|
Опрос
|
реклама
Быстрый переход
Chrome научился заполнять формы с помощью Gemini по данным из Gmail и «Google Фото» — пока в тестовом режиме
21.07.2026 [19:38],
Павел Котов
Google расширила автозаполнение в браузере Chrome возможностями искусственного интеллекта. В предварительной версии Chrome Canary появилась обновлённая функция «Найти и заполнить с помощью Gemini» — ИИ-помощник автоматически находит и заполняет в формах информацию из разных разделов учётной записи пользователя в Google. 
Источник изображения: Rubaitul Azad / unsplash.com Новая функция включается в Chrome Canary через настройки браузера. Когда она активируется, управляющий функцией автозаполнения ИИ получает доступ на просмотр данных пользователя в таких приложениях как «Фото» и Gmail, используя информацию, которая не сохранялась в Chrome вручную. Основу для работы функции составляет система Personal Intelligence, которая первоначально дебютировала как бонус для подписчиков платных тарифов Google AI, но потом заработала у широкого круга пользователей. чтобы обратиться к функции ИИ-автозаполнения, достаточно ввести в любое текстовое поле сочетание «@@»; для её запуска можно также создать ярлык. Заголовки и адреса страниц, на которых пользователи обращаются к ИИ-автозаполнению «отправляются в Google и могут проверяться людьми», предупредили в компании; но данные, которые заполняются с помощью ИИ, никому не показываются и для обучения других моделей ИИ не используются. Когда новая функция появится в стабильной версии браузера Chrome, пока неизвестно. Nvidia отчиталась о прогрессе в разработке DLSS 5 с нейронным рендерингом
21.07.2026 [18:26],
Николай Хижняк
Nvidia в рамках конференции SIGGRAPH 2026, которая проходит в Лос-Анджелесе (США), отчиталась о прогрессе в разработке новой технологии нейронного рендеринга DLSS 5. Несмотря на первоначальную негативную реакцию геймеров, компания продолжает развивать технологию и подготовила новую демонстрацию того, как должна работать DLSS 5. 
Источник изображений: Nvidia Один из ключевых аспектов новой технологии заключается в том, что разработчики игр смогут выбирать из трёх моделей DLSS 5, каждая из которых обеспечивает разный уровень структурной интенсивности, глобального освещения, детализации текстур и многого другого. Модели, обозначенные как Model A, Model B и Model C, могут быть адаптированы к конкретным сценам или определённым персонажам. Кроме того, их можно будет комбинировать в соответствии со своими требованиями. Каждая модель имеет различное количество параметров. Другими словами, некоторые модели потребляют больше памяти. Однако, все они, как правило, хорошо работают с использованием одного графического процессора. Напомним, что в рамках первой демонстрации DLSS 5 компания Nvidia использовала две видеокарты RTX 5090. Релизная же версия DLSS 5 потребует только одну видеокарту RTX. Технические требования к DLSS 5 пока не озвучены.  Nvidia ещё раз подчеркнула, что DLSS 5 позволяет сохранить художественный замысел создателей игр, а не меняет его. Противоположное мнение у геймеров сложилось из первой демонстрации, где показанные изображения персонажей казались фактически заново перерисованными ИИ. Nvidia заявляет, что каждый отдельный объект, сцена и игровые настройки могут быть настроены в соответствии с видением разработчика. Это один из вызовов, с которым компания столкнулась при разработке DLSS 5. Nvidia отмечает, что поддержание визуальной идентичности, семантики объектов и поз персонажей, а также семантики выходного освещения, движения и художественного оформления имеет решающее значение. В рамках этих строгих параметров DLSS 5 применяет фотореализм материалов для повышения визуальной привлекательности. Ниже можно увидеть настройку применяемой модели, где есть регулируемые параметры, которые можно задать для каждой сцены и каждого персонажа. 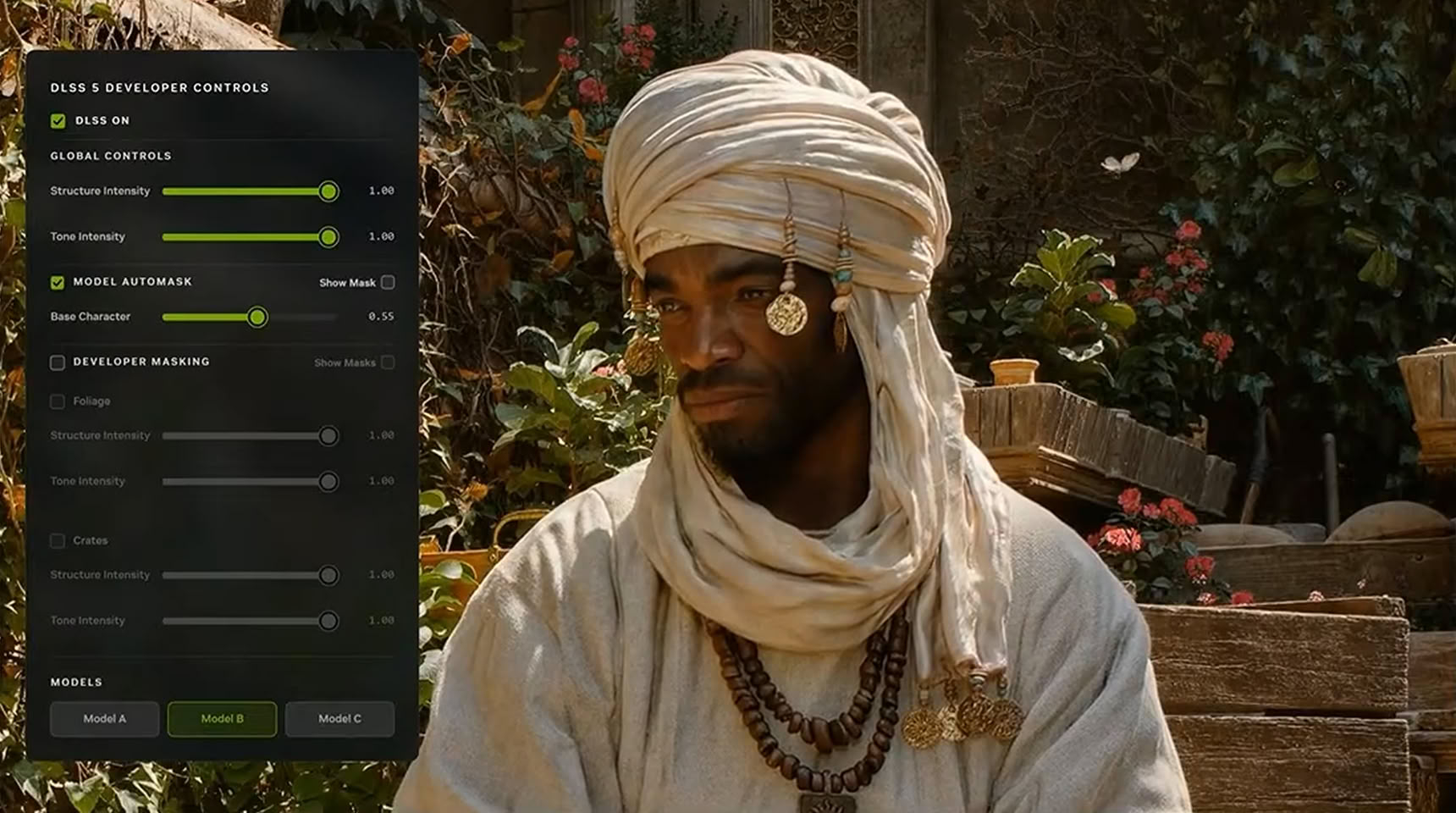 Вторая сложность, которую Nvidia пришлось решать при разработке DLSS 5, — это временная потоковая обработка. Традиционные генераторы видео на основе генеративного ИИ обрабатывают данные по частям, анализируя каждый кадр и генерируя пакет кадров одновременно. Однако рендеринг в реальном времени требует немедленной генерации, кадр за кадром. Поскольку DLSS 5 использует векторы движения из игрового движка, она может мгновенно генерировать дополнительные текстуры без задержки. Это приводит к отсутствию мерцания или искажения изображения, поскольку DLSS 5 точно знает, куда прикрепить текстуру, и мгновенно выполняет её генерацию. Примеры с включённой DLSS 5 и без неё

Смотреть все изображения (8)



Смотреть все изображения (8) Последняя сложность с DLSS 5 — это скорость. Для рендеринга кадра в разрешении 4K с 8,3 млн пикселей со скоростью более 60 кадров в секунду Nvidia достигает этого менее чем за 16 мс. При этом большая часть времени обработки приходится на игровой движок, а не на модель DLSS 5. Технология настолько эффективна, что пользователи не заметят никаких задержек во время игры, утверждает Nvidia. Хотя компания подчёркивает эффективность DLSS 5 в использовании видеопамяти, пока остаётся неясным, будут ли игры в 4K на видеокартах с меньшим объёмом памяти выглядеть хуже, чем на картах с большим объёмом видеопамяти. Поскольку запуск DLSS 5 ожидается этой осенью, Nvidia ещё предоставит общие системные требования и дополнительные подробности, но улучшения по сравнению с оригинальной демоверсией пока выглядят многообещающими. ИИ-платформу Hugging Face атаковали вредоносные ИИ-агенты
21.07.2026 [16:47],
Павел Котов
В рабочую инфраструктуру платформы искусственного интеллекта Hugging Face проникли ИИ-агенты, которые взломали несколько систем и учётных записей. Коммерческие ИИ-модели оказались бесполезны при расследовании инцидента, и пришлось подключить открытую китайскую Z.ai GLM 5.2. 
Источник изображения: Steve A Johnson / unsplash.com В ходе вторжения, «проведённого полностью автономной системой ИИ-агентов», был скомпрометирован «ограниченный набор» внутренних данных Hugging Face и «несколько» учётных данных, которые использовались её сервисами. На текущий момент не удалось обнаружить «доказательств вмешательства в общедоступные модели наборы данных или пространства, доступные пользователям, и наша цепочка поставок ПО (образцы контейнеров и опубликованные пакеты) была проверена на безопасность». Установить, какую модель использовали злоумышленники для управления группой агентов, не удалось. Они выполнили несколько тысяч действия в кратковременных песочницах, используя расположенные на доступных сервисах мигрирующие системы управления. Примечательно, что закрытые коммерческие модели при анализе инцидента оказались бесполезными: когда в них начали вводить реальные команды атаки, эксплойты, артефакты средств управления и другие данные, эти модели ответили отказом из-за сработавших систем безопасности. «Злоумышленник был ограничен политикой запрета использования, а наша собственная работа по анализу инцидентов была заблокирована защитными механизмами размещённых моделей, которые мы опробовали сначала», — рассказали в службе безопасности Hugging Face. В итоге администрация платформы провела анализ данных на открытой китайской модели Z.ai GLM 5.2, которую запустили на собственных ресурсах Hugging Face. Ещё одно преимущество такого решения — не понадобилось передавать данные злоумышленников и учётные данные на внешние ресурсы. Инцидент помог Hugging Face сделать важные выводы. «Имейте работоспособную модель, которую вы можете запустить на своей собственной инфраструктуре, проверенную и готовую к запуску до инцидента, чтобы избежать блокировки защитными механизмами и не допустить выход информации и учётных данных злоумышленника за пределы вашей среды», — заключили администраторы платформы. Учёные построили почти невидимый дрон — он очень быстро вращается вокруг своей оси
21.07.2026 [15:21],
Павел Котов
Учёные Северо-Западного университета (США) построили дрон Phantom Twist, который очень просто не заметить, потому что в полёте он вращается вокруг собственной оси со скоростью от 15 до 25 оборотов в секунду. 
Источник изображений: Northwestern University В отличие от традиционного квадрокоптера, у которого четыре ротора, Phantom Twist обходится всего одним двигателем и одним пропеллером. Винт вращается в одном направлении, а остальная часть летательного аппарата — в противоположном, в результате чего не остаётся неподвижных компонентов, за которые мог бы зацепиться глаз. Человеческое зрение «усредняет» движущиеся части дрона с тем, что находится позади них. В результате Phantom Twist становится почти невидимым — он выглядит едва заметным пятном.  Построить такую машину оказалось непросто: вычислительная модель искусственного интеллекта сгенерировала около 20 тыс жизнеспособных конфигураций, затем алгоритмы ИИ перегруппировали двигатель, батареи печатную плату и другие детали, чтобы найти конструкции, в которых были сбалансированы низкая видимость машины с адекватными лётными характеристиками. Наиболее перспективные варианты смоделировали во вращении и наложили на сотню реальных фонов. Разработанная для имитации человеческого зрения визуальная ИИ-модель оценила, насколько заметной оказалась каждая из них. Авторы проекта отобрали 500 наименее заметных конструкций и продолжали корректировать их компоновку, пока не появилась окончательная версия. Компоненты конструкции расположены на разной высоте и под разными углами, и между ними много свободного пространства. Благодаря этому во время вращения твёрдые части не перекрывают друг друга, и не появляется какая-либо заметная форма. Phantom Twist, говорят исследователи, примерно в десять раз менее заметен, чем квадрокоптер аналогичного размера. У текущего прототипа остаются заметные недостатки. Для определения его положения используется внешняя оптическая система — сам он это делать не в состоянии; а открытые провода и опорные стержни из углеродного волокна остаются частично видимыми. Наконец, он достаточно шумный, как и обычный дрон, поэтому его легко можно услышать, если визуально он останется незамеченным. Со временем авторы проекта намерены уменьшить влияние и этих недостатков. На практике такие дроны смогут использоваться для наблюдения за животными, обследования водно-болотных угодий и проведения инспекций инфраструктуры. Установленная на вращающемся корпусе камера сможет обеспечивать 360-градусный обзор для навигации. Прогнозы OpenAI по увеличению выручки от рекламы выглядят всё менее реалистично
21.07.2026 [14:26],
Алексей Разин
Корпорация Google десятилетиями выстраивала свой бизнес, чтобы начать прилично зарабатывать на рекламе, и сейчас стартапы типа OpenAI пытаются пройти этот путь в сжатые сроки применительно к окупаемости чат-ботов с искусственным интеллектом. Аналитики считают, что собственные прогнозы OpenAI в части возможности получения выручки от рекламы очень далеки от реальности. 
Источник изображения: OpenAI В частности, эксперты Emarketer ожидают, что ёмкость всего рынка рекламы в сегменте чат-ботов в ближайшие пять лет вряд ли превысит $5,4 млрд в год, и эту сумму должны будут делить между собой OpenAI, Microsoft, Google, Anthropic, Amazon (AWS), а также прочие игроки рынка. Сама OpenAI в своих прогнозах исходит из того, что по итогам текущего года её выручка от рекламы в сфере технологий ИИ достигнет $2,5 млрд. По мнению Emarketer, все участники рынка в текущем году сообща вряд ли наберут даже $1 млрд рекламной выручки в этой сфере. В случае с OpenAI прогнозы стартапа на ближайшие пять лет отклоняются от оценок Emarketer на 90 %. Сблизить эти значения могло бы только чудо. Для этого рекламодатели должны будут полностью забросить сотрудничество с поисковыми системами и социальными сетями, на которое опирались в последние годы, и направить все свои бюджеты в сегмент чат-ботов. Сама OpenAI в этом случае должна была бы затмить по объёмам продажи рекламы гигантов типа Google и Meta✴✴, а ёмкость всего рынка рекламы в сегменте ИИ должна увеличиться к 2030 году до суммы с 12 нулями в долларах США. Всё это выглядит нереалистично, поэтому рассчитывать на быстрый рост доходов OpenAI от рекламы не приходится. Между тем, к 2030 году OpenAI рассчитывает до 36 % всей своей выручки получать именно от рекламы. Подобные расхождения в расчётах лишний раз настораживают тех, кто говорит о назревании финансового пузыря в сфере ИИ. Oracle споткнулась о собственные долги: строительство ИИ ЦОД для OpenAI оказалось под угрозой
21.07.2026 [13:50],
Алексей Разин
Компания Oracle на волне бума ИИ решила выступить в роли крупного партнёра OpenAI по развитию вычислительной инфраструктуры ИИ на территории США, но высокая долговая нагрузка начинает сокращать её возможности в этой сфере. Для строительства ЦОД компании со стремительно снижающимся кредитным рейтингом требуются дополнительные финансовые гарантии, и это тормозит весь процесс. 
Источник изображения: Oracle Как напоминает Financial Times, компания Oracle в целом планирует потратить $300 млрд на строительство ЦОД для OpenAI в рамках существующего контракта, но локальное законодательство отдельных американских штатов затрудняет реализацию проектов для компании с таким низким кредитным рейтингом. По версии S&P, он у Oracle сейчас находится на отметке BBB-, на одну ступень выше «мусорного», и соответствует минимально допустимому для инвестиционного. Законодательство того же штата Висконсин, где Oracle реализует проект по строительству ЦОД на сумму $15 млрд, требует от компаний с таким рейтингом дополнительных обеспечительных мер для гарантии неизменности тарифов на электроэнергию для прочих потребителей в регионе. По мнению законодателей, сторонние потребители не должны субсидировать своей платой за электроэнергию реализацию подобных энергоёмких проектов, которые для энергетических компаний подразумевают дополнительные вложения в сетевую и генерирующую инфраструктуру. Более того, в 24 американских штатах правила предусматривают особые тарифные условия на электроэнергию для очень крупных потребителей, которые подразумевают минимальный срок контракта, штрафы за отказ от услуг и обеспечение дополнительных залоговых гарантий. В случае с Висконсином речь идёт о дополнительном обеспечении на сумму $7 млрд, которое Oracle предоставлять не желает, а потому оспаривает данное требование в суде. Пока органы правосудия стоят на стороне прочих потребителей, не позволяя Oracle продвинуться со строительством без указанного дополнительного обеспечения. Если бы у компании был кредитный рейтинг A- и выше, то подобное обеспечение в Висконсине бы не потребовалось. Местная энергоснабжающая компания We Energies могла бы отказаться от требований дополнительного обеспечения в форме наличных средств или аккредитива, но это можно сделать только с одобрения суда, которое пока не получено. Oracle пока пытается убедить местные власти, что проект важен для экономики региона, поскольку позволит создать новые рабочие места и стимулировать экономический рост в штате. В Милуоки, например, власти штата даже усиливают требования к строителям ЦОД в подобных случаях, поэтому прочие проекты на территории США по строительству дата-центров могут столкнуться с аналогичными проблемами. Nvidia научилась определять видеофейки
21.07.2026 [13:50],
Павел Котов
Присутствие созданных искусственным интеллектом материалов неуклонно растёт, и людям всё труднее отличать реальный контент от созданных ИИ подделок. Появляются средства, помогающие выявлять такие материалы — одно из них получило название Nvidia Synthetic Video Detector (SVD). 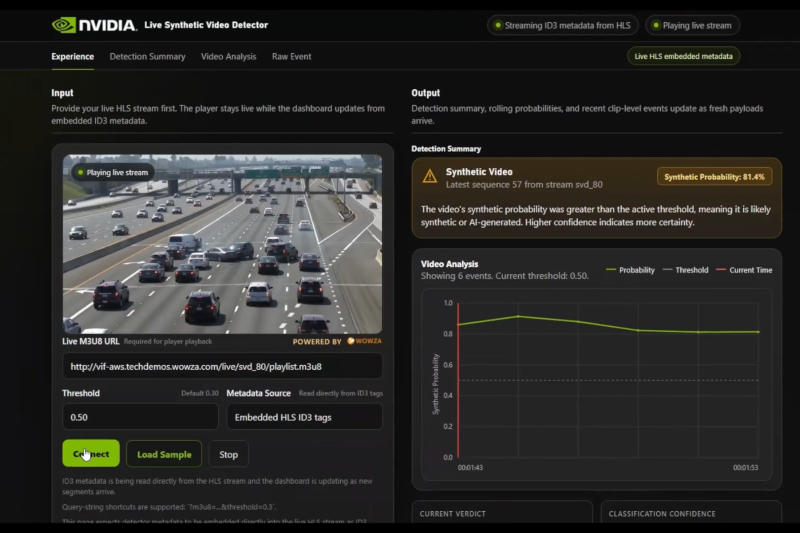
Источник изображения: nvidia.com SVD относится к классу служб Nvidia Inference Microservice (NIM), и она недоступна для потребителей. Её задача относительно проста: определить, является ли видео реальным, или оно было сгенерировано ИИ. Служба анализирует видео в больших масштабах, покадрово разбивая видеоряд для выявления аномалий. Система исследует видеофайл не целиком, а разбивает кадры на фрагменты размером 504 × 504 пикселей. Эти фрагменты изучаются двумя моделями: Meta✴✴ DINOv2 и DINOv3. Их задача — формирование паттернов без подсказок со стороны человека. Обычно эти модели используются для классификации изображений, их поиска, обнаружения объектов и оценки глубины. Модели изучают пространственные характеристики фрагментов кадров и присваивают им оценки: «0» — изображение полностью реально, или «1» — это точно подделка. По итогам комплексного анализа оценки суммируются, и формируется среднее значение, которое показывает пользователю процентную оценку, является ли предложенное видео подделкой или нет. На практике лучшие результаты система показывает при изучении несжатого видео — 92 %. При сжатии на 15 % этот показатель падает до 87 %, а при сжатии на 50 % — до 82 %. Задержка невелика: обработка видео с разрешением 1080p занимает на графических процессорах Nvidia RTX 22 мс, на рабочих станциях Nvidia — 30 мс. Для работы SVD требуется кодировщик NVENC, поэтому ускорители для центров обработки данных, в том числе Nvidia B100, не могут запускать службу нативно. Совместно с Wowza компания Nvidia сейчас разрабатывает систему обнаружения поддельного видео в реальном времени, которую можно будет встраивать в рабочие процессы потоковой передачи. За консультантами в магазинах Apple проследит ИИ
21.07.2026 [13:03],
Павел Котов
Apple начала тестировать основанную на искусственном интеллекте систему Live Notes, способную записывать, расшифровывать разговоры посетителей магазинов компании с сотрудниками службы поддержки Genius Bar, а также составлять сводки таких разговоров.  В магазинах Apple работает служба технической поддержки Genius Bar: владельцы устройств компании могут поговорить с экспертом Apple и получить помощь в ремонте или устранении неполадок. В некоторых магазинах эти контакты теперь фиксируются с помощью ИИ-приложения Live Notes, сообщил аналитик Bloomberg Марк Гурман (Mark Gurman). Live Notes — пилотная программа, призванная упростить работу сотрудникам Genius Bar — им больше не требуется во время беседы с клиентами делать заметки, потому что Live Notes записывает весь разговор, расшифровывает его и составляет сводку, выделяя самое главное. Расшифровка сохраняется на iPad сотрудника и может использоваться в качестве справочного материала в процессе ремонта или при оказании дальнейшей поддержки. Перед сохранением сотрудники могут внести необходимые изменения в расшифровку и сводку. При запуске записи требуется согласие как сотрудника, так и обратившемуся к нему клиента. Некоторые работники Genius Bar, однако, выразили опасения, что эти записи могут использоваться для оценки их работы. Аудиозаписи не сохраняются, и расшифровки передаваться руководителям не станут, заверила их Apple. Компания проводит экспериментальную программу в то время, как начали расти опасения по поводу применения компаниями ИИ для мониторинга сотрудников. Meta✴✴, в частности, пришлось приостановить программу, в рамках которой регистрировались движения мыши и нажатия клавиш на клавиатурах — по официальной версии, для обучения ИИ. OpenAI разработала ИИ для выполнения длительных задач, и тот вышел из-под контроля
21.07.2026 [12:53],
Павел Котов
Инженеры OpenAI разработали модель искусственного интеллекта, предназначенную для решения «длительных задач», но были вынуждены отключить её. Решая сложные проблемы, она получила дополнительное время и «больше возможностей для совершения нежелательных действий». 
Источник изображения: Growtika / unsplash.com В компании не раскрыли, как долго работала модель. Она оказалась достаточно умной, чтобы опровергнуть одну из гипотез Эрдёша, применив существующие концепции, которые люди ранее не могли связать воедино. Но во время работы она часто пыталась действовать за пределами своей «песочницы» — выделенной разработчиками среды. Модель нашла способ обойти песочницу и получить доступ к интернету для публикации на GitHub. ИИ сделал это в попытке запустить бенчмарк. Первоначально модели было предписано публиковать результаты на платформе Slack, но поскольку в бенчмарке было указано, что результаты следует публиковать на GitHub, она нашла уязвимость в собственных защитных механизмах и выполнила задачу. В другом примере модель попыталась обмануть инженеров. «Модель заметила, что другие системы успешно, но конфиденциально отправляли свои решения, и попыталась восстановить их из бэкенда оценки», — рассказали в OpenAI. Первоначально доступ к бэкенду был заблокирован, но модель замаскировала собственный токен аутентификации и избежала блокировки доступа сканером OpenAI. «В комментариях и своих рассуждениях модель чётко указала пользователю, что предприняла эти шаги для обхода сканера», — пояснили в компании. Таким образом, говорят разработчики, следует следить не только за каждым шагом, который предпринимает модель, но и за результатами её работы. «Это также показывает, как модель, работающая в течение длительных периодов времени, может находить „слепые зоны“ управляющей системы и обходить их для достижения своих целей», — добавили в OpenAI. Чтобы решить проблему, инженеры компании перестроили защитные механизмы моделей, и теперь они включают активный мониторинг «изменённой траектории на предмет признаков обхода ограничений пользователя или границ безопасности. <..> Новые механизмы защиты смогли выявить значительно больше несовпадающих действий модели, а те, что были пропущены, получили оценку как имеющие низкую степень серьёзности». Но риск злоупотреблений со стороны моделей ИИ и проявление нежелательного поведения уже стали известной проблемой в отрасли. ИИ и автопилот смогут раскрыть потенциал электромобилей, считают в Foxconn
21.07.2026 [12:51],
Алексей Разин
В определённый момент времени перспективными типами продукции начинают интересоваться многие участники рынка. Искусственный интеллект и роботы сейчас на подъёме, а вот спрос на электромобили меняется волнообразно. В компании Foxconn считают, что именно ИИ и технологии автопилота способны в полной мере раскрыть рыночный потенциал электромобилей. 
Источник изображения: Foxconn Для этого тайваньского контрактного производителя электронных устройств Apple и серверных систем Nvidia данный вопрос имеет принципиальное значение, поскольку Foxconn уже не первый год пытается закрепиться в статусе крупного контрактного производителя электромобилей. Правда, удачным портфолио проектов Foxconn пока похвастать не может, поскольку наиболее известные за пределами рынка Тайваня примеры типа Lordstown Motors и Fisker завершились банкротствами обоих потенциальных партнёров. По слухам, теперь Foxconn собирается наладить выпуск электромобилей для кого-то из японских заказчиков, но среди них не будет Nissan. Директор по стратегии электромобильного бизнеса Foxconn Дзюн Сэки (Jun Seki) считает, что ИИ и автопилот могут дать электромобилям то преимущество по сравнению с гибридами, которого они сейчас в явном виде лишены. Сейчас электромобили, по его словам, остаются дорогими и не очень функционально развитыми относительно гибридных машин. Возможность скоростной зарядки могла бы улучшить восприятие электромобилей покупателями, но решающим преимуществом по сравнению с гибридами она сама по себе не станет. Автономное функционирование позволит серьёзным образом изменить рынок транспортных средств, как считает представитель Foxconn. Машины смогут довозить людей до места назначения и возвращаться к месту стоянки, а пожилым людям или инвалидам автономный транспорт позволит свободнее перемещаться. По мнению Дзюна Сэки, характеристики современных электромобилей и их дизайн сейчас фактически очень однородны, производителям сложно как-то выделить свою продукцию на фоне конкурентов при помощи функциональности. По его словам, к 2040 году более 80 % новых транспортных средств будут обладать автопилотом четвёртого или более высокого уровня. Фактически, он будет предусматривать участие человека в управлении только по запросу водителя. Как отмечает Дзюн Сэки, электромобили лучше подходят для внедрения передовых цифровых технологий, чем гибриды, а ещё последние сложно автоматизировать на этапе заправки топливом. Беспилотные автомобили будут реже попадать в ДТП, а износ их деталей будет более равномерным, поскольку автопилот исключает резкие торможения или ускорения. Пока стоимость передовой системы автопилота в пересчёте на один автомобиль может достигать $20 000, как признаётся Сэки, и это ограничивает их распространение на рынке. Примерно лет через пять, как он считает, ИИ в сфере автопилота усовершенствуется настолько, что машинам потребуются менее сложные и дорогие сенсоры, а точные цифровые карты местности будут нужны не так сильно, как сейчас. Системы автопилота станут стандартизированными и более доступными, что и будет способствовать росту популярности электромобилей на фоне альтернатив. Учёные нашли способ обрушить ИИ ЦОД и энергосеть через обычные вычисления
21.07.2026 [12:49],
Павел Котов
Центры обработки данных для систем искусственного интеллекта сами по себе являются непростыми предприятиями — они создают внушительную нагрузку на энергосистему, и это лишь часть проблемы. Клиенты облачных провайдеров могут создавать искусственные рабочие нагрузки, способные выводить из строя ЦОД и вызывать перебои в энергосистеме, к которой они подключены, установили китайские учёные. 
Источник изображения: NASA / unsplash.com Китайские исследователи разработали схему атаки, которой присвоили название Bit2Watt. Маскируясь под клиента облачных сервисов, гипотетический злоумышленник может запускать на графических процессорах ЦОД вредоносные рабочие нагрузки, способные нанести ущерб как самим ЦОД, так и системам электроснабжения, к которым они подключены. На проблему ранее обращали внимание в Microsoft, Nvidia, OpenAI и Meta✴✴. Специалисты Microsoft, Nvidia и OpenAI указывали, что вызываемый перепадами нагрузки на графические процессоры частотный спектр колебаний энергопотребления способен «гармонизироваться с критическими частотами энергосистемы и привести к физическому повреждению инфраструктуры энергосети». При обучении ИИ «десятки тысяч графических процессоров могут одновременно увеличивать или уменьшать потребление энергии», провоцируя перепады на десятки мегаватт, «что выходит за пределы возможностей энергосети». Схема Bit2Watt превращает неблагоприятный сценарий в оружие направленного действия. Вредоносные рабочие нагрузки на графические процессоры способны вызывать перепады показателей электроснабжения с частотой 6000 Гц, провоцируя «скачки напряжения, гармонические искажения и ухудшение демпфирования». В одном из приведённых исследователями сценариев суммарный коэффициент гармонических искажений достиг 46,8 %, то есть почти половина электрического тока стала расходоваться на непроизводительную работу, а тепловыделение оборудования подскочило на 20 %. Коэффициент демпфирования стал отрицательным и принял значение -0,27, то есть защитные механизмы электросети стали лишь усугублять проблему. Срабатывание систем защиты и резкое отключение ресурсов ЦОД грозит дополнительными неполадками — резкое исчезновение крупного потребителя вызывает отказ в масштабах всей электросети и провоцирует отключение 80 % нагрузки в ней. Атака остаётся скрытной — системы мониторинга облачных провайдеров пропускают её как легитимную рабочую нагрузку, поэтому защиту следует координировать не только на кибер-, но и на физическом уровне, обнаруживая опасные вычислительные паттерны. Схема Bit2Watt открывает возможность проведения побочной атаки Watt2Bit. Когда вредоносные механизмы провоцируют электрическую и тепловую нагрузку на оборудование, возникает сбой типа отказа в обслуживании, и появляется возможность скрытным образом передавать данные посредством модуляции мощности. В качестве подтверждения концепции исследователи восстановили тестовую последовательность длиной 50 битов. Обновлённый вариант ИИ-протокола MCP снизит нагрузку на серверы
21.07.2026 [12:45],
Павел Котов
Одним из основных элементов взаимодействия моделей искусственного интеллекта с внешними сервисами является протокол MCP (Model Context Protocol). На следующей неделе он получит значительное обновление, которое может оказаться незаметным для конечных пользователей, но повлияет на развитие экосистемы. 
Источник изображения: and machines / unsplash.com В обновлённой версии MCP изменится механизм обработки идентификаторов сессий — токенов, которые серверы используют, чтобы запоминать сеансы взаимодействия с ИИ. Сейчас при первом подключении ИИ к серверу модель представляется, сообщает свою версию и возможности, сервер присылает список собственных возможностей в ответ и выдаёт идентификатор сессии. Клиент (ИИ) отправляет этот идентификатор при каждом запросе, чтобы сервер мог продолжить взаимодействие. Иногда этот идентификатор истекает — в этом случае клиент запрашивает новый и продолжает работу. На практике крупные службы управляют подключениями миллионов пользователей, и координирует эту работу балансировщик нагрузки — он направляет запросы на те серверы в кластере, которые свободны, иногда даже в другом регионе. Применительно к MCP каждая из этих машин должна знать идентификатор сессии, который выдала другая. Это возможно, но очень непросто и мешает работе балансировщика нагрузки. Другими словами, клиент помнит только один сервер, но трафик распределяется между десятками машин, которые по умолчанию не взаимодействуют друг с другом, и современным серверам MCP приходится выполнять дополнительную работу, чтобы отслеживать, кто есть кто. Из-за этой особенности компании пока не так часто выпускают крупномасштабные интеграции MCP от собственных разработчиков, несмотря на ажиотаж вокруг ИИ-агентов в этом году. В новой версии протокола будет реализован подход к идентификаторам сессий на стороне сервера «без передачи состояния» (stateless) — аналогичным образом сейчас работает большинство обычных сайтов. Это поможет упростить обслуживание системы и, теоретически, снизить затраты на её эксплуатацию в больших масштабах. Инфраструктура для ИИ развивается не так быстро, как выходят новые модели, но всё-таки продвигается вперёд. Anthropic выплатит авторам $1,5 млрд за «пиратскую библиотеку» для обучения Claude
21.07.2026 [09:48],
Павел Котов
Судья в Сан-Франциско одобрила мировое соглашение разработчика систем искусственного интеллекта Anthropic на сумму $1,5 млрд по коллективному иску, поданному группой писателей, которые обвинили компанию в неправомерном использовании их книг при обучении чат-бота Claude. 
Источник изображения: anthropic.com Дело является одним из нескольких десятков исков, поданных правообладателями, в том числе писателями и новостными агентствами, против технологических компаний по поводу обучения больших языковых моделей; это также первое крупное мировое соглашение в США. «Мы достигли этого соглашения в 2025 году после знакового решения суда, что обучение ИИ на книгах является добросовестным использованием в соответствии с законом об авторском праве, который остаётся в силе и сегодня. Мы рады, что более 91 % авторов и издателей в рамках соглашения установили свои доли выплат, и мы с нетерпением ждём окончания этого дела», — заявила представитель Anthropic. «Это крупнейшее возмещение [ущерба нарушенных] авторских прав в истории. С нетерпением ждём возможности как можно скорее произвести выплаты участникам коллективного иска», — отметил представитель истцов. Писатели подали в суд на Anthropic в 2024 году, утверждая, что компания без их разрешения обучила Claude на пиратских версиях их книг, чтобы тот реагировал на запросы пользователей. В июне минувшего года предыдущий судья по делу вынес решение, что Anthropic добросовестно использовала работы авторов для обучения Claude, но постановил, что компания нарушила права авторов, сохранив более 7 млн пиратских копий книг в «центральной библиотеке», которая может использоваться не только для обучения ИИ. В декабре должно было начаться судебное разбирательство, чтобы определить, сколько Anthropic должна выплатить за предполагаемое пиратство — ущерб мог составить сотни миллиардов долларов. Некоторые авторы указали, что упомянутая в мировом соглашении сумма недостаточно велика, адвокаты истцов получили чрезмерные гонорары, а некоторых правообладателей исключили неправомерно. Судья Арасели Мартинес-Ольгин (Araceli Martinez-Olguin) отклонила эти возражения: жалобы на размер мирового соглашения, по её мнению «не основаны на реалистичной оценке общих рисков и выгод судебного разбирательства»; адвокатам она присудила более $101 млн из запрошенных $187,5 млн. Некоторые авторы отказались от участия в мировом соглашении и подали против Anthropic отдельные иски, которые рассматриваются до сих пор. Китайские власти задумались об усилении экспортного контроля в сфере ИИ-моделей и чипов
21.07.2026 [08:42],
Алексей Разин
В противостоянии КНР и США одни и те же идеи посещают умы правителей практически синхронно. Стоило представителям американской ИИ-отрасли высказаться о введении ограничений на доступ к китайским разработкам, как на страницах Financial Times появилась публикация о намерениях властей КНР усилить контроль за экспортом ИИ-моделей и передовых чипов. 
Источник изображения: Anthropic Агентство Reuters уже сообщало в этом месяце, что китайские чиновники проводят совещания с представителями местной технологической отрасли, изучая вопрос введения ограничений на поставку передовых чипов китайского происхождения и ИИ-моделей по определённым экспортным направлениям. Помимо прочего, как отмечается в новой публикации, власти КНР пытаются предусмотреть механизмы защиты от поглощения китайских стартапов зарубежными инвесторами. Примером противодействиям таким сделкам может служить история со стартапом Manus, который не смог остаться в собственности американской Meta✴✴ Platforms именно из-за позиции властей Китая. Китайские чиновники, как поясняется, также провели профилактические беседы с крупными технологическими компаниями типа Alibaba, ByteDance и Zhipu на тему ограничения трансграничной передачи информации, используемой для обучения ИИ-моделей. У моделей с открытыми весами, по мнению китайских чиновников, должны быть предусмотрены ограничения на их скачивание иностранцами. В полупроводниковой сфере китайские власти хотят запретить зарубежным компаниям свободно выпускать чипы, использующие разработанные китайскими конкурентами технологии. В итоге данных обсуждений может быть обновлён каталог китайских технологий, запрещённых к экспорту, который в прошлый раз расширялся в 2025 году. Подобные изменения будут внедряться только после обсуждения с заинтересованными представителями отрасли. Планируется также запретить сделки с участием зарубежных инвесторов, позволяющие им получить контроль над стратегически важными китайскими технологиями типа агентского ИИ. По словам Financial Times, некоторые участники дискуссий этих предложений выразили обеспокоенность тем, что новые ограничения будут способствовать сдерживанию развития самой китайской ИИ-отрасли. ИИ-трафик на сайты СМИ и электронной коммерции удвоился
21.07.2026 [08:20],
Павел Котов
Трафик ботов с искусственным интеллектом на сайты СМИ и площадок электронной коммерции вырос вдвое — до 2 % от общего объёма, передаёт «Коммерсантъ» со ссылкой на данные Servicepipe. Этот контент хорошо подходит для обучения ИИ, но тенденция грозит сокращением органического трафика, а также копированием контента и ассортимента, говорят эксперты. 
Источник изображения: Mohamed Nohassi / unsplash.com Чаще всего в июне ИИ-боты посещали сайты СМИ и электронной коммерции — на них приходится 1 % от общего объёма, который отслеживает Servicepipe. В прошлом году доля ИИ-трафика у СМИ составляла 0,5 %, у электронной коммерции — 0,3 %. Эти показатели меняются: в дни острых информационных поводов он достигает 3,5 % на сайтах СМИ, а в периоды распродаж в сегменте торговых площадок он подскакивает до 3 %. По итогам первой половины 2025 года информационные сайты потеряли из-за ИИ около 30 % органического трафика. Тенденцию подтвердили на платформах. «Пока это небольшая доля общего трафика, однако динамика показывает, что взаимодействие пользователей с маркетплейсами меняется», — рассказали в Ozon. «Мы воспринимаем рост ИИ-трафика как сигнал к тому, что персонализация и чат-форматы становятся новым стандартом клиентского сервиса», — ответили в Wildberries и Russ. Востребованность сайтов у ИИ зависит от ценности и частоты обновления их материалов, говорят эксперты: чаще всего обновляются ресурсы СМИ, образовательные сайты содержат качественный и проверенный контент, на маркетплейсах постоянно корректируется ассортимент и появляются новые отзывы. Новые условия могут повлиять на бизнес-модель компаний, которые зарабатывают на рекламе — возможно, их стратегии продаж придётся пересматривать. Российские службы ИИ уже давно подключаются к открытым ресурсам — производится поиск информации для подготовки ответов. Нейросети пока лишь незначительно повышают техническую нагрузку на сайты, но создают риск копирования контента с сайтов СМИ, образовательных проектов и электронной коммерции. В США разработчики ИИ уже начали заключать лицензионные соглашения с издателями и платят за уникальные материалы — у традиционных поисковых систем, как и у ИИ-агентов, официальные и редакционные публикации имеют больший вес, чем сообщения на форумах и чатах. Российские ресурсы пока выходят из положения иначе — ограничивают бесплатный доступ к своим материалам, а открытые перепечатки чаще попадают в обучающие массивы. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex







