Опрос
|
реклама
Быстрый переход
OpenAI выпустила ИИ-модель ChatGPT Images 2.0, которая отлично генерирует текст на картинках
22.04.2026 [06:26],
Дмитрий Федоров
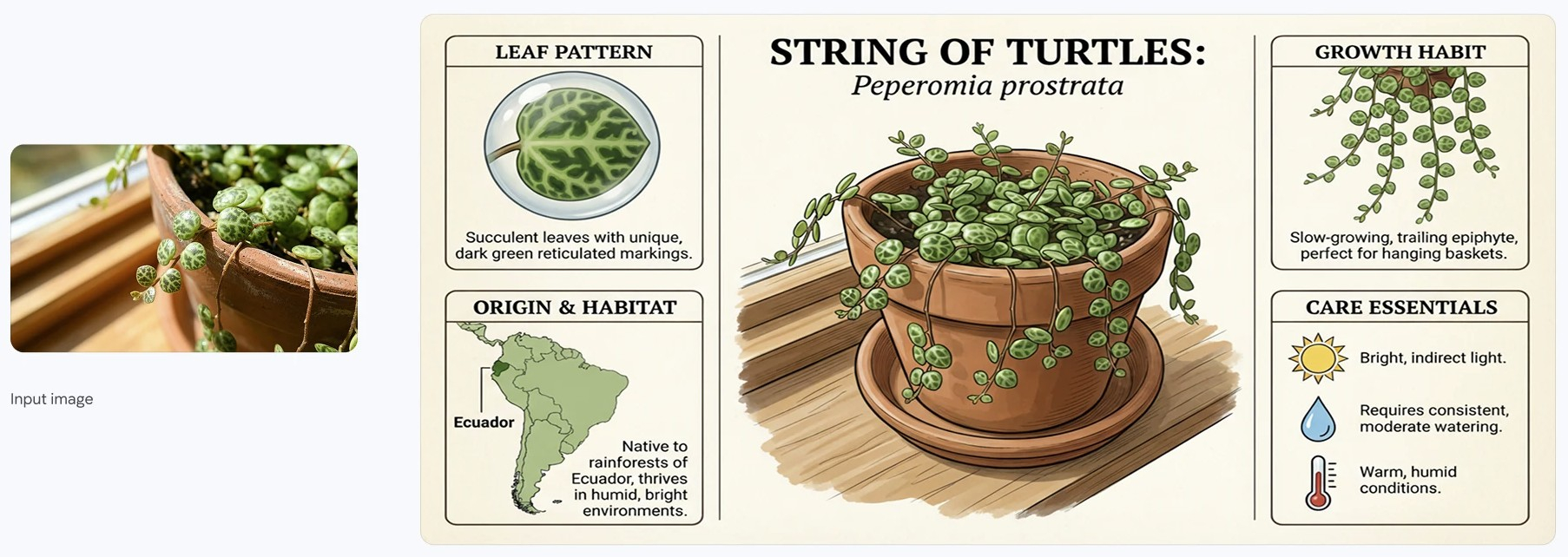
OpenAI представила модель генерации изображений ChatGPT Images 2.0, которая впервые среди массовых ИИ корректно отрисовывает текст на картинках. Если два года назад диффузионные ИИ-модели не могли составить меню мексиканского ресторана без выдуманных слов вроде «enchuita» и «burrto», то новая модель создаёт изображения с надписями, пригодными к использованию без правок.  Ещё в 2024 году диффузионные ИИ-модели систематически искажали надписи. По словам Асмелаша Тека Хадгу (Asmelash Teka Hadgu), основателя и гендиректора Lesan AI, модели восстанавливают изображение из шума и усваивают паттерны, покрывающие основную массу пикселей, а текст занимает ничтожную долю площади. 
Слева — меню, сгенерированное ChatGPT Images 2.0: все надписи читаемы, ни одного выдуманного слова. Справа — три варианта от Microsoft Designer на основе DALL-E 3: «Enchidas», «Tamrielo», «Churiros», «Margartas» и десятки других искажений. Источник изображений: ChatGPT Images 2.0, Microsoft Designer (DALL-E 3) / techcrunch.com С тех пор исследователи опробовали альтернативные подходы — в частности, авторегрессионные модели, которые предсказывают содержание изображения и работают по принципу, близкому к большим языковым моделям (LLM). OpenAI не раскрыла, какая архитектура лежит в основе Images 2.0. Компания пояснила лишь, что новинка умеет «рассуждать» — искать информацию в интернете, генерировать несколько изображений по одному запросу и перепроверять результаты. Благодаря этому Images 2.0 создаёт маркетинговые материалы в разных размерах и даже комиксы. У ИИ-модели также улучшена работа с нелатинскими шрифтами — японским, корейским, хинди и бенгальским. Однако знания Images 2.0 ограничены декабрём 2025 года, что может сказаться на точности генерации по запросам о недавних событиях. 
Источник изображения: ChatGPT Images 2.0 / openai.com «Images 2.0 выводит детализацию и точность генерации на беспрецедентный уровень. Модель способна продумать сложную композицию и воплотить её на практике: следовать инструкциям, сохранять заданные детали и отрисовывать элементы, на которых обычно спотыкаются генераторы, — мелкий текст, пиктограммы, элементы интерфейса, насыщенные композиции и тонкие стилистические ограничения, — и всё это в разрешении до 2K», — говорится в пресс-релизе компании. Генерация при этом занимает больше времени, чем обычный текстовый запрос к ChatGPT, но даже многопанельный комикс укладывается в несколько минут. 
