|
Опрос
|
реклама
Быстрый переход
iOS 27 принесёт тройку мощных ИИ-функций для iPhone
10.11.2025 [23:20],
Николай Хижняк
Apple уже активно ведёт разработку операционной системы iOS 27, выпуск которой ожидается в следующем году, пишет Марк Гурман (Mark Gurman) из Bloomberg. По данным аналитика издания, компания делает акцент в новой ОС на трёх ключевых направлениях, связанных с искусственным интеллектом. 
Источник изображения: Apple На прошлой неделе Гурман в своей колонке Power On намекнул, что будущие операционные системы — iOS 27, macOS 27 и другие — «будут сопровождаться крупными обновлениями Apple Intelligence и более широкой стратегией в области ИИ». Никаких подробностей он тогда не привёл. Одним из самых ожидаемых обновлений в экосистеме ИИ Apple является улучшенная версия голосового помощника Siri. Аналитики предполагают, что эти изменения появятся уже в версии iOS 26.4, которая ожидается в марте–апреле будущего года. В свою очередь, презентация iOS 27 состоится в июне. По мнению Гурмана, Apple в iOS 27 сделает акцент на новом визуальном дизайне Siri, инструменте веб-поиска на базе ИИ, а также на ИИ-агенте, который будет помогать пользователям следить за своим здоровьем. «Как я уже говорил, в iOS 26.4 ожидается появление новой Siri. Новый дизайн голосовой помощник получит в iOS 27. Также планируется создание инструмента веб-поиска на базе ИИ. Но давайте сосредоточимся на функции, о которой я давно не рассказывал: обновлённом приложении “Здоровье” с новым сервисом Health+. Оно будет включать ИИ-агента, помогающего пользователям следить за своим здоровьем. В случае успеха этот сервис может сделать Apple одной из первых крупных технологических компаний, набирающих обороты в сфере чат-ботов для здравоохранения на базе ИИ», — написал Гурман в свежей колонке. В отличие от различных улучшений Apple Intelligence в iOS 26, большинство из которых представляют собой довольно незначительные обновления, грядущие изменения в iOS 27, связанные с ИИ, выглядят потенциально гораздо более значимыми. Гендиректор Nvidia попросил TSMC нарастить производство чипов из-за высокого спроса на ИИ-ускорители
08.11.2025 [16:45],
Владимир Фетисов
Генеральный директор Nvidia Дженсен Хуанг (Jensen Huang) заявил, что обратился к руководству тайваньской TSMC с просьбой увеличить объем поставляемых чипов в условиях сохраняющегося высокого спроса на ИИ-ускорители. Об этом он рассказал в недавней беседе с журналистами во время посещения ежегодного корпоративного спортивного мероприятия TSMC на Тайване. 
Источник изображения: Nvidia «Наш бизнес очень сильный и он продолжает ежемесячно расти, становясь всё более мощным», — добавил господин Хуанг. Он также отметил, что три поставщика чипов для Nvidia в лице компаний SK Hynix, Samsung Electronics и Micron уже значительно нарастили производственные мощности для обеспечения сохраняющегося уровня спроса. Генеральный директор TSMC Си Си Вэй (C.C. Wei) подтвердил, что во время очередной встречи Хуанг попросил увеличить поставки кремниевых пластин. Во время выступления на недавно прошедшем мероприятии Вэй сообщил сотрудникам, что TSMC ожидает сохранения рекордных объёмов продаж по итогам года. Также он отметил, что производственные мощности компании остаются очень загруженными, и TSMC пытается сокращать разрыв между спросом и предложением. Акции крупнейших технологических компаний на этой неделе пережили серьёзное падение, поскольку волна скептицизма среди инвесторов сменила эйфорию по поводу дальнейшего будущего сегмента искусственного интеллекта. Несмотря на это, Nvidia продолжает оставаться самой дорогой компанией мира, опережая Apple и Microsoft. В пятницу вечером Хуанг провёл встречу с Вэем, после чего выразил благодарность TSMC за оказанную поддержку, которая, по словам главы Nvidia, стала ключевым фактором успеха компании. «Без TSMC не было бы и Nvidia», — приводит источник слова Хуанга. ИИ-генератор видео Sora от OpenAI для Android скачали почти полмиллиона человек в первый день
07.11.2025 [05:19],
Николай Хижняк
Запуск приложения Sora для Android оказался весьма удачным. Согласно оценкам аналитической компании Appfigures, в первый день своего появления в магазине Google Play приложение для генерации видеоконтента с использованием искусственного компании OpenAI, разработчика ChatGPT, скачало более 470 тыс. человек на всех рынках, где оно было доступно. 
Источник изображения: OpenAI Цифры говорят о том, что запуск Sora на Android более чем в четыре раза превышает показатели на момент запуска приложения на iOS. При этом число установок приложения более чем втрое выше, но Appfigures отмечает, что это не прямое сравнение. На iOS приложение Sora было доступно только в США и Канаде, и только по приглашению. Версия для Android была выпущена в США, Канаде, Японии, Южной Корее, Тайване, Таиланде и Вьетнаме. В конце октября OpenAI отказалась от условия «доступ по приглашению» на всех своих основных рынках. Генератор видеоконтента с помощью ИИ стал настоящим хитом после своего дебюта, несмотря на свой прежний эксклюзивный статус. Приложение для iOS установили более миллиона раз за первую неделю после запуска, и оно быстро вырвалось на вершину App Store. Сегодня оно занимает 4-е место в рейтинге лучших бесплатных приложений для iPhone в App Store в США. Sora предлагает создание видео с помощью ИИ на основе подсказок пользователей (промптов). Видеоролики могут включать анимированных искусственным интеллектом пользователей и их друзей с помощью функции Cameos. Видео можно прокручивать в вертикальной ленте, как в TikTok. Таким образом, можно видеть, что другие пользователи делают с помощью этой технологии. Appfigures также пересмотрела свои предыдущие оценки количества загрузок приложения Sora на iOS в первый день. Изначально было подсчитано около 56 тыс. загрузок в первый день. Сейчас оценка приближается 110 тыс. При этом 69 300 установок приходятся на пользователей из США. Для сравнения, приложение Sora для Android было установлено в США примерно 296 тыс. раз. Общее количество установок составляет 470 тыс., что свидетельствует о сохраняющемся интересе к ИИ-видеоредактору даже после того, как первоначальный ажиотаж вокруг его запуска на iOS утих. Генератор видео от OpenAI будет конкурировать с приложением Vibes от Meta✴✴, которое в целом выполняет те же функции. Сегодня компания выпустила мобильное приложение Vibes в Европе. В США приложение дебютировало в августе. Через пару лет тестировать новые игры Square Enix будет по большей части генеративный ИИ
06.11.2025 [20:09],
Михаил Романов
Японский издатель Square Enix отчитался о прогрессе в реализации среднесрочной стратегии «Перезагрузка и пробуждение Square Enix». Теперь план включает оптимизацию процессов разработки с помощью генеративного ИИ. 
Источник изображения: Steam (D4riocodex) Как стало известно, Square Enix заключила партнёрство с лабораторией Мацуо-Ивасавы из Токийского университета для «повышения эффективности процессов разработки игр с помощью технологий ИИ». Инициатива получила название «Технология автоматизации разработки игр с помощью генеративного ИИ». Ей занимается группа из «более чем десяти человек», включая специалистов из Токийского университета и инженеров Square Enix. 
Источник изображения: Square Enix Целью нового партнёрства является автоматизация (другими словами, передача генеративному ИИ) к концу 2027 года 70 % задач по контролю качества и отладке программ в области разработки игр. По словам руководства Square Enix, использование технологии автоматизации нацелено на увеличение эффективности работы отдела по контролю качества и создание конкурентного преимущества на рынке. 
План Square Enix (источник изображения: Square Enix) Ранее руководство Square Enix обещало «агрессивно» использовать генеративный ИИ в разработке игр, но впоследствии сочло разумным применение технологии лишь в областях, не связанных с творчеством. Помимо автоматизации процессов разработки, инициатива «Перезагрузка и пробуждение Square Enix» включает меньше консольных эксклюзивов и переход от «количества к качеству» выпускаемых игр. OpenAI хочет занять триллион долларов на ИИ — и просит США взять на себя риски
06.11.2025 [18:49],
Сергей Сурабекянц
OpenAI, крупнейшая в мире частная компания, обратилась к правительству США с просьбой предоставить гарантии по кредитам для масштабного расширения своей инфраструктуры на сумму более чем триллион долларов. Финансовый директор OpenAI Сара Фрайар (Sarah Friar) объяснила, что государственная поддержка поможет привлечь инвестиции, необходимые для вычислений и инфраструктуры ИИ. 
Источник изображения: unsplash.com «Именно здесь мы ищем экосистему банков, частных инвестиций, а возможно, даже и государства», — заявила Фрайар. Она рассчитывает, что федеральные гарантии по кредитам «действительно снизят стоимость финансирования», что позволит OpenAI и её инвесторам привлекать больше средств по более низким ставкам для достижения амбициозных целей компании. Эта необычная для технологического гиганта из Кремниевой долины просьба теоретически может снизить стоимость заимствований OpenAI, поскольку правительство возьмёт на себя убытки в случае дефолта компании. Такие гарантии также значительно расширят круг потенциальных кредиторов OpenAI, поскольку многие банки и финансовые учреждения сталкиваются со строгими ограничениями на высокорискованное кредитование. Обращение OpenAI за государственной поддержкой происходит на фоне масштабных расходов на вычислительную инфраструктуру, что ставит под сомнение способность компании окупить эти инвестиции. По некоторым оценкам, только в этом году OpenAI заключила инфраструктурные сделки на сумму около одного триллиона долларов, включая партнёрство с Oracle на $300 млрд и проект Stargate на $500 млрд с Oracle и SoftBank. Ожидаемая в этом году выручка в десятки миллиардов долларов даже близко не покрывает вычислительные затраты, необходимые для поддержки продвинутых чат-ботов OpenAI. Фрайар опровергла сообщения о том, что OpenAI планирует вскоре выйти на биржу. «IPO пока не рассматривается», — сказала она, подчеркнув, что текущий приоритет компании — рост. В недавних сообщениях СМИ говорилось, что OpenAI готовится к публичному размещению акций после завершения сложной реструктуризации управления. Многие компании начали просить уволенных сотрудников вернуться — ИИ не оправдал ожиданий
06.11.2025 [18:22],
Сергей Сурабекянц
Вопреки продолжающейся шумихе вокруг ИИ, многие компании, сделавшие на него ставку и сократившие штат, стали планомерно возвращать уволенных сотрудников. По мнению аналитиков, это признак того, что технологии автоматизации пока не заменяют работников в тех масштабах, которых ожидали некоторые руководители. 
Источник изображения: unsplash.com Аналитическая компания Visier изучила данные о занятости 2,4 млн сотрудников из 142 компаний по всему миру. Около 5,3 % уволенных сотрудников впоследствии вернулись к предыдущему работодателю. Этот показатель оставался стабильным в течение нескольких лет, но недавно начал расти. Директор Visier Андреа Дерлер (Andrea Derler) полагает, что многие организации вынуждены возвращать людей на рабочие места, столкнувшись с практическими ограничениями инструментов ИИ. Эта тенденция подчёркивает несоответствие между ожиданиями в отношении технологий и операционными результатами. Хотя агенты на базе ИИ и системы цифрового управления персоналом расширяются во всех отраслях, выводы Visier показывают, что эти системы редко полностью заменяют человека. Они, как правило, автоматизируют лишь часть задач, что приводит к нехватке человеческих ресурсов, необходимых для управления этими новыми инструментами или их дополнения, в то время как затраты и сложность интеграции ИИ растут. Дерлер отметила, что многие руководители высшего звена просто не успели оценить фактические затраты на масштабное внедрение ИИ или определить, какие роли можно реально автоматизировать. Внедрение инфраструктуры ИИ — оборудования, систем обработки данных и систем безопасности — требует значительных капитальных затрат. Эти затраты часто превышают первоначальные прогнозы, что вынуждает руководство пересматривать фактическую окупаемость инвестиций по сравнению с удержанием квалифицированных сотрудников. Данные Visier согласуются с исследованием Массачусетского технологического института, которое показывает, что около 95 % организаций ещё не получили ощутимой финансовой отдачи от своих инвестиций в ИИ. Некоторые эксперты полагают, что последние тенденции расходов в секторе указывают на то, что «возможно, все эти деньги на самом деле тратятся не так уж и разумно». Стандартные меры по сокращению расходов, такие как увольнения, имеют скрытые последствия. По данным платформы для планирования персонала Orgvue, компании тратят примерно $1,27 на каждый доллар, сэкономленный за счёт сокращения персонала. Этот показатель включает выходные пособия, страхование по безработице и другие косвенные расходы, которые могут свести на нет экономию на заработной плате. Эти результаты указывают на существенные пробелы в планировании и завышенные ожидания от ИИ. Увольнения могут обеспечить краткосрочное улучшение баланса или улучшить инвестиционный имидж, но редко упрощают долгосрочные стратегии в области управления персоналом или технологий. В конечном итоге компании, переоценившие потенциал экономии от внедрения ИИ, могут столкнуться с необходимостью вернуть тех самых специалистов, которых уволили. ИИ разогнал рынок онлайн-рекламы и укрепил доминирование на нём IT-гигантов
06.11.2025 [18:08],
Сергей Сурабекянц
Технологические гиганты вкладывают значительные средства в развитие и продвижение искусственного интеллекта. ИИ помог существенно улучшить таргетинг рекламы, обеспечив компаниям доминирование на рынке рекламы. Результаты применения ИИ опровергли прогнозы участников рекламного бизнеса, ожидавших замедления роста рекламы в связи с тарифными войнами и снижением покупательной способности потребителей. 
Источник изображения: Joshua Earle / unsplash.com Значительные объёмы пользовательских данных, собираемых такими цифровыми платформами, как Facebook✴✴, Instagram✴✴ и YouTube, помогают брендам точнее таргетировать рекламу для своей аудитории. По данным аналитика Madison & Wall Брайана Визера (Brian Wieser), расходы на рекламу в США, включая политическую, в этом году вырастут более чем на 8,5 %. Он полагает, что при сохранении текущих тенденций роста расходы на рекламу в 2026 году в США могут вырасти на целых 10 %. ИИ помогает Meta✴✴ и Google дольше удерживать пользователей в таких приложениях, как Instagram✴✴ и YouTube, совершенствуя системы рекомендаций. По данным Meta✴✴, её системы рекомендаций на основе ИИ привели к увеличению времени, проведённого пользователями в Facebook✴✴ в третьем квартале, на 5 %, что соответственно увеличивает и количество демонстрируемой рекламы. Meta✴✴ стремится предоставить брендам возможность самостоятельно создавать и таргетировать рекламу с использованием генеративного ИИ к концу следующего года. По информации Google, инвестиции в ИИ-сводки для «Google Поиска» привели к увеличению количества запросов и поисковых чатов с ИИ, включая коммерческие запросы, что стимулирует продажи и рекламу. Компания заявила о планах по дальнейшему инвестированию в функции на базе ИИ, которые помогают авторам быстрее переходить от идеи к контенту. Google и Meta✴✴ внедрили инструменты для создания рекламы на основе ИИ, которые автоматизируют часть процесса запуска рекламных кампаний. Это позволяет заметно снизить затраты на производство рекламы, хотя результат не всегда хорошо принимается целевой аудиторией. Например, недавно Coca-Cola снова разочаровала общественность рождественской рекламой, сгенерированной ИИ. ИИ стимулирует рекламную индустрию и другими способами, в том числе упрощая создание новых стартапов, которые рано или поздно прибегают к запуску рекламных кампаний. Это новая глава в тенденции, которая началась с расцветом электронной коммерции, когда организации, работающие напрямую с потребителями, стали развиваться стремительными темпами. Демонстрация преимуществ ИИ крайне важна, поскольку инвесторы оказывают серьёзное давление на технологические компании, которые, в свою очередь, жалуются на недостаток вычислительных мощностей. По прогнозам Madison & Wall, в этом году на Meta✴✴, Google и Amazon придётся более 56 % рекламного рынка США по сравнению с 51 % два года назад. Google наконец разрешила Gemini рыться в письмах и документах в Gmail, «Диске» и Chat
05.11.2025 [23:21],
Николай Хижняк
Компания Google начала добавлять поддержку взаимодействия со своими фирменными сервисами в Google Gemini, — всего через месяц после того, как Microsoft начала предлагать аналогичные возможности тестировщикам Windows. 
Источник изображения: Google В среду Google заявила, что Gemini Deep Research теперь может подключаться к почте Gmail, облачному хранилищу «Google Диск» и приложению Chat, а также получать доступ к документам, презентациям, таблицам и PDF-файлам, хранящимся или пересылаемым в этих сервисах. «Эта новая мощная функция теперь доступна всем пользователям Gemini. Чтобы начать, просто выберите "Deep Research" в меню "Инструменты" в Gemini на компьютере и выберите источники. Внедрение этой функции начнётся в ближайшие дни для мобильных пользователей», — сообщила Google в своём блоге. Компания Microsoft в октябре объявила, что её собственный ИИ Copilot может начать читать Gmail и «Google Календарь» с помощью технологии Connectors, которая позволяет вручную предоставить доступ Copilot для сбора и анализа данных. На тот момент эта функция была доступна только участникам программы тестирования Windows Insiders. Неделю спустя Microsoft официально объявила, что эти же «коннекторы» позволят Copilot получать доступ к файлам OneDrive, контактам, электронной почте и событиям календаря Outlook, а также подключаться к сервисам Google, включая Google Drive, Gmail, «Google Календарь» и «Google Контакты». Однако Microsoft официально не сообщила, когда эти дополнительные возможности станут доступны пользователям, что дало Google преимущество первого выхода на рынок. В августе компания OpenAI кратко продемонстрировала возможность интеграции ChatGPT с Gmail. В октябре на мероприятии DevDay 2025 OpenAI показала, что ChatGPT может работать с такими приложениями, как Zillow и Canva, и запрашивать у них дополнительную информацию. В «Google Картах» появился ИИ-ассистент Gemini — главное не заболтаться и не пропустить свой поворот
05.11.2025 [19:09],
Сергей Сурабекянц
Появившийся в «Google Картах» ИИ-ассистент Gemini позволит пользователям повысить интерактивность взаимодействия с приложением. В отличие от существующего голосового помощника («Google Ассистента») Gemini сможет предоставить более подробную и персонализированную информацию. Ориентироваться станет намного проще благодаря новой функции навигации по ориентирам, которая будет использовать узнаваемые объекты в поле зрения водителя для подсказок о маршруте. 
Источник изображений: Google «Он [ИИ-ассистент Gemini] может рассказать вам о парковке, рассказать, как выглядит место, ответить на ваши вопросы в гораздо более интерактивной форме, — заявила директор по продуктам «Google Карт» Аманда Лейхт Мур (Amanda Leicht Moore). — Он также может интегрироваться со всеми функциями Gemini. Так что вы можете задавать ему вопросы о новостях или на любую другую тему». Ещё одно заметное улучшение «Google Карт» — это способ подсказок о маршруте. Обычно картографические приложения предупреждают о манёвре, указав расстояние («поверните налево через 100 метров»), что бывает сложно оценить водителям. Теперь система будет использовать видимые объекты, такие как светофоры, знаки «Стоп», заправочные станции или известные достопримечательности. Эти объекты будут подсвечиваться на карте по мере приближения. 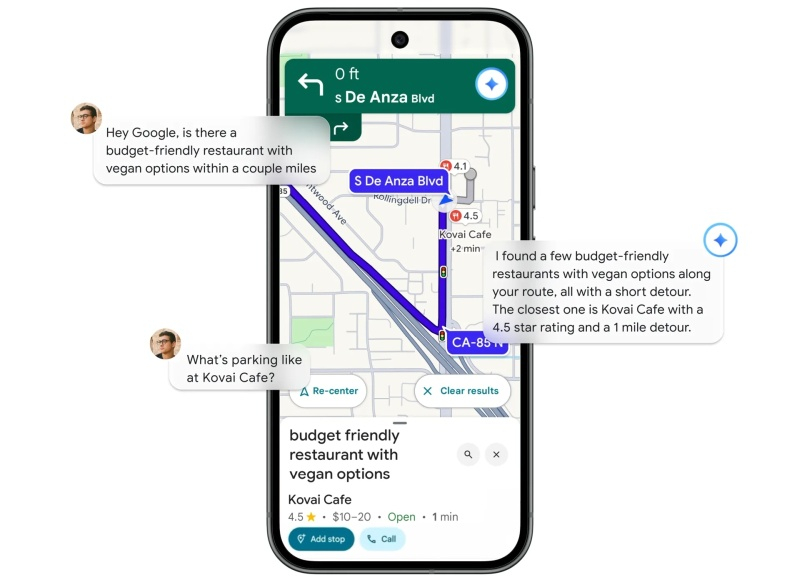 По словам Google, «Gemini анализирует актуальную и полную информацию “Google Карт” о 250 миллионах мест и сопоставляет её с изображениями Street View, чтобы отбирать наиболее полезные ориентиры, видимые с улицы, обеспечивая точность и полезность навигации». Интеграция с Gemini, естественно, вызывает опасения по поводу точности выдаваемой чат-ботом информации. Однако Google заявляет, что интеграция с Gemini «обоснована» и отображает только реальную информацию, основанную на данных карты. Google также обещает не использовать чаты в «Картах» для таргетинга рекламы. Навигация по ориентирам уже доступна для пользователей Android и iOS в США. Чат -бот Gemini появится в ближайшие недели в приложениях для Android и iOS. Компания работает над интеграцией с Android Auto, но пока неясно, появится ли он в Apple CarPlay из-за определённых программных ограничений. Ещё одно улучшение позволяет «Google Картам» предупреждать о пробках на дороге, даже при неактивном приложении. Эти «проактивные оповещения о дорожной обстановке» уже внедряются в США, но пока только на Android.  В конце октября Google расширила возможности ИИ в сервисе Google Earth для пользователей, имеющих статус «доверенных тестировщиков». К примеру, они могут попросить Gemini выявить закономерности на спутниковых снимках Земли при помощи простого текстового запроса. Ранее в Google Earth появились модели ИИ для выявления инфраструктуры, уязвимой для цунами, штормов и наводнений, или населённых пунктов, подверженных риску пылевых бурь во время засухи. Важная победа ИИ: Stability AI выиграла суд у Getty Images по делу об авторских правах
05.11.2025 [18:02],
Сергей Сурабекянц
Компания Stability AI, создатель популярного инструмента для генерации изображений Stable Diffusion, одержала победу над Getty Images в британском судебном процессе по вопросу нарушения авторских прав фотохостинга при обучении моделей ИИ. Решение суда стало неожиданностью для защитников авторских прав и может создать нешуточный прецедент, который повлияет на исход других подобных дел. 
Источник изображения: unsplash.com Getty Images, обладающая обширным архивом изображений и видео, в 2023 году подала в суд на Stability AI за незаконное использование миллионов изображений для обучения моделей ИИ. Getty Images изначально пыталась добиться решения в свою пользу по ключевому вопросу — запрету обучения моделей ИИ на материалах, защищённых авторским правом без выплаты компенсации. Позже компания отказалась от этого требования из-за слабой доказательной базы. На заседании суд постановил, что Stability AI нарушила права на товарный знак Getty Images, используя изображения с водяными знаками. Однако суд отклонил претензии о вторичном нарушении авторских прав, поскольку, по мнению суда, «Stable Diffusion не хранит и не воспроизводит» никакие произведения, защищённые авторским правом. Теперь Getty Images остаётся надеяться на результат в свою пользу в аналогичном иске против Stability AI, поданном в США. Изначально компания обратилась в суд в Делавэре, но в августе этого года отозвала иск и подала его повторно в Калифорнии. Число подобных исков неуклонно растёт. Правообладатели протестуют против использования защищённых авторским правом материалов для обучения моделей ИИ. Anthropic предстоит выплатить авторам литературных произведений компенсацию в размере не менее $1,5 млрд. Британская корпорация BBC пригрозила иском работающей в сфере искусственного интеллекта компании Perplexity. Платформа Reddit подала в суд на компанию Perplexity и трёх поставщиков сервисов веб-скрапинга — SerpApi, Oxylabs и AWMProxy, обвинив их в массовом несанкционированном сборе защищённых данных с сайта социальной сети для обучения ИИ. Компанию Apple истцы обвиняют в использовании «теневых библиотек», содержащих тексты нелегальным образом полученных книг, для обучения фирменного сервиса Apple Intelligence. Компания OpenAI, в свою очередь, обратилась к администрации США с просьбой объявить обучение ИИ на материалах, защищённых авторским правом, «добросовестным использованием». Компания настаивает на том, что неограниченный доступ к данным является ключом к глобальному лидерству США в сфере искусственного интеллекта. Бывший глава Intel Патрик Гелсингер запустил проект по созданию христианского ИИ
04.11.2025 [09:40],
Анжелла Марина
Экс-генеральный директор Intel Патрик Гелсингер (Patrick Gelsinger) возглавил технологическую компанию Gloo, которая занимается созданием искусственного интеллекта, проводя религиозную линию. По словам Гелсингера, его жизненной миссией является разработка технологии, способной «ускорить второе пришествие Христа». 
Источник изображения: Grok Гелсингер, покинувший Intel в прошлом году, в марте 2025 года занял пост исполнительного председателя в технологической компании Gloo. Согласно сообщению издания Futurism со ссылкой на материал The Guardian, компания нацелена на «продвижение христианских ценностей в Кремниевой долине и Конгрессе США». Называющий себя христианином-возрожденцем, он давно известен своей публичной позицией относительно религии. Гелсингер является автором двух книг для христианской аудитории, изданных в 2003 (Balancing Your Family, Faith & Work) и 2008 (The Juggling Act: Bringing Balance to Your Faith, Family, and Work) годах, и даже как-то назвал Кремниевую долину своим «миссионерским полем». По заявлению Гелсингера, его жизненной миссией является работа над технологией, которая улучшит качество жизни каждого человека на планете и «ускорит возвращение Христа». В Gloo заявляют, что обслуживают более 140 000 лидеров религиозных организаций, служителей и представителей некоммерческих структур. В её арсенале имеется набор цифровых инструментов, включая собственную языковую модель под названием Christian-Aligned Large Language Model (CALLM), также известную как Gloo Kingdom-Aligned Large Language Model (KALLM). При этом, бесплатная подписка позволяет церковным лидерам создавать собственных ИИ-ассистентов, обученных на их проповедях и контенте. На недавнем семинаре, организованном совместно Gloo и Колорадским христианским университетом, Гелсингер назвал появление ИИ «ещё одним моментом Гутенберга», сравнивая его потенциал с изобретением печатного станка с подвижными литерами немецким первопечатником Иоганном Гутенбергом. По словам Гелсингера, церковь в XVI веке использовала печатный станок для трансформации человечества, и сегодня, он убеждён, возникает аналогичная возможность «воплотить и выразить религию через технологию искусственного интеллекта». Сэма Альтмана стали раздражать вопросы об огромных расходах OpenAI
03.11.2025 [13:55],
Владимир Фетисов
Генеральный директор OpenAI Сэм Альтман (Sam Altman) недавно заявил, что годовая выручка компании «существенно превышает» $13 млрд. При этом он выглядел несколько раздражённым, когда его спросили, как компания планирует компенсировать свои огромные расходы. Это произошло во время совместного интервью Альтмана и гендиректора Microsoft Сатьи Наделлы (Satya Nadella) для подкаста Bg2, выпуск которого был посвящён партнёрству компаний. 
Источник изображения: wikipedia.org Ведущий подкаста Брэд Герстнер (Brad Gerstner) во время беседы упомянул, что выручка OpenAI в районе $13 млрд выглядит весьма внушительной, но она меркнет на фоне более $1 трлн, которые разработчик планирует потратить на развитие вычислительной инфраструктуры в течение следующего десятилетия. «Во-первых, наша выручка существенно больше этой суммы. Во-вторых, Брэд, если ты хочешь продать свои акции, я найду тебе покупателя. Я просто <…> хватит. Думаю, найдётся много желающих купить акции OpenAI», — ответил на это Альтман. «Включая меня», — добавил Герстнер. Затем Альтман добавил, что есть критики, которые «с наигранным беспокойством рассуждают о наших вычислительных мощностях или о чём-то ещё, но были бы рады купить наши акции». Он также добавил, что не часто хочет сделать OpenAI публичной компанией. «Один из редких случаев, когда это кажется привлекательным, — это когда люди пишут такие нелепые посты о том, что OpenAI вот-вот обанкротится. Мне бы хотелось сказать им, чтобы они открыли короткую позицию по нашим акциям, и я бы с удовольствием посмотрел, как они на этом обожгутся», — заявил Альтман. Он также признал, что есть варианты, при которых компания «может всё испортить». К примеру, OpenAI может оказаться не в состоянии обеспечить себе доступ к достаточному объёму вычислительных ресурсов. Однако он добавил, что «выручка растёт очень быстрыми темпами». «Мы делаем ставку на будущее, полагая, что рост продолжится: не только ChatGPT будет развиваться, нам также удастся стать одним из ключевых облачных сервисов для ИИ, наш бизнес потребительских устройств станет значимым, а способный автоматизировать науку ИИ создаст огромную ценность», — добавил Альтман. Наделла также отметил, что OpenAI «превзошла» все бизнес-планы, которые были предоставлены Microsoft как инвестору. Позднее Герстнер вернулся к теме выручки OpenAI, предположив, что компания может достичь $100 млрд выручки к 2028-2029 году. «А как насчёт 2027-го?» — парировал Альтман. Вместе с этим он опроверг сообщения о том, что OpenAI проведёт IPO в следующем году. «Нет, нет, нет, у нас нет ничего конкретного. Я реалист и предполагаю, что когда-нибудь это произойдёт, но я не понимаю, зачем люди высказывают такие предположения. У нас нет определённой даты, нет решения совета директоров сделать это или что-то подобное. Я просто предполагаю, что в конечном счёте всё пойдёт именно так», — заявил Альтман. Инженеры «боевого» развёртывания стали новым кадровым трендом ИИ-компаний
03.11.2025 [06:00],
Анжелла Марина
На фоне растущих потребностей бизнеса в ИИ-решениях, крупные компании, разрабатывающие технологии искусственного интеллекта, такие как Anthropic, OpenAI, канадская компания Cohere и другие, стали активно нанимать инженеров передового развёртывания (forward-deployed engineers, FDE), сочетающих навыки программирования и работы с клиентами. Эти специалисты внедряются непосредственно в бизнес-процессы заказчика для адаптации генеративных ИИ-моделей под специфические отраслевые задачи. 
Источник изображения: AI По сообщению Financial Times со ссылкой на данные крупнейшей платформы по поиску работы Indeed, число вакансий FDE выросло более чем на 800 % с января по сентябрь 2025 года. OpenAI сформировала команду FDE в начале 2025 года и планирует увеличить её до 50 человек к концу года, также сообщает Арно Фурнье (Arnaud Fournier), возглавляющий подразделение FDE компании в Европе и на Ближнем Востоке. Anthropic, в ответ на растущий спрос, заявила о намерении расширить свой отдел прикладного ИИ, включающий FDE и продуктовых инженеров, в пять раз в течение 2025 года. Интересно, что американская компания Palantir — разработчик программного обеспечения, специализирующаяся на анализе больших данных, по собственным заявлениям, ввела эту должность уже почти двадцать лет назад, и сегодня FDE составляют около половины её штата. В ходе внедрения Palantir использует парную модель сотрудничества, когда один инженер выявляет потребности клиента, а другой реализует техническое решение. И подобный подход уже принёс ощутимые результаты. Например, OpenAI в партнёрстве с производителем сельхозтехники John Deere удалось сократить использование химикатов на 60–70 % за счёт точной настройки ИИ-инструментов. При этом руководители компаний подчёркивают, что ценность программного обеспечения определяется не «красотой кода, а реальной пользой для конечного пользователя». Стартапы в сфере ИИ стремятся воспроизвести успешную модель Palantir. Так, Айдан Гомес (Aidan Gomez), сооснователь и генеральный директор Cohere, пояснил, что размещение инженеров у клиента на раннем этапе сотрудничества способствует формированию долгосрочных партнёрских отношений. По его словам, инженеры внедряются в начале работы, чтобы гарантировать, что клиент получает в текущий момент именно то, что ему нужно, а по мере запуска и стабилизации системы их участие постепенно сокращается. Несмотря на то, что доля FDE в общей численности персонала ИИ-компаний пока невелика, спрос на таких специалистов превзошёл ожидания. По словам Фурнье из OpenAI, такая практика позволяет компании изучать реальные потребности клиентов из разных отраслей, экспериментировать и совместно внедрять инновации, а полученные знания впоследствии помогают совершенствовать исследовательскую деятельность и продуктовые предложения компании на основе того, что хорошо работает именно в реальных условиях. Adobe представила ИИ-инструмент для редактирования видео по одному кадру
02.11.2025 [12:33],
Владимир Фетисов
Компания Adobe показала публике несколько экспериментальных инструментов на базе искусственного интеллекта, работа над которыми ещё продолжается и которые предназначены для интуитивно понятного редактирования изображений, видео и аудио. Один из таких инструментов разрабатывается в рамках проекта Project Frame Forward и позволяет в процессе редактирования видео добавлять и удалять разные объекты без использования масок — трудоёмкого процесса выделения объектов или людей. 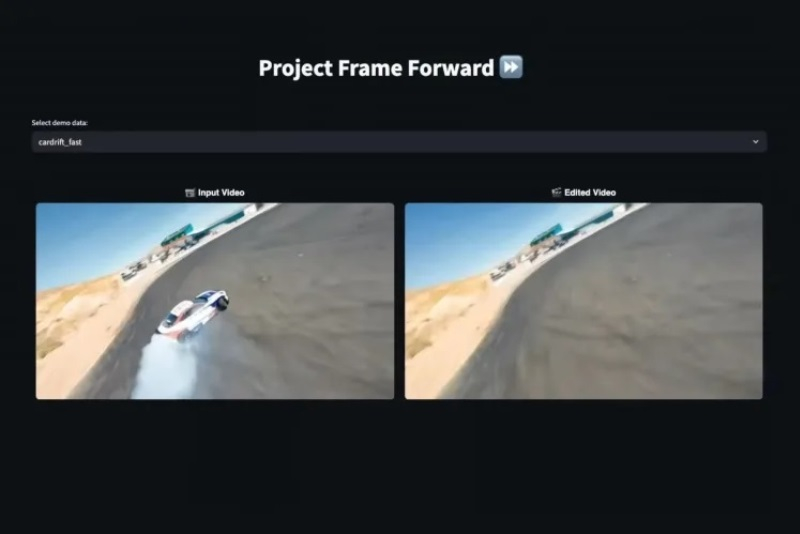
Источник изображения: Adobe В одном из демонстрационных видео Adobe показала, как с помощью Frame Forward можно легко удалить из видео какой-либо объект. Данный инструмент идентифицировал, выделил и удалил женщину в первом кадре видео, а затем заменил её естественно выглядящим фоном. После этого данные изменения применились ко всему видео буквально в несколько кликов. Пользователи также могут добавлять объекты в кадр. Для этого нужно выделить область, в которую требуется добавить объект и с помощью текстовых описаний подсказать ИИ-алгоритму больше деталей. Эти изменения в первом кадре будут применены ко всему видео. Вставленные объекты могут хорошо вписываться в видео, как, например, вставленная в кадр лужа, в которой отражается кошка, которая была в видео изначально. Ещё один ИИ-инструмент Project Light Touch позволяет изменить источник света на фотографиях. С его помощью можно менять направление освещения, создавать эффект освещения, будто комната освещается лампами, а также контролировать рассеивание света и тени. Этот инструмент можно задействовать для добавления динамического освещения, которое можно перемещать по рабочей области редактирования, изменяя то, как свет проходит вокруг и позади людей, а также других объектов. Цвет этих источников света можно изменять, позволяя корректировать теплоту освещения и создавать яркие RGB-эффекты. Инструмент Project Clean Take позволяет менять манеру речи на основе текстовых подсказок, что позволит избежать необходимости перезаписывать видео или аудиоклип. Пользователь может изменить стиль подачи или эмоциональную окраску голоса, при необходимости можно полностью заменить проговариваемые слова, сохраняя идентификационные характеристики исходного голоса. Clean Take подходит для разделения исходных шумов на отдельные источники для последующей детальной настройки звука и повышения разборчивости речи. Это лишь некоторые из разрабатываемых Adobe ИИ-инструментов, которые были показаны на конференции Max. Среди других выделим Project Surface Swap, с помощью которого можно мгновенно изменить материал или текстуру объектов и поверхностей. Ещё есть Project Turn Style для редактирования объектов на изображении за счёт их вращения, подобно 3D-моделям. Project New Depths позволяет редактировать фото как бы в 3D-пространстве, где система сама определяет, когда вставляемые объекты должны быть частично перекрыты окружающей средой. Все эти ИИ-инструменты на данный момент недоступны для публичного использования. Когда они могут стать частью Adobe Creative Cloud или приложения Firefly, не уточняется. Несмотря на ИИ-бум, онлайн-реклама остаётся главным двигателем роста IT-гигантов
01.11.2025 [21:00],
Сергей Сурабекянц
По мере того, как технологические гиганты увеличивают свои и без того впечатляющие расходы на ИИ, их цифровые рекламные направления также набирают обороты. Квартальные отчёты Meta✴✴, Amazon, Alphabet и Microsoft продемонстрировали хорошую выручку в сфере рекламы. Рост продаж онлайн-рекламы развеял опасения, высказанные ранее в этом году, что экономическая нестабильность, усугублённая торговой политикой США, негативно повлияет на рекламные бюджеты. 
Источник изображения: unsplash.com Meta✴✴ превзошла своих конкурентов в этом квартале, показав самый быстрый рост продаж, связанных с рекламой. Общая выручка компании в третьем квартале, 98 % которой приходится на онлайн-рекламу, выросла на 26 % в годовом исчислении до $51,24 млрд, что является самым высоким показателем продаж компании с первого квартала 2024 года. Выручка подразделения онлайн-рекламы Amazon выросла на 24 % в годовом исчислении до $17,7 млрд, что превышает темпы роста подразделения облачных вычислений AWS, продажи которого выросли на 20 %. Компания продолжает расширять свою рекламную платформу для привлечения большего количества сторонних приложений и сайтов. Общий объём продаж рекламы Alphabet в третьем квартале составил $74,18 млрд, что на 13 % больше, чем $65,85 млрд годом ранее. Продажи онлайн-рекламы на YouTube выросли на 15 % до $10,26 млрд. Подразделение Microsoft, занимающееся поисковой и новостной рекламой, принесло компании $3,7 млрд долларов в первом финансовом квартале, что на 14 % больше, чем 3,2 млрд долларов годом ранее. Reddit сообщила о росте продаж в третьем квартале на 68 %. Число активных пользователей в мире выросло на 19 % по сравнению с аналогичным периодом прошлого года до 116 миллионов, превысив прогноз в 114 миллионов. Аналитики отмечают, что даже если из-за экономической нестабильности бюджеты на рекламу и сократились, рекламодатели пожертвовали консервативными видами коммуникаций, увеличив затраты в социальных сетях и на поисковую рекламу. Но хотя инвесторы ростом акций продемонстрировали веру в Amazon и Google, они были менее воодушевлены Microsoft, и особенно Meta✴✴. Акции компании вчера упали на 11 %, после известий о повышении планируемых капитальных затрат с $66 млрд до 72 млрд. Многие аналитики понизили рейтинг акций Meta✴✴ с «покупать» до «держать», поскольку неочевидно, как эта социальная сеть выиграет от своих инвестиций в ИИ по сравнению с конкурентами, также предоставляющими услуги облачных вычислений. В то же время технологические гиганты не видят препятствий для дальнейшего увеличение инвестиций в ИИ и продолжают повышать свои прогнозы по капитальным расходам, несмотря на опасения некоторых экспертов. Капитальные затраты Alphabet, Meta✴✴, Amazon и Microsoft в сфере ИИ в этом году превысят внушительные $380 млрд, но эта цифра меркнет по сравнению с триллионом долларов, которые привлекла OpenAI благодаря сделкам с Nvidia, Oracle, Broadcom и другими партнёрами. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex



