
Опрос
|
реклама
Быстрый переход
Слепой тест аудиокабелей за $4250 и $7 показал самый ожидаемый результат
30.03.2026 [19:46],
Сергей Сурабекянц
Слепой тест, проведённый Audio Science Review, в очередной раз подтвердил, что единственное, что аудиокабель за несколько тысяч долларов передаёт эффективнее, чем кабель за $7 — это огромная сумма денег со счёта пользователя в карманы производителя. В тесте использовался кабель от Kimber Kable, хотя тот же результат, скорее всего, будет получен с кабелем любого именитого бренда. 
Источник изображений: Audio Science Review Из-за своей субъективности индустрия высококачественной аудиотехники спекулирует на утверждениях, что посеребрённые проводники и алмазные матрицы каким-то образом могут сделать звучание джазового фортепиано трёхмерным. Однако анализ, проведённый Амиром Маджидимехром (Amir Majidimehr) из Audio Science Review, в очередной раз подтвердил несостоятельность обещаний производителей «золотых» кабелей. В процессе тестирования сравнивались кабель Kimber Kable Select KS-1136 стоимостью $4250 и дешёвый RCA-кабель Amazon Basics за $7,19.  Результаты оказались катастрофическим провалом для люксового бренда: тестовое оборудование показало, что оба кабеля работают практически одинаково. Фактически, дорогой кабель продемонстрировал даже немного больший уровень наводок от сети, чем его конкурент за 7 долларов. По всем значимым показателям, таким как сдвиг фазы, передача прямоугольного импульса и частотный диапазон, два кабеля оказались идентичны. Единственное измеримое различие заключалось в микроскопическом увеличении джиттера (нежелательные фазовые или частотные отклонения передаваемого сигнала) у кабеля Amazon, что, вероятно объясняется просто большей его длиной. Кабель Kimber позиционируется с использованием терминологии, обычно применяемой к редким космическим минералам, в то время как кабель Amazon — просто как способ передачи аудиосигнала. Однако, как показывает исследование, физика передачи звука остаётся практически неизменной, независимо от маркетинговых уловок. Более того, кабель Kimber оказался хуже с точки зрения базовой эргономики. Он оснащён специальным механизмом фиксации, который при неумелом отключении может привести к поломке разъёма усилителя. Кроме того, внутри него были обнаружены «хлипкие пластиковые защёлки», качество которых исследователи оценили ниже, чем у кабеля Amazon. Хотя некоторые аудиофилы утверждают, что с помощью сверхдорогого кабеля они могут услышать дополнительный воздух или брызги слюны, вылетающие из саксофона Сэчмо, слепое тестирование показало, что в основном они ощущают эффект плацебо. Для тех, кто хочет улучшить свой домашний кинотеатр, выводы очевидны: купите кабель за $7 и потратьте оставшийся бюджет на что угодно другое. Windows 11 научилась передавать стереозвук на Bluetooth-наушники во время звонков
28.08.2025 [00:22],
Анжелла Марина
Microsoft объявила о внедрении в Windows 11 24H2 новой функции улучшения звука в беспроводных наушниках с поддержкой Bluetooth LE Audio. Это обновление устраняет давнее ограничение, при котором использование встроенного микрофона гарнитуры или наушников автоматически переводило звук в монорежим. Теперь совместимые устройства смогут одновременно передавать широкополосный стереозвук (Super Wideband Stereo, SWS) при частоте дискретизации 32 кГц и работать с микрофоном. 
Источник изображения: Laurent Jollet / Unsplash Это существенное улучшение для пользователей, которые часто совершают голосовые и видеозвонки, используя Bluetooth-гарнитуры. Ранее система переключалась на монофонический звук из-за технических ограничений стандарта. Как пишет Tom's Hardware, новая функция гарантирует, что звук останется стереофоническим независимо от активности микрофона. Правда, для работы функции требуется как совместимое Bluetooth-устройство, поддерживающее стандарт LE Audio, так и актуальная версия операционной системы — Windows 11 версии 24H2 или новее. При этом в Microsoft отмечают, что это не отменяет преимуществ специализированных игровых гарнитур с собственным беспроводным подключением 2.4 ГГц, где ключевым фактором является малая задержка, но, по крайней мере, решает проблему с качеством звука. Параллельно Microsoft анонсировала внедрение технологии 3D-аудио — пространственного звука в приложении Microsoft Teams. Эта функция создаёт эффект полного погружения в звук, имитируя трёхмерный звуковой ландшафт во время звонков и позиционируя голоса участников в соответствии с их расположением на экране. Как заявляют в компании, 3D-аудио способствует лучшей концентрации внимания и позволяет легче следить за ходом обсуждения. В Китае создали микрофон для записи звука с помощью света — даже через стекло и звукоизоляцию
05.08.2025 [21:04],
Геннадий Детинич
Дистанционная запись звука с помощью лазерного луча, направленного на вибрирующую поверхность, — давно известный шпионский приём. В Китае учёные разработали более простую систему записи звука в условиях звукоизоляции. Она дешевле и проще в реализации, поэтому подходит для гражданского применения — например, для наблюдения за пациентами или спасения людей из-под завалов. 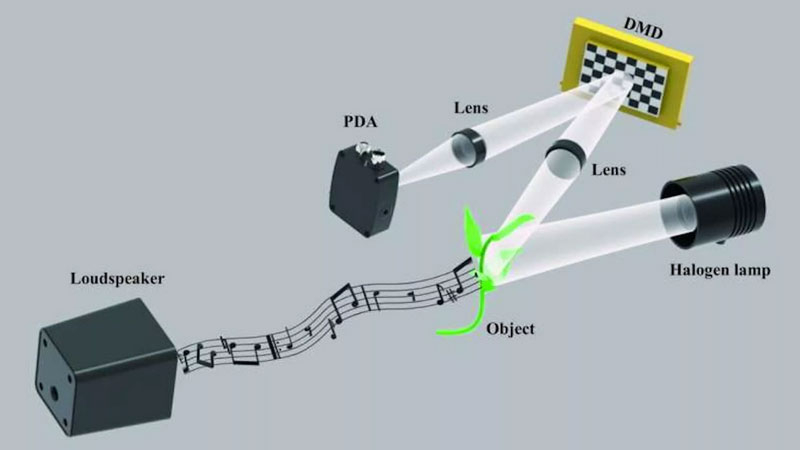
Схема эксперимента. Источник изображения: Beijing Institute of Technology «Визуальный микрофон», как назвали разработку исследователи из Пекинского технологического института (Beijing Institute of Technology), улавливает световые сигналы и не нуждается в приёме звуковых волн — он извлекает звук из вибрирующих поверхностей, отражающих свет. В лабораторных условиях учёные восстановили звук по колебаниям бумажной открытки и листьев комнатного растения. В обоих случаях машинная обработка сигнала позволила получить чистый звук, сопоставимый с записью на обычный микрофон. «Наш метод упрощает и удешевляет использование света для записи звука, а также позволяет применять его в ситуациях, где традиционные микрофоны неэффективны – например, при разговоре через стеклянное окно, — поясняют исследователи. — Пока есть возможность пропускать свет, передача звука не требуется». Ранее попытки записывать звук с помощью света основывались на применении сложного и дорогостоящего оборудования — лазеров или высокоскоростных камер. Команда из Китая выбрала другой подход: в их системе используется технология однопиксельной съёмки, устраняющая необходимость в датчике изображения с миллионами пикселей. Вместо этого применяется один световой детектор и структурированные световые паттерны, проецируемые пространственным световым модулятором. «Сочетание однопиксельной визуализации с методами локализации на основе преобразования Фурье позволило нам добиться высокоэффективного обнаружения звука с использованием более простого и дешёвого оборудования, — отмечают учёные. — Наша система позволяет улавливать звуки с помощью повседневных объектов — таких как бумажные открытки и листья комнатных растений – при естественном освещении и без необходимости в специфическом отражающем покрытии поверхности». По сути, метод заключается в проецировании контролируемого света на объект и улавливании малейших изменений яркости отражённого света, возникающих при вибрации объекта под воздействием звуковых волн. Эти колебания фиксируются и с помощью вычислительных алгоритмов преобразуются в звуковой сигнал. Такой подход не только снижает стоимость и техническую сложность, но и делает технологию более доступной. Система также создаёт относительно небольшой поток данных — около 4 Мбайт в секунду, что делает её подходящей для долговременной или непрерывной записи, а также практичной для хранения или передачи по интернету. Высокие частоты распознаются с меньшей точностью, чем низкие, но полностью восстанавливаются алгоритмами. Предложенный метод открывает новые возможности прослушивания в условиях, с которыми обычные микрофоны не справляются — например, при общении через стекло или мониторинге в звукоизолированных помещениях. Кроме того, система может помочь в поиске людей под завалами, когда звуковые волны блокируются. Windows 11 «заговорила» голосом Vista: Microsoft объяснила курьёзный сбой звука загрузки ОС
16.06.2025 [14:23],
Сергей Сурабекянц
Многочисленные участники программы тестирования Windows Insider сообщают о том, что Microsoft по ошибке заменила звук загрузки Windows 11 в тестовых версиях ОС на звук запуска из Windows Vista, выпущенной в 2007 году. Оказалось, что в предварительной сборке Windows под номером 26200.5651 файл со звуком загрузки, который хранится в системной библиотеке imageres.dll, был заменён на звук запуска Windows Vista. 
Источник изображения: Microsoft Первые сообщения об этой странности тестировщики Windows начали замечать ещё 13 июня вскоре после выпуска последней сборки Windows 11 на канале Dev Channel. Microsoft быстро признала ошибку и добавила описание проблемы в свои заметки о выпуске для последней сборки. «Эта неделя полёта идёт с восхитительным приветом из прошлого и будет воспроизводить звук загрузки Windows Vista вместо звука загрузки Windows 11, — с юмором прокомментировал проблему представитель команды Windows Insider. — Мы работаем над исправлением». Разработчик из команды Windows Insider Брэндон Леблан (Brandon LeBlanc) сообщил в соцсети X, что это он «зашёл и повеселился со звуковыми файлами в Windows, так как подумал, что людям нужен привет из прошлого», но затем отказался от своих слов и подтвердил, что это на самом деле просто ошибка. Журналисты The Verge предположили, что, возможно, один из инженеров Microsoft слишком много ностальгировал о Windows Vista после появления нового дизайна Apple Liquid Glass, который весьма схож с интерфейсом Aero Glass в Windows Vista. Samsung и Google выпустят бесплатный заменитель Dolby Atmos в этом году
04.01.2025 [13:01],
Владимир Фетисов
Компании Samsung и Google намерены собственными силами продвигать технологию пространственного звука Eclipsa Audio. Позднее в этом году поддержка данного формата появится в некоторых роликах на YouTube, а также будет реализована во всех саундбарах и телевизорах Samsung 2025 года. 
Источник изображения: Samsung Eclipsa Audio является передовой технологией пространственного звука, которая позволяет создавать реалистичное и объёмное звучание, а также даёт возможность авторам контента осуществлять настройку основных параметров, включая расположение звука в пространстве, его интенсивность и др. В конечном счёте Eclipsa Audio может стать бесплатной альтернативой технологии Dolby Atmos, за использование которой производителям приходится платить лицензионные отчисления. Samsung и Google объявили о партнёрстве, в рамках которого ведётся разработка новой технологии 3D-звука, в 2023 году. Первоначально этот проект носил имя Immersive Audio Model and Formats (IAMF) и уже тогда было объявлено, что основой разработки станет открытый исходный код. Спецификация IAMF также была принята организацией Alliance for Open Media, которая с 2015 года занимается разработкой и внедрением открытых видеоформатов, и в которую входят Amazon, Apple, Microsoft, Netflix, Samsung и Google. В сообщении также сказано, что Samsung и Google совместно с Ассоциацией телекоммуникационных технологий работают над созданием программы сертификации для «обеспечения стабильного качества звука» на всех устройствах, использующих новый формат. Более детальная информация о технологии Eclipsa Audio может появиться в течение ближайших дней, поскольку уже 7 января в Лос-Анджелесе начнётся ежегодная выставка CES 2025, в рамках которой Samsung представит новые продукты. Apple показала лаборатории, где тестирует аудио- и видеовозможности следующих iPhone
31.12.2024 [16:10],
Николай Хижняк
Apple недавно пригласила журналиста портала CNET Патрика Холланда (Patrick Holland) посетить свои специализированные лаборатории в Купертино, где инженеры компании тестируют и проводят калибровку аудио- и видеовозможностей смартфонов iPhone 16. 
Источник изображений: Celso Bulgatti / CNET Одним из мест, которые посетил Холланд, стала длинноволновая безэховая камера, где стены, потолок и пол покрыты специальными звукопоглощающими клиньями из вспененного материала для устранения эффекта эха. Объект используется для тестирования четырех микрофонов iPhone 16, которые, несмотря на свой небольшой размер, спроектированы для обеспечения профессионального качества звука.  «iPhone — это настолько распространённое записывающее устройство, которое используется в самых разных условиях, что мы хотим быть уверены, что наши пользователи смогут запечатлеть свои воспоминания в самой истинной своей форме. Мы выбрали подход, сочетающий качество и практичность. В этих рамках мы разработали новый компонент микрофона, который позволяет нам обеспечивать одни из лучших акустических характеристик в телефонном продукте. В то же время [мы] разработали такую функцию, как Audio Mix, которая предоставляет пользователям гибкость, возможность записывать различные звуки, а также даёт творческую свободу в редактировании, чтобы настроить звук так, как вам нравится», — объяснил в разговоре с представителем портала CNET старший директор по акустическим технологиям в Apple Ручир Дэйв (Ruchir Dave).  В ходе тестирования звуковых возможностей своих смартфонов Apple использует сложный набор динамиков, которые воспроизводят звуки колокольчиков, пока iPhone, установленный на специальную подставку в центре безэховой камеры, вращается, создавая таким образом сферический звуковой профиль. Эти данные формируют основу для таких функций, как пространственное аудио и Audio Mix, которые позволяют пользователям настраивать записанный звук для имитации различных типов микрофонов. В отдельных звукоизолированных студиях Apple проводит сравнительные тесты воспроизведения записанных звуков с несколькими тестерами, чтобы гарантировать постоянное качество звучания у iPhone. 
Источник изображения: Celso Bulgatti / CNET Изюминкой тура стала лаборатория проверки видеовозможностей смартфонов размером с кинотеатр. В этом помещении инженеры Apple калибруют производительность дисплея в различных условиях освещения. 
Источник изображения: Patrick Holland / CNET В помещении установлен огромный экран, который имитирует то, как видео выглядит на дисплеях iPhone, независимо от того, просматривается ли оно в условиях тёмной комнаты, пространства офиса или при ярком солнечном свете. Представлен ПК для аудиофилов за €28 000 — оперативная память с «лучшим качеством звука», два Intel Xeon и пассивное охлаждение
10.12.2024 [16:51],
Павел Котов
Нидерландский производитель высококачественного аудиооборудования Taiko Audio представил безвентиляторный музыкальный сервер Extreme, предназначенный для хранения аудиофайлов в форматах без потери качества, а также потоковой трансляции с помощью таких сервисов как Tidal. Его цена начинается от €28 000 за вариант с накопителем на 2 Тбайт. 
Источник изображений: taikoaudio.com Компьютер комплектуется двумя процессорами Intel Xeon Scalable с пассивной системой охлаждения на 240 Вт, которая гарантирует ему бесшумную работу. Два процессора позволяют ему использовать выделенные подсистемы для самостоятельных процессов — один чип отвечает за пользовательский интерфейс на базе Windows 10 Enterprise LTSC 2019, из которой исключили всё кроме необходимого для прослушивания музыки; второй — за работу музыкального менеджера Roon.  Для работы операционной системы используется SSD Intel Optane ёмкостью 280 Гбайт, а для хранения данных предусмотрен накопитель на 2 Тбайт, который за дополнительные €1850 можно расширить до 64 Тбайт. Объем оперативной памяти составляет 48 Гбайт — и это 12 планок по 4 Гбайт, потому что «меньший объём и низкая скорость DIMM лучше для качества звука».  За качество звука здесь отвечает и специальный блок питания мощностью 400 Вт на конденсаторах Mundorf и Duelund, которые, по версии производителя, не оказывают влияния на звучание. Для подключения внешних устройств предусмотрены пять портов USB, два медных порта Ethernet, оптический SFP, разъём VGA, порт S/PDIF, и один порт AES/EBU в двух- или четырёхканальной конфигурации.  Nvidia представила ИИ-модель Fugatto, которая «понимает и генерирует звук, как это делают люди»
25.11.2024 [18:33],
Сергей Сурабекянц
Nvidia представила новую экспериментальную генеративную модель ИИ, которую компания описывает как «швейцарский армейский нож для звука». Модель Fugatto (Foundational Generative Audio Transformer Opus 1) использует текстовые подсказки для генерации новых или изменения существующих музыкальных, голосовых и звуковых файлов. В создании модели принимали участие разработчики со всего мира, что усилило «многоакцентные и многоязычные возможности модели». 
Источник изображения: Nvidia «Мы хотели создать модель, которая понимает и генерирует звук, как это делают люди», — рассказал участник проекта и менеджер по прикладным исследованиям звука в Nvidia Рафаэль Валле (Rafael Valle). Компания предложила несколько сценариев, в которых модель Fugatto может оказаться востребованной:
Исследователи утверждают, что модель при некоторой дополнительной тонкой настройке также может выполнять задачи, не входившие в её предварительное обучение. Модель может объединять отдельные инструкции, например, генерировать речь с определёнными интонациями и акцентом или звук пения птиц во время грозы. Модель также умеет генерировать изменяющиеся со временем звуки, например, шум приближающегося ливня или удаляющегося поезда. Fugatto не является первой технологией генеративного ИИ, которая может создавать звуки из текстовых подсказок. Ранее Meta✴✴ выпустила аналогичную модель ИИ с открытым исходным кодом. Google предлагает ИИ-инструмент собственной разработки для преобразования текста в музыку MusicLM, доступ к которому можно получить через сайт компании AI Test Kitchen. Nvidia пока не предоставила публичный доступ к Fugatto и воздержалась от комментариев на этот счёт. Adobe показала проект Super Sonic для создания звуковых эффектов для видео при помощи ИИ
15.10.2024 [18:05],
Сергей Сурабекянц
На ежегодной конференции Max компания Adobe продемонстрировала экспериментальный проект Super Sonic — прототип программного обеспечения на основе ИИ, которое может превращать текст в аудио, распознавать объекты и голос автора для быстрого создания звуковых эффектов и фонового аудио для видеопроектов. 
Источник изображения: Adobe «Мы хотели дать нашим пользователям контроль над процессом, […] выйти за рамки первоначального рабочего процесса преобразования текста в звук, и именно поэтому мы работали над таким аудиоприложением, которое действительно даёт вам точный контроль над энергией и синхронизацией и превращает его в выразительный инструмент», — рассказал руководитель отдела ИИ Adobe Джастин Саламон (Justin Salamon). Super Sonic использует ИИ для распознавания объектов в любом месте видеоряда, чтобы создать запрос и сгенерировать нужный звук. В другом режиме инструмент анализирует различные характеристики голоса и спектр звука и использует полученные данные для управления процессом генерации. Пользователю необязательно использовать голос, можно хлопать в ладоши, играть на инструменте или извлекать исходный звук любым другим доступным способом. Стоит отметить, что на конференции Max компания Adobe традиционно представляет ряд экспериментальных функций. В дальнейшем многие из них попадают в Adobe Creative Suite. Super Sonic может стать полезным дополнением, например, к Adobe Premiere, но пока дальнейшие перспективы проекта неясны, и он остаётся в статусе демонстрационной версии. Ранее разработчики Super Sonic участвовали в разработке функции генеративного ИИ Firefly под названием Generative Extend, которая позволяла удлинять короткие видеоклипы на несколько секунд, включая звуковую дорожку. Возможность создавать звуковые эффекты из текстового запроса или голоса — полезная функция, но далеко не новаторская. Многие компании, такие как ElevenLabs, уже предлагают подобные коммерческие инструменты. Представлена технология DTS Clear Dialogue, которая повысит чёткость диалогов в фильмах и сериалах
04.09.2024 [13:49],
Павел Котов
У любителей домашнего просмотра кино и сериалов иногда возникают жалобы на то, что диалоги персонажей звучат слишком тихо — они просто теряются на фоне звуковых эффектов и музыкального сопровождения. Решение проблемы предложила компания DTS, представившая технологию Clear Dialogue. 
Источник изображения: Mohamed Hassan / pixabay.com Функция DTS Clear Dialogue представляет собой «основанное на искусственном интеллекте решение, разработанное для повышения чёткости разговорных диалогов на телевизорах». Предложенный компанией алгоритм ИИ распознаёт и усиливает диалоги в звуковых потоках, избавляя любителей домашнего видео от попыток решить эту проблему изменением настроек звука, положения звуковой панели или даже включением субтитров. Система DTS Clear Dialogue позволяет даже персонализировать настройки звука, потому что идеальное звучание для одного человека не всегда оказывается таковым для другого. DTS Clear Dialogue представляет собой пакет инструментов для конечного устройства, то есть его поддержкой придётся озаботиться производителям телевизоров. Компания пока не сообщила, кто будет пользоваться новым решением, но среди её партнёров числятся такие марки как Sony, Hisense, Philips и LG. Работу системы Clear Dialogue компания DTS намеревается продемонстрировать на выставке IFA в Берлине. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