Источник изображения: ChatGPT Images 2.0 / openai.com Доступ к Images 2.0 получат все пользователи ChatGPT и Codex. Платные подписчики смогут генерировать более сложные изображения. OpenAI также откроет программный интерфейс (API) gpt-image-2 — стоимость будет зависеть от качества и разрешения выходных изображений. Google представила Nano Banana 2 — обновлённый генератор изображений работает быстрее и качественнее, и доступен бесплатно
26.02.2026 [20:49],
Николай Хижняк
Компания Google анонсировала последнюю версию своей популярной ИИ-модели для генерации изображений — Nano Banana 2. Новая модель, которая технически является аналогом Gemini 3.1 Flash Image, способна создавать более реалистичные изображения по сравнению с предшественницей. Nano Banana 2 станет моделью по умолчанию в приложении Gemini для режимов Fast, Thinking и Pro, то есть новинка будет доступна и бесплатным пользователям. 
Источник изображений: Google Компания впервые выпустила Nano Banana в августе 2025 года. Она быстро завоевала популярность среди пользователей Gemini, особенно в таких странах, как Индия. В ноябре Google представила Nano Banana Pro, позволяющую создавать более детализированные и высококачественные изображения. Новая Nano Banana 2 сохраняет ряд характеристик высокой детализации версии Pro, но генерирует изображения быстрее. С её помощью можно создавать изображения с разрешением от 512 пикселей до 4K и с различными соотношениями сторон.  Nano Banana 2 поддерживает единообразие персонажей (до пяти) и точную проработку до 14 объектов в одном рабочем процессе, что улучшает возможности повествования. По словам Google, пользователи могут отправлять сложные запросы с подробными нюансами для генерации изображений. Кроме того, модель позволяет создавать медиаконтент с более ярким освещением, насыщенными текстурами и чёткими деталями.  С запуском Nano Banana 2 станет моделью по умолчанию для генерации изображений во всех приложениях Gemini. Компания также сделает её моделью по умолчанию для генерации изображений в своём инструменте для редактирования видео Flow. В 141 стране Nano Banana 2 станет моделью по умолчанию в Google Lens и в режиме поиска с ИИ в мобильной и веб-версии Google Search. Пользователи тарифных планов Google AI Pro и Ultra смогут продолжать использовать Nano Banana Pro для специализированных задач, выбрав соответствующую настройку через меню с тремя точками. Для разработчиков Nano Banana 2 будет доступна в режиме предварительного просмотра через API Gemini, Gemini CLI и Vertex API. Она также появится в AI Studio и инструменте разработки Antigravity, выпущенном в ноябре прошлого года. Google заявляет, что все изображения, созданные с помощью новой модели, будут иметь водяной знак SynthID — фирменный маркер для обозначения изображений, сгенерированных искусственным интеллектом. Изображения также совместимы с системой C2PA Content Credentials, которая подтверждает происхождение контента и фиксирует, подвергался ли он изменениям. Систему поддерживают Adobe, Microsoft, Google, OpenAI и Meta✴✴. Google сообщила, что с момента запуска проверки SynthID в приложении Gemini в ноябре ей воспользовались более 20 млн раз. Firefly без ограничений: Adobe сняла лимиты на ИИ-генерацию изображений и видео, но не навсегда
02.02.2026 [19:35],
Сергей Сурабекянц
Adobe предоставит подписчикам своего ИИ-сервиса Firefly неограниченное количество генераций изображений и видео как с использованием собственных, так и поддерживаемых сторонних моделей ИИ. Ежемесячные кредиты на генерацию изображений и видео будут отменены для новых подписчиков, которые зарегистрируются в системе до 16 марта. 
Источник изображения: Adobe Firefly — это набор генеративных моделей Adobe для создания изображений и видео. В него входят как собственные модели Adobe, так и интеграции со сторонними сервисами, такими как Google Nano Banana Pro, OpenAI GPT-Image 1.5 и Runway Gen-4. После первоначального запуска Firefly в составе пакета приложений Creative Cloud, Adobe выпустила Firefly как отдельную платформу, доступную в браузере или через специальные приложения на мобильных платформах. Подписчики Adobe Firefly могут выбрать один из нескольких тарифных планов. До сих пор одним из ключевых отличий было количество кредитов на создание изображений, включённых в каждый тарифный план. Но с сегодняшнего дня Adobe предлагает при оформлении подписки генерацию неограниченного количества изображений и видео. Важно отметить, что предложение действительно только для отдельной подписки Adobe Firefly, а не для подписок Creative Cloud. «Зарегистрируйтесь до 16 марта и получите неограниченное количество поколений изображений и видео Firefly с разрешением до 2K в приложении Adobe Firefly. Предложение распространяется на клиентов, использующих тарифные планы Firefly Pro, Firefly Premium, а также планы на 4000, 7000 и 50 000 кредитов, и включает неограниченное количество генераций с использованием ведущих в отрасли моделей изображений, включая Google Nano Banana Pro, GPT Image Generation, Runway Gen-4 Image, а также коммерчески безопасные модели изображений и видео Firefly от Adobe», — заявила Adobe. По данным Adobe, 86 % создателей контента теперь используют ИИ в своей повседневной работе. Кроме того, за последний год длина их запросов удвоилась. Это свидетельствует о том, что создатели контента всё чаще используют ИИ как часть своих рабочих процессов. Компания отмечает, что сегодняшний шаг направлен на то, чтобы помочь создателям оставаться в творческом потоке, проходя через процесс проб и ошибок, не беспокоясь о своих кредитах на создание изображений. Adobe также сообщила, что в преддверии Дня святого Валентина и Лунного Нового года пользователи по всему миру получат возможность использовать собственные модели, а также интеграцию Firefly со сторонними сервисами, чтобы протестировать платформу. X заявила, что Grok больше не раздевает людей — но это не так
15.01.2026 [11:08],
Владимир Мироненко
После волны критики из-за создания в соцсети X с помощью чат-бота Grok AI дипфейков сексуального характера без согласия пользователей, платформа сообщила о внесении изменений в возможности аккаунта Grok AI редактировать изображения реальных людей. Однако, как утверждает ресурс The Verge, в приложении Grok можно по-прежнему создавать откровенные изображения человека в бикини, используя бесплатный аккаунт. 
Источник изображения: Mariia Shalabaieva/unsplash.com «Мы внедрили технологические меры, чтобы предотвратить редактирование изображений реальных людей в откровенной одежде, такой как бикини, через аккаунт Grok. Это ограничение распространяется на всех пользователей, включая платных подписчиков», — сообщается в обновлении аккаунта X. В нём также отмечено, что создание изображений и возможность редактирования изображений через аккаунт Grok на платформе X теперь доступны только платным подписчикам. «Это добавляет дополнительный уровень защиты, помогая гарантировать, что лица, пытающиеся злоупотреблять аккаунтом Grok для нарушения закона или нашей политики, могут быть привлечены к ответственности», — сообщила администрация соцсети. Кроме того, было объявлено, что платформа блокирует возможность для всех пользователей создавать изображения реальных людей в бикини, нижнем белье и подобной одежде через аккаунт Grok и в Grok in X в тех юрисдикциях, где это незаконно. Ранее стало известно, что британское Управление связи (Ofcom) начало расследование по этому поводу. Также сообщается, что на этой неделе в Великобритании вступит в силу закон, согласно которому создание интимных дипфейк-изображений без согласия пользователей будет считаться уголовным преступлением. OpenAI выпустила генератор изображений ChatGPT Images 1.5 — более высокая скорость и новые возможности
17.12.2025 [07:37],
Владимир Фетисов
На прошлой неделе OpenAI выпустила модель искусственного интеллекта GPT-5.2, а теперь она стала основой фирменного генератора изображений ChatGPT Images 1.5. По словам разработчиков, это позволило в четыре раза повысить скорость работы сервиса по сравнению с предыдущей версией, а также реализовать несколько полезных нововведений. 
Источник изображения: ChatGPT Images ChatGPT Images стал лучше следовать пользовательским инструкциям, в том числе в случаях, когда дело доходит до редактирования только что созданного изображения. Пользователь может попросить алгоритм добавить, убрать, объединить, смешать или даже перенести какие-то элементы на картинке. OpenAI заявила, что обновлённый ChatGPT Images лучше справляется с отображением текста, что традиционно является слабым местом многих генераторов изображений. По данным OpenAI, повысилось качество генерации читаемого текста, а также появилась возможность работы с более мелким и плотным тестом. В рамках этого обновления фирменного генератора изображения OpenAI добавила в боковую панель ChatGPT отдельный раздел Images. В нём собраны готовые к использованию фильтры и промпты, призванные помочь в поиске вдохновения. «Мы считаем, что всё ещё находимся в самом начале пути к тому, что может дать генерация изображений. Сегодняшнее обновление — это значительный шаг вперёд, и впереди нас ждёт многое: от более детальных правок до более насыщенных и подробных результатов на разных языках», — говорится в сообщении OpenAI. Разработчики приступили к развёртыванию ChatGPT Images 1.5 и в скором времени обновлённая версия сервиса станет доступна всем пользователям. Отмечается, что пользователи также смогут продолжить взаимодействие с моделью GPT-4o через пользовательский интерфейс чат-бота компании. Новый ChatGPT Images появляется как раз в тот момент, когда его главный конкурент Google Nano Banana Pro вызвал всплеск популярности Gemini среди пользователей. В октябре Google заявила, что пользовательская база фирменного чат-бота выросла до 650 млн человек, что существенно больше 450 млн человек, о которых компания сообщала в июле. Nano Banana Pro оказалась настолько популярной, что Google для снижения нагрузки на инфраструктуру пришлось ограничить бесплатных пользователей всего двумя генерациями изображений в день. Для OpenAI, вероятно, было не столь важно дать сильный ответ на появление Nano Banana Pro, сколько обеспечить сильную конкуренцию чат-боту Gemini 3 Pro. Это связано с тем, что наличие в арсенале компании ChatGPT Images является одним из основных факторов, обеспечивающих ИИ-боту ChatGPT пользовательскую базу в 800 млн человек. Google выпустила Nano Banana Pro — «ИИ-фотошоп», который делает 4K-картинки, правит детали и даже меняет освещение
20.11.2025 [22:29],
Николай Хижняк
Google представила Nano Banana Pro (Gemini 3 Pro Image) — усовершенствованную модель для создания и редактирования изображений, созданную на базе Gemini 3 Pro. Компания описывает её как инструмент, который «превратит ваши идеи в дизайн студийного качества с беспрецедентным контролем, безупречной визуализацией текста и расширенными знаниями о мире». 
Источник изображений: Google Для того, чтобы использовать Nano Banana Pro в Gemini App, нужно выбрать режим «Думающая», который включает Gemini 3 Pro, а затем в инструментах выбрать «создать изображение». Попробовать возможности модели можно бесплатно. Google заявляет, что Nano Banana Pro поможет создавать насыщенную контекстом инфографику и диаграммы для визуализации информации в режиме реального времени, например, погоды или спортивных событий. А возможность отображать читаемый текст прямо на изображении — будь то короткий слоган или длинный абзац — делает её подходящей для создания плакатов или приглашений на различных языках. 
 Модель также поддерживает объединение нескольких элементов в единую композицию, используя до 14 изображений и до пяти человек. Для Nano Banana Pro также заявлены расширенные возможности редактирования. Можно выбрать и локально отредактировать любую часть изображения, настроить ракурсы камеры, добавить эффект боке, изменить фокус, цветовую гамму или изменить освещение с дневного на ночное. 
 Поддерживаются разрешения до 4K с различными соотношениями сторон.  Изображения, созданные или отредактированные с помощью модели Nano Banana Pro, будут содержать встроенные метаданные C2PA. Это должно упростить обнаружение созданного генеративным ИИ контента или дипфейков в результатах поиска и лентах социальных сетей. Пользователи бесплатной версии Nano Banana Pro будут ограничены квотой. Для доступа ко всем функциям требуется подписка Google AI Plus, Pro и Ultra. Режим ИИ также доступен в «Google Поиске» в США при наличии подписки на Google AI Pro или Ultra, а также по всему миру — для пользователей ИИ-блокнота NotebookLM. ИИ-бот Google Gemini успешно конкурирует в области редактирования фото с инструментами Adobe
18.10.2025 [08:19],
Владимир Фетисов
В августе Google представила ИИ-модель Gemini 2.5 Flash Image, которая позволяет с высокой точностью контролировать процесс редактирования фотографий. Этот инструмент стал доступен всем пользователям приложения Gemini бесплатно, а разработчики могут задействовать соответствующий API для интеграции сервиса в свои продукты за относительно невысокую плату. За прошедшие с тех пор несколько месяцев алгоритм превратился в конкурента ИИ-инструментам для работы с медиаконтентом компании Adobe. 
Источник изображения: Google Об этом пишет Business Insider со ссылкой на данные аналитической компании Appfigures, которая подсчитала, что по мере стремительного роста числа загрузок приложения Gemini после интеграции в него новых функций для редактирования изображений, количество скачиваний приложения Firefly, в котором реализованы ИИ-инструменты Adobe для генерации изображений и видео, постепенно снижается. Невозможно точно сказать, связаны ли эти два события между собой. По данным Appfigures, после запуска в июне приложение Firefly показало «впечатляющий» рост, а в августе количество его загрузок выросло на 150 % по сравнению с июлем. За тот же период количество скачивания Gemini выросло лишь на 20 %. Эта статистика включает в себя данные о загрузках приложений из магазинов Google Play Маркет и Apple App Store. После обновления приложения Gemini 26 августа, когда в нём появились новые возможности в плане ИИ-редактирования фото, количество загрузок Firefly упало более чем вдвое в течение следующей недели. В это же время количество скачиваний Gemini стремительно росло. По данным Appfigures, по состоянию на 6 октября количество загрузок Gemini выросло на 331 % по сравнению с последней неделей июля, тогда как количество скачиваний Firefly снизилось на 68 %, что стало самым низким показателям с момента обновления Gemini в августе. Для лучшего понимания масштабов следует учитывать, что на прошлой неделе Gemini скачивали на 6,1 млн раз больше, чем на неделе, когда в приложение была интегрирована новая ИИ-модель для точного редактирования фото. За этот же период количество скачиваний Firefly снизилось на 2 млн. Данные Appfigures по разным регионам указывают на то, что в США количество скачиваний Gemini в октябре подскочило на 88 % по сравнению с сентябрём. За этот же период популярность Firefly в стране упала на 82 %. Это указывает на то, что Gemini превращается в серьёзного конкурента в сфере обработки изображений. Photoshop получил ИИ-инструмент для быстрого повышения качества старых фотографий
29.07.2025 [19:37],
Сергей Сурабекянц
Adobe представила в последней бета-версии Photoshop серию новых инструментов, которые, по заявлению компании, устранят «утомительные шаги, снизят уровень сложности и сделают точное редактирование более быстрым и интуитивно понятным». Самой востребованной среди пользователей, по словам Adobe, является ИИ-функция Generative Upscale («Генеративное Масштабирование»), позволяющая увеличивать изображения до 8 мегапикселей без потери качества. 
Источник изображений: Adobe В последней версии программы также появился обновлённый инструмент Remove («Удаление»), созданный на основе последней ИИ-модели Adobe Firefly. Он выполняет все ожидаемые функции стирания и удаления объектов, но при этом, по утверждению Adobe, обеспечивает более реалистичное изображение — на фотографии остаётся «меньше артефактов от удалённых объектов». Этот инструмент, как и Generative Upscale, доступен в бета-версии для настольных компьютеров и в веб-приложении. Adobe также запускает функцию Harmonize («Гармонизация»), ранее анонсированную под названием Project Perfect Blend на конференции Max в октябре 2024 года. Используя ИИ-модель Adobe Firefly, Harmonize «интеллектуально анализирует окружающий контекст, автоматически корректируя цвет, освещение, тени и визуальный тон для создания бесшовных, цельных композиций». Adobe утверждает, что новая функция существенно сократит необходимость ручной корректировки. Помимо бета-версии на настольном компьютере или в веб-браузере, она также доступна для пользователей мобильных устройств iOS.  Теперь пользователи получили возможность переключаться между различными ИИ-моделями Adobe Firefly. Кроме того, в этой бета-версии Photoshop появилась функция Projects («Проекты»), которая обеспечит сохранение всех файлов пользователя в едином пространстве и позволит отправлять заказчику целые коллекции, а не одну версию за раз. AMD представила Amuse 3.0 — приложение для ИИ-генерации изображений на Ryzen и Radeon
15.04.2025 [18:45],
Николай Хижняк
Компания AMD представила Amuse 3.0 — программный инструмент для ИИ-генерации изображений. Платформа разработана в партнёрстве с компанией TensorStack AI. Она использует мощности процессоров AMD Ryzen AI и видеокарт Radeon RX для создания изображений и коротких видеороликов локально на ПК. 
Источник изображений: TechPowerUp / AMD AMD заявляет, что платформа Amuse 3.0 способна генерировать изображения печатного качества и видеоролики чернового качества (низкого разрешения) длиной до 6 секунд. Amuse 3.0 поддерживает более 100 новых моделей ИИ, включая Stable Diffusion 3.5 и FLUX. 
 Каждая из этих моделей была тщательно оптимизирована для работы с аппаратным обеспечением AMD, что привело к увеличению скорости вывода до 4,3 раз по сравнению с универсальными моделями. Для платформы заявлена поддержка видеофильтров на основе ИИ. Amuse 3.0

Смотреть все изображения (6)



Смотреть все изображения (6) AMD заявляет, что производительность Amuse 3.0 по сравнению с универсальной базовой платформой генерации изображения Olive Optimize в 4,3 раза выше и была достигнута на видеокарте Radeon RX 9070 XT. Компания также добавила данные о производительности процессоров Ryzen AI со встроенным NPU мощностью 50 TOPS, с которыми оптимизированные модели AMD показали себя в 3,3 раза быстрее при генерации изображений. Amazon представила ИИ-модель Nova Reel 1.1 для генерации двухминутных видео по текстовым подсказкам
08.04.2025 [07:56],
Владимир Мироненко
Amazon представила обновлённую ИИ-модель Nova Reel 1.1, позволяющую генерировать видео продолжительностью до двух минут на основе текстовых подсказок пользователей. Её предыдущая версия Nova Reel была анонсирована в декабре 2024 года, став первой попыткой компании выйти на рынок моделей для создания видео с помощью генеративного ИИ. 
Источник изображения: Amazon Nova Reel 1.1, может генерировать «многокадровые» видео с «единым стилем» между кадрами, сообщила в блоге разработчик-адвокат AWS Элизабет Фуэнтес (Elizabeth Fuentes). Пользователи могут предоставить текстовую подсказку длиной до 4000 символов для генерации двухминутного видео, состоящего из шестисекундных кадров. Обновлённая модель также получила новый режим под названием «Ручной многокадровый» (Multishot Manual). В этом режиме модель может использовать изображение вместе с подсказкой, чтобы обеспечить лучшее соответствие запросу композиции видеокадра. По словам Фуэнтес, при наличии изображения с разрешением 1280 × 720 пикселей и подсказки с максимальным количеством символов 512 модель может генерировать видео, содержащие до 20 кадров. Модели Nova Reel доступны только на платформах и в сервисах AWS, включая Bedrock — набор инструментов для разработки ИИ компании. При этом клиенты должны запросить доступ к ним. Модели, генерирующие видео, обучаются на огромном количестве образцов видео, необходимых для «изучения» закономерностей для создания новых клипов. Некоторые компании обучают модели на видео, защищённых авторским правом без получения на это разрешения от владельцев или авторов. В результате эти модели могут «выдать» защищённые авторским правом кадры, подвергая пользователей моделей опасности судебного иска в связи нарушением прав на интеллектуальную собственность. Amazon не раскрыла источник данных для обучения Nova Reel, но пообещала, что будет защищать клиентов AWS в случае их обвинения в нарушении авторских прав в соответствии со своей политикой возмещения ущерба. Завирусившийся новый генератор изображений в ChatGPT стал доступен всем пользователям
01.04.2025 [11:24],
Владимир Фетисов
Новый генератор изображений OpenAI, работающий на базе большой языковой модели GPT-4o, теперь доступен всем пользователям. Об этом на своей странице в социальной сети X написал гендиректор OpenAI Сэм Альтман (Sam Altman). До этого момента использовать новый ИИ-генератор изображений могли только платные подписчики ChatGPT. 
Источник изображения: OpenAI Бесплатные пользователи сервиса сейчас могут генерировать не больше двух изображений в сутки. Ранее Альтман упоминал о возможности введения лимита в три изображения в день. Инструмент генерации изображений OpenAI мгновенно стал сверхпопулярным сразу после его запуска в массы. Альтман заявлял, что спрос на генерацию картинок был так высок, что используемые компанией графические ускорители попросту «плавились». Генератор быстро стал известен тем, что его использовали для преобразования изображений в стиль японской анимационной студии Studio Ghibli. Это вызвало обеспокоенность по поводу нарушения авторских прав, поскольку создаваемые ИИ-генератором изображения были очень похожи на работы студии. Некоторые люди также использовали данный инструмент для создания поддельных квитанций, например, ресторанных счетов. В компании на это заявили, что все сгенерированные ИИ изображения содержат метаданные, указывающие на их происхождение. Вместе с этим OpenAI заявила о привлечении $40 млрд инвестиций, за счёт чего рыночная стоимость компании составила $300 млрд. В качестве основного инвестора в рамках этого раунда финансирования выступил Softbank. Компания также объявила, что ИИ-бот ChatGPT еженедельно используют более 500 млн человек по всему миру, тогда как количество ежемесячно активных пользователей выросло до 700 млн человек. Microsoft накрыла банду хакеров, которая обманом заставляла ИИ рисовать неподобающие фейки со знаменитостями
28.02.2025 [10:36],
Владимир Фетисов
Microsoft заявила об обнаружении американских и зарубежных хакеров, которые обходили ограничения генеративных инструментов на базе искусственного интеллекта, включая службы OpenAI в облаке Azure, для создания вредоносного контента, в том числе интимных изображений знаменитостей и другого контента сексуального характера. По данным компании, в этой деятельности участвовали хакеры из США, Ирана, Великобритании, Гонконга и Вьетнама. 
Источник изображения: Mika Baumeister / Unsplash В сообщении сказано, что злоумышленники извлекали логины пользователей сервисов генеративного ИИ из открытых источников и использовали их для собственных целей. После получения доступа к ИИ-сервису хакеры обходили установленные разработчиками ограничения и продавали доступ к ИИ-сервисам вместе с инструкциями по созданию вредоносного контента. Microsoft предполагает, что все идентифицированные хакеры являются членами глобальной киберпреступной сети, которую в компании именуют Storm-2139. Двое из них территориально находятся во Флориде и Иллинойсе, но компания не раскрывает личностей, чтобы не навредить уголовному расследованию. Софтверный гигант заявил, что ведёт подготовку соответствующих запросов в правоохранительные органы США и ряда других стран. Эти меры Microsoft принимает на фоне растущей популярности генеративных нейросетей и опасения людей по поводу того, что ИИ может использоваться для создания фейковых изображений общественных деятелей и простых граждан. Такие компании, как Microsoft и OpenAI, запрещают генерацию подобного контента и соответствующим образом ограничивают свои ИИ-сервисы. Однако хакеры всё равно пытаются обойти эти ограничения, что зачастую им успешно удаётся сделать. «Мы очень серьёзно относимся к неправомерному использованию искусственного интеллекта и признаём серьёзные и долгосрочные последствия злоупотребления изображениями для потенциальных жертв. Microsoft по-прежнему стремится защитить пользователей, внедряя надёжные меры ИИ-безопасности на платформах и защищая сервисы от незаконного и вредоносного контента», — заявил Стивен Масада (Steven Masada), помощник главного юрисконсульта подразделения Microsoft по борьбе с киберпреступлениями. Это заявление последовало за декабрьским иском Microsoft, который компания подала в Восточном округе Вирджинии против 10 неизвестных в попытке собрать больше информации о хакерской группировке и пресечь её деятельность. Решение суда позволило Microsoft взять под контроль один из основных веб-сайтов хакеров. Это и обнародование ряда судебных документов в прошлом месяце посеяло панику в рядах злоумышленников, что могло установить личности некоторых участников группировки. StabilityAI представила улучшенную ИИ-модель для генерации изображений Stable Diffusion 3.5
23.10.2024 [05:06],
Анжелла Марина
Компания StabilityAI представила новую версию ИИ-модели для генерации изображений Stable Diffusion 3.5 с улучшенным реализмом, точностью и стилизацией. По сообщению Tom's Guide, модель бесплатна для некоммерческого использования, включая научные исследования, а также для малых и средних предприятий с доходом до $1 млн. 
Источник изображения: StabilityAI Как и предыдущая версия SD3, Stable Diffusion 3.5 доступен в трёх конфигурациях: Large (8B), Large Turbo (8B) и Medium (2,6B). Все конфигурации оптимизированы для работы на обычном пользовательском оборудовании и их можно настраивать. В своём пресс-релизе StabilityAI признала, что модель Stable Diffusion 3 Medium, выпущенная в июне, не полностью соответствовала стандартам и ожиданиям сообщества. «После того как мы выслушали ценные отзывы, вместо быстрого исправления мы решили уделить время разработке версии, которая продвигает нашу миссию по трансформации визуальных медиа», — сказали в компании. Новые модели ориентированы на возможность гибкой настройки, высокую производительность и разнообразие результатов. Поддерживаются стилистические настройки, включая фотографию и живопись. Для указания определённого стиля можно также использовать хештеги, например, boho, impressionism или modern. Ещё можно выделять ключевые слова в запросе для получения более реалистичных изображений. Модель Stable Diffusion 3.5 Large лидирует на рынке по лучшему соответствию запросам и качеству изображений. Модель Turbo имеет минимальное время вывода результатов. Medium превосходит другие модели в плане баланса между качеством изображений и соответствия запросам, что делает её, по утверждению компании, самым эффективным выбором для создания контента. Все три конфигурации свободно доступны по лицензии Stability AI Community License. Для использования в коммерческих целях потребуется лицензия Enterprise License. AMD представила Amuse 2.0 — ПО для ИИ-генерации изображений для Ryzen и Radeon
29.07.2024 [00:20],
Николай Хижняк
AMD представила Amuse 2.0 — программный инструмент для ИИ-генерации изображений. Программа доступна в бета-версии. В перспективе её функциональность будет расширяться. Amuse 2.0 является своего рода аналогом инструмента AI Playground от Intel, использующего мощности видеокарт Intel Arc. Решение от AMD для генерации контента в свою очередь полагается на мощности процессоров Ryzen и видеокарт Radeon. 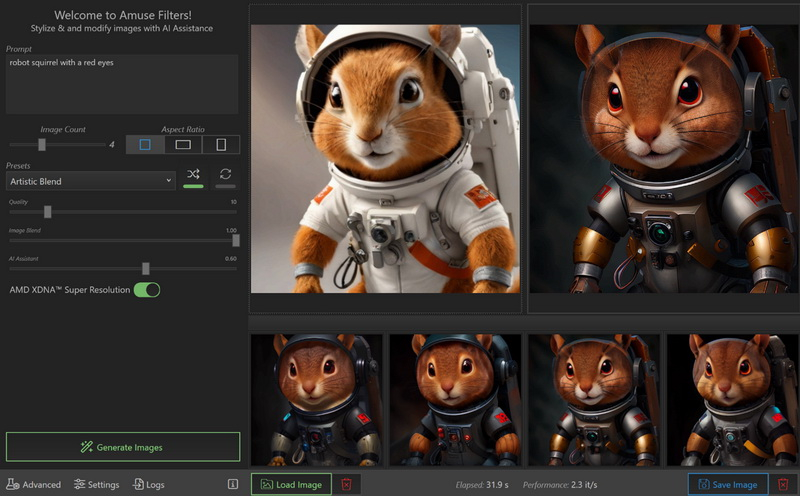
Источник изображений: AMD Приложение Amuse 2.0, разработанное с помощью TensorStack, отличается простотой использования, без необходимости загружать множество внешних компонентов, задействовать командные строки или запускать что-либо ещё. Для использования приложения достаточно лишь запустить исполняемый файл. 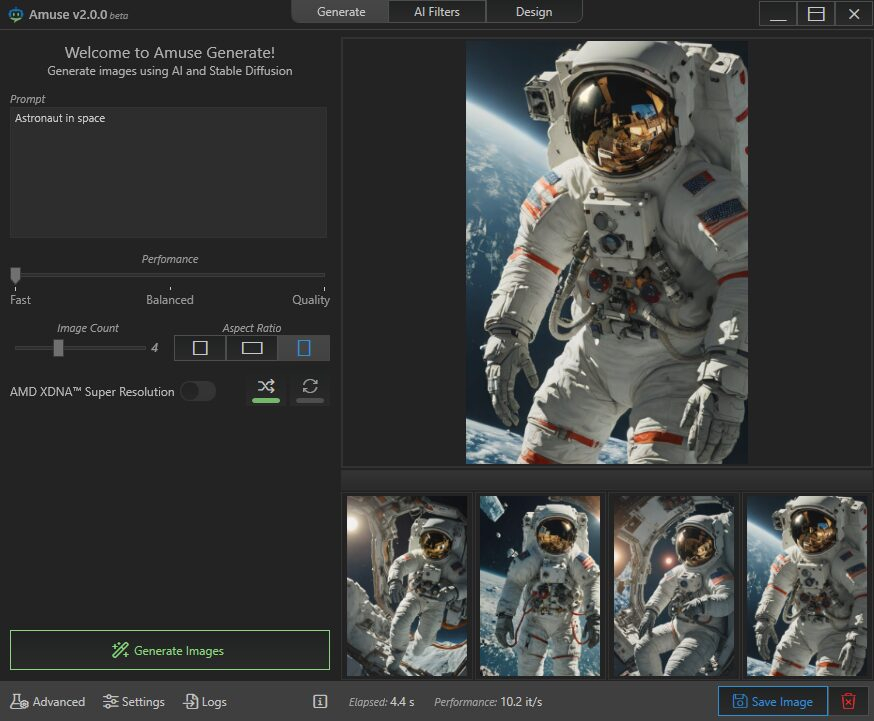 По сравнению с Intel AI Playground, Amuse 2.0 не поддерживает запуск чат-ботов на основе больших языковых моделей. В настоящее время приложение предназначено только для генерации изображений с помощью ИИ. Amuse 2.0 использует модели Stable Diffusion и поддерживает процессоры Ryzen AI 300 (Strix Point), Ryzen 8040 (Hawk Point) и серию видеокарт Radeon RX 7000. Почему компания не добавила поддержку видеокарт Radeon RX 6000 и более ранних моделей, а также процессоров Ryzen 7040 (Phoenix), обладающих практически идентичными характеристиками с Hawk Point, неизвестно. Возможно, это изменится в будущем. 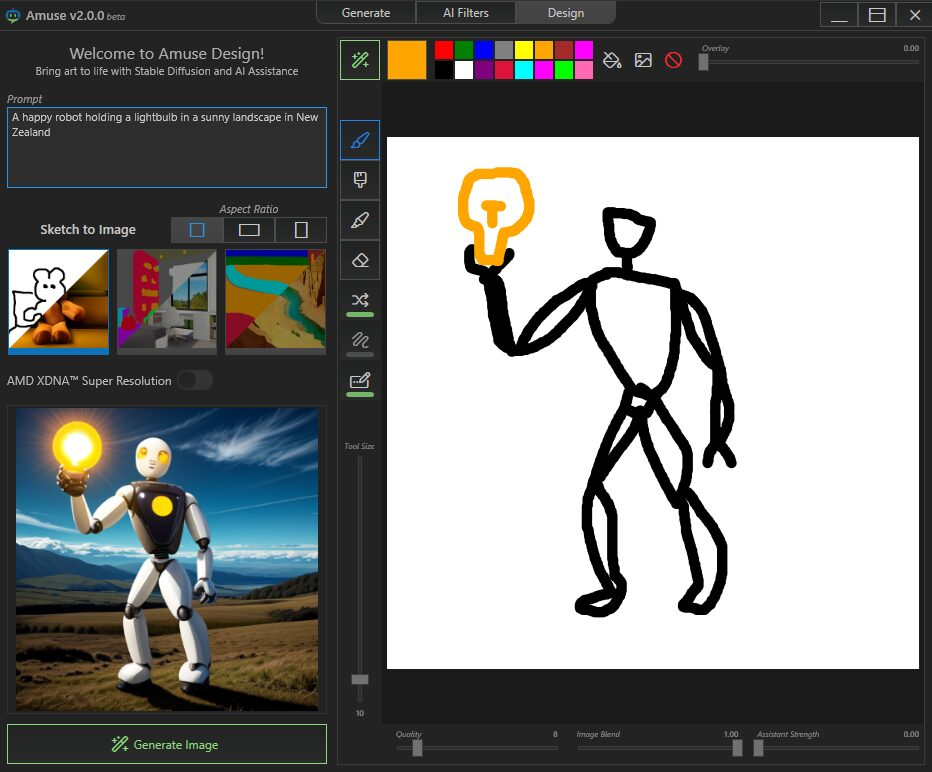 Для работы Amuse 2.0 AMD рекомендует использовать 24 Гбайт ОЗУ или больше для систем на базе процессоров Ryzen AI 300 и 32 Гбайт оперативной памяти для систем на базе Ryzen 8040. Для видеокарт Radeon RX 7000 требования к необходимому объёму памяти не указаны. 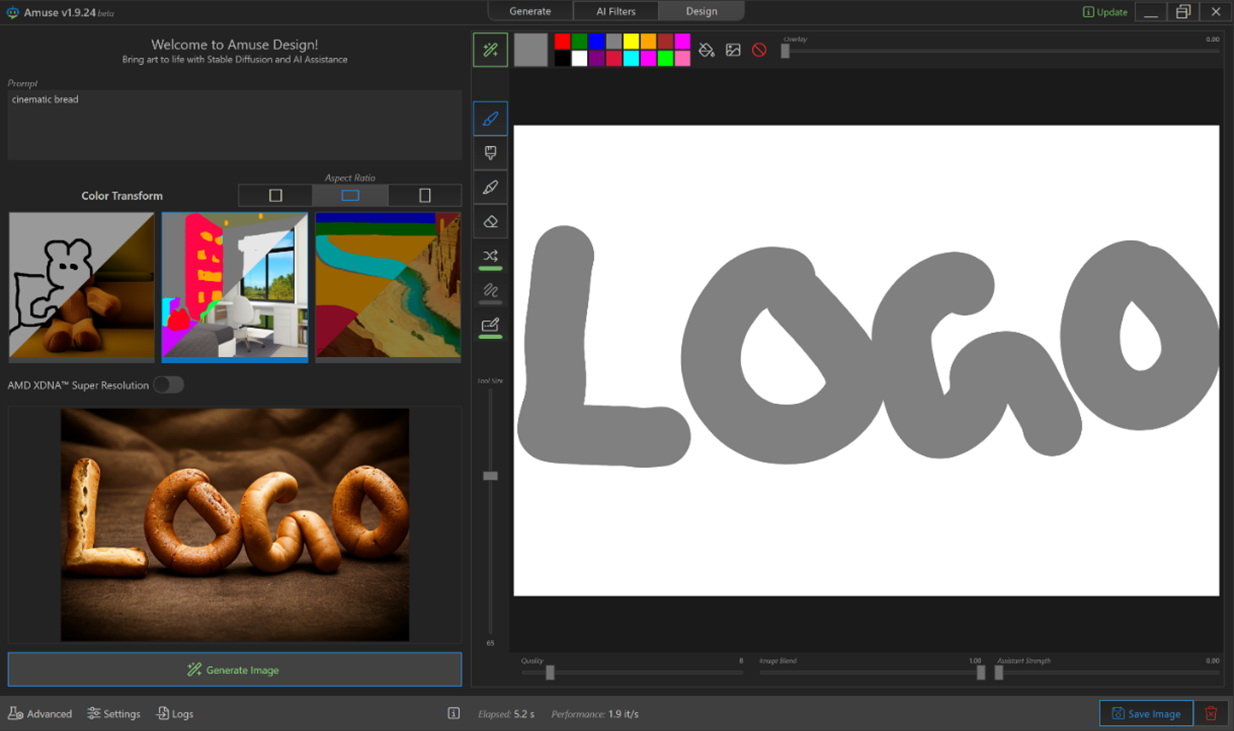 Возможности Amuse 2.0:
Стоит отметить, что инструмент поддерживает XDNA Super Resolution — технологию, позволяющую увеличивать масштаб изображений вдвое. Более подробно об Amuse 2.0 можно узнать по этой ссылке. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex