|
Опрос
|
реклама
Быстрый переход
Опрос Steam показал рост популярности 8-ядерных процессоров и снижение интереса к дисплеям Full HD
03.08.2026 [06:01],
Анжелла Марина
Valve опубликовала результаты июльского опроса Steam Hardware Survey, показавшие заметные изменения в конфигурациях игровых ПК. Впервые 8-ядерные процессоры стали самой распространённой категорией среди пользователей Steam, тогда как популярность экранов Full HD продолжила снижаться. 
Источник изображения: digitalfoundry.net По итогам июля 2026 года доля 8-ядерных процессоров выросла до 27,85 %, что позволило им обойти 6-ядерные модели, набравшие 27,5 %. По сообщению Digital Foundry, конфигурации с восемью ядрами постепенно укрепляли позиции на протяжении длительного времени и теперь впервые заняли первое место. При этом небольшое увеличение доли также показали десяти- и восемнадцатиядерные процессоры Intel. Одновременно статистика продолжила отражать последствия роста цен на память. Категория компьютеров с 8 Гбайт оперативной памяти увеличилась на 0,2 процентного пункта, тогда как системы с 16 Гбайт потеряли такую же долю. Несмотря на это, именно 16 Гбайт остаются наиболее распространённым объёмом оперативной памяти с показателем чуть менее 41 %, а второе место занимают системы с 32 Гбайт, доля которых приблизилась к 37 %. Изменения затронули и рынок мониторов. Разрешение 1920 × 1080 пикселей за месяц потеряло около 0,8 процентного пункта — это одно из самых заметных снижений за всё время наблюдений. Тем не менее, Full HD по-прежнему используется более чем на половине игровых ПК, занимая около 51 % рынка. Основными бенефициарами этого процесса стали дисплеи с разрешением 2560 × 1440 пикселей, которые прибавили 0,26 %, а также устройства с 4K, популярность которых продолжила расти благодаря снижению стоимости. Помимо этого, отчёт зафиксировал дальнейший переход пользователей с Windows 10 на Windows 11, стабилизацию распределения между процессорами AMD и Intel, а также небольшое увеличение доли видеокарт Nvidia среди участников опроса. Продажи мобильных процессоров MediaTek и Qualcomm упали, а Samsung и Google — выросли
30.07.2026 [16:38],
Павел Котов
Продажи мобильных процессоров крупных брендов MediaTek и Qualcomm по итогам первой половины 2026 года сократились, а рыночные доли Google и Samsung на рынках чипов для смартфонов выросли, подсчитали аналитики Counterpoint Research.  Общие поставки мобильных процессоров за первую половину 2026 года снизились на 15 % по сравнению с аналогичным периодом годом ранее. Это означает, что ведущие производители устройств под Android сократили продажи, Samsung и Google разрабатывают собственные чипы, а MediaTek и Qualcomm сократились доли рынка. Доля чипов MediaTek снизилась с 37 % до 32 %, доля Qualcomm — с 26 % до 22 %. При этом доли рынка Google, Samsung и Unisoc выросли. По итогам первой половины 2026 года поставки процессоров MediaTek и Qualcomm сократились более чем на 25 %, а Apple, Samsung, Google и Unisoc показали уверенный рост. 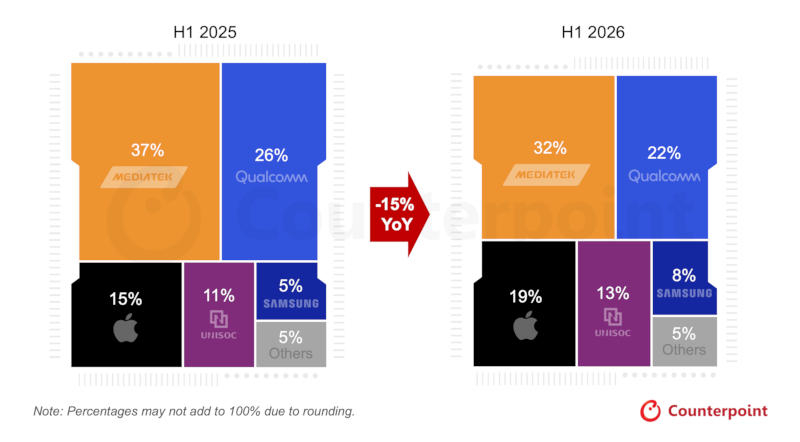
Источник изображения: counterpointresearch.com Причина такой динамики — дефицит чипов памяти и рост цен на них. Производители смартфонов вынуждены повышать цены на продукцию, а с учётом того, что память в годовом исчислении подорожала примерно на 300 %, процессоры больше не составляют основную часть цены. Всё большим спросом пользуются чипы с ускорителями искусственного интеллекта, такие как Google Tensor G5. Android-смартфоны наращивают число функций ИИ, и за Google следуют другие разработчики процессоров — этот сегмент показал рост на 24 % в годовом исчислении, даже несмотря на общее снижение рынка. Как ожидается, 12 августа Google представит смартфоны серии Pixel 11 на процессорах Tensor G6. Собственную линейку мобильных чипов продолжает разрабатывать Samsung, но из последней линейки складных смартфонов фирменный Exynos установлен только на младший Galaxy Z Flip8. Раскрыты характеристики грядущего флагманского чипа Snapdragon 8 Elite Gen 6 Pro от Qualcomm
29.07.2026 [20:43],
Павел Котов
Флагманский мобильный процессор Qualcomm Snapdragon 8 Elite Gen 6 Pro (модельный индекс SM8975), анонс которого ожидается в конце сентября, обещает значительный архитектурный прорыв для производителя, сообщает Gizmochina. 
Источник изображения: Qualcomm Новый чип будет производиться с использованием техпроцесса TSMC N2P (класс 2 нм), и это первая подобная модель Qualcomm — актуальный лидер линейки выпускается по технологии 3 нм. При этом размер кристалла у новой модели окажется крупнее — около 134 мм2 против 126,2 мм2, несмотря на более высокую плотность транзисторов. Это указывает, что разработчик добавил новые компоненты или усложнил конструкцию. Центральный процессор на чипе включает только собственные ядра Qualcomm Oryon в конфигурации 2+3+3: два основных, три производительных и три энергоэффективных. Точные тактовые частоты пока неизвестны, зато сообщается о графическом процессоре Adreno 850 с видеобуфером (GMEM) объёмом 18 Мбайт. Чип также получит два выделенных блока Matrix ALU для работы новой функции AI Frame Fusion — она предназначена для системы масштабирования: увеличения разрешения и генерации кадров. Но эта функция, по неподтверждённым данным, будет присутствовать только на чипе Pro. Базовый Snapdragon 8 Elite Gen 6 (SM8950) ограничится только Adreno 845 с видеобуфером объёмом 12 Мбайт. Общий кеш вырастет до 16 Мбайт, его дополнят 8 Мбайт системного. Snapdragon 8 Elite Gen 6 Pro будет поддерживать оперативную память стандартов LPDDR5X и LPDDR6, а базовый вариант чипа — только LPDDR5X. Старшая модель будет дороже в производстве, и её получит меньшее число моделей смартфонов. Официальный анонс новых чипов ожидается на мероприятии Snapdragon Summit, которое пройдёт с 22 по 24 сентября. Цены на клиентские процессоры Intel выросли на 27 %, объёмы продаж сократились на 8 %, но чипов всё равно не хватило на всех
26.07.2026 [07:19],
Алексей Разин
В минувшем квартале компании Intel пришлось работать в сложных условиях, но на отсутствие спроса в серверном сегменте она жаловаться не могла. В клиентском сегменте сложилась необычная ситуация: поставки процессоров сокращались, но средние цены реализации росли опережающими темпами, что и позволило нарастить профильную выручку почти на 13 %. 
Источник изображения: Intel Опубликованная Intel форма квартального отчёта 10-Q раскрывает больше подробностей относительно взаимной зависимости объёмов поставок, средних цен реализации и собственно выручки. Реализация конкретно компонентов для ноутбуков и настольных систем принесла Intel в прошлом квартале $7,7 млрд, что на 16,7 % больше в годовом сравнении. Этот прирост главным образом был обеспечен увеличением средней цены реализации на 27 %, поскольку фактически отгруженное количество продукции сократилось на 8 %. Всего с начала года средние цены реализации клиентских процессоров Intel выросли на 22 %, а объёмы поставок сократились на 10 % в годовом сравнении. То есть, тенденция к сокращению поставок при одновременном росте выручки из-за роста цен наблюдается уже не первый месяц подряд. Intel признаётся, что в этом году повышала цены на свои процессоры преимущественно ради компенсации возросших затрат на их производство, и в меньшей степени для учёта конъюнктуры спроса. Последний превышал возможности Intel по поставкам процессоров как во втором квартале, так и в первом полугодии в целом, как отмечается в отчёте компании. Во втором полугодии Intel рассчитывает на уменьшение дефицита своей продукции в клиентском сегменте. В серверном сегменте, как уже отмечалось на этой неделе, выручка Intel во втором квартале взлетела на 62 % до $6,3 млрд. Средние цены реализации при этом выросли на 48 %, а объёмы поставок увеличились на 9 %. За первое полугодие рост средних цен составил 38 %, а объёмов реализации 2 %. Как отмечает компания, основной рост спроса демонстрировали гиперскейлеры. Дефицит процессоров был очевиден и в серверном сегменте, и устранить его до следующего года компания не рассчитывает. Об этом на квартальном отчётном мероприятии говорил и генеральный директор Intel Лип-Бу Тан (Lip-Bu Tan). По его словам, отрасль столкнулась с одним из самых сильных дефицитов в своей истории, который охватывает передовые логические компоненты, кремниевые пластины, микросхемы памяти и подложки. Как убеждён глава компании, проблемы с доступностью компонентов сохранятся в обозримом будущем. Больше всего выражен дефицит памяти, и сама Intel активно работает над его устранением во взаимодействии с тремя крупнейшими поставщиками. Финансовый директор Intel Дэвид Зинснер (David Zinsner) прогнозирует, что выручка компании в клиентском сегменте по итогам третьего квартала будет оставаться на том же уровне, что и во втором, и к четвёртому кварталу ситуация не исправится, поскольку Intel будет вынуждена направлять основные ресурсы на увеличение объёмов выпуска серверных процессоров. Он ожидает, что во втором полугодии объёмы продаж ПК окажутся ниже сезонных норм, а по итогам всего 2026 года они сократятся более чем на 10 % из-за дефицита памяти и роста цен. Intel подтвердила возвращение Hyper-Threading в чипах Coral Rapids в 2028 году
25.07.2026 [14:29],
Павел Котов
Свою реализацию технологии «одновременной многопоточности» (SMT) компания Intel называет Hyper-Threading. Речь идёт о методе, при котором одно ядро может совмещать обработку двух отдельных программных потоков, обеспечивая общее повышение производительности в многопоточных задачах. Intel отказалась от неё с выходом процессоров Core Ultra 200, и новое семейство Xeon 7 Diamond Rapids тоже не будет её поддерживать. Очевидно, это была ошибка, потому что глава Intel Лип-Бу Тан (Lip-Bu Tan) подтвердил, что Hyper-Threading вернётся с чипами Coral Rapids в 2028 году. 
Источник изображения: Rubaitul Azad / unsplash.com В ходе телефонной конференции Intel с аналитиками господина Тана спросили, как он намерен вернуть Intel долю рынка в серверном сегменте, где компании противостоят AMD и Arm-процессоры. Он ответил: «В отношении серверов и центров обработки данных у нас, очевидно, есть чёткая дорожная карта. У нас есть Clearwater Forest, Diamond Rapids, а также Coral Rapids с поддержкой технологии SMT. Мы продолжаем работать над повышением конкурентоспособности по отношению к нашим соперникам. Считаю, что очень важно улучшать как однопоточные, так и многопоточные вычисления. В Coral Rapids появится многопоточность». Intel не продаёт серверные Xeon с гибридными ядрами, поэтому существуют два вида этих процессоров: с производительными P-ядрами и с эффективными E-ядрами. Последние не поддерживают Hyper-Threading ещё со времён Saltwell в 2012 году; а P-ядра её поддерживали всегда, в том числе и актуальные Granite Rapids. Однако Hyper-Threading исчезнет в поколении Diamond Rapids и вернётся в 2028 году. Информации о Coral Rapids пока немного. Выпуск этих процессоров намечен на 2028 год, они появятся в исполнении с 8-канальной памятью, но ассортимент может расшириться в зависимости от реакции на Diamond Rapids, которые идут только с 16-канальной. Hyper-Threading вернётся, но архитектура чипов и техпроцесс пока неизвестны: скорее всего, это будет либо Intel 14A, либо усовершенствованная 18A-P. Потребительские процессоры Intel также лишились поддержки Hyper-Threading, потому что её присутствие в 10-ядерных чипах начального уровня — расточительство. Дополнительные кристаллы для поддержки SMT в большинстве случаев используются неэффективно, потому что большинство пользователей не запускает ресурсоёмкие задачи, требующие высокой пропускной способности, где Hyper-Threading может оказаться полезной. Без поддержки этой технологии площадь кристалла уменьшается, потребляет он меньше, а его однопоточная производительность растёт, потому что конкуренции потоков за ресурсы процессоров больше нет. А вот в серверных нагрузках Hyper-Threading может дать прирост производительности на величину до 30 %; и в разрезе конкуренции с AMD это актуально. AMD раскрыла, когда выпустит процессоры на Zen 7 и Zen 8
24.07.2026 [15:16],
Николай Хижняк
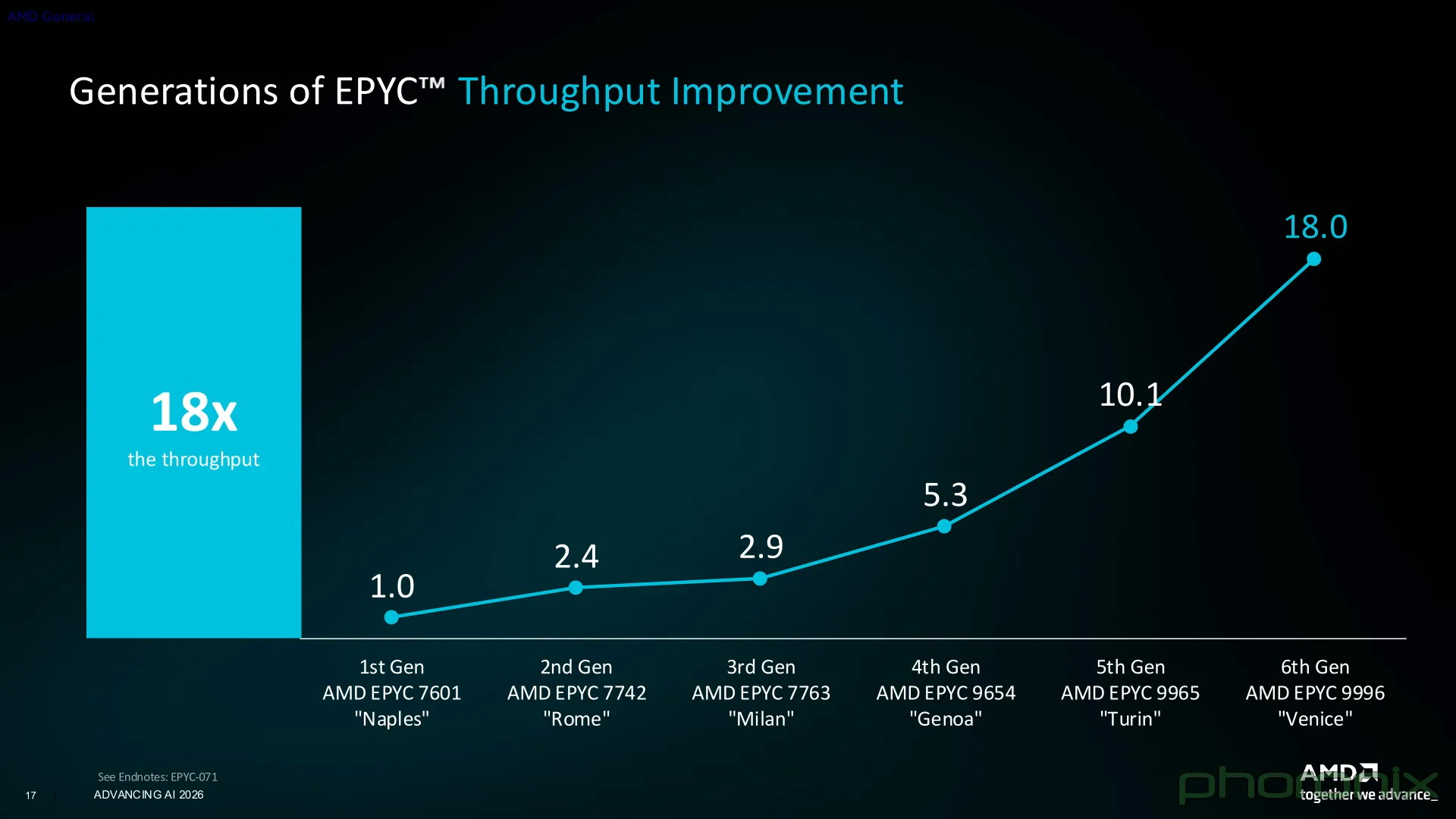
AMD опубликовала свежий план по выпуску серверных процессоров EPYC вплоть до 2030 года, тем самым раскрыв, когда можно ожидать выход процессоров на архитектурах Zen 7 (Florence) и Zen 8 (Ravenna). Выпуск этих серий запланирован на 2028 и 2030 годы соответственно. 
Источник изображений: AMD С выпуском новых серверных чипов Zen 6 (Venice) AMD стала первым производителем, представившим 2-нм процессор с поддержкой 512 потоков. Компания также реализовала в новых продуктах поддержку интерфейса PCIe Gen 6 для x86 и памяти JEDEC MRDIMM, что, по её словам, стало первым подобным достижением в отрасли. Благодаря большому количеству ядер, более высокой пропускной способности памяти и значительному приросту производительности процессоры Zen 6 от AMD должны обеспечить впечатляющий уровень быстродействия. AMD не раскрыла никаких подробностей о процессорах EPYC на базе Zen 8. Эта архитектура находится в разработке и будет представлена в 2030 году. Вместе с тем компания сообщила дополнительную информацию о Zen 7, заявив, что архитектура будет использовать «технологический процесс следующего поколения» (вероятно, TSMC A14), поддерживать вычислительные инструкции ACE AI и технологии памяти следующего поколения.  По всей видимости, процессоры AMD Zen 7 будут поддерживать как память DDR6, так и LPDDR6. Они должны обеспечить увеличение пропускной способности по сравнению с современными модулями DDR5 и LPDDR5X. AMD также подтвердила, что в рамках Zen 7 будут выпускаться как стандартные ядра Zen 7, так и более компактные Zen 7c. Ниже представлен слайд AMD с планами компании по выпуску процессоров серии Zen 7 для различных потенциальных рабочих нагрузок. В их число входят рабочие нагрузки общего назначения, сложные корпоративные рабочие нагрузки, хост-узлы ИИ и системы для агентного ИИ.  Следует отметить, что AMD заявляет о «лидерском количестве ядер и производительности» для будущих процессоров Florence, подразумевая, что компания планирует выпустить модели серверных чипов с ещё большим количеством ядер в рамках архитектуры Zen 7. Судя по всему, AMD считает, что 256 ядер в процессорах EPYC Venice на архитектуре Zen 6 — не предел. Представлены чипы AMD X100 — процессоры на Zen 5 с мощной графикой для роботов
24.07.2026 [11:41],
Павел Котов
AMD представила спецверсии гибридных чипов APU Strix Halo для систем физического искусственного интеллекта — для роботов. Они имеют схожие характеристики с клиентскими Ryzen AI Max, но рассчитаны на круглосуточный режим работы и десять лет эксплуатации. 
Источник изображений: AMD Существуют три варианта чипов, соответствующих трём оригинальным моделям Strix Halo. Старшая модель X199 предлагает 16 ядер Zen 5 и 40 вычислительных блоков RDNA 3.5; X188 — 12 ядер и 32 вычислительных блока; X168 — восемь ядер и те же 32 вычислительных блока. Подробные спецификации каждой модели не уточняются, но известно о тактовой частоте до 5,1 ГГц в режиме Boost и поддержке до 128 Гбайт унифицированной памяти. Во всех случаях присутствуют нейропроцессор XDNA 2 с производительностью до 50 TOPS, настраиваемый TDP от 45 до 120 Вт и диапазон рабочих температур от -40 °C до 105 °C.  Новая линейка AMD — это ответ на чипы Intel Panther Lake для роботов. Обе компании выступают за интегрированные решения, позволяющие снизить задержку по сравнению с архитектурами, в которых центральный, графический и нейропроцессор, а также память находятся на разных чипах. Чипы линейки AMD X100 физически больше, чем аналоги Panther Lake, но и содержат больше кремниевых компонентов для более ресурсоёмких задач.  AMD показала сравнительные тесты флагманского X199 с Intel Core Ultra X7 358H — 16-ядерным процессором и интегрированной графикой Intel Arc B390 с 12 ядрами Xe3. Модель AMD X199 оказалась в 1,2 и 1,3 раза быстрее в тестах GeekBench 6.1 и PassMark соответственно, а также в 1,5 раза производительнее в неофициальном тесте SPECrate 2017 с целочисленными нагрузками. В графическом бенчмарке AMD превзошла конкурента в 1,4 раза в Vulkan, в 1,7 раза — в OpenGL (в обоих случаях использовался GFXBench 5 под Ubuntu), а также в 1,6 раза — в Unigine Heaven Extreme. 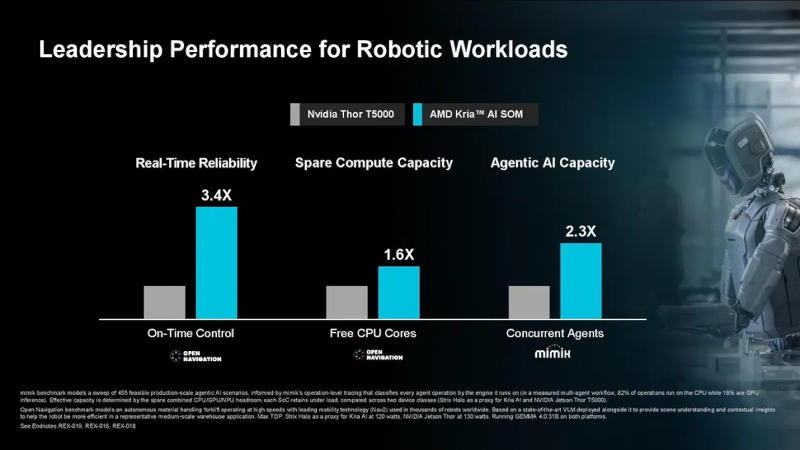 В задачах физического ИИ время до первого токена (TTFT) удалось сократить в 1,4 раза, а число токенов в секунду в бенчмарке Llama с бэкендом Vulkan и TDP 45 Вт — увеличить в 3,5 раза. Правда, тестирование проводилось на AMD Ryzen AI Max 395+, «сконфигурированном в соответствии со спецификациями Ryzen AI Embedded X199», на эталонной плате Maple с тактовой частотой центрального процессора 5,1 ГГц, графического — 2,9 ГГц и постоянным TDP 45 Вт. Intel Core Ultra X7 358H тестировался на MSI Prestige 16 Flip AI+ с TDP 30 Вт, после чего AMD «спрогнозировала» производительность чипа Intel при TDP 45 Вт, «используя коэффициенты масштабирования, полученные из общедоступных данных бенчмарков». Другими словами, сравнение не совсем корректное. 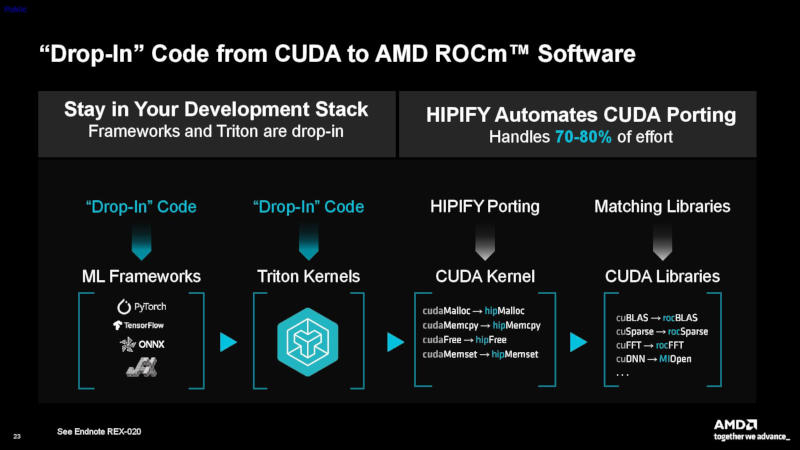 AMD предлагает не только сами чипы X100, но и выпускает их в составе Kria System on Module (SOM) — интегрированной платформы для разработчиков робототехники. Плата размером 120 × 120 мм соответствует стандартному формфактору COM-HPC. Это полностью интегрированное устройство с платой AMD Spartan UltraScale+ FPGA — готовое решение для создания робототехнических систем, включающее специализированные интерфейсы для подключения камер, промышленных сетей и датчиков. В тестах AMD X100 Kria сравнивали с Nvidia Thor T5000, однако проводились они не самой AMD, а по заказу компаний Open Navigation и Mimix. И здесь бенчмарки также не были прямыми: комплект разработчика Nvidia Jetson AGX Thor сравнивался с мини-ПК GMKtech EVO-X2 AI на чипе Ryzen AI Max+ 395, «сконфигурированном в соответствии со спецификациями Ryzen AI Embedded X199». AMD не оставляет попыток переманить разработчиков с платформы Nvidia CUDA: инструмент HIPIFY преобразует код CUDA в AMD HIP C++, принимая на себя 70–80 % «трудозатрат» по портированию. В ходе тестирования компания успешно портировала 15 приложений CUDA общим объёмом 1199 строк кода с показателем автоматизации 70–80 %. AMD X100 Kria составляет «мозг» робототехнической платформы, но компания планирует создать комплексное решение для человекоподобных роботов с использованием программируемых микросхем Spartan UltraScale+, Zynq UltraScale+ и Versal AI Edge Gen 2. AMD представила первые процессоры на Zen 6 — версии EPYC 9006X получат более 1 Гбайт кеша
24.07.2026 [00:18],
Николай Хижняк
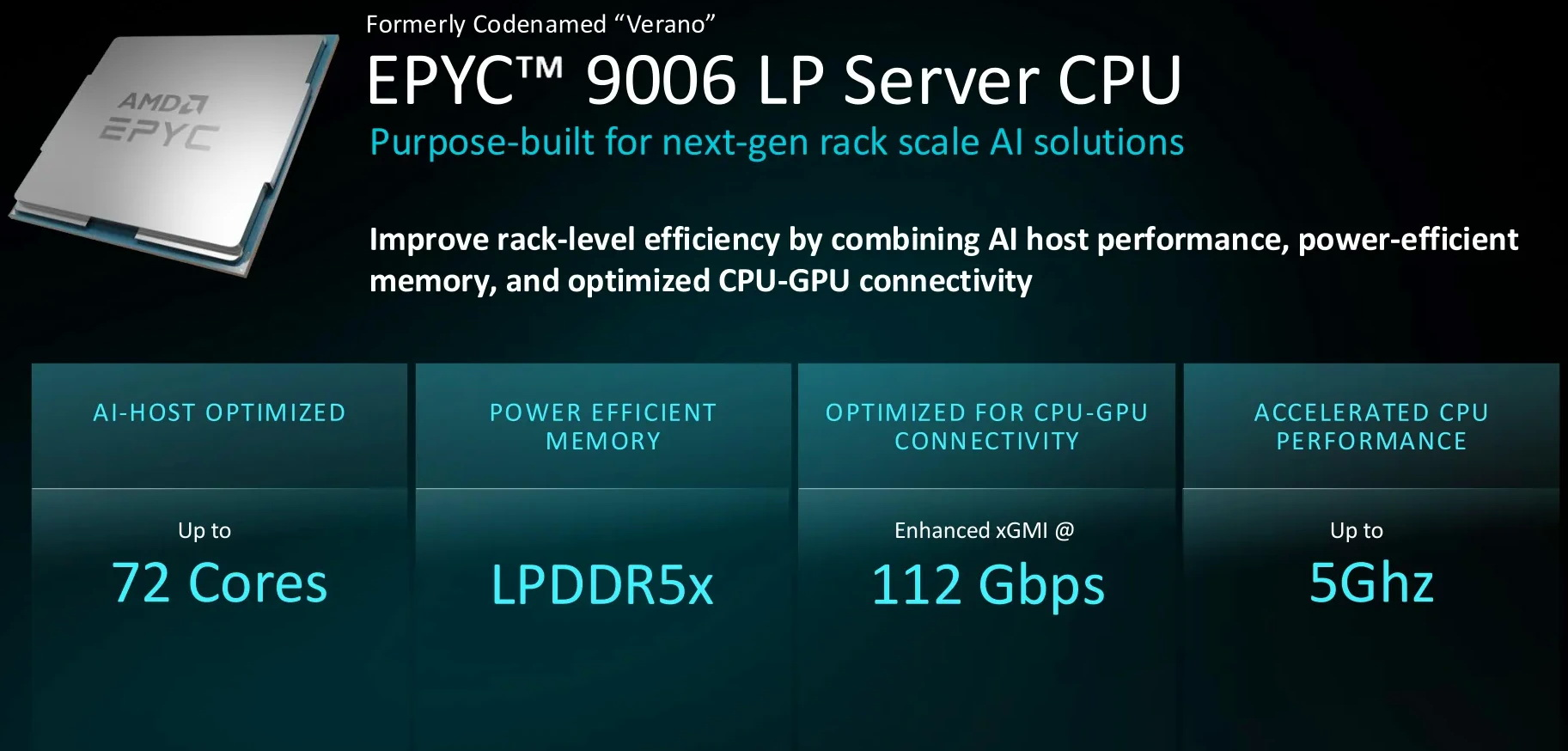
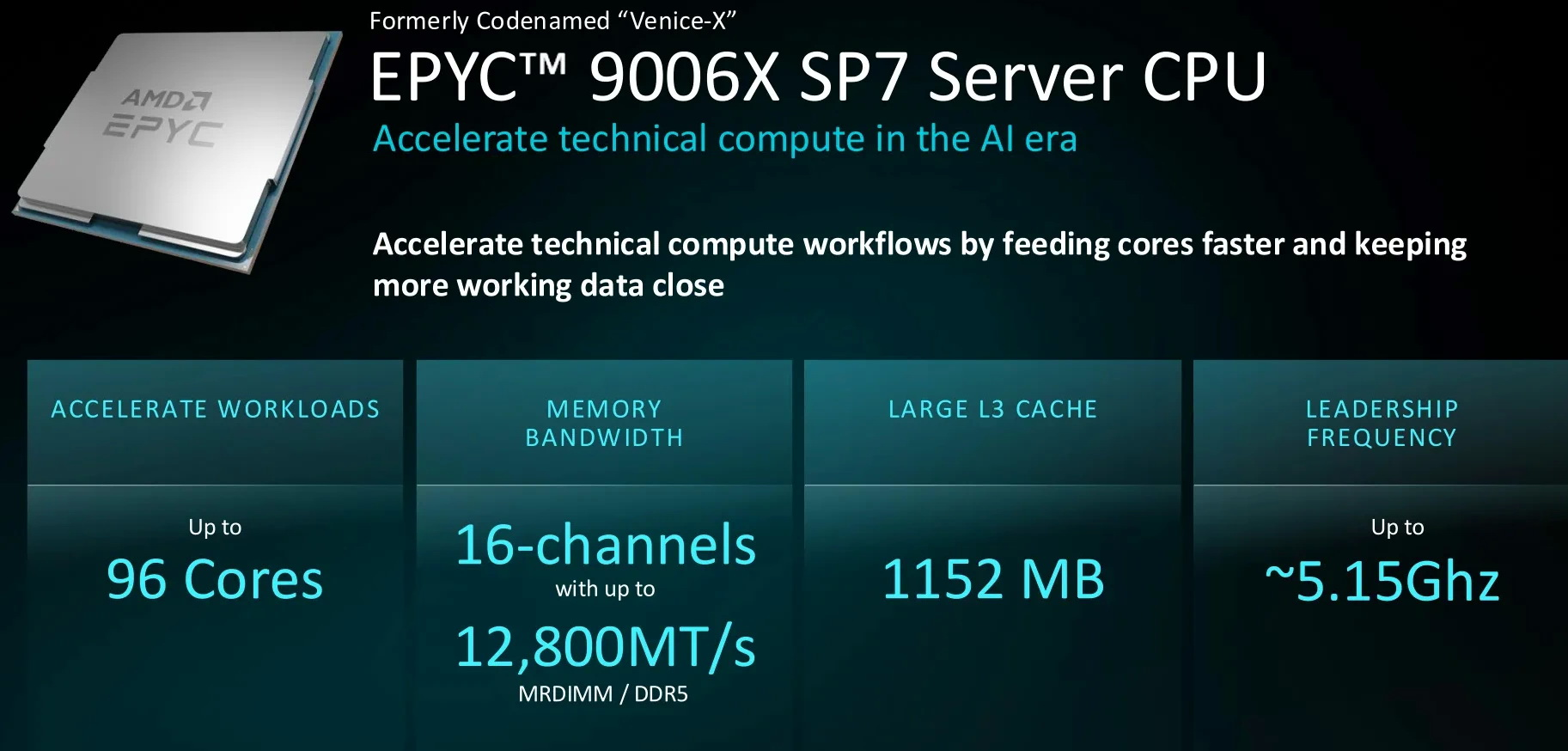
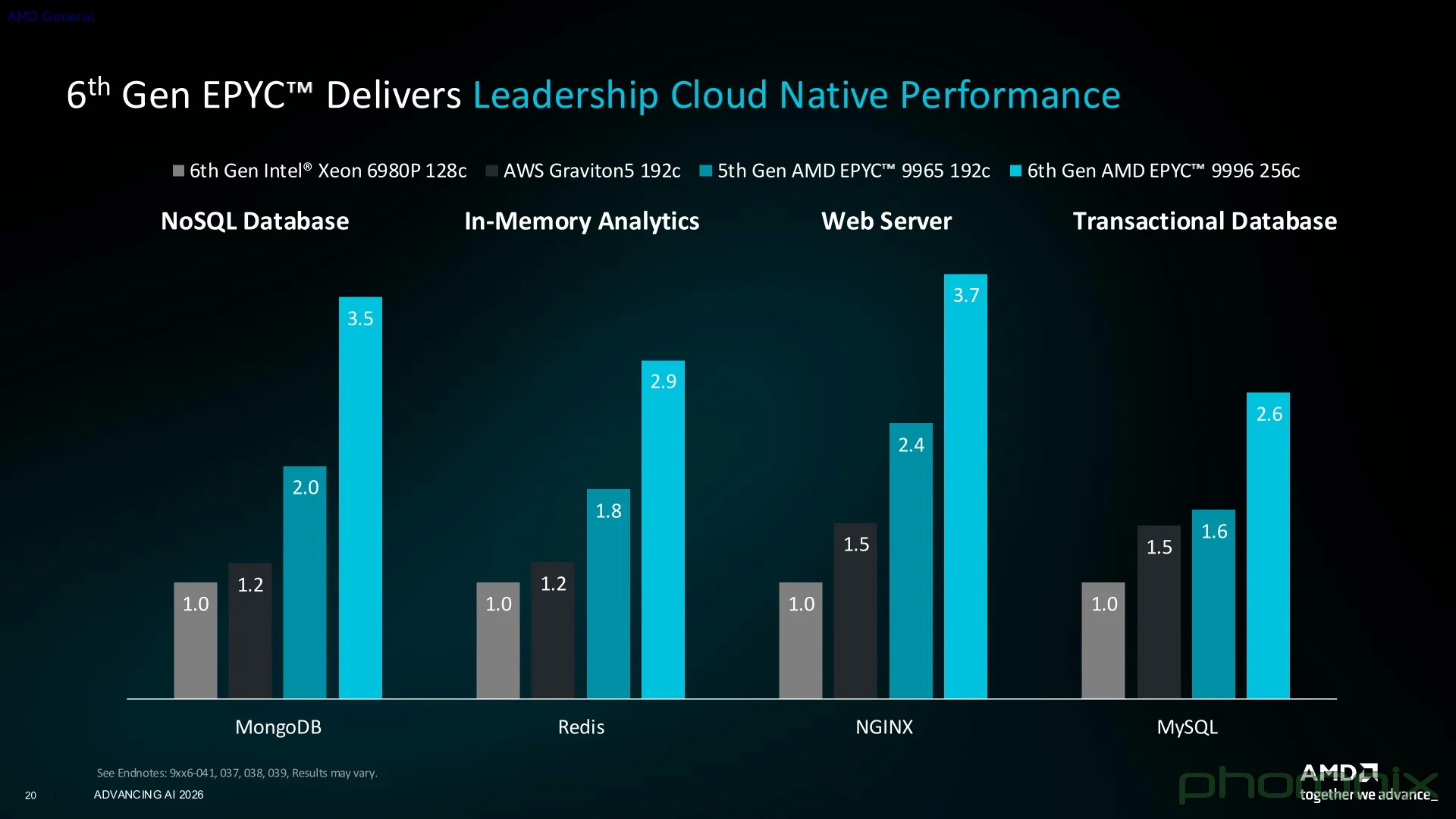
Компания AMD анонсировала шестое поколение своих серверных процессоров EPYC — серию EPYC 9006 с кодовым названием Venice. Это первые процессоры AMD на базе новых ядер Zen 6 и Zen 6c. Поставки первых систем на базе чипов EPYC 9006 для платформы SP7 ожидаются в четвёртом квартале 2026 года. 
Источник изображений: AMD Серия процессоров EPYC 9006 охватывает четыре платформы. Первыми выйдут чипы для платформы SP7 — модели EPYC 9006 SP7 (серия Venice), которые несут до 256 ядер Zen 6c с поддержкой 512 потоков, а также чипы, несущие до 96 ядер Zen 6 с частотой до 5,0 ГГц. Следом, в первой половине 2027 года, выйдут чипы для платформы SP8 с меньшим количеством ядер — модели EPYC 9006 SP8 предложат от 8 до 128 ядер, с поддержкой двухсокетных конфигураций. Во второй половине будущего года выйдут процессоры EPYC 9006X SP7 (Venice-X) с 3D V-Cache, которые также будут предназначены для платформы SP7. Они предложат до 96 ядер с частотой до 5,15 ГГц. Наконец, также во втором полугодии 2027 года выйдет серия чипов EPYC 9006 LP с памятью LPDDR5X (серия Verano), которые предложат до 72 ядер с частотой до 5,0 ГГц. Компания не сообщила полные спецификации для каждой отдельной модели процессора.  Для основной платформы SP7 заявляется поддержка до 16 каналов оперативной памяти с максимальной пропускной способностью до 1,6 Тбайт/с. Поддерживается память DDR5 со скоростью до 8000 МТ/с и модули MRDIMM второго поколения со скоростью до 12 800 МТ/с. Кроме того, SP7 поддерживает интерфейс PCIe 6.0 с пропускной способностью 64 Гбит/с на линию и интерфейс CXL 3.1. Платформа рассчитана на процессоры с TDP до 600 Вт.  Модели процессоров EPYC 9006X будут ориентированы на рабочие нагрузки, эффективность которых зависит от объёма кеш-памяти L3. Эти чипы предложат до 1152 Мбайт кеша L3 (за счёт технологии AMD 3D V-Cache). Модели EPYC 9006 LP, в свою очередь, поддерживают заменяемые модули памяти SOCAMM2 LPDDR5X и предназначены для хост-систем с GPU.  В материалах презентации AMD сравнивает 256-ядерный EPYC 9996 с 128-ядерным Intel Xeon 6980P в нескольких стандартизированных тестах. По данным компании, производительность в NGINX выше до 3,7 раза, в MongoDB — до 3,5 раза, а в GROMACS и NAMD — до 3,1 раза. Особенности и производительность EPYC 9006
AMD заявляет, что процессоры EPYC 9006 для платформы SP7 уже находятся в производстве, но их поставки начнутся в четвёртом квартале 2026 года. Вся линейка процессоров EPYC 9006 будет выпущена в течение 2027 года. Компания также добавила, что процессоры EPYC шестого поколения станут основой для стоечных систем Helios. Серверные процессоры становятся дефицитом: Intel и AMD переходят на долгосрочные контракты
23.07.2026 [08:50],
Алексей Разин
В контексте последствий ИИ-бума нам чаще приходилось слышать о стремлении участников рынка памяти заключать долгосрочные контракты с клиентами, которые подразумевают крупные авансовые выплаты и фиксирование цен в определённом коридоре. На рынке серверных процессоров такая тенденция тоже имеет место, как отмечает Reuters. 
Источник изображения: AMD Во всяком случае, источники сообщают, что Intel и AMD начали заключать с китайскими производителями серверного оборудования контракты на поставку центральных процессоров, которые рассчитаны на более длительные сроки, чем обычно. Минимально они заключаются на год, но переговоры ведутся и относительно более продолжительных сроков. Условия контрактов пока предусматривают только минимально обеспечиваемый объём поставляемой продукции, а вот цены не фиксируются. По данным источника, цены на серверные процессоры в Китае сейчас по отдельным позициям могут последовательно увеличиваться на 10 %. С начала года некоторые серверные процессоры на местном рынке подорожали на 40 %. Очевиден дефицит, и та же компания Intel на прошлом квартальном мероприятии не скрывала, что её серверные процессоры начали пользоваться более высоким спросом на фоне перехода к инференсу в инфраструктуре систем искусственного интеллекта. При этом сроки поставок некоторых серверных процессоров Intel уже растягиваются на шесть месяцев. Мировой рынок центральных процессоров также испытывает дефицит, и комментарии на эту тему наверняка можно будет услышать от руководства Intel на текущей неделе, поскольку компания выступит с квартальным отчётом. Nvidia раскрыла детали процессора Vera: 88 Arm-ядер Olympus, 176 потоков и память LPDDR5X с пропускной способностью 1,2 Тбайт/с
21.07.2026 [22:35],
Николай Хижняк
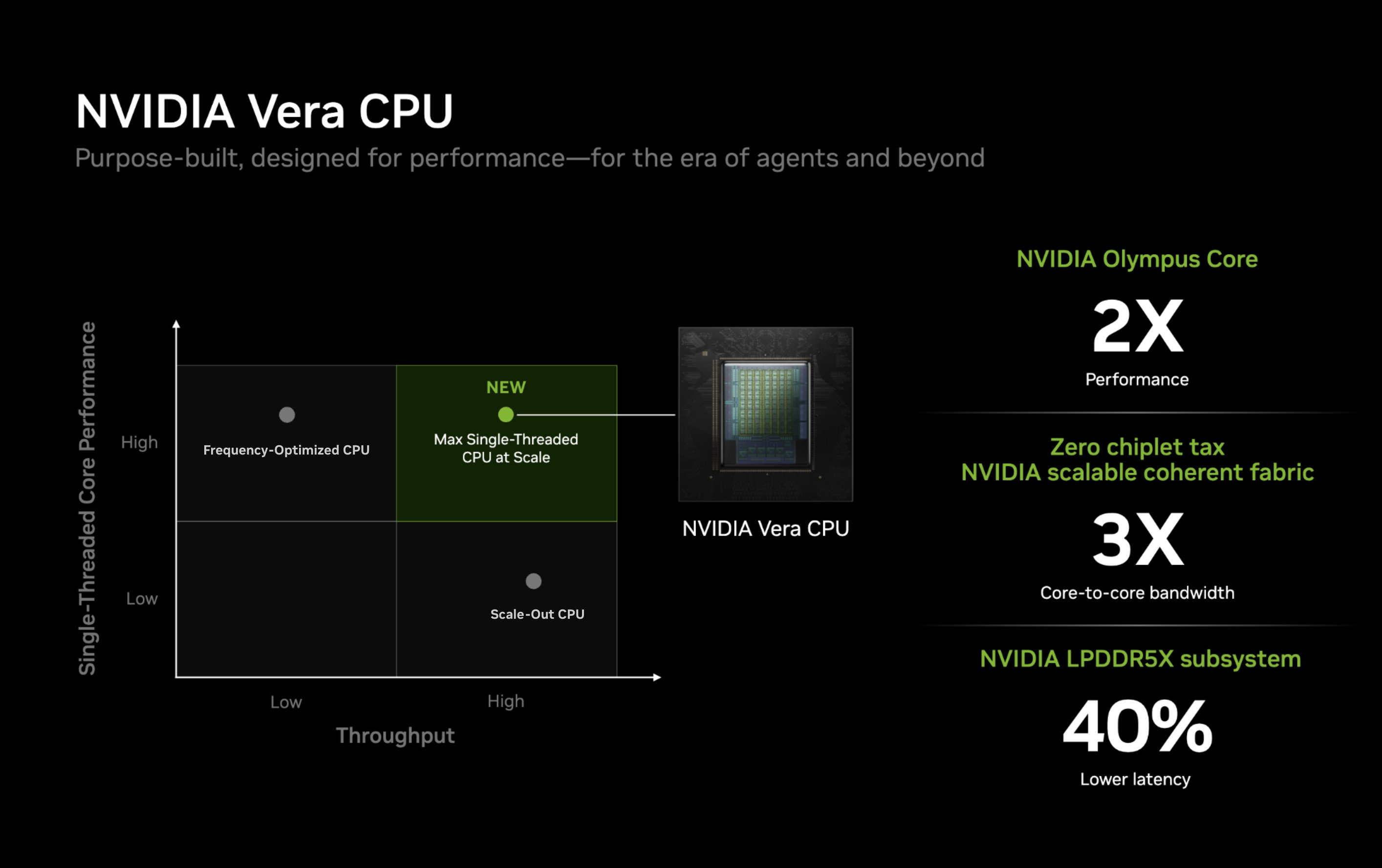
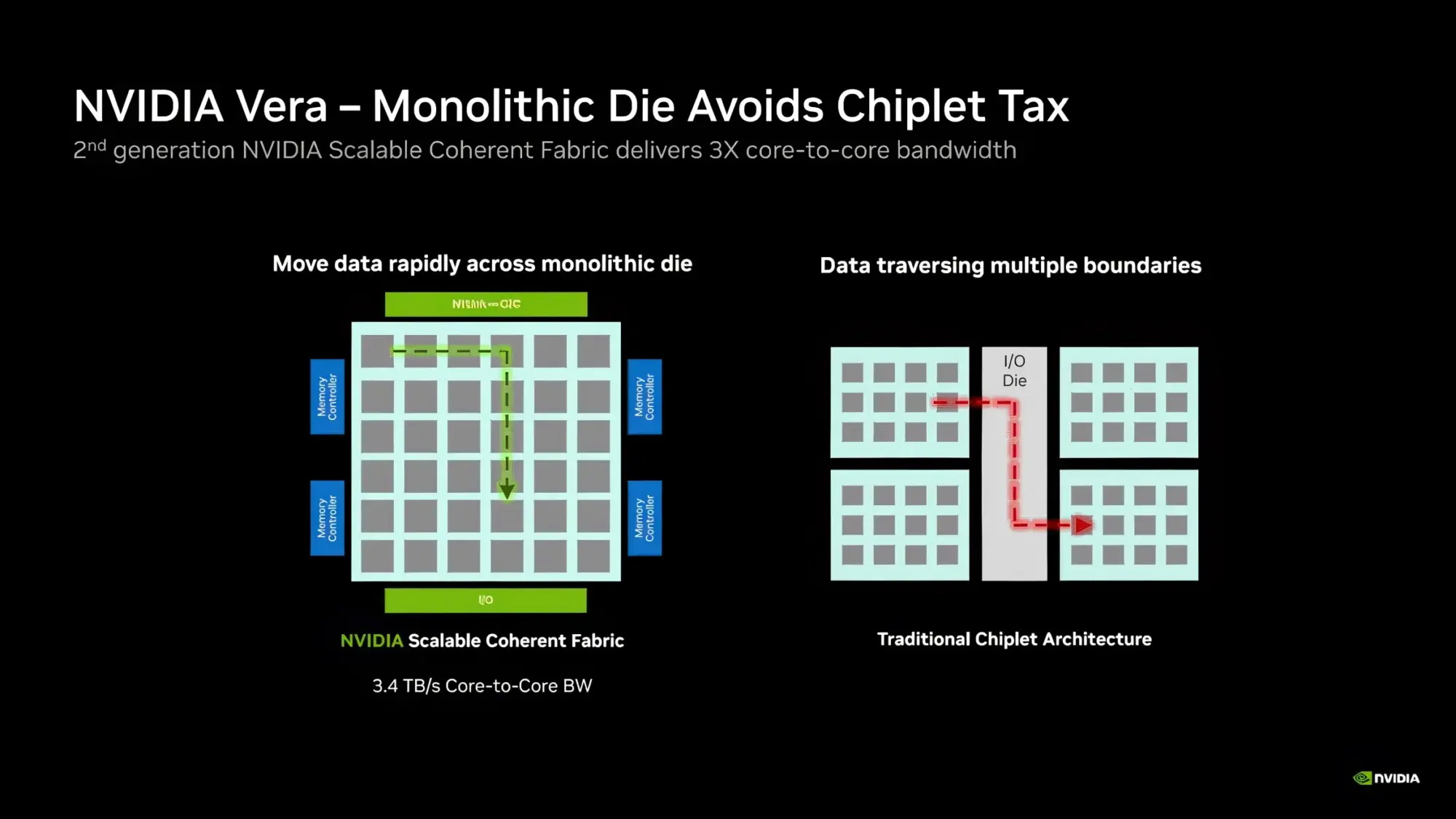
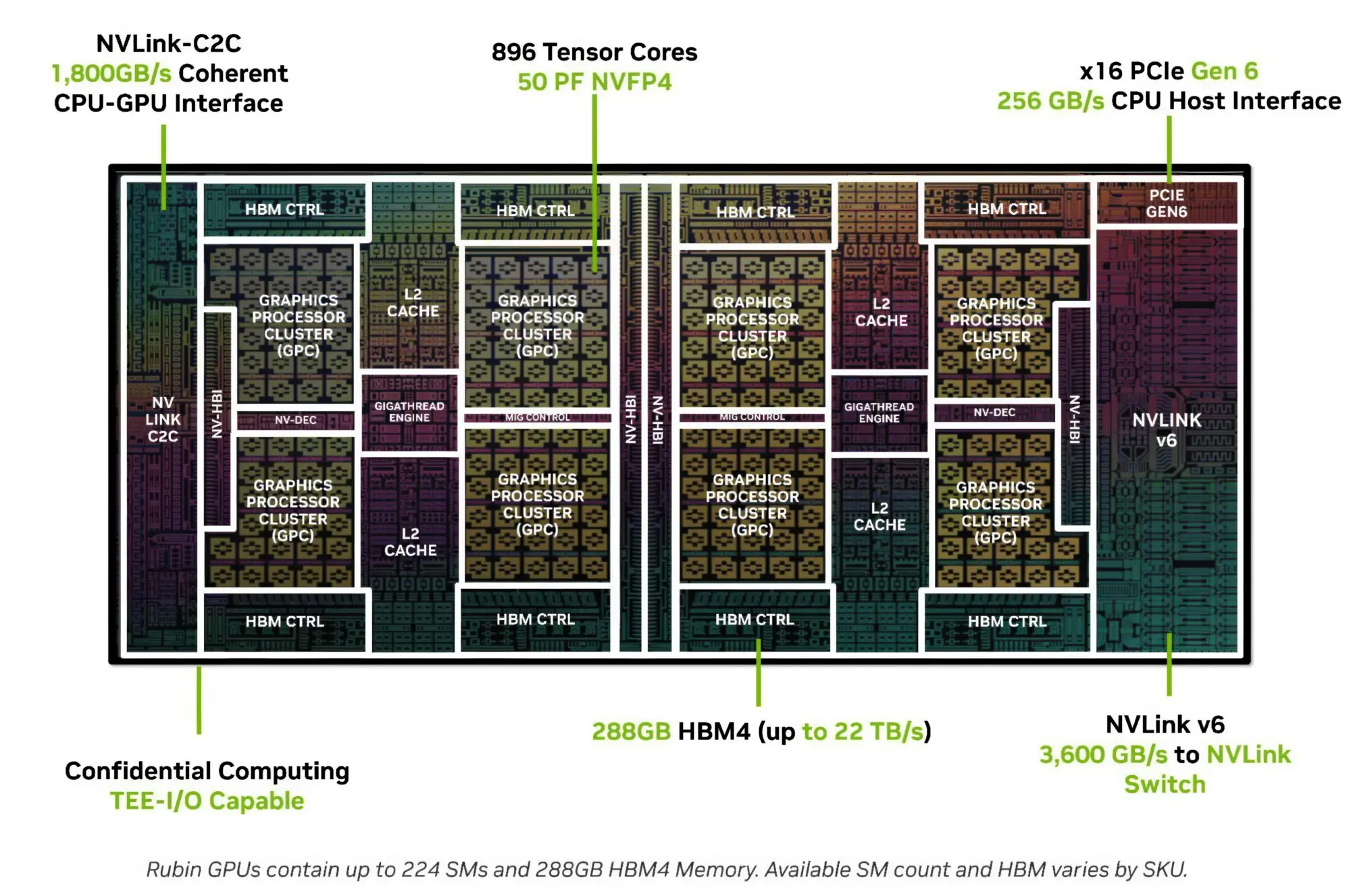
Компания Nvidia опубликовала новые подробности об архитектуре своего процессора Vera для центров обработки данных и используемом в нём специализированном ядре Olympus. Чип Vera объединяет 88 ядер Olympus, 176 аппаратных потоков и унифицированный кеш L3 объёмом 164 Мбайт на монолитном вычислительном кристалле. 
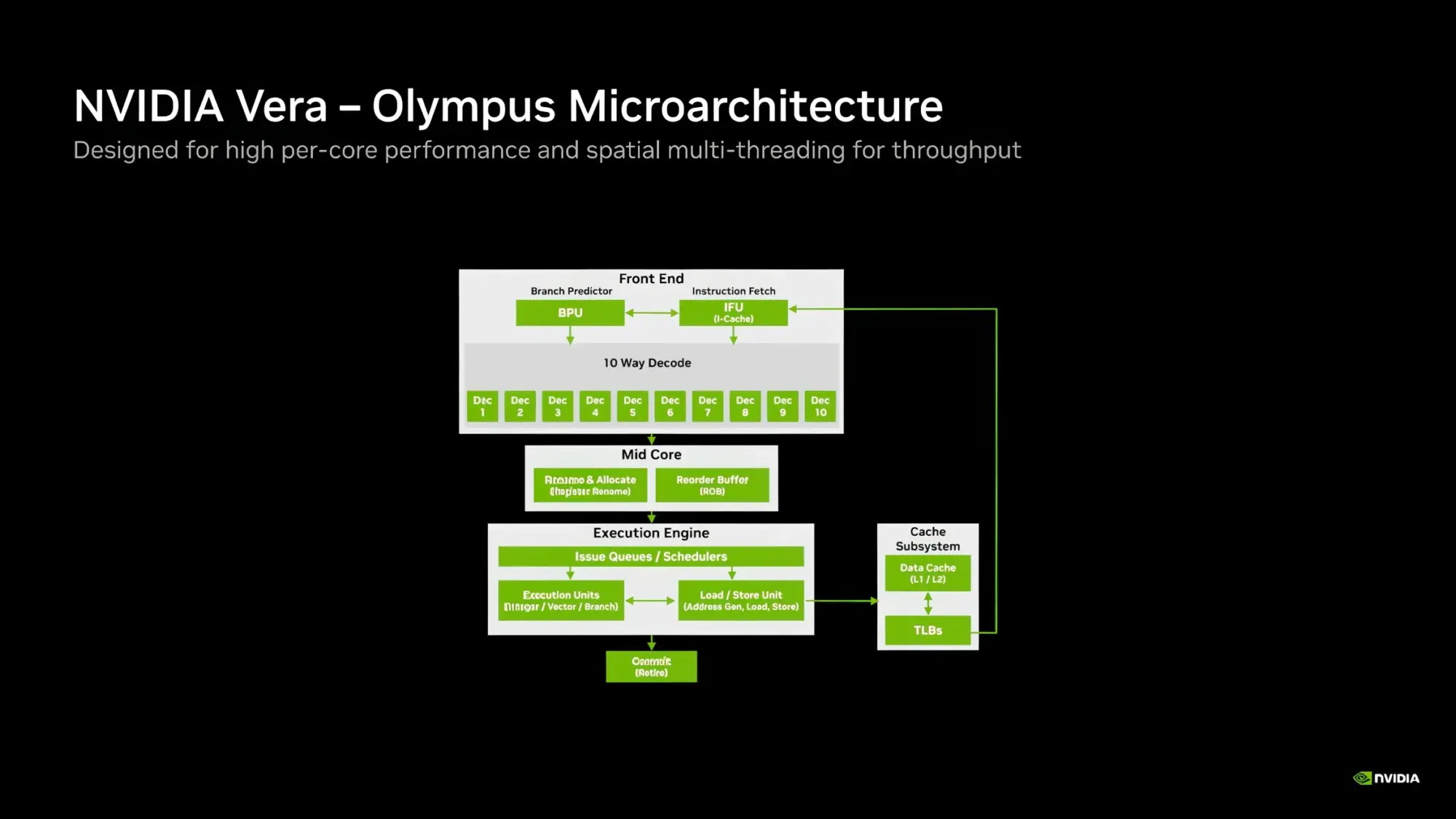
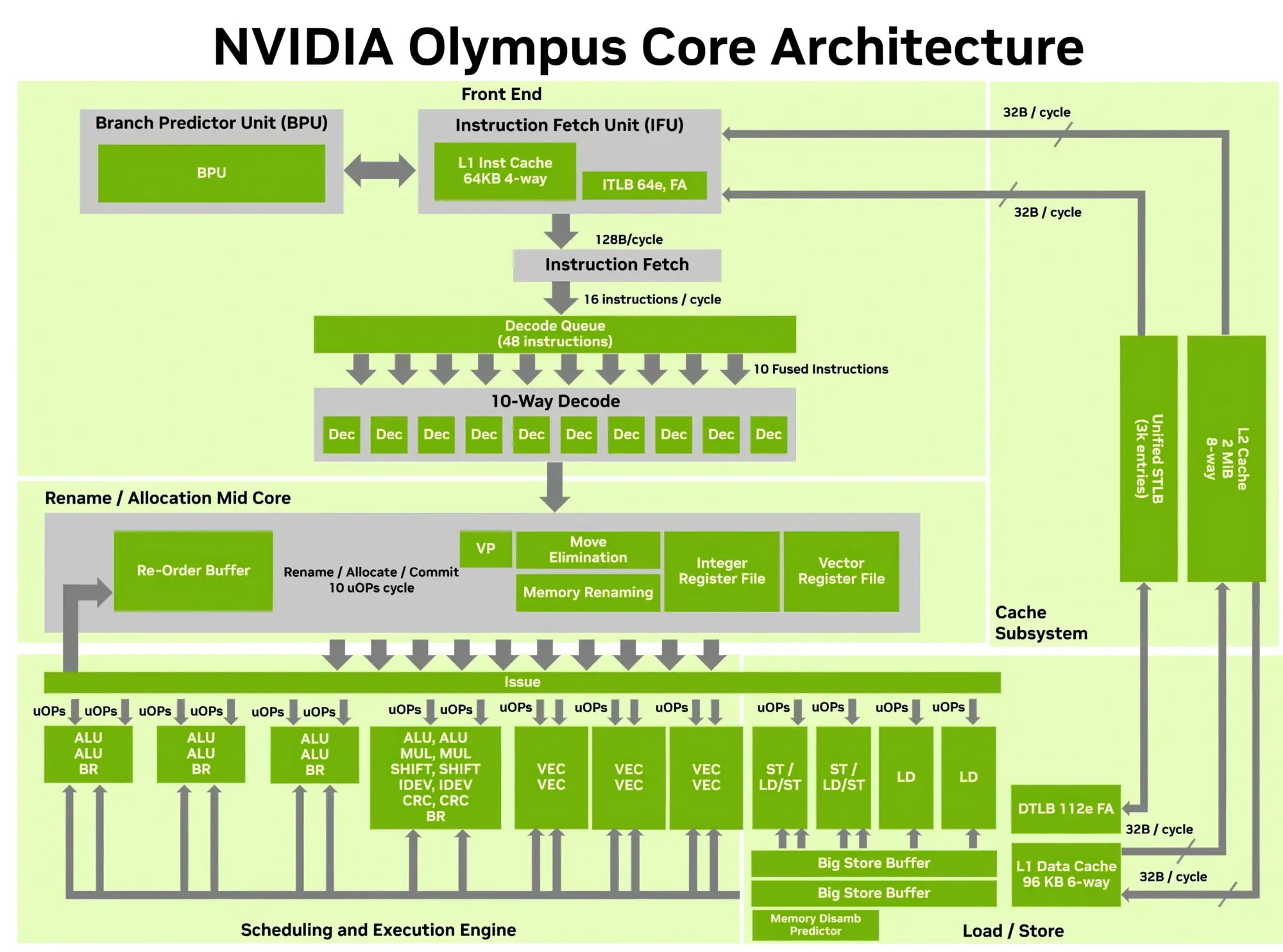
Источник изображений: Nvidia Каждое ядро Olympus использует широкий конвейер с нейронным предсказателем ветвлений, 64-килобайтный четырёхканальный кеш инструкций L1 и очередь декодирования на 48 инструкций. Ядро может считывать до 16 инструкций за такт и включает 10-канальный декодер, способный обрабатывать до десяти объединённых инструкций за такт. 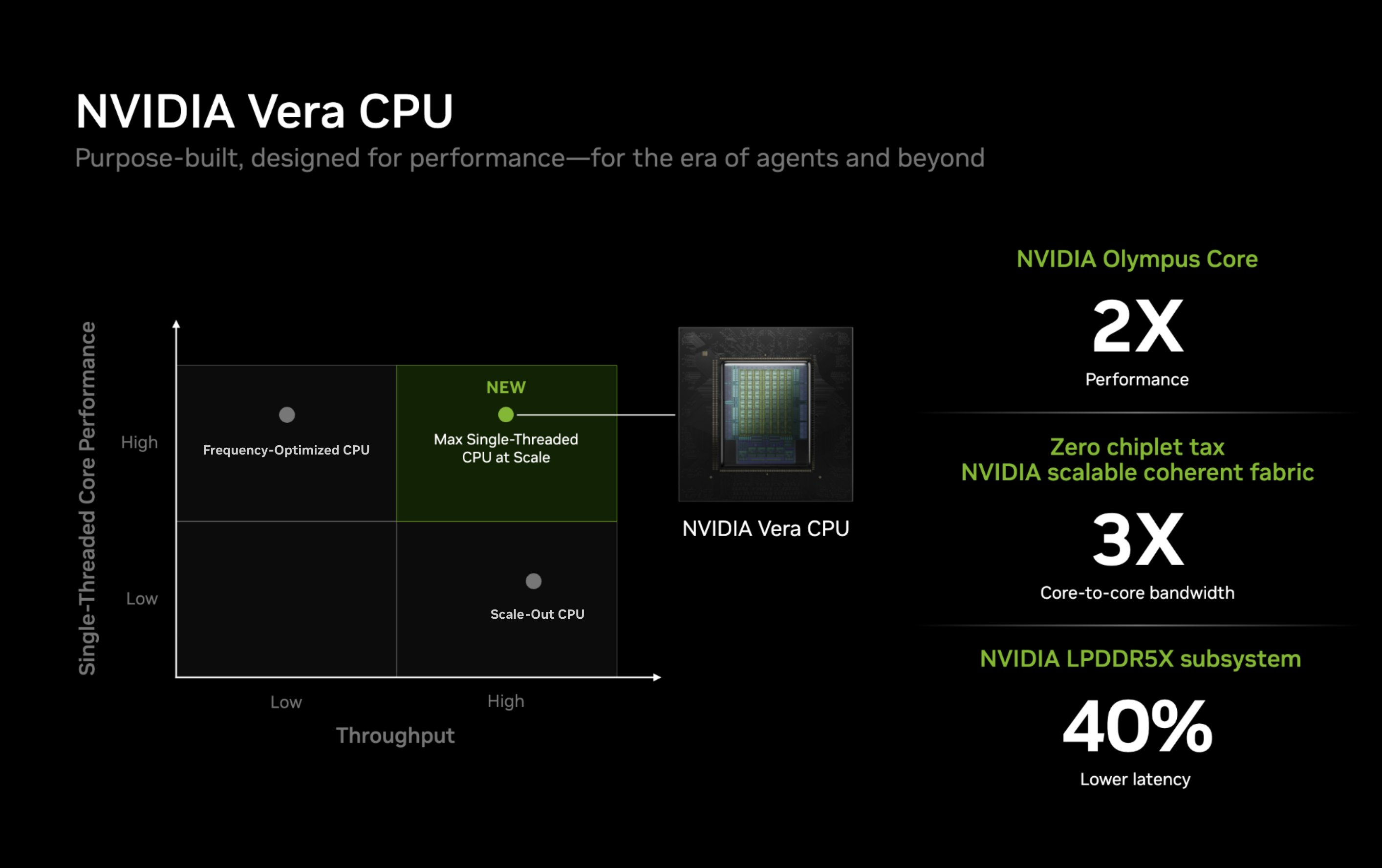 Каждое ядро может переименовывать, выделять и фиксировать до десяти микроопераций за такт. Nvidia также отмечает использование технологий переименования памяти, предсказания значений и исключения перемещений, предназначенных для уменьшения задержек, связанных с зависимостями. Исполнительный блок включает целочисленные операции, операции ветвления, векторные операции, операции с плавающей запятой, криптографические операции, а также выделенные ресурсы для операций загрузки и сохранения данных. Каждое ядро Olympus имеет 96-килобайтный шестиканальный кеш данных L1 и 2-мегабайтный восьмиканальный кеш L2. Nvidia также добавила несколько механизмов аппаратной предварительной выборки, включая предварительную выборку графов для структур данных с большим количеством указателей и рабочих нагрузок, связанных с обработкой графов. Особенности Nvidia Vera
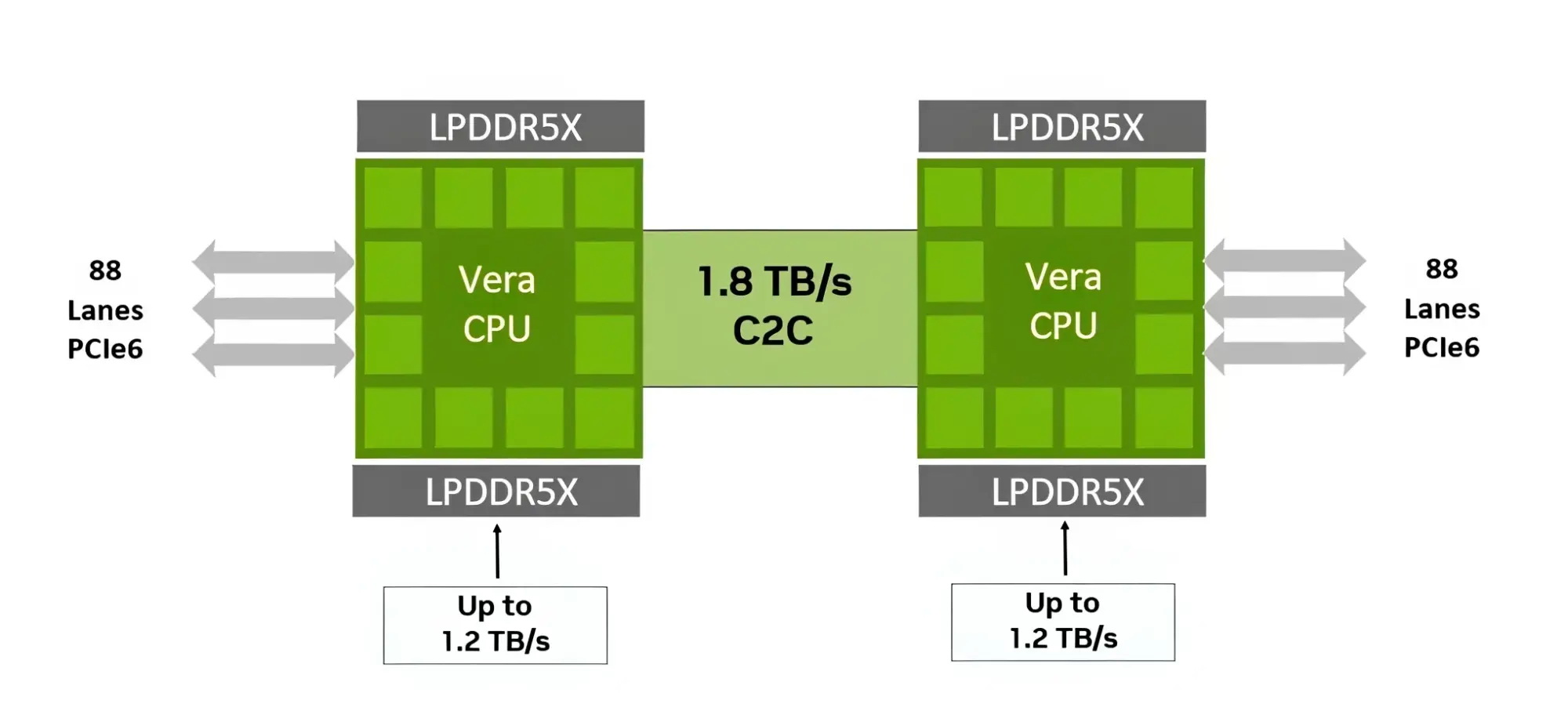
Процессор Vera использует фирменную технологию пространственной многопоточности, которая обеспечивает два аппаратных потока на каждое ядро Olympus. Nvidia заявляет, что такая конструкция позволяет распределять ресурсы ядра между потоками, уменьшая конкуренцию по сравнению с традиционной одновременной многопоточностью. Ядро может отдавать приоритет одному потоку, чувствительному к производительности, в то время как второй поток обрабатывает системные и управляющие задачи. 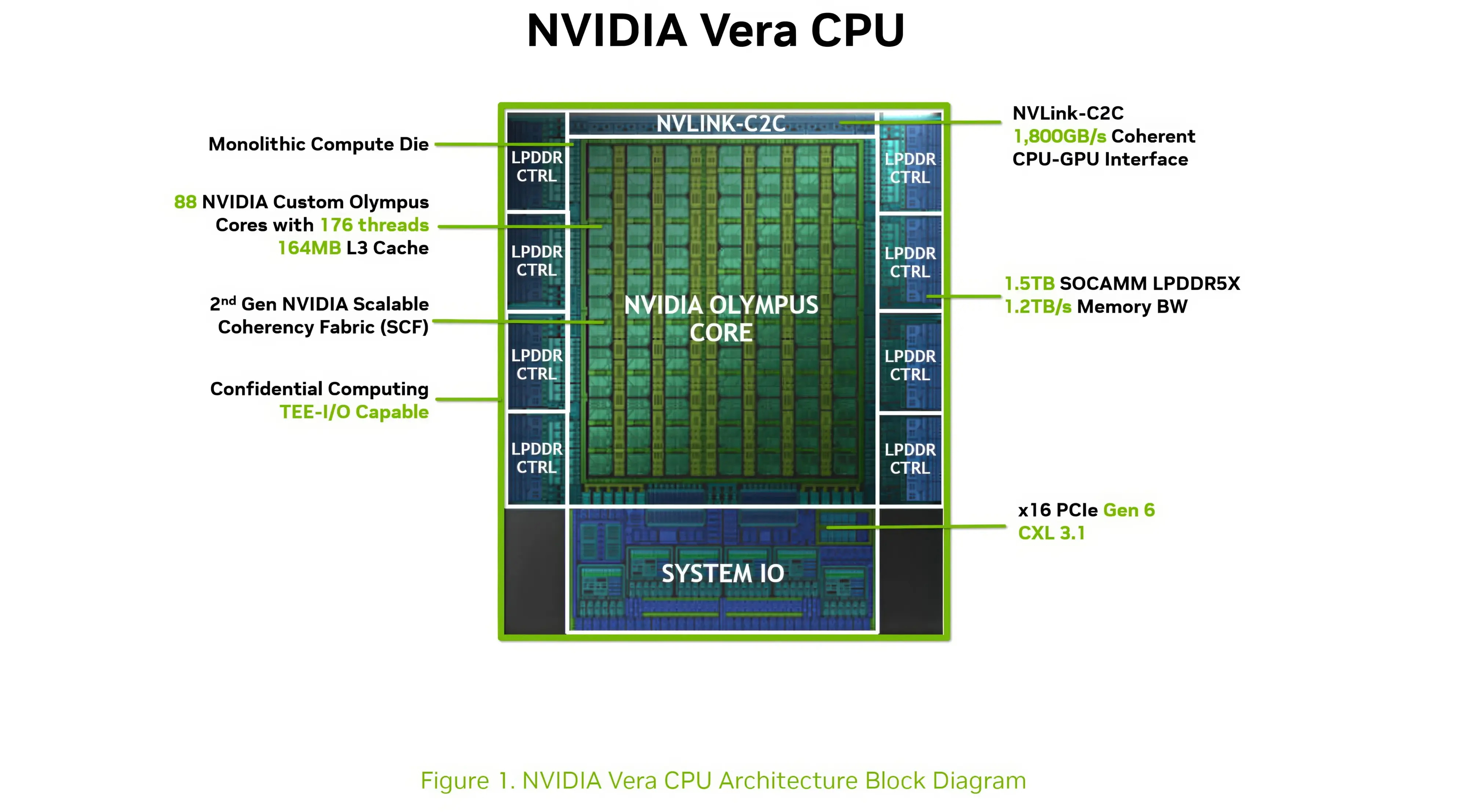 Ядра процессора, кеш, контроллеры памяти и ввода-вывода объединены через масштабируемую когерентную структуру Nvidia второго поколения. Компания заявляет о пропускной способности между ядрами до 3,4 Тбайт/с, пропускной способности памяти SOCAMM2 LPDDR5X до 1,2 Тбайт/с и поддержке до 1,5 Тбайт памяти на процессор. Vera также поддерживает интерфейс NVLink-C2C со скоростью до 1,8 Тбайт/с, PCIe 6.0 и CXL 3.1. Системы с двумя сокетами обеспечивают 176 линий PCIe и используют двухузловую конфигурацию NUMA — по одному домену NUMA на каждый сокет. Nvidia утверждает, что Vera обеспечивает до 1,8 раза более высокую производительность, чем неназванные системы x86, в отдельных рабочих нагрузках, связанных с работой ИИ-агентов. Результаты основаны на внутренних тестах Nvidia SPEC CPU 2026, проведённых в июле 2026 года, и пока не были независимо подтверждены. Прежде чем похоронить семейство Mac Pro, компания Apple рассматривала возможность оснащения этих ПК процессорами Intel
20.07.2026 [08:12],
Алексей Разин
В конце марта текущего года Apple объявила о снятии с производства Mac Pro — мощного настольного ПК, который в последние годы оснащался процессорами разработки Intel, но в свете перехода компании на собственную компонентную базу более не вписывался в стратегические планы производителя. Как выясняется, Apple всё же надеялась создать подходящие для Mac Pro собственные процессоры, а в качестве резервного плана рассматривала использование чипов Intel. 
Источник изображения: Apple По крайней мере, такую версию традиционно изложил в своём воскресном дайджесте на страницах сайта Bloomberg осведомлённый о планах Apple Марк Гурман (Mark Gruman). По его словам, изначально компания не собиралась снимать с производства семейство Mac Pro, и даже разрабатывала две новые перспективные модели J170 и J190, последняя из которых должна была получить процессор M3 Ultra, который был замечен в начале 2023 года в составе Mac Studio. Система J170 при этом должна была оснащаться неким процессором Intel. В целом, как поясняет Гурман, Apple планировала разработать как минимум два флагманских процессора для систем уровня Mac Pro: M2 Extreme и M3 Extreme, но реализации этих планов помешали высокая стоимость чипов и озабоченность компании ограниченностью рынка сбыта таких систем. Теперь самой производительной настольной системой в линейке Apple остаётся Mac Studio, которой и достаются самые мощные процессоры собственной разработки, но они явно уступают в быстродействии гипотетическим чипам с суффиксом Extreme в наименовании. Новая статья: Лучший процессор под DDR4 в 2026 году: AM4 против LGA 1700
20.07.2026 [00:00],
3DNews Team
Данные берутся из публикации Лучший процессор под DDR4 в 2026 году: AM4 против LGA 1700 Утечка: Intel выпустит настольные Core Ultra 400S в несколько этапов на протяжении 2027 года
18.07.2026 [18:25],
Андрей Созинов
Настольные процессоры Intel поколения Nova Lake-S выйдут не одновременно, а несколькими волнами на протяжении почти всего 2027 года. Такой график следует из утечки внутреннего роадмапа компании, опубликованной сайтом VideoCardz. 
Источник: Videocardz Как следует из опубликованных данных, первыми Intel выпустит модели с расширенным кешем bLLC, затем последуют процессоры серии K и другие массовые версии, а дебют 52-ядерного флагмана ожидается лишь во второй половине года. Одновременно утечка впервые раскрыла и коммерческое название нового семейства — Core Ultra 400S: вместе с роадмапом в Сеть попал логотип серии. Согласно опубликованному роадмапу, в первом квартале 2027 года Intel планирует выпустить только процессоры с дополнительным кристаллом кеша bLLC (Big Last Level Cache). Предполагается, что они будут ориентированы прежде всего на игровые системы и станут ответом Intel на процессоры AMD Ryzen X3D. Первой моделью должен стать 28-ядерный процессор с конфигурацией из восьми производительных, 16 эффективных и четырёх малых энергоэффективных ядер. Во втором квартале компания начнёт выпуск остальных представителей семейства Core Ultra 400S. Сначала ожидается появление моделей серии K с разблокированным множителем, после чего Intel постепенно выведет на рынок 16- и 8-ядерные процессоры, а также версии с заблокированным множителем. Таким образом, основная часть линейки должна появиться в течение второго квартала, однако не одновременно, а несколькими последовательными волнами. Выпуск старшего 52-ядерного процессора с двумя вычислительными кристаллами, который считается флагманом поколения Nova Lake, согласно роадмапу, запланирован на период с мая по сентябрь 2027 года. Иными словами, наиболее производительное настольное решение нового поколения, ориентированное на сегмент HEDT, может появиться почти на полгода позже первых представителей семейства. Если утечка подтвердится, Intel впервые за долгое время существенно изменит привычную стратегию вывода настольных процессоров на рынок. Вместо единовременного запуска всей линейки компания будет выпускать новые модели постепенно, распределив их дебют практически на весь 2027 год. По имеющимся данным, процессоры Nova Lake-S получат новую платформу LGA1954, производительные ядра Coyote Cove и эффективные Arctic Wolf, поддержку памяти DDR5-8000, до 24 линий PCI Express 5.0, встроенную графику архитектуры Xe3 Celestial и нейропроцессор нового поколения. Современной памяти не хватает: новые ПК всё чаще получают старые процессоры Intel и AMD
17.07.2026 [18:53],
Алексей Разин
Даже сами производители процессоров признают, что вынуждены поддерживать выпуск устаревающих моделей в условиях концентрации спроса на серверном направлении. Потребительским ПК банально не хватает микросхем памяти современных стандартов, а потому в ход идут совместимые со старой памятью центральные процессоры. Их доля в составе новых ПК в этом году продолжает расти, как отмечают аналитики. 
Источник изображения: Intel Своими наблюдениями с Seeking Alpha поделились эксперты Susquehanna — по их данным, во втором квартале доля современных CPU марки Intel с поддержкой ИИ-функций последовательно не изменилась. Семейство Arrow Lake, например, было представлено в 10 % новых ноутбуков, поступивших на рынок за указанный период. Семейство Lunar Lake последовательно увеличило своё присутствие с 8 до 9 %. При этом более старые семейства процессоров Intel укрепили свои позиции в ассортименте первичного рынка ноутбуков. Так, Tiger Lake прибавило 2 п.п. по сравнению с первым кварталом текущего года, а Ice Lake нарастило присутствие на 1 процентный пункт. В целом, доля выпускаемых по технологии Intel 7 процессоров на первичном рынке ноутбуков во втором квартале сократилась с 54 до 48 %, что может говорить о концентрации компании на производстве серверных процессоров с использованием достаточно современных литографических норм. Зрелые техпроцессы на конвейере Intel в этой ситуации уступают место более современным. Кроме того, серверные процессоры Xeon семейств Sapphire Rapids и Emerald Rapids тоже выпускаются с использованием техпроцесса Intel 7, поэтому компания могла перераспределить доступные мощности в их пользу. Аналогичная тенденция наблюдается и с продукцией AMD, с той лишь разницей, что эта компания не выпускает процессоры самостоятельно, а поручает это делать TSMC и GlobalFoundries. В любом случае, процессоры прежних поколений в новых ПК стали встречаться чаще и в случае с продукцией AMD. Пока объёмы выпуска ПК в текущем году оказываются выше ожидаемого уровня, но представители Susquehanna убеждены, что второе полугодие продемонстрирует более выраженную отрицательную динамику, и в целом по итогам года поставки новых ПК просядут на 10 %. Учёные впервые синхронизировали 105 тысяч наноосцилляторов — это шаг к сверхбыстрой альтернативе кремниевым транзисторам
17.07.2026 [17:19],
Павел Котов
Группа учёных под руководством специалистов из Индийского технологического института в Бхубанешваре добилась крупного прорыва в спинтронных вычислениях — они обеспечили синхронизацию более 105 000 наноосцилляторов всего за 45 наносекунд. Технология открывает путь к сверхбыстрым вычислительным элементам, более эффективным, чем современные кремниевые транзисторы. 
Источник изображения: Brecht Corbeel / unsplash.com Традиционные кремниевые чипы обрабатывают данные, гоняя электроны по нескольким миллиардам крошечных транзисторов — при этом выделяются большие объёмы тепла. Спинтроника предлагает изящную альтернативу: исходной величиной здесь является собственный спин, аналог магнитного вращения, электронов, но не их физическое движение, а передача данных осуществляется через спиновые волны. Основу новой технологии составили спиновые наноосцилляторы Холла, которые генерируют распространяющиеся магнитные спиновые волны. Чтобы создать мощный процессор, необходимо добиться колебания этих наноэлементов в унисон. Ранее учёным удавалось синхронизировать не более 64 таких наноосцилляторов в двухмерной сетке. Чтобы увеличить это число, необходимо было расположить их как можно ближе друг к другу. Решить проблему индийским учёным помогли коллеги из Гетеборгского университета (Швеция) и Университета Тохоку (Япония) — совместными усилиями они построили сверхузкие наноконстуркции размером всего 10 и 20 нм в поперечнике. Используя трехслойные материалы вольфрам-тантал и кобальт-железо-бор, они собрали в одной сетке более 105 000 компонентов. При подаче электрического тока вся сеть синхронизировалась за 45 нс. Быстро упорядочить фазы помог обмен магнонами — квазичастицами спиновых волн. Между наноустройствами образовалась связь при минимальном рассеянии энергии. Общая мощность сети и качество сигнала очень хорошо масштабируется, установили учёные. При таком уровне производительности на наноосцилляторах можно будет строить машины Изинга — специализированные процессоры, предназначенные исключительно для почти мгновенного решения задач по оптимизации со множеством переменных. Можно будет формировать наиболее эффективные маршруты доставки, в реальном времени моделировать схемы финансовых рисков, а также оптимизировать нейросети — передовые системы искусственного интеллекта. |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex