|
Опрос
|
реклама
Быстрый переход
«Т-Банк» выпустил ИИ-модель распознавания речи с открытым исходным кодом — T-one
22.07.2025 [11:32],
Антон Чивчалов
Российская группа компаний «Т-Технологии», владеющая «Т-Банком», опубликовала собственную ИИ-модель распознавания речи с открытым исходным кодом. Речевая модель под названием T-one обещает новый уровень качества распознавания, по словам её разработчиков. Также обещаются прорывные решения, такие как распознавание речи в реальном времени, передаёт Forbes. 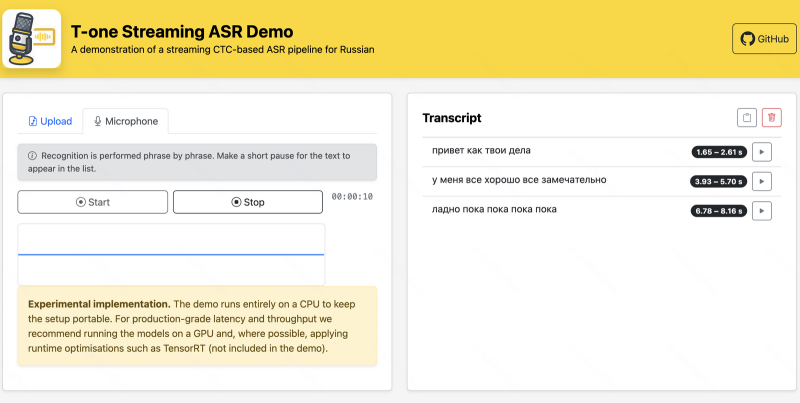
Источник изображения: «Т-Технологии» Более подробно о T-one представители «Т-Технологий» рассказали 19 июля в Москве на Второй конференции по машинному обучению Turbo ML. А на официальном ресурсе компании на платформе GitHub объясняется, что T-one — это высокопроизводительная система автоматического распознавания речи (ASR) с акцентом на распознавание русского языка в телефонии. Кстати, на GitHub она уже доступна для скачивания. Также её можно загрузить с Hugging Face. Для разработчиков приведены инструкции по развёртыванию системы. T-one — модель относительно небольшая, около 70 млн параметров. Для сравнения, речевая модель компании GigaAM от «Сбера» состоит из 240 млн параметров, а модель Whisper large-v3 от OpenAI — из 1,55 млрд. Однако, по утверждениям разработчиков T-One, это не мешает последней обгонять именитых конкурентов именно в распознавании русской речи в телефонных разговорах, под что она «заточена». «Т-Технологии» позиционируют свою разработку как для бизнеса, так и для научного сообщества. Второму она будет интересна низкой стоимостью: эксплуатация на собственном сервере должна быть в десятки раз дешевле конкурирующих решений от облачных провайдеров. T-one хорошо адаптируется под нужды конкретной компании и разработку собственных решений. «Это могут быть компании, разрабатывающие голосовых роботов и ассистентов, занимающиеся автоматизацией кол-центров, — пояснили представители «Т-Технологий» на конференции Turbo ML. — Они могут взять за основу эту модель и адаптировать её под свои решения. Это позволит сократить ресурсы на разработку с нуля». Meta✴ в партнёрстве с ЮНЕСКО запускает новую программу сбора данных для улучшения речи и перевода ИИ
07.02.2025 [18:49],
Сергей Сурабекянц
LTPP (Language Technology Partner Program — партнёрская программа по языковым технологиям) — совместная инициатива ЮНЕСКО и Meta✴✴ по поиску авторов, которые могут предоставить более 10 часов записей речи с транскрипциями, большие объёмы письменного текста и наборы переведённых текстов на разных языках. В дальнейшем эти данные будут интегрированы в ИИ-модели с открытым исходным кодом для распознавания речи и перевода. Усилия LTPP будут сосредоточены на недостаточно обслуживаемых языках для поддержки работы, уже проводимой в этом направлении ЮНЕСКО. «В конечном итоге наша цель — создать интеллектуальные системы, которые могут понимать и реагировать на сложные потребности человека, независимо от языка или культурного происхождения», — заявил представитель Meta✴✴. В дополнение к новой инициативе Meta✴✴ опубликовала открытый исходный код программы для оценки производительности моделей языкового перевода. Тест, состоящий из предложений, созданных лингвистами, поддерживает семь языков, и доступен на платформе разработки ИИ Hugging Face. Meta✴✴ продолжает расширять количество языков, поддерживаемых её ИИ-моделями и развивать функции автоматического перевода для создателей контента. В сентябре прошлого года компания начала тестирование инструмента для перевода голосов в Instagram✴✴ Reels, который дублирует речь создателя на другом языке с автоматическим липсинком. На сегодняшний день обработка на платформах Meta✴✴ контента на языках, отличных от английского, далека от совершенства. По некоторым данным, в соцсети Facebook✴✴ 79 % дезинформации о COVID на итальянском и испанском языках не были распознаны и отмечены системой, по сравнению с 29 % на английском языке. А сообщения на арабском языке, наоборот, часто ошибочно помечаются как разжигающие ненависть. Meta✴✴ заявила, что принимает меры по улучшению своих технологий перевода и модерации. И, хотя компания позиционирует обе свои языковые инициативы как филантропические, нет никаких сомнений, что главным бенефициаром этих программ станет именно Meta✴✴, которая сможет существенно улучшить качество распознавания речи и перевода. |
|
✴ Входит в перечень общественных объединений и религиозных организаций, в отношении которых судом принято вступившее в законную силу решение о ликвидации или запрете деятельности по основаниям, предусмотренным Федеральным законом от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности»; |
© 1997—2026 Электронное периодическое издание "3ДНьюс" | Свидетельство о регистрации СМИ Эл ФС 77-22224
выдано Федеральной Службой по надзору за соблюдением законодательства в сфере массовых коммуникаций и охране культурного наследия
При цитировании документа ссылка на сайт с указанием автора обязательна. Полное заимствование документа является
нарушением
российского и международного законодательства и возможно только с согласия редакции 3DNews.








 MWC 2018
MWC 2018 2018
2018 Computex
Computex




