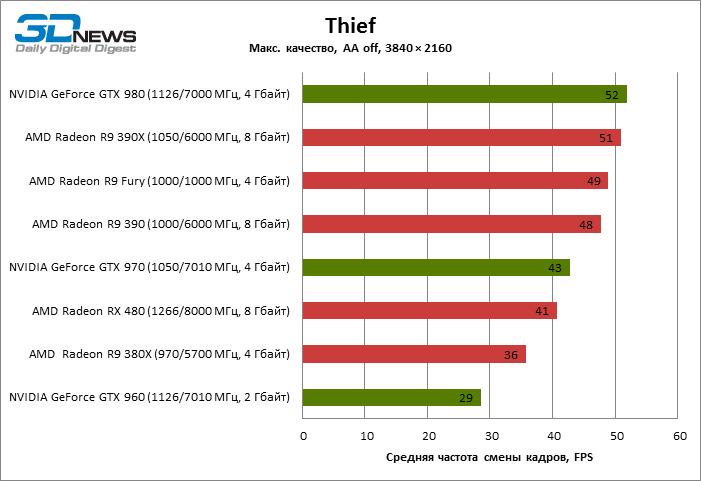
| Thief |
41 |
36 |
48 |
51 |
49 |
29 |
43 |
52 |
| Tom Clancy's The Division |
19 |
15 |
21 |
23 |
22 |
7 |
16 |
22 |
| Total War: Attila |
14 |
11 |
14 |
16 |
18 |
6 |
15 |
18 |
|
Полноэкранное сглаживание |
AMD Radeon RX 480 (1266/8000 МГц, 8 Гбайт) |
AMD Radeon R9 380X (970/5700 МГц, 4 Гбайт) |
AMD Radeon R9 390 (1000/6000 МГц, 8 Гбайт) |
AMD Radeon R9 390X (1050/6000 МГц, 8 Гбайт) |
AMD Radeon R9 Fury (1000/1000 МГц, 4 Гбайт) |
NVIDIA GeForce GTX 960 (1126/7010 МГц, 2 Гбайт) |
NVIDIA GeForce GTX 970 (1050/7010 МГц, 4 Гбайт) |
NVIDIA GeForce GTX 980 (1126/7000 МГц, 4 Гбайт) |
| Alien: Isolation |
Выкл. |
100% |
87% |
126% |
131% |
151% |
66% |
155% |
117% |
| Battlefield 4 |
100% |
79% |
127% |
130% |
130% |
70% |
115% |
133% |
| Crysis 3 |
100% |
88% |
119% |
141% |
106% |
65% |
106% |
128% |
| DOOM |
100% |
66% |
112% |
121% |
138% |
45% |
79% |
141% |
| Far Cry Primal |
100% |
75% |
120% |
129% |
121% |
46% |
92% |
108% |
| GRID Autosport |
100% |
81% |
109% |
119% |
118% |
72% |
107% |
126% |
| GTA V |
100% |
76% |
105% |
113% |
118% |
34% |
95% |
118% |
| Metro: Last Light |
100% |
77% |
110% |
119% |
124% |
71% |
116% |
138% |
| Middle-Earth: Shadow of Mordor |
100% |
84% |
94% |
141% |
124% |
42% |
100% |
120% |
| Rise of the Tomb Raider |
100% |
71% |
93% |
121% |
105% |
20% |
89% |
89% |
| Sid Meier's Civilization: Beyond Earth |
100% |
92% |
141% |
130% |
123% |
85% |
123% |
132% |
| Thief |
100% |
88% |
117% |
125% |
120% |
70% |
105% |
128% |
| Tom Clancy's The Division |
100% |
79% |
112% |
121% |
116% |
37% |
84% |
116% |
| Total War: Attila |
100% |
80% |
103% |
114% |
129% |
44% |
107% |
129% |
| Макс. |
|
|
92% |
141% |
141% |
151% |
85% |
155% |
141% |
| Среднее |
|
|
80% |
113% |
126% |
123% |
55% |
105% |
123% |
| Мин. |
|
|
66% |
93% |
113% |
105% |
20% |
79% |
89% |
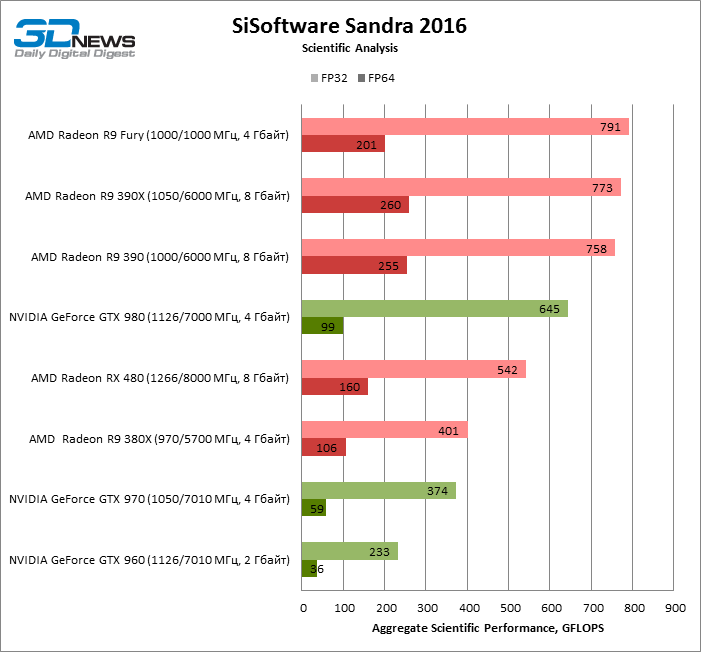
⇡#Производительность: вычисления
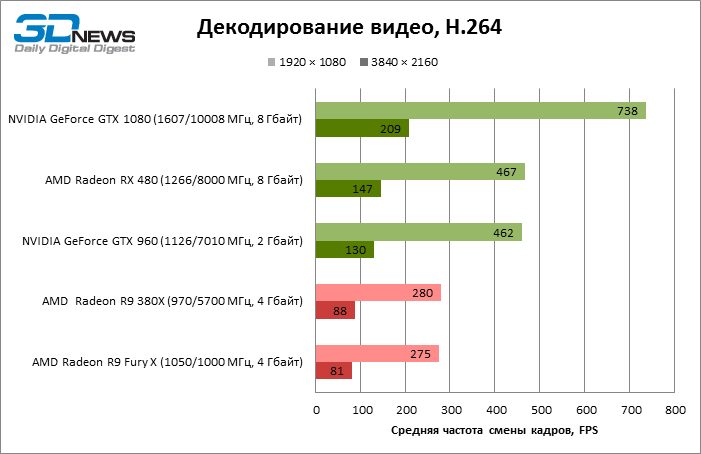
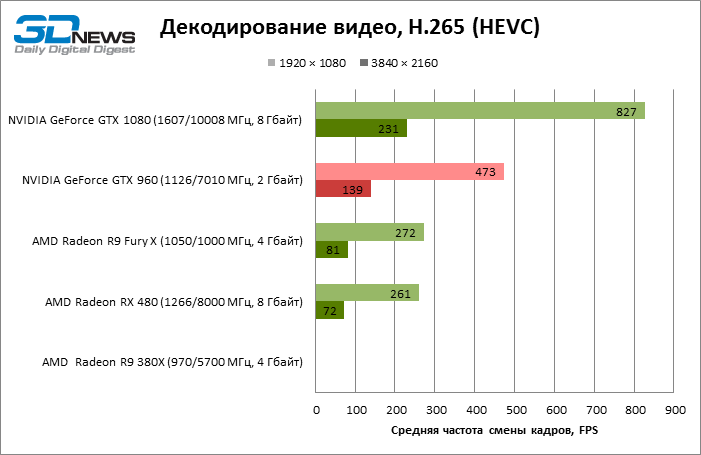
Декодирование видео (DXVA Checker, Decode Benchmark)
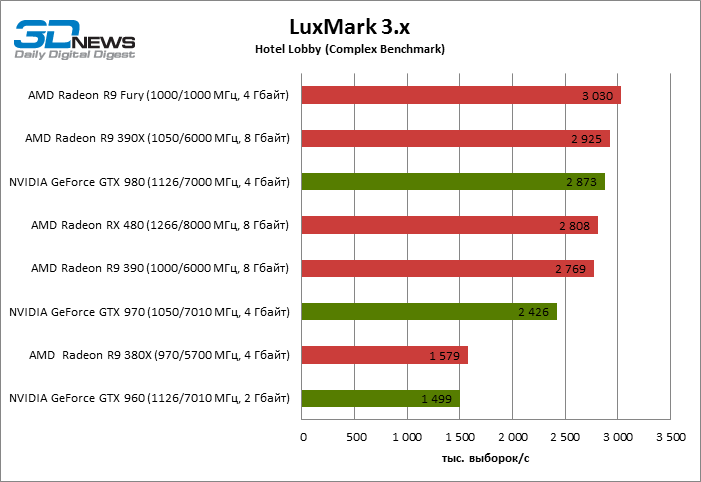
Luxmark 3.x: Hotel Lobby (Complex Benchmark)
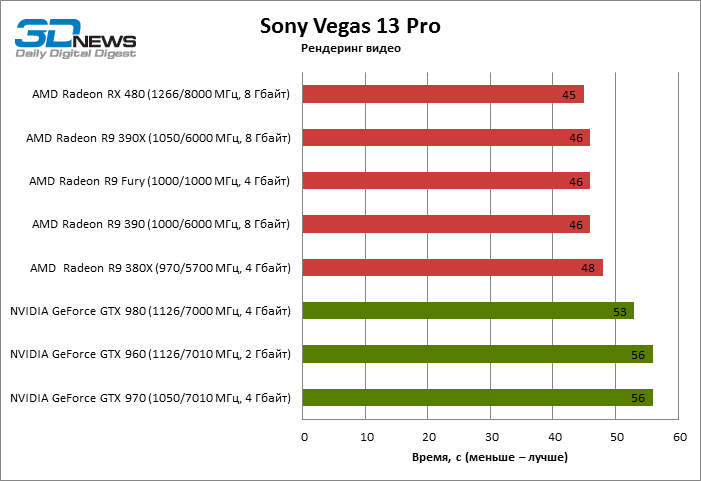
Sony Vegas Pro 13
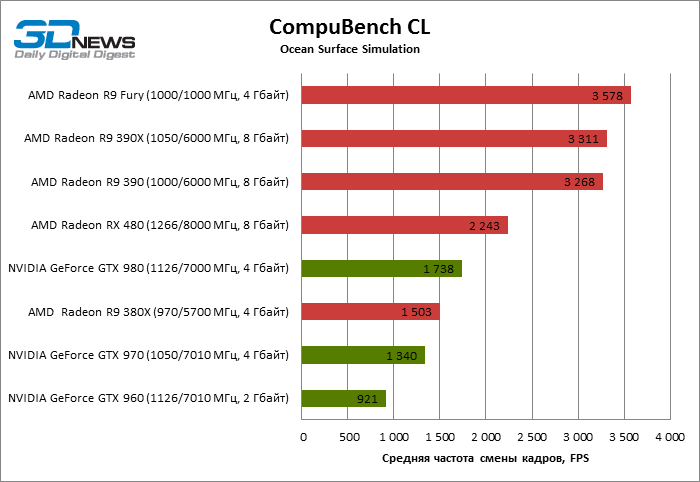
CompuBench CL: Ocean Surface Simulation
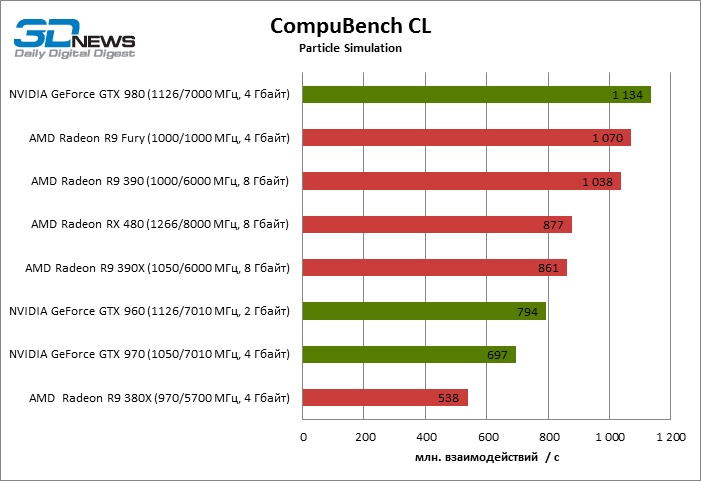
CompuBench CL: Particle Simulation
SiSoftware Sandra 2016: Scientific Analysis
⇡#Тактовые частоты, энергопотребление, температура, разгон
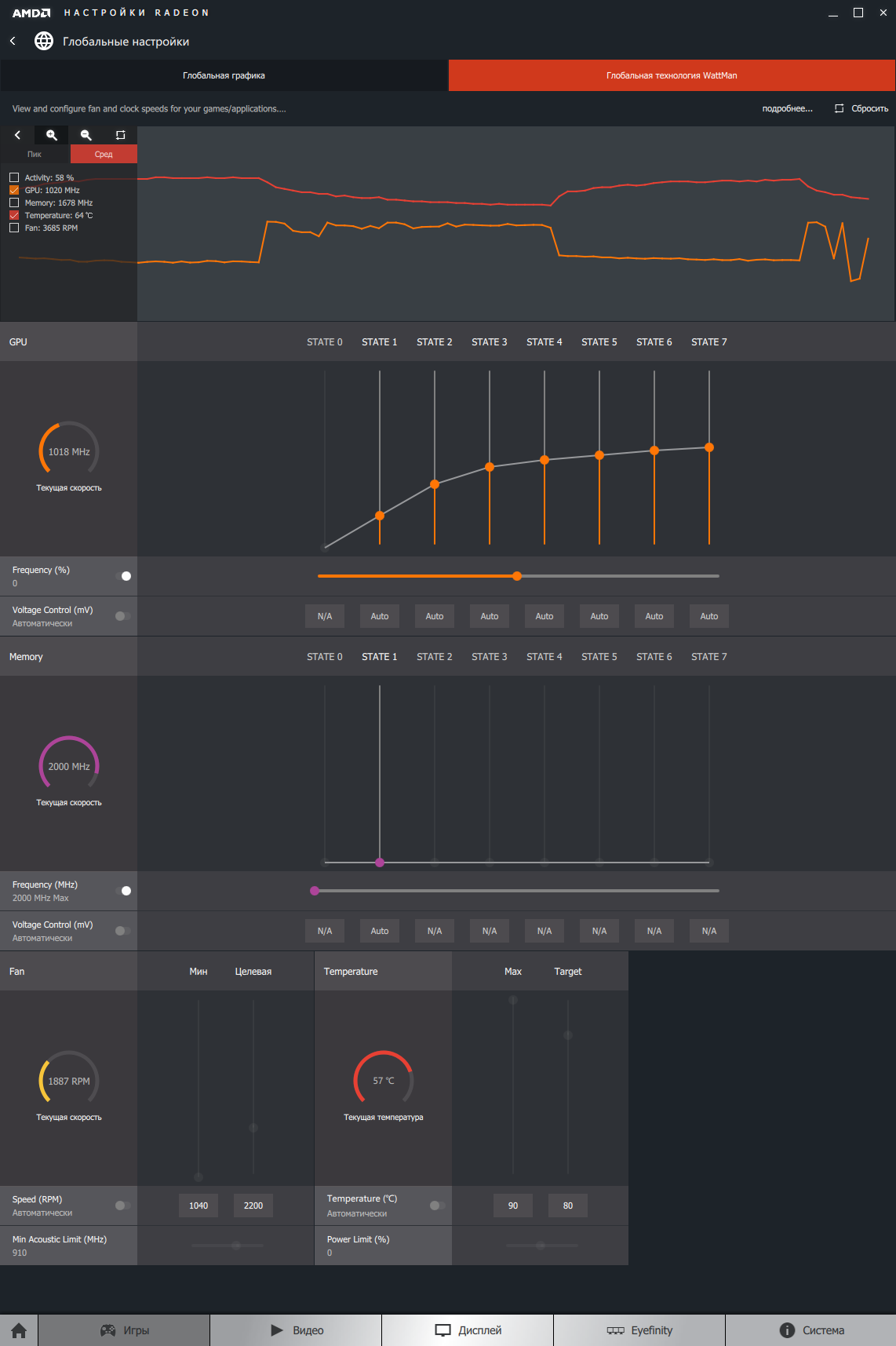
В пакете Radeon Software с поддержкой Polaris AMD ввела новый интерфейс для оверклокинга — WattMan, заменивший привычный Overdrive и несущий новые возможности для более гибкого и прямого управления всеми необходимыми параметрами.
В верхней части окна мы видим график, регистрирующий несколько переменных: частоты GPU и RAM, загрузку графического процессора, температуру GPU и скорость вращения турбины. Другие инструменты позволяют отдать приоритет охлаждению GPU или акустическому комфорту: для вентилятора устанавливается минимум и желаемый максимум скорости вращения, предельный уровень шума. Помимо целевой температуры, при достижении которой видеокарта начнет увеличивать обороты турбины, устанавливается температура троттлинга, вызывающая пропуск тактов GPU.
Наиболее важно то, что WattMan впервые дает возможность поднимать не только частоту видеопамяти, но и напряжение питания на чипах RAM, а для GPU произвольно меняется кривая соотношения частоты и напряжения.
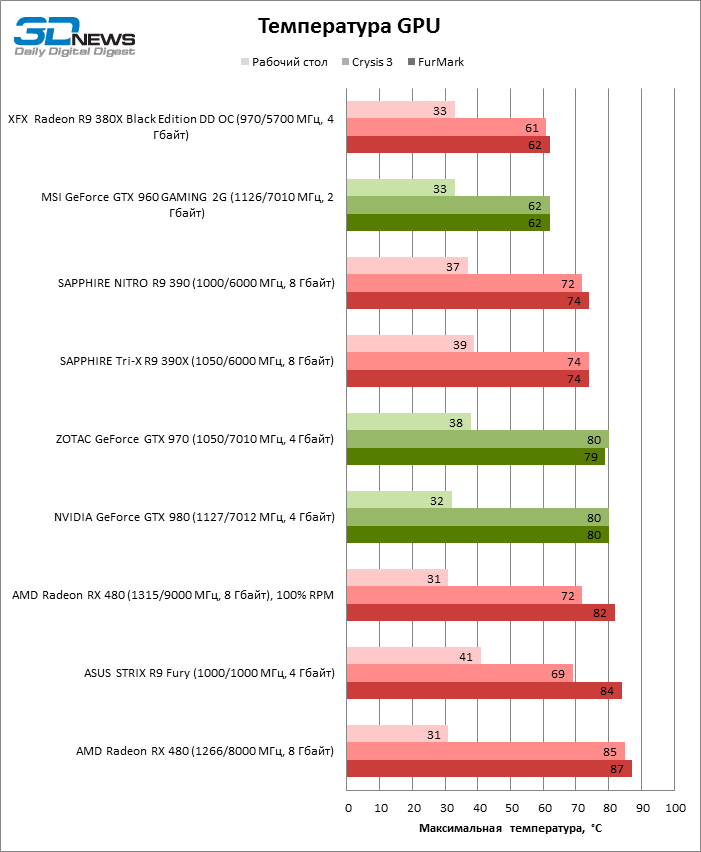
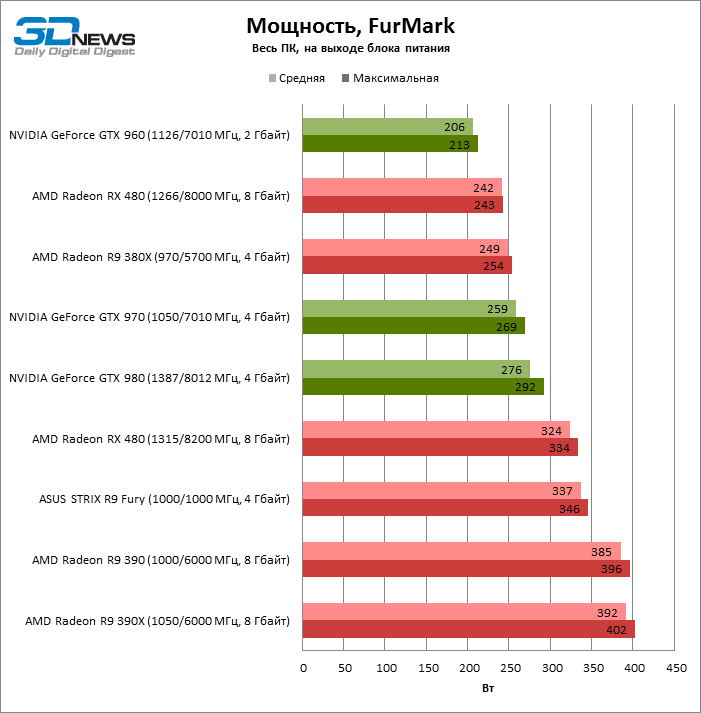
В штатном режиме Radeon RX 480 удерживает тактовую частоту GPU в диапазоне 1218-1240 МГц в большинстве игр, которые мы используем как бенчмарки. Напряжение на ядре колеблется в пределах 818-1087 мВ, а стандартное значение для чипов памяти — 1 В. Целевая температура по умолчанию составляет 85 °С, и референсный кулер поддерживает ее на скорости вращения 2200 об/мин. Нельзя сказать, что видеокарта при этом работает совсем тихо, но и не столь громко, как референсные образцы Radeon R9 290X или GeForce GTX 980 Ti.
В FurMark GPU вынужден сбросить частоты намного ниже номинальных значений — 697-685, сохраняя температуру в пределах 87 °С.
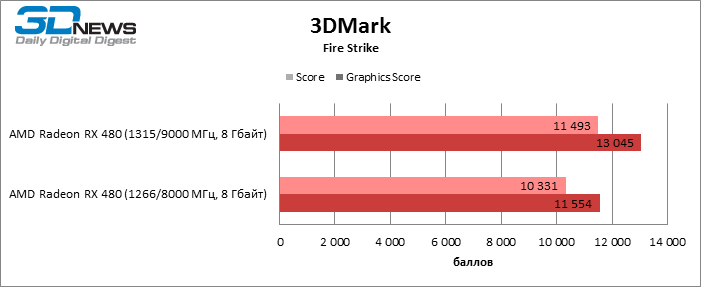
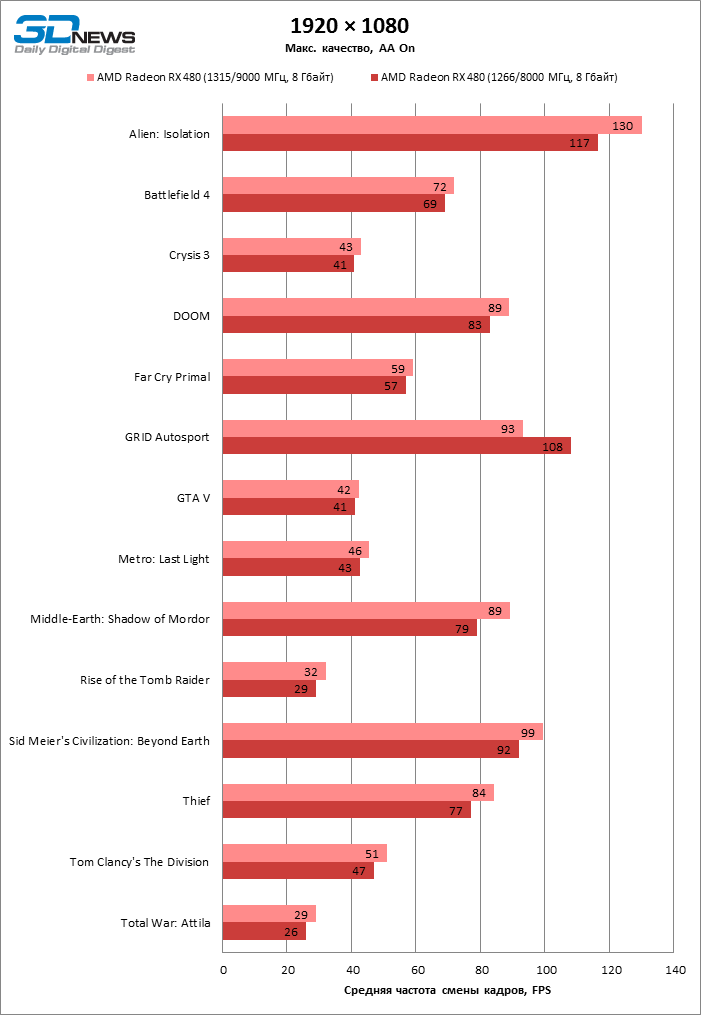
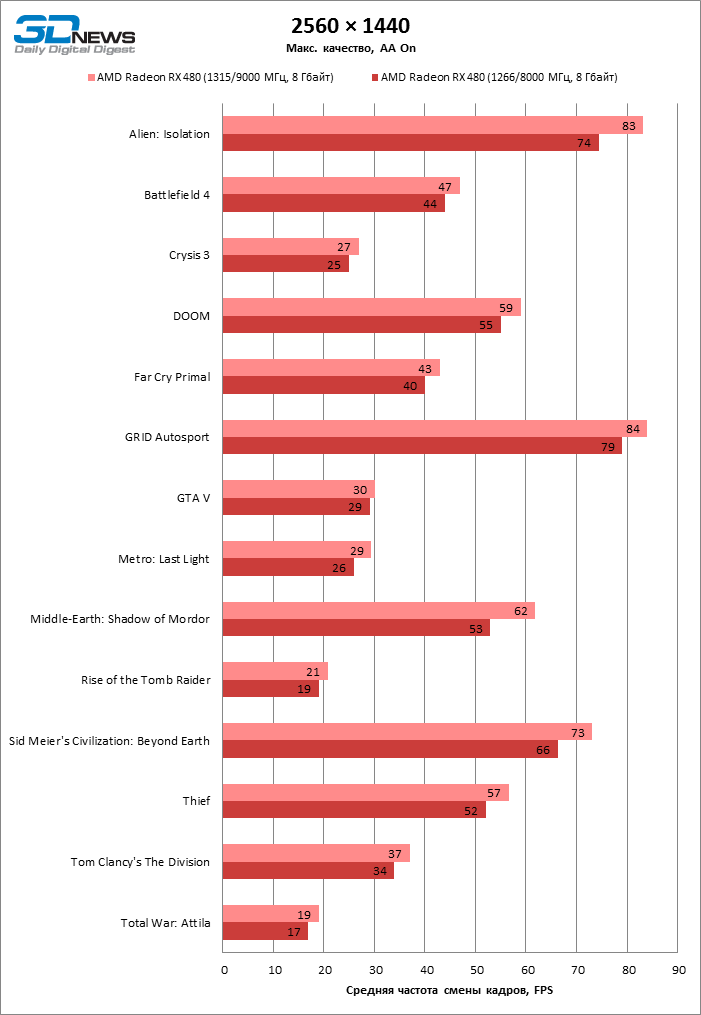
Получив доступ к кривой «частота — напряжение» в WattMan, мы разгоняли RX 480 наиболее простым способом: была выставлена фиксированная частота для GPU, исключая десктопный режим, и напряжение питания 1150 мВ как на графическом процессоре, так и на чипах памяти. Для того чтобы полностью раскрыть потенциал компонентов карты, вентилятор работал на максимальной скорости, а лимит мощности был увеличен на 50%.
Увы, придется признать, что даже в таких условиях RX 480 — плохой объект для оверклокинга. Все, что удалось выжать из GPU, — 1315 МГц. Разгон памяти в WattMan ограничен 1000 МГц эффективной частоты, которая и была достигнута при повышении напряжения на чипах RAM со стандартных до 1,150 В. В неудачном разгоне GPU нельзя обвинить кулер референсной карты: несмотря на бюджетную конструкцию, на полных оборотах он сумел снизить температуру GPU под игровой нагрузкой на 13 °С. Похоже, что Polaris 10 в этой карте изначально близок к своему частотному пределу.
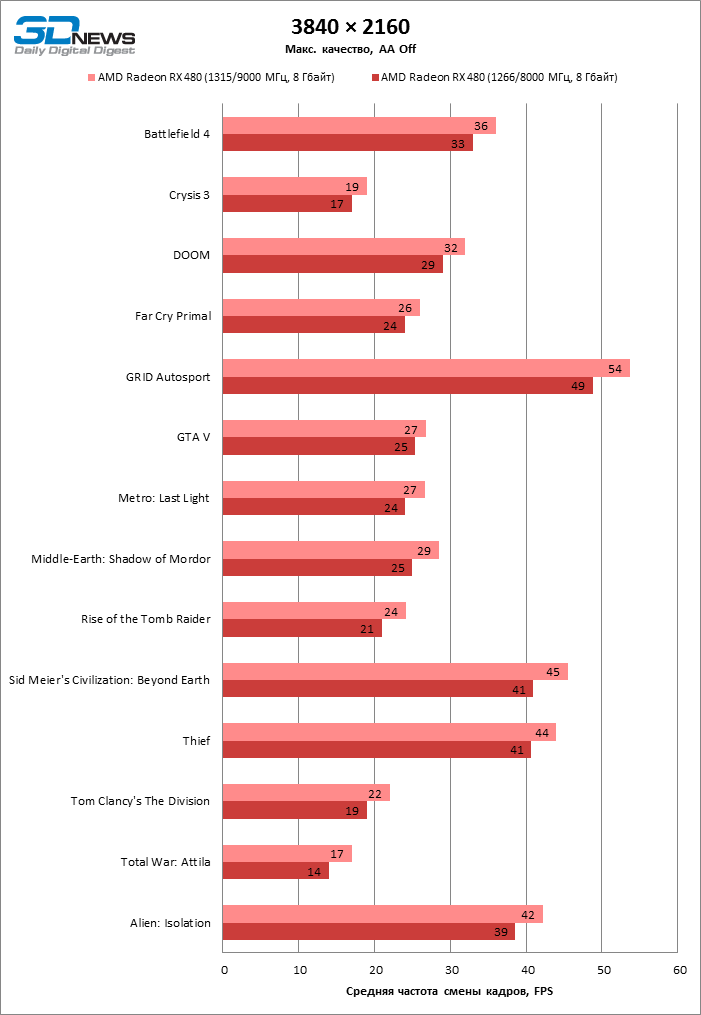
⇡#Производительность: разгон
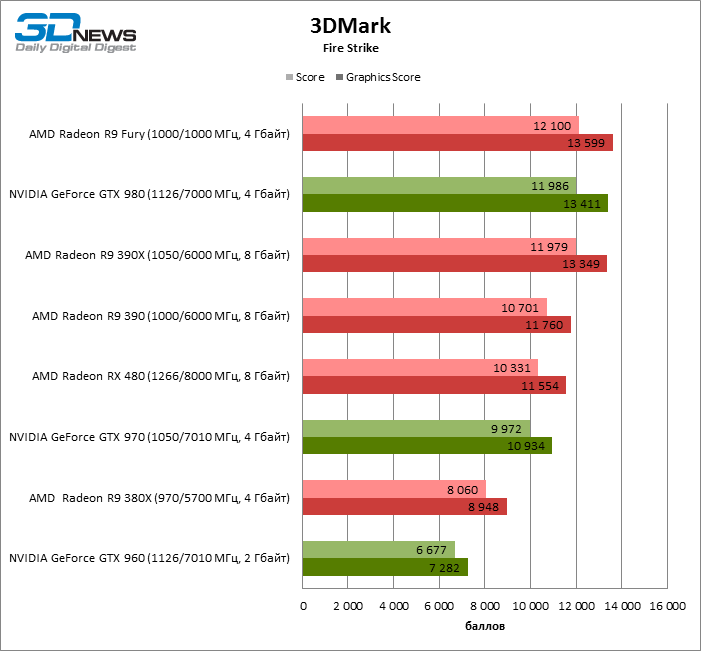
| 3DMark Fire Strike |
|---|
|
AMD Radeon RX 480 (1266/8000 МГц, 8 Гбайт) |
AMD Radeon RX 480 (1315/9000 МГц, 8 Гбайт) |
Прирост производительности |
| 3DMark Score |
10331 |
11493 |
11% |
| Graphics Score |
11554 |
13045 |
13% |
| 1920 × 1080 |
|
Полноэкранное сглаживание |
AMD Radeon RX 480 (1266/8000 МГц, 8 Гбайт) |
AMD Radeon RX 480 (1315/9000 МГц, 8 Гбайт) |
Прирост производительности |
| Alien: Isolation |
SMAA T2X |
117 |
130 |
112% |
| Battlefield 4 |
MSAA 4x + FXAA |
69 |
72 |
104% |
| Crysis 3 |
MSAA 4x |
41 |
43 |
105% |
| DOOM |
TSSAA 8TX |
83 |
89 |
107% |
| Far Cry Primal |
SMAA |
57 |
59 |
104% |
| GRID Autosport |
MSAA 4x |
108 |
93 |
86% |
| GTA V |
MSAA 4x + FXAA |
41 |
42 |
103% |
| Metro: Last Light |
SSAA 4x |
43 |
46 |
107% |
| Middle-Earth: Shadow of Mordor |
Не поддерживается |
79 |
89 |
113% |
| Rise of the Tomb Raider |
SSAA 4x |
29 |
32 |
111% |
| Sid Meier's Civilization: Beyond Earth |
SMAA T2X |
92 |
99 |
108% |
| Thief |
SSAA 4x + FXAA |
77 |
84 |
109% |
| Tom Clancy's The Division |
SMAA 1x High |
47 |
51 |
109% |
| Total War: Attila |
MSAA 4x |
26 |
29 |
112% |
| Макс. |
|
|
|
113% |
| Среднее |
|
|
|
106% |
| Мин. |
|
|
|
86% |
| 2560 × 1440 |
|
Полноэкранное сглаживание |
AMD Radeon RX 480 (1266/8000 МГц, 8 Гбайт) |
AMD Radeon RX 480 (1315/9000 МГц, 8 Гбайт) |
Прирост производительности |
| Alien: Isolation |
SMAA T2X |
74 |
83 |
112% |
| Battlefield 4 |
MSAA 4x + FXAA |
44 |
47 |
107% |
| Crysis 3 |
MSAA 4x |
25 |
27 |
108% |
| DOOM |
TSSAA 8TX |
55 |
59 |
107% |
| Far Cry Primal |
SMAA |
40 |
43 |
108% |
| GRID Autosport |
MSAA 4x |
79 |
84 |
106% |
| GTA V |
MSAA 4x + FXAA |
29 |
30 |
104% |
| Metro: Last Light |
SSAA 4x |
26 |
29 |
113% |
| Middle-Earth: Shadow of Mordor |
Не поддерживается |
53 |
62 |
117% |
| Rise of the Tomb Raider |
SSAA 4x |
19 |
21 |
109% |
| Sid Meier's Civilization: Beyond Earth |
SMAA T2X |
66 |
73 |
110% |
| Thief |
SSAA 4x + FXAA |
52 |
57 |
109% |
| Tom Clancy's The Division |
SMAA 1x High |
34 |
37 |
109% |
| Total War: Attila |
MSAA 4x |
17 |
19 |
112% |
| Макс. |
|
|
|
117% |
| Среднее |
|
|
|
109% |
| Мин. |
|
|
|
104% |
| 3840 × 2160 |
|
Полноэкранное сглаживание |
AMD Radeon RX 480 (1266/8000 МГц, 8 Гбайт) |
AMD Radeon RX 480 (1315/9000 МГц, 8 Гбайт) |
Прирост производительности |
| Alien: Isolation |
SMAA T2X |
39 |
42 |
109% |
| Battlefield 4 |
MSAA 4x + FXAA |
33 |
36 |
109% |
| Crysis 3 |
MSAA 4x |
17 |
19 |
112% |
| DOOM |
TSSAA 8TX |
29 |
32 |
110% |
| Far Cry Primal |
SMAA |
24 |
26 |
108% |
| GRID Autosport |
MSAA 4x |
49 |
54 |
110% |
| GTA V |
MSAA 4x + FXAA |
25 |
27 |
106% |
| Metro: Last Light |
SSAA 4x |
24 |
27 |
111% |
| Middle-Earth: Shadow of Mordor |
Не поддерживается |
25 |
29 |
114% |
| Rise of the Tomb Raider |
SSAA 4x |
21 |
24 |
115% |
| Sid Meier's Civilization: Beyond Earth |
SMAA T2X |
41 |
45 |
111% |
| Thief |
SSAA 4x + FXAA |
41 |
44 |
108% |
| Tom Clancy's The Division |
SMAA 1x High |
19 |
22 |
116% |
| Total War: Attila |
MSAA 4x |
14 |
17 |
121% |
| Макс. |
|
|
|
121% |
| Среднее |
|
|
|
111% |
| Мин. |
|
|
|
106% |
⇡#Выводы
Судя по результатам игровых тестов, стихия Radeon RX 480 — разрешения от 1920 × 1080 до 2560 × 1440, где эта видеокарта выступает примерным эквивалентом Radeon R9 390 и GeForce GTX 970 по быстродействию. Принимая во внимание сниженное энергопотребление, объем памяти с заделом на будущее и главное, привлекательную цену новинки, можно смело предсказать Radeon RX 480 светлое будущее и покупательские симпатии.
Семейство Polaris несет колоссальную массу нововведений, которые устранили либо по меньшей мере компенсировали те недоработки, которые преследовали GPU от AMD в предыдущие годы. Собственно архитектура GCN четвертого поколения лишь укрепила достоинства GCN 1.2, на базе которой AMD выпустила процессоры Tonga и Fiji, но главная хорошая новость в том, что теперь эти наработки распространяются на всю линейку дискретных видеоадаптеров. Графическое подразделение AMD наконец вышло из затянувшегося периода, когда сил разработчиков не хватало на полное обновление, и большинство моделей Radeon 300-й серии комплектовалась неминуемо устаревающими GPU, которые могли предложить пользователю немногое помимо выгодного соотношения цена/производительность. Polaris, продолжая агрессивную ценовую политику AMD, не идет на компромисс ни в энергопотреблении, ни в функциональных возможностях. Одна оговорка: у нас пока нет информации о поддержке новых функций рендеринга DirectX 12 в Polaris, но как только появятся такие данные, мы дополним обзор.
Единственное, на что можно посетовать, так это обескураживающе низкие результаты разгона графического процессора Polaris 10 в референсной видеокарте. Заметно, что несмотря на достоинства техпроцесса 14 нм FinFET, изощренные способы управления напряжением, которые AMD внедрила в Polaris (по факту, GPU от AMD были и остаются лидерами в этой дисциплине), и энергоэффективность, которую GCN в ее современной форме продемонстрировала ранее на примере Fiji, ядро в RX 480 работает почти на пределе своих возможностей.
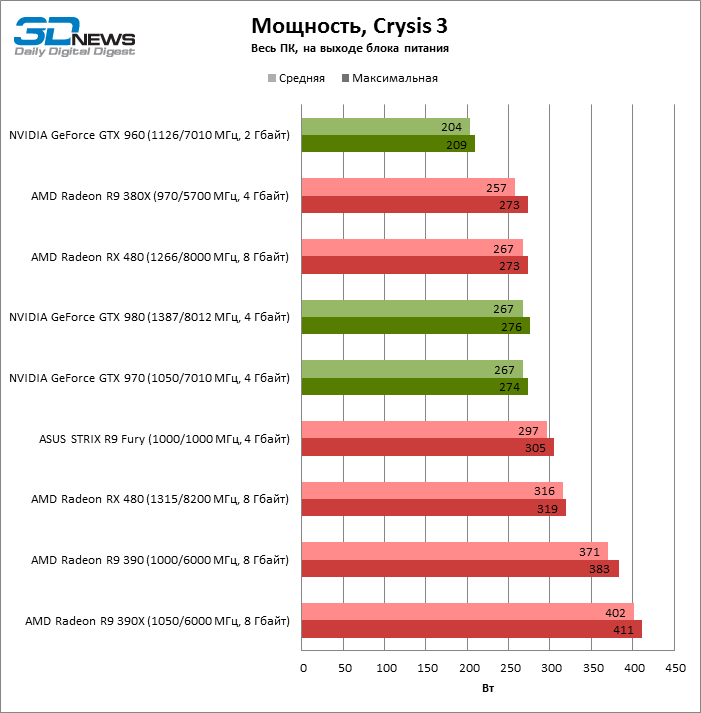
Если сравнивать Radeon RX 480 с Radeon R9 380X по усредненной производительности в играх и официальным значениям TDP, то AMD достигла прироста 62% прироста производительности на ватт. При сравнении GeForce GTX 1080 с GTX 980 получается даже несколько меньшее соотношение — 51%. Но так как AMD и NVIDIA теперь впервые за долгие годы используют для производства микросхем разные фабрики (GlobalFoundries/Samsung и TSMC соответственно), со стороны невозможно судить, чья микроархитектура является более экономичной по сравнению с конкурирующей.
Учитывая то, что это первый продукт AMD, выполненный по норме 14 нм FinFET, и тот объем работы, который отделяет семейство Polaris от его предшественников, можно предположить, что потенциал нового техпроцесса еще только осваивается и в будущем позволит AMD выпустить графические процессоры с более эффектными параметрами частот и энергопотребления. Кроме того, есть вероятность, что ускорители оригинального дизайна от партнеров AMD смогут предложить повышенные частоты и лучшие условия для разгона GPU по сравнению с референсным образцом.
Ну а пока мы можем поздравить AMD с отличным продуктом в популярной ценовой категории. Сделав первый, и весьма сильный, ход в «производительном» сегменте, AMD вступила на новый виток обостренной конкуренции на рынке дискретных видеокарт, которая, как известно, идет только на пользу и самой индустрии, и покупателям. Пожелаем, чтобы Radeon Technologies Group сохранила этот импульс в столь важное и плодотворное для игровой графики время.
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex