
Опрос
|
реклама
Быстрый переход
Хакеры похитили и слили в Сеть секретные файлы полиции Лос-Анджелеса
10.04.2026 [06:09],
Анжелла Марина
Киберпреступники похитили большой массив конфиденциальных внутренних документов Департамента полиции Лос-Анджелеса и выложили данные в сеть. Как стало известно TechCrunch, за утечкой стоит группировка World Leaks, которая публикует похищенную информацию, чтобы заставить жертв заплатить выкуп. 
Источник изображения: xAI Украденные данные включают личные дела сотрудников полиции, материалы расследований внутренних проверок и процессуальные документы с уголовными жалобами. Файлы также содержат персональную информацию, включая имена свидетелей и медицинские данные. Эмма Бест (Emma Best), основатель некоммерческой организации и платформы для сбора и публикации крупных утечек информации от государственных структур DDoSecrets, подтвердила, что смогла просмотреть часть информации, которая была опубликована (а затем удалена по неизвестной причине) на сайте группировки. В публичном заявлении Департамент полиции Лос-Анджелеса сообщил, что расследует инцидент, уточнив, что взлом не затронул системы и сети LAPD, а произошёл через систему цифрового хранения, принадлежащую офису городского прокурора Лос-Анджелеса. Департамент уже работает с этим офисом, чтобы получить доступ к скомпрометированным файлам и понять полный масштаб инцидента. Взлом, по данным Los Angeles Times, затронул 7,7 терабайт различной информации и более 337 000 файлов. Так как по законам штата Калифорния большинство документов полицейских считаются конфиденциальными, эта утечка, если её подлинность подтвердится, станет беспрецедентным нарушением безопасности полицейских. World Leaks начала свою деятельность в январе 2025 года как очевидный ребрендинг предыдущей группировки Hunters International, и с тех пор скомпрометировала организации в различных отраслях, включая здравоохранение, производство и технологии, продемонстрировав способность атаковать даже оборонных подрядчиков и компании из списка ежегодного рейтинга 500 крупнейших компаний США (Fortune 500). Google закрыла дыру в Chrome: украденные cookie теперь бесполезны
10.04.2026 [05:12],
Анжелла Марина
Google внедрила в Chrome 146 для Windows технологию Device Bound Session Credentials (DBSC), которая защищает от кражи cookie-файлов сессий вредоносным ПО. Эта мера безопасности криптографически привязывает активные сеансы пользователей к аппаратному обеспечению их устройств, делая похищенные данные аутентификации непригодными для использования хакерами. Пользователи macOS получат эту защиту в одном из будущих обновлений браузера. 
Источник изображения: bleepingcomputer.com Анонсированная в 2024 году технология работает через привязку к аппаратным компонентам — модулю Trusted Platform Module (TPM) в Windows и Secure Enclave в macOS. Чип безопасности генерирует уникальные публичные и приватные ключи для шифрования данных, которые невозможно экспортировать с устройства. Выпуск новых краткосрочных cookie сессий происходит только после того, как Chrome докажет серверу владение соответствующим приватным ключом. Без этого ключа украденные cookie истекают и становятся бесполезными для атакующих практически мгновенно. 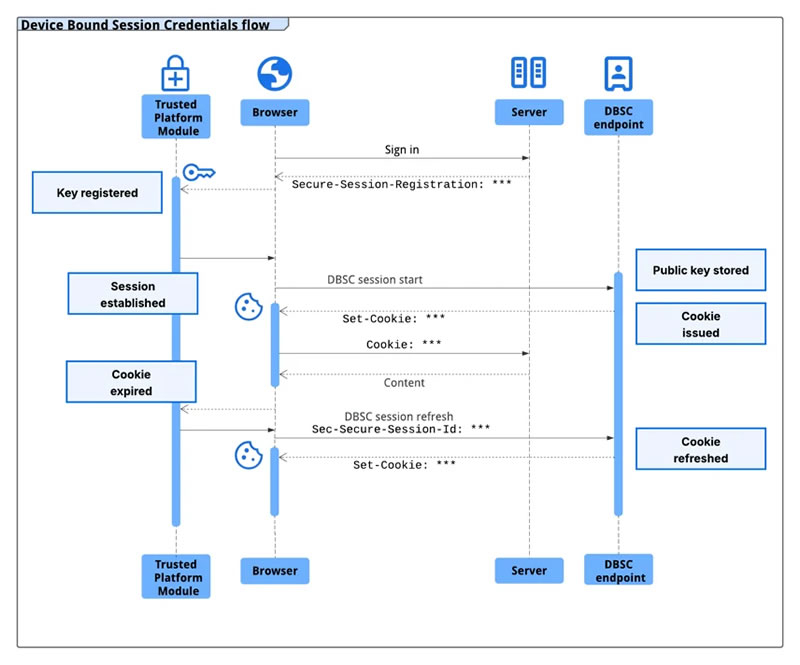
Источник изображения: Google Напомним, как работают сессионные куки (Сookies). Они выполняют роль аутентификационных токенов для входа на ту или иную интернет-платформу с длительным сроком действия и создаются на стороне сервера на основе логина и пароля пользователя. Поскольку они позволяют проходить аутентификацию без ввода учётных данных, киберпреступники используют специализированное вредоносное ПО (инфостилеры) для сбора этих токенов. Google отмечает, что такие вредоносы, как LummaC2, становятся всё более изощренными в краже учётных данных. После получения доступа к машине такое ПО может читать локальные файлы и память, где браузеры хранят cookie аутентификации, и не существует надёжного способа предотвратить их кражу исключительно программными средствами. Протокол же DBSC требует минимального обмена информацией в виде публичного ключа для подтверждения владения (не раскрывая идентификаторы устройства) и защищает каждую сессию отдельным ключом, не позволяя сайтам отслеживать активность пользователя между различными сессиями. Google тестировала раннюю версию DBSC совместно с несколькими веб-платформами, включая Okta, и зафиксировала заметное снижение краж сессий. Протокол разработан в партнёрстве с Microsoft как открытый веб-стандарт и получил положительную экспертную оценку от многих специалистов по веб-безопасности. Веб-сайты могут перейти на более защищённые сессии с аппаратной привязкой, добавив специальные точки регистрации и обновления в свой бэкенд без потери совместимости с существующим фронтендом. Спецификации доступны на сайте консорциума World Wide Web Consortium (W3C), а подробное руководство по внедрению — в документации Google и на GitHub. Япония собралась стать раем для ИИ-разработчиков и ослабила запреты по персональным данным
08.04.2026 [10:42],
Павел Котов
Японские власти решили сделать страну самым свободным в мире регионом для разработки приложений на основе искусственного интеллекта. Для этого они внесли изменения в законодательство и устранили требование для компаний получать у граждан согласие на использование некоторых категорий персональных данных. 
Источник изображения: Roméo A. / unsplash.com Накануне, 7 апреля, правительство Японии одобрило поправки к «Закону о защите персональных данных», которые отменяют требование получать согласие перед сбором персональных данных. Речь идёт только об информации, представляющей незначительную угрозу нарушения прав человека, и при её использовании для сбора статистики в исследовательских целях. Под действие поправок подпадают данные, связанные со здоровьем граждан, если они помогут улучшить общественное здравоохранение. Разрешается сканирование лиц — поправки требуют, чтобы занимающиеся их сбором организации объясняли, как они обрабатывают эту информацию; предоставлять гражданам возможность отказаться от использования их данных они больше не обязаны. Для сбора изображений детей младше 16 лет требуется согласие родителей; в отношении прочей связанной с несовершеннолетними информации будет применяться критерий «наилучших интересов». Организации, которые собирают недопустимые данные или злонамеренно используют эту информацию для причинения вреда гражданам, будут штрафоваться на сумму, равную полученной от неправомерной деятельности прибыли. Штрафы также полагаются за получение данных мошенническим путём. Все эти меры, считают японские власти, необходимы, потому что действующее законодательство представляет собой «очень большое препятствие к развитию и применению ИИ в Японии». «Мы должны это предотвратить, потому что без доступа к [персональным] данным Японии будет непросто разрабатывать и развёртывать полезный ИИ», — заявил глава министерства по цифровой трансформации Хисаси Мацумото (Hisashi Matsumoto). Cloudflare ускорила переход на постквантовую криптографию из-за роста угроз
07.04.2026 [23:03],
Анжелла Марина
Компания Cloudflare объявила об ускорении своей дорожной карты в области постквантовой безопасности. К 2029 году вся платформа компании, включая системы аутентификации, будет полностью защищена от угроз, связанных с развитием квантовых компьютеров. 
Источник изображения: siliconangle.com Пересмотр сроков связан с новыми исследованиями, которые указывают на то, что текущие стандарты шифрования могут быть взломаны гораздо раньше, чем ожидалось. В частности, недавние работы Google и исследователей из Oratomic продемонстрировали значительный прогресс в создании алгоритмов и оборудования, способных обойти широко используемые методы защиты, такие как RSA-2048. В связи с этим Cloudflare готовится к более скорому наступлению так называемого «Q-дня» — момента, когда квантовые системы смогут массово взламывать современные криптографические протоколы. По некоторым прогнозам, этот рубеж может быть пройден уже к концу текущего десятилетия. Фокус отрасли смещается с долгосрочной защиты зашифрованных данных на обеспечение безопасности текущих систем аутентификации. Злоумышленники с доступом к квантовым мощностям смогут подделывать учётные данные для прямого проникновения в корпоративные сети. Однако внедрение постквантовой аутентификации технически сложнее обычного шифрования из-за зависимости от долгоживущих ключей и сторонних сертификатов и для надёжной защиты компаниям придётся не только внедрить новые стандарты, но и полностью отключить устаревшие криптографические системы. На данный момент более половины пользовательского трафика в сети Cloudflare уже использует постквантовое согласование ключей. В 2026 году компания планирует расширить поддержку постквантовой аутентификации, а к 2028 году развернуть её в большинстве своих продуктов. К 2029 году все сервисы платформы станут постквантово-защищенными по умолчанию и без дополнительных затрат для клиентов. Новость об этих изменениях была опубликована изданием SiliconANGLE, у истоков которого стоят технологические предприниматели Джон Фарриер (John Furrier) и Дейв Велланте (Dave Vellante). «Google Диск» научился выявлять программы-вымогатели и автоматически восстанавливать файлы пользователя
31.03.2026 [20:42],
Сергей Сурабекянц
В сентябре прошлого года Google начала бета-тестирование новой функции «Google Диска», которая проверяет файлы пользователя на наличие программ-вымогателей. Сегодня компания сообщила в блоге Google Workspace Updates, что функции «обнаружения программ-вымогателей» и «восстановления файлов» доступны всем пользователям. 
Источник изображений: Google По словам Google, теперь файлы пользователя, хранящиеся в облаке, будут надёжно защищены от программ-вымогателей. В дополнение к защите от программ-вымогателей, Google также внедряет функцию восстановления файлов, которая позволит восстановить файлы пользователей, ставших жертвами программы-вымогателя, до их первоначального состояния. 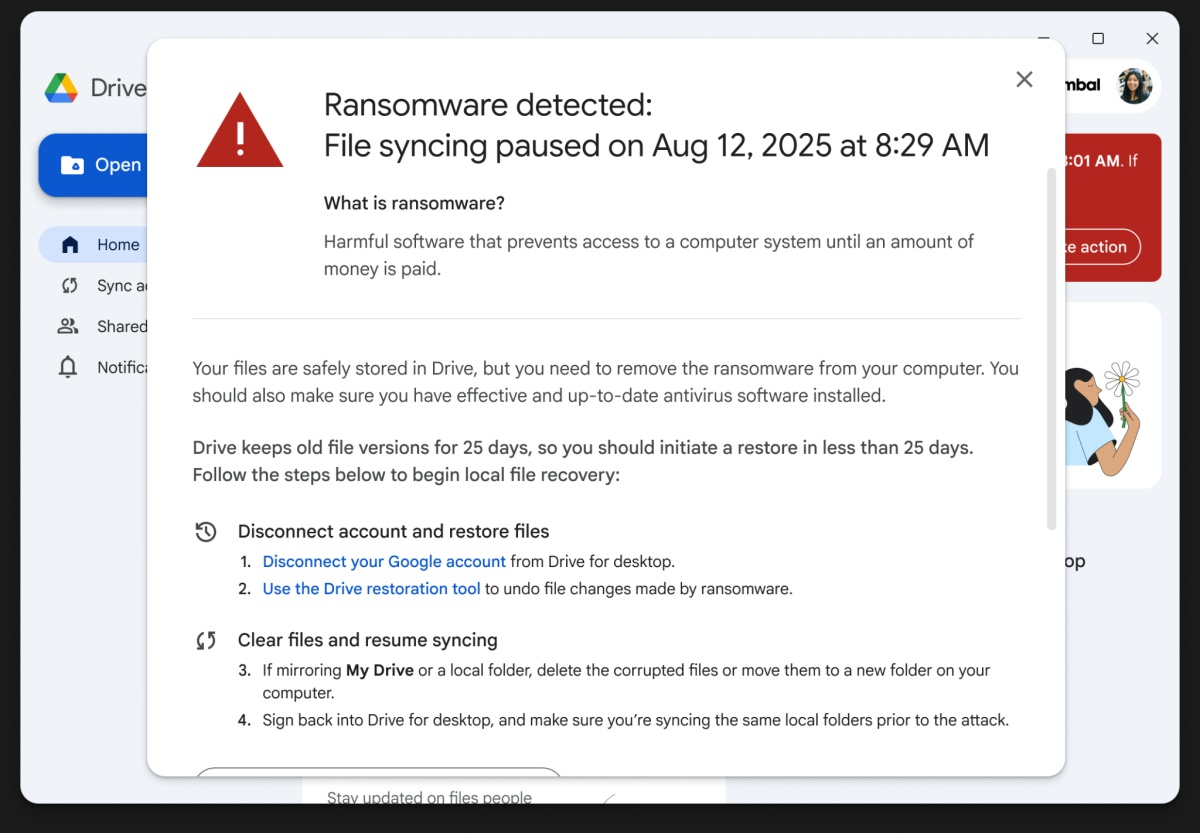 Если на ПК установлена настольная версия «Google Диска», приложение автоматически приостановит синхронизацию файлов в облаке, как только обнаружит программу-вымогатель. Обычные пользователи увидят предупреждение о программе-вымогателе и инструкции с дальнейшими действиями, ИТ-администраторы также получат уведомление по электронной почте. Apple: режим Lockdown Mode не позволил хакерам взломать ни одного устройства
28.03.2026 [05:20],
Анжелла Марина
Компания Apple заявила, что за почти четыре года существования функции Lockdown Mode (Режим блокировки) не было зафиксировано ни одного случая успешного взлома iPhone. Если функция активирована, гаджеты успешно противостоят атакам коммерческого шпионского программного обеспечения. 
Источник изображения: Benny Bowden/Unsplash Функция Lockdown Mode была представлена в 2022 году в качестве дополнительной меры безопасности для пользователей, подвергающихся повышенному риску. Она отключает определённые системные возможности iPhone и других устройств, которые чаще всего используются злоумышленниками для внедрения вирусов. Как сообщила представитель Apple Сара О'Рурк (Sarah O'Rourke), компании неизвестно о каких-либо успешных атаках хакеров на устройства с этим режимом в активированном статусе. Изначально инструмент создавался для противодействия угрозам со стороны правительственного шпионского ПО. Независимые исследователи из лаборатории Citizen Lab при Университете Торонто публично сообщали о случаях, когда Lockdown Mode активно блокировал попытки заражения шпионским ПО Pegasus от NSO Group и Predator от компании Intellexa. Также, по меньшей мере в одном задокументированном случае специалисты компании Google выявили, что некоторые вредоносные программы самостоятельно прекращают попытку заражения гаджета, если режим блокировки включен — вероятно, как способ избежать обнаружения. 
Источник изображения: Apple В свою очередь эксперт по кибербезопасности Apple Патрик Уордл (Patrick Wardle) назвал Lockdown Mode одним из самых эффективных инструментов защиты, когда-либо доступных массовому потребителю, поскольку он значительно сокращает возможность для атак. «Я думаю, можно с уверенностью сказать, что режим блокировки — одна из самых агрессивных функций повышения безопасности для потребителей, когда-либо выпущенных», — сказал он изданию TechCrunch. Как пояснил Уордл, режим уничтожает целые классы методов доставки вредоносного кода, блокируя большинство типов вложений в сообщениях и ограничивая функциональность WebKit, вынуждает создателей шпионского ПО применять более сложные и дорогостоящие методы разработки, так как режим блокировки практически сводит на нет любые возможности для взлома без участия жертвы (zero-click). Как отмечает TechCrunch, несмотря на то, что технически возможность существования методов обхода режима полностью не исключена, последнее заявление Apple, которая обычно сдержана в комментариях, можно рассматривать, как «значимую веху в истории безопасности устройств компании». В SpaceX признали, что вряд ли смогут застроить орбиту миллионом спутников для ИИ
27.03.2026 [06:16],
Дмитрий Федоров
Заявленный SpaceX предел в 1 млн спутников для орбитальных ЦОД может остаться недостижимым, однако компания добивается согласования именно такой численности орбитальной группировки на начальном этапе. Заявка рассматривается Федеральной комиссией по связи США (FCC) и вызывает возражения астрономов, экологических активистов и представителей общественности из-за рисков светового загрязнения, возможного воздействия на атмосферу и безопасности в околоземном пространстве. 
Источник изображений: spacex.com Президент SpaceX Гвинн Шотвелл (Gwynne Shotwell) заявила изданию Time, что была удивлена отсутствием заметной реакции на заявку компании в FCC. Позднее планы компании по орбитальным центрам обработки данных получили больший резонанс, в том числе после заявления Илона Маска (Elon Musk) о строительстве завода Terafab для выпуска чипов для этих систем. По его словам, каждый такой спутник будет длиннее Международной космической станции (МКС). Вслед за SpaceX компания Blue Origin представила собственный план орбитальных ЦОД с группировкой из 51 600 спутников, а стартап Starcloud готовит аналогичный проект на 88 000 спутников. Nvidia также разрабатывает ИИ-чипы для использования в космосе.  Шотвелл допустила размещение таких аппаратов не только на орбите Земли, но и на орбите Луны, а в перспективе — вокруг Солнца. Маск также заявил о возможности строить эти спутники на Луне с использованием будущей лунной базы. По словам Шотвелл, сила тяжести на Луне составляет около одной шестой земной, поэтому производство спутников на Луне из лунных элементов и материалов ускорило бы и удешевило их запуск. Отвечая на вопрос о перегруженности орбит, Шотвелл заявила, что для обеспечения безопасности будут приняты необходимые меры. SpaceX сообщила FCC, что намерена начать с небольшого числа орбитальных ЦОД, чтобы отслеживать их возможное воздействие на земную атмосферу, прежде чем расширять свой проект. Ответ компании занял 32 страницы. Он был подан после того, как предложение получило в онлайн-системе FCC более 1 400 комментариев, значительная часть которых была негативной. Критики заявили, что компания не ответила на их замечания по существу. Center for Space Environmentalism сообщил FCC, что SpaceX просит довериться её заявлениям, не представив достаточных подтверждений. По оценке организации, запрашиваемые исключения фактически перекладывают экологические риски частного ИИ-проекта на американскую общественность. Измеритель скорости интернета «Яндекс Интернетометр» обзавёлся мобильным приложением
19.03.2026 [14:20],
Андрей Крупин
Команда разработчиков «Яндекса» сообщила о выпуске мобильного приложения для своего бесплатного сервиса «Интернетометр», предназначенного для оценки скорости передачи данных и проверки параметров сетевого соединения. 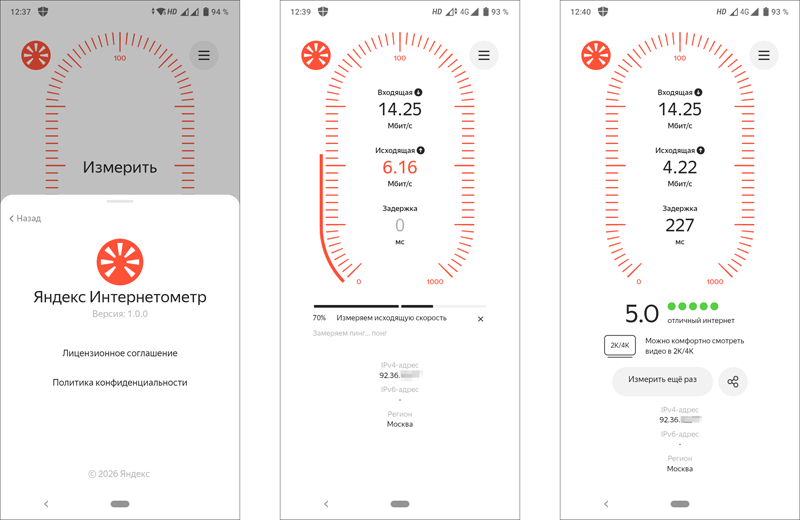 Мобильный «Яндекс Интернетометр» доступен для смартфонов и планшетов c iOS 15 и выше, Android 7 и выше. Программа позволяет измерять скорость входящего и исходящего соединения, оценивать время задержки передачи пакетов в миллисекундах, а также просматривать сведения об IP-адресе и местоположении. По результатам измерений формируется краткий отчёт о качестве сетевого соединения — приложение демонстрирует результат в понятной форме (например, «Можно комфортно смотреть видео в 2K/4K») и по пятибалльной шкале. Программа получает сведения из разных источников. Например, местоположение она определяет по IP, а скорость интернет-соединения — после обмена данными с распределёнными по стране CDN-серверами «Яндекса». «Яндекс Интернетометр» доступен для скачивания в Apple App Store, Google Play и RuStore. Хранение данных на ДНК в дата-центрах уже в текущем году — французы готовы сделать фантастику реальностью
07.03.2026 [22:12],
Геннадий Детинич
Французская компания Biomemory объявила о планах развернуть технологию хранения данных на основе ДНК в дата-центрах уже во второй половине 2026 года. Это стало возможным после приобретения активов профильной американской компании Catalog Technologies — пионера в области записи данных на ДНК, а также вычислений с её помощью. 
Источник изображения: ИИ-генерация Grok 4/3DNews Тем самым Biomemory позиционирует себя как первого интегратора, который выведет технологии DNA Data Storage на уровень коммерческих решений для ЦОД — в формате решений для стандартной серверной стойки, совместимых с традиционной инфраструктурой. Технология предлагает устойчивую, безопасную и энергоэффективную альтернативу жёстким дискам, магнитной ленте и SSD, особенно для «холодных» данных. В основе подхода Biomemory лежит запатентованный метод массового производства биобезопасной ДНК и ферментных расходных материалов, обеспечивающий стоимость эксплуатации ДНК-хранилищ данных не выше или ненамного выше традиционных. Данные записываются на синтетические ДНК-цепочки и хранятся в специальных контейнерах (DNA Cards), гарантируя надёжное хранение от 50 до 150 лет в стандартных условиях или на протяжении тысячелетий при охлаждении в герметичном состоянии. При этом уровень необратимых ошибок заявлен не выше допустимого в индустрии. Приобретённые у компании Catalog активы, включая прототип «пишущего устройства» ДНК под названием Shannon (по сути, это массив печатающих головок), патенты, технологии чтения/записи и вычислений на ДНК, органично дополняют и усиливают собственные разработки Biomemory, обещая ускорить создание масштабируемых решений с высокой плотностью и низким энергопотреблением. Накопители на основе ДНК будут представлены как дополнительный уровень хранения данных, используя при этом стандартный интерфейс S3 (как объектное хранилище). Тем самым доступ к архивам останется привычным для пользователей. Добавим, что ещё в 2022 году с компанией Catalog начала активно сотрудничать Seagate. Скорее всего, сотрудничество продолжится уже с новым владельцем разработок. Напомним, компания Catalog громко заявила о себе в 2022 году, записав на ДНК фрагмент из «Гамлета» Уильяма Шекспира объёмом 17 тыс. слов и осуществив полномасштабный поиск по фрагменту без индексирования. В теории в одном грамме ДНК можно записать 200 петабайт данных, но первые накопители будут намного скромнее по ёмкости. Спецслужбы США и Европола накрыли LeakBase — один из крупнейших хакерских форумов в мире с 142 000 участников
06.03.2026 [21:30],
Николай Хижняк
Министерство юстиции США и Европол пресекли деятельность LeakBase — одного из крупнейших хакерских форумов для торговли украденными данными, работавшего в 14 странах. 
Источник изображения: US DoJ / Europol Министерство юстиции США сообщило о захвате инфраструктуры LeakBase. Согласно судебным документам, форум насчитывал более 142 тысяч участников, которые оставили свыше 215 тысяч сообщений. LeakBase работал в обычной сети и использовал английский язык, поэтому доступ к площадке оставался открытым для пользователей со всего мира. Сейчас на платформе отображается уведомление, информирующее посетителей об изъятии данных, которое произошло с 3 по 4 марта в ходе скоординированных действий из штаб-квартиры Европола в Гааге. По данным Министерства юстиции, LeakBase содержал данные, полученные в результате многочисленных громких атак, включая «сотни миллионов учётных записей». Изъятые данные также включали «номера кредитных и дебетовых карт, банковскую информацию и данные маршрутизации, конфиденциальную деловую и личную информацию», похищенные у американских компаний и частных лиц. Совместная операция спецслужб проводилась не только в киберпространстве. Обыски, задержания и допросы прошли в США, Австралии, Бельгии, Польше, Португалии, Румынии, Испании и Великобритании. В общей сложности спецслужбы провели около сотни операций по борьбе с киберпреступностью, направленных против 37 наиболее активных пользователей платформы. Федеральное бюро расследований США заявило, что изъяло учётные записи пользователей, публикации, сведения о платежах, личные сообщения и журналы IP-адресов. Эти материалы будут использованы в качестве доказательств по делу. Согласно последним оценкам, киберпреступность в мире в целом растёт. На 2025 год уровень ущерба оценивался в $10,5 трлн, что является ошеломляющей цифрой. Если сравнивать её с ВВП стран, то она уступает лишь ВВП США и Китая. Официальные власти по всему миру усиливают борьбу с киберпреступностью, но эта проблема, вероятно, будет только усложняться с каждым днём на фоне роста автоматизации атак с использованием ИИ, которые становятся всё более привычным явлением. В США представили прообраз «жёсткого диска» на ДНК с упрощёнными процедурами записи и чтения
03.03.2026 [20:21],
Геннадий Детинич
Исследователи из Университета Миссури сообщили о прорыве в области хранения данных на основе ДНК, разработав метод, который позволяет многократно стирать и перезаписывать информацию. Ранее ДНК благодаря её исключительной плотности хранения и долговечности рассматривалась только для однократной записи архивных данных. Новый метод упрощает операции записи и чтения, поскольку не использует в процессе работы с информацией синтез нуклеотидов и ферменты — только одно электричество. 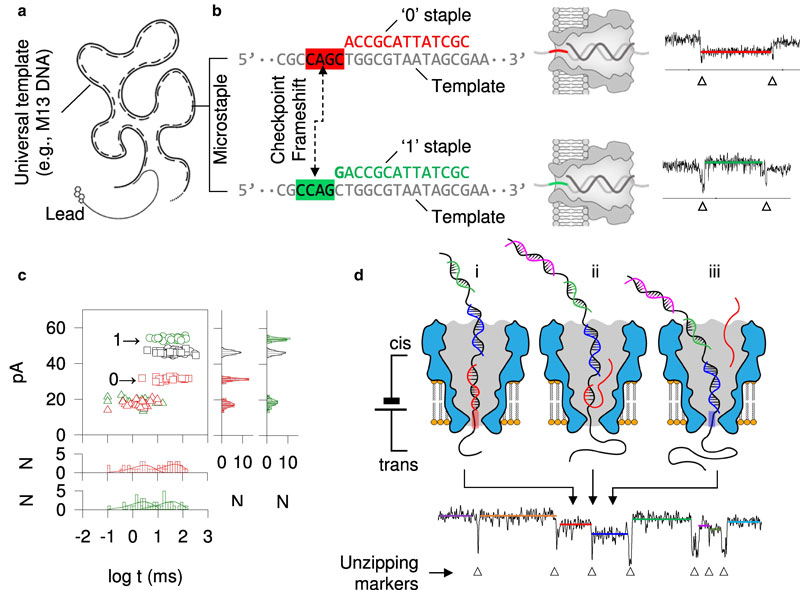
Источник изображения: PNAS 2025 Одновременная реализация чтения, стирания и записи ДНК без сложной химии обещает приблизить практическое применение технологии, которая до этого была сильно ограничена условиями подготовки к записи и к последующему чтению. Теперь учёные фактически превратили ДНК в перезаписываемый «жёсткий диск» молекулярного уровня, обещая новый уровень в индустрии хранения данных. Новый метод основан на сдвиговом кодировании, которое позволяет эффективно записывать, считывать и изменять данные без синтеза ДНК и ферментов. В частности, для чтения применяется датчик с порами нанометрового масштаба: молекула ДНК проходит через нанопору, вызывая характерные электрические сигналы, которые преобразуются в двоичный код (0 и 1). Стирание и перезапись происходят за счёт разрыва водородных связей участков ДНК с двойной спиралью. Эти же участки — переход от одиночной цепочки ДНК к двойной спирали — служат сигналом битового перехода. Запись информации происходит подобным же образом — на подготовленных участках одиночной цепочки ДНК электрически восстанавливаются водородные связи, служащие сцеплением для второй цепочки ДНК. Чередование одиночных цепочек и двойных спиралей кодирует в себе информацию без традиционных для секвенирования ДНК ферментов и синтеза нуклеотидов с последующим присоединением. Такая технология кратно упрощает кодирование и считывание данных, записанных на ДНК. Преимущества технологии огромны: ДНК обеспечивает сверхвысокую плотность хранения и стабильность без энергозатрат на поддержание данных, в отличие от современных SSD и HDD. Исследователи обратили внимание на междисциплинарный характер проведенных работ, которые объединили физику, биологию, информатику и материаловедение. Долгосрочная цель — создать компактное устройство размером с обычную USB-флешку, способное хранить огромные объёмы данных надёжно и энергоэффективно. Кстати, в производстве нанопор также возник прорыв, но это уже другая история. Приложения для Smart TV незаметно выкачивают интернет, чтобы обучать ИИ-модели
01.03.2026 [12:57],
Владимир Фетисов
Компании, которые собирают открытые данные из интернета для обучения ИИ-моделей, всё активнее ищут новые источники трафика. Одна из них — Bright Data, оператор глобальной прокси-сети. Компания выпустила SDK для приложений Smart TV, позволяющий использовать телевизоры пользователей для сбора веб-данных. 
Источник изображения: techspot.com Как выяснилось, код Bright Data обнаружили в ряде приложений для смарт-телевизоров. После запросов журналистов разработчики этих программ либо отказались от комментариев, либо удалили интеграцию прокси из своих приложений. Bright Data позиционирует свою платформу как инструмент для превращения веб-сканирования в структурированную систему «доставки данных». На практике это означает, что веб-трафик клиентов компании может маршрутизироваться через домашние интернет-подключения обычных пользователей. В рекламных материалах утверждается, что SDK обеспечивает «100-процентную монетизацию» аудитории при сохранении привычного пользовательского опыта. SDK встраивается в приложения для Smart TV, после чего пользователю предлагается согласиться на участие в прокси-сети. Если согласие получено, соединение может использоваться для передачи стороннего трафика через его домашний интернет-канал. Собранные таким образом данные затем поступают на серверы Bright Data и продаются компаниям, работающим в сфере ИИ. В компании заявляют, что SDK не собирает личные данные напрямую и что участие полностью добровольное — пользователь может отказаться в любой момент. Bright Data продолжает сотрудничать с экосистемами смарт-телевизоров на базе Tizen OS и webOS. По данным источника, функциональность прокси-сбора веб-данных потенциально может присутствовать в сотнях приложений для этих платформ. iPhone и iPad стали первыми потребительскими устройствами, допущенными к секретным данным НАТО
27.02.2026 [00:29],
Николай Хижняк
Компания Apple объявила, что смартфоны iPhone и планшеты iPad стали первыми потребительскими устройствами, одобренными для использования в секретных сетях НАТО. Это означает, что стандартный iPhone под управлением iOS 26 может получить доступ к ограниченным данным НАТО без необходимости использования какого-либо специализированного программного обеспечения безопасности или модификации оборудования. 
Источник изображения: MacRumors «Это достижение подтверждает, что Apple изменила традиционный подход к обеспечению безопасности. До iPhone защищённые устройства были доступны только государственным и корпоративным организациям после масштабных инвестиций в специализированные решения по безопасности. Вместо этого Apple создала самые защищённые устройства в мире для всех своих пользователей, и теперь эти же средства защиты уникальным образом сертифицированы в соответствии с требованиями безопасности стран НАТО, в отличие от любых других устройств в отрасли», — прокомментировал в заявлении для 9to5Mac Иван Крстич (Ivan Krstić), вице-президент Apple по проектированию и архитектуре безопасности. Для сертификации подобного уровня недостаточно просто выпустить хорошо защищённую операционную систему — это длительный и непрерывный процесс, отмечает издание. Ранее iPhone и iPad получили разрешение на обработку секретных данных правительства Германии с использованием встроенных механизмов безопасности iOS и iPadOS. Это стало результатом всесторонней оценки, технических исследований и глубокого анализа безопасности, проведённых Федеральным управлением по информационной безопасности Германии (Bundesamt für Sicherheit in der Informationstechnik, BSI). Теперь, опираясь на это одобрение BSI, iPhone и iPad под управлением iOS 26 и iPadOS 26 официально сертифицированы для использования во всех странах НАТО. Устройства под управлением iOS 26 и iPadOS 26 также официально включены в Каталог продуктов обеспечения информационной безопасности НАТО. Сертификацию устройства Apple прошли благодаря критическим функциям безопасности, уже встроенным в каждый современный iPhone и iPad:
«Безопасная цифровая трансформация будет успешной только в том случае, если информационная безопасность учитывается с самого начала разработки мобильных продуктов. После тщательной проверки безопасности платформ и устройств iOS и iPadOS со стороны BSI для использования в секретных информационных средах Германии, мы рады подтвердить соответствие [этих устройств] требованиям стран НАТО по обеспечению безопасности», — заявила Клаудия Платтнер, президент BSI. Anthropic обвалила акции CrowdStrike и Cloudflare, представив ИИ-багхантера Claude Code Security
21.02.2026 [09:52],
Анжелла Марина
Рынок кибербезопасности отреагировал падением акций на новость о выходе инструмента Claude Code Security от компании Anthropic. По сообщению SiliconANGLE, акции CrowdStrike и Cloudflare просели примерно на 8 %, поскольку инвесторы увидели в новинке серьёзного конкурента традиционным средствам защиты. 
Источник изображения: Anthropic Главное отличие Claude Code Security от классических инструментов поиска уязвимостей в том, что он не полагается на базы данных с готовыми правилами. Вместо этого нейросеть анализирует логику работы приложения, отслеживает потоки данных и связи между компонентами, имитируя подход специалиста по безопасности. Такой метод позволяет находить проблемы, которые могут быть пропущены при использовании стандартных средств из-за ограничений статических баз. Для начала работы разработчикам необходимо подключить Claude Code Security к репозиторию на платформе GitHub и инициировать сканирование. Система способна определять широкий спектр проблем, включая отсутствие фильтрации пользовательского ввода, что может привести к выполнению несанкционированных SQL-команд. Инструмент также находит более сложные логические ошибки, позволяющие злоумышленникам обходить механизмы аутентификации приложений. Найденные уязвимости автоматически ранжируются по степени значимости. Для каждой проблемы генерируется подробное объяснение на естественном языке, что ускоряет процесс анализа инцидента специалистами. Под описанием ошибки также доступна функция создания патча, которая позволяет профессионалам в области кибербезопасности получить готовый вариант исправления кода от искусственного интеллекта. Стоит отметить, что запуск Claude Code Security состоялся примерно через четыре месяца после того, как OpenAI представила свой автоматизированный инструмент безопасности под названием Aardvark. Он обладает схожими возможностями и, по заявлениям разработчиков, тестирует уязвимости в изолированной программной среде для оценки сложности их эксплуатации хакерами. Эксперты полагают, что в будущем Anthropic и OpenAI могут пойти дальше и интегрировать свои системы в пайплайны разработки (CI/CD), чтобы автоматически блокировать выкатку кода с «дырами» в безопасности для ускорения выпуска продукта. ИИ помог Google заблокировать тысячи разработчиков и удалить миллионы сомнительных приложений в 2025 году
19.02.2026 [23:14],
Николай Хижняк
Google заблокировала в прошлом году более 1,75 млн приложений, нарушающих правила, и не допустила их загрузки в свой магазин приложений Play Store. Компания также удалила более 80 тыс. учётных записей разработчиков, пытавшихся опубликовать вредоносные приложения. Свежим отчётом поделился Виджая Каза (Vijaya Kaza), вице-президент Google по вопросам доверия к приложениям и экосистемам. 
Источник изображения: Google Для поиска потенциально вредоносных приложений Google активно использует искусственный интеллект. Компания заявляет, что внедрила модели ИИ непосредственно в процесс проверки приложений. Рецензенты-люди по-прежнему участвуют в этом процессе, но ИИ помогает выявлять сложные вредоносные схемы гораздо быстрее, чем человек мог бы вручную проверять код. Компания также усилила меры защиты конфиденциальности. В прошлом году Google заблокировала более 255 тыс. приложений, запрашивающих слишком много конфиденциальных данных. Разработчики также получают помощь от таких инструментов, как Play Policy Insights в Android Studio, которые указывают на возможные проблемы ещё на этапе написания кода. Google также ведёт активную борьбу со спамом. В 2025 году компания заблокировал 160 млн спам-оценок и отзывов, включая фейковые пятизвездочные отзывы и организованные попытки занизить рейтинг приложений. Google заявляет, что предотвратила падение рейтинга в среднем на 0,5 звезды для приложений, ставших мишенью для так называемой «бомбардировки отзывами». Усиление защиты распространяется не только на магазин Play Store. Google Play Protect, встроенный в Android сканер вредоносных программ, теперь проверяет более 350 млрд приложений каждый день. В прошлом году сканирование в режиме реального времени обнаружило 27 млн новых вредоносных приложений, доступных за пределами Google Play. Если вы когда-либо устанавливали приложение с ненадёжного веб-сайта, вы могли видеть предупреждение. Это работа Play Protect. Эффективность этой функции также постоянно совершенствуется. Улучшенная защита от мошенничества теперь блокирует установки из интернет-источников (через браузеры и мессенджеры), которые запрашивают чувствительные разрешения. В 2025 году функция была запущена на 185 рынках, охватывая 2,8 млрд устройств, и предотвратила 266 млн попыток установки рискованных приложений. Google также внесла изменения для борьбы с мошенническими звонками. Если вы разговариваете по телефону, Play Protect теперь не даёт отключить защиту. Это связано с тем, что мошенники часто пытаются убедить людей отключить защиту, чтобы получить доступ к данным на устройстве. Теперь этот метод больше не работает. |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



